1. Introduction
Diabetes is one of the diseases that people are most afraid of nowadays. Every country around the globe, whether developed or underdeveloped, is affected by the diabetes epidemic. These days, it affects the entire country and is a hardship for all the nations, especially for emerging nations like Bangladesh, India, and Pakistan [
1]. People with little awareness of medical conditions are at greater risk. The World Health Organization (WHO) report says that, from 1980 to 2014, there were about 314 million diabetes patients worldwide [
2]. Moreover, according to this research, diabetes spreads more rapidly in developing nations than in high-income ones [
2]. From 2000 to 2019, diabetes deaths among certain ages have increased by almost 3%. Diabetes and kidney disease caused almost 2 million deaths worldwide in 2019 [
2]. Based on research findings, the rate of diabetes was most pronounced in South Asian populations, with the highest prevalence in individuals from Sri Lanka (26.8%), followed by those from Bangladesh (22.2%), Pakistan (19.6%), India (18.3%), and Nepal (16.5%), when compared to non-immigrant populations, which had a prevalence of 11.6% [
1].
Diabetes is a chronic illness brought on by either insufficient insulin production by the pancreas or inefficient insulin utilization by the body. There are mainly two types of diabetes, namely type 1 and type 2 diabetes. In addition to that there, are additional types of diabetes such as diabetes mellitus and gestational diabetes [
3]. Diabetes is the source of many other deadly diseases. It is a highly potential disease to harm the heart, blood vessels, eyes, kidneys, and nerves. Therefore, it is urgent to predict diabetes among patients. Otherwise, it can cause other diseases in our bodies. We can prevent this dangerous disease by following some lifestyle rules, although this does not discard the risk of developing diabetes. If we can predict diabetes at an early stage, it is possible to control it. Changing their lifestyle and obeying the doctor’s suggestion, a patient can experience relief from this disease. Therefore, it is said that predicting diabetes at an early stage is crucial to reducing the mortality rate of this disease. Every year, all the countries around the globe spend a large number of funds on diabetes. A report from the American Diabetes Association (ADA) expresses that the whole world spent USD 245 billion in 2012, and the amount of money increased by USD 82 billion in the following five years.In 2017, this number reached USD 327 billion [
4]. Predicting diabetes disease at an early stage can also help reduce these costs.
In recent years, numerous studies have looked into predicting diabetes through several machine learning (ML) models. Khanam et al. (2021) have shown a neural network (NN) (NN)-based model with an accuracy of 88.6%. In their study, they utilized a dataset obtained from the Pima Indian Diabetes (PID) dataset. Although they built a model with an NN, they did not show the impact of the features on this model in their research and the accuracy of the model was also not good enough [
5]. Islam et al. (2020) performed data mining techniques and found that random forest (RF) gave the best results, with a 97.4% accuracy on 10-fold cross-validation and a 99% accuracy on the train–test split. They used a dataset collected through oral interviews from Sylhet Diabetes Hospital patients in Sylhet, Bangladesh. They showed good accuracy, but their dataset was unbalanced. They did not use any data-balancing techniques [
6]. Krishnamoorthi et al. (2022) built a framework for diabetes prediction called the intelligent diabetes mellitus prediction framework (IDMPF) with an accuracy of 83%. They employed a dataset called the Pima Indian Diabetes (PID) dataset. The result of their model is still not good enough, and there is scope to improve it [
7].
Islam et al. (2020) proposed a model for the prediction of type 2 diabetes in the future, and they achieved a 95.94% accuracy [
8]. The collected dataset used in their study was from the San Antonio Heart Study, a widely prescribed investigation. The study was successful, but the number of features used was only 11, which is an insufficient number to build and validate a machine learning model. Hasan et al. (2020) assembled classifiers to propose a model with an AUC of 0.95. In this work, they utilized the Pima Indian Diabetes (PID) dataset [
9]. Fazakis et al. (2021) proposed an ensemble Weighted Voting LRRFs ML model with an AUC of 0.884 for type 2 diabetes prediction [
10]. The collected dataset in their study was from the English Longitudinal Study of Ageing (ELSA) database. In this study, there were not any feature analysis techniques. Ahmed et al. (2022) proposed a machine learning (ML) based model of the Fused Model for Diabetes Prediction (FMDP) and obtained an accuracy of 94.87% [
11]. For this study, they used a dataset collected from the hospital of Sylhet, Bangladesh. Their study method was well designed, but they did not show any feature impact on the model and conducted no feature analysis. Maniruzzaman et al. (2020) introduced a model combining logistic regression (LR) feature selection and random forest (RF), which gave an accuracy of 94.25% and an AUC of 0.95 [
12]. The National Health and Nutrition Examination Survey conducted from 2009 to 2012 was used in their research. The dataset has only 14 features. Barakat et al., in 2010, conducted a study for diabetes mellitus prediction using a support vector machine (SVM) with an accuracy of 94%, a sensitivity of 93%, and a specificity of 94% [
13]. In this study, they did not introduce any feature analysis techniques.
Therefore, in this research, we proposed a machine learning (ML)-based model for diabetes prediction at an early stage. In recent years, ML has proven to be a very efficient technique for disease prediction. Nowadays, ML plays an essential role in the biomedical sector to overcome traditional methods of diagnosis, disease prediction, and treatment. Consequently, there is no doubt about using an ML-based prediction model to predict diabetes. Our contributions are mentioned as follows:
Building an ML model that will predict diabetes using socio-demographic characteristics rather than clinical attributes. This is relevant because not all people, especially those from lower-income countries, have access to their clinical features.
Revealing significant risk factors that indicate diabetes.
Proposing a best fit and clinically usable framework to predict diabetes at an early stage.
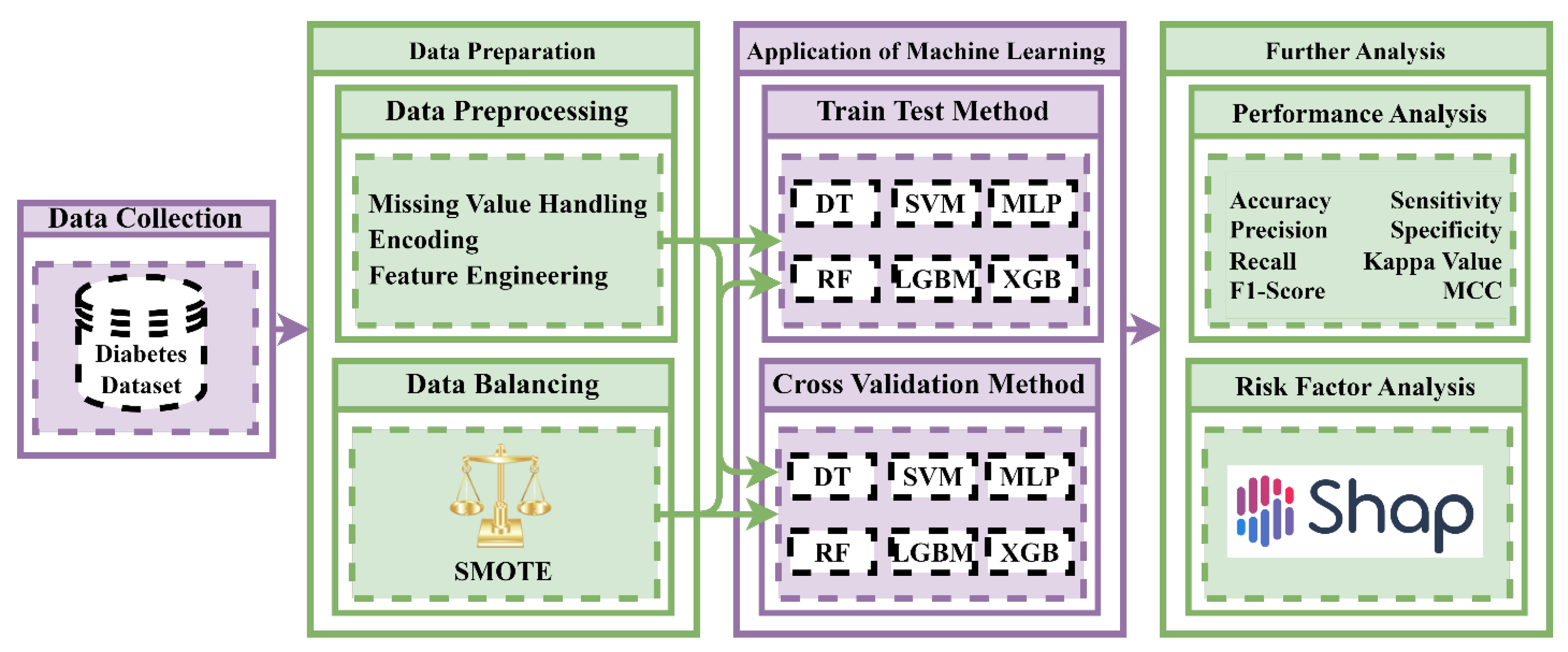
3. Result Analysis and Discussion
In this study, six supervised ML algorithms were employed to build a model to predict diabetes using socio-demographic characteristics in the early stages. Before applying machine learning techniques, exploratory data analysis (EDA) is performed to explore the hidden knowledge of the applied dataset. Then, ML techniques are conducted to build a potential model to predict diabetes and to identify the most significant socio-demographic risk factors related to diabetes. All the findings of this study are represented in this section.
3.1. Exploratory Data Analysis (EDA) Result
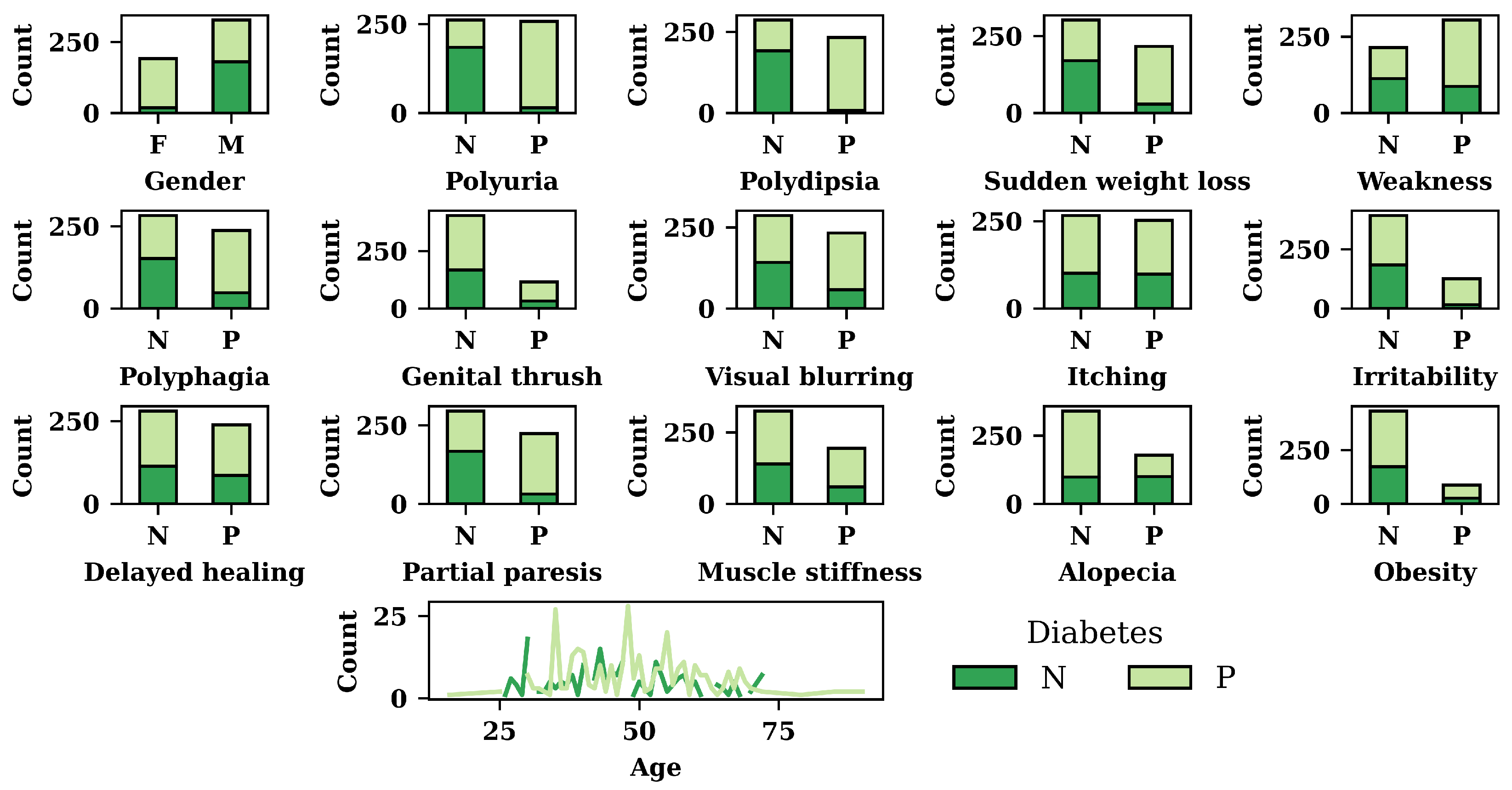
Figure 3 depicts the results of exploratory data analysis of the diabetes dataset for all the features. In
Figure 3, N refers to the negative, whereas P refers to the positive. In addition to that F, and M refer to females and males, respectively. According to
Figure 3, females are more affected by diabetes compared to males. The figure also shows that patients with polyuria, polydipsia, or sudden weight loss are more likely to have diabetes. Of the patients who do not have polyuria, polydipsia, and sudden weight loss, around 70% do not have diabetes. For polyphagia, irritability, partial paresis, and obesity syndromes, patients have a high diabetes risk. Among those who do not have polyphagia, irritability, partial paresis, or obesity, about half have diabetes. According to
Figure 3, patients who are more than 30 years old are highly vulnerable to diabetes.
3.2. Performance Evaluation of ML Models
Six machine learning models such as MLP, SVM, DT, LGBM, XGB, and RF were applied and their performances were compared to each other to find the best-fit model to predict diabetes in the early stage. The results of the ML models are represented in the following sections.
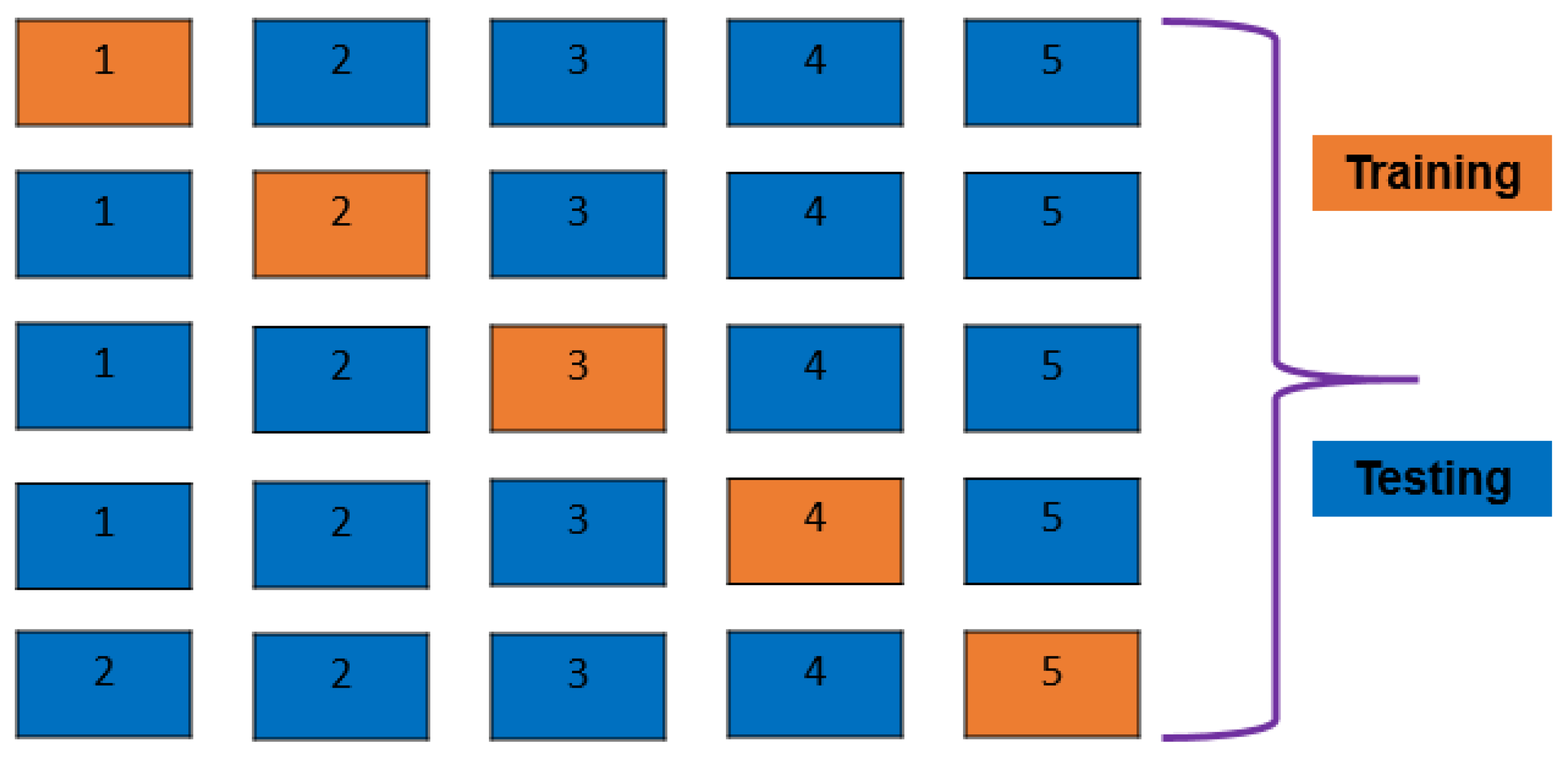
At first, the imbalanced dataset was trained using the train–test split method, where 70% of the dataset was utilized to train the model, and 30% of the dataset was employed for testing the built models. The result of the train–test split method on the imbalanced dataset is represented in
Table 2. According to
Table 2, the lowest performance is generated by SVM and MLP classifiers. RF has the highest accuracy score of 98.44% among the six ML algorithms. Furthermore, RF also gives the maximum scores for the rest of the performance metrics: precision, recall, f1-score, sensitivity, specificity, kappa statistics, and MCC value, which are, respectively, 0.9800, 0.9899, 0.9849, 0.9785, 0.9899, 0.9687, and 0.9687.
Table 3 shows the results for different performance metrics on the imbalanced dataset. RF has the highest accuracy score of 98.44% among the six ML algorithms. Furthermore, RF also gives the maximum scores for the rest of the performance metrics: precision, recall, f1-score, sensitivity, specificity, kappa statistics, and MCC value, which are, respectively, 0.9800, 0.9899, 0.9849, 0.9785, 0.9899, 0.9687, and 0.9687.
Table 4 represents detailed information about the ML approaches for five-fold CV results on the balanced dataset. The maximum CV accuracy is 94.87% for RF classifiers. DT shows the highest precision value of 0.9784, and RF gives the highest recall and f1-scores of 0.9608 and 0.9608. At the same time, DT also gains the maximum sensitivity value of 0.9629. The maximum specificity, kappa statistics, and MCC values given through RF are 0.9608, 0.8867, and 0.8867, respectively.
The five-fold CV results on the balanced dataset for the ML approaches are described in
Table 5. According to
Table 5, RF and LGBM have the highest maximum accuracy of 93.23%. Moreover, RF and LGBM show the highest precision value of 0.9574. The highest recall and specificity value is 0.9091, which is generated by DT, RF, XGBoost, and LGBM classifiers. Both RF and LGBM show a maximum sensitivity score of 0.9570. RF and LGBM have shown maximum values of f1-score, kappa statistics, and MCC of 0.9326, 0.8647, and 0.8658, respectively.
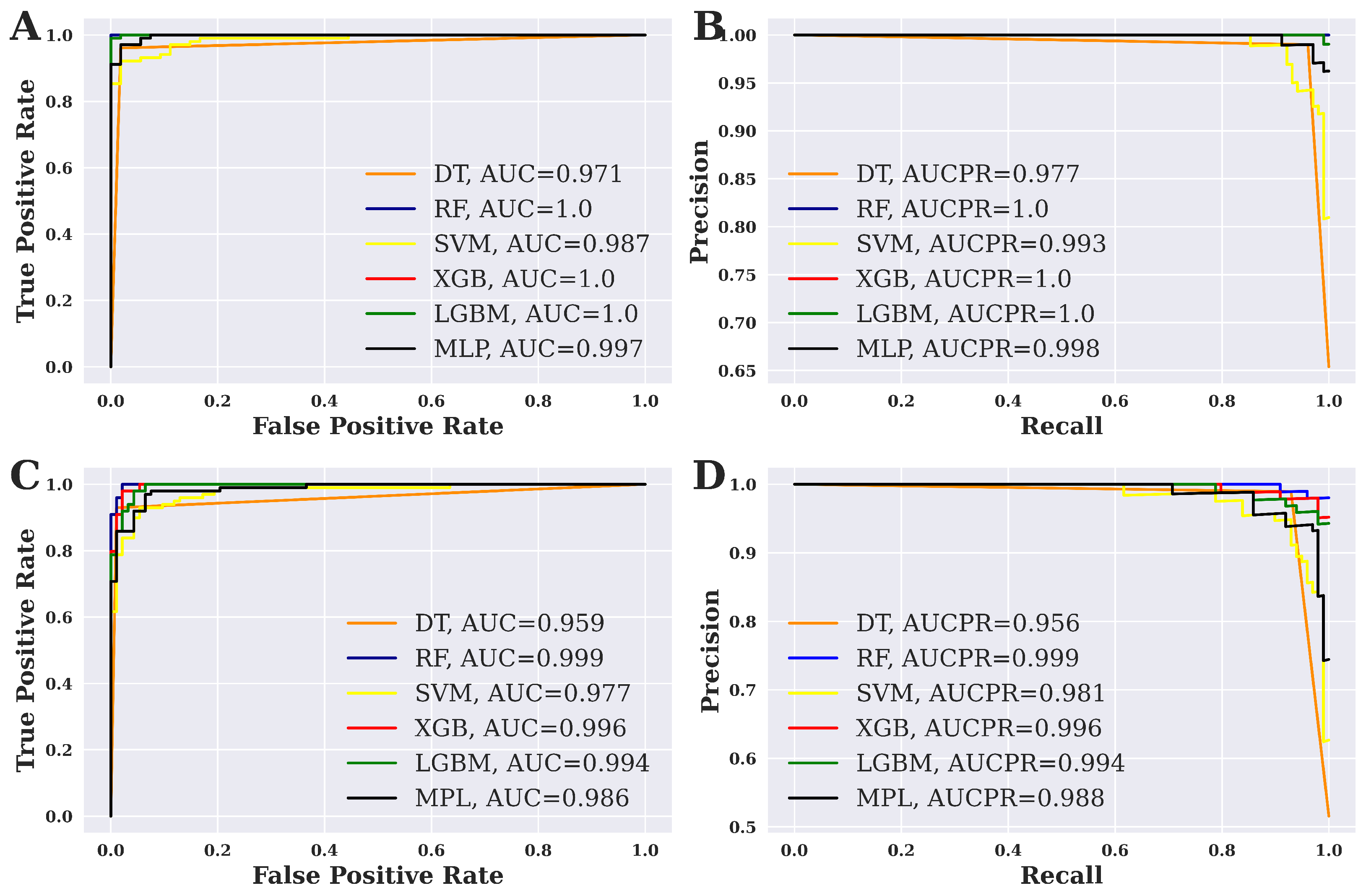
Figure 4 shows the ROC curve and precision–recall (PR) curve for six different ML techniques that have been applied in this study. The results for the balanced dataset are shown in
Figure 4A,B. On the other hand,
Figure 4C,D show the results of the imbalanced dataset. For a balanced dataset, the highest AUC score is 1.00 for RF, XGBoost, and LGBM, as shown in the figure. At the same time, RF, XGBoost, and LGBM show the highest AUCPR value, which is also 1.00. On the contrary, the maximum AUC score is 0.999, as shown by RF. It is worth noting that RF also shows the highest AUCPR value of 0.999 for an imbalanced dataset.
3.3. Overall Performance Evaluation for ML Methods
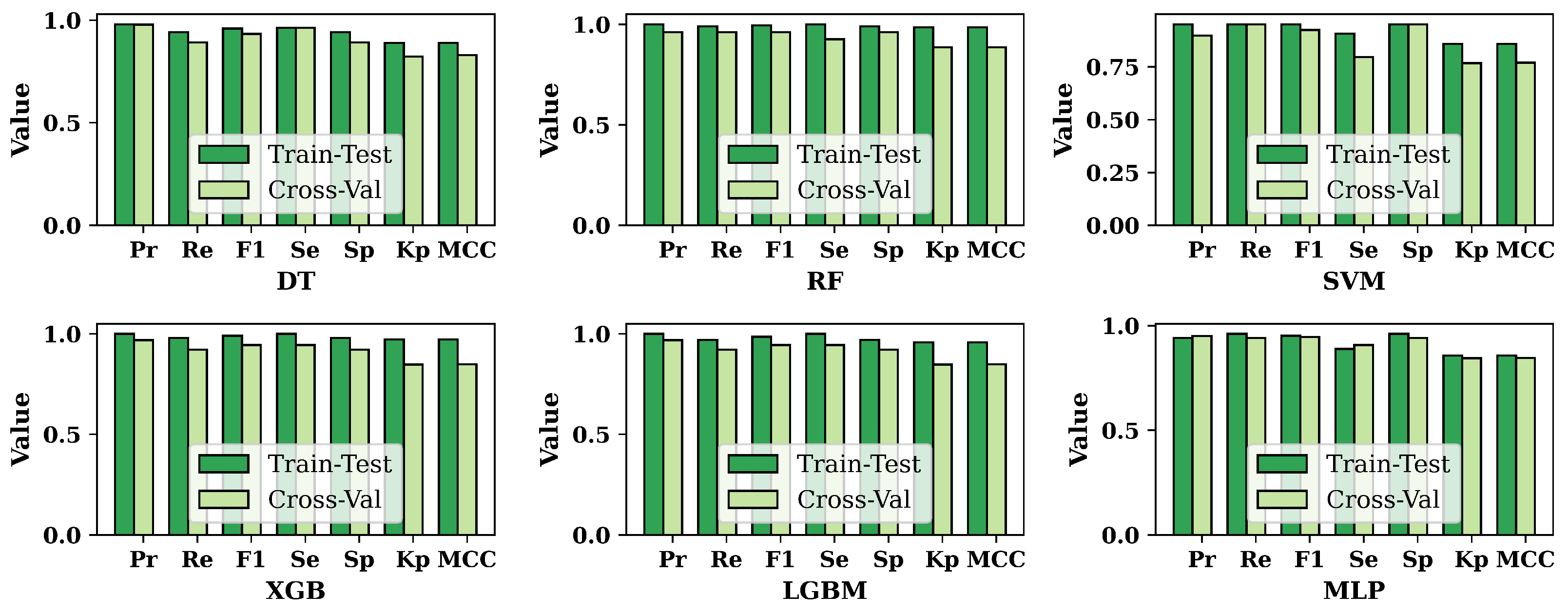
The results of the performance metrics for six ML approaches are shown in
Figure 5. In
Figure 5, we compare the results of train–test split and cross-validation techniques for the balanced dataset. It is shown that the results of train–test-split are mostly higher than those of cross-validation. But in a few cases, the results of cross-validation are increasing. For DT, precision and sensitivity show the same results for both train–test split and cross-validation. SVM yields the same recall and specificity results for both techniques. Furthermore, the MLP shows few exceptions; in the MLP, the results of precision and sensitivity for cross-validation are higher than the train–test split’s result.
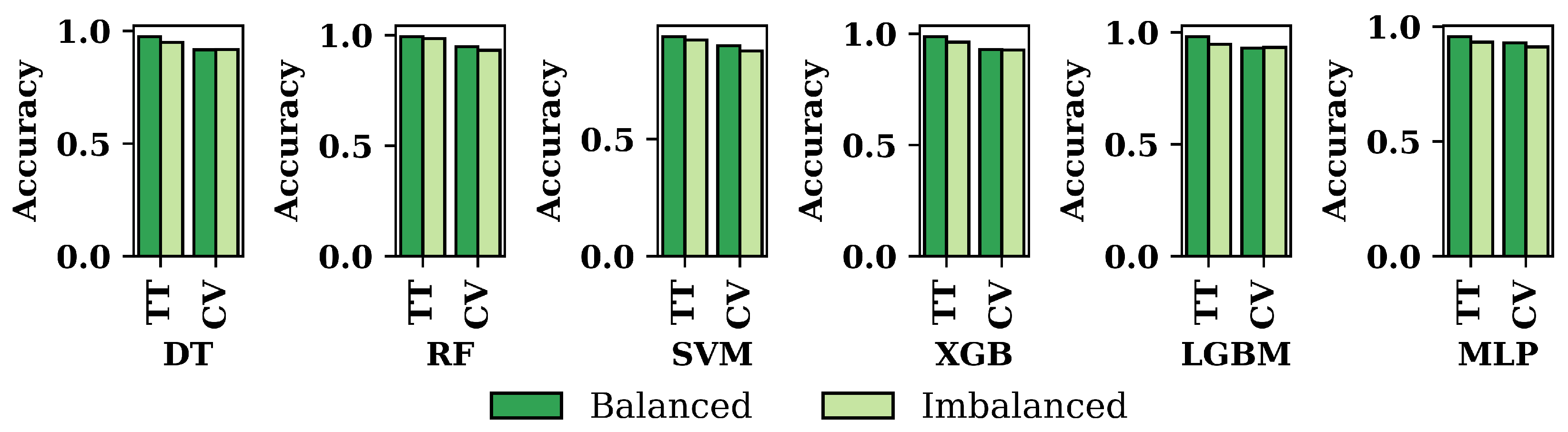
Figure 6 compares the accuracy of the six ML approaches for both datasets. It has been shown that the balanced dataset’s accuracy is always higher than the imbalanced dataset for all the classifiers that have been used in this research. Among the six ML algorithms, RF shows the highest accuracy for both the dataset and the techniques of train–test split and cross-validation.
3.4. Risk Factor Analysis and Model Explanation Based on SHAP Value
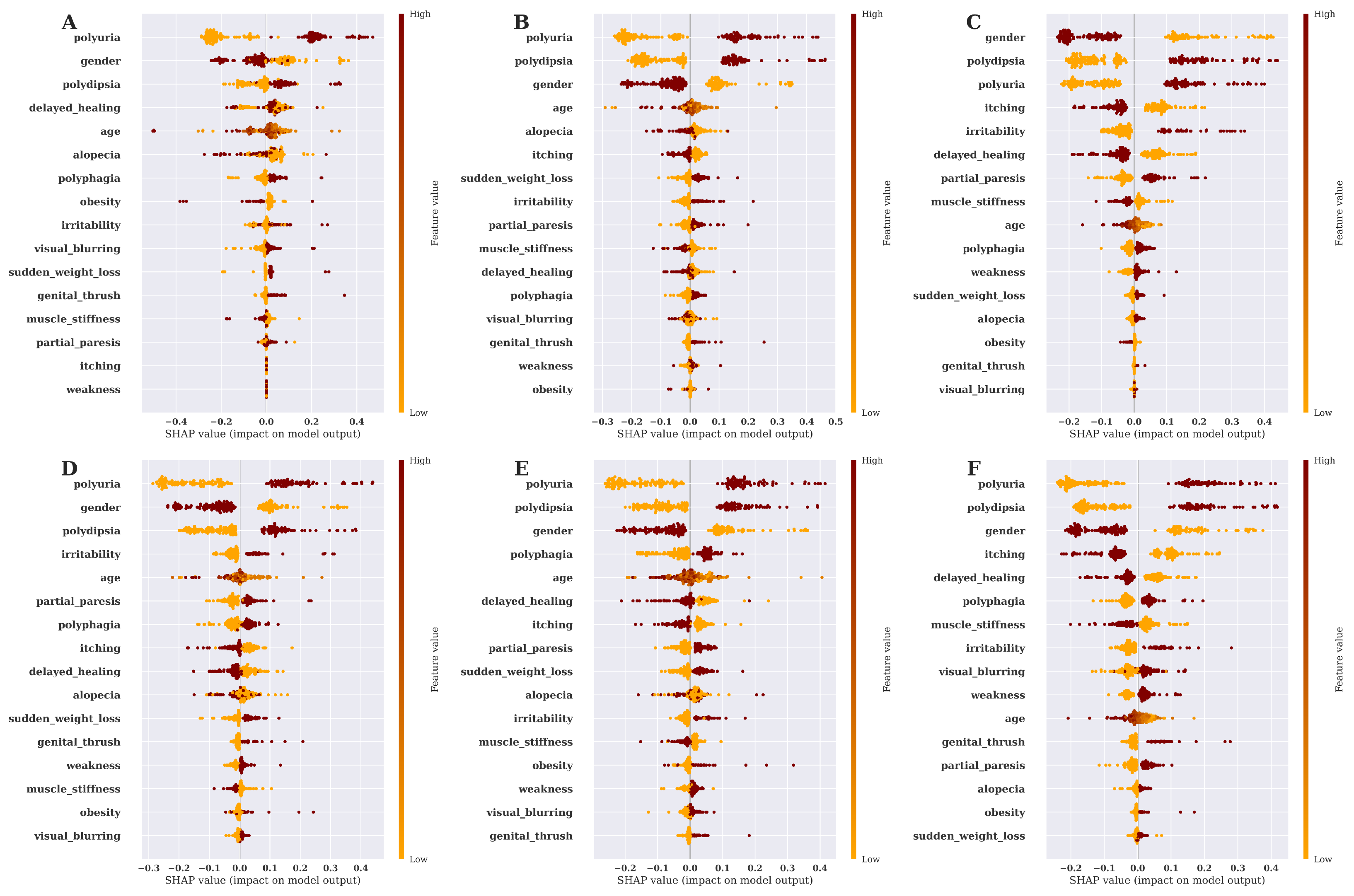
This study also aims to find the features’ impact on predicting diabetes for different ML techniques. We have utilized the SHAP summary plot to carry out and show the feature’s impact on the models. Using SHAP value, summary plot is depicted to show how the features affect the forecast.It takes into account the absolute SHAP value; hence, it matters if the feature affects the prediction either positively or negatively [
35]. The features’ impact on model prediction utilizing the SHAP Summery plot for six ML algorithms is shown in
Figure 7.
3.5. Discussion
Researchers have conducted a significant amount of research on diabetes prediction, but there is still room for improvement in diabetes prediction research. For predicting diabetes in this work, we employ a socio-demographic diabetes dataset. After collecting the dataset, we pre-processed it to make it suitable for further analysis. We applied six supervised ML algorithms, namely DT, RF, SVM, XGBOOST, LGBM, and MLP to predict diabetes. After applying the ML approaches, we assessed the results of the applied ML approaches utilizing different performance metrics like accuracy, precision, recall, f1-measure, sensitivity, specificity, kappa statistics, and MCC. Among the applied ML algorithms, RF shows the highest result with a 99.37% accuracy; 1.00 precision; 0.9902 recall; 0.9951 f1-score; 1.00 sensitivity; 0.9902 specificity; as well as kappa statistics and MCC of 0.9859 and 0.9860, respectively, for the train–test split technique, which effectively predicts diabetes. The same socio-demographic diabetes dataset that we analyzed for diabetes prediction was also analyzed by Islam, M. M. et al. (2020) and has been shown to have the highest result of 99.00% accuracy for the RF approaches [
6]. And Ahmed, Usama et al. (2022) also used the same dataset and obtained a 94.87% accuracy; 0.9552 sensitivity; 0.9438 specificity; and 0.9412 f1-score [
11]. The impact of features on the model plays an essential role in the ML field for any disease prediction. Therefore, in this work, we also show the features’ impact on model prediction of the six ML algorithms by utilizing the SHAP summary plot, which is graphically expressed in
Figure 7.
According to
Table 6, it has been found that our proposed model is highly capable of predicting diabetes using only socio-demographic features. In addition to that, the proposed model is validated by more evaluation metrics than the existing models. The proposed model has some practical application in different fields such as early diabetes risk assessment, customized diabetes prevention plans, community health initiatives, telehealth and remote monitoring, and others. In addition to that, this study will contribute to develop personalized diabetes management apps and personalized medicine. In brief, this study demonstrates many potential real-life applications in the health sector.
However, this study has some limitations. First of all, the number of instances in this dataset is only 520, which is enough to build an ML-based prediction model but not good enough. As a result, we should collect more data in the future. The attributes of the diabetes dataset are only socio-demographic, but the socio-demographic data on diabetes are not sufficient to accurately predict diabetes. For that reason, we should collect clinical data in the future and merge them together to build an effective diabetes prediction model. Also, in the future, this study should be focused on utilizing more effective ML approaches to build an effective prediction model and develop an end-user website for diabetes prediction. Alongside its weakness, some of the strengths of this study include proposing a low-cost and efficient machine learning model with high accuracy. The model has shown a significant outcome in terms of predicting diabetes in early stages.


 ,
, 









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}