1. Introduction
In the modeling and optimization of real-world problems, there is usually a level of uncertainty associated with the input parameters and their future outcomes. Stochastic programming (SP) models have been widely studied to solve optimization problems under uncertainty over the past decades [
1,
2]. SP is acknowledged for providing superior results compared to the corresponding deterministic model with nominal values for the uncertain parameters, which can lead to suboptimal or infeasible solutions. SP applications in process systems engineering include manufacturing networks and supply chain optimization [
3,
4], production scheduling [
5], synthesis of process networks [
6].
Two-stage stochastic programming is a commonly applied framework for cases where parameter uncertainties are decision independent (exogenous uncertainties). In stochastic programming, uncertain parameters are explicitly represented by a set of scenarios. Each scenario corresponds to one possible realization of the uncertain parameters, according to a discretized probability distribution. The goal is to optimize the expected value of the objective function over the full set of scenarios, subject to the implementation of common decisions at the beginning of the planning horizon.
Stochastic programs are often difficult to solve due to their large size and complexity that grows with the number of scenarios. To overcome these difficulties, decomposition algorithms, such as Benders decomposition [
7], Lagrangian decomposition [
8], and progressive hedging [
9], have been developed to solve linear programming (LP) and mixed-integer linear programming (MILP) stochastic problems. For a comprehensive review of recent algorithmic advances in two-stage stochastic MIP, we refer the readers to the tutorial [
10].
On the software development front, several modeling systems and optimization platforms have included extensions for a convenient algebraic representation of stochastic problems, as offered by major software vendors, such as GAMS, LINDO, XpressMP, AIMMS, and Maximal.
In recent years, various commercial and open-source applications have been developed specifically to represent and solve two-stage and multistage SP problems. Some of them include capabilities to read and build stochastic MPS (SMPS) files, the standard exchange format for SP applications. However, despite advances in the field and proven benefits, SP has not been widely used in industrial applications. Existing applications include power systems planning and scheduling [
11,
12,
13], and process systems engineering [
14,
15].
The scope of this paper is to provide a tutorial for beginners on linear and mixed-integer linear stochastic programming, introducing the fundamentals on solution methodologies with a focus on available software. To accomplish this objective, we present a general description of techniques based on Benders decomposition and dual decomposition, which are the fundamentals of most known solvers designed specifically to tackle special problem structures. We then review the currently available state-of-the-art software for the solution of two-stage stochastic programming problems and evaluate their performance, using large-scale test libraries in SMPS format.
The remainder of this paper is organized as follows. In
Section 2, we explain the mathematical formulation of (mixed-integer) linear stochastic problems.
Section 3 describes the classical L-shaped algorithm.
Section 4 summarizes the enhancement strategies to improve the performance of Benders decomposition.
Section 5 describes scenario decomposition methods and algorithmic enhancements. In
Section 6, we describe algorithmic innovations in software packages for dual decomposition and show some computational results. Finally, in
Section 7, we summarize the conclusions.
2. Problem Statement
We consider a two-stage stochastic mixed-integer linear problem (
P) in the following form:
where
x denotes the ‘here and now’ decisions, taken at the beginning of the planning horizon before the uncertainties unfold, and
is the set of scenarios. Vector
represents the recourse or corrective actions (wait and see), applied after the realization of the uncertainty. Matrix
and vector
represent the first-stage constraints. Matrices
and
, and vector
represent the second-stage problem. Matrices
and
are called technological and recourse matrices, respectively. Let
be the index set of all first-stage variables. Set
as the subset of indices for binary first-stage variables. Let
be the index set of all second-stage variables. If the second-stage variables are mixed integer,
, where set
is the subset of indices for binary second-stage variables. If all the second-stage variables are continuous, set
and
. The objective function (
) minimizes the total expected cost with the scenario probability
, and the cost vectors
c and
. It should be noted that the approaches discussed in this paper can be applied to mixed-integer variables. Here, we restrict the variables to be mixed binary for simplicity. Equation (1) is often referred to as the deterministic equivalent, or extensive form of the SP.
Formulation (
P) can be rewritten in an equivalent form (
PNAC) with nonanticipativity constraints (
NACs), where the first-stage variables are no longer shared, and each scenario represents an instance of a deterministic problem with a specific realization outcome [
16,
17].
In Equation (
2c),
represents the feasible region for scenario
, which is defined by constraints (
1b)–(
1e). Nonanticipativity constraints (
2b) are added to ensure that the first-stage decisions are the same across all scenarios. Nonanticipativity constraints are represented by a suitable sequence of matrices
. One example of such constraints is the following:
Given the mathematical structure of the deterministic equivalent formulations (
P) and (
PNAC), (mixed-integer) linear stochastic problems can be solved using decomposition methods derived from duality theory [
18]. Such methods split the deterministic equivalent into a master problem and a series of smaller subproblems to decentralize the overall computational burden. Decomposition methodologies are classified in two groups: (i) node-based or
vertical decomposition, which includes Benders decomposition and variants where the problem is decomposed by the nodes in the scenario tree, and (ii) scenario-based or
horizontal decomposition, where the problem is decomposed by scenarios. In the following
Section 3, we provide a tutorial overview of Benders decomposition. In
Section 4, we also provide a tutorial review of scenario decomposition methods, including the dual decomposition algorithm and the progressive hedging algorithm.
3. L-Shaped Algorithm/Benders Decomposition
If the second-stage variables are all continuous (i.e.,
), problem (
P) can be solved with Benders decomposition. Benders decomposition (
BD) was originally developed in 1962 by Benders [
19] to solve large-scale mixed-integer linear problems (MILP) with complicating variables. This concept has been extended to solve a broader range of optimization problems [
20], including multistage, bilevel, and nonlinear programming. When applied to stochastic problems, it is commonly referred to as the L-shaped algorithm [
7].
The L-shaped algorithm partitions the deterministic formulation (
P) into multiple problems: (i) a master problem (
MP) that contains all the first-stage constraints and variables, which can be mixed integer; and (ii) a collection of subproblems that include corrective future actions for the given first-stage solution. The master problem (
MP) is derived from the projection of (
P) on the variables
x:
where
is defined as the recourse function (or expected second-stage value function); and
is defined by the primal second-stage program for scenario
,
,
The recourse functions
and
are convex, differentiable, and piece-wise linear, characteristics that are exploited in the BD method [
1]. These conditions do not hold when integer variables are included in the second-stage program. For the case of integer recourse, a logic-based Benders framework [
21], second-stage convexification techniques [
22,
23,
24], specialized branch-and-bound schemes [
25,
26] or dual decomposition methods [
16] may be applied to solve large stochastic problems. In this section, we only focus on Benders decomposition for SP with continuous second-stage variables.
Formulation (
) is a linear program for any given feasible value of
x. By the strong duality theorem, the second-stage program is equivalent to its dual (
) if (
) is feasible and bounded. Vector
represents the Lagrangian multipliers associated with the second-stage constraints given by Equation (
5b):
BD introduces a set of piece-wise linear approximations of the recourse function in the problem MP, known as optimality cuts, which are built from dual solutions of the second-stage program. It is important to highlight that the dual feasible region does not depend on the value of x. Thus, the exact representation of the expected cost consists of the computation of all the extreme points of problems ().
However, the second-stage program may not be feasible for some values of
x. BD enforces second-stage constraints (
5b) by adding feasibility cuts, which are valid inequalities that exclude infeasible first-stage solutions from the MP. Subproblem feasibility is evaluated by solving the following recourse reformulation for scenario
:
where
is a vector with all-1 entries, and
is the slack of constraints (
5b). The objective function
measures the amount by which these constraints are violated; thus, if
equals zero, it implies that the original subproblem (5) is feasible. To derive feasibility cuts in terms of
x, BD considers the dual of problem (7) to generate an expression equivalent to Equation (
7a). The optimal solution
of the dual feasibility problem (8) corresponds to one of the extreme rays (or directions) of the recourse subproblem (6):
The master problem (4) is linearized by (i) substituting function
with the weighted sum of the future cost estimation (
6a), and (ii) applying feasibility cuts as needed. This reformulation is referred to as the multi-cut Benders master problem (BMP),
where variables
represent the outer linearization of the second-stage cost
. Parameters
and
represent the extreme points and rays from the dual form of the recourse program (
), which are stored in sets
E and
K, respectively. Constraints (
9c) and (
9d) denote the feasibility and optimality cuts,
and
respectively. Matrices
and
correspond to the matrices
and
for the scenario where a feasibility cut can be found.
The complete enumeration of the extreme points and rays of the dual second-stage program is impractical, if not impossible. Instead, the L-shaped algorithm relaxes the MP by initially considering a subset of the optimality and feasibility cuts. BD iteratively solves the relaxed problem to generate a candidate solution for the first-stage variables (
), and then solves the collection of scenarios subproblems at fixed
to generate a new group of optimality or feasibility cuts. This process is repeated until the optimal solution is found [
26].
The optimal solution of the relaxed Benders master problem provides a valid lower estimation (
) of the optimal total cost, TC. On the other hand, the solution of the second-stage programs (
) at feasible
yields an upper bound of the original objective function (
), given by Equation (
10). The solution procedure terminates when the difference between the bounds is closed, as implied by Equation (
11). Algorithm 1 summarizes the procedure.
| Algorithm 1: Multi-cut Benders decomposition |
![Algorithms 15 00103 i001]() |
The L-shaped method is summarized in Algorithm 1. It is initialized with a guess of the first-stage solution and considers two stopping criteria: (i) the optimality tolerance that limits the relative gap between the dual and primal bounds of the objective function , and (ii) the maximum number of allowed iterations .
6. Software Packages for Scenario Decomposition
In this section, we review two software packages, PySP [
52,
60] and DSP [
49], for scenario decomposition. The two software packages are benchmarked based on the problems in SIPLIB [
61], including the SSLP [
62], SSLPR [
63], and DCAP [
64] test problems.
The SSLP test set consists of 12 two-stage stochastic mixed-integer programs arising in stochastic server location problems (SSLPs). The base deterministic server location problem considers building servers in some potential locations to serve clients in given locations. The stochastic version of the server location problem considers different realizations of client locations. Each scenario represents a set of potential clients that do materialize. The decisions in SSLP are all binary variables. In the first stage, we decide whether a server is located at each given location. The second-stage (recourse) actions decide whether any given client is served by any given server. SSLPR (stochastic server location problem with random recourse) is an extension of SSLP. While SSLP assumes fixed demands for the clients, SSLPR considers the demands of the clients as uncertain parameters.
DCAP consists of 12 two-stage stochastic integer programs arising in dynamic capacity acquisition and allocation applications. The deterministic model considers a capacity expansion schedule over
T time periods. In each time period, the amount of capacity expansion for each resource needs to be decided. There is a fixed and a variable cost for each capacity expansion. In each time period, each task must be assigned to one of the existing resources, which is represented by binary variables that decide whether a given task is assigned to a given resource. Since there are multiple periods, the stochastic version of this problem should, in principle, be formulated as a multi-stage stochastic program, which is difficult to solve. Ahmed and Garcia [
64] proposed to approximate the multi-stage problem with a two-stage stochastic program in which the first-stage decisions are the capacity expansions. The second-stage decisions are the assignment decisions. The uncertainties include the processing requirement for each task and the cost of processing each task.
The sizes of all the test problems are shown in
Table 1. The names of the SSLP and SSLPR instances are expressed in the form sslp(rf)_m_n, where m is the number of potential server locations, and n is the number of potential clients. Each instance is tested with a different number of scenarios. The size is expressed as the number of constraints (Rows), variables (Cols), and integer variables (Ints) in the first stage and the second stage per scenario. Note that the SSLP problems have pure binary first-stage variables, and the DCAP problems have mixed-binary first-stage variables. This difference affects the PH algorithm, which is discussed in detail later.
All of the test problems are available in the SMPS format; however, we implement an interpreter to make the format compatible with PySP. All of the tests are run on a server with an Intel Xeon CPU (24 cores) at 2.67 GHz and 128 GB of RAM. The whole set of instances is solved in a synchronous parallel manner to reduce the time of each iteration.
6.1. PySP: Pyomo Stochastic Programming
PySP is a software package implemented in the Python programming language using Pyomo [
65] as the optimization modeling framework. PySP enables the user to solve stochastic programs with a specialized progressive hedging algorithm for stochastic mixed-integer programs. In order to use PySP, the user only needs to write a deterministic base model and define the scenario tree structure in Pyomo. With these inputs, PySP is able to apply the progressive hedging algorithm as an effective heuristic for obtaining feasible solutions to multi-stage stochastic programs. We highlight that starting from distribution 6.0, PySP will not be part of Pyomo’s source code; however, it will still be available and maintained. Furthermore, the PySP project will be continued as
mpi-sppy, available in
https://github.com/Pyomo/mpi-sppy, accessed on 20 January 2022.
6.1.1. Algorithmic Innovations in PySP
The innovations in PySP for multi-stage mixed-integer stochastic programs were described by Watson and Woodruff [
52]. Here, we briefly paraphrase those innovations. First, instead of keeping a fixed
value for all first-stage decisions in Algorithm 4, the authors proposed several variable-dependent
strategies. The cost-proportional (CP) strategy sets
to be proportional to the cost parameter
, i.e.,
, where
is a constant multiplier for all first-stage variables
i. The other variable-dependent
strategy was denoted by SEP in [
52], where the
for integer variables is calculated by
After PH iteration 0, for each variable
x,
and
. For continuous variables, the
is calculated with
where
is the weighted average of
, i.e.,
.
The authors also proposed some heuristics for accelerating convergence. One heuristic is called “variable fixing”. The values of some of the first-stage decisions are fixed after they stay at a given value for a few iterations for all scenarios. In order to apply this heuristic, the authors introduced a lag parameter . At a given PH iteration k, the value of is fixed to for all subsequent iterations , if for all and , such that . Additionally, the authors proposed another more aggressive variable fixing heuristic called “variable slamming”, where the is fixed if they are “sufficiently converged”, i.e., there can be some discrepancies for across all scenarios. In order to decide when variable slamming should be applied, the authors proposed several termination criteria based on the deviations of the first-stage variables.
In solving stochastic mixed-integer programs with PH, the cyclic behavior can be found in some instances. In order to detect the cyclic behavior, the authors proposed a strategy based on the values of the vectors, i.e., the weights associated with the first-stage decision variable . The authors proposed a simple hashing scheme. Let hash value , where is an integer hash weight for each scenario when the PH is initialized. If equal hash weights are detected, they are interpreted as evidence for a potential cycle. Variable can be fixed if cyclic behaviors are found.
The heuristics, including variable fixing and slamming and cyclic behavior detection, are denoted as WW (Watson–Woodruff) heuristics in the software distribution of PySP.
6.1.2. Computational Results for PySP
We use PySP (Pyomo 5.0.0) to solve the SSLP, SSLPR, and DCAP problems. Each subproblem is solved with the CPLEX (12.7.0) quadratic solver. We use the cost-proportional (CP) heuristic to set the values of . The multipliers in the CP heuristic are set to 0.1, 0.3, 0.5, and 1.0, respectively. Note that the main results shown in this section are not using WW heuristics, i.e., we do not use the variable fixing and slamming, or cycle-detection heuristics. We will make a comparison of PySP with WW heuristics and PySP without WW heuristics at the end of this section.
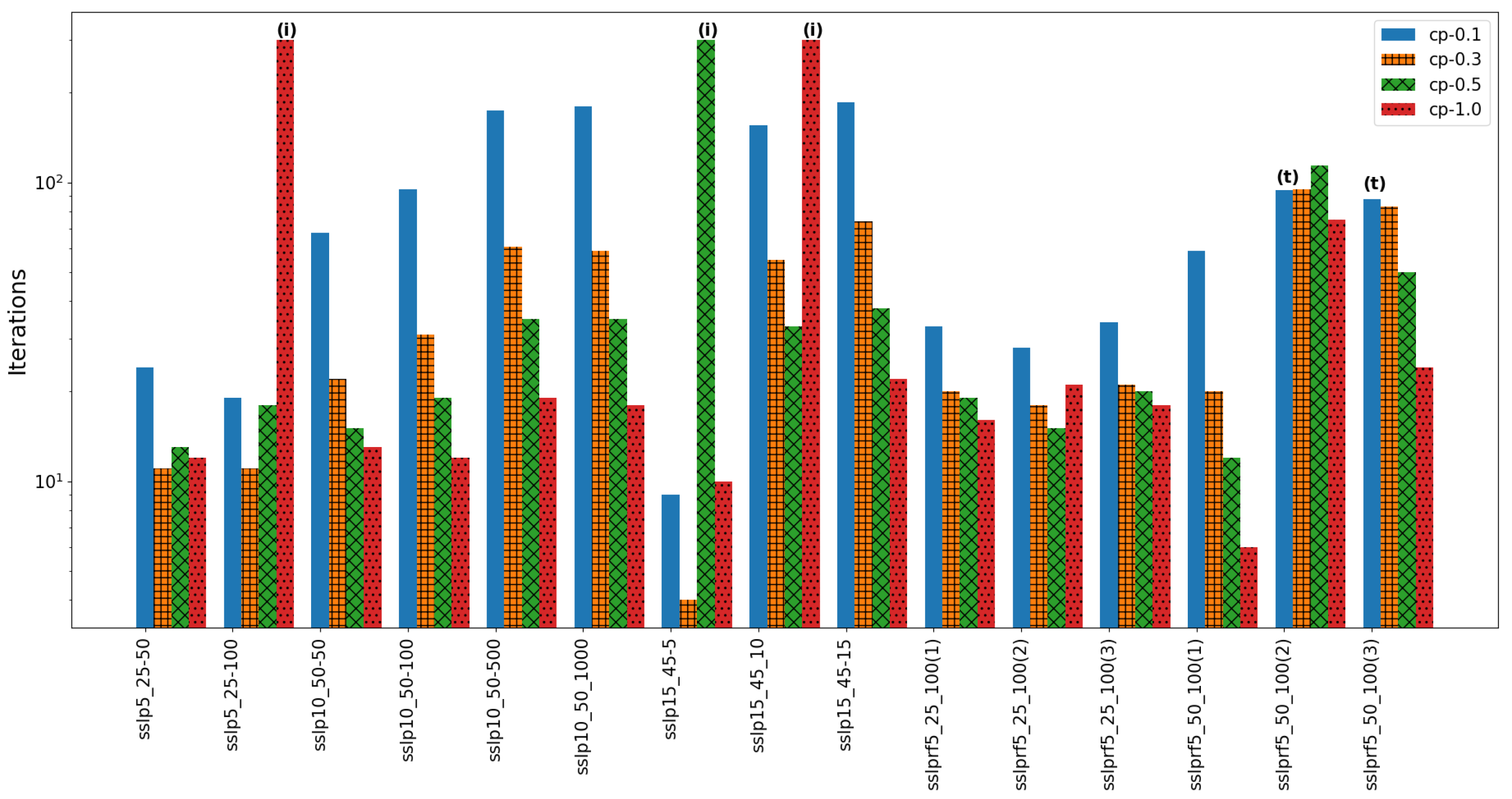
The number of iterations and the walltime for different multipliers are shown in
Figure 1 and
Figure 2, respectively. If the PH algorithm reaches iteration limit, there is an “(
i)” label at the top of the column. If the PH algorithm reaches the time limit, there is a “(
t)” label on top of the column. From
Figure 1 and
Figure 2, one can observe that setting the
value to 0.1 makes PH take the largest number of iterations and largest amount of walltime to converge in most of the instances, which may be due to the small step size. On the other hand, setting
to the largest value, i.e., 1.0, takes fewer iterations and less walltime than using other
values in most instances. However, it runs out of the iteration limit in two of the instances. Overall, setting
to 0.3 seems to be a robust choice because cp-0.3 always converges within a reasonable walltime and number of iterations. The details of the SSLP and SSLPR results are shown in
Table A1 and
Table A2 in
Appendix A.
We also apply PySP to solve DCAP instances. We observe that for all the DCAP instances, PySP is unable to converge within 300 iterations. The details of the results are shown in
Table A3 in
Appendix A where the walltime of the upper bound for those instances is reported.We compare the upper bound obtained by PySP with those obtained by DSP in the next subsection. From this experiment, we can see that it is more difficult for PySP to solve problems with mixed-binary first-stage variables than problems with pure binary first-stage variables because it is more difficult for the continuous variables to satisfy the NACs.
Scenario bundling [
66,
67,
68] is a technique that has been used in dual decomposition algorithms. The main idea is to dualize only “some” of the non-anticipativity constraints, rather than dualizing all of them. In other words, the individual scenario subproblems are bundled into larger subproblems in which the NACs are preserved. Ryan et al. [
67] used PH with scenario bundling to solve stochastic unit commitment problems. The authors showed that with the use of scenario bundling, PH can obtain solutions with a smaller optimality gap. In order to test the effectiveness of the scenario bundling, we test several instances from the SSLP and DCAP libraries. The computational results are shown in
Table 2. For each instance, we try a different number of bundles. For the SSLP instances, PH with a different number of bundles can obtain the same upper bound. However, the number of bundles has a significant impact on the computational time. For example, for SSLP_10_50 with 1000 scenarios, PH with 50 bundles can reduce the walltime of the original PH with 1000 bundles to 3%. Additionally, it only takes PH with 50 bundles one iteration to converge. For DCAP problems, PH does not converge within 300 iterations for most cases, even with scenario bundling. However, PH is able to obtain better feasible solutions with scenario bundling (see UB in
Table 2).
Finally, we evaluate how the use of WW heuristics can affect the performance of PySP on the SSLP and SSLPR libraries. The results on DCAP library are omitted here since PySP does not converge for DCAP instances. The solution time improvements by using WW heuristics for each SSLP and SSLPR instance are shown in
Figure 3. Note that there are three cases where the improvements are omitted in the figure: case (1)—neither PH nor PH with WW heuristics can converge in 300 iterations; case (2)—only PH-WW fails to converge in 300 iterations; and case (3)—both PH and PH-WW exceed the time limit of 3 h (10,800 CPU seconds). Using WW heuristics gives significant improvements for small cost-proportional multipliers, i.e., 0.1 and 0.3. As we have described in
Table 1, PH with small multipliers usually takes more iterations to converge. Therefore, the WW heuristics can accelerate convergence for those instances, more effectively. However, there are also a few instances where PH can converge, but PH with WW heuristics cannot converge, which are denoted by case (2) in
Figure 3.
6.2. DSP: Decompositions for Structured Programming
DSP [
49] is an open-source software package implemented in C++ that provides different types of dual decomposition algorithms to solve stochastic mixed-integer programs (SMIPs). DSP can take SMPS files, and JuMP models as input via a Julia package Dsp.jl.
6.2.1. Algorithmic Innovations in DSP
From the description of the dual decomposition algorithm in
Section 5, one can observe that the lower bounds of the dual decomposition algorithm are affected by the way the Lagrangian multipliers are updated. One advantage of DSP is that the authors have implemented different dual-search methods including the subgradient method, the cutting plane method, and a novel interior-point cutting-plane method for the Lagrangian master problem. The authors observed that if the simplex algorithm is used, the solutions to the Lagrangian master problem can oscillate significantly, especially when the Lagrangian dual function is not well approximated. Therefore, the authors proposed to solve the Lagrangian master problem suboptimally using an interior point method, which follows from the work of Mitchell [
69].
The authors also proposed some tightening inequalities that are valid for the Lagrangian subproblems. These valid inequalities, including feasibility and optimality cuts, are obtained from Benders subproblems, where the integrality constraints are relaxed. Computational results show that the Benders-like cuts can be effective in practice. The latest DSP distribution is able to complete Algorithm 3 using the Dantzig–Wolfe decomposition-based branching strategy described in [
51].
6.2.2. Computational Results for DSP in Comparison with PySP
We test the dual decomposition algorithm on the SSLP, SSLPR, and DCAP libraries. Each subproblem is solved with CPLEX (12.7.0) mixed-integer linear solver. The interior point method proposed by the authors [
49] is used to solve the Lagrangian master problem, which is solved with CPLEX as well. Benders-like cuts are not used because the implementation of Benders cuts in DSP only works with SCIP.
In
Figure 4 and
Figure 5, we evaluate the best feasible solution (the upper bound) obtained by PySP, and the upper and lower bounds obtained by DSP. For each instance, we include three different gaps. The upper and lower bounds from Ref. [
61] are used to evaluate the bounds from PySP and DSP. Note that the bounds from literature are close to the global optimality of each instance. The first column for each instance in both
Figure 4 and
Figure 5 is the gap between the upper bound from PySP (
) and the lower bound from the literature (
). The second column represents the gap between the upper bound from DSP (
) and the lower bound from the literature (
). The third column represents the gap between the upper bound from literature (
) and the lower bound from DSP (
).
For the SSLP and SSLPR instances shown in
Figure 4, although PySP can converge within the time and iteration limit, the best feasible solution obtained from PySP (
) may not be optimal. There are about 1% gaps for some of the SSLP instances (see the first column of each instance in
Figure 4). DSP can solve more instances to optimality than PySP (see the second column of each instance in
Figure 4). The lower bounds obtained by DSP are also quite tight, usually less than 0.01% (see the third column of each instance in
Figure 4). Note that the literature values for SSLPRF5_50_100(1), SSLPRF5_50_100(2), and SSLPRF5_50_100(3) do not match the values from our experiment. Therefore, we try to solve the deterministic equivalent of these instances to obtain bounds. The literature bounds of SSLPRF5_50_100(3) come from solving the deterministic equivalent. The gaps of SSLPRF5_50_100(1) and SSLPRF5_50_100(2) are omitted since the corresponding deterministic equivalent cannot be solved within 3 h.
For the DCAP instances where we have mixed-integer first-stage variables, the best feasible solutions from PySP () and DSP () are quite far from optimality. The gaps of the first two columns are around 10%. On the other hand, the lower bounds obtained from DSP () are tight. The gaps between () and () are around 0.1%. Therefore, in order to improve the relative optimality gap of DSP, the focus should be on designing more advanced heuristics to obtain better feasible solutions.
6.3. Results from Branch-and-Bound Algorithm in DSP
As we were completing this paper, a new version of DSP [
51] was developed that uses the branch-and-bound algorithm similar to Algorithm 3. We test the branch-and-bound decomposition on the SLSP, SSLPR, and DCAP test instances. The computational setting is the same as the one described in the previous section.
Table 3,
Table 4 and
Table 5 show the results obtained by DSP. We highlight that almost all the instances were solved to optimality within the walltime limit.
In all the SSLP instances (except SSLP15_45), DSP using the DW-based branch-and-bound (DSP-DW) is able to solve the instances to optimality in times lower than the ones from the DSP implementing only the first iteration of DD. The same trend is replicated on the SSLPRF instances.
On the other hand DSP-DW is remarkably slower in attaining algorithmic convergence in the DCAP test set. This behavior can be explained by looking at the
vs.
gap in
Figure 4 and
Figure 5. The standard implementation of DSP is able to close the optimality gap in the SSLP and SSLPR instances by solving the Lagrangian relaxation problem (
15a) and using heuristics to compute a primal bound. Nonetheless, this strategy does not work in the DCAP set for which additional computation is devoted by DSP-DW to close the gap via branch-and-bound.
7. Conclusions
We presented a summary of the state-of-the-art methodologies for the solution of two-stage linear stochastic problems. First, we introduced the mathematical formulation of such programs and highlighted features in their structure, which enable the development of decomposition algorithms. These methodologies are classified in two groups: node-based decomposition and scenario-based decomposition.
For two-stage stochastic programs with continuous recourse, we summarized Benders decomposition, which partitions the problem according to its time structure. BD may present computational problems, which can be alleviated by reducing the cost of each iteration, and/or decreasing the number of iterations.
Scenario decomposition methodologies are popular alternatives in the case of (mixed) integer recourse. The progressive hedging algorithm and dual decomposition relax the nonanticipatity restrictions and provide the user with valid bounds. Our numerical results show that the performance of PH is strongly affected by the constant penalty multiplier. Furthermore, its performance and the quality of the approximate solution may be enhanced by grouping the scenarios in large bundles (or scenario sets). We also tested the dual decomposition algorithm with the DSP package. The computational results show that DSP is able to provide a tight lower bound on the instances that we tested. However, the optimality gaps can be as large as 10%, relative to the upper bound from literature. Therefore, for those tested instances, future effort should be focused on developing more advanced heuristics to improve the best feasible solution. Moreover, we tested the newest DSP implementation, which incorporates a Dantzig–Wolfe decomposition-based branch-and-bound algorithm to close the optimality gap. In most of the instances, it is able to retrieve a global solution in the given walltime limit. We highlight that its computational performance depends on the strength of the dual decomposition.
At the time we completed this paper, several new developments were made in stochastic programming software. These software packages have the capability of solving multi-stage stochastic programs, e.g.,
SDDP.jl [
70],
StochasticPrograms.jl [
71], and
MSPPy [
72]. In the terms of algorithmic development, recent works have extended the capability to solve nonlinear problems [
4,
73,
74,
75,
76,
77,
78]. Furthermore, it should be noted that the paper focuses on the risk-neutral setting of two-stage stochastic programs. However, the studied approaches can be easily extended to the risk-averse setting [
79], e.g., by including some risk measures, such as the conditional value at risk (CVar).







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}







