5.5. Correlation Discovery: Dynamic Time Warping
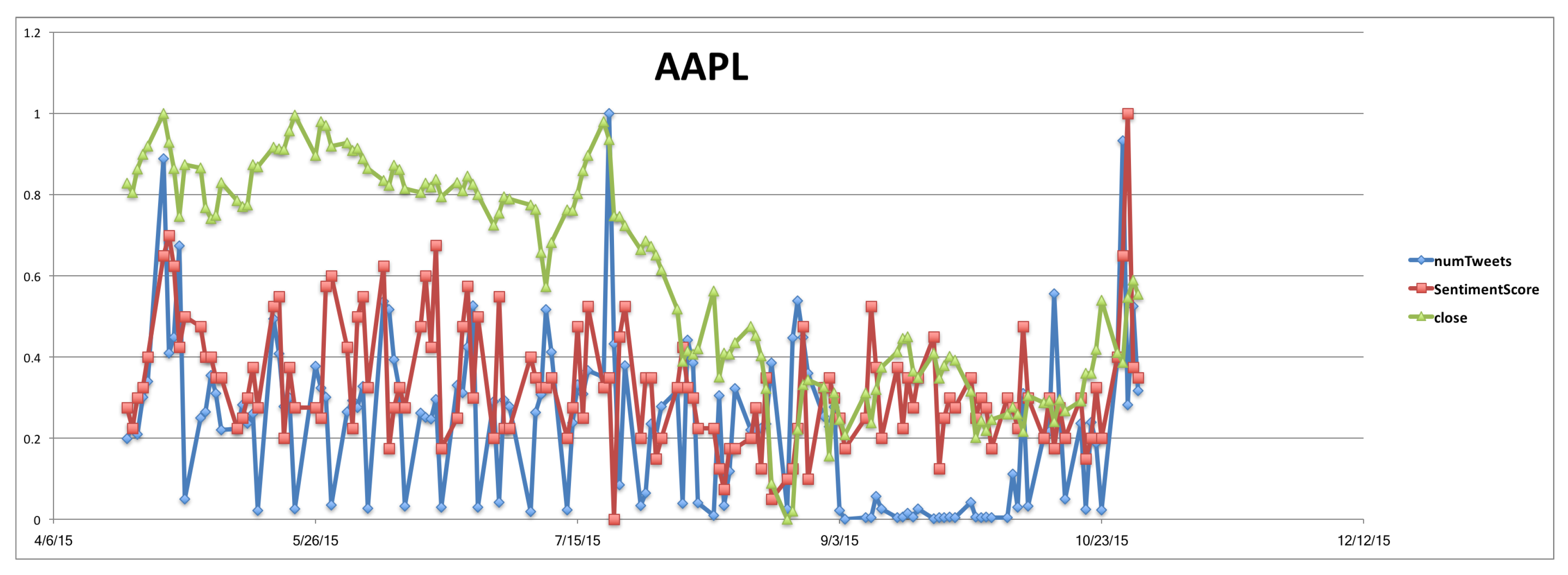
A first attempt was to find out whether there was a correlation at common intervals, overlaps, between the intervals of the time series close, sentimentScore and close, numTweets, in which patterns were found. However, this approach did not work satisfactorily.
The next step was to discover if a correlation existed between the time series:
close and sentimentScore
close and numTweets,
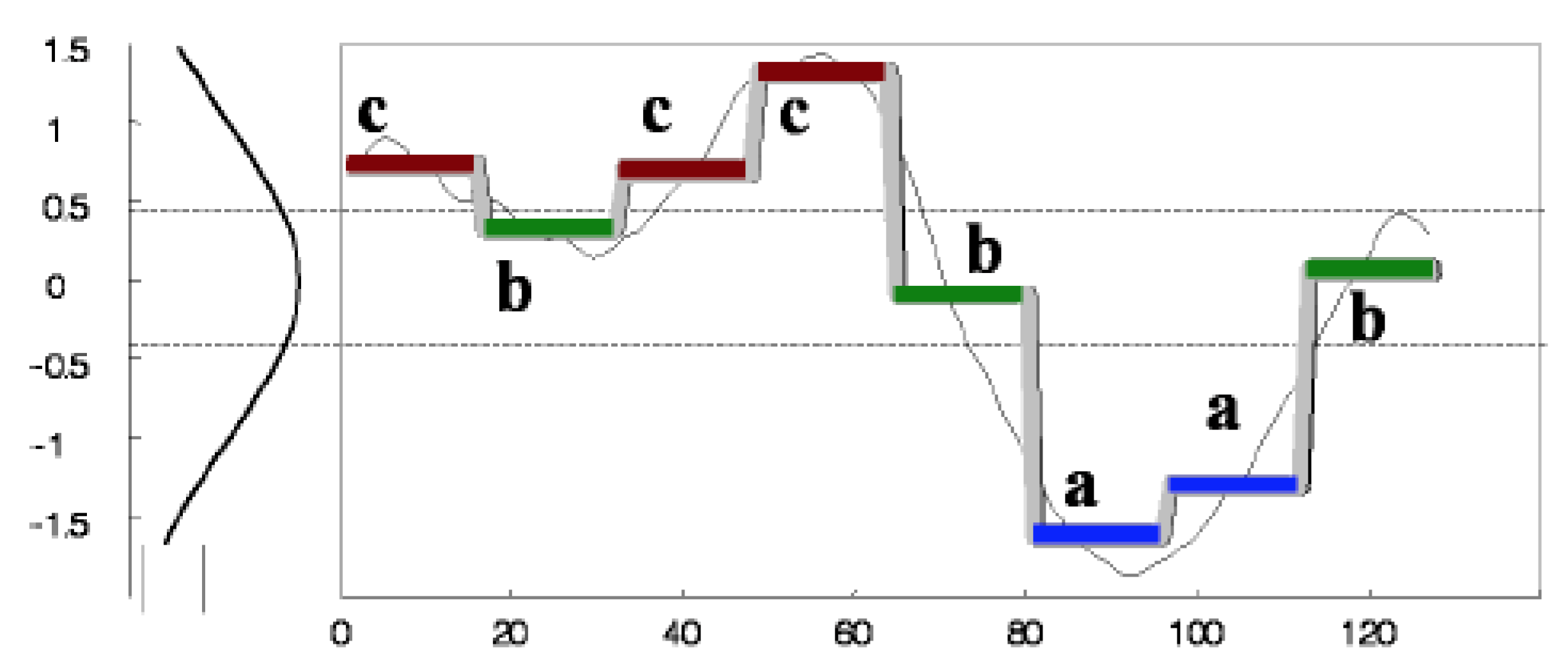
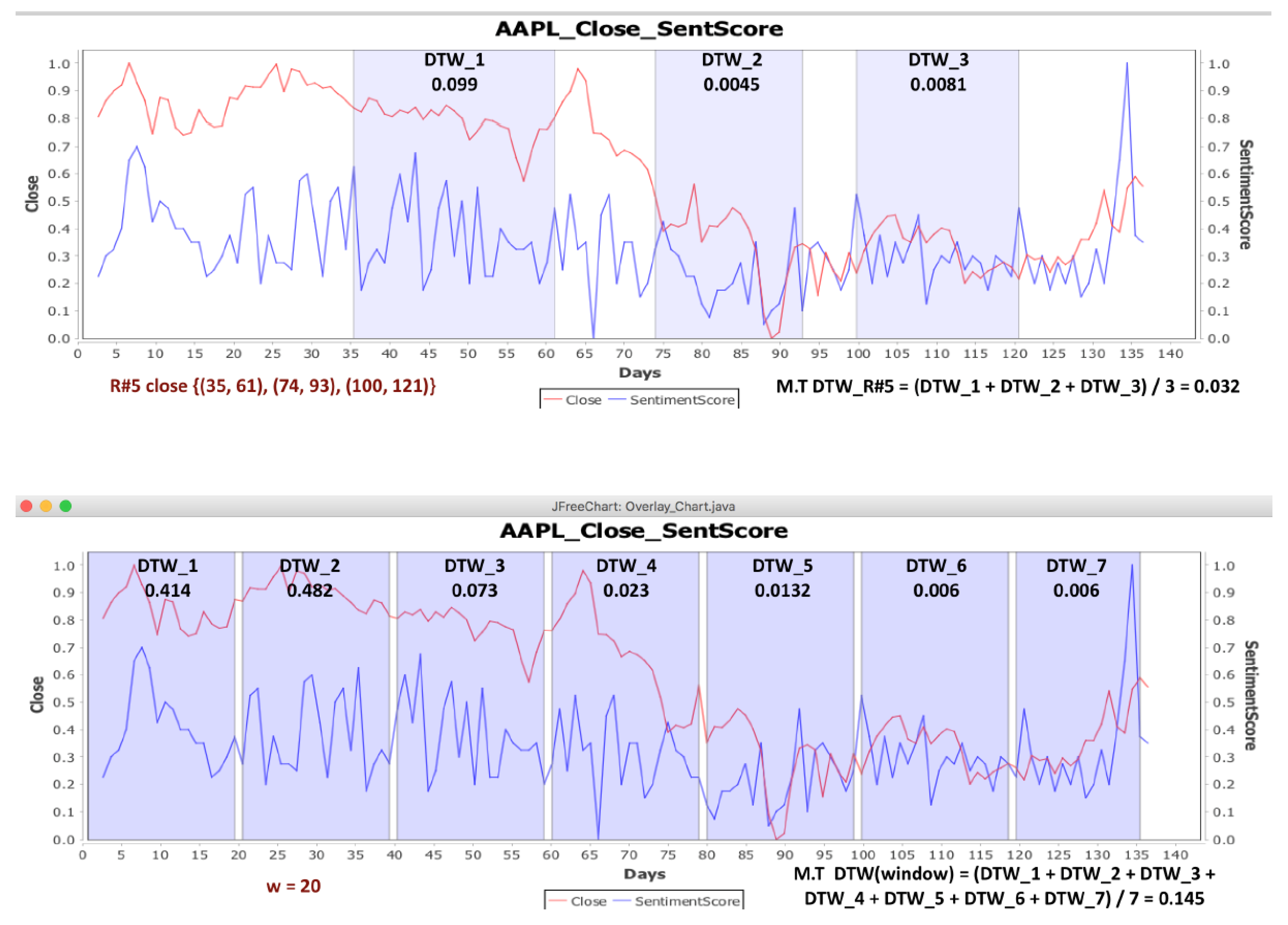
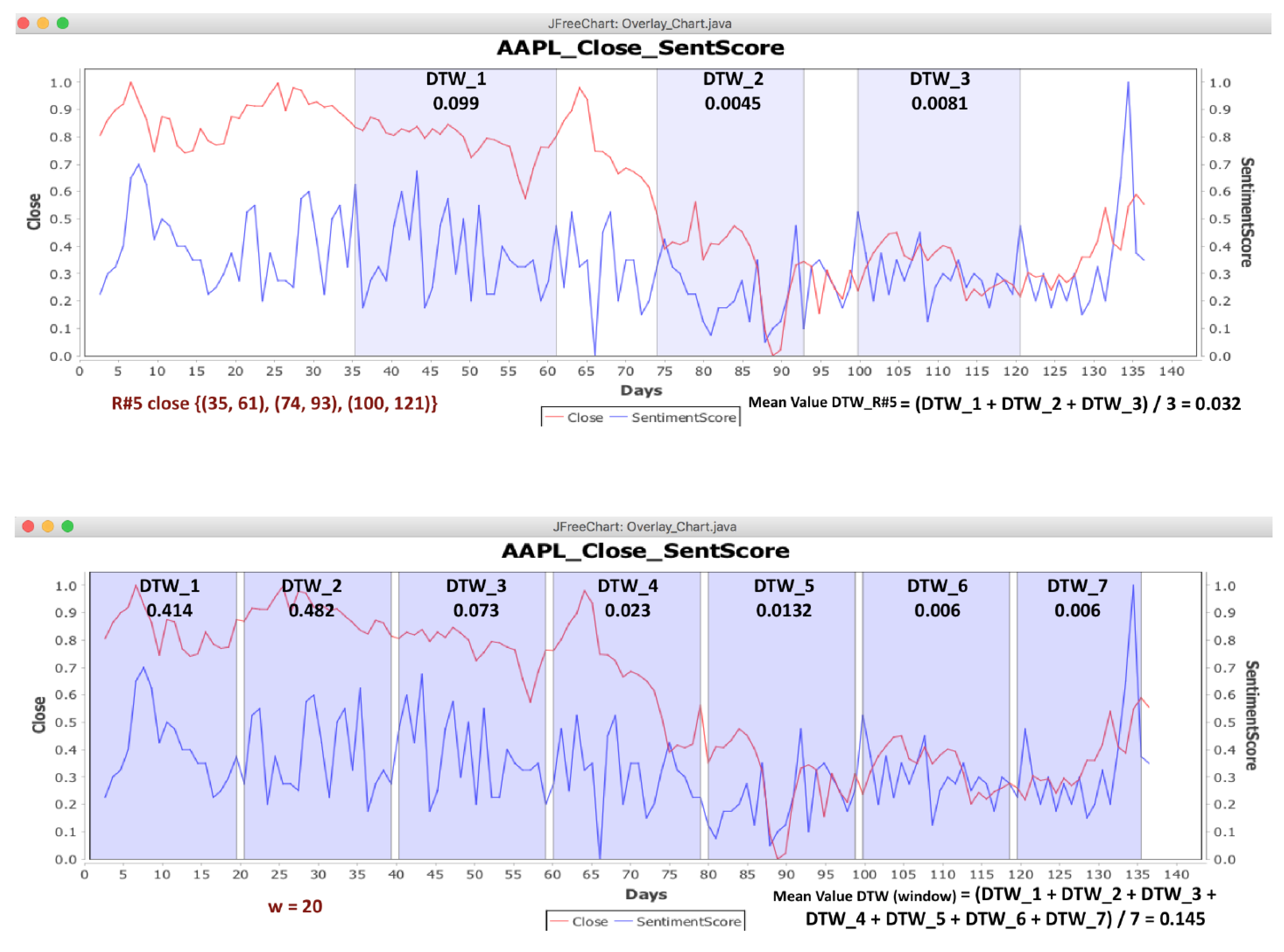
to use the DTW algorithm. First, for each of the five stocks (AAPL, GE, IBM, MSFT and ORCL), we measured the DTW distance between the close time series and the sentimentScore time series. We measured the DTW distance between the two time series at the intervals of close time series, where patterns were found via the GrammarViz 2.0 API, ±3 units. For each rule, we found the Mean Value (M.V.) of the DTW distance of intervals that compose this rule.
Tables S11–S15 show the DTW distances for AAPL, GE, IBM, MSFT and ORCL, respectively.
Then, random windows of
w length were selected for the time series. Thus, we compared the mean value of the DTW distance of each rule to the mean value of the DTW distance of the random windows. If the mean value of the DTW distance of rules was smaller than the mean value of the DTW distance of the random window, then there was a correlation between the time series at the intervals of rules where patterns were found in the close time series (
Figure 6).
The two time series are considered to be similar when the value of their distance is close to zero. On the other hand, when the distance is closer to one, that means that there is difference between the two time series.
For example, we compared the mean value (M.V.) of the rules of the patterns that were found for AAPL company (stock) (
Supplementary Material file, Table S11) with the mean value of the random windows. As seen, the mean value of the distance of the
rule is equal to 0.179, but in
Table S16, the mean value of the random window for the AAPL stock is smaller than this of
rule. Thus, for the intervals of the rule
, we cannot say that there is a correlation between the two time series. On the other hand, for the rule
(
Supplementary Material file, Table S11), the mean value of the distance is equal to 0.068. In
Table S16, we will see that there are random windows for which their mean value is bigger than the mean value of
. This means that there is a correlation between the two time series in ((4, 21), (79, 98)) intervals of the
. In addition,
Table S16 depicts the random windows that we have taken for the five companies (AAPL, GE, IBM, MSFT, ORCL).
Table S17 of the Supplementary Material file gives an overview of all the rules of the five companies where there is a correlation, i.e., a small DTW distance between the two time series. There are many rules with a small DTW distance, thus there is a correlation between close and sentimentScore time series (i.e., between closing price and news).
In order to check if there is a correlation between the time series of closing prices (close) and the number of tweets (numTweets), we followed the same steps as for the closing price and news. We measured the DTW distance between the close and the numTweets time series.
Tables S18–S22 of the Supplementary Material file show the distances for each stock that were found via the DTW algorithm. For each rule, the mean value of the distances of intervals, which are composing the rule, is calculated. The process to find if there is a correlation between the two time series is the same as the process of the close and the sentimentScore time series. In more detail, we compared the mean value of rules with the mean value of the random windows. If the mean value of the rules is smaller than the mean value of the random windows, there is a correlation between the two time series. We observed that in this case, also, there are intervals (i.e., rules) with a very small distance with respect to the random intervals (
Supplementary Material file, Table S23), which means that the close and numTweets time series are similar in these intervals; consequently, there is a correlation.
Table S24 of the Supplementary Material file gives an overview of all the rules of the five companies where there is a correlation, i.e., a small DTW distance between the two time series. There are many rules with a small DTW distance; thus, there is correlation between close and numTweets time series (i.e., between closing price and number of tweets).
5.5.1. Forecasting Methods and Models
Time series forecasting performance is usually evaluated upon training some model over a given period of time and then asking the model to forecast the future values for some given horizon. Provided that someone already knows the real values of the time series for the given horizon, it is straightforward to check the accuracy of the prediction by comparing them with the forecasting values.
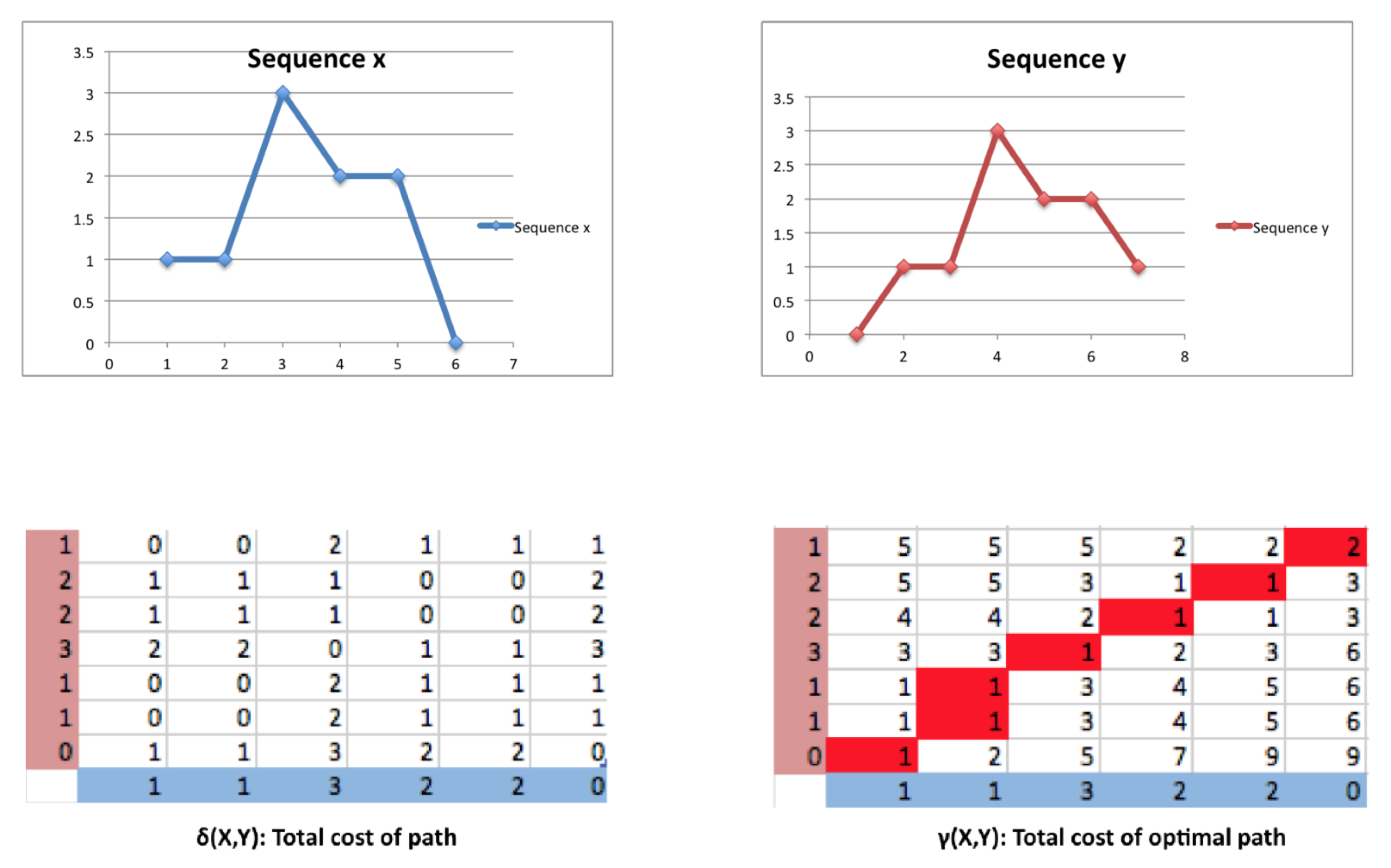
Denoting a time series of interest as
with
N points and a forecast of it as
, the resulting forecast error is given as
. Using this notation, the most common set of forecast evaluation statistics considered can be presented as below (
Table 2).
Intuitively, RMSE and MAE focus on the forecasting accuracy; RMSE assigns a greater penalty on large forecast errors than the MAE, while the statistic focuses on the quality, which will take the value of one under the naive forecasting method. Values less than one indicate greater forecasting accuracy than the naive forecasting method, and values greater than one indicate the opposite.
According to the literature, the most frequently used methods for time series forecasting include Autoregressive Integrated Moving Average (ARIMA) [
20,
21], Linear Regression (LR) [
22], the Generalized Linear Model (GLM) [
22], Support Vector Machines (SVM) [
23] and Artificial Neural Networks (ANN) [
24].
ARIMA
There are two commonly-used linear time series models in the literature, i.e., Autoregressive (AR) and Moving Average (MA) models. Combining these two, the Autoregressive Integrated Moving Average (ARIMA) model has been proposed in the literature. In a similar way to regression, ARIMA uses independent variables to predict a dependent variable (the series variable). The name autoregressive implies that the series values from the past are used to predict the current series value. In other words, the autoregressive component of an ARIMA model uses the lagged values of the series variable, that is values from previous time points, as predictors of the current value of the series variable.
LR and GLM
LR can be used to fit a forecasting model to an observed dataset, consisting of values of the response and explanatory variables. Upon learning of such a model, often fitted using the least squares approach, if additional values of the explanatory variables are collected without the accompanying response value, the fitted model can be used to make a prediction of the response. GLM is a flexible generalization of ordinary LR that allows for response variables to have error distributions other than the normal (Gaussian) distribution.
SVM
Initially, SVM were mainly applied to pattern classification problems such as character recognition, face identification, text classification, etc. However, soon, researchers found wide applications in other domains as well, such as function approximation, regression and time series forecasting. SVM techniques are based on the structural risk minimization rule. The objective of SVM is to find a decision rule with good generalization capability through selecting some particular subset of training data called support vectors. In this method, a best possible separating hyperplane is constructed, upon nonlinearly mapping of the input space into a higher dimensional feature space. Thus, the quality and complexity of SVM solution is not directly dependent on the input space. Another important characteristic of SVM is that the training process is equivalent to solving a linearly inhibited quadratic programming problem.
ANN
The ANN approach has been endorsed as an alternative technique to time series forecasting and has achieved immense popularity in the last few years. The main objective of ANN is to build a model for mimicking the intelligence of the human brain in a machine. Similar to the processed followed by a human brain, ANN will try to identify predictabilities and patterns within the input data, learn from past knowledge and then provide accurate estimates on new, unobserved data. Despite the fact that the development of ANN was mainly biologically motivated, they have been applied in numerous domains, primarily for forecasting and classification purposes. The main characteristic of ANN is that it is a data-driven and self-adaptive in nature method. There is no need to specify a particular model form or to make any a priori statement about the statistical distribution of data. Therefore, the desired model is adaptively formed and based on the features presented from the data.
Despite the fact that ARIMA only supports univariate time series and therefore cannot cope with sentiment data from news or tweets, we initially carried out an evaluation of the aforementioned models upon only the closing price of each of the five stock indices, namely AAPL, GE, IBM, MSFT and ORCL. Data from each company were split into two subsets, i.e., a training set of the first 127 days and a test set of the remaining 10. Since all models are sensitive to internal parameters, such as p (order of the autoregressive model) and q (order of the moving average) for ARIMA,
(learning rate) for the ANN, C (misclassification coefficient) for SVM, etc., we applied a grid search approach that optimized these parameters on the training set. This approach searched among various combinations of the parameters for the model that minimized the RMSE, using 10-fold cross-validation on the first 127 days. Therefore, we ensured that the last 10 days used as the test set would never be known to any of the above models.
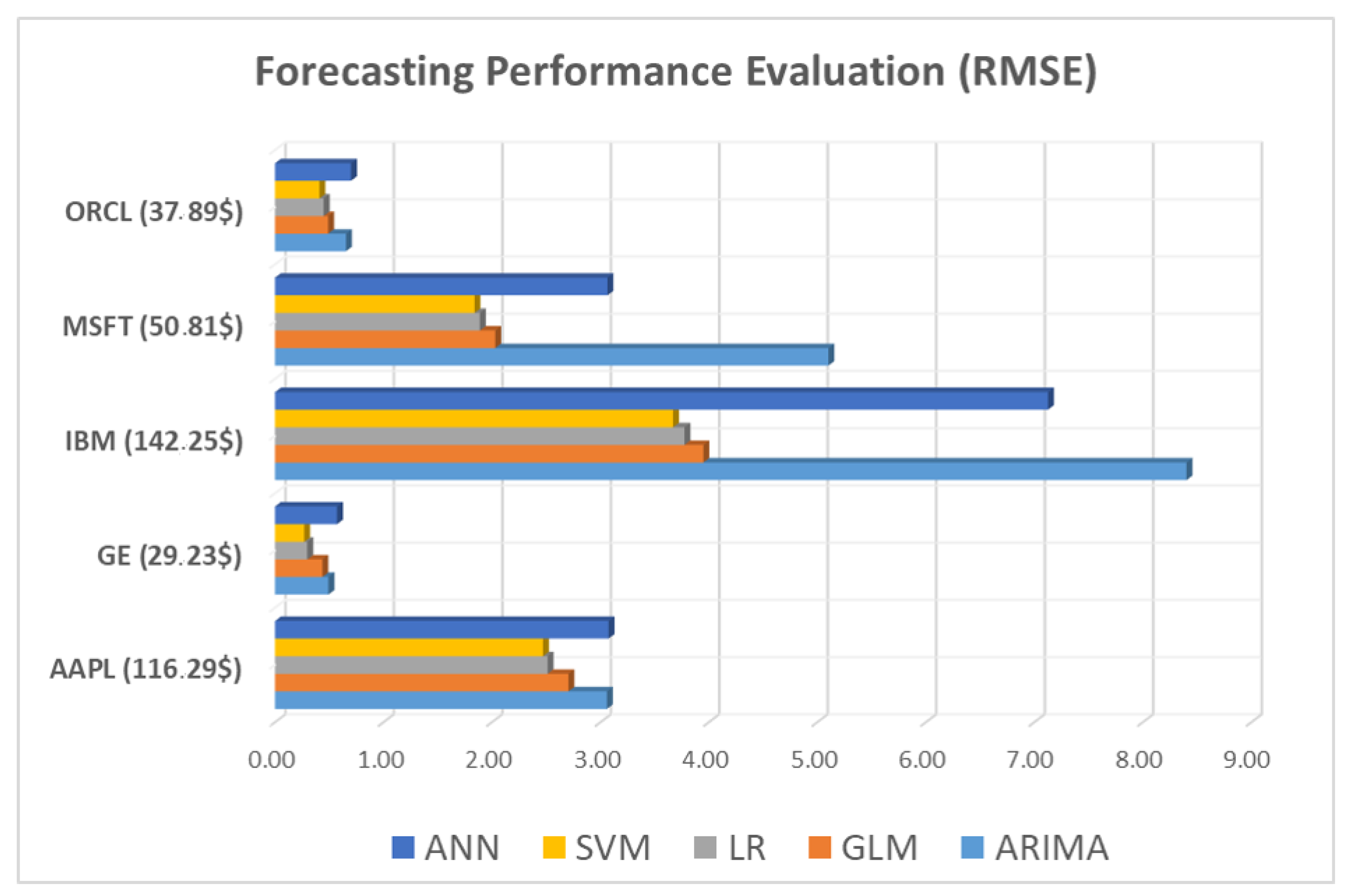
Figure 7 tabulates the performance of each model expressed in RMSE, for each stock. In the parenthesis next to the stock’s index, the average close price for the last 10 days test set is included.
As regards Theil’s
decomposition metric, the results support our aforementioned claim about the superiority and robustness of SVM and LR, since as shown in
Table 3, they present the lowest
scores.
Based on the above, we only consider the first two superior models, i.e., SVM and LR, throughout the further experiments that would examine if news and tweets can improve the prediction of the closing price of the next day, especially when considering time periods that have been identified from the rule extraction phase.
Even though the obvious approach when comparing two forecasting models is to select the one that has the smaller error measurement based on one of the error measurements described above, we need to determine whether this difference is significant or basically due to the specific choice of data values in the sample. Therefore, each of the five forecasting models was compared to the others in terms of the Diebold–Mariano (DM) test [
25].
Considering the null hypothesis to be as: “both forecasting model have the same accuracy”, the DM test returns two metrics, i.e., a p-value, denoting that the hypothesis holds when close to one or does not hold when close to zero, and DM-statistics, measuring the squared errors of the two models. Negative values show that the squared errors of the model listed first are lower than those of the model listed last.
For reasons of space economy,
Table 4 tabulates the DM test between all models for the AAPL stock. The results for the other companies are almost identical to AAPL.
We could observe that based on both the p-values and DM-statistic metrics, LR and SVM can be considered as having almost the same accuracy, while all other pairs of comparisons do not follow this trend, with the small exception of the GLM method.
5.5.2. Can News and Tweets Improve the Prediction of the Next Closing Price?
In order to check if the sentiment score of the news and the number of tweets can improve the prediction of the next closing price, we examined the intervals in which there are patterns and at the same time have a small DTW distance, i.e., the rules that have a small DTW distance (
Supplementary Material file, Table S25). If the sentiment score of news and the number of tweets on these rules help to improve the prediction, then the rules are more useful than the random intervals of days. Thus, the experiments to check if these rules improve the prediction of the next closing price were performed as follows:
Afterwards, we compared these rules against random intervals of time. In the random intervals of time, the improvement rates of the next closing price are calculated, again, by the sentiment score of news, the number of tweets and both of them.
The RapidMiner tool [
26] was used for the experiments, and for the prediction, we used two methods of regression, linear regression and the SVM regression. Due to the fact that linear and SVM regression are two of the most popular algorithms in predictive modeling, we decided to perform our experiments by using these two methods. In addition, SVM is a rather robust method for forecasting. The prediction was based on the three previous days. Then, we compared the two methods to evaluate which gives better improvement rates.
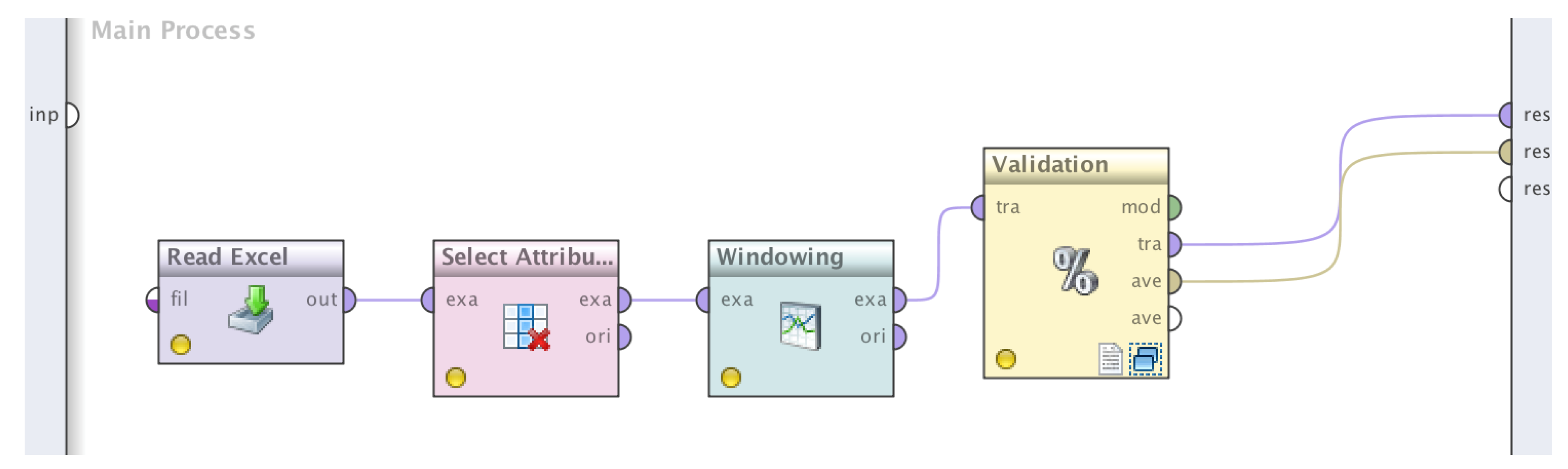
Figure 8 shows the basic process, which consisted of the following four processes in the RapidMiner tool.
The steps of the process in more detail:
This operator can be used to load data from Microsoft Excel spreadsheets. In our case, the excel file that will be loaded in the Rapid Miner tool has the following columns (attributes): date, close, volume, open, high, low, sentiment and tweets.
This operator selects which attributes of an ExampleSet should be kept and which attributes should be removed. This is used in cases when not all attributes of an ExampleSet are required; it helps to select required attributes. In our case, we selected the “date” as a filter of attributes, and we selected the option “invert selection” because we needed to filter a subset of attributes.
Windowing
This operator transforms a given example set containing series data into a new example set containing single valued examples. For this purpose, windows with a specified window and step size are moved across the series, and the attribute value lying horizon values after the window end is used as a label that should be predicted. In simpler words, we select the step in order to make the prediction. We have chosen to predict the next closing price based on the three previous days.
This operator performs a cross-validation in order to estimate the statistical performance of a learning operator (usually on unseen datasets). It is mainly used to estimate how accurately a model (learned by a particular learning operator) will perform in practice. As previously explained, the two most accurate regression types were used for our experiments, i.e., linear regression and Support Vector Machines (SVM).
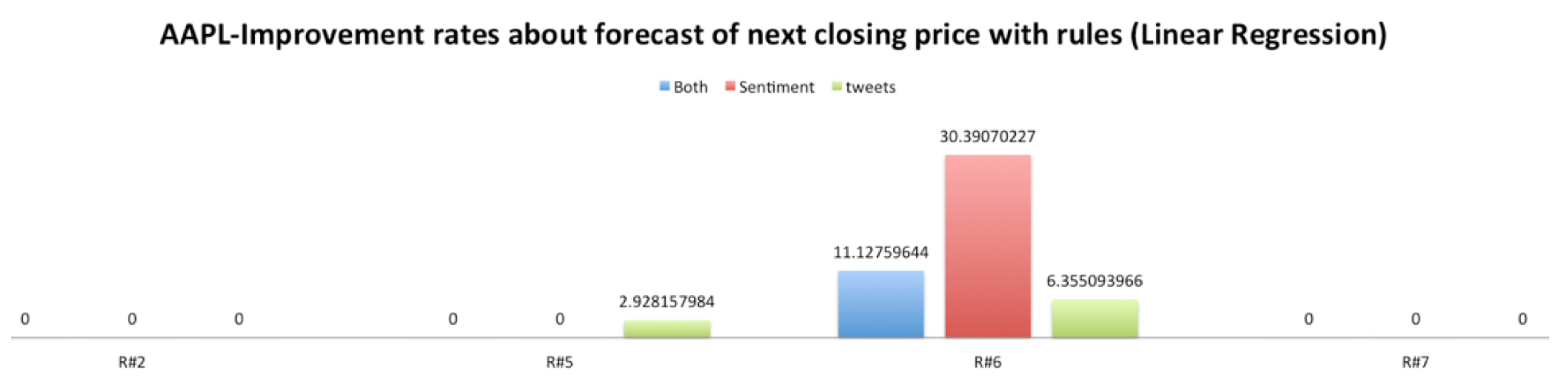
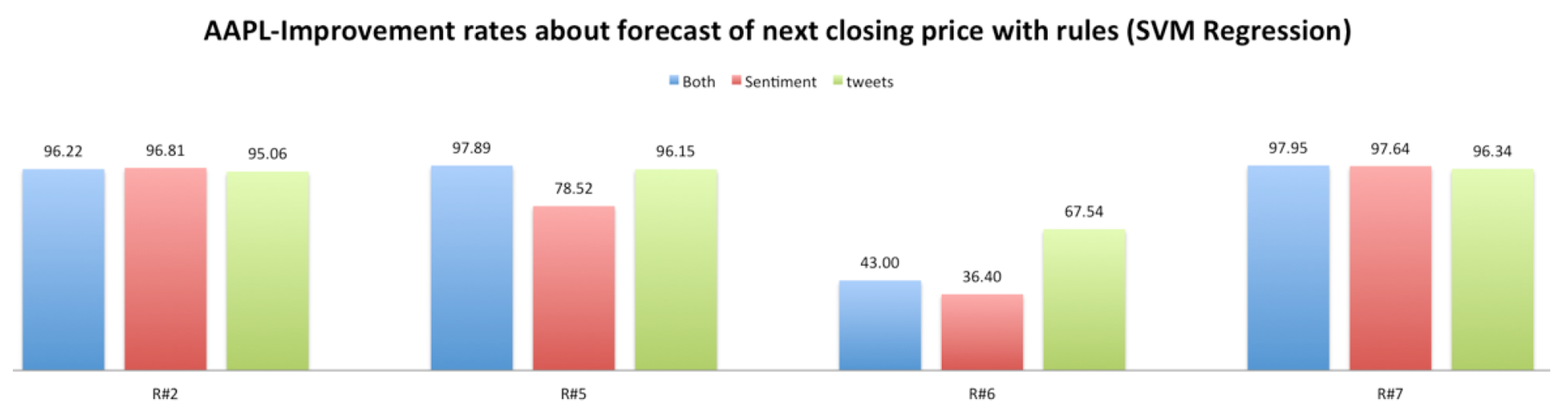
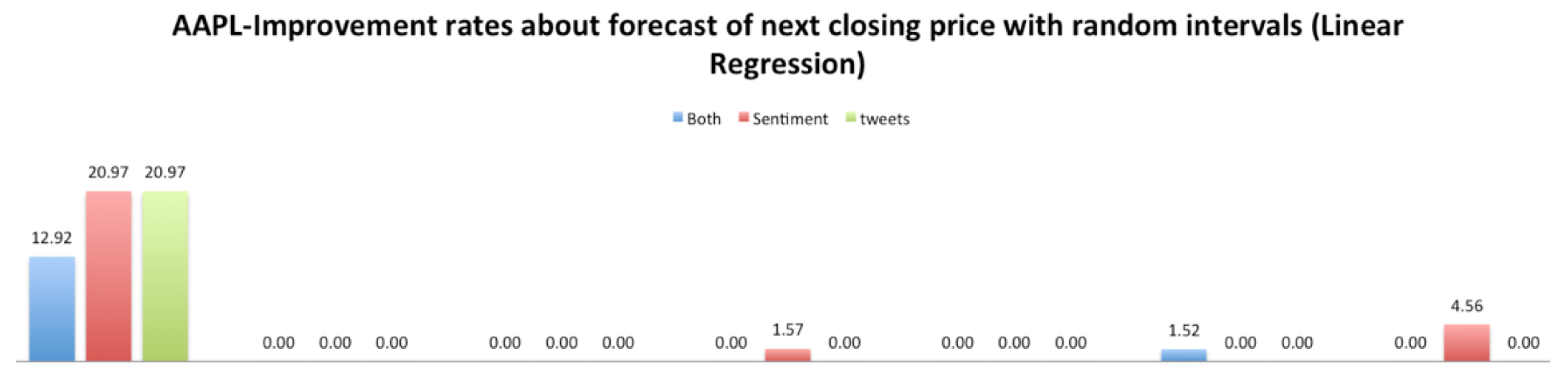
As we can see in
Figure 9,
Figure 10,
Figure 11 and
Figure 12, the improvement rates were better when we used the rules than the random intervals. Furthermore, using SVM regression, we have better results than with the linear regression. Similar results were found for the other four stocks, and in most cases, the rules improved the prediction of the next closing price. The improvements are depicted below in
Table 5 and
Table 6.
5.5.3. Results
We have also performed a DM-test to verify that the forecasting performance of SVM within the intervals denoted by the rules is superior to the outcome of the same method for random intervals. We used the dataset of both sentiments and tweets to conduct the evaluations for all stock prices. Again, the null hypothesis was considered to be that the two forecasting models (rule vs. random intervals) have equal accuracy.
Table 7 presents the
p-value and DM-statistic metrics. Recall that when the
p-value is close to zero, the null hypothesis is rejected. Furthermore, negative values of the DM-statistic depict that the squared errors of the model listed first (the rule-based intervals) are lower than those of the model listed last.
As seen from that table, for all companies, p-values are close to zero and the DM-statistic is negative, denoting that not only the null hypothesis does not hold, but the intervals identified by the rules have lower squared errors.
The fact that rules have been found in which the sentiment score, the tweets or both can improve the prediction is a very encouraging result for further future study.
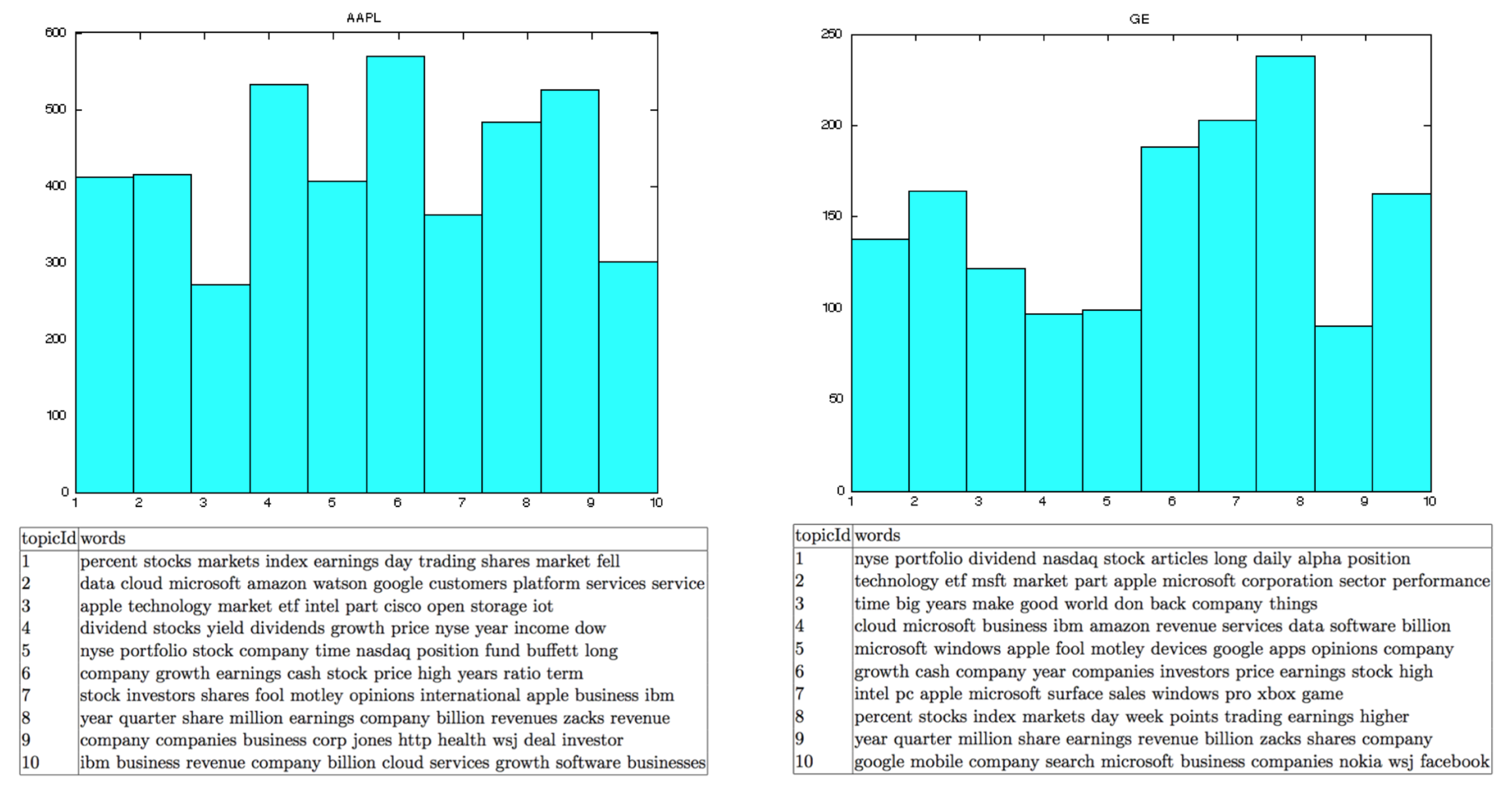
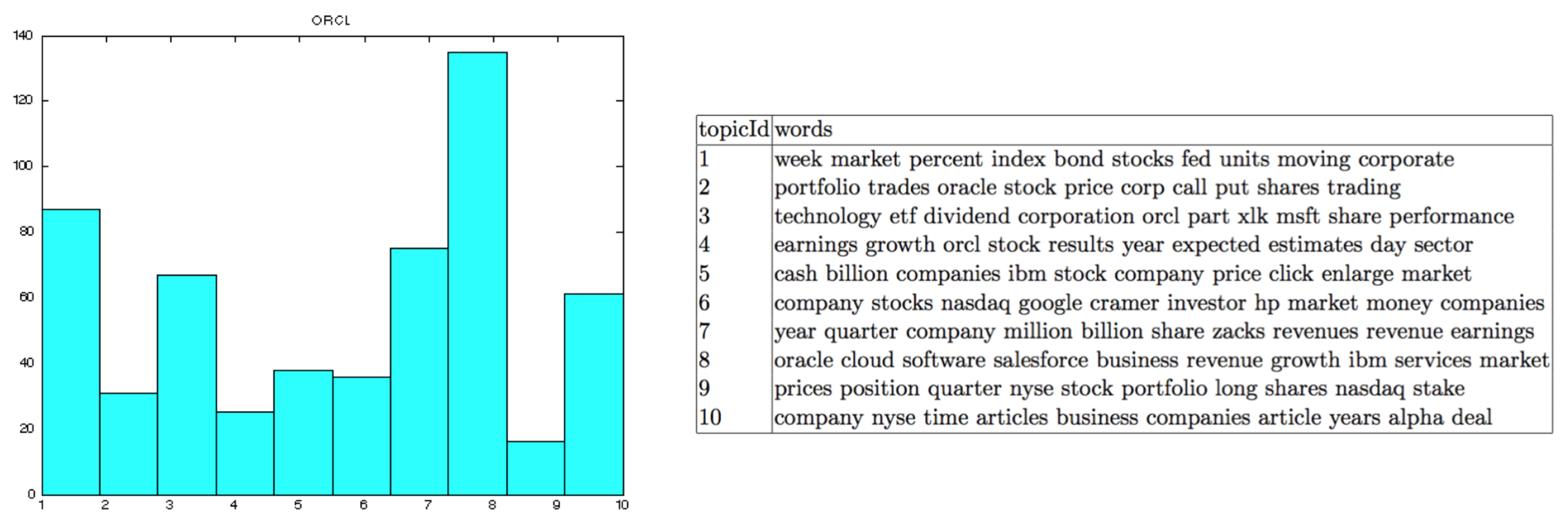
In
Figure 13,
Figure 14 and
Figure 15, all texts have been clustered in topics, using the LDA algorithm. The latter could help to improve our method by incorporating a better filtering of news data by using the topic of each text. In other words, we could choose the texts that are more relevant to the stock market, based on the results of the topic modeling.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}