The Experimental Process Design of Artificial Lightweight Aggregates Using an Orthogonal Array Table and Analysis by Machine Learning


Abstract
:1. Introduction
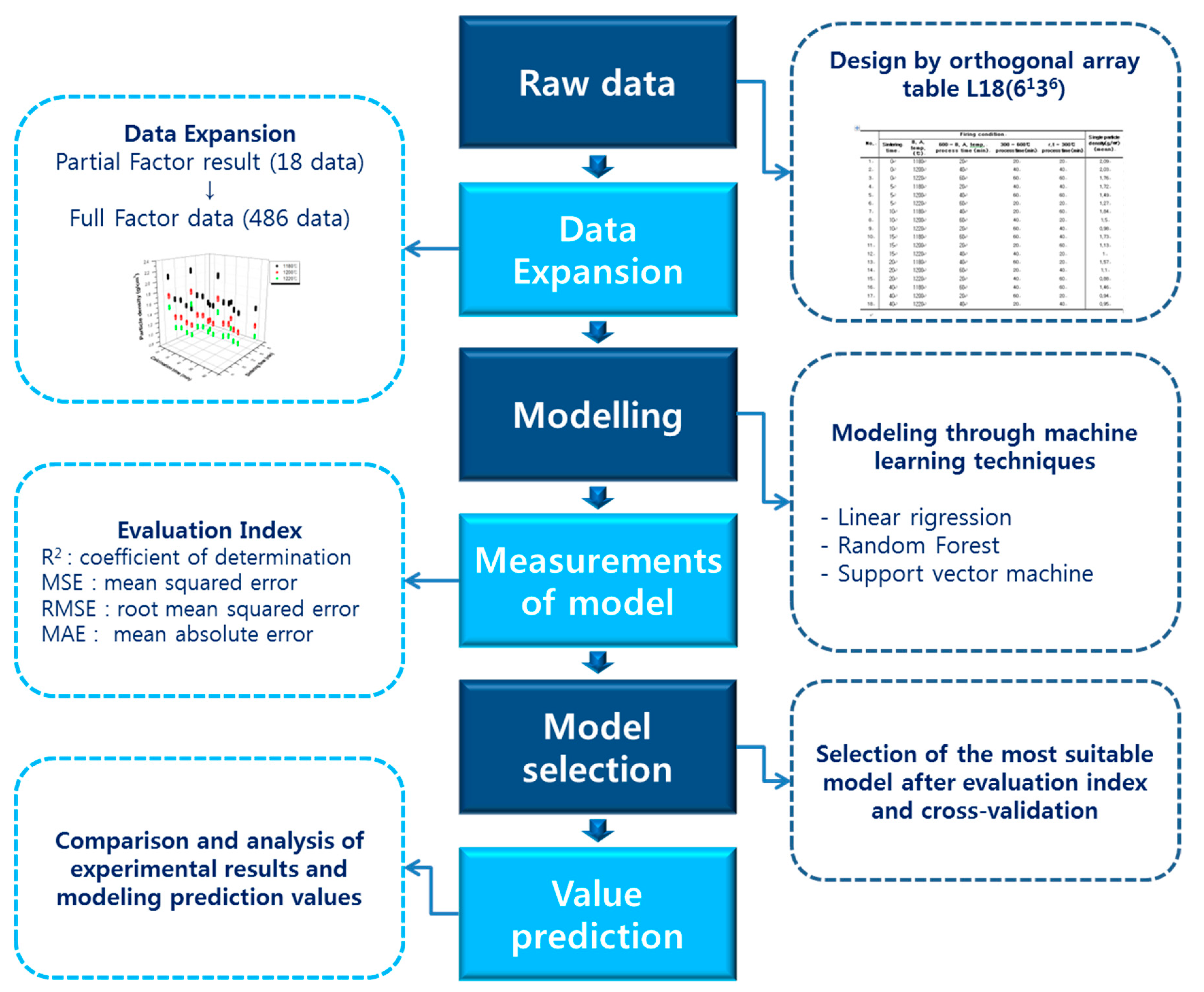
2. Experiment Method
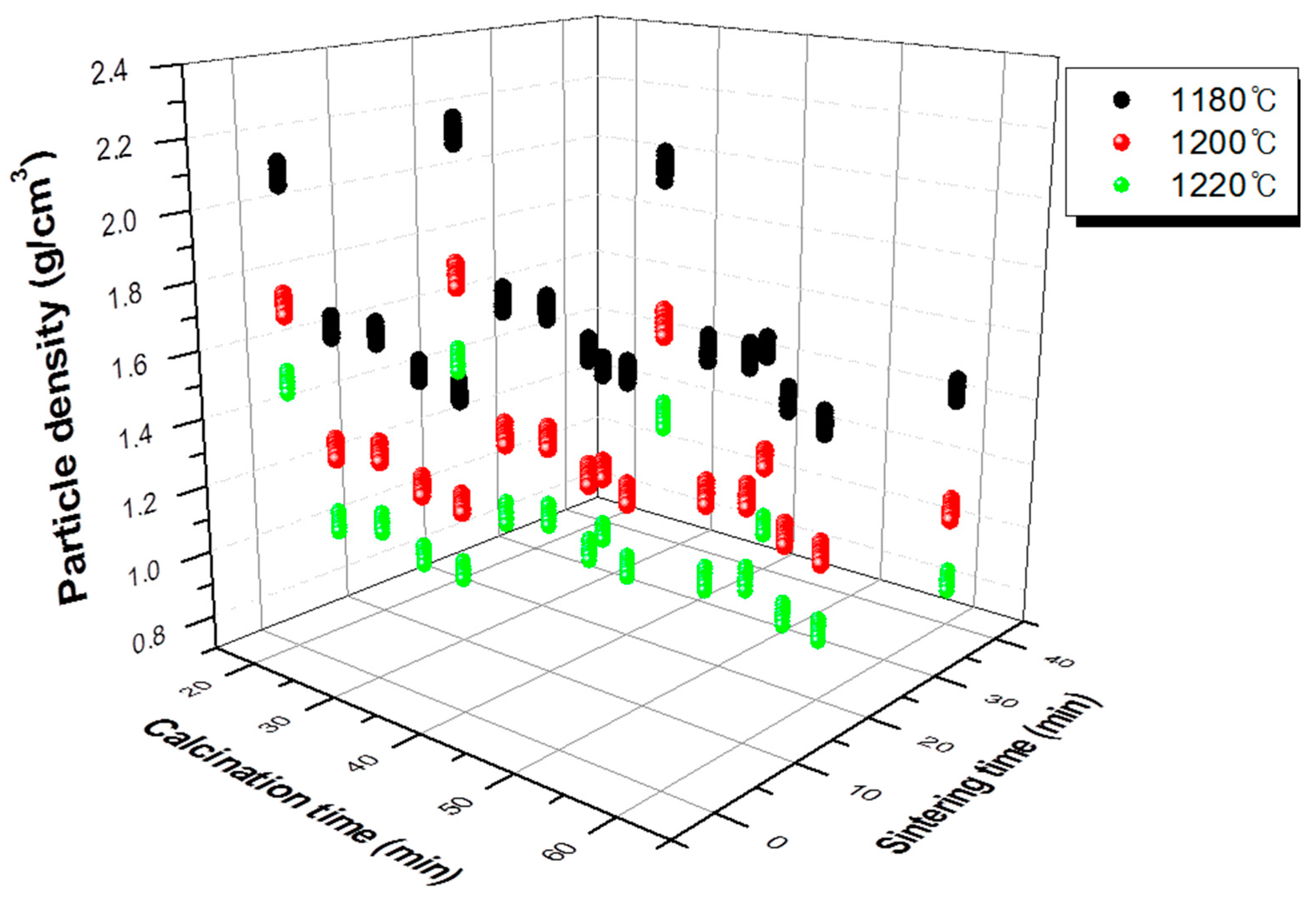
2.1. Experimental Variables and Experimental Design
2.2. Data Expansion by Means of an Orthogonal Array Experiment Design
2.3. Machine-Learning Analysis Using Extended Data
3. Machine-Learning Regression Methods
3.1. Linear Regression
3.2. Regression Tree
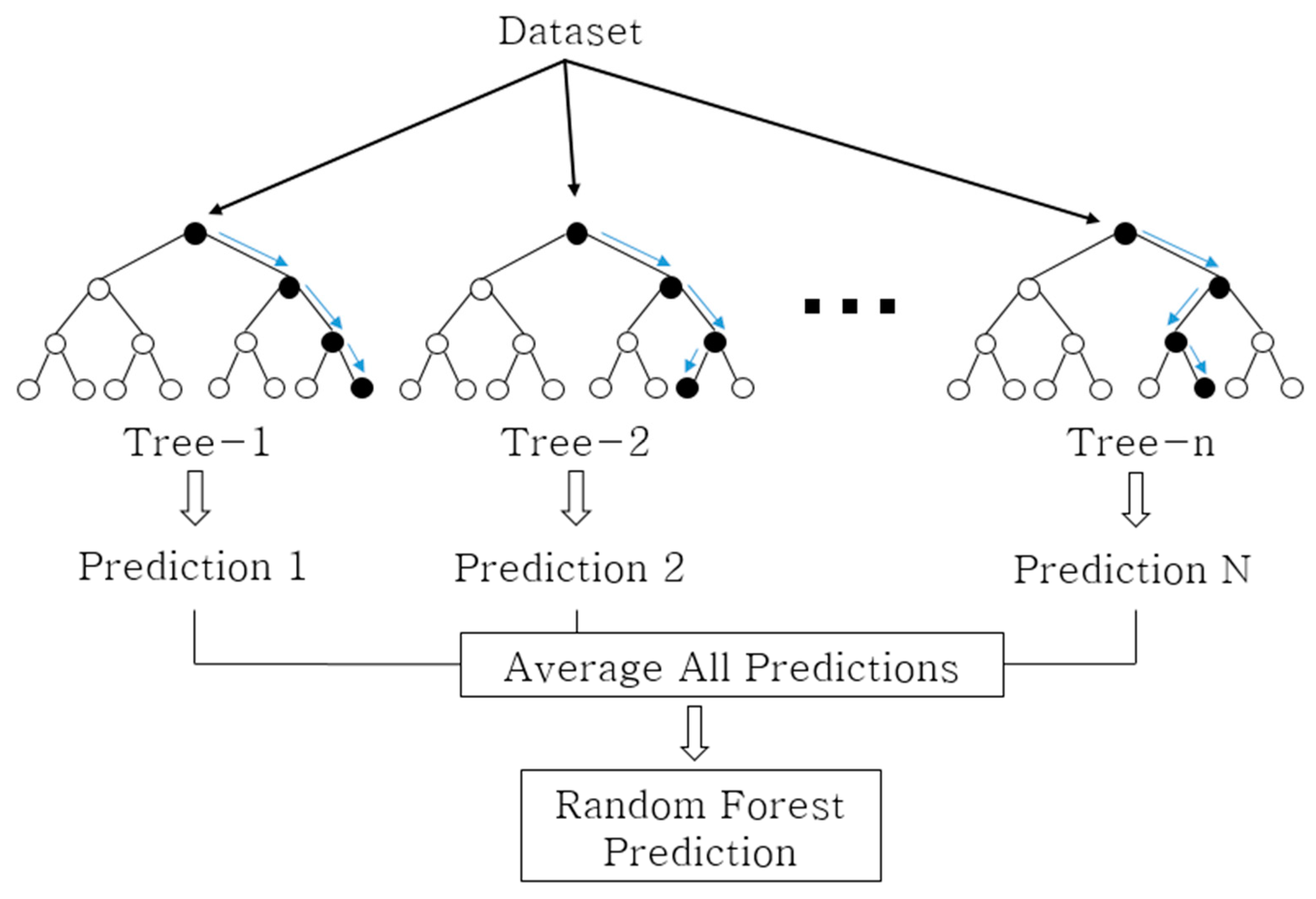
3.3. Random Forest
- Create bootstrap sample using n data for training data .
- At , only values of independent variables are randomly selected to generate a decision tree.
- Compute the final predicted value of the random forest by combining the predicted values of the trees. In general, the average value is used.
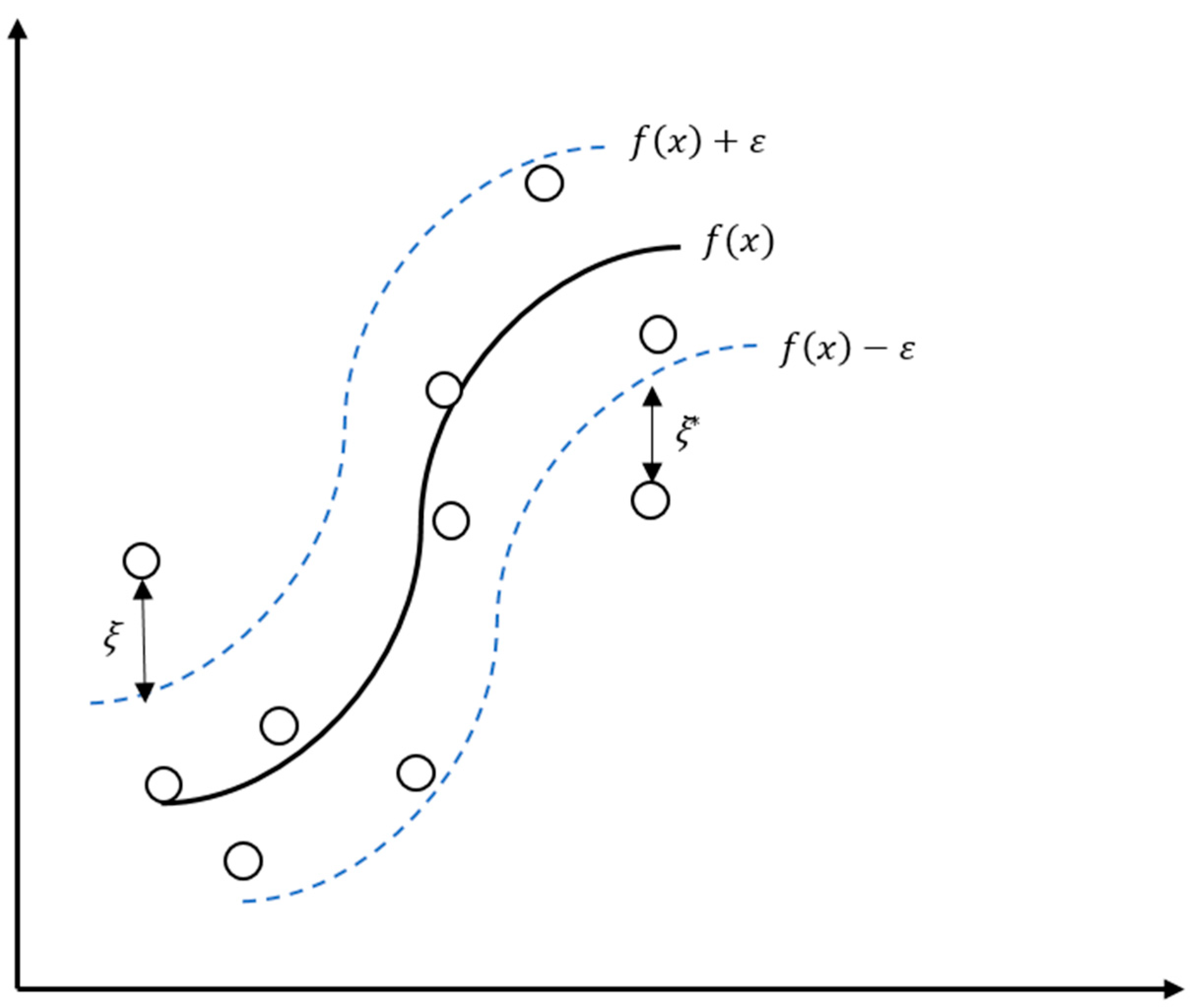
3.4. SVR (Support Vector Regression)
4. Evaluation of the Performance
4.1. Leave-One-Out Cross Validation, (LOOCV)
4.2. Performance Evaluation Measures
5. Results and Discussion
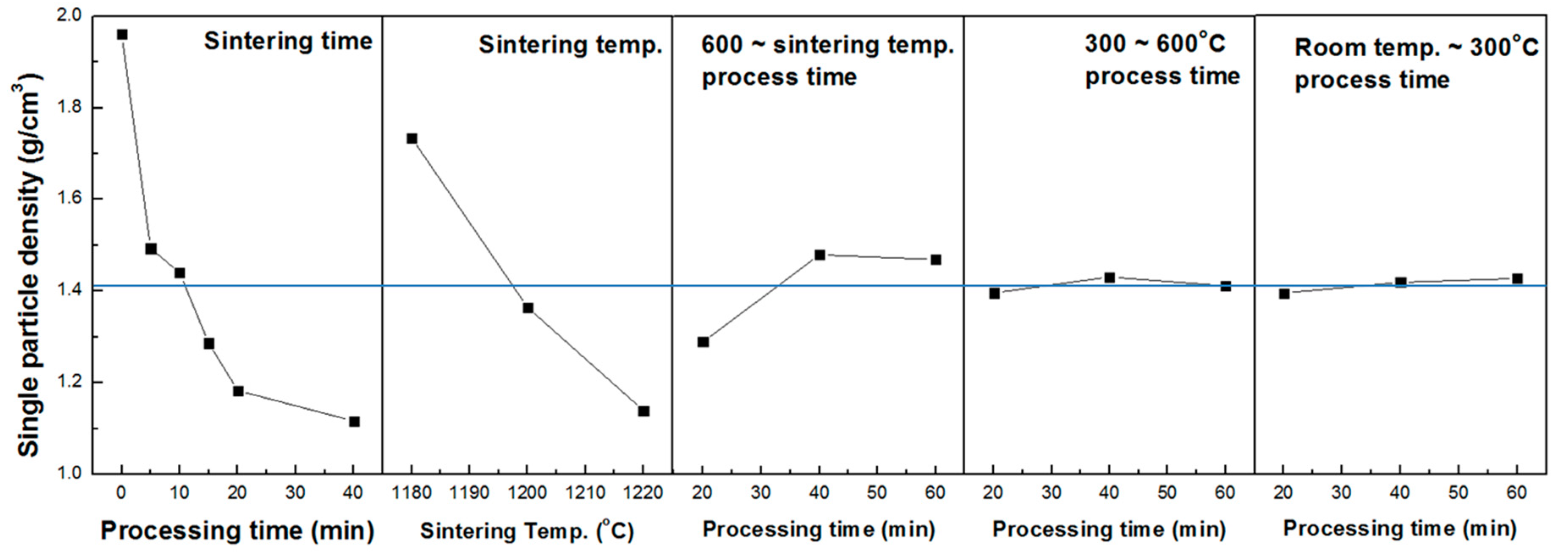
5.1. Property Prediction and Data Expansion by the Orthogonal Array Experiment Design
- (1)
- Gas is generated inside the aggregates.
- (2)
- The generated gas creates pressure, the pore walls are destroyed by the pressure, and the pores merge.
- (3)
- The pores grow due to the pressure difference between small pores and large pores.
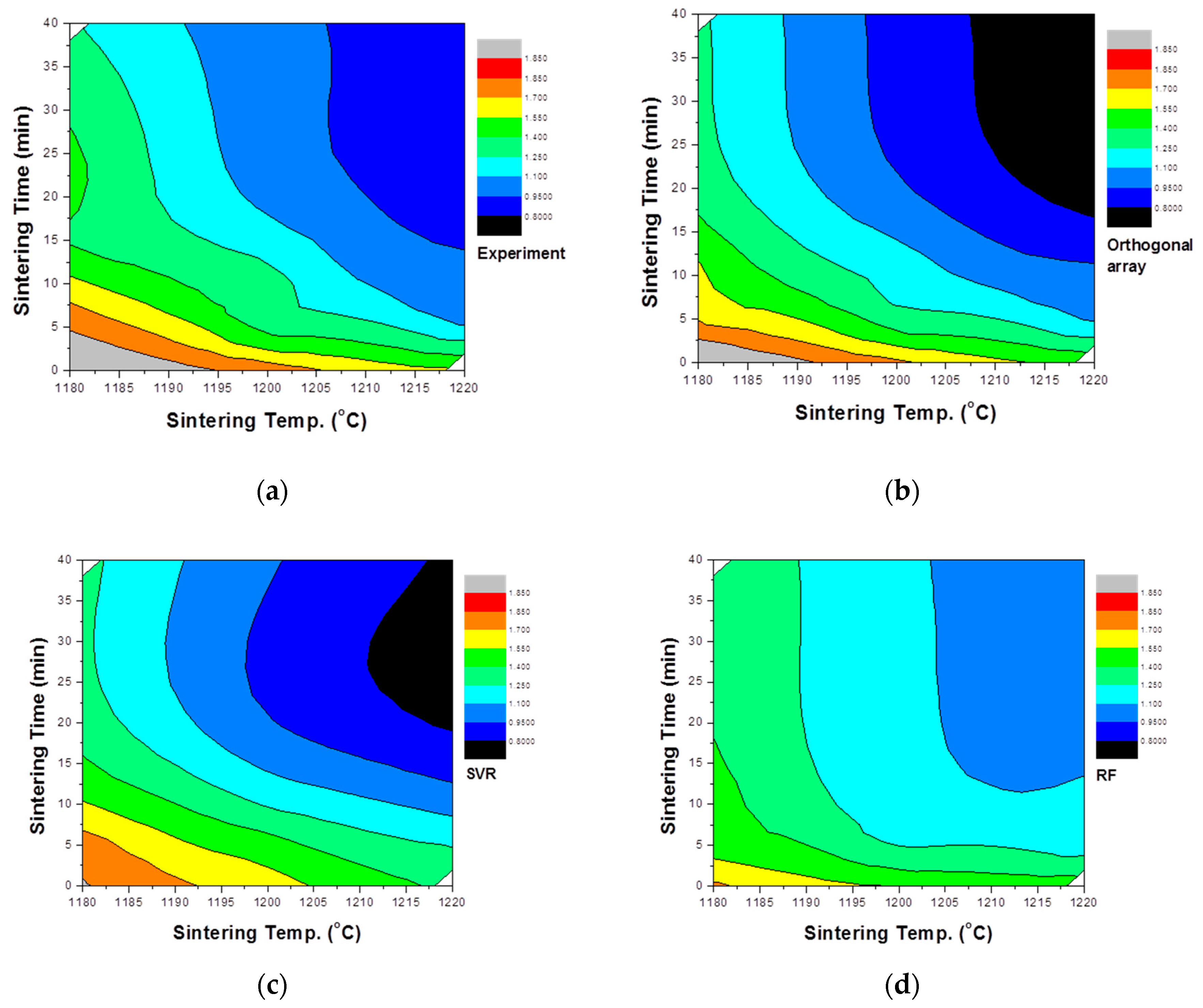
5.2. Evaluation of the Model
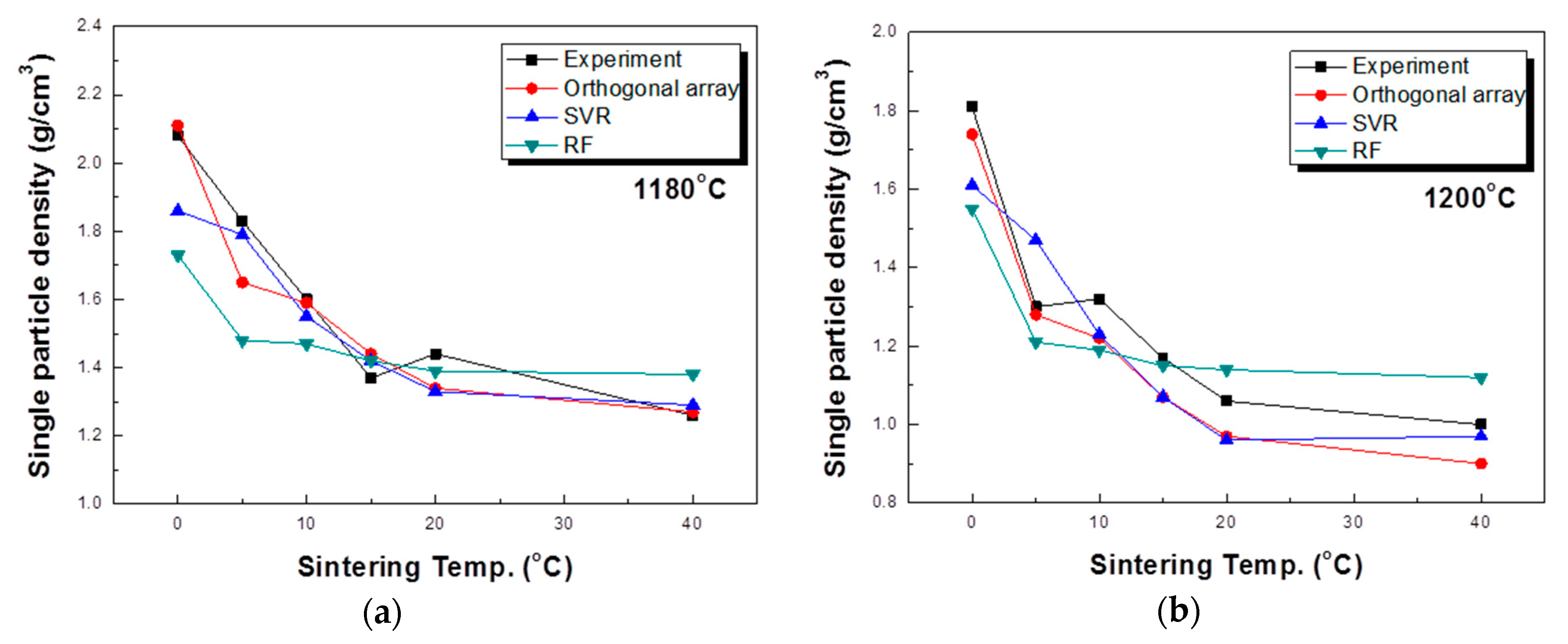
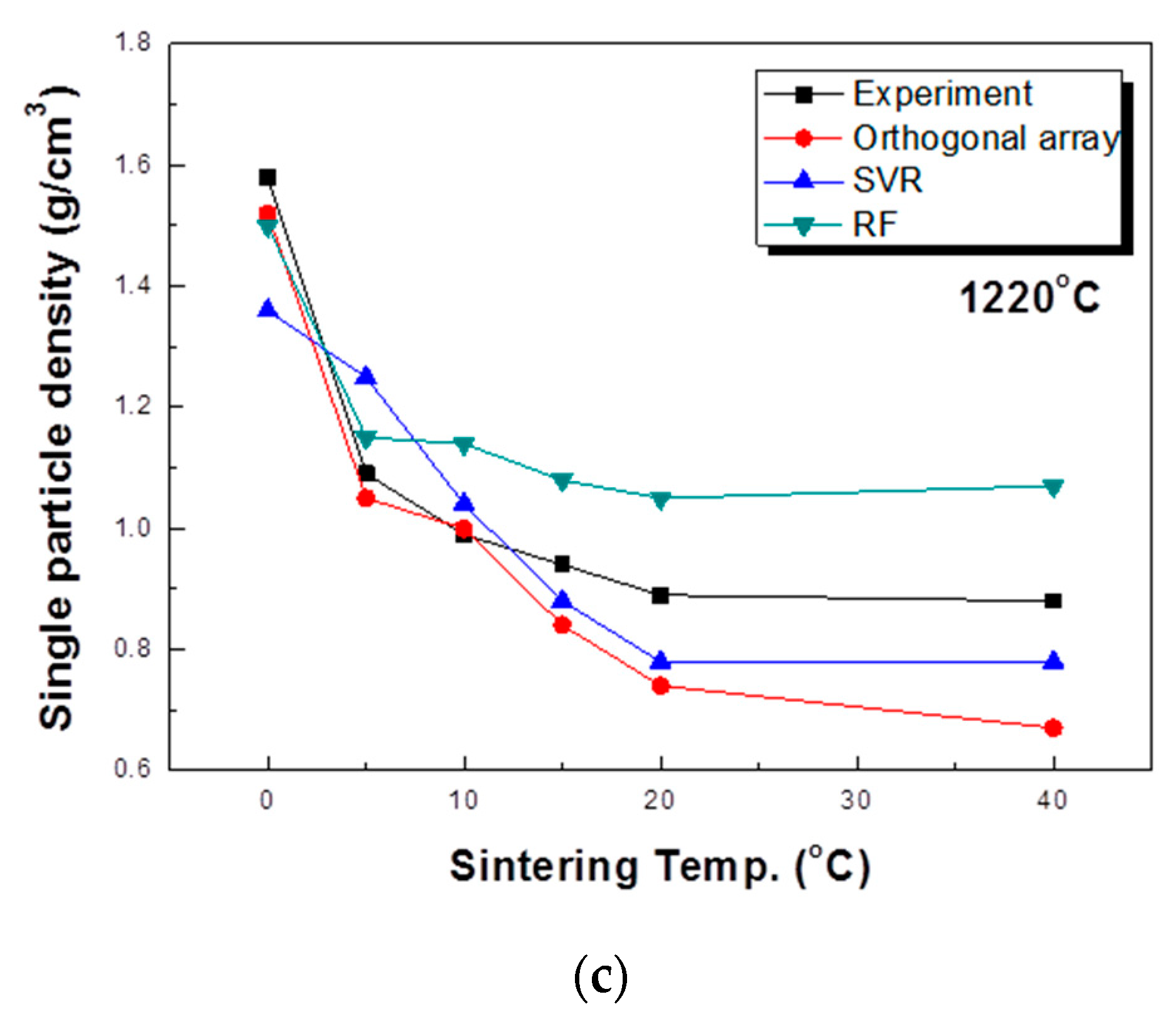
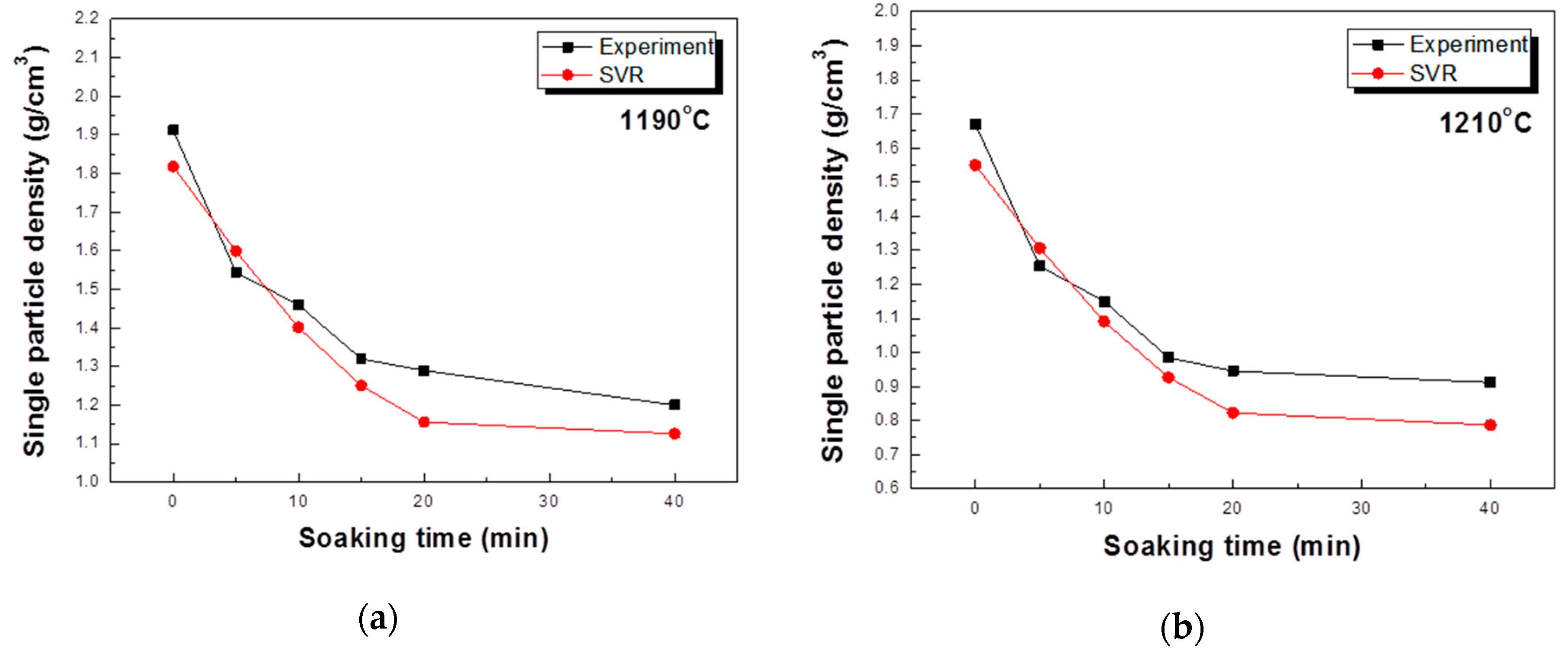
5.3. Experimental Evaluation of the Model Accuracy
6. Conclusions
- The experimental design using the orthogonal array table and the expanded data gained through this method did not show a significant difference from the measured values.
- The SVR model showed the best prediction accuracy among the reviewed models and generally showed good results even with untested variables.
- Modeling by the random forest method predicts the trend of the process well. However, the result was predicted to be closer to the mean value than the actual value, and it could not be predicted for an untested part.
- Through the experimental design and the expansion of the data by the orthogonal array table and modeling with the machine-learning technique, a model capable of efficiently predicting physical properties was realized.
Author Contributions
Funding
Conflicts of Interest
References
- Moreno-Maroto, J.M.; Uceda-Rodríguez, M.; Cobo-Ceacero, C.J.; Cotes-Palomino, T.; Martínez-García, C.; Alonso-Azcárate, J. Studying the feasibility of a selection of Southern European ceramic clays for the production of lightweight aggregates. Constr. Build. Mater. 2020, 237, 117583. [Google Scholar] [CrossRef]
- Kim, D.S. Construction Material Demand Forecast in 2020. Korea Construction News. Available online: http://www.conslove.co.kr/news/articleView.html?idxno=63080 (accessed on 28 October 2020).
- Franus, M.; Panek, R.; Madej, J.; Franus, M. The properties of fly ash derived lightweighth aggregates obtained using microwave radiation. Constr. Build. Mater. 2019, 239, 116677. [Google Scholar] [CrossRef]
- Moreno-Maroto, J.M.; Uceda-Rodríguez, M.; Cobo-Ceacero, C.J.; de Hoces, M.C.; MartínLara, M.A.; Cotes-Palomino, T.; García, A.B.L.; Matínez-García, C. Recycling of ‘alperujo’ (olive pomace) as a key component in thesintering of lightweight aggregates. J. Clean. Prod. 2019, 239, 118041. [Google Scholar] [CrossRef]
- Moreno-Maroto, J.M.; González-Corrochano, B.; Alonso-Azcárate, J.; García, C.M. A study on the valorization of a metallic ore mining tailing and its combination with polymeric wastes for lightweight aggregates production. J. Clean. Prod. 2019, 212, 997–1007. [Google Scholar] [CrossRef]
- Guo, J.; Zhang, L.; Wang, W.; Zhang, H.; Liu, X.; Liu, M. Effect of SiO2 and Al2O3 on characteristics of lightweight aggregate made from sewage sludge and river sediment. Ceram. Int. 2017, 44, 4313–4319. [Google Scholar] [CrossRef]
- Souza, M.M.; Anjos, M.A.S.; Sá, M.V.V.A.; Souza, N.S.L. Developing and classifying lightweight aggregates fromsewage sludge and rice husk ash. Case Stud. Constr. Mater. 2020, 12, e00340. [Google Scholar] [CrossRef]
- Chang, C.; Hong, G.; Lin, H. Artificial Lightweight Aggregate from Different Waste Materials. Environ. Eng. Sci. 2016, 33, 283–289. [Google Scholar] [CrossRef]
- Wei, Y.; Cheng, S.; Ou, K.; Kuo, P.; Chung, T.; Xie, X. Effect of calcium compounds on lightweight aggregates prepared by firing a mixture of coal fly ash and waste glass. Ceram. Int. 2017, 43, 15573–15579. [Google Scholar] [CrossRef]
- Wei, Y.; Cheng, S.; Chen, W.; Lu, Y.; Chen, K.; Wu, P. Influence of various sodium salt species on formation mechanism of lightweight aggregates made from coal fly ash-based material. Constr. Build. Mater. 2020, 239, 117890. [Google Scholar] [CrossRef]
- Piszcz-Karaś, K.; Klein, M.; Hupka, J.; Łuczak, J. Utilization of shale cuttings in production of lightweight aggregates. J. Environ. Manag. 2019, 231, 232–240. [Google Scholar] [CrossRef]
- Lee, K.G. Bloating Mechanism of Lightweight Aggregate with the Size. J. Korean Ceram. Soc. 2016, 53, 241–245. [Google Scholar] [CrossRef]
- Kang, S.H.; Lee, K.G. Bloating Mechanism of Artificial Lightweight Aggregate for Recycling the Waste Glass. J. Korean Ceram. Soc. 2010, 47, 445–449. [Google Scholar] [CrossRef] [Green Version]
- Li, Z.; Zhang, H.; Zhao, P.; He, X.; Duan, X. Manufacturing of Ultra-Light Ceramsite from Slate Wastes in Shangri-la, China. J. Korean. Ceram. Soc. 2018, 55, 36–43. [Google Scholar] [CrossRef] [Green Version]
- Kang, M.A.; Kang, S.G.; Lee, K.G.; Kim, Y.T. Fabrication of Artificial Light-Weight Aggregates of Uniform Bloating Properties Using a Temperature-Raising Sintering Method. J. Korean Ceram. Soc. 2012, 49, 161–166. [Google Scholar] [CrossRef]
- Wie, Y.M.; Lee, K.G. Optimum Bloating-Activation Zone of Artificial Lightweight Aggregate by Dynamic Parameters. Materials 2019, 12, 267. [Google Scholar] [CrossRef] [Green Version]
- Dondi, M.; Cappelletti, P.; D’Amore, M.; de Gennaro, R.; Graziano, S.F.; Langella, A.; Raimondo, M.; Zanelli, C. Lightweight aggregates from waste materials: Reappraisal of expansion behavior and prediction schemes for bloating. Constr. Build. Mater. 2016, 127, 394–409. [Google Scholar] [CrossRef]
- Moreno-Maroto, J.M.; Cobo-Ceacero, C.J.; Uuceda-Rodríguez, M.; Cotes-Palomino, T.; García, C.M.; Alonso-Azcára, J. Unraveling the expansion mechanism in lightweight aggregates:Demonstrating that bloating barely requires gas. Constr. Build. Mater. 2020, 247, 118583. [Google Scholar] [CrossRef]
- Wie, Y.M.; Lee, K.G.; Lee, K.H. Optimum conditions for unit processing of artificial lightweight aggregates using the Taguchi method. J. Asian Ceram. Soc. 2019, 7, 331–341. [Google Scholar] [CrossRef] [Green Version]
- Gos, M.; Krzyszczak, J.; Baranowski, P.; Murat, M. Combined TBATS and SVM model of minimum and maximum air temperatures applied to wheat yield prediction at different locations in Europe. Agric. For. Meteorol. 2020, 281, 107827. [Google Scholar] [CrossRef]
- Ge, Y.; Zhao, S.; Zhao, X. A step-by-step classification algorithm of protein secondary structures based on double-layer SVM model. Genomics 2020, 112, 1941–1946. [Google Scholar] [CrossRef]
- Gerhardt, N.; Schwolow, S.; Rohn, S.; Pérez-Cacho, P.R.; Galán-Soldevilla, H.; Arce, L.; Weller, P. Quality assessment of olive oils based on temperature-ramped HS-GC-IMS and sensory evaluation: Comparison of different processing approaches by LDA, kNN, and SVM. Food Chem. 2019, 278, 720–728. [Google Scholar] [CrossRef] [PubMed]
- Li, M.; Wei, D.; Liu, T.; Liu, Y.; Yan, L.; Wei, Q.; Du, B.; Xu, W. EDTA functionalized magnetic biochar for Pb(II) removal: Adsorption performance, mechanism and SVM model prediction. Sep. Purif. Technol. 2019, 227, 115696. [Google Scholar] [CrossRef]
- Fan, J.; Yue, W.; Wu, L.; Zhang, F.; Cai, H.; Wang, X.; Lu, X.; Xiang, Y. Evaluation of SVM, ELM and four tree-based ensemble models for predicting daily reference evapotranspiration using limited meteorological data in different climates of China. Agric. For. Meteorol. 2018, 263, 225–241. [Google Scholar] [CrossRef]
- Yu, Y.; Zhang, C.; Gu, X.; Cui, Y. Expansion prediction of alkali aggregate reactivity-affected concrete structures using a hybrid soft computing method. Neural Comput. Appl. 2019, 31, 8641–8660. [Google Scholar] [CrossRef]
- Sihag, P.; Kumar, M.; Singh, V. Enhanced soft computing for ensemble approach to estimate the compressive strength of high strength concrete. J. Mater. Eng. Struct. 2019, 6, 93–103. [Google Scholar]
- Abd, A.M.; Abd, S.M. Modelling the strength of lightweight foamed concrete using support vector machine (SVM). Case Stud. Constr. Mater. 2017, 6, 8–15. [Google Scholar] [CrossRef] [Green Version]
- Azimi-Pour, M.; Eskandari-Naddaf, H.; Pakzad, A. Linear and non-linear SVM prediction for fresh properties and compressive strength of high volume fly ash self-compacting concrete. Constr. Build. Mater. 2020, 230, 117021. [Google Scholar] [CrossRef]
- Bolandi, H.; Banzhaf, W.; Lajnef, N.; Barri, K.; Alavi, A.H. An Intelligent Model for the Prediction of Bond Strength of FRP Bars in Concrete: A Soft Computing Approach. Technologies 2019, 7, 42. [Google Scholar] [CrossRef] [Green Version]
- Solhmirzaei, R.; Salehi, H.; Kodur, V.; Naser, M.Z. Machine learning framework for predicting failure mode and shear capacity of ultra high performance concrete beams. Eng. Struct. 2020, 224, 111221. [Google Scholar] [CrossRef]
- Korean Standards Association. Testing Method for Density and Absorption of Coarse Aggregate; KS F 2503:2007; Korean Standards Association: Seoul, Korea, 2007. [Google Scholar]
- Sabarish, K.V.; Paul, P. An experimental analysis on structural beam with Taguchi orthogonal array. Mater. Today Proc. 2020, 22, 874–878. [Google Scholar] [CrossRef]
- Zhang, F.; Wang, M.; Yang, M. Successful application of the Taguchi method to simulated soil erosion experiments at the slope scale under various conditions. CATENA 2021, 196, 104835. [Google Scholar] [CrossRef]
- Prakash, K.S.; Gopal, P.M.; Karthik, S. Multi-objective optimization using Taguchi based grey relational analysis in turning of Rock dust reinforced Aluminum MMC. Measurement 2020, 157, 107664. [Google Scholar] [CrossRef]
- Khalilarya, S.; Chitsaz, A.; Mojaver, P. Optimization of a combined heat and power system based gasification of municipal solid waste of Urmia University student dormitories via ANOVA and taguchi approaches. Int. J. Hydrogen Energy 2020. [Google Scholar] [CrossRef]
- Saarish, K.V.; Parvati, T.S. An anatomization of concrete elements with Taguchi optimization method. Case Mater. Today Proc. 2020. [Google Scholar] [CrossRef]
- Rathinam, N.; Dhinakaran, R.; Sharath, E. Optimizing process parameters to reduce blowholes in high pressure die casting using Taguchi methodology. Mater. Today Proc. 2020. [Google Scholar] [CrossRef]
- Mohd, U.; Pandulu, G.; Jayaseelan, R. Strength evaluation of eco-friendly concrete using Taguchi method. Mater. Today Proc. 2020, 22, 937–947. [Google Scholar] [CrossRef]
- Sharifi, E.; Sadjadi, S.J.; Aliha, M.R.M.; Moniri, A. Optimization of high-strength self-consolidating concrete mix design using and improved Taguchi optimization method. Constr. Build. Mater. 2020, 236, 117547. [Google Scholar] [CrossRef]
- Kechagias, J.D.; Aslani, K.-E.; Fountas, N.A.; Vaxevanidis, N.M.; Manolakos, D.E. A comparative investigation of Taguchi and full factorial design for machinability prediction in turning of titanium alloy. Measurement 2020, 151, 107213. [Google Scholar] [CrossRef]
- Tyagi, R.; Shama, P.; Nautiyal, R.; Lakhera, A.K.; Kumar, V. Sythesis of quaternised guargum using Taguchi L(16) orthogonal array. Carbohydr. Polym. 2020, 237, 116136. [Google Scholar] [CrossRef]
- Feng, G.; Lei, S.; Guo, Y.; Shi, D.; Shen, J.B. Optimisation of air-distributor channel structural parameters based on Taguchi orthogonal design. Case Stud. Therm. Eng. 2020, 21, 100685. [Google Scholar] [CrossRef]
- Wang, H.K.; Wang, Z.H.; Wang, M.C. Using the Taguchi method for optimization of the powder metallurgy forming process for Industry 3.5. Comput. Ind. Eng. 2020, 148, 106635. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Drucker, H.; Burges, C.J.C.; Kaufman, L.; Smola, A.; Vapnik, V. Support vector regression machines. In Proceedings of the 9th International Conference on Neural Information Processing Systems, Denver, CO, USA, 3–5 December 1996; pp. 155–161. [Google Scholar]
- Kõse, V.S.; Bayer, G. Bubble formation in the system waste glass-SiC and properties of such foam glasses. Glastech. Ber. 1982, 55, 151–160. [Google Scholar]
- NezhadShokouhi, M.M.; Majidi, M.A.; Rasoolzadegan, A. Software defect prediction using over‑sampling and feature extraction based on Mahalanobis distance. J. Supercomput. 2020, 76, 602–635. [Google Scholar] [CrossRef]
- Zhu, T.; Lin, Y.; Liu, Y. Improving interpolation-based oversampling for imbalanced data. Knowl. Based Syst. 2020, 187, 104826. [Google Scholar] [CrossRef]
- Liang, X.W.; Jiang, A.P.; Li, T.; Xue, Y.Y.; Wang, G.T. LR-SMOTE—An improved unbalanced data set oversampling based on K-means and SVM. Knowl. Based Syst. 2020, 196, 105845. [Google Scholar] [CrossRef]
- Maazinejad, B.; Mohammadnia, O.; Ali, G.A.M.; Makhlouf, A.S.H.; Nadagouda, M.N.; Sillanpää, M.; Asiri, A.M.; Agarwal, S.; Gupta, V.K.; Sadegh, H. Taguchi L9(34) orthogonal array study based on methylene blue removalby single-walled carbon nanotubes-amine: Adsorption optimizationusing the experimental design method, kinetics, equilibriumand thermodynamic. J. Mol. Liq. 2020, 298, 112001. [Google Scholar] [CrossRef]
- Akyalcin, S.; Akyalcin, L.; Bjørge, M. Optimization of desilication parameters of low-silica ZSM-12 by Taguchimetho. Microporous Mesoporous Mater. 2019, 273, 256–264. [Google Scholar] [CrossRef]
- Ayhan, V.; Cesur, Ç.Ç.I.; Çoban, A.; Ergen, G.; Çay, Y.; Kolip, A.; Özser, I. Optimization of the factors affecting performance and emissions in a dieselengine using biodiesel and EGR with Taguchi method. Fuel 2020, 261, 116371. [Google Scholar] [CrossRef]
- Chen, H.-J.; Chang, S.-N.; Tang, C.-W. Application of the Taguchi Method for Optimizing the Process Parameters of Producing Lightweight Aggregates by Incorporating Tile Grinding Sludge with Reservoir Sediments. Materials 2017, 10, 1294. [Google Scholar] [CrossRef] [Green Version]
- Burges, C.J. A Tutorial on Support Vector Machines for Pattern Recognition. Data Min. Knowl. Discov. 1998, 2, 121–167. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Process | Process Temp. (°C) | Variables | |
|---|---|---|---|
| Drying and preheating | 25 ~ 300 °C | 20, 40, 60 min | |
| 300 ~ 600 °C | 20, 40, 60 min | ||
| Calcination | 600 °C ~ B.S.A. temp. | 20, 40, 60 min | |
| Bloating Start and Activation (B.S.A.) | 1180, 1200, 1220 °C | Time | 0, 5, 10, 15, 20, 40 min |
| No. | Firing Condition | Single Particle Density (g/cm3) (mean) | ||||
|---|---|---|---|---|---|---|
| Sintering Time | B. S. A. Temp. (°C) | 600 ~ B.S.A. Temp. Process Time (min) | 300~600 °C Process Time (min) | r.t. ~ 300 °C Process Time (min) | ||
| 1 | 0 | 1180 | 20 | 20 | 20 | 2.09 |
| 2 | 0 | 1200 | 40 | 40 | 40 | 2.03 |
| 3 | 0 | 1220 | 60 | 60 | 60 | 1.76 |
| 4 | 5 | 1180 | 20 | 40 | 40 | 1.72 |
| 5 | 5 | 1200 | 40 | 60 | 60 | 1.49 |
| 6 | 5 | 1220 | 60 | 20 | 20 | 1.27 |
| 7 | 10 | 1180 | 40 | 20 | 60 | 1.84 |
| 8 | 10 | 1200 | 60 | 40 | 20 | 1.5 |
| 9 | 10 | 1220 | 20 | 60 | 40 | 0.98 |
| 10 | 15 | 1180 | 60 | 60 | 40 | 1.73 |
| 11 | 15 | 1200 | 20 | 20 | 60 | 1.13 |
| 12 | 15 | 1220 | 40 | 40 | 20 | 1 |
| 13 | 20 | 1180 | 40 | 60 | 20 | 1.57 |
| 14 | 20 | 1200 | 60 | 20 | 40 | 1.1 |
| 15 | 20 | 1220 | 20 | 40 | 60 | 0.88 |
| 16 | 40 | 1180 | 60 | 40 | 60 | 1.46 |
| 17 | 40 | 1200 | 20 | 60 | 20 | 0.94 |
| 18 | 40 | 1220 | 40 | 20 | 40 | 0.95 |
| Linear Regression | Random Forest | SVR | |
|---|---|---|---|
| 0.799 | 0.783 | 0.933 | |
| MSE | 0.029 | 0.031 | 0.009 |
| RMSE | 0.171 | 0.178 | 0.098 |
| MAE | 0.146 | 0.143 | 0.071 |
| Process | Process Temp. (°C) | Variables | |
|---|---|---|---|
| Drying and preheating | 25~300 °C | 60 min Fixed | |
| 300~600 °C | 60 min Fixed | ||
| Calcination | 600 °C ~ B.S.A. temp. | 20 min Fixed | |
| Bloating Start and Activation (B.S.A.) | 1180, 1190, 1200, 1210, 1220 °C | Time | 0, 5, 10, 15, 20, 40 min |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wie, Y.M.; Lee, K.G.; Lee, K.H.; Ko, T.; Lee, K.H. The Experimental Process Design of Artificial Lightweight Aggregates Using an Orthogonal Array Table and Analysis by Machine Learning. Materials 2020, 13, 5570. https://doi.org/10.3390/ma13235570
Wie YM, Lee KG, Lee KH, Ko T, Lee KH. The Experimental Process Design of Artificial Lightweight Aggregates Using an Orthogonal Array Table and Analysis by Machine Learning. Materials. 2020; 13(23):5570. https://doi.org/10.3390/ma13235570
Chicago/Turabian StyleWie, Young Min, Ki Gang Lee, Kang Hyuck Lee, Taehoon Ko, and Kang Hoon Lee. 2020. "The Experimental Process Design of Artificial Lightweight Aggregates Using an Orthogonal Array Table and Analysis by Machine Learning" Materials 13, no. 23: 5570. https://doi.org/10.3390/ma13235570