
Classification of Highly Imbalanced Supervisory Control and Data Acquisition Data for Fault Detection of Wind Turbine Generators

 , , , and
, , , and
Abstract
:1. Introduction
- We carried out an exhaustive analysis of the SCADA operating data and alarms. In the case of operational data, their high sampling frequency allowed us to better observe the behavior patterns in the variables of interest.
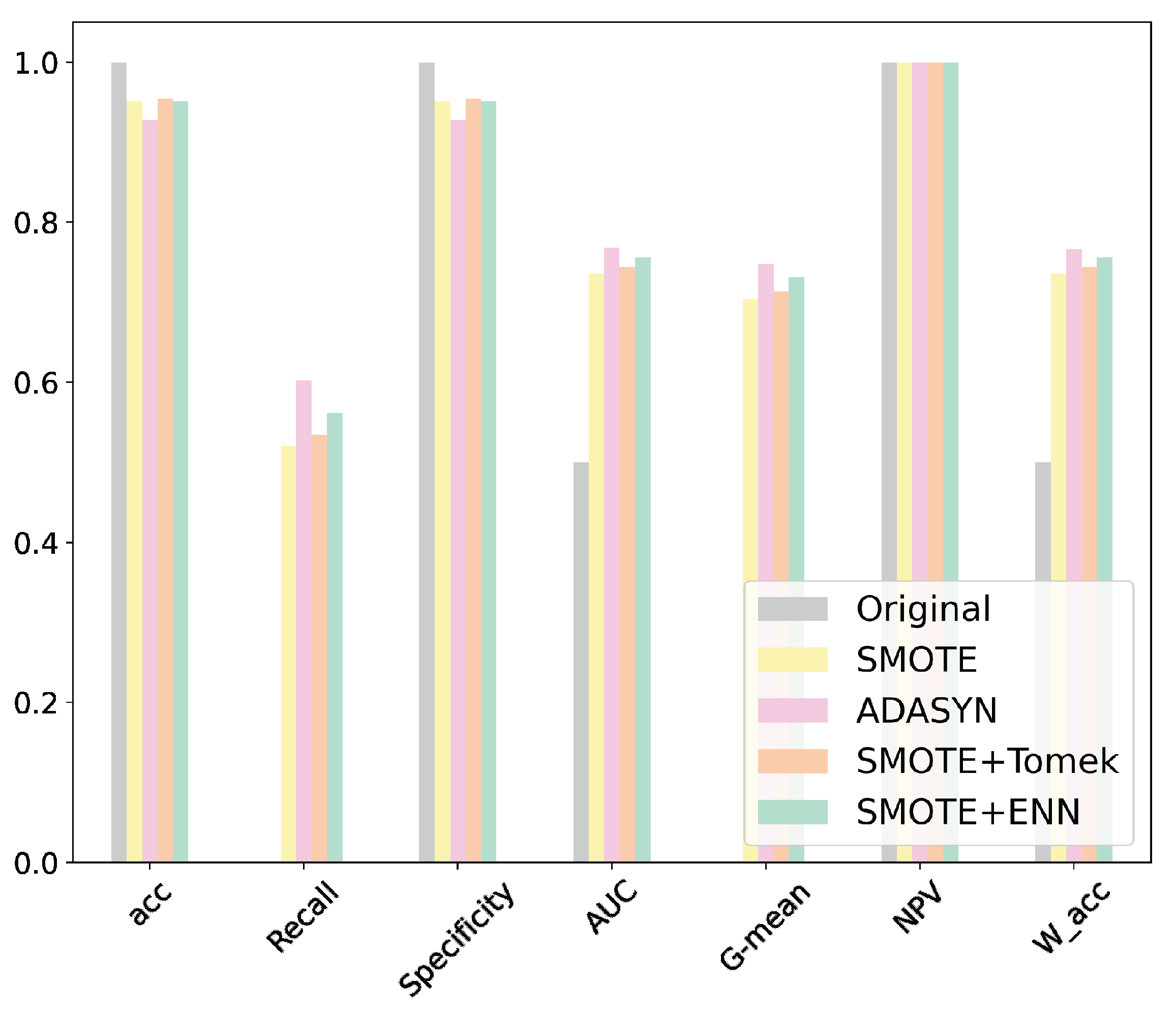
- We used different resampling techniques to analyze our dataset, which is characterized by a severe imbalance between classes (normal and faults), with an approximate imbalance rate of 10,000:1. To reduce the classification bias of the data toward the majority class, the data were resampled in the training set with different oversampling methods.
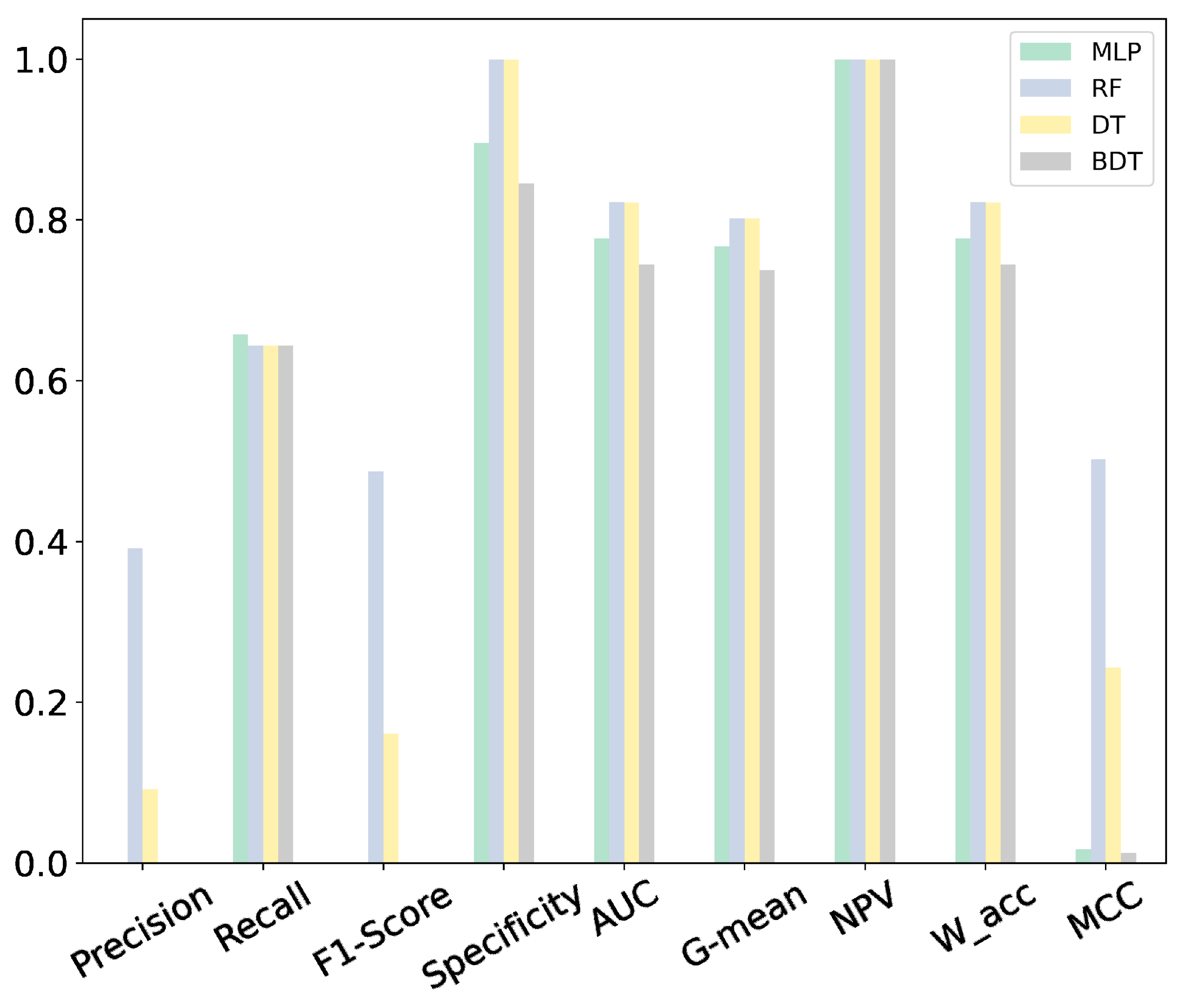
- Using different metrics, we compared the performance of four binary classification algorithms. We tried to use evaluation metrics that measure the overall performance of the classification algorithms without solely focusing on one particular class.
2. State of the Art and Motivation
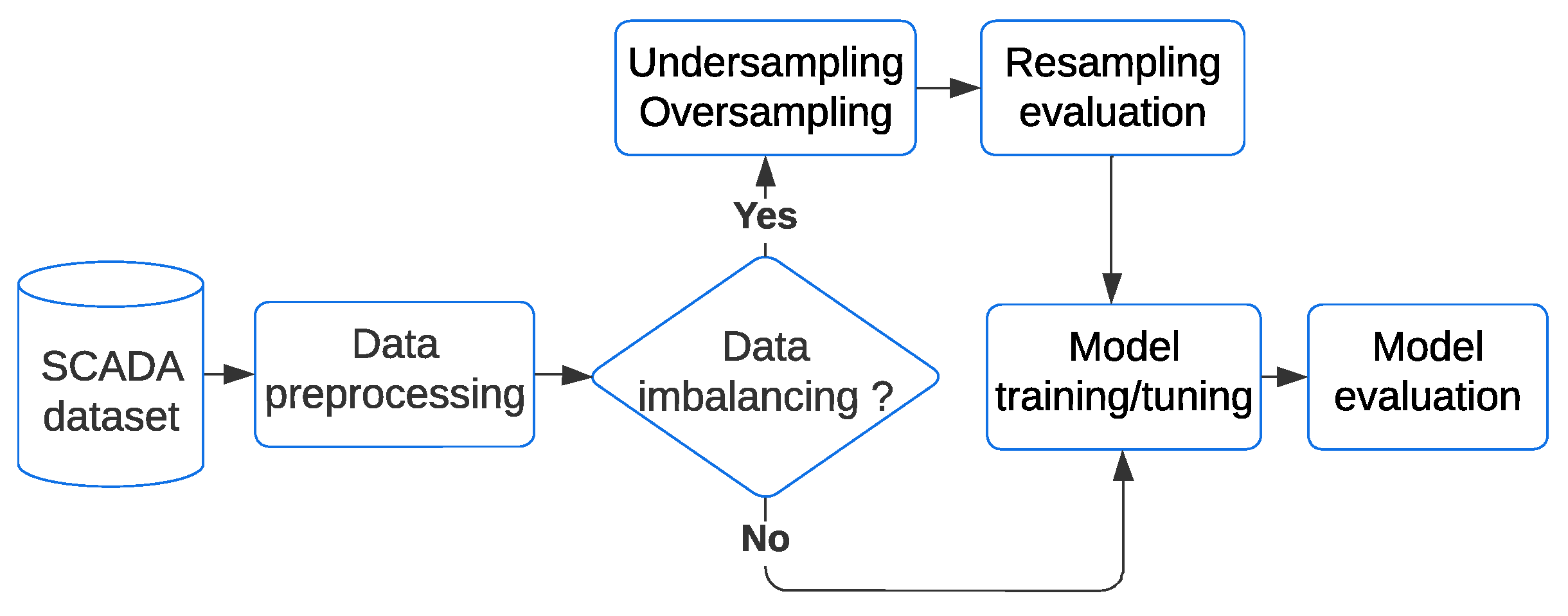
3. Materials and Methods
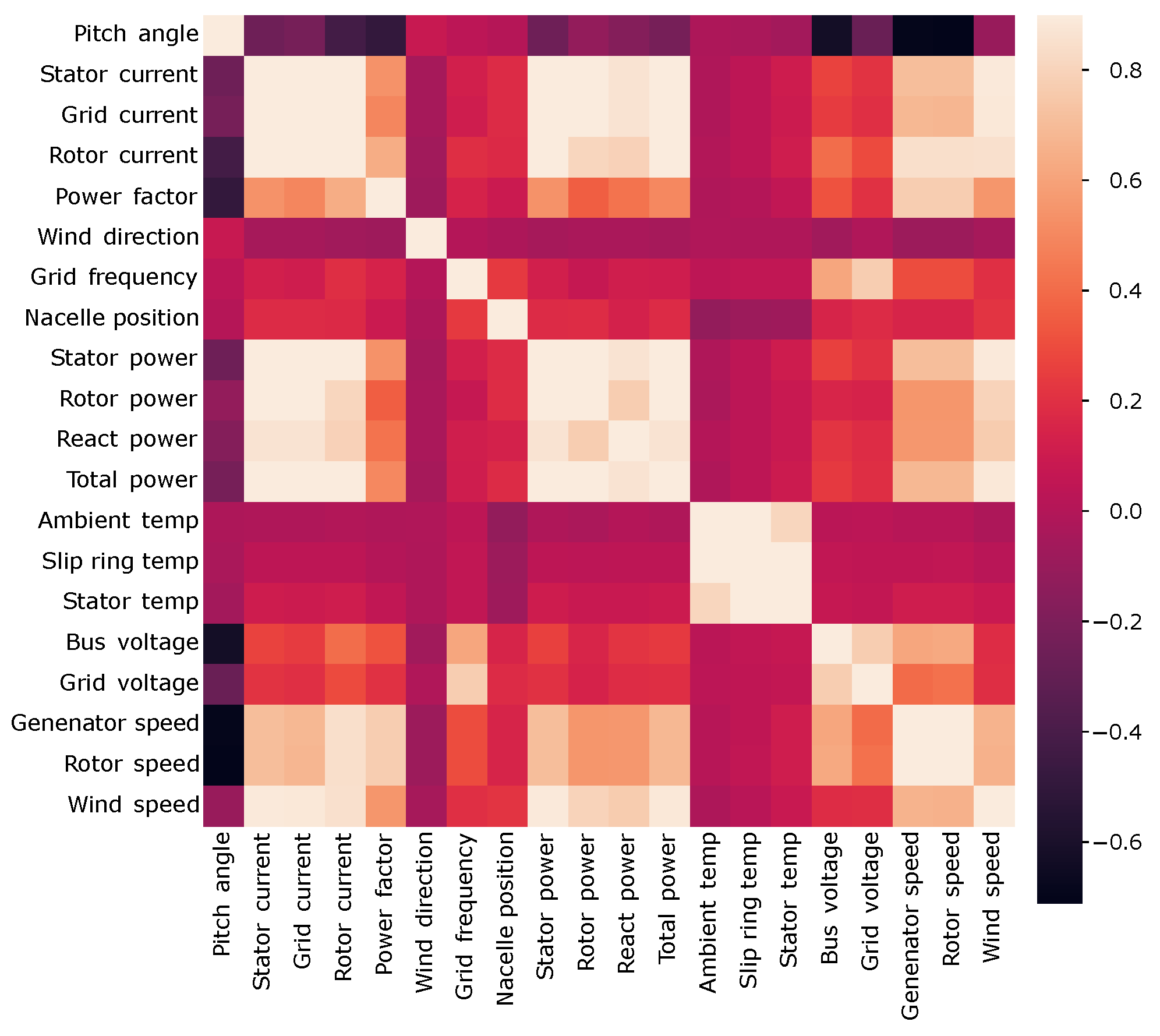
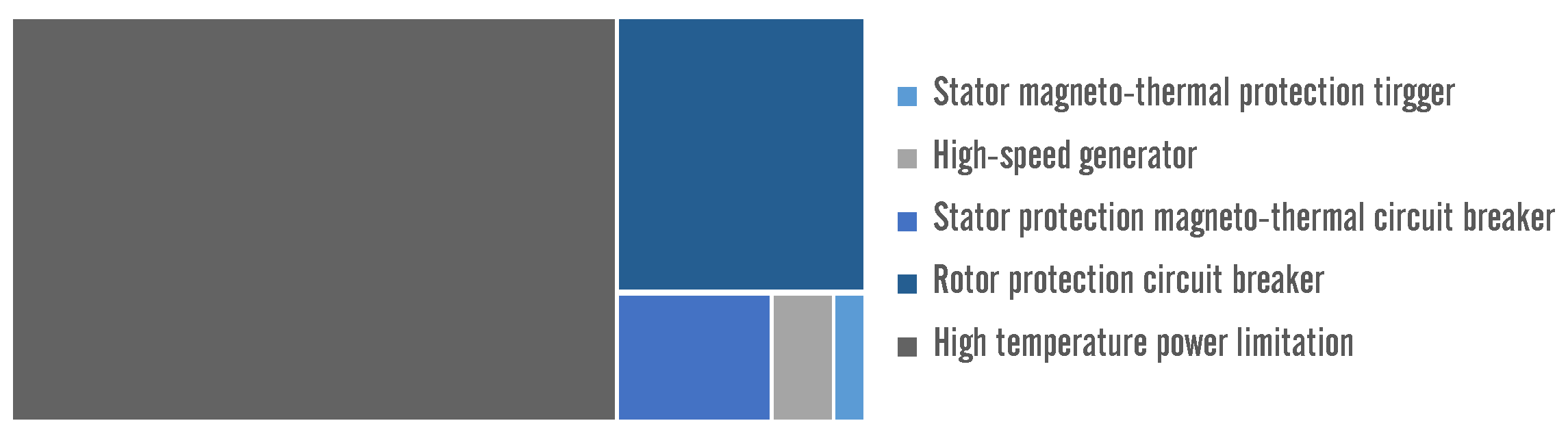
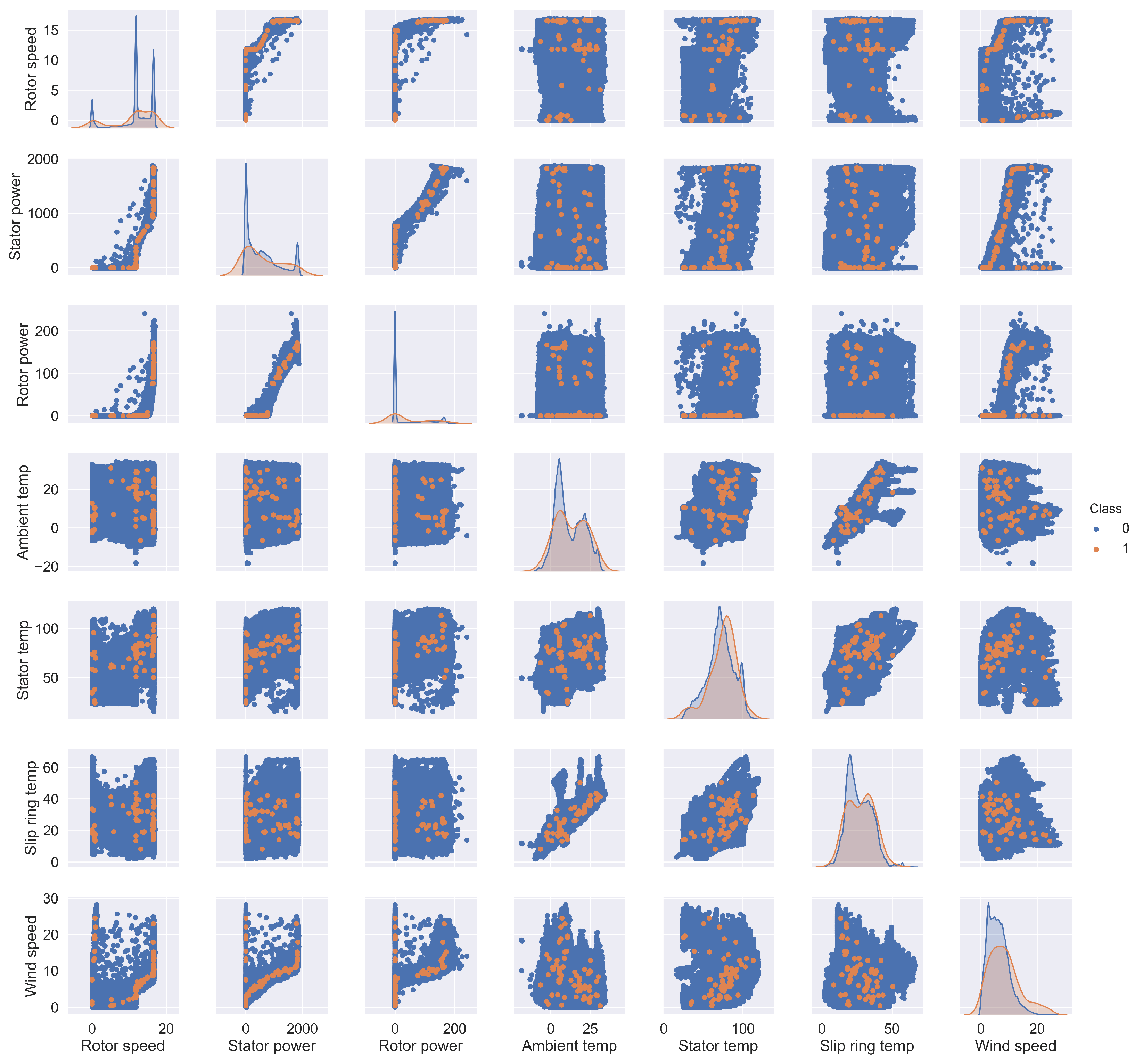
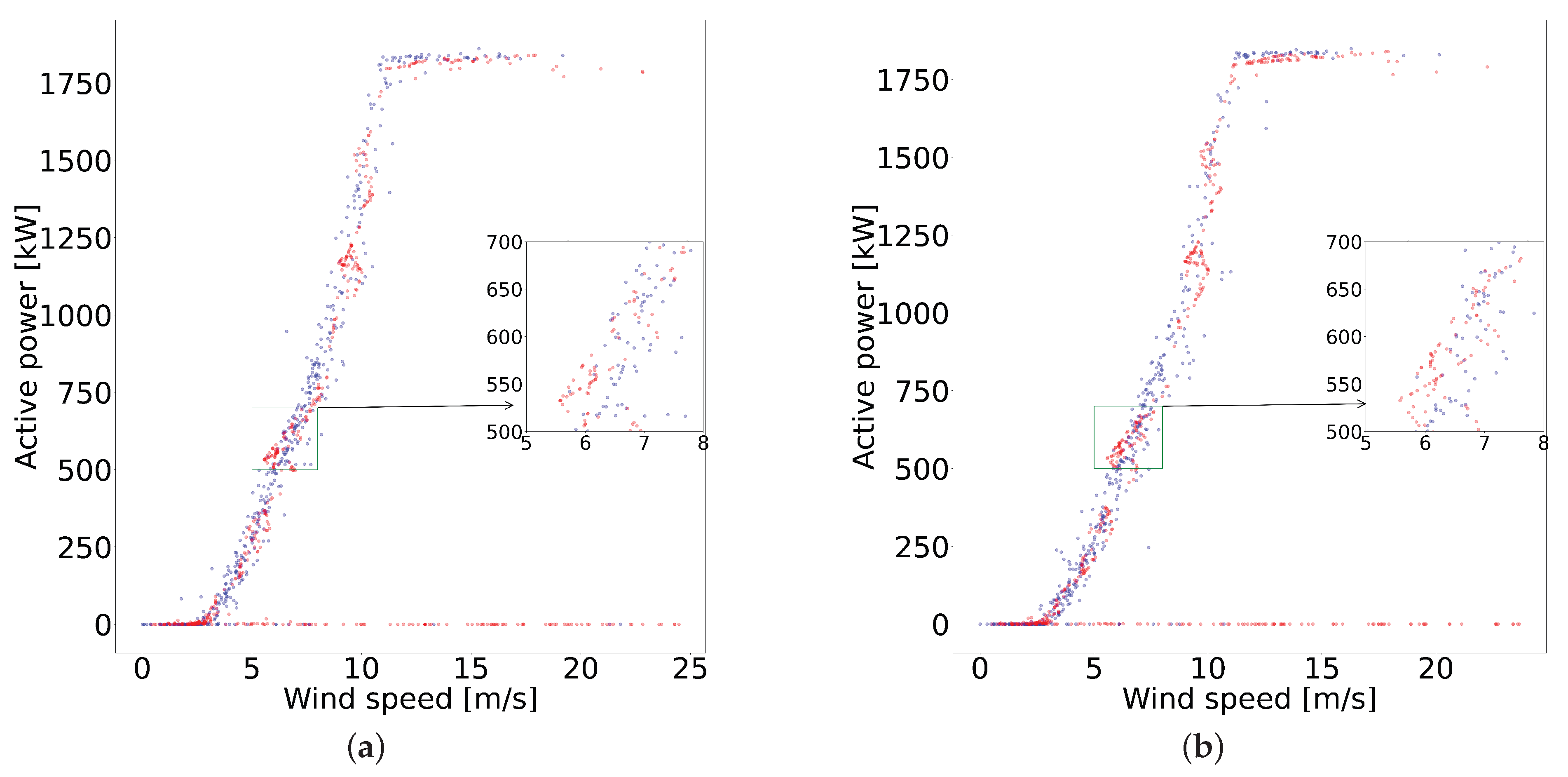
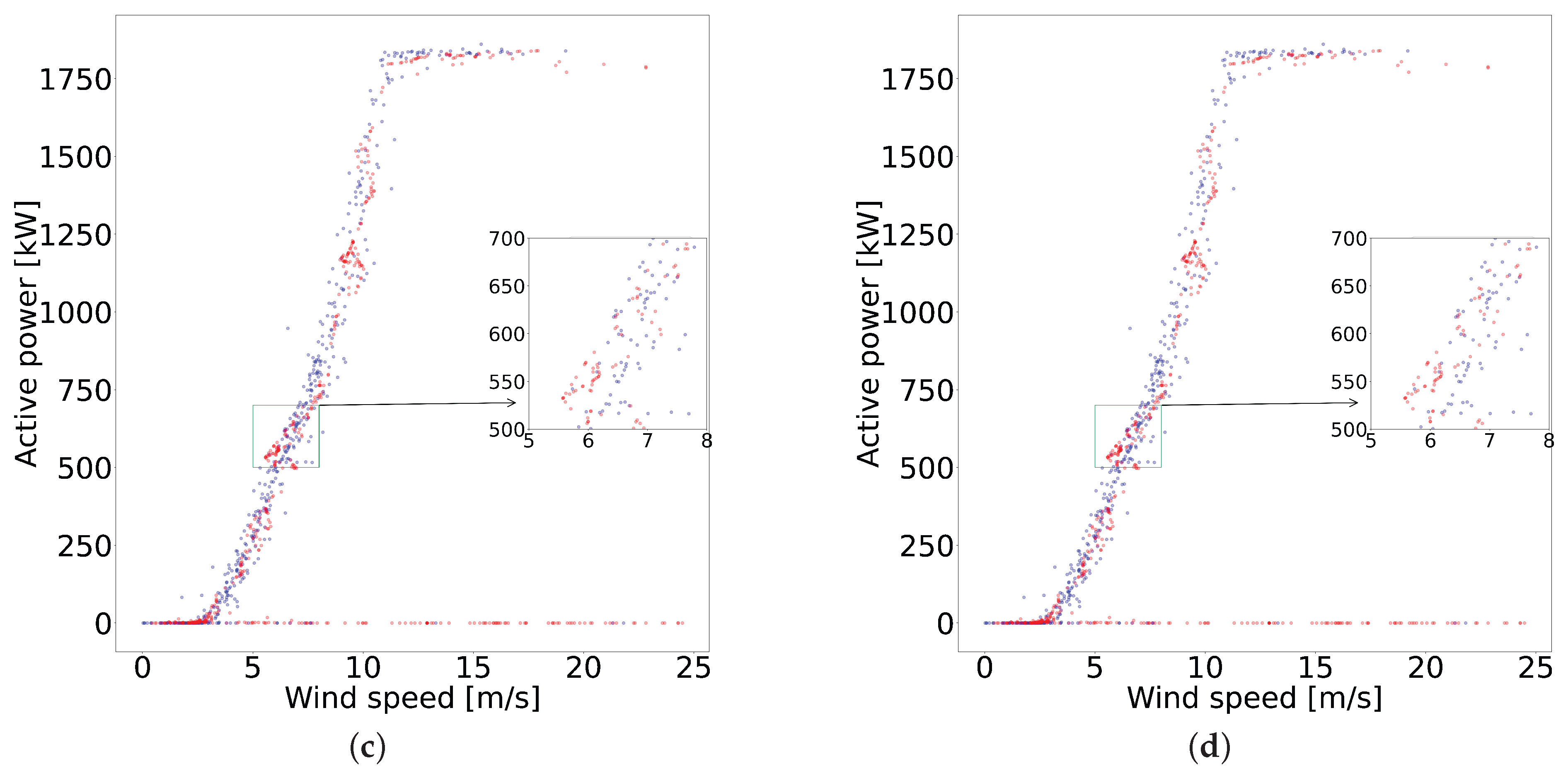
3.1. Data Description
3.2. Methods to Balance the Class Distribution
- First, the number of synthetic data examples that need to be generated for the minority class is determined:where represents the number of minority class examples, represents the number of majority class examples, and is used to specify the balance level after the generation of the synthetic data, being between [0,1].
- Afterward, for each example, the minority class , finds k-nearest neighbors based on the Euclidean distance in n dimensional space, and calculates the ratio defined aswhere represents the number of examples in the k-nearest neighbors of , associated with the predominant class.
- Then, normalize the ratio according towhere represents the density distribution, and .
- Finally, the number of synthetic data instances that must be developed is calculated for each :
- The nearest neighbor sample for each minority class sample is found.
- Random samples to interpolate are chosen among the nearest neighbor samples.
- The original minority class samples and their neighbor samples are linearly interpolated. The synthetic sample is generated bywhere represents the original samples used to obtain the new samples, is a random number from 0 to 1, which guarantees that is on the line joining the original data and one of its nearest neighbors, and represents a randomly selected sample among the minority class samples.
3.3. ML Methods for Fault Detection
- Random Forest (RF). Proposed by Leo Breiman in 2001 [37], this is a supervised learning algorithm used for classification or regression problems, which works by building many decision trees, where each tree yields a class prediction, and the class with the most votes becomes the model prediction [38]. The general RF classifier pseudocode used in this study is shown in Algorithm 1.
- Decision Trees (DTs). Non-parametric algorithms obtained from a set of learning cases, labeled by class and attribute values. This prediction algorithm is suitable for regression and classification problems, although it can be highly unstable, and overtraining should be avoided [39]. Algorithm 2 shows the pseudocode of the DT classifier.
- Multilayer Perceptron (MLP). ANNs are applied to a sequence of time series forecasting problems. These have an input layer, one or more hidden layers, and an output layer [40]. The advantages of MLP include the ability to withstand elevated levels of noise in the input data and to learn independently of the linear and nonlinear relationships existing in the variables under study.For the binary classification problem, the MLP can be described aswhere denotes the weights associated with the neuron, are its inputs, b is the bias, and is the transfer or activation function.
| Algorithm 1: Random Forest Classifier |
 |
| Algorithm 2: Decision Tree Classifier |
 |
- The MLP structure used in this study consists of four hidden layers in addition to the input and output layers. The activation functions of the hidden layers are rectified linear unit (ReLU) and Sigmoid for the output layer. In addition, in the first hidden layer, a dropout rate equal to 0.5 was applied to avoid the model overfitting problems. The MLP pseudocode is shown in Algorithm 3.
- Boosting Decision Tree (BDT). In this algorithm, each tree depends on the previous trees (boosting). Therefore, each tree has information about the errors made by the previous one, thus helping to refine the result [10]. The pseudocode for the BDT classifier employed in this study is presented in Algorithm 4.
| Algorithm 3: Multilayer Perceptron Classifier |
 |
| Algorithm 4: Boosting with Decision Trees Classifier |
 |
3.4. Metrics Used to Quantify the Prediction Accuracy
- Acc: The total percentage of correctly classified elements is given by the total number of correct predictions divided by the total number of m predictions (Equation (7)).
- Recall: Known as True Positive Rate, this is the percentage of positive instances correctly classified, i.e., the ability of the model to predict the class correctly, as shown in Equation (8). Recall is useful for failure prediction as it effectively measures the minority class prediction coverage [13].
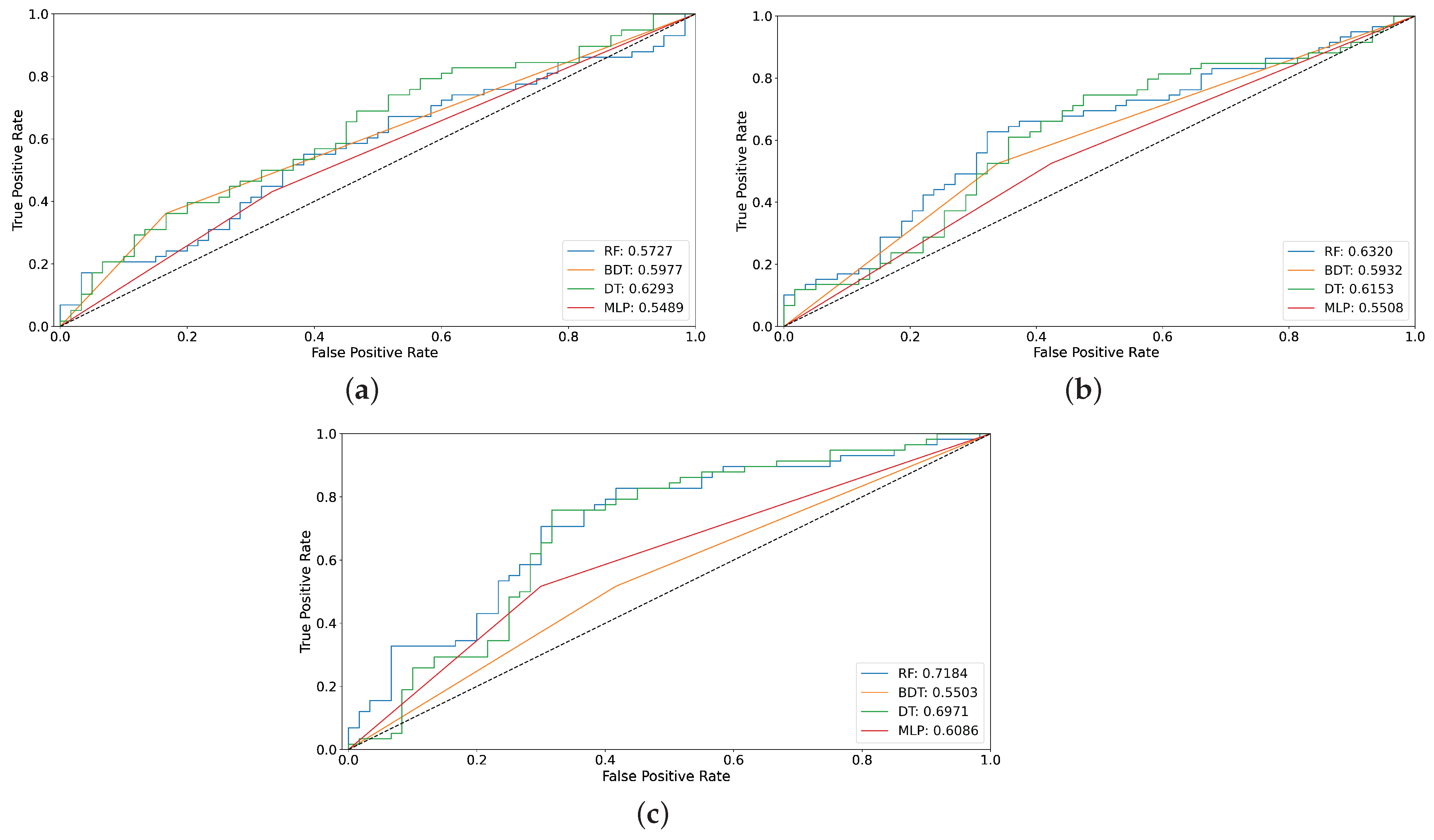
- AUC: This metric represents the area under the ROC curve. The ROC (Receiver Operating Characteristic) curve is a graph that shows the performance of a classification model. The graph represents the distribution of the True Positive Rate on the y-axis versus the False Positive Rate on the x-axis.
- F1-Score: This is a metric for quantifying model performance. It is useful for imbalanced data because it attempts to find the balance between precision and recall [36]. The F1-Score measure is calculated as follows:
- G-mean: This evaluates the performance of the majority and minority classes compared to each other. Although negative cases are successfully classified, a low G-mean suggests poor performance in classifying positive cases [9]. G-mean can be calculated as follows:
- NPV: This is the ratio of properly categorized negative class labels to the total number of predicted negative labels [13]. The formula for this metric is given by
- W_acc: This is the average of the recall and specificity (Equation (15)), and measures the average accuracy of both minority and majority classes. If a classifier performs equally well on both classes, this number drops to the traditional accuracy. In contrast, if the high value of traditional accuracy is due to the classifier exploiting the majority class distribution, the balanced accuracy will be lower than the accuracy [21].
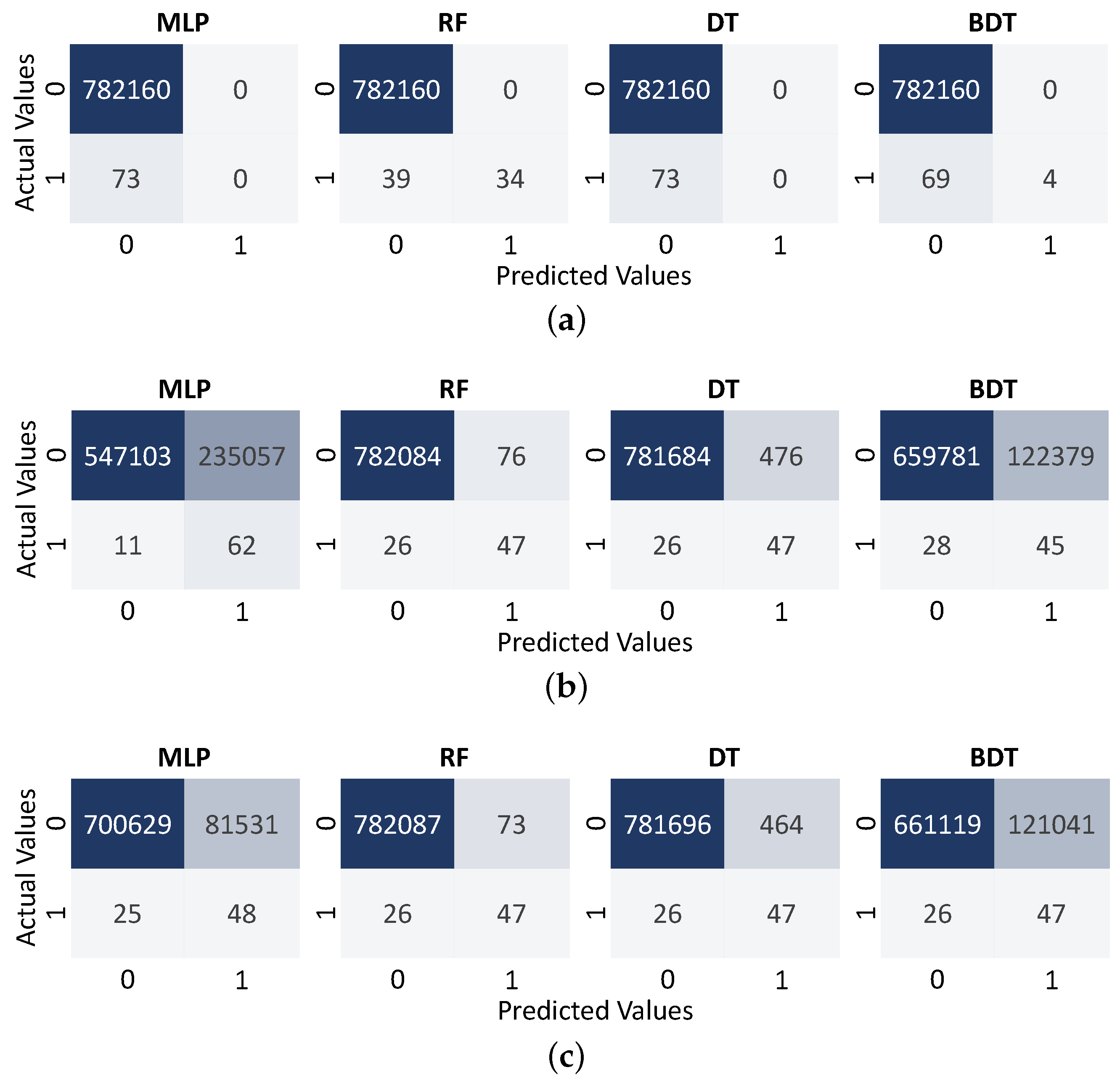
4. Results
4.1. Data Resampling
4.2. Performance of Classification Algorithms
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| SMOTE | Synthetic Minority Oversampling Technique |
| MC-SMOTE | Minority Clustering SMOTE |
| RF | Random Forest |
| kNN | k-Nearest Neighbor |
| SC-SMOTE | Safe Circle SMOTE |
| DNNs | Deep Neural Networks |
| STMNN | Spatio-Temporal Multiscale Neural Network |
| FL | Focal Loss |
| SDWBOTE | Synthetic and Dependent Wild Bootstrapped Oversampling Technique |
| CNNs | Convolutional Neural Networks |
| SVCs | Support Vector Classifiers |
| DTs | Decision Trees |
| TL | Transfer Learning |
| ANNs | Artificial Neural Networks |
| ADASYN | Adaptive Synthetic Sampling |
| MLP | Multi-Layer Perceptron |
| BDT | Boosting Decision Tree |
| CM | Condition monitoring |
| AUC | Area Under Curve |
| acc | Accuracy |
| G-mean | Geometric mean |
| MCC | Matthews Correlation Coefficient |
| TP | True positives |
| TN | True negatives |
| FP | False positives |
| FN | False negatives |
| ROC | Receiver Operating Characteristic |
| NPV | Negative Predictive Value |
| W_acc | Weighted accuracy |
| Nomenclature | |
| G | Number of examples synthetic data to be generated |
| Number of minority class examples | |
| Number of majority class examples | |
| Balance level after the generation of the synthetic data | |
| Examples of the minority class | |
| n | Dimensional space |
| Majority class ratio within k-nearest minority neighbors | |
| k | Number of nearest neighbors |
| Number of examples in the k-nearest neighbors of | |
| Density distribution | |
| Number of synthetic data instances to generate for each | |
| Synthetic sample to be generated | |
| Original samples | |
| Randomly selected sample among the minority class samples | |
| Weights associated with the neuron | |
| Input vector | |
| b | Bias |
| Transfer or activation function | |
| m | Total number of predictions |
References
- Global Wind Energy Council GWEC. Global Wind Report 2023; Technical report; Global Wind Energy Council GWEC: Lisbon, Portugal, 2023. [Google Scholar]
- Khanafer, M.; Shirmohammadi, S. Applied AI in instrumentation and measurement: The deep learning revolution. IEEE Instrum. Meas. Mag. 2020, 23, 10–17. [Google Scholar] [CrossRef]
- Blanco, M.A.; Gibert, K.; Marti-Puig, P.; Cusidó, J.; Solé-Casals, J. Identifying health status of wind turbines by using self organizing maps and interpretation-oriented post-processing tools. Energies 2018, 11, 723. [Google Scholar] [CrossRef]
- Chen, L.; Xu, G.; Zhang, Q.; Zhang, X. Learning deep representation of imbalanced SCADA data for fault detection of wind turbines. Measurement 2019, 139, 370–379. [Google Scholar] [CrossRef]
- Maldonado-Correa, J.; Martín-Martínez, S.; Artigao, E.; Gómez-Lázaro, E. Using SCADA Data for Wind Turbine Condition Monitoring: A Systematic Literature Review. Energies 2020, 13, 3132. [Google Scholar] [CrossRef]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic Minority Over-sampling Technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Zhang, T.; Chen, J.; Li, F.; Zhang, K.; Lv, H.; He, S.; Xu, E. Intelligent fault diagnosis of machines with small & imbalanced data: A state-of-the-art review and possible extensions. ISA Trans. 2022, 119, 152–171. [Google Scholar] [CrossRef] [PubMed]
- Chen, H.; Hsu, J.Y.; Hsieh, J.Y.; Hsu, H.Y.; Chang, C.H.; Lin, Y.J. Predictive maintenance of abnormal wind turbine events by using machine learning based on condition monitoring for anomaly detection. J. Mech. Sci. Technol. 2021, 35, 5323–5333. [Google Scholar] [CrossRef]
- Yi, H.; Jiang, Q.; Yan, X.; Wang, B. Imbalanced Classification Based Minority Clustering Synthetic Minority Oversampling Technique with Wind Turbine Fault Detection Application. IEEE Trans. Ind. Inform. 2020, 17, 5867–5875. [Google Scholar] [CrossRef]
- Wu, Z.; Lin, W.; Ji, Y. An Integrated Ensemble Learning Model for Imbalanced Fault Diagnostics and Prognostics. IEEE Access 2018, 6, 8394–8402. [Google Scholar] [CrossRef]
- Ge, Y.; Yue, D.; Chen, L. Prediction of wind turbine blades icing based on MBK-SMOTE and random forest in imbalanced data set. In Proceedings of the 2017 IEEE Conference on Energy Internet and Energy System Integration (EI2), Beijing, China, 26–28 November 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Peng, C.; Chen, Q.; Zhang, L.; Wan, L.; Yuan, X. Research on Fault Diagnosis of Wind Power Generator Blade Based on SC-SMOTE and kNN. J. Inf. Process. Syst. 2020, 16, 870–881. [Google Scholar] [CrossRef]
- Velandia-Cardenas, C.; Vidal, Y.; Pozo, F. Wind Turbine Fault Detection Using Highly Imbalanced Real SCADA Data. Energies 2021, 14, 1728. [Google Scholar] [CrossRef]
- He, Q.; Pang, Y.; Jiang, G.; Xie, P. A Spatio-Temporal Multiscale Neural Network Approach for Wind Turbine Fault Diagnosis With Imbalanced SCADA Data. IEEE Trans. Ind. Inform. 2021, 17, 6875–6884. [Google Scholar] [CrossRef]
- Jiang, N.; Li, N. A wind turbine frequent principal fault detection and localization approach with imbalanced data using an improved synthetic oversampling technique. Int. J. Electr. Power Energy Syst. 2021, 126, 106595. [Google Scholar] [CrossRef]
- Karadayi, B.; Kuvvetli, Y.; Ural, S. Fault-related Alarm Detection of a Wind Turbine SCADA System. In Proceedings of the 2021 3rd International Congress on Human-Computer Interaction, Optimization and Robotic Applications (HORA), Ankara, Turkey, 11–13 June 2021; pp. 1–5. [Google Scholar] [CrossRef]
- Santos, P.; Maudes, J.; Bustillo, A. Identifying maximum imbalance in datasets for fault diagnosis of gearboxes. J. Intell. Manuf. 2018, 29, 333–351. [Google Scholar] [CrossRef]
- Zhang, Y.; Liu, B.; Wang, C. A Fault Diagnosis Method for Electrical Equipment With Imbalanced SCADA Data Based on SMOTE Oversampling and Domain Adaptation. In Proceedings of the 2023 8th International Conference on Power and Renewable Energy (ICPRE), Shanghai, China, 22–25 September 2023; pp. 195–202. [Google Scholar] [CrossRef]
- Santolamazza, A.; Dadi, D.; Introna, V. A Data-Mining Approach for Wind Turbine Fault Detection Based on SCADA Data Analysis Using Artificial Neural Networks. Energies 2021, 14, 1845. [Google Scholar] [CrossRef]
- Xiao, C.; Liu, Z.; Zhang, T.; Zhang, X. Deep Learning Method for Fault Detection of Wind Turbine Converter. Appl. Sci. 2021, 11, 1280. [Google Scholar] [CrossRef]
- Chen, W.; Qiu, Y.; Feng, Y.; Li, Y.; Kusiak, A. Diagnosis of wind turbine faults with transfer learning algorithms. Renew. Energy 2021, 163, 2053–2067. [Google Scholar] [CrossRef]
- Liu, X.; Du, J.; Ye, Z.S. A Condition Monitoring and Fault Isolation System for Wind Turbine Based on SCADA Data. IEEE Trans. Ind. Inform. 2022, 18, 986–995. [Google Scholar] [CrossRef]
- Zhao, Y.; Li, D.; Dong, A.; Kang, D.; Lv, Q.; Shang, L. Fault prediction and diagnosis of wind turbine generators using SCADA data. Energies 2017, 10, 1210. [Google Scholar] [CrossRef]
- Chatterjee, J.; Dethlefs, N. Scientometric review of artificial intelligence for operations & maintenance of wind turbines: The past, present and future. Renew. Sustain. Energy Rev. 2021, 144, 111051. [Google Scholar]
- Li, B.; Tang, B.; Deng, L.; Wei, J. Joint attention feature transfer network for gearbox fault diagnosis with imbalanced data. Mech. Syst. Signal Process. 2022, 176, 109146. [Google Scholar] [CrossRef]
- Chatterjee, J.; Dethlefs, N. Deep learning with knowledge transfer for explainable anomaly prediction in wind turbines. Wind Energy 2020, 23, 1693–1710. [Google Scholar] [CrossRef]
- Tang, M.; Meng, C.; Wu, H.; Zhu, H.; Yi, J.; Tang, J.; Wang, Y. Fault Detection for Wind Turbine Blade Bolts Based on GSG Combined with CS-LightGBM. Sensors 2022, 22, 6763. [Google Scholar] [CrossRef] [PubMed]
- Desai, A.; Guo, Y.; Sheng, S.; Sheng, S.; Phillips, C.; Williams, L. Prognosis of Wind Turbine Gearbox Bearing Failures using SCADA and Modeled Data. Annu. Conf. PHM Soc. 2020, 12, 10. [Google Scholar] [CrossRef]
- Zhang, G.; Li, Y.; Jiang, W.; Shu, L. A fault diagnosis method for wind turbines with limited labeled data based on balanced joint adaptive network. Neurocomputing 2022, 481, 133–153. [Google Scholar] [CrossRef]
- Chatterjee, S.; Byun, Y.C. Highly imbalanced fault classification of wind turbines using data resampling and hybrid ensemble method approach. Eng. Appl. Artif. Intell. 2023, 126, 107104. [Google Scholar] [CrossRef]
- Sun, S.; Hu, W.; Liu, Y.; Wang, T.; Chu, F. Matching contrastive learning: An effective and intelligent method for wind turbine fault diagnosis with imbalanced SCADA data. Expert Syst. Appl. 2023, 223, 119891. [Google Scholar] [CrossRef]
- Qian, M.; Li, Y.F. A Weakly Supervised Learning-Based Oversampling Framework for Class-Imbalanced Fault Diagnosis. IEEE Trans. Reliab. 2022, 71, 429–442. [Google Scholar] [CrossRef]
- Qiu, Y.; Feng, Y.; Infield, D. Fault diagnosis of wind turbine with SCADA alarms based multidimensional information processing method. Renew. Energy 2020, 145, 1923–1931. [Google Scholar] [CrossRef]
- Nunes, A.R.; Morais, H.; Sardinha, A. Use of Learning Mechanisms to Improve the Condition Monitoring of Wind Turbine Generators: A Review. Energies 2021, 14, 7129. [Google Scholar] [CrossRef]
- Elreedy, D.; Atiya, A.F. A Comprehensive Analysis of Synthetic Minority Oversampling Technique (SMOTE) for handling class imbalance. Inf. Sci. 2019, 505, 32–64. [Google Scholar] [CrossRef]
- He, H.; Bai, Y.; Garcia, E.A.; Li, S. ADASYN: Adaptive synthetic sampling approach for imbalanced learning. In Proceedings of the 2008 IEEE International Joint Conference on Neural Networks (IEEE World Congress on Computational Intelligence), Hong Kong, 1–8 June 2008; pp. 1322–1328. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Zhang, D.; Qian, L.; Mao, B.; Huang, C.; Huang, B.; Si, Y. A Data-Driven Design for Fault Detection of Wind Turbines Using Random Forests and XGboost. IEEE Access 2018, 6, 21020–21031. [Google Scholar] [CrossRef]
- Peco Chacón, A.M.; Segovia Ramírez, I.; García Márquez, F.P. State of the Art of Artificial Intelligence Applied for False Alarms in Wind Turbines. Arch. Comput. Methods Eng. 2021, 29, 2659–2683. [Google Scholar] [CrossRef]
- Helbing, G.; Ritter, M. Deep Learning for fault detection in wind turbines. Renew. Sustain. Energy Rev. 2018, 98, 189–198. [Google Scholar] [CrossRef]
- Ahakonye, L.A.C.; Nwakanma, C.I.; Lee, J.M.; Kim, D.S. SCADA intrusion detection scheme exploiting the fusion of modified decision tree and Chi-square feature selection. Internet Things 2023, 21, 100676. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref. and Year | TDID 1 | Learning Algorithms | Tools/ Methods | Main Components | Results |
|---|---|---|---|---|---|
| [4] 2019 | Triplet loss function | classification | DNN, kNN | blade | 90.85% (precision), 63.10% (recall), 74.47% (F1-Score) |
| [7] 2021 | SMOTE | classification | GANs 2, DNN, SVM 3 | WT | not specified |
| [8] 2021 | SMOTE | classification | DNN, SVM 3, RF, kNN | WT | >90% (precision) |
| [9] 2020 | MC-SMOTE | classification, clustering | SVM 3, CART 4, Bayesian classifiers | blade | 91.70% (precision), 92.10% (recall), 91.90% (F1-Score) |
| [10] 2018 | SMOTE | classification | RF, GBDT 5, XGBoost 6 | WT | 86.82% (precision), 96.50% (recall), 91.49% (F1-Score) |
| [11] 2017 | MBK-SMOTE | classification, clustering | K-means, RF | blade | 54.00% F1-Score), 74.85% (AUC) |
| [12] 2020 | SC-SMOTE | classification | kNN | blade | 78.90% (acc) |
| [13] 2021 | Random oversampling, data reshaping | classification | kNN, SVM 3, RUSBoost 7 | gearbox | 99.82% (recall), 95.48% (F1-Score), 95.36% (acc) |
| [14] 2021 | FL function | classification | STMNN, LSTM 8, CNN | WT | 94.70% (F1-Score), 90.10% (G-mean) |
| [15] 2021 | SDWBOTE | classification | CNN | WT | 97.51% (F1-Score) |
| [16] 2021 | SMOTE | classification | SVC, DT | WT | 80.00% (precision), 83.00% (recall), 81.00% (F1-Score), 87.00% (acc) |
| [17] 2018 | SMOTE, undersampling, cost-sensitive learning | classification | MLP 9, Naive Bayes, kNN, DT, Bagging, Rotation Forest | gearbox | 85.00% (MCC) |
| [18] 2023 | SMOTE | classification | CNN, ResNet 10 | gearbox, generator bearing, hydraulic system | >75.00% (recall), >51.43% (F1-Score) |
| [20] 2021 | Upsampling operations | classification | CNN | converter | 98.41% (precision), 97.66% (recall), 98.04% (acc) |
| [21] 2021 | Re-sampling | classification | kNN, RF, TrAdaBoost 11, Inception V3 | blade, pitch system | >73.20% (recall), >89.40% (acc) |
| [23] 2017 | SMOTE | classification | ANN, SVM 3, KNN, Naive Bayes | generator | 96.34% (recall), 94.80% (acc) |
| [25] 2022 | SMOTE, FL function, re-sampling | classification | GANs 2, JAFTN 12, WDCNN 13 | gearbox | 99.70% (precision), 99.60% (F1-Score), 99.60% (acc) |
| [26] 2020 | SMOTE | classification, clustering | LSTM 8, XGBoost 6 | WT | 97.00% (acc) |
| [27] 2022 | SMOTE, cost-sensitive learning | classification | LGBM 14, GMM 15 | blade | 97.80% (F1-Score) |
| [28] 2020 | SMOTE, cost-sensitive learning | classification | Logistic regression, RF, XGBoost 6, LSTM 8 | gearbox | 52.00% (precision), 86.00% (recall), 57.00% (F1-Score) |
| [29] 2022 | SMOTE | classification | LSTM 8, CNN, MLP 9 | hydraulic system, generator, converter | >80.20% (F1-Score), >90.60% (acc) |
| [30] 2023 | SMOTE+ENN | classification | DT, AdaBoost 16, KNN, RF | WT | 99.60% (precision), 99.20% (recall), 99.60% (F1-Score) |
| [31] 2023 | SMOTE, Adasyn | classification | MCL 17, STMNN, STFNN 18 | WT | 94.70% (F1-Score) |
| [32] 2022 | SMOTE, Adasyn, SMOTE+ENN | classification | DT, KNN, SVM 3, MLP 9 | blade | 94.20% (F1-Score), 94.20% (G-mean), 93.80% (MCC) |
| Hyperparameter | Value | Description |
|---|---|---|
| max_depth | 5 | Maximum Tree Depth |
| min_samples_split | 2 | Minimum number of samples to split node |
| min_samples_leaf | 1 | Minimum number of samples in a leaf |
| max_features | None | Maximum number of characteristics |
| criterion | gini | Measure of the quality of a node split |
| MLP | ||||||||||
| hidden_layer sizes | alpha | Precision | Recall | F1-Score | Specificity | AUC | G-mean | NVP | W_acc | MCC |
| 100 | 0.0001 | 0.000 | 0.150 | 0.001 | 0.766 | 0.610 | 0.481 | 0.989 | 0.558 | 0.016 |
| 100 | 0.001 | 0.000 | 0.200 | 0.001 | 0.762 | 0.571 | 0.639 | 0.989 | 0.581 | 0.021 |
| 100 | 0.01 | 0.001 | 0.625 | 0.001 | 0.895 | 0.771 | 0.769 | 0.999 | 0.775 | 0.024 |
| (50, 50) | 0.0001 | 0.000 | 0.105 | 0.001 | 0.787 | 0.597 | 0.322 | 0.989 | 0.518 | 0.008 |
| (50, 50) | 0.001 | 0.000 | 0.100 | 0.001 | 0.788 | 0.595 | 0.314 | 0.989 | 0.544 | 0.020 |
| BDT (lr: 50, max_depth: 0.01) | ||||||||||
| n_estimators | min_samples split | Precision | Recall | F1-Score | Specificity | AUC | G-mean | NVP | W_acc | MCC |
| 0 | 3 | 0.000 | 0.300 | 0.000 | 0.005 | 0.784 | 0.589 | 0.924 | 0.723 | 0.013 |
| 1 | 3 | 0.000 | 0.500 | 0.000 | 0.005 | 0.784 | 0.589 | 0.953 | 0.723 | 0.002 |
| 2 | 3 | 0.000 | 0.600 | 0.001 | 0.005 | 0.844 | 0.739 | 0.994 | 0.750 | 0.014 |
| 3 | 5 | 0.000 | 0.500 | 0.000 | 0.003 | 0.830 | 0.576 | 0.907 | 0.744 | 0.001 |
| 4 | 5 | 0.000 | 0.400 | 0.000 | 0.003 | 0.830 | 0.576 | 0.907 | 0.740 | 0.001 |
| DT (criterion: gini) | ||||||||||
| max_depth | min_samples split | Precision | Recall | F1-Score | Specificity | AUC | G-mean | NVP | W_acc | MCC |
| None | 2 | 0.082 | 0.500 | 0.131 | 0.993 | 0.546 | 0.555 | 0.999 | 0.546 | 0.227 |
| None | 2 | 0.082 | 0.300 | 0.131 | 0.993 | 0.546 | 0.315 | 0.999 | 0.546 | 0.227 |
| 5 | 2 | 0.094 | 0.600 | 0.162 | 0.993 | 0.822 | 0.805 | 0.999 | 0.826 | 0.247 |
| 5 | 5 | 0.022 | 0.300 | 0.111 | 0.918 | 0.595 | 0.525 | 0.999 | 0.609 | 0.219 |
| 5 | 5 | 0.022 | 0.300 | 0.111 | 0.918 | 0.595 | 0.525 | 0.999 | 0.609 | 0.219 |
| RF (n_stimators: 50) | ||||||||||
| max_depth | min_samples split | Precision | Recall | F1-Score | Specificity | AUC | G-mean | NVP | W_acc | MCC |
| None | 2 | 0.149 | 0.400 | 0.426 | 0.937 | 0.648 | 0.722 | 0.999 | 0.523 | 0.420 |
| None | 5 | 0.219 | 0.400 | 0.425 | 0.996 | 0.668 | 0.722 | 0.999 | 0.523 | 0.419 |
| None | 10 | 0.019 | 0.500 | 0.425 | 0.996 | 0.661 | 0.622 | 0.999 | 0.523 | 0.419 |
| 10 | 2 | 0.183 | 0.500 | 0.489 | 0.934 | 0.589 | 0.743 | 0.999 | 0.657 | 0.413 |
| 10 | 5 | 0.391 | 0.643 | 0.487 | 0.999 | 0.821 | 0.802 | 0.999 | 0.821 | 0.502 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Maldonado-Correa, J.; Valdiviezo-Condolo, M.; Artigao, E.; Martín-Martínez, S.; Gómez-Lázaro, E. Classification of Highly Imbalanced Supervisory Control and Data Acquisition Data for Fault Detection of Wind Turbine Generators. Energies 2024, 17, 1590. https://doi.org/10.3390/en17071590
Maldonado-Correa J, Valdiviezo-Condolo M, Artigao E, Martín-Martínez S, Gómez-Lázaro E. Classification of Highly Imbalanced Supervisory Control and Data Acquisition Data for Fault Detection of Wind Turbine Generators. Energies. 2024; 17(7):1590. https://doi.org/10.3390/en17071590
Chicago/Turabian StyleMaldonado-Correa, Jorge, Marcelo Valdiviezo-Condolo, Estefanía Artigao, Sergio Martín-Martínez, and Emilio Gómez-Lázaro. 2024. "Classification of Highly Imbalanced Supervisory Control and Data Acquisition Data for Fault Detection of Wind Turbine Generators" Energies 17, no. 7: 1590. https://doi.org/10.3390/en17071590