
Machine Learning Algorithms for Lithofacies Classification of the Gulong Shale from the Songliao Basin, China
 , and
, and
Abstract
:1. Introduction
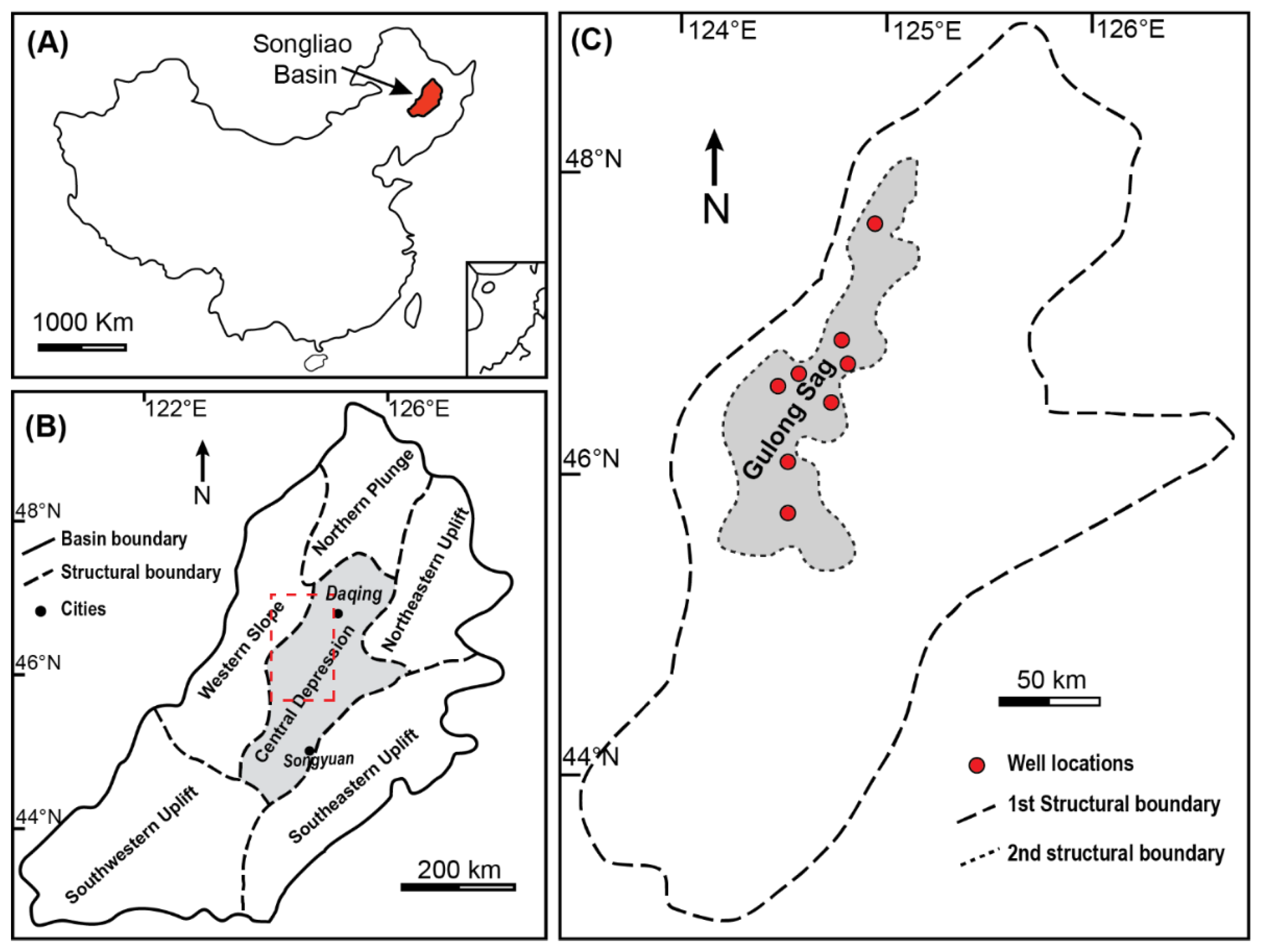
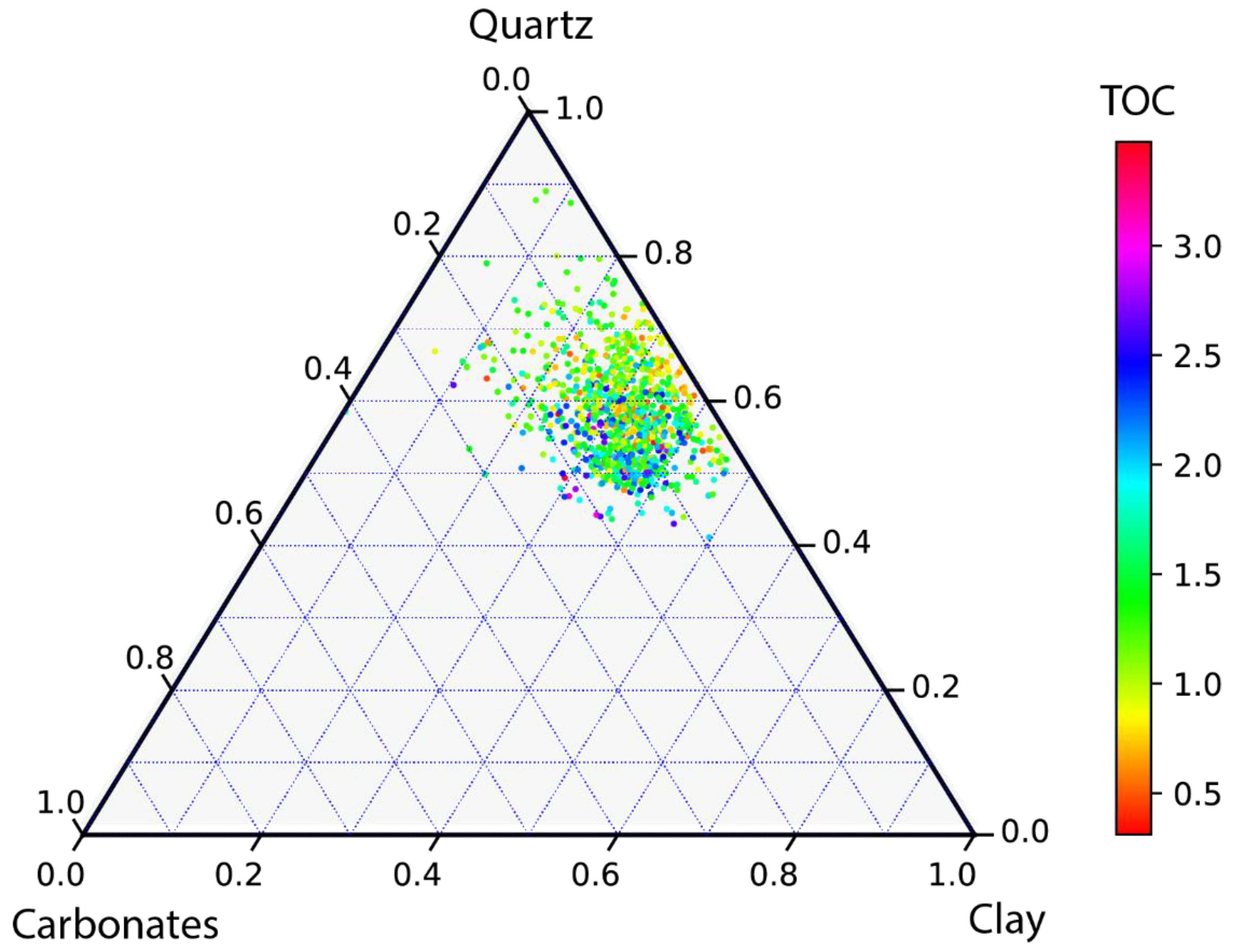
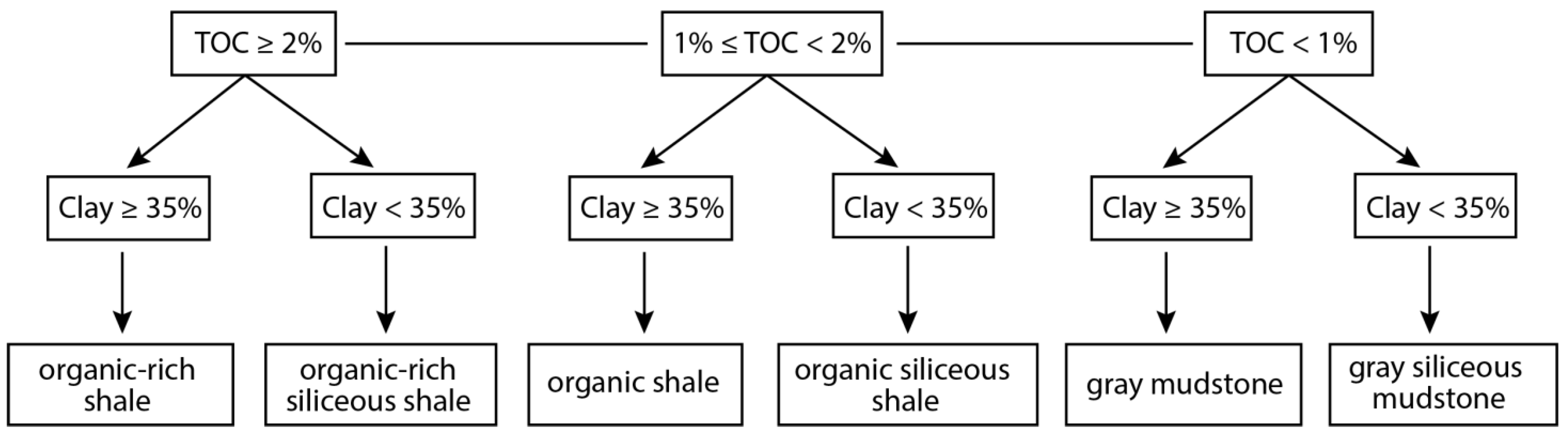
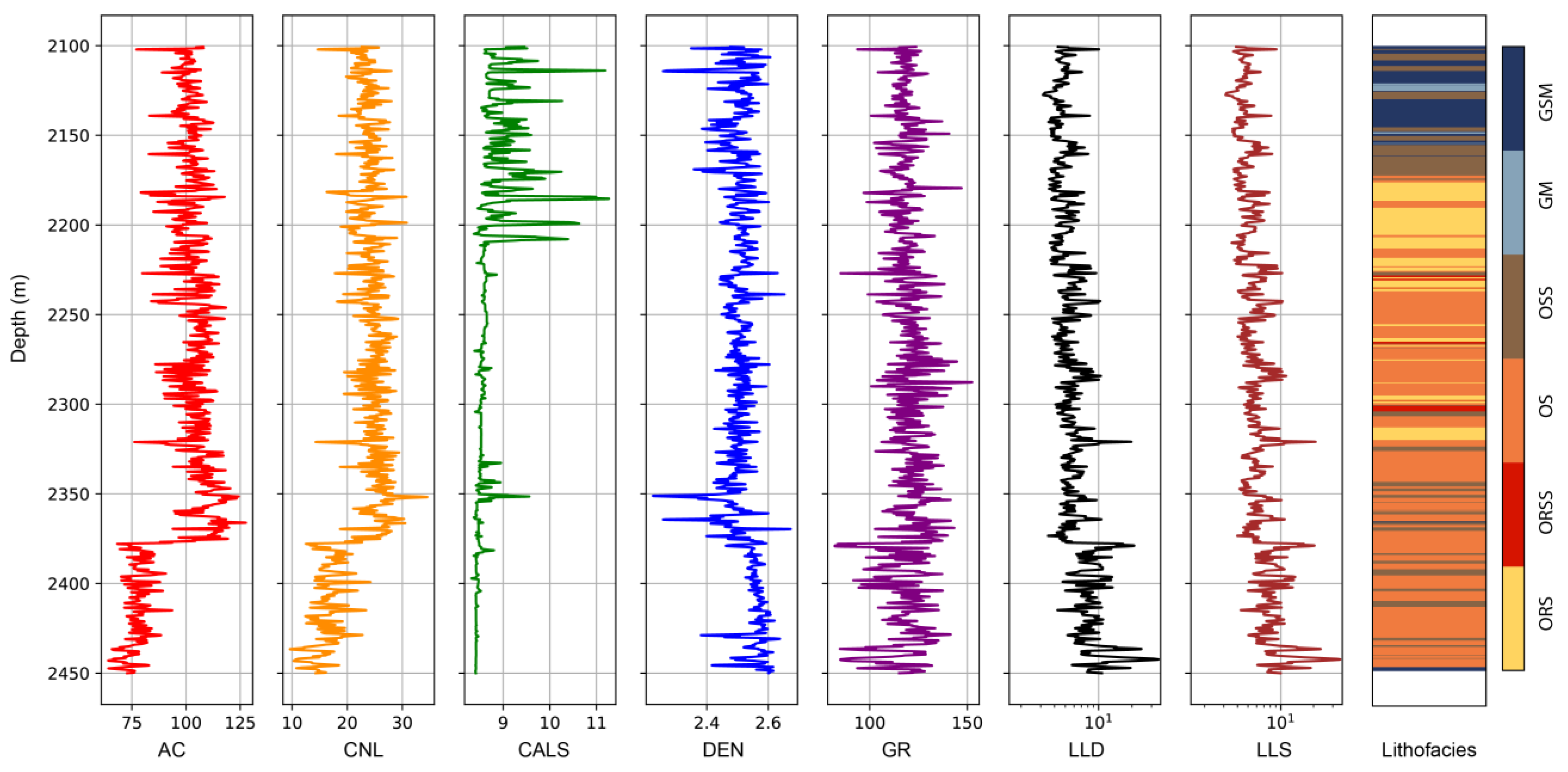
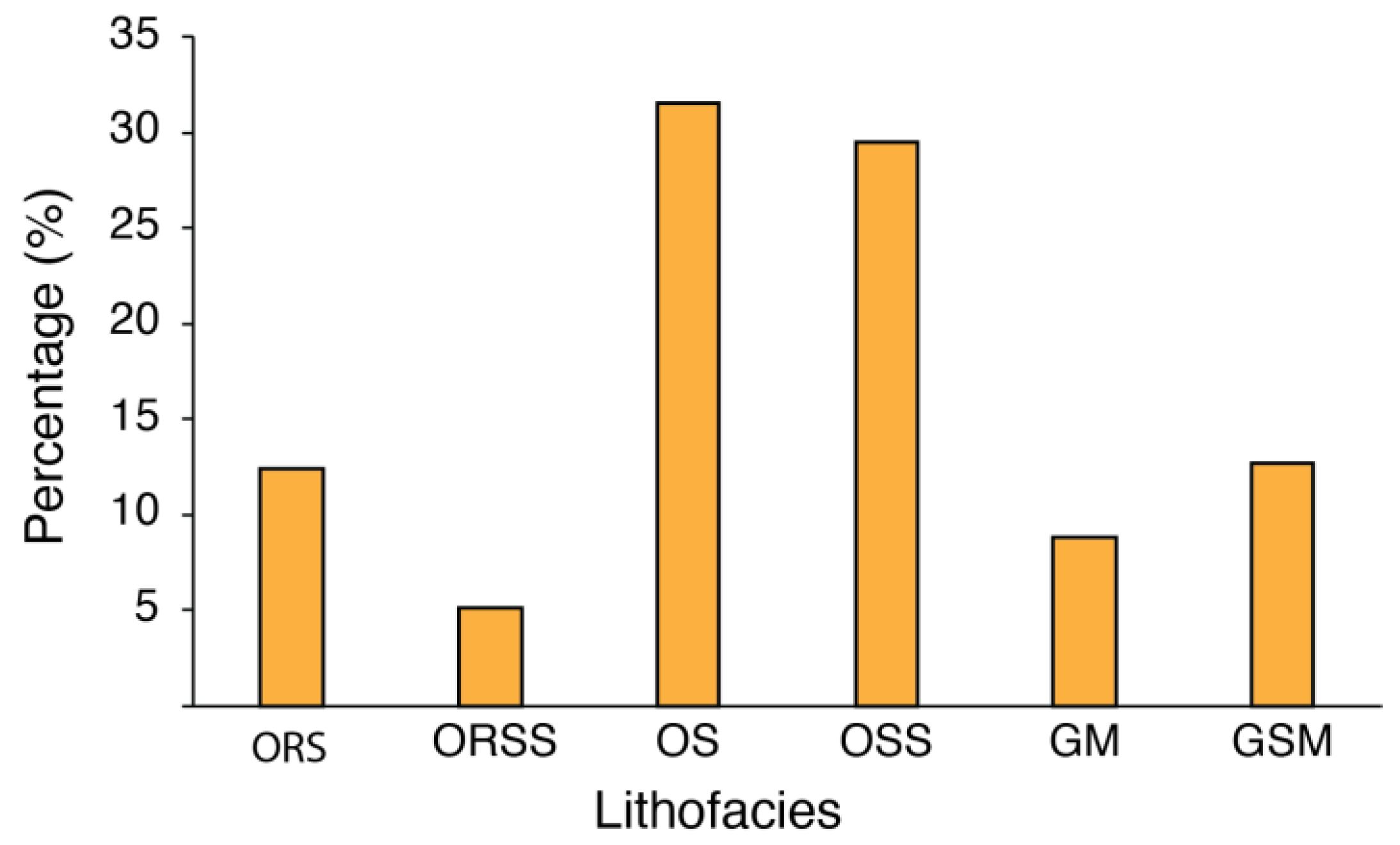
2. Geological Settings and Gulong Lithofacies
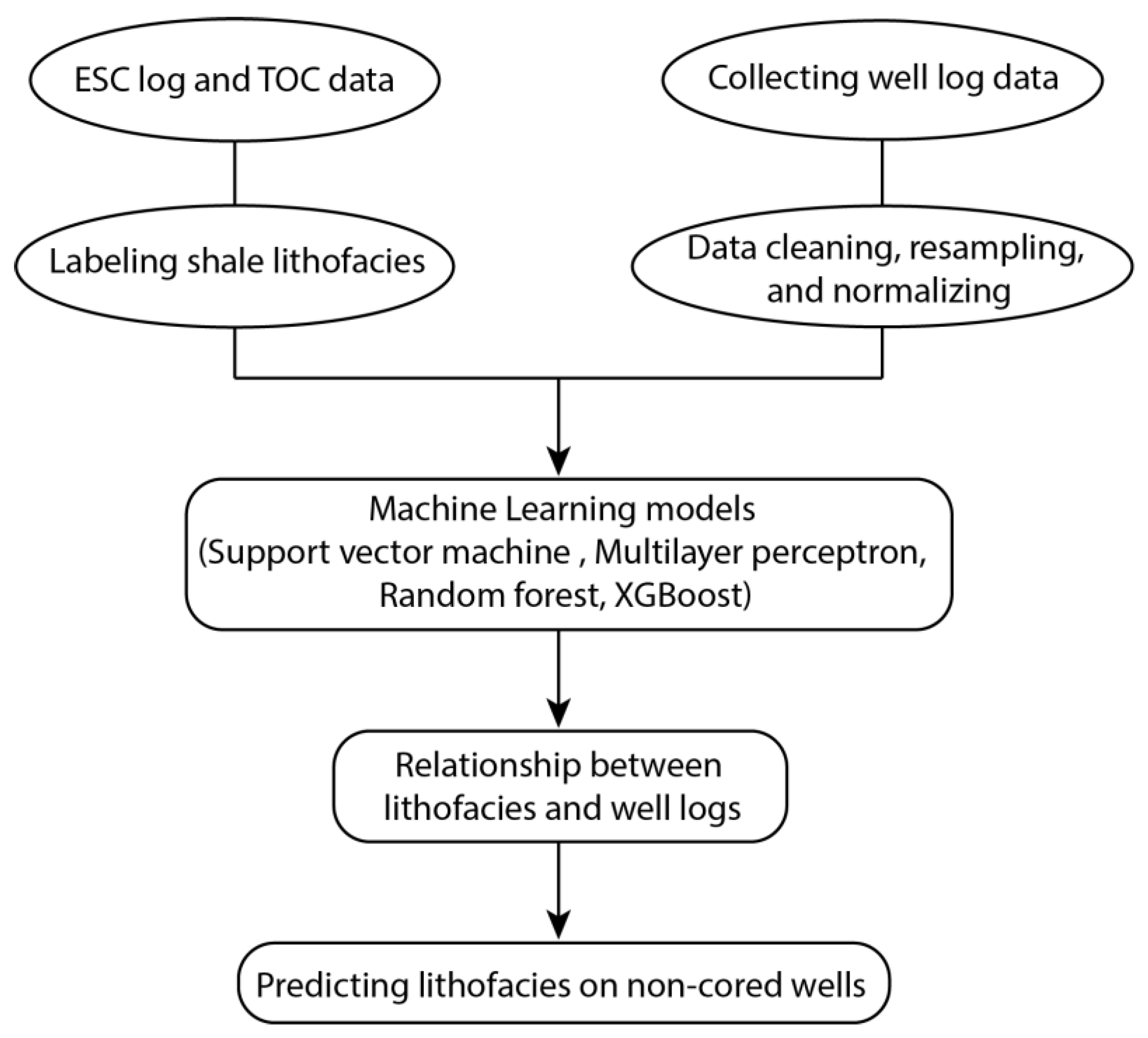
3. Materials and Methods
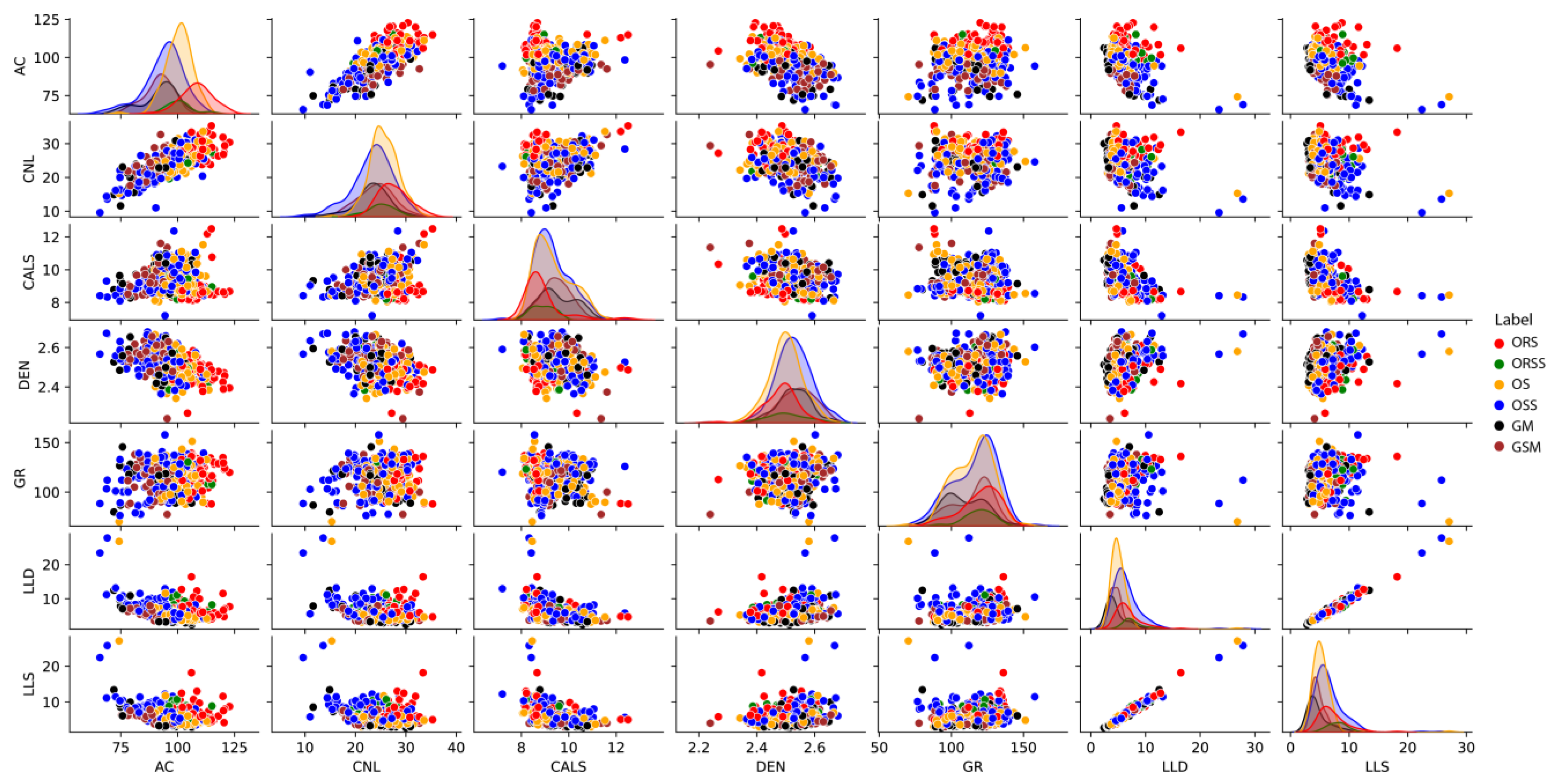
3.1. Selection of Well Logs
3.2. Well Log Data Processing
3.3. Machine Learning Models
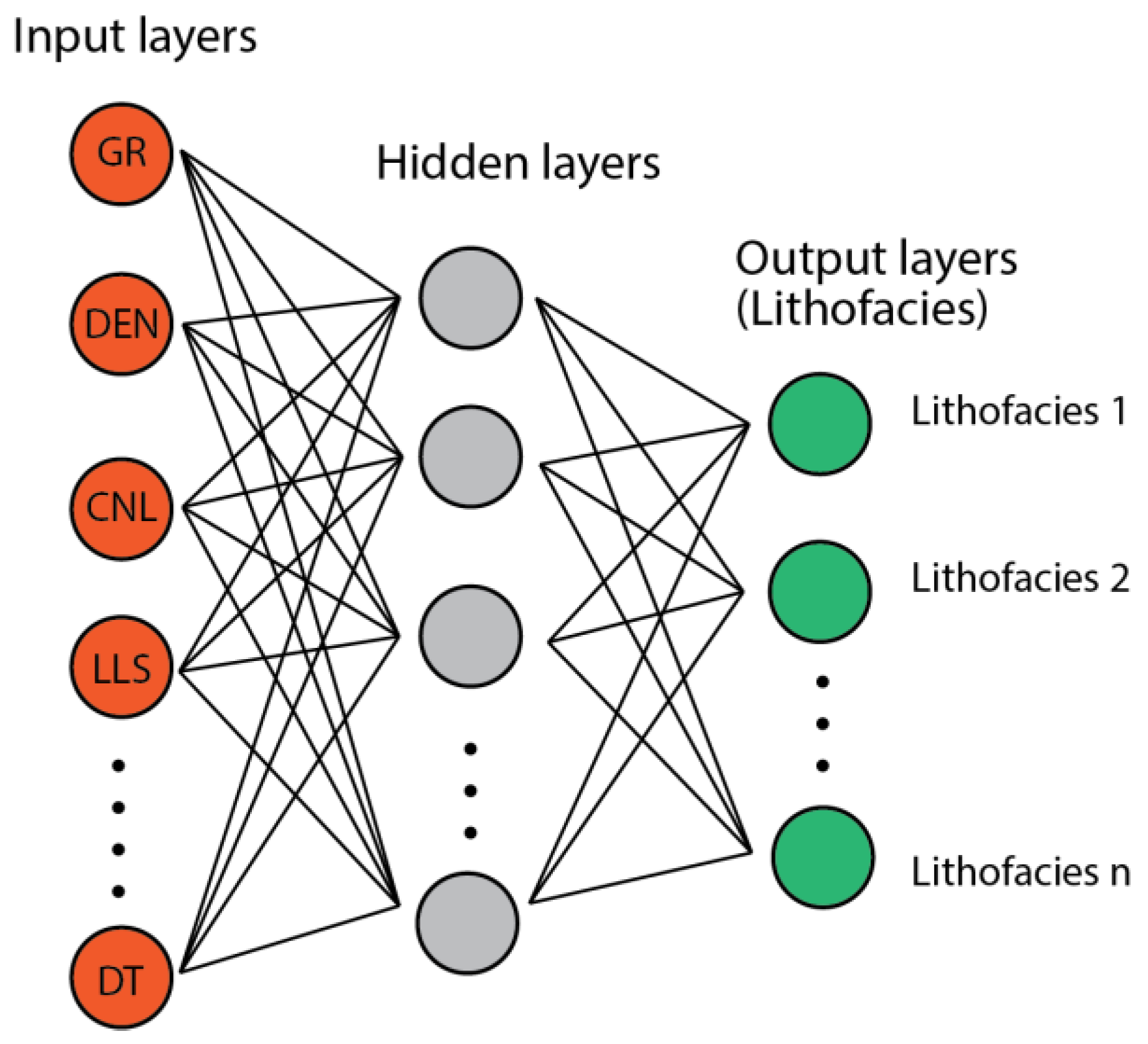
3.3.1. Multilayer Perceptron (MLP)
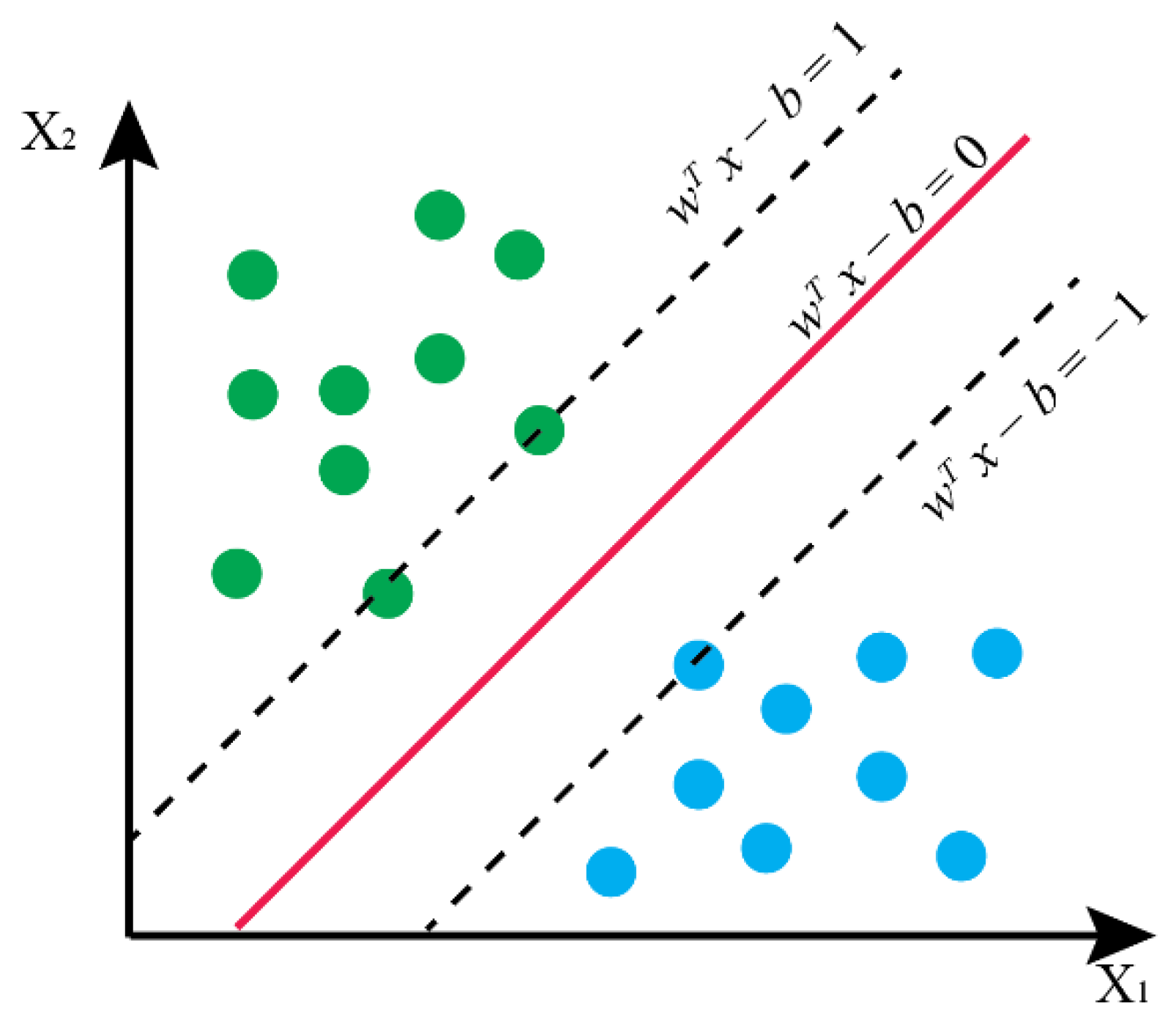
3.3.2. Support Vector Machine (SVM)
- Minimize
- Subject to:
3.3.3. Random Forest
3.3.4. Extreme Gradient Boosting (XGBoost)
3.3.5. Data Resampling, Tuning Processes, and Prediction Evaluation
3.4. Overfitting and Cross-Validation
4. Results
4.1. Tuning Parameters
4.2. The Effect of Resampling on Imbalanced Datasets
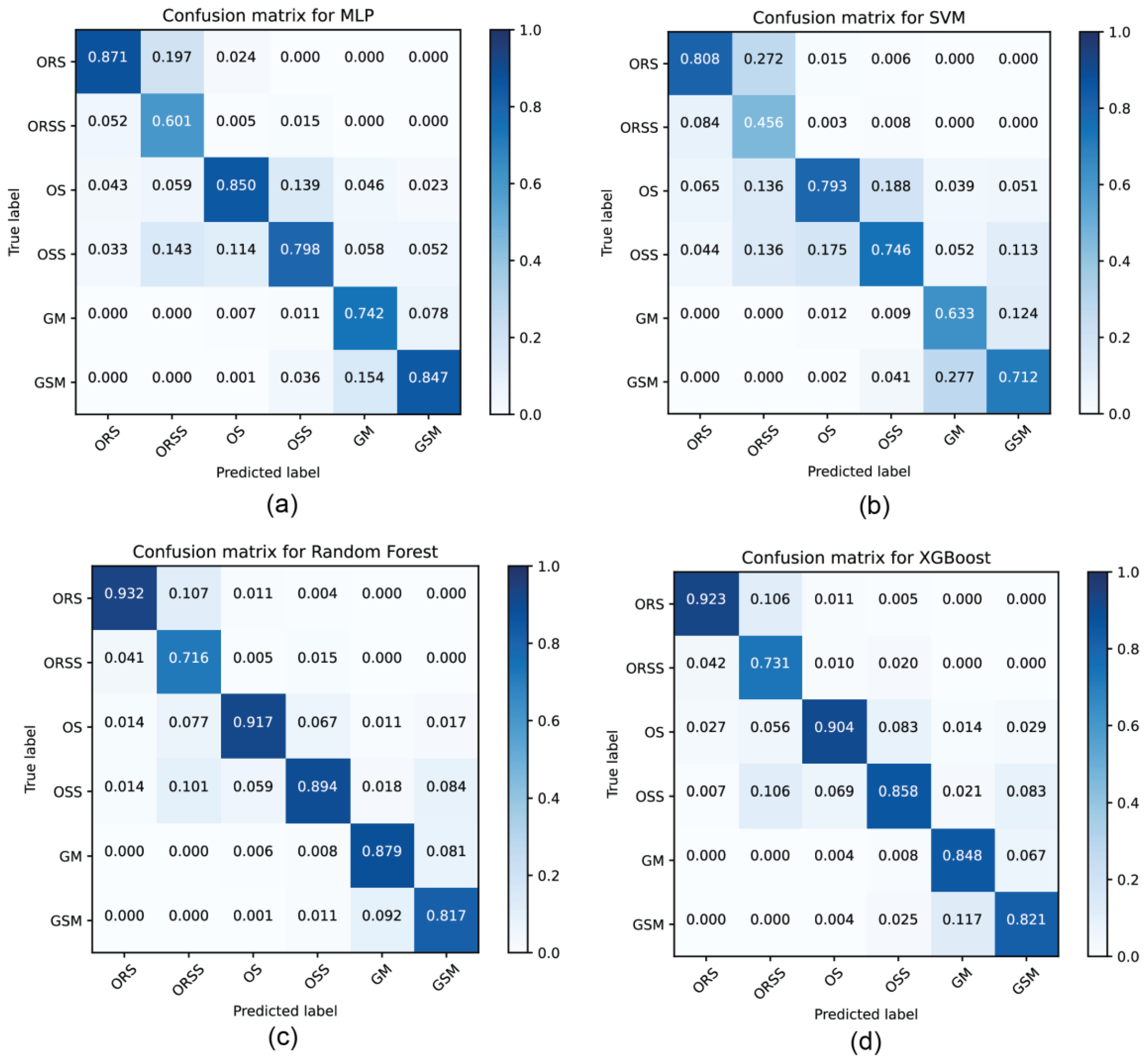
4.3. Performances of Machine Learning Models
5. Discussion
5.1. Comparison of the Performances of Machine Learning Models in Shale Lithofacies Prediction from Well Logs
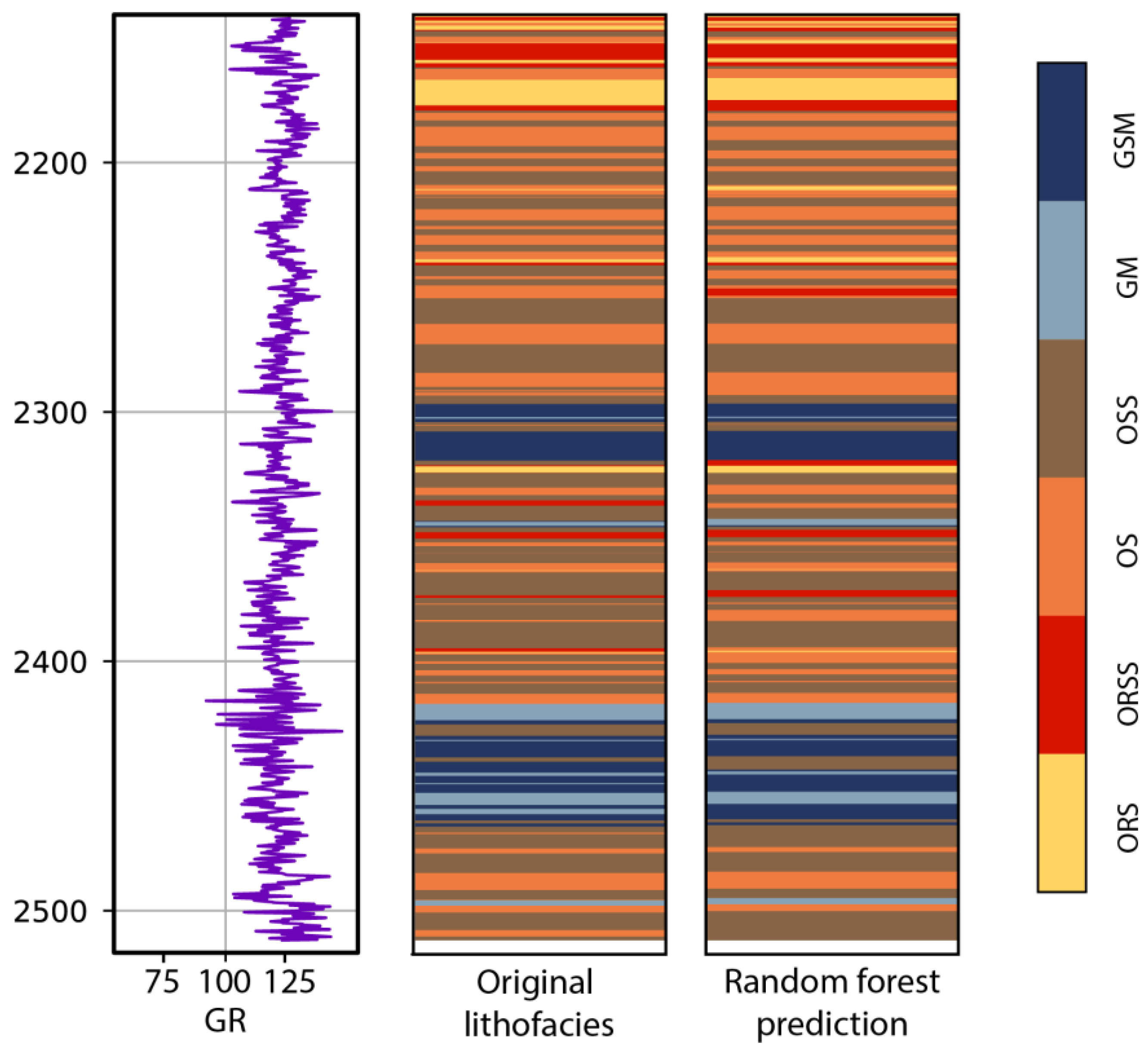
5.2. Prediction of Sweet Spots Based on Lithofacies Analysis
5.3. Future Works of Machine Learning Models for Lithofacies Prediction
6. Conclusions
- Ensemble models (Random Forest and XGBoost) yield a better performance than the other models do for shale lithofacies identification. Random Forest conducts the best prediction with an accuracy of 0.884, precision of 0.859, recall of 0.874, and F1 score of 0.866.
- The differences in the models’ performances in predicting Gulong Shale and Bakken and Marcellus Shale in the previous studies may be due to the different mineral compositions. Our findings show that ensemble methods (Random Forest and XGBoost algorithms) are more suitable for classifying homogenous, clay-rich lithofacies such as Gulong Shale than the other models are.
- The performance of machine learning models on lithofacies prediction of shale can be associated with mineral composition. Understanding the characteristics of shale mineralogy is critical for choosing the appropriate classifiers for automated lithofacies prediction.
- Machine learning models have a large potential for identifying shale lithofacies of non-cored stratigraphic succession and predicting sweet spots of unconventional reservoirs. Further improvements in model performances can be achieved by adding domain knowledge and employing advanced well log data.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| CNL | Compensated neutron log |
| CAL | Caliper log |
| DEN | Density log |
| DT | Acoustic log |
| GR | Gamma-ray log |
| LLS | Shallow laterolog resistivity log |
| LLD | Deep laterolog resistivity log |
| K2qn1 | The first member of the Qingshankou Formation |
| K2qn2 | The second member of the Qingshankou Formation |
| K2qn3 | The third member of the Qingshankou Formation |
| ORS | organic-rich shale |
| ORSS | organic-rich siliceous shale |
| OS | organic shale |
| OSS | organic siliceous shale |
| GM | gray mudstone |
| GSM | gray siliceous mudstone |
| MP | Multilayer Perceptron |
| SVM | Support vector machine |
| XGBoost | Extreme gradient boosting |
| SMOTE | Synthetic Minority Oversampling Technique |
| ADASYN | Adaptive Synthetic |
| TP | True positive |
| TN | True negative |
| FP | False positive |
| FN | False negative |
References
- Wu, M.; Zhuang, G.; Hou, M.; Liu, Z. Expanded lacustrine sedimentation in the Qaidam Basin on the northern Tibetan Plateau: Manifestation of climatic wetting during the Oligocene icehouse. Earth Planet. Sci. Lett. 2021, 565, 116935. [Google Scholar] [CrossRef]
- Hou, M.; Zhuang, G.; Ji, J.; Xiang, S.; Kong, W.; Cui, X.; Wu, M.; Hren, M. Profiling interactions between the Westerlies and Asian summer monsoons since 45 ka: Insights from biomarker, isotope, and numerical modeling studies in the Qaidam Basin. GSA Bull. 2020, 133, 1531–1541. [Google Scholar] [CrossRef]
- Hou, M.; Zhuang, G.; Wu, M. Isotopic fingerprints of mountain uplift and global cooling in paleoclimatic and paleoecological records from the northern Tibetan Plateau. Palaeogeogr. Palaeoclimatol. Palaeoecol. 2021, 578, 110578. [Google Scholar] [CrossRef]
- Bhattacharya, S.; Carr, T.; Wang, G. Shale lithofacies classification and modeling: Case studies from the Bakken and Marcellus formations, North America. In Proceedings of the AAPG Annual Convention and Exhibition, Denver, CO, USA, 31 May–3 June 2015. [Google Scholar]
- Zou, C.; Feng, Y.; Yang, Z.; Jiang, W.; Pan, S.; Zhang, T.; Wang, X.; Zhu, J.; Li, J. What are the Lacustrine Fine-Grained Gravity Flow Sedimentation Process and the Genetic Mechanism of Sweet Sections for Shale Oil? J. Earth Sci. 2022, 33, 1321–1323. [Google Scholar] [CrossRef]
- Hou, M.; Zhuang, G.; Ellwood, B.B.; Liu, X.-l.; Wu, M. Enhanced precipitation in the Gulf of Mexico during the Eocene–Oligocene transition driven by interhemispherical temperature asymmetry. GSA Bull. 2022, 134, 2335–2344. [Google Scholar] [CrossRef]
- Slatt, R.M. Important geological properties of unconventional resource shales. Cent. Eur. J. Geosci. 2011, 3, 435–448. [Google Scholar] [CrossRef] [Green Version]
- Law, B.E.; Curtis, J. Introduction to unconventional petroleum systems. AAPG Bull. 2002, 86, 1851–1852. [Google Scholar]
- Zhan, C.; Sankaran, S.; LeMoine, V.; Graybill, J.; Mey, D.-O.S. Application of machine learning for production forecasting for unconventional resources. In Proceedings of the Unconventional Resources Technology Conference, Denver, CO, USA, 22–24 July 2019. [Google Scholar]
- Liu, B.; Shi, J.; Fu, X.; Lyu, Y.; Sun, X.; Gong, L.; Bai, Y. Petrological characteristics and shale oil enrichment of lacustrine fine-grained sedimentary system: A case study of organic-rich shale in first member of Cretaceous Qingshankou Formation in Gulong Sag, Songliao Basin, NE China. Pet. Explor. Dev. 2018, 45, 884–894. [Google Scholar] [CrossRef]
- Wang, L.; Zeng, W.; Xia, X.; Zhou, H.; Bi, H.; Shang, F.; Zhou, X. Study on lithofacies types and sedimentary environment of black shale of Qingshankou Formation in Qijia-Gulong Depression, Songliao Basin. Nat. Gas Geosci. 2019, 30, 1125–1133. [Google Scholar]
- Jin, C.; Dong, W.; Bai, Y.; Lv, J.; Fu, X.; Li, J.; Ma, s. Lithofacies characteristics and genesis analysis of Gulong shale in Songliao Basin. Pet. Geol. Oilfield Dev. Daqing 2020, 39, 35–44. [Google Scholar]
- He, W.; Meng, Q.; Zhang, J. Controlling factors and their classification-evaluation of Gulong shale oil enrichment in Songliao Basin. Pet. Geol. Oilfield Dev. Daqing 2021, 40, 1–12. [Google Scholar]
- Wang, G.; Carr, T.R. Marcellus Shale Lithofacies Prediction by Multiclass Neural Network Classification in the Appalachian Basin. Math. Geosci. 2012, 44, 975–1004. [Google Scholar] [CrossRef]
- Wang, G.; Carr, T.R. Organic-rich Marcellus Shale lithofacies modeling and distribution pattern analysis in the Appalachian Basin. AAPG Bull. 2013, 97, 2173–2205. [Google Scholar] [CrossRef] [Green Version]
- Bhattacharya, S.; Carr, T.R.; Pal, M. Comparison of supervised and unsupervised approaches for mudstone lithofacies classification: Case studies from the Bakken and Mahantango-Marcellus Shale, USA. J. Nat. Gas Sci. Eng. 2016, 33, 1119–1133. [Google Scholar] [CrossRef] [Green Version]
- Gao, B.; He, W.; Feng, Z.; Shao, H.; Zhang, A.; Pan, H.; Chen, G. Lithology, physical property, oil-bearing property and their controlling factors of Gulong shale in Songliao Basin. Pet. Geol. Oilfield Dev. Daqing 2022, 41, 68–79. [Google Scholar]
- Cui, B.; Chen, C.; Lin, X.; Zhao, Y.; Cheng, X.; Zhang, Y.; Lu, G. Characteristics and distribution of sweet spots in Gulong shale oil reserviors of Songliao Basin. Pet. Geol. Oilfield Dev. Daqing 2020, 39, 45–55. [Google Scholar]
- Busch, J.; Fortney, W.; Berry, L. Determination of lithology from well logs by statistical analysis. SPE Form. Eval. 1987, 2, 412–418. [Google Scholar] [CrossRef]
- Ellis, D.V.; Singer, J.M. Well Logging for Earth Scientists; Springer: Berlin/Heidelberg, Germany, 2007; Volume 692. [Google Scholar]
- Asquith, G.B.; Krygowski, D.; Gibson, C.R. Basic Well Log Analysis; American Association of Petroleum Geologists: Tulsa, OK, USA, 2004; Volume 16. [Google Scholar]
- Song, S.; Mukerji, T.; Hou, J.; Zhang, D.; Lyu, X. GANSim-3D for Conditional Geomodeling: Theory and Field Application. Water Resour. Res. 2022, 58, e2021WR031865. [Google Scholar] [CrossRef]
- Song, S.; Mukerji, T.; Hou, J. GANSim: Conditional facies simulation using an improved progressive growing of generative adversarial networks (GANs). Math. Geosci. 2021, 53, 1413–1444. [Google Scholar] [CrossRef]
- Ashraf, U.; Zhang, H.; Anees, A.; Mangi, H.N.; Ali, M.; Zhang, X.; Imraz, M.; Abbasi, S.S.; Abbas, A.; Ullah, Z. A core logging, machine learning and geostatistical modeling interactive approach for subsurface imaging of lenticular geobodies in a clastic depositional system, SE Pakistan. Nat. Resour. Res. 2021, 30, 2807–2830. [Google Scholar] [CrossRef]
- Ali, M.; Jiang, R.; Ma, H.; Pan, H.; Abbas, K.; Ashraf, U.; Ullah, J. Machine learning-A novel approach of well logs similarity based on synchronization measures to predict shear sonic logs. J. Pet. Sci. Eng. 2021, 203, 108602. [Google Scholar] [CrossRef]
- Raeesi, M.; Moradzadeh, A.; Doulati Ardejani, F.; Rahimi, M. Classification and identification of hydrocarbon reservoir lithofacies and their heterogeneity using seismic attributes, logs data and artificial neural networks. J. Pet. Sci. Eng. 2012, 82–83, 151–165. [Google Scholar] [CrossRef]
- Rogers, S.J.; Fang, J.; Karr, C.; Stanley, D. Determination of lithology from well logs using a neural network. AAPG Bull. 1992, 76, 731–739. [Google Scholar]
- Al-Mudhafar, W.J. Integrating well log interpretations for lithofacies classification and permeability modeling through advanced machine learning algorithms. J. Pet. Explor. Prod. Technol. 2017, 7, 1023–1033. [Google Scholar] [CrossRef] [Green Version]
- Zheng, D.; Hou, M.; Chen, A.; Zhong, H.; Qi, Z.; Ren, Q.; You, J.; Wang, H.; Ma, C. Application of machine learning in the identification of fluvial-lacustrine lithofacies from well logs: A case study from Sichuan Basin, China. J. Pet. Sci. Eng. 2022, 215, 110610. [Google Scholar] [CrossRef]
- Ren, X.; Hou, J.; Song, S.; Liu, Y.; Chen, D.; Wang, X.; Dou, L. Lithology identification using well logs: A method by integrating artificial neural networks and sedimentary patterns. J. Pet. Sci. Eng. 2019, 182, 106336. [Google Scholar] [CrossRef]
- Xie, Y.; Zhu, C.; Zhou, W.; Li, Z.; Liu, X.; Tu, M. Evaluation of machine learning methods for formation lithology identification: A comparison of tuning processes and model performances. J. Pet. Sci. Eng. 2018, 160, 182–193. [Google Scholar] [CrossRef]
- Ippolito, M.; Ferguson, J.; Jenson, F. Improving facies prediction by combining supervised and unsupervised learning methods. J. Pet. Sci. Eng. 2021, 200, 108300. [Google Scholar] [CrossRef]
- Ehsan, M.; Gu, H. An integrated approach for the identification of lithofacies and clay mineralogy through Neuro-Fuzzy, cross plot, and statistical analyses, from well log data. J. Earth Syst. Sci. 2020, 129, 1–13. [Google Scholar] [CrossRef]
- Khalil Khan, H.; Ehsan, M.; Ali, A.; Amer, M.A.; Aziz, H.; Khan, A.; Bashir, Y.; Abu-Alam, T.; Abioui, M. Source rock geochemical assessment and estimation of TOC using well logs and geochemical data of Talhar Shale, Southern Indus Basin, Pakistan. Front. Earth Sci. 2022, 1593, 969936. [Google Scholar] [CrossRef]
- Merembayev, T.; Kurmangaliyev, D.; Bekbauov, B.; Amanbek, Y. A Comparison of Machine Learning Algorithms in Predicting Lithofacies: Case Studies from Norway and Kazakhstan. Energies 2021, 14, 1896. [Google Scholar] [CrossRef]
- Manzoor, U.; Ehsan, M.; Radwan, A.E.; Hussain, M.; Iftikhar, M.K.; Arshad, F. Seismic driven reservoir classification using advanced machine learning algorithms: A case study from the lower Ranikot/Khadro sandstone gas reservoir, Kirthar fold belt, lower Indus Basin, Pakistan. Geoenergy Sci. Eng. 2023, 222, 211451. [Google Scholar] [CrossRef]
- Safaei-Farouji, M.; Thanh, H.V.; Dashtgoli, D.S.; Yasin, Q.; Radwan, A.E.; Ashraf, U.; Lee, K.-K. Application of robust intelligent schemes for accurate modelling interfacial tension of CO2 brine systems: Implications for structural CO2 trapping. Fuel 2022, 319, 123821. [Google Scholar] [CrossRef]
- Tewari, S.; Dwivedi, U.D. Ensemble-based big data analytics of lithofacies for automatic development of petroleum reservoirs. Comput. Ind. Eng. 2019, 128, 937–947. [Google Scholar] [CrossRef]
- Wang, P.-J.; Mattern, F.; Didenko, N.A.; Zhu, D.-F.; Singer, B.; Sun, X.-M. Tectonics and cycle system of the Cretaceous Songliao Basin: An inverted active continental margin basin. Earth Sci. Rev. 2016, 159, 82–102. [Google Scholar] [CrossRef] [Green Version]
- Gao, R.; Zhang, Y.; Cui, T. Cretaceous Petroleum Bearing Strata in the Songliao Basin; Petroleum Industry Press: Beijing, China, 1994. [Google Scholar]
- Wu, H.; Zhang, S.; Jiang, G.; Huang, Q. The floating astronomical time scale for the terrestrial Late Cretaceous Qingshankou Formation from the Songliao Basin of Northeast China and its stratigraphic and paleoclimate implications. Earth Planet. Sci. Lett. 2009, 278, 308–323. [Google Scholar] [CrossRef]
- Xu, J.; Liu, Z.; Bechtel, A.; Meng, Q.; Sun, P.; Jia, J.; Cheng, L.; Song, Y. Basin evolution and oil shale deposition during Upper Cretaceous in the Songliao Basin (NE China): Implications from sequence stratigraphy and geochemistry. Int. J. Coal Geol. 2015, 149, 9–23. [Google Scholar] [CrossRef]
- Wang, Y.; Liang, J.; Zhang, J. Resource potential and exploration direction of Gulong shale oil in Songliao Basin. Pet. Geol. Oilfield Dev. Daqing 2020, 39, 20–34. [Google Scholar]
- Liu, B.; Wang, H.; Fu, X.; Bai, Y.; Bai, L.; Jia, M.; He, B. Lithofacies and depositional setting of a highly prospective lacustrine shale oil succession from the Upper Cretaceous Qingshankou Formation in the Gulong sag, northern Songliao Basin, northeast China. AAPG Bull. 2019, 103, 405–432. [Google Scholar] [CrossRef] [Green Version]
- Mahesh, B. Machine learning algorithms-a review. Int. J. Sci. Res. 2020, 9, 381–386. [Google Scholar]
- Jordan, M.I.; Mitchell, T.M. Machine learning: Trends, perspectives, and prospects. Science 2015, 349, 255–260. [Google Scholar] [CrossRef]
- Bishop, C.M. Neural Networks for Pattern Recognition; Oxford University Press: Oxford, UK, 1995. [Google Scholar]
- Hearst, M.A.; Dumais, S.T.; Osuna, E.; Platt, J.; Scholkopf, B. Support vector machines. IEEE Intell. Syst. Appl. 1998, 13, 18–28. [Google Scholar] [CrossRef] [Green Version]
- Vapnik, V. The Nature of Statistical Learning Theory; Springer Science & Business Media: Berlin/Heidelberg, Germany, 1999. [Google Scholar]
- Ho, T.K. Random decision forests. In Proceedings of the 3rd International Conference on Document Analysis and Recognition, Montreal, QC, Canada, 14–16 August 1995. [Google Scholar]
- Safavian, S.R.; Landgrebe, D. A survey of decision tree classifier methodology. IEEE Trans. Syst. Man Cybern. 1991, 21, 660–674. [Google Scholar] [CrossRef] [Green Version]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016. [Google Scholar]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- He, H.; Bai, Y.; Garcia, E.A.; Li, S. ADASYN: Adaptive synthetic sampling approach for imbalanced learning. In Proceedings of the 2008 IEEE International Joint Conference on Neural Networks (IEEE World Congress on Computational Intelligence), Hong Kong, China, 1–8 June 2008. [Google Scholar]
- Hackley, P.C.; Cardott, B.J. Application of organic petrography in North American shale petroleum systems: A review. Int. J. Coal Geol. 2016, 163, 8–51. [Google Scholar] [CrossRef] [Green Version]
- Song, S.; Hou, J.; Dou, L.; Song, Z.; Sun, S. Geologist-level wireline log shape identification with recurrent neural networks. Comput. Geosci. 2020, 134, 104313. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithms | Parameters | Candidates | Optimal Value |
|---|---|---|---|
| MLP | Number of hidden layers | 1, 2 | 2 |
| Number of neurons in a hidden layer | 10, 20, 50, 100 | 100 | |
| SVM | Kernel | Polynomial, Sigmoid, RBF | RBF |
| Regularization | 0.1, 1, 10 | 10 | |
| Gamma | 0.0001, 0.001, 0.1 | 0.1 | |
| XGBoost | Learning rate | 0.01, 0.02, 0.05, 0.1 | 0.1 |
| Maximum child weight | 1, 3, 5, 7 | 1 | |
| Maximum tree depth | 7, 9, 12, 15 | 15 | |
| Random Forest | Minimum samples split | 2, 4, 7, 10 | 2 |
| Minimum samples leaf | 1, 2, 5, 10, 20 | 1 | |
| Maximum tree depth | 5, 10, 15, 20 | 20 |
| Oversampling Algorithms | SVM | MLP | XGBoost | Random Forest |
|---|---|---|---|---|
| No sampling | 0.708 | 0.810 | 0.845 | 0.875 |
| SMOTE | 0.723 | 0.809 | 0.868 | 0.884 |
| ADASYN | 0.693 | 0.794 | 0.853 | 0.870 |
| SVM | MLP | XGBoost | Random Forest | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Precision | Recall | F1-Score | Precision | Recall | F1-Score | Precision | Recall | F1-Score | Precision | Recall | F1-Score | |
| ORS | 0.808 | 0.777 | 0.792 | 0.871 | 0.857 | 0.864 | 0.923 | 0.925 | 0.924 | 0.932 | 0.920 | 0.926 |
| ORSS | 0.456 | 0.751 | 0.568 | 0.601 | 0.762 | 0.672 | 0.731 | 0.745 | 0.738 | 0.716 | 0.801 | 0.756 |
| OS | 0.793 | 0.750 | 0.771 | 0.850 | 0.819 | 0.835 | 0.904 | 0.887 | 0.895 | 0.917 | 0.909 | 0.913 |
| OSS | 0.746 | 0.663 | 0.702 | 0.798 | 0.778 | 0.788 | 0.858 | 0.847 | 0.853 | 0.894 | 0.861 | 0.877 |
| GM | 0.633 | 0.790 | 0.703 | 0.742 | 0.859 | 0.796 | 0.848 | 0.879 | 0.863 | 0.879 | 0.860 | 0.870 |
| GSM | 0.712 | 0.660 | 0.685 | 0.847 | 0.779 | 0.812 | 0.821 | 0.848 | 0.834 | 0.817 | 0.892 | 0.853 |
| Average | 0.691 | 0.732 | 0.704 | 0.785 | 0.809 | 0.794 | 0.847 | 0.855 | 0.851 | 0.859 | 0.874 | 0.866 |
| Precision | Recall | F1-Score | |
|---|---|---|---|
| ORS | 0.847 | 0.835 | 0.841 |
| ORSS | 0.721 | 0.844 | 0.778 |
| OS | 0.836 | 0.835 | 0.835 |
| OSS | 0.917 | 0.89 | 0.903 |
| GM | 0.934 | 0.87 | 0.901 |
| GSM | 0.943 | 0.916 | 0.929 |
| Average | 0.866 | 0.865 | 0.865 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hou, M.; Xiao, Y.; Lei, Z.; Yang, Z.; Lou, Y.; Liu, Y. Machine Learning Algorithms for Lithofacies Classification of the Gulong Shale from the Songliao Basin, China. Energies 2023, 16, 2581. https://doi.org/10.3390/en16062581
Hou M, Xiao Y, Lei Z, Yang Z, Lou Y, Liu Y. Machine Learning Algorithms for Lithofacies Classification of the Gulong Shale from the Songliao Basin, China. Energies. 2023; 16(6):2581. https://doi.org/10.3390/en16062581
Chicago/Turabian StyleHou, Mingqiu, Yuxiang Xiao, Zhengdong Lei, Zhi Yang, Yihuai Lou, and Yuming Liu. 2023. "Machine Learning Algorithms for Lithofacies Classification of the Gulong Shale from the Songliao Basin, China" Energies 16, no. 6: 2581. https://doi.org/10.3390/en16062581