1. Introduction
During the operation of a condenser, various impurities in the circulating water inevitably result in fouling within the condenser’s heat exchange tubes over time [
1]. The accumulation of fouling significantly decreases the heat exchange efficiency of the condenser [
2], leading to an increase in exhaust pressure and exhaust temperature of the steam turbine and reducing the output power. Additionally, fouling increases the flow resistance within the tubes, resulting in higher total energy consumption for the condenser. Moreover, the removal of fouling requires the use of auxiliary equipment, cleaning agents, and labor, along with the need for periodic shutdowns for cleaning. These additional operational and maintenance expenses, coupled with a shortened normal operation cycle, lead to economic losses. Furthermore, the accumulation of fouling in specific areas of the heat exchange tubes can lead to overheating, local corrosion, or even tube perforation. These issues pose a significant risk to the safe operation of the condenser [
3]. Therefore, it is of utmost significance to accurately predict the fouling effect and address it scientifically and timely for condenser energy savings, reducing consumption, improving economic efficiency, and ensuring its safe operation [
4].
In engineering practice, to mitigate the risk of equipment failure and implement appropriate maintenance measures, the application of fault prognosis technology has emerged as a prominent research area within the field of reliability [
5]. By utilizing such technology, proactive measures can be taken to identify potential faults and address them before they lead to equipment failure. The fault prognosis is employed to anticipate equipment failures. These methods can be broadly classified into two categories [
6]: physical model-based prognosis methods and data-driven prognosis methods. Physical model-based prognosis methods utilize mathematical formulations that embody physical laws to simulate the progression of failure in the target system over time. Nevertheless, this approach demands a high level of precision in physical modeling, making it challenging to establish an accurate mathematical model for the dynamic and stochastic nature of condenser fouling processes. Data-driven prognosis methods are frequently employed to address the aforementioned challenges [
7]. These methods do not rely on prior knowledge (such as mathematical models and expert experience) of the target system but instead utilize sensor data to monitor the fault progression and estimate the future state evolution trend, as well as the remaining useful life (RUL) of the system. Soualhi M. et al. [
8] proposed an adaptive prognosis approach for heat exchanger fouling prediction that combined long- and short-term predictors. The method utilized the long short-term memory model to capture the long-term dynamic evolution of fouling. Four nonlinear autoregressive exogenous models were employed to predict fouling levels over discrete short-term horizons. The accuracy of fouling prognostics was enhanced by integrating short-term predictors to update the predictions of the long-term models through a fusion mechanism. Zachary Welz et al. [
9] applied a developed lifecycle prognostic approach to a heat exchanger fouling test bed under accelerated degradation conditions. Hanchi H. et al. [
10] proposed an adaptive neurofuzzy inference system for fouling prediction. This model incorporated not only the operating time, but also the rate of humidity condensation in the compressor. The model parameters effectively memorized the variation records of fouling symptoms concerning the ratio of humidity to condensation. The obtained results demonstrated a better fit between the predicted and observed fouling factors. YF Jin et al. [
11] proposed a hybrid framework based on long short-term memory neural networks and a thermodynamic model. The thermodynamic model was used to obtain the expected parameters in the healthy state, calculated by comparing the expected value with the actual measured value, and then combined with the prognosis model to predict the next washing cycle. GH Zhou et al. [
12] designed a fouling factor prediction model combining the K-mean algorithm and the Chebyshev neural network. The curve of fouling factor development over time was divided into three stages: the starting stage, the adhesion stage, and the aging stage. Results showed that the modified Chebyshev neural networks can effectively predict the law of condenser fouling factor development.
Data-driven fault prognosis methods often rely on a substantial amount of historical fault datasets. However, in practical applications, acquiring typical data for certain key equipment can be costly. Furthermore, even if such data is obtained, there may be significant uncertainties and incomplete information associated with it. The digital twin can solve such problems using emulation tools [
13]. These tools simulate the behavior and characteristics of the physical equipment or system being modeled. By utilizing these emulation tools, virtual test data can be generated to compensate for the lack of real-world data. This capability enables data-driven fault prognosis methods to overcome limitations, such as the high cost or incomplete nature of acquiring historical data, thereby facilitating more accurate and robust prognoses. Hence, the study of fault prognosis methods for complex systems driven by the digital twin has emerged as a prominent and trending topic in current research on system health management. The digital twin is an important technology to realize intelligent manufacturing [
14]. As a new technology in the field of information-physical system integration, the physical entity is reconstructed in the information space. Through the dynamic digital model, the digital twin constantly updates with the change in the physical entity, simulating and describing its state and attributes synchronously [
15]. The concept of the digital twin was first introduced by Professor Grieves from the University of Michigan [
16]. Initially, it found significant application in the aerospace field. A digital twin involves creating an information model within the virtual space of a computer that is a complete replica of the physical entity. The information model makes it possible to simulate, analyze, and optimize the physical entity [
17]. In recent years, digital twin technology has experienced rapid development in both theory and application. This progress can be attributed to advancements in reliability modeling, model-based system engineering, product modeling, simulation, and other digital expression technologies. These innovations have enabled more comprehensive and effective implementation of the digital twin in various fields and industries. As a result, digital twin technology continues to evolve [
18], offering immense potential for enhancing system performance, optimizing operations, and enabling data-driven decision-making. A digital twin possesses several key characteristics that effectively address challenges related to real-time data acquisition, analysis, and prediction. These characteristics include high-fidelity modeling of physical entities, real-time and efficient data acquisition and analysis of operational processes, and the fusion of models and data. The digital twin provides a solution to the problem of limited or difficult-to-collect real-time data, as well as the insufficiency of data volume for accurate predictions. By leveraging these characteristics, the digital twin enables more comprehensive and accurate prognoses, facilitating better decision-making and problem-solving [
19].
In addressing the issue of insufficient fault data for data-driven fault prognosis methods, this paper leverages the characteristics of the digital twin to swiftly generate a substantial amount of reliable fault data. Specifically, based on the empirical equation for fouling growth that reflects the basic trend of fouling thermal resistance changes, and in combination with measurement data, a fouling thermal resistance digital twin model is established by using the particle swarm optimization (PSO) algorithm for parameter optimization. Subsequently, fouling faults are injected into the condenser simulation loop, and fault data related to fouling are obtained through simulation tools to compensate for the lack of fouling fault data. In the research of prognosis methods, the performance of prognosis, is to some extent, related to the model describing the fault behavior of the research object. Establishing a reliable model is beneficial for obtaining accurate prediction results. However, the uncertainties in the modeling process significantly affect the accuracy and precision of the prognosis results. In the typical state space model, there are uncertain parameters in both the state transition equation and the state observation equation. Classical modeling methods do not take uncertainties into account or subjectively set uncertain parameters, lacking a theoretical basis [
20,
21]. The appropriate selection of uncertainties can further improve modeling. Therefore, this paper proposes a method that applies differential modeling to predict fouling faults in condensers. By effectively quantifying the uncertainty factors in the fault process, this approach enhances the accuracy of the prediction results, providing rational maintenance recommendations for the safe operation of condensers.
3. Prognosis Theory and Methods
The classic Riemann sampling prognosis method is highly effective in monitoring diverse performance parameters and mathematically modeling their changing processes [
29]. Subsequently, various prognosis methods are employed to forecast their future changes accurately and calculate the specific time of the occurrence of faults [
30]. This section mainly introduces the theoretical background of the state-space model, the Particle Filtering algorithm (PF), and the differential modeling method.
In reality, most dynamic processes can be analyzed theoretically by a continuous time system [
31]. In continuous time systems, the nonlinear dynamic process of state variables can be defined as follows:
where
represents the state,
t represents the time instant,
represents the linear or nonlinear evaluation function, and
represents the derivative of
x on
t.
However, applications such as state estimation and control are often realized by digital circuits in discrete operating environments, so the continuous time system can be converted to a discrete time system based on Riemann integral calculation. The result can be expressed as follows:
where
is the state at time
t,
is the length of time, and [
t,
t + ] represents a small discrete time range, which is usually very short in length. Therefore,
can be approximated and simplified as a time varying function
.
The state space model is commonly used to address various problems in fields such as statistics and signal processing. In the study of life prognosis, a considerable number of degradation processes can also be described using state-space models. Some common application areas include the crack growth process [
32], the degradation process of bearings [
33], the degradation process of lithium-ion batteries [
34], and so on. Due to the variations in requirements across different application scenarios, the state space models also have different structural forms. The following provides the most general and common solutions.
The state space model comprises a state transition model and a state observation model. The state transition model can be expressed as follows:
where
is the corresponding state value at time
t,
is used to describe state changes, and
is the uncertain parameter of the state transition process. The state value at time
t is dependent on the state value at the previous time, thus the aforementioned model can be considered as a first-order Markov process [
21,
35].
The state observation model can be expressed as follows:
where
y is the observed value of the state value
x,
is the uncertain parameter in the observation process. In practical applications, the state value often has a one-to-one correspondence with its observed value [
36], thus the state observation model can be simplified as follows:
There are lots of uncertainties in the degradation process. To obtain better results, appropriate treatment of the abovementioned uncertain parameters is necessary.
As for the prognosis part, the Bayesian estimation method is an efficient recursive estimation technique that enables real-time and dynamic state estimation and prognosis with good robustness. Common Bayesian estimation methods include the particle filter algorithm, the Kalman filter algorithm, and related derivative methods [
37,
38,
39]. In the Bayesian recursive estimation process, Equation (15) is utilized to predict the next state value and obtain the corresponding prior estimate. Subsequently, with the acquisition of new observations, the prior estimate is updated using Equation (17) to derive the corresponding posterior estimate. Specifically, at time
t − 1, the posterior probability distribution function (pdf) of the state value is denoted as
. Then, by applying the state transition equation, the prior pdf
of the state at time
t can be derived, where
. Thereafter, after obtaining the observations
at time
t, the posterior pdf
at time
t is updated, and the mathematical equation can be expressed as:
where
represents the likelihood function of the state transition process, determined by Equation (15),
represents the likelihood function of the observation process, determined by Equation (17),
represents the normalization factor, which is calculated as follows:
In practice, analytical solutions for Equations (18) and (19) are often not available. The Particle Filter algorithm employs Monte Carlo methods to approximate the probability distribution using a set of particles
. The basic idea of Monte Carlo can be expressed as follows: when solving a problem that involves the probability of a certain random event occurrence or the expected value of a certain random variable, the probability of the event occurrence is approximated by the frequency of the event occurrence through “experimental” methods. Alternatively, the numerical characteristics of the random variable are obtained to estimate its expected value [
40]. The posterior pdf
can be expressed as follows:
where
represents the particle,
represents the weight of the corresponding particle,
N represents the total number of particles, and
is the Dirac delta function.
Since the posterior probability distribution is often multivariate, high-dimensional, nonanalytical, and difficult to sample directly, the importance sampling method is adopted, which is easy to implement. The weight calculation of particles is shown in Equation (22).
where
represents the importance distribution used. When using the probability distribution of state transition as the importance distribution, the weight calculation of particles can be simplified as follows:
From the above equation, it can be observed that the weight magnitude represents the probability of obtaining the corresponding observation value when the state value is taken as . In other words, particles with higher weights are more likely to generate the observed value. Throughout the entire process, prognosis information is incorporated into the particle distribution, while observation information is incorporated into the corresponding particle weights.
Normalize the weights thereafter:
During the recursive iteration process, it is common for the weight distribution to become increasingly skewed over time. As the iteration progresses, a small number of particles tend to have significantly higher weights, while the weights of other particles become negligible. This phenomenon is known as particle degradation. To address this phenomenon, resampling can be used as a solution. Additionally, to avoid the diversity loss of particles after resampling, which may result in an insufficient representation of the posterior probability distribution, the following resampling method is implemented. Randomly select a number u from the interval [0, 1] and sequentially sum the weights of the particles. In the resampling process, when the cumulative sum of weights of the first M − 1 particles is less than the generated random number u(, ), and the cumulative sum of weights of the M particles is greater than or equal to u(, ), the Mth particle is selected as the new particle after resampling. This ensures that particles with higher weights have a higher chance of being selected, while particles with lower weights have a lower chance of being selected. The resampling process is repeated N times to obtain the new particle set . After resampling, the weights of the particles are updated to .
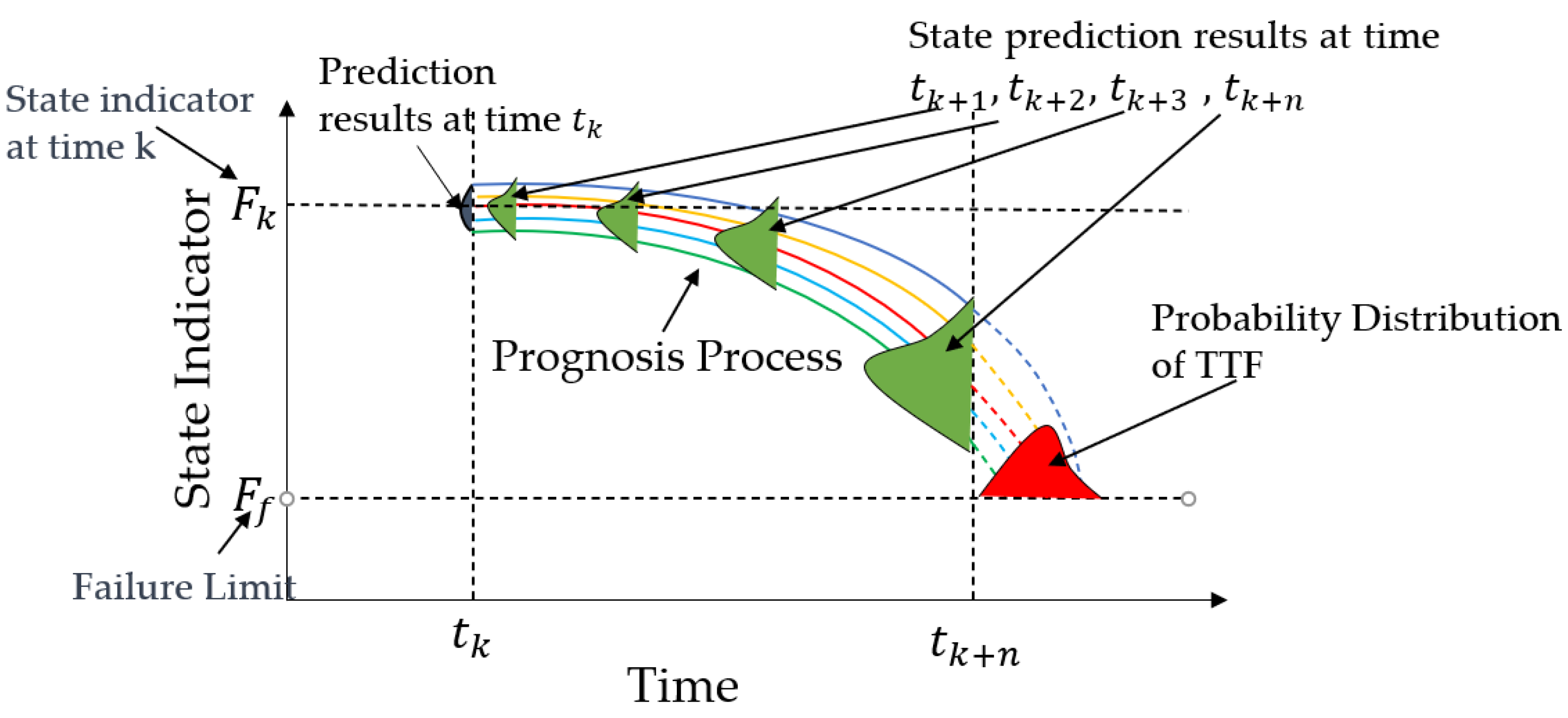
The purpose of life prognosis is to obtain the future development of the degradation process and then calculate the expected time to failure (TTF) for the state indicators to reach the failure threshold. In the prognosis, the estimation results at the current time are used as the initial values. During the prognosis stage, a multistep prognosis approach is used to recursively obtain the predicted values of state indicators at any future time, and the prognosis process continues until the predicted value of the state indicator exceeds the preset failure limit. Afterward, based on the prognosis results, the final TTF probability distribution can be obtained. As shown in
Figure 6, the green probability distribution presents the state prognosis results at times
tk+1,
tk+2, and
tk+3, and the red region represents the corresponding TTF probability distribution. The calculation process for a multistep prognosis can be expressed as follows:
where
represents the probability distribution of the state after the next m steps,
,
, and
represent the state transition process of the prognosis process. Afterward, the distribution of TTF is calculated based on the preset failure limit. The calculation process can be represented as follows:
where
represents the failure probability at time
t,
represents the failure threshold.
In multistep prognosis, the future observed values are not available in advance, making it impossible to perform posterior updates on the predicted values. As the prognosis progresses, the uncertain parameters in the model accumulate during the iteration process, which can impact the effectiveness of the prognosis results. The above analysis indicates that uncertain parameters have a significant impact on prognosis results, but the classic modeling method lacks theoretical descriptions of uncertainties, failing to provide appropriate values for uncertain parameters. Manual adjustments of parameter values are necessary to obtain acceptable results. Therefore, to address this issue, a differential modeling method can be utilized to accurately model the heat transfer process of condenser fouling, effectively quantify the uncertain parameters in the process, and maximize the effectiveness of the prognosis results.
Describe the change in state between any two adjacent moments using the Differential law:
where
g′(·) is the differential equation, and
represents the differential uncertainty present in the process. Transforming it into the state transition equation, the resulting state space model based on differential modeling is as follows:
The above equation utilizes the differential law to describe the actual dynamic process. After performing the differential operation on the original fault data, fitting the obtained differential feature allows for the determination of model parameters corresponding to g′(·) and uncertainty parameters corresponding to . The steps for model establishment and obtaining parameter values are as follows:
Data smoothing: Due to the influence of internal components, circuit elements, and external factors such as human or environmental interference, actual equipment often exhibits noise when using sensors to collect performance parameters. The presence of random noise makes it difficult to directly and accurately identify valid differential laws through differential operations. Therefore, at the beginning of establishing the differential model, it is necessary to smooth the data to eliminate the random noise present in the raw data and obtain a smoothed dataset that still retains the primary characteristic information from the original data.
Extracting and quantifying state observation uncertainty: Subtract the smoothed data from the original data to obtain the removed random noise and treat it as the uncertainty of the state observation process. According to its distribution, it is possible to quantify and determine the specific values.
Extracting dynamic differential features: The dataset obtained after smoothing, which retains the main information of the original data, can be utilized to construct a differential model. Performing a differential operation on the values corresponding to any two adjacent moments with a fixed interval, and then fitting the obtained differential data to construct the corresponding differential model g′(·).
Extracting and quantifying the uncertainty in the state transition: Using a similar method as mentioned above, extract the uncertainty in the state transition process. Subtract the results of the differential model from the actual differential data, and determine the value of based on the distribution of the differences.
Establishing a state transition model: Based on the obtained differential model g′(·), substitute it into Equation (28) to establish the corresponding state-space model. Afterward, the state space model can be combined with the Particle Filtering algorithm to predict the future state and RUL of the system.
4. Case Study
In the previous section, the theoretical aspects involved were explained. The following is a specific case to illustrate the above content.
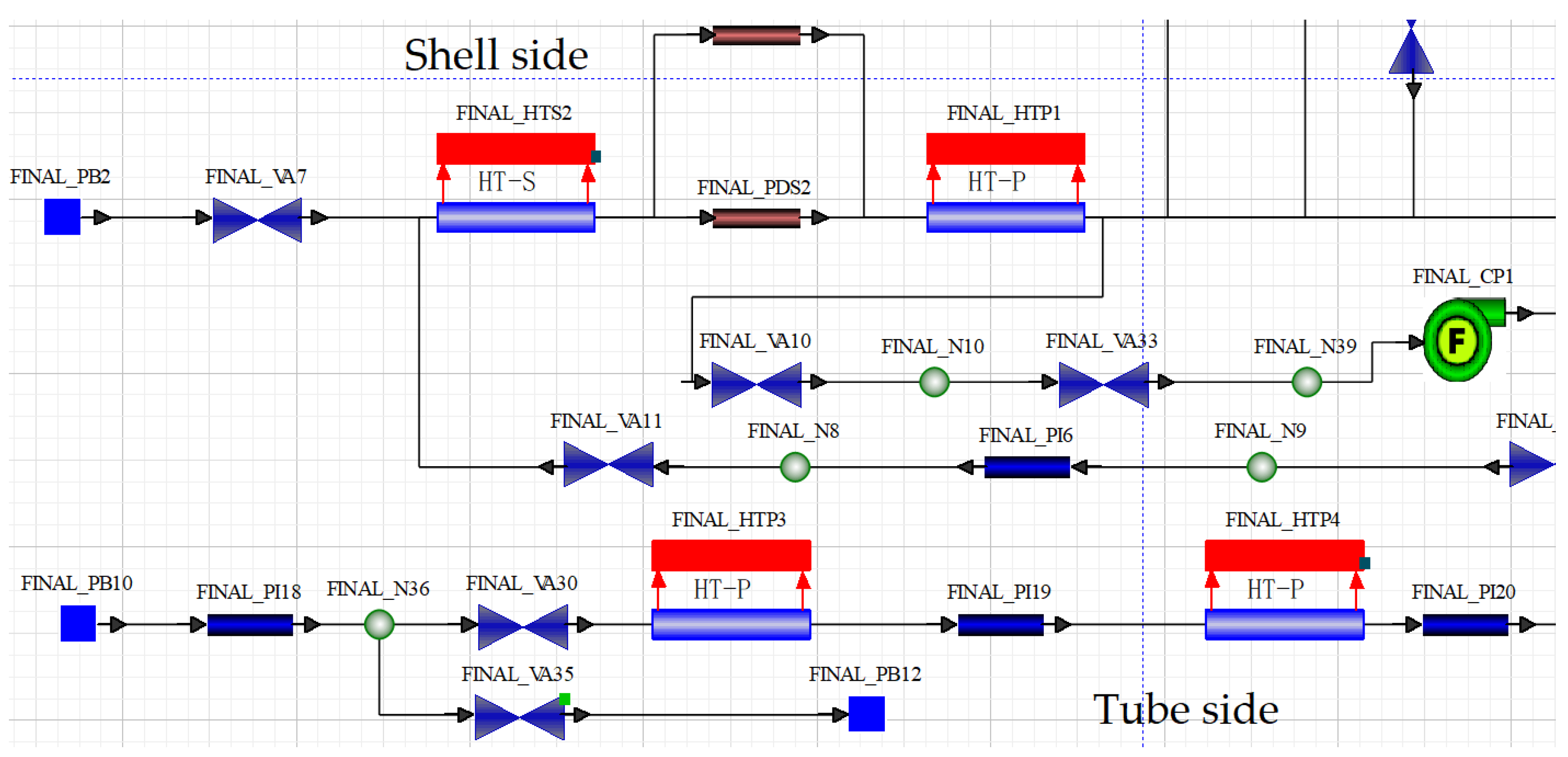
Based on the methods mentioned in
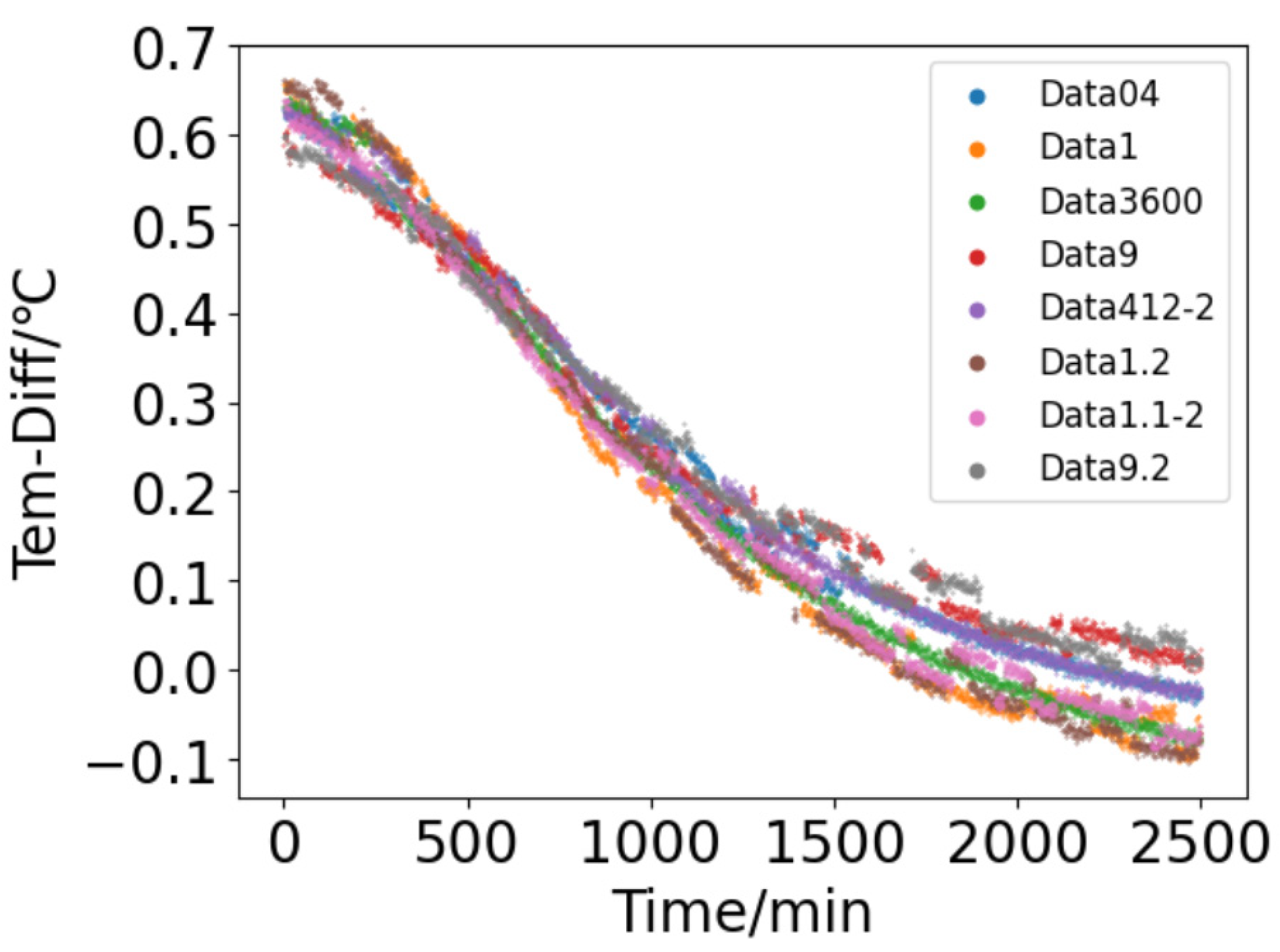
Section 2, the inlet and outlet temperatures of cooling water under the fouling fault can be obtained through simulation tools. The established simulation model has a condenser inlet temperature of 48.5 °C, a cooling water inlet temperature of 28 °C, and a cooling water flow rate of 129 kg/s. Under the condition of not changing the trends of fouling thermal resistance, adjust the size of thermal resistance in a certain proportion to simulate different fault scenarios and obtain multiple sets of fault data. To simulate the temperature data collected by the actual temperature sensor, noise is added to the calculated temperature data from the simulation model. The resulting data is shown in
Figure 7. The vertical axis represents the temperature difference between the inlet and outlet, measured in degrees Celsius (°C). (The data has been normalized.) The horizontal axis represents time, and the curve represents the changes of multiple sets of temperature difference data over time. The figure contains 8 sets of fault data under different conditions, labeled as DATA04, Data1, Data3600, Data9, Data412-2, Data1.2, Data1.1-2, and Data9.2.
For the heat exchange process of a condenser, the efficiency of the heat exchanger is defined as [
41]:
The denominator represents the maximum temperature difference between the fluids in the heat exchanger, while the numerator represents the larger of the actual temperature differences between the cold or hot fluids in the heat exchanger.
In the heat exchange process of the condenser mentioned above, the temperature difference of the cooling water plays a crucial role in determining the heat exchange efficiency. Specifically, the numerator of the heat exchange efficiency equation represents the temperature difference between the inlet and outlet of the cooling water. When the temperatures of the inlet steam and the inlet cooling water remain relatively constant, the heat exchange efficiency is directly influenced by the temperature difference between the inlet and outlet of the cooling water. As the temperature difference decreases, the heat exchange efficiency also decreases proportionally. To establish a failure limit for the condenser, a certain value can be set as a threshold for the temperature difference. When the temperature difference is below , the heat exchange efficiency also decreases to a certain extent, indicating a potential failure condition. The deposition of fouling will reduce the temperature difference between the inlet and outlet of the cooling water, which will reduce the heat transfer efficiency. Therefore, the change in temperature difference between the inlet and outlet of the cooling water can, to some extent, characterize the impact of fouling on the heat transfer process of the condenser.
4.1. Classic Modeling Method
For the classic modeling method, using a portion of the acquired fault data as the training set, the classic curve fitting method is employed to model the data. The mathematical form of the polynomial model can be expressed as follows:
where
is the temperature difference between the inlet and outlet of the cooling water, and
a = [
a0,
a1,
a2,
a3,
a4] are the coefficients of the model. Four datasets (Data04, Data3600, Data9, and Data1) from the fault data were selected as the training set, and the fitting results are presented in
Figure 8. The axes in
Figure 8 have the same meaning as in
Figure 7, and the black solid line represents the results obtained from the fitted model calculation. From the figure, it can be observed that the polynomial model fits the actual values very well, indicating that the fitted model effectively describes the changing process of the temperature difference between the inlet and outlet of cooling water.
Equation (15) represents the recursive relationship between states, so it is necessary to perform certain transformations on Equation (31). Firstly, for the temperature difference
at time
t + 1, it can be expressed as follows:
After the mathematical transformation of Equations (31) and (32), the following recursive relation can be obtained:
Then, incorporating the uncertain parameter in the model, the state space model based on the polynomial model can be expressed as follows:
where
and
are Gaussian noises with zero mean and standard deviations of
and
, respectively.
After establishing a suitable state space model, particle filter algorithms can be combined to predict the future development status of state indicators. Based on the significant impact of uncertain parameters on the prognosis results, it is necessary to make reasonable choices for their values. According to the modeling process mentioned above, it can be seen that the classic modeling method lacks a theoretical description and analysis of uncertain parameter values, and the parameter settings are often subjective. As shown in
Figure 9,
Figure 10 and
Figure 11, the test results obtained by using different uncertain parameters for prognosis are shown. The model parameters (
a= [
a0,
a1,
a2,
a3,
a4]) are kept constant, and the standard deviation of the difference between the curve fitting result and the actual data is 0.0359. Based on their order of magnitude, three levels of uncertain parameters are selected for testing: 0.01, 0.001, and 0.0001. The predicted results are presented in
Figure 9,
Figure 10 and
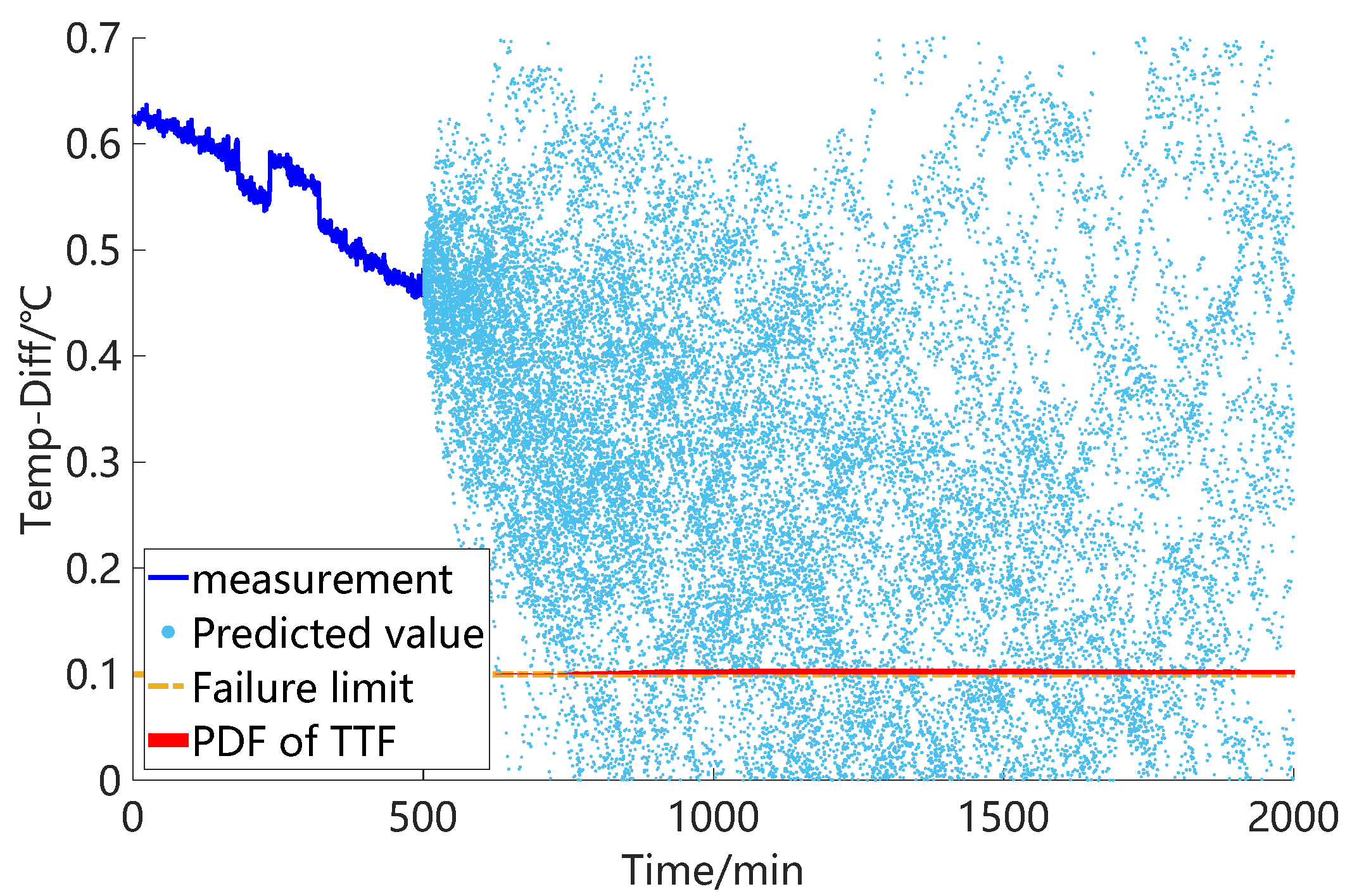
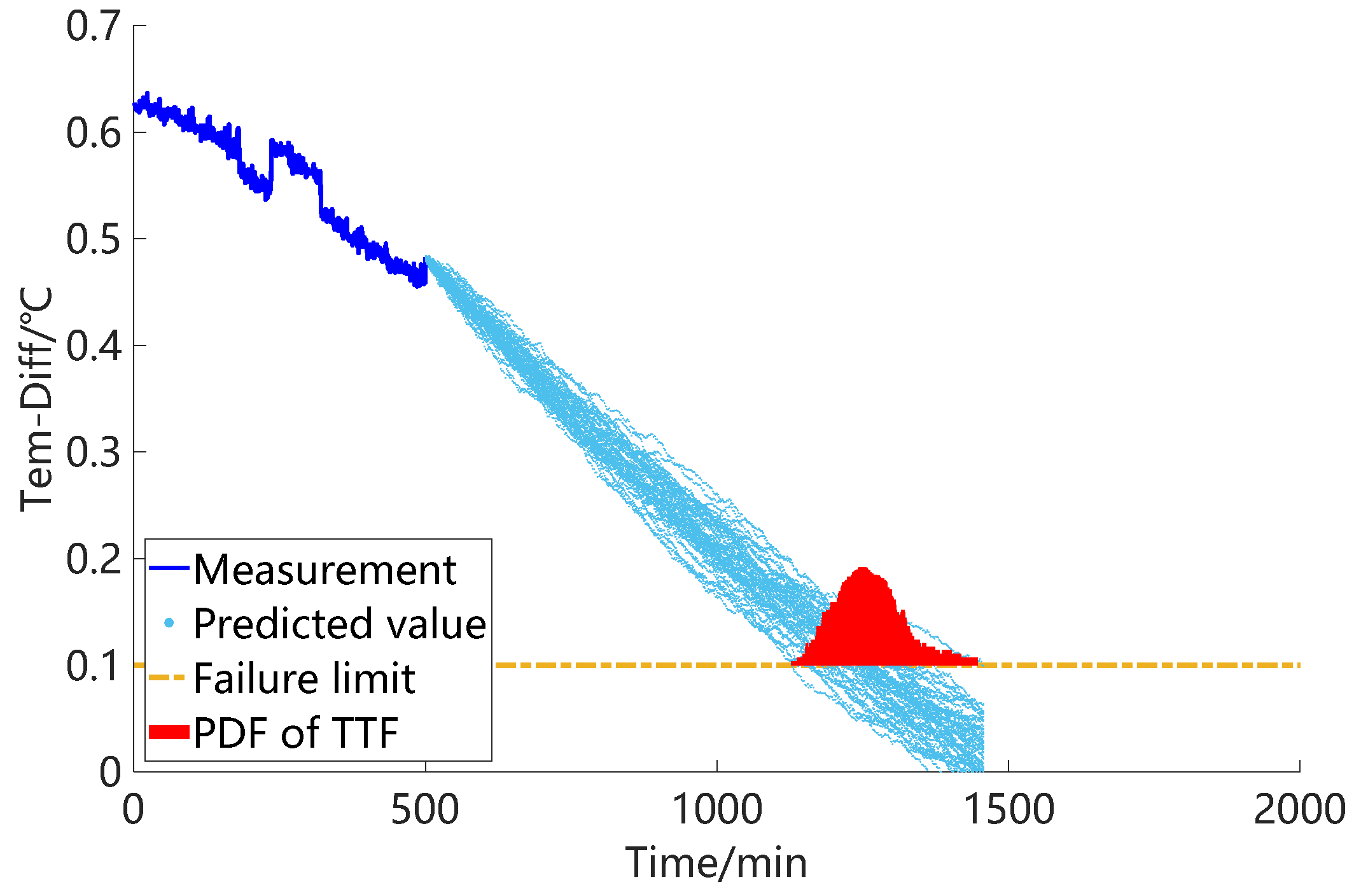
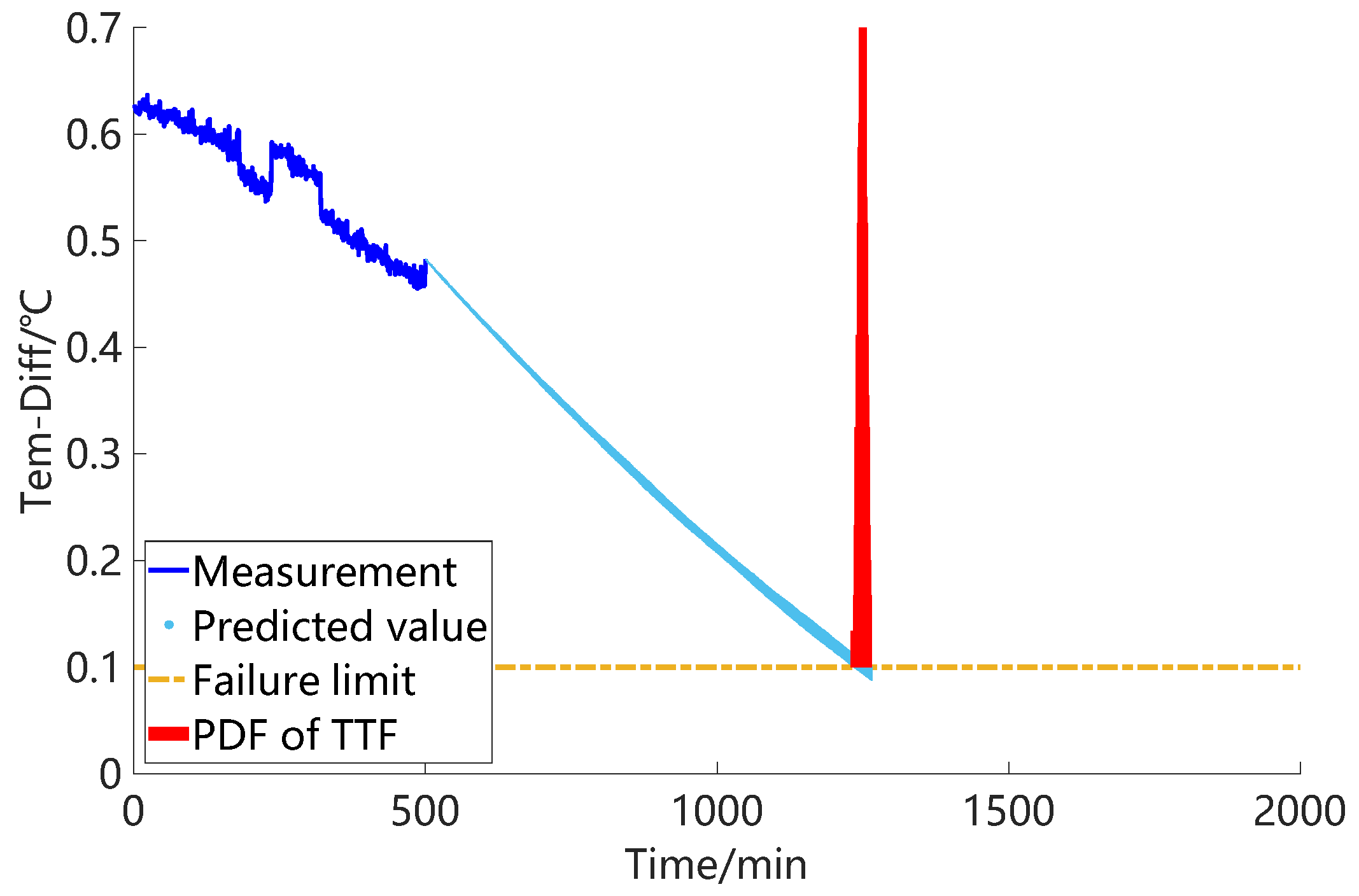
Figure 11, respectively. The dark blue line in the figure represents the measurement data, the light blue dots represent the predicted results obtained after each particle filter, and the red area represents the probability distribution of TTF. Through the comparison of the three results, it can be observed that reducing the uncertain parameters has a significant impact on the prognosis results. As the uncertain parameters decrease, the predicted values of the state indicators become more concentrated, indicating higher confidence in the prognosis. Additionally, the confidence interval of the TTF probability distribution also decreases, indicating increased accuracy.
To provide a better reference for operation and maintenance, the corresponding RUL can be predicted and calculated. RUL refers to the duration from the predicted start time until the TTF is reached. In practical applications, prognoses are often initiated when the system’s performance has degraded significantly. This is conducted by setting an initial threshold to determine whether performance deterioration has occurred. This threshold determines the starting prediction time, denoted as
Ts. However, for fouling faults in the condenser, the accumulation of fouling in the coolant occurs continuously once the condenser is in use. Therefore, in the case of condenser fouling faults,
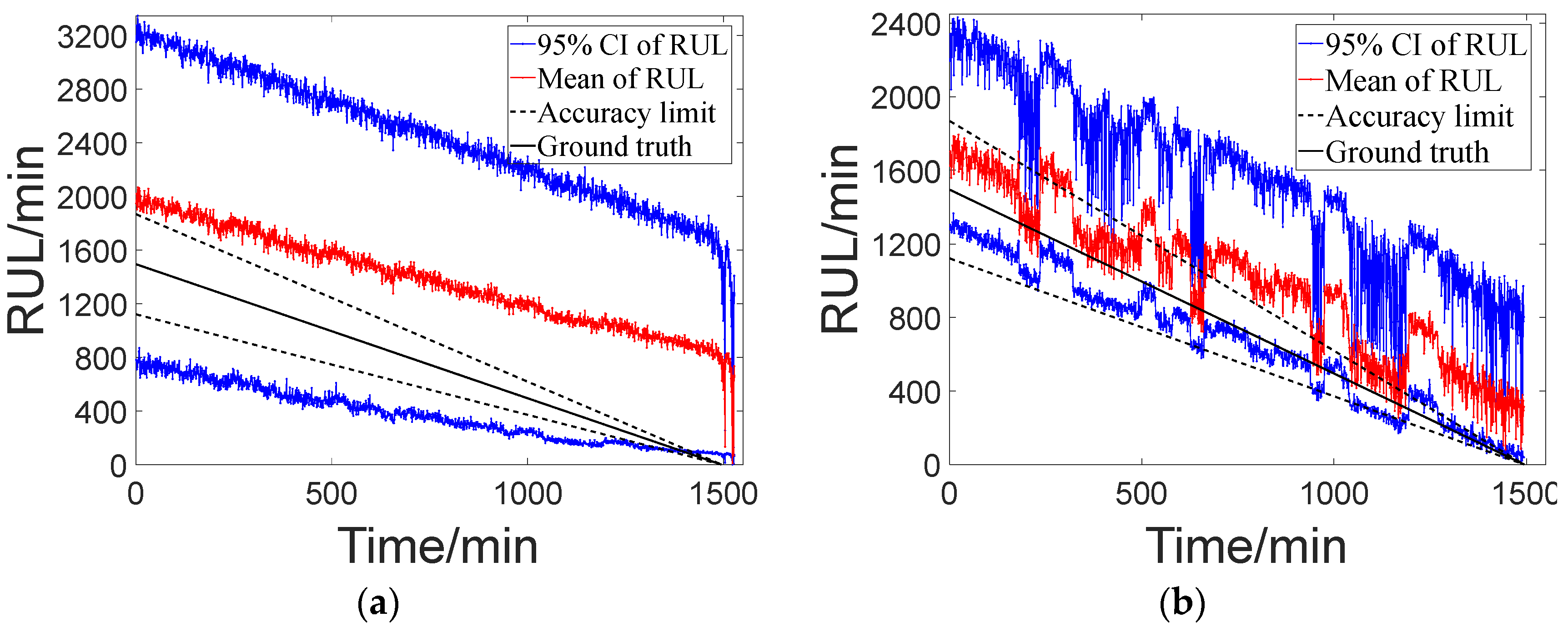
Ts can be set to 0, indicating that predictions can be made from the beginning of the system’s operation. The results of the corresponding RUL obtained through predictive operations throughout the entire cycle under various settings of uncertain parameters are depicted in
Figure 12. In the figure, the solid black line represents the true values of the RUL. The black dashed line represents the upper and lower limits of the error (with α set to 0.25). The red line represents the mean of the prognosis results, while the blue line represents the range of the results. Based on the standard deviation (0.0359) of the above fitting results, the prognosis results obtained by setting uncertain parameters (0.01) of the same magnitude are poor, and satisfactory prognosis results cannot be achieved. As the uncertain parameters decrease, there is an improvement in the predictive performance of the RUL.
Two performance evaluation indicators,
CMAPE (cumulative mean absolute percentage error) and
CMPCIL (cumulative mean percentage 95% confidence interval length), are employed to assess the overall performance of the prognosis results throughout the entire cycle.
CMAPE takes into account the temporal accuracy of the prognosis results, while
CMPCIL considers the temporal precision of the prognosis results. The calculation methods for both are as follows:
where
is the starting time of the prognosis,
is the end time of the prognosis,
represents the RUL result obtained after executing the prognosis at time
,
represents the actual RUL result at time
,
represents the upper limit of the confidence interval for the prognosis result at time
,
represents the lower limit of the confidence interval for the prognosis result at time
. The two evaluation indicators,
CMAPE and
CMPCIL, consider all prognosis results from the start to the end of the prognosis phase and are subjected to arithmetic averaging.
The performance testing was conducted on multiple datasets, and the calculated results for the indicators are shown in
Table 1. The table showcases the variation in prognosis performance as the values of
and
change. The test results from multiple datasets further indicate that setting uncertain parameters based on the standard deviation of the curve fitting results does not yield effective results. As the parameters decrease,
CMAPE and
CMPCIL show significant improvements, indicating a substantial enhancement in prognosis performance. However, when the parameters reach a sufficiently low value, further reducing the settings only leads to improvements in precision but marginal gains in the accuracy of the prognosis results. The aforementioned results indicate that, when using the prognosis method based on classic modeling, the setting of uncertain parameters has a significant impact on the prognosis results. But obtaining appropriate parameter values during the modeling process is not directly achievable, and it requires manual adjustment to obtain suitable values.
4.2. Differential Modeling Method
According to the performance test results, it is evident that the setting of uncertain parameters significantly affects the prognosis’s performance. Prognosis methods based on classic modeling can achieve acceptable results when uncertain parameters are appropriately configured. Indeed, the process of obtaining appropriate values for uncertain parameters often involves multiple manual adjustments and lacks a clear determination of the optimal values and quantification criteria for these parameters. The differential modeling method can effectively address such issues. Follow the differential modeling steps mentioned in the previous section to establish the differential model and quantify the uncertain parameters.
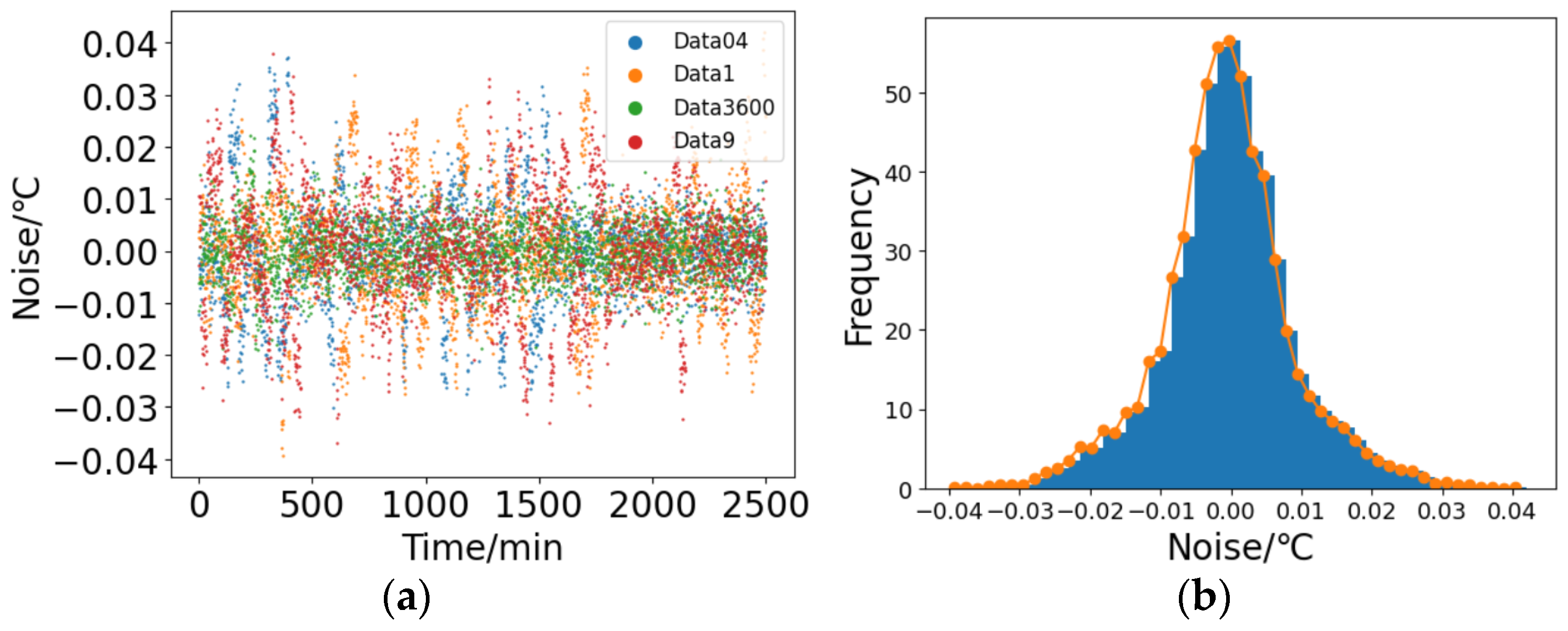
According to Step 1, the Savitzky–Golay algorithm is used to smooth the data. Random noise in the original data can be eliminated. The obtained random noise is shown in
Figure 13a. The vertical axis in the figure represents the magnitude of the noise.
Figure 13b shows the statistical distribution of the noise, and it can be seen that it resembles a Gaussian distribution. The “Frequency” axis represents the frequency of the noise in the statistical sense. Based on its distribution and the standard deviation calculated as 0.0094,
can be set as this standard deviation. i.e.,
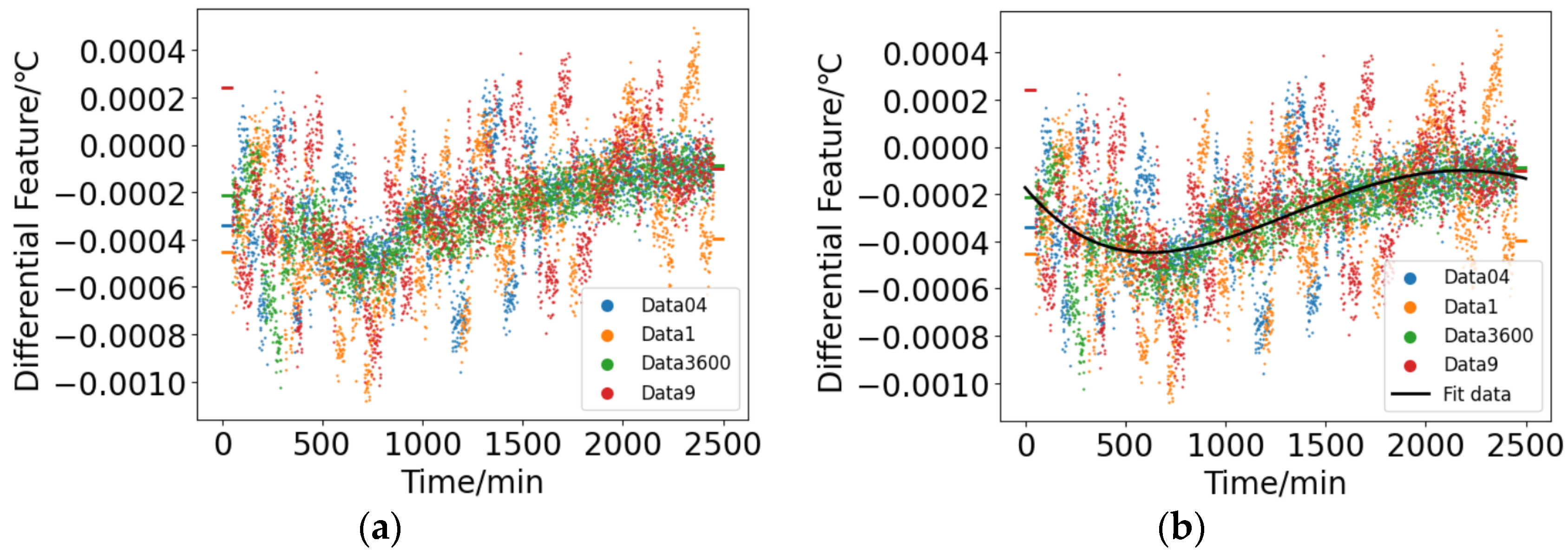
. According to Step 3, the differential operation is performed on the smoothed dataset, and the results are shown in
Figure 14a. The vertical axis in the figure represents the magnitude of the differential feature. The distribution range of this is primarily within [0.0002, −0.001]. This range is smaller in magnitude compared to the noise depicted in
Figure 13a, indicating that the differential feature is susceptible to being overwhelmed by random noise, making it challenging to directly extract it. From the figure, it can be seen that the differential feature exhibits a clear time-varying pattern. Therefore, it is possible to perform curve fitting on the differential data to construct a corresponding differential model. The results of this modeling process are illustrated in
Figure 14b. The black curve in the figure represents the fitting results of the differential model.
The mathematical model obtained by fitting the differential feature using a 4-order polynomial model is as follows:
where
b = [
b0,
b1,
b2,
b3,
b4] are the coefficients of the differential model.
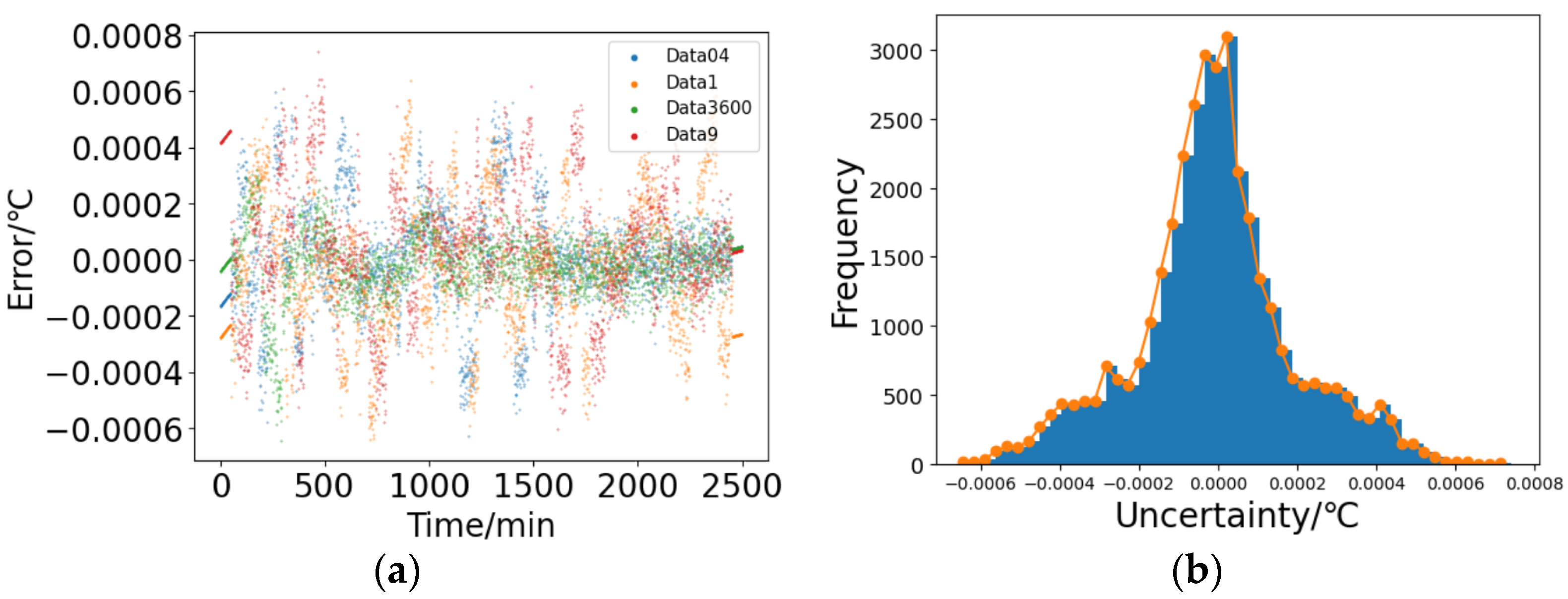
The results obtained by subtracting the fitted data from the original data in
Figure 14b are depicted in
Figure 15a. The vertical axis in the figure represents the magnitude of the error between the calculated results of the differential model and the actual differential feature.
Figure 15b shows the statistical distribution of the error, where the “uncertainty” axis also represents “error/°C”. Similarly, based on its distribution, it closely resembles a Gaussian distribution. Therefore, it can be treated as the uncertainty in the state transition process, and its standard deviation is calculated to be
. i.e.,
. Based on the fitted
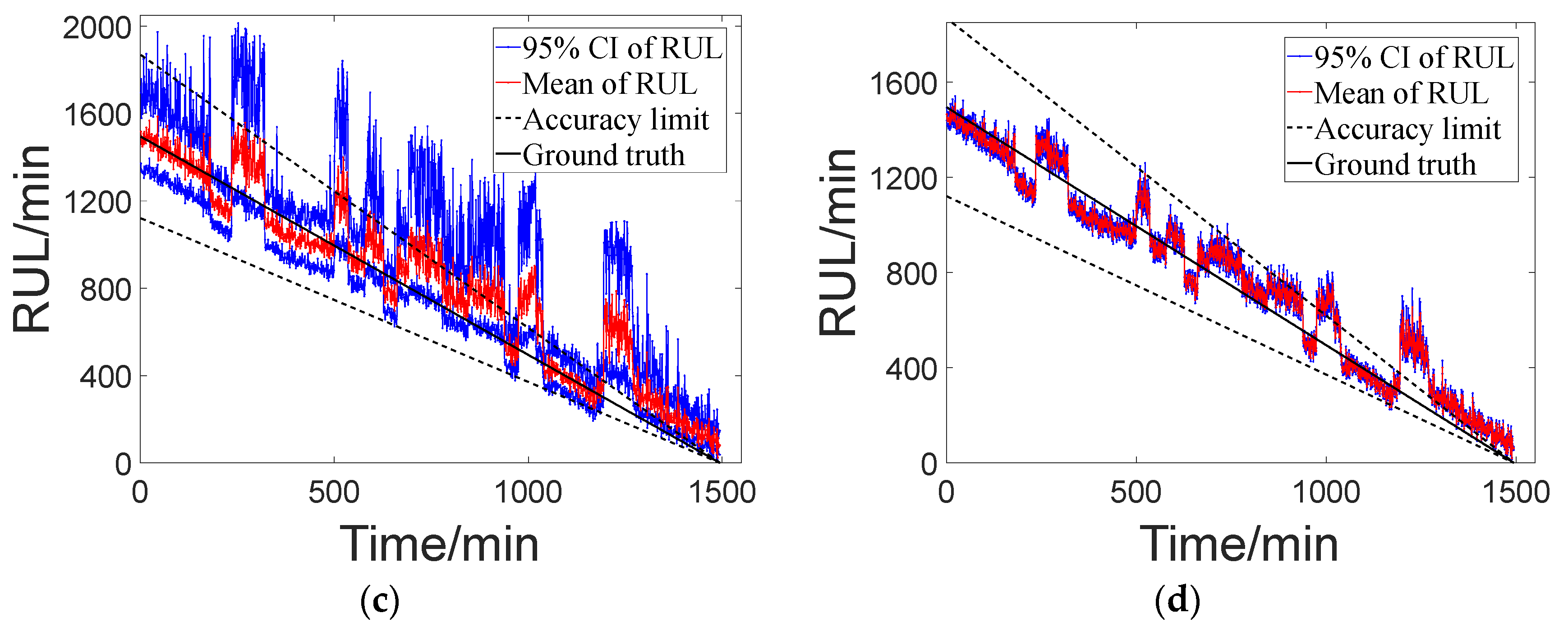
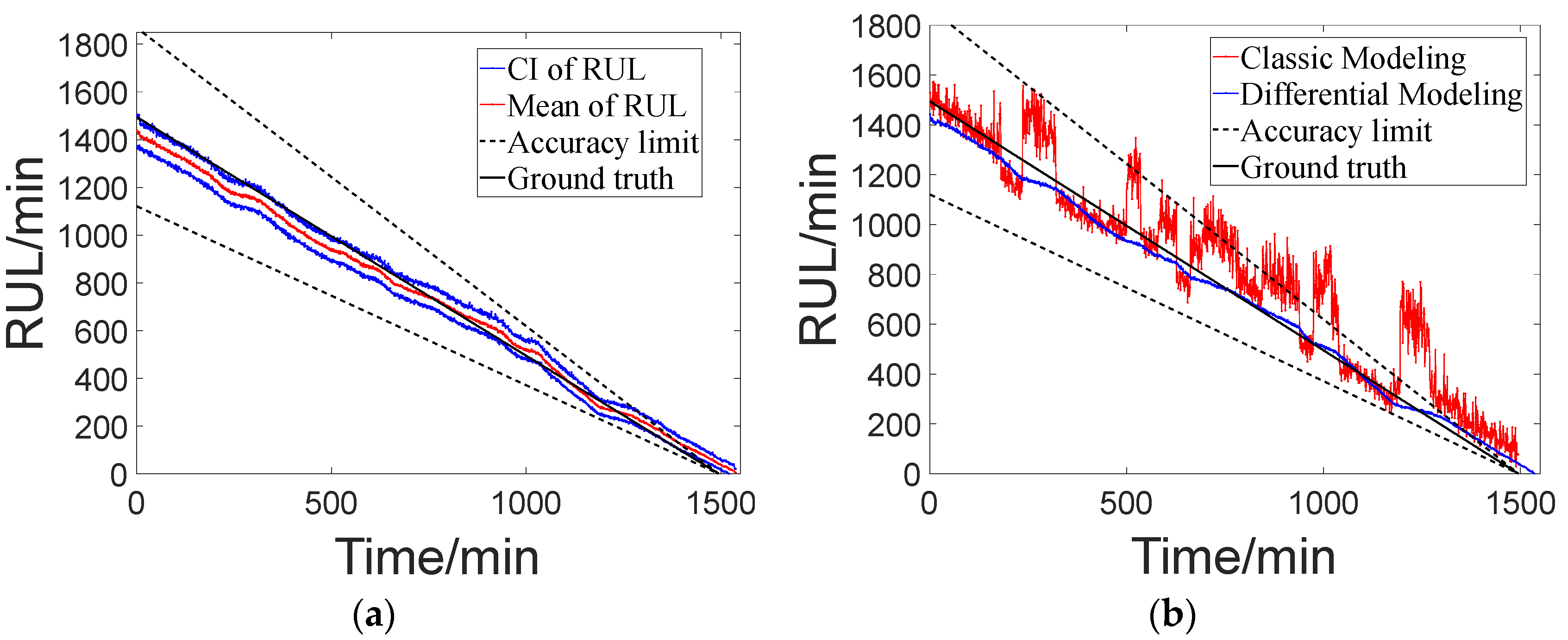
g′(·), the corresponding state transition model is established, and then combined with particle filtering for prognosis. The predicted RUL results are shown in
Figure 16a.
Compared with the classic method, the prognosis method based on differential modeling can simultaneously obtain the specific settings of model parameters and uncertain parameters. Based on the comparison of the prognosis results in
Figure 16b, the red line represents the prognosis results based on classic modeling with uncertain parameters of 0.0005, while the blue line represents the prognosis results based on differential modeling. The latter demonstrates an advantage in terms of stability in the prognosis results. In prognosis results based on classic modeling, when dealing with data that contains noise, the final results often exhibit significant random fluctuations. Similarly, performance testing was conducted on multiple test datasets, and the evaluation indicator calculation results obtained are shown in
Table 2. The best
CMAPE reached 0.09, with an average value of 0.35. Compared to the classic modeling method, the accuracy of the prognosis results was further improved, and the best
CMPCIL reached 0.13, with an average value of 0.18. Based on this, it can be seen that the prognosis method based on differential modeling can achieve superior results in the prognosis of condenser fouling. It possesses excellent modeling capabilities and effective management of uncertainties, eliminating the need for manual adjustment and optimization of parameters to obtain acceptable prediction performance.





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}