

Attention-Focused Machine Learning Method to Provide the Stochastic Load Forecasts Needed by Electric Utilities for the Evolving Electrical Distribution System

Abstract
:1. Introduction
- (1)
- The method provides automated meter infrastructure (AMI) data-driven hourly forecasts at the distribution transformer level with much greater spatial and temporal resolution compared to past practices and available research.
- (2)
- It delivers the data required to develop and deploy NWA solutions and microgrids to serve smaller pockets of load.
- (3)
- It creates the visibility needed to avoid reliability, power quality, and protection issues due to changing customer needs.
- (4)
- It establishes the fundamental basis for an integrated framework to determine the likelihood of occurrences using stochastic methods.
2. State of the Art
2.1. Overview
2.2. Short-Term Forecasts
2.3. Large Area Forecasts
2.4. Representative Load Shapes
2.5. State of the Art Summary
2.6. Influence on Current Work
3. Method Overview and Development
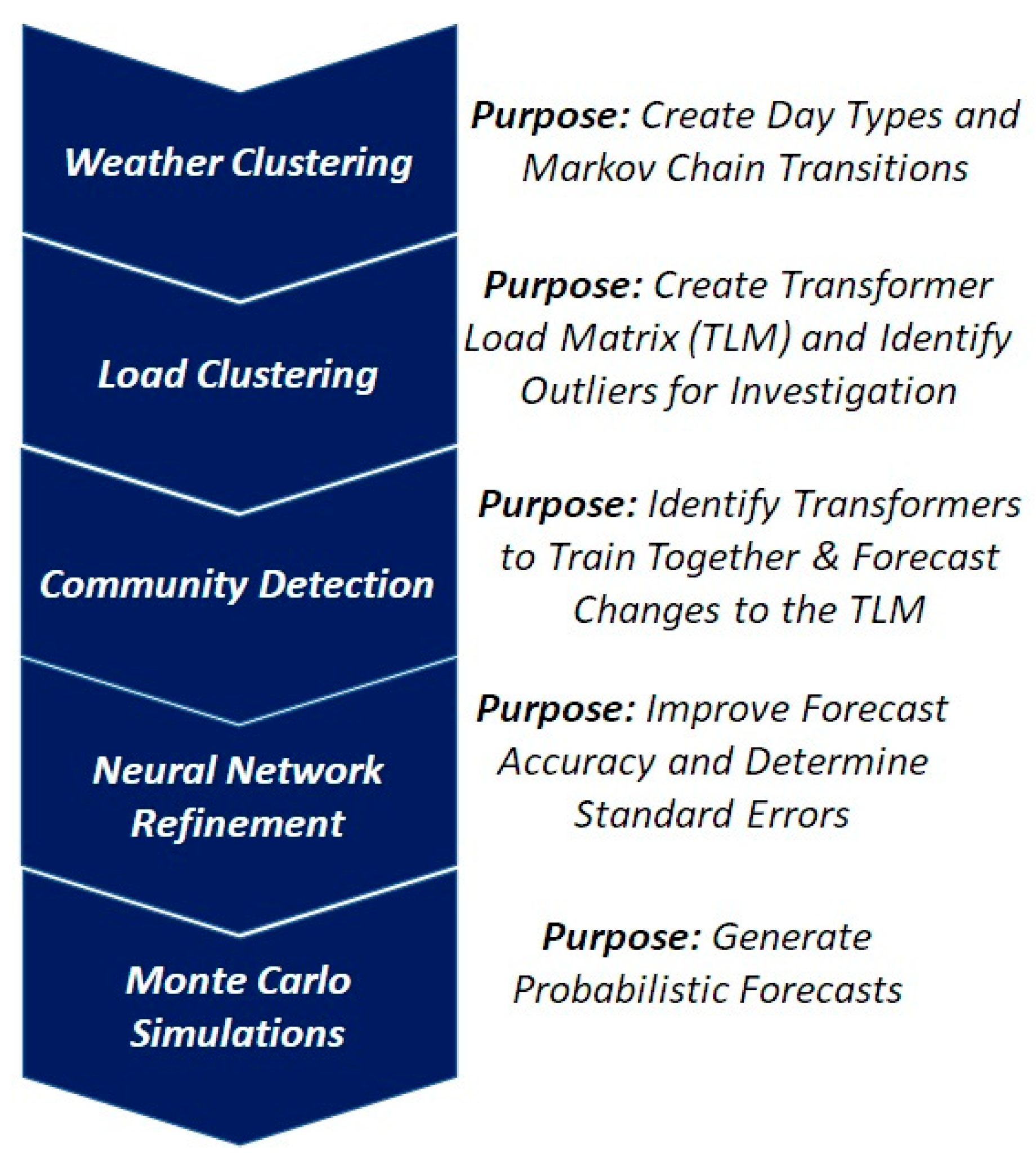
3.1. Method Overview
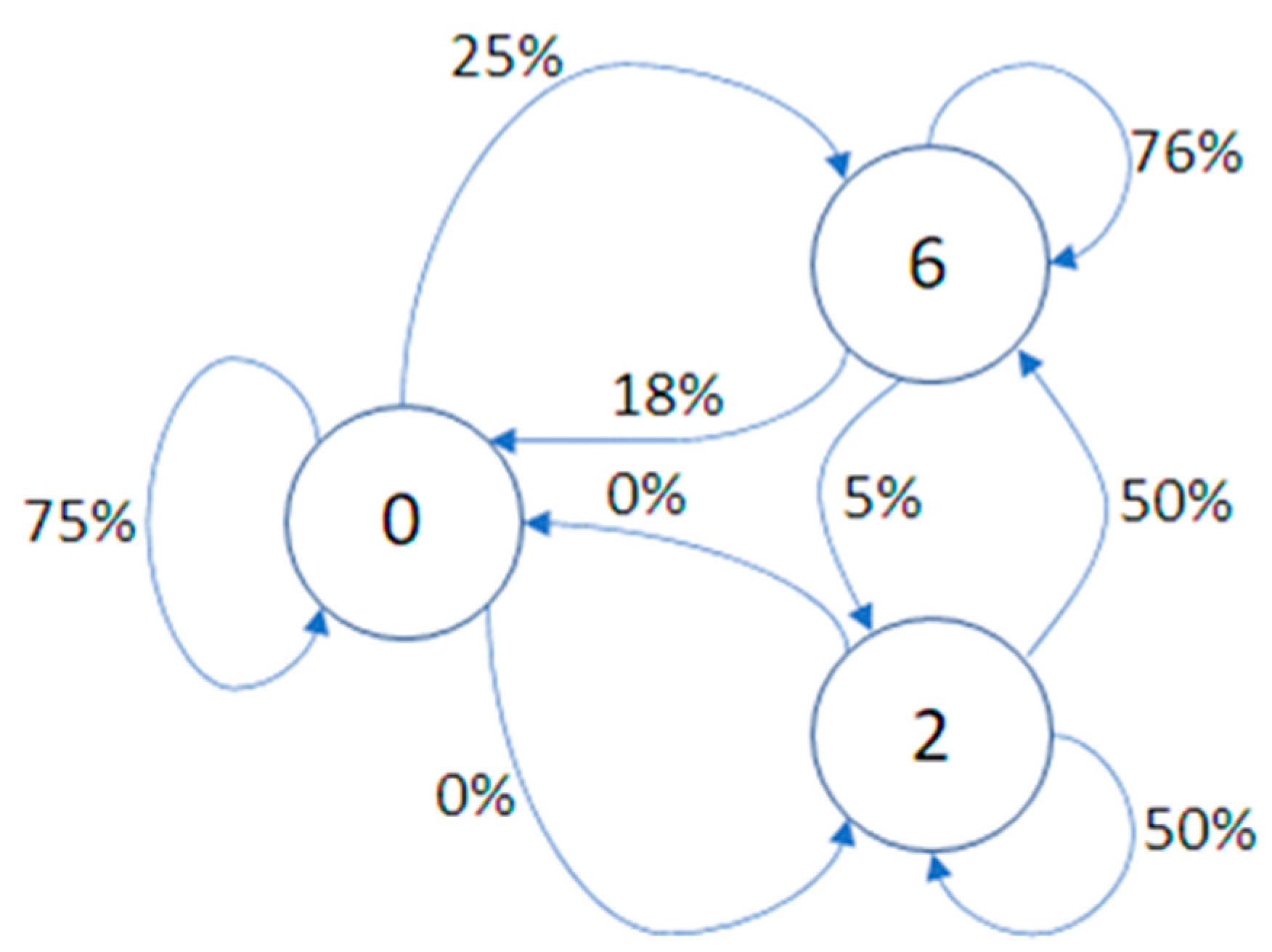
3.1.1. Weather Clustering
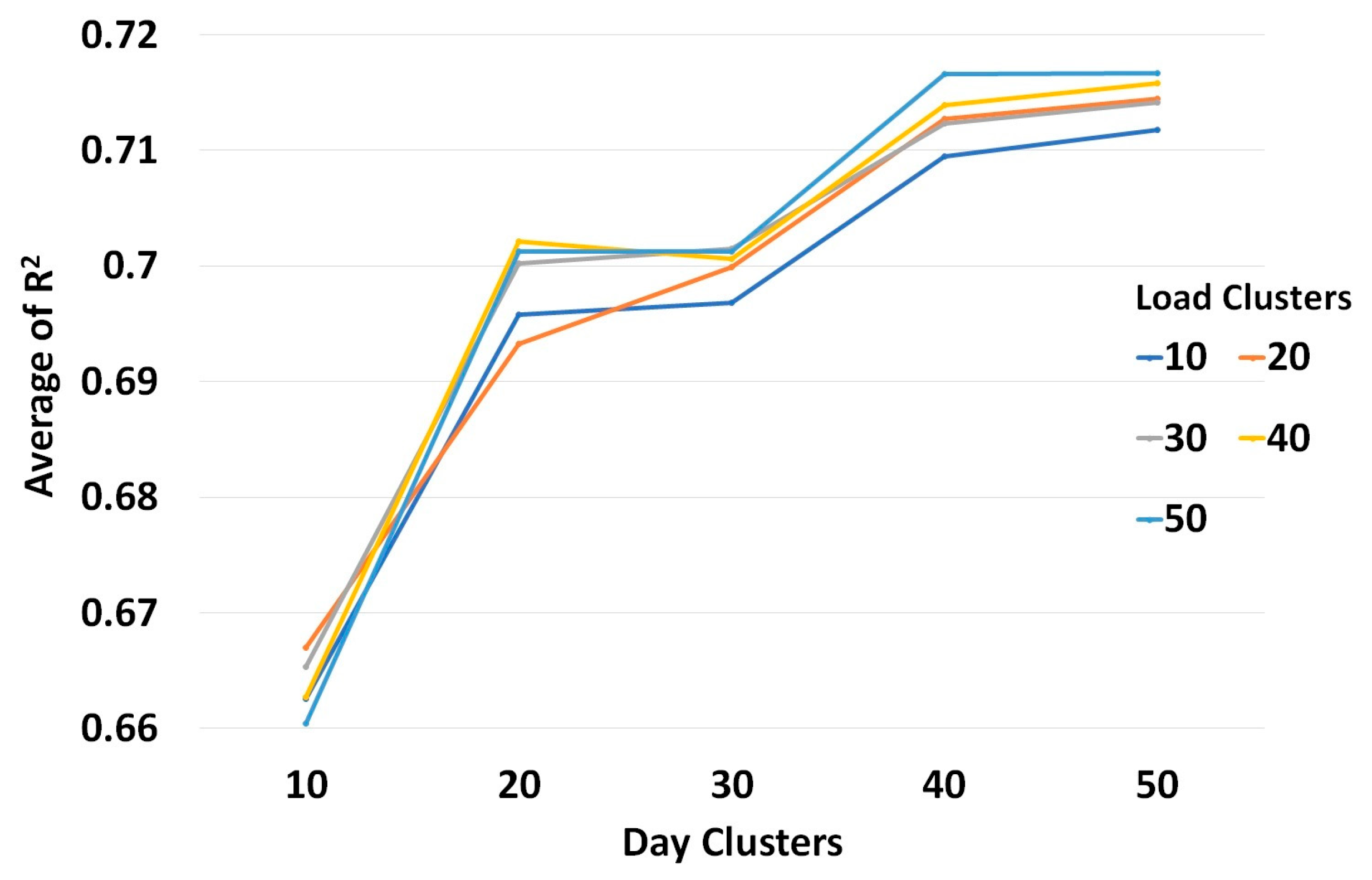
3.1.2. Load Clustering
3.1.3. Community Detection
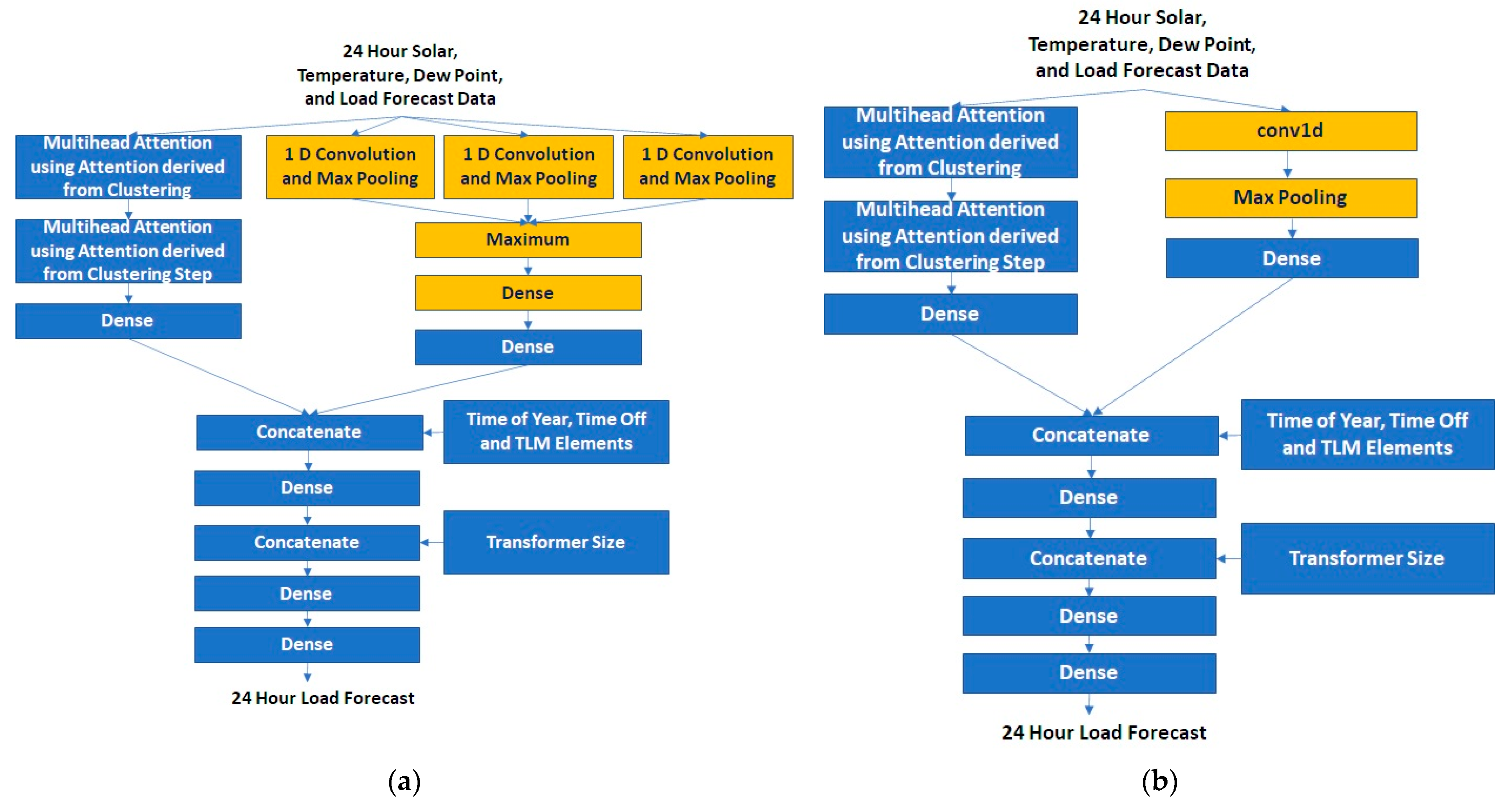
3.1.4. Neural Network Refinement
3.1.5. Monte Carlo Simulations
3.2. Development Approach and Datasets
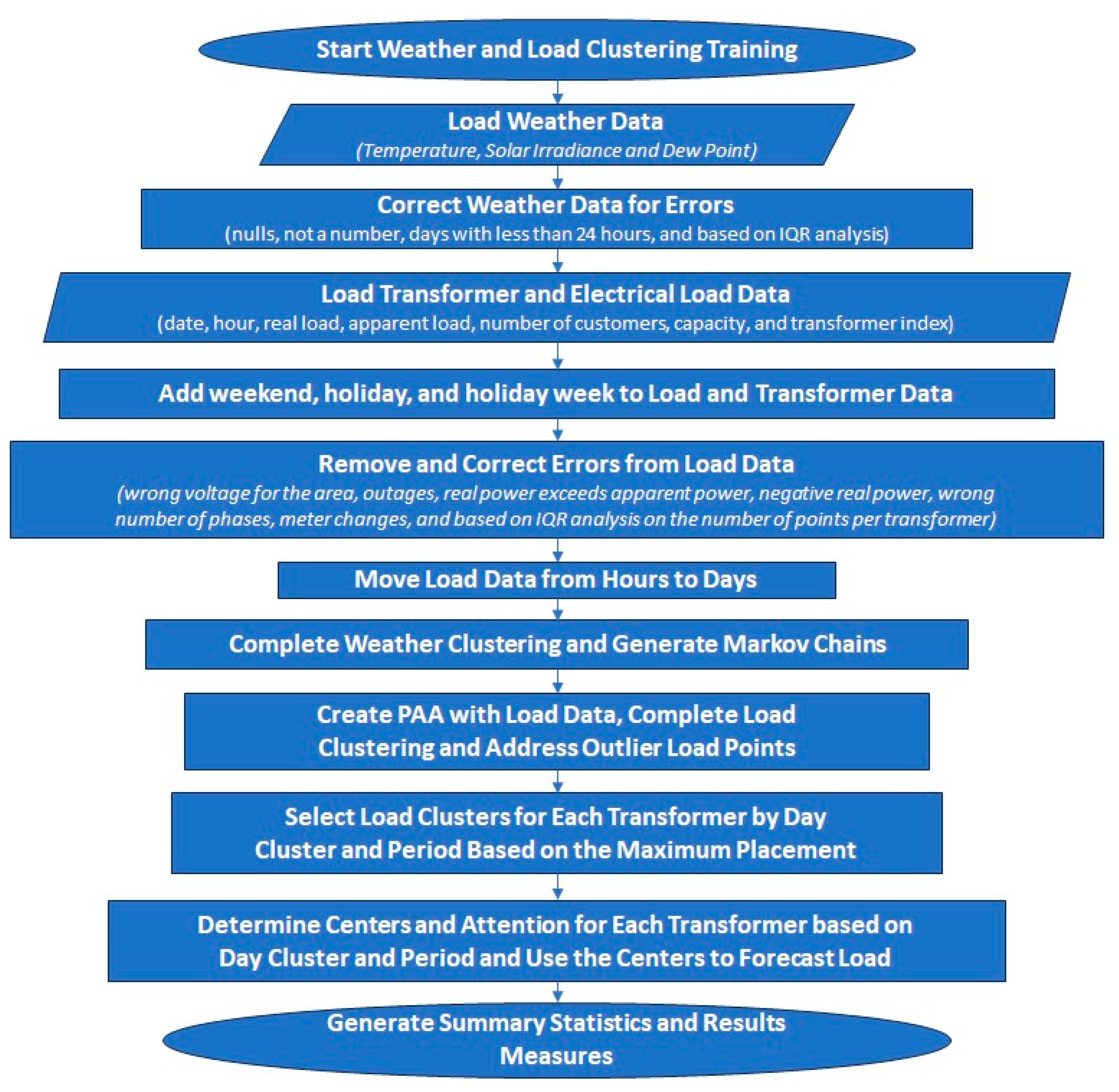
4. Weather and Load Clustering
4.1. Purpose
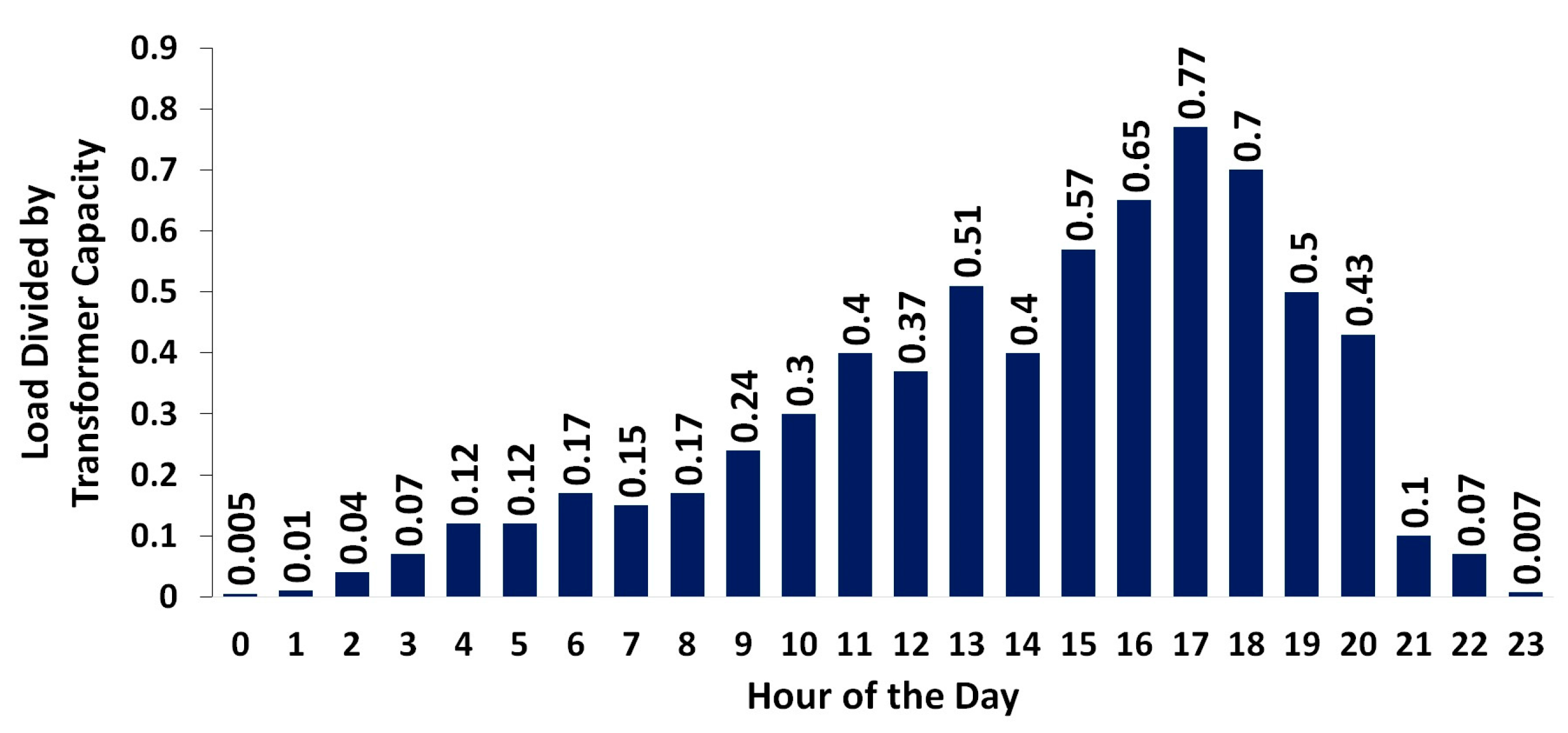
4.2. Influence of Weather
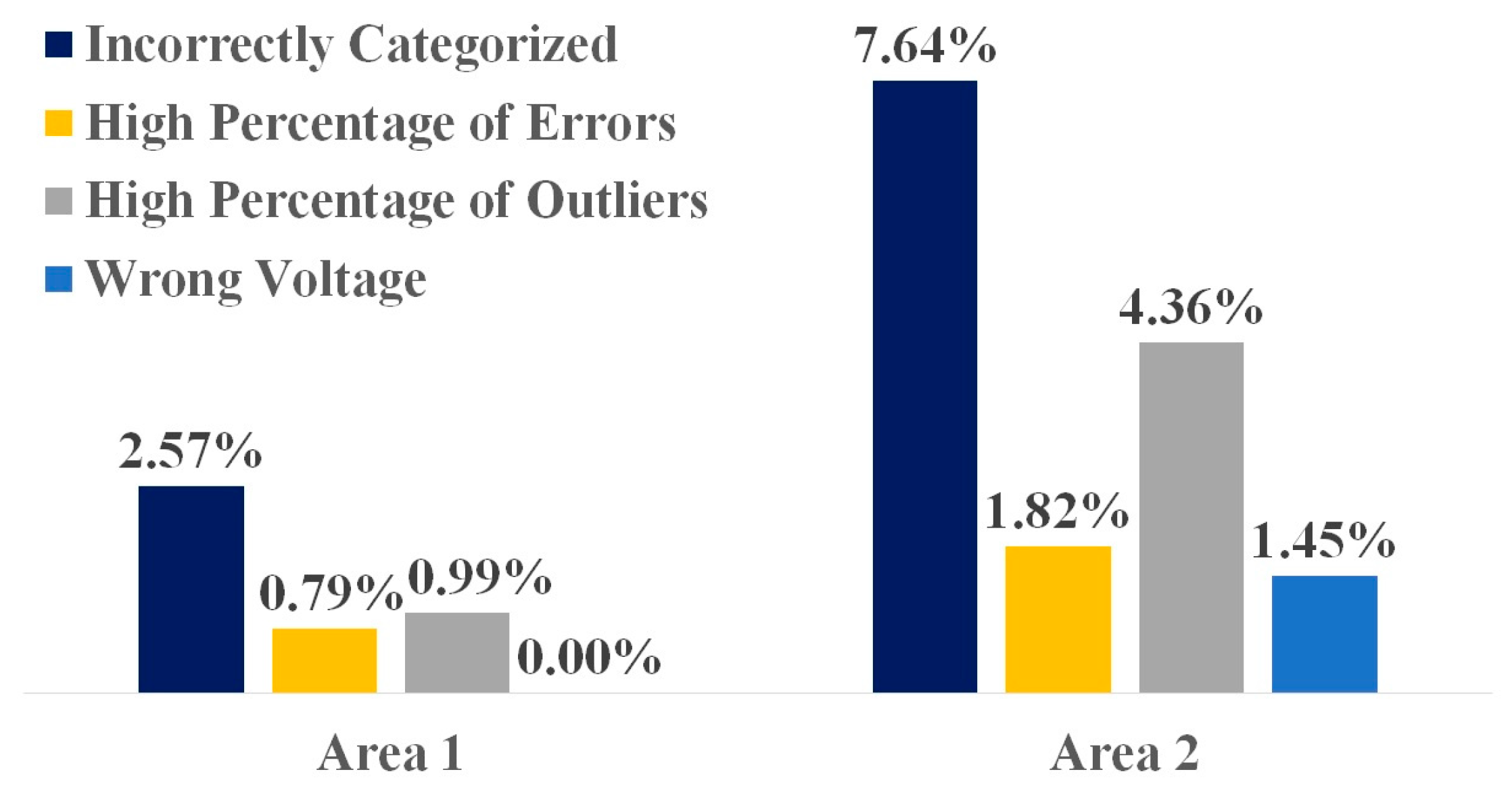
4.3. Error and Outlier Detection and Correction
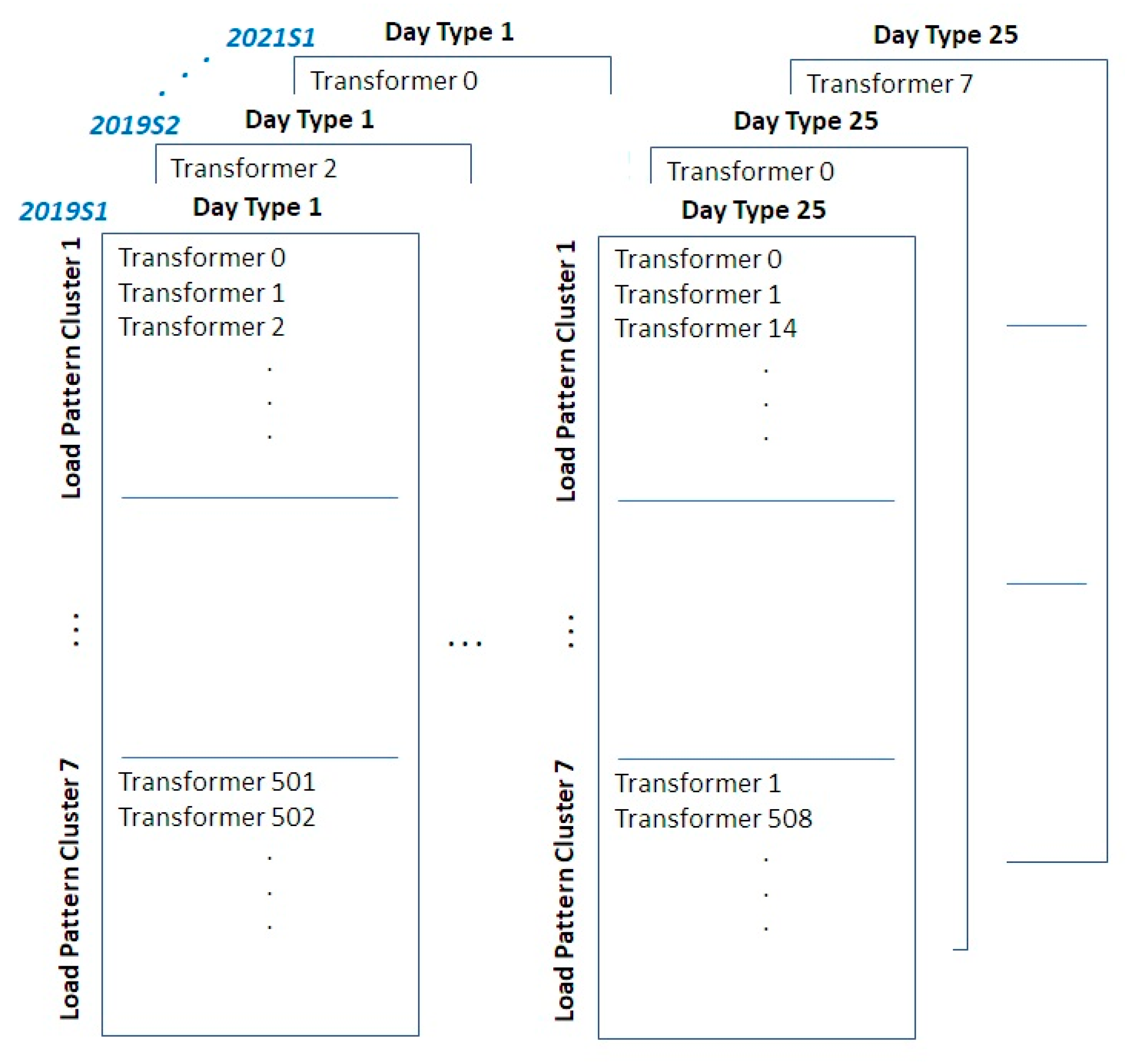
4.4. Clustering Methods for Load
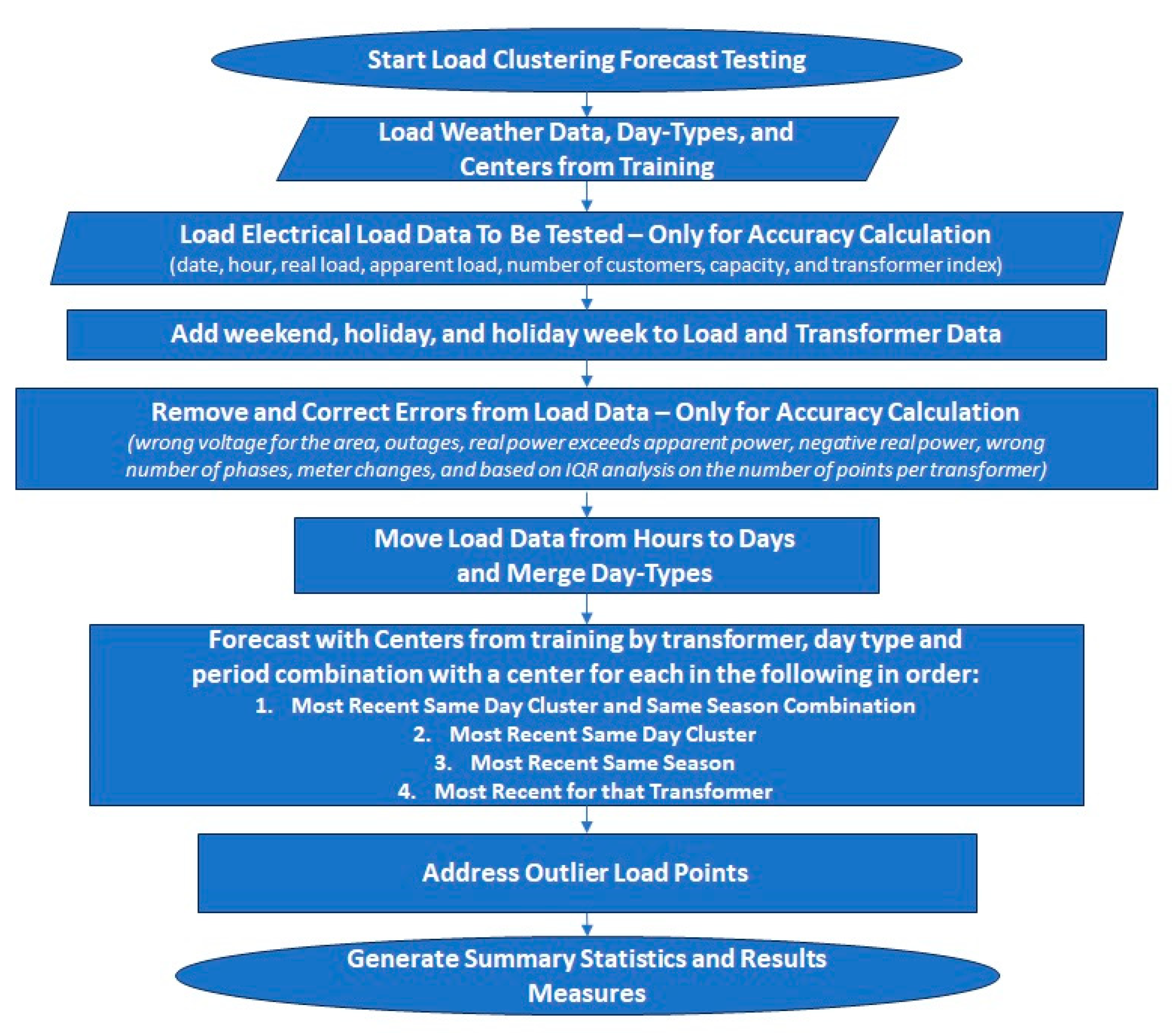
4.5. Process Details
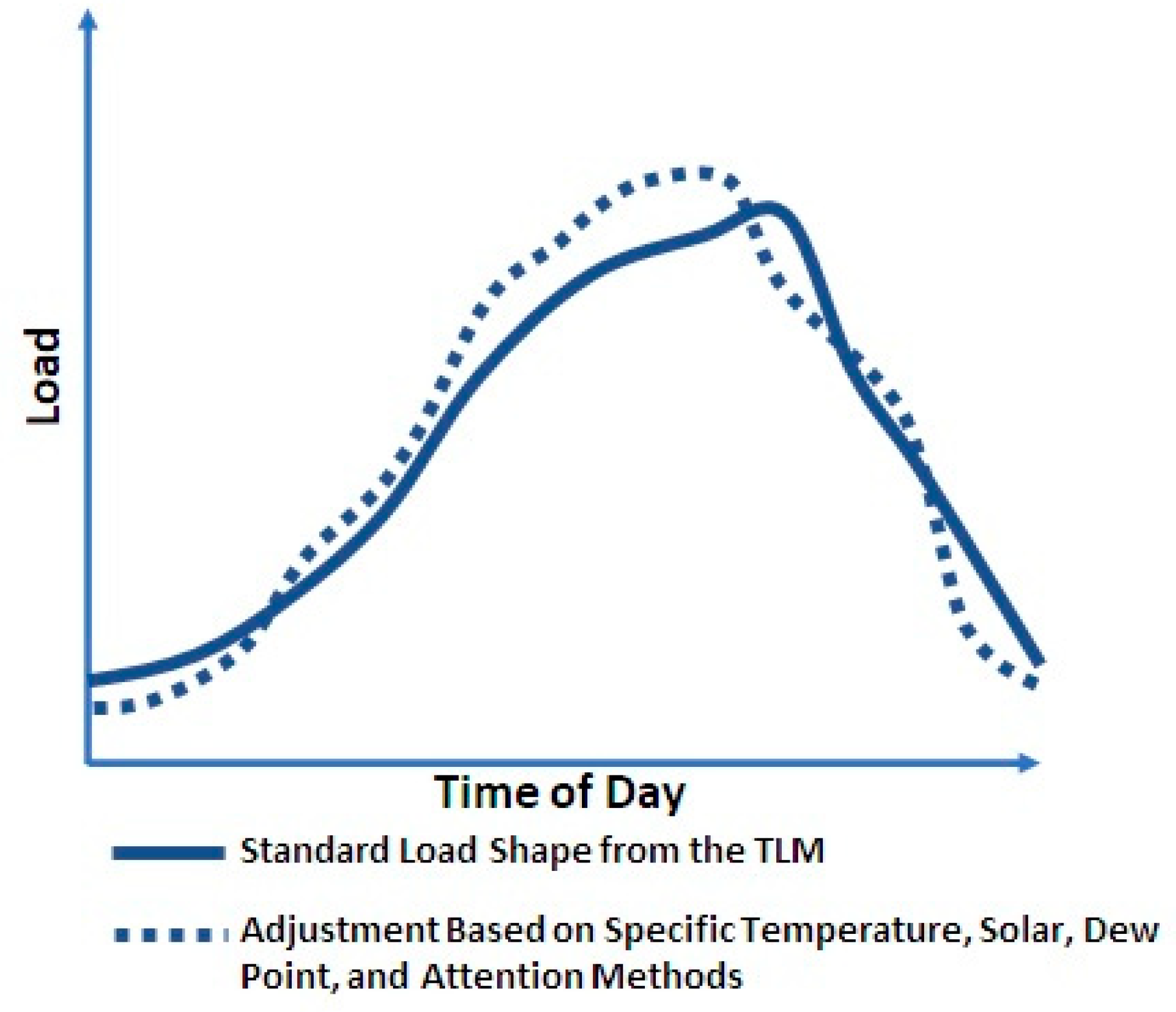
4.6. Attention
4.7. Conclusions
5. Community Detection and Neural Network Refinement
5.1. Purpose
5.2. Neural Network Areas of Focus
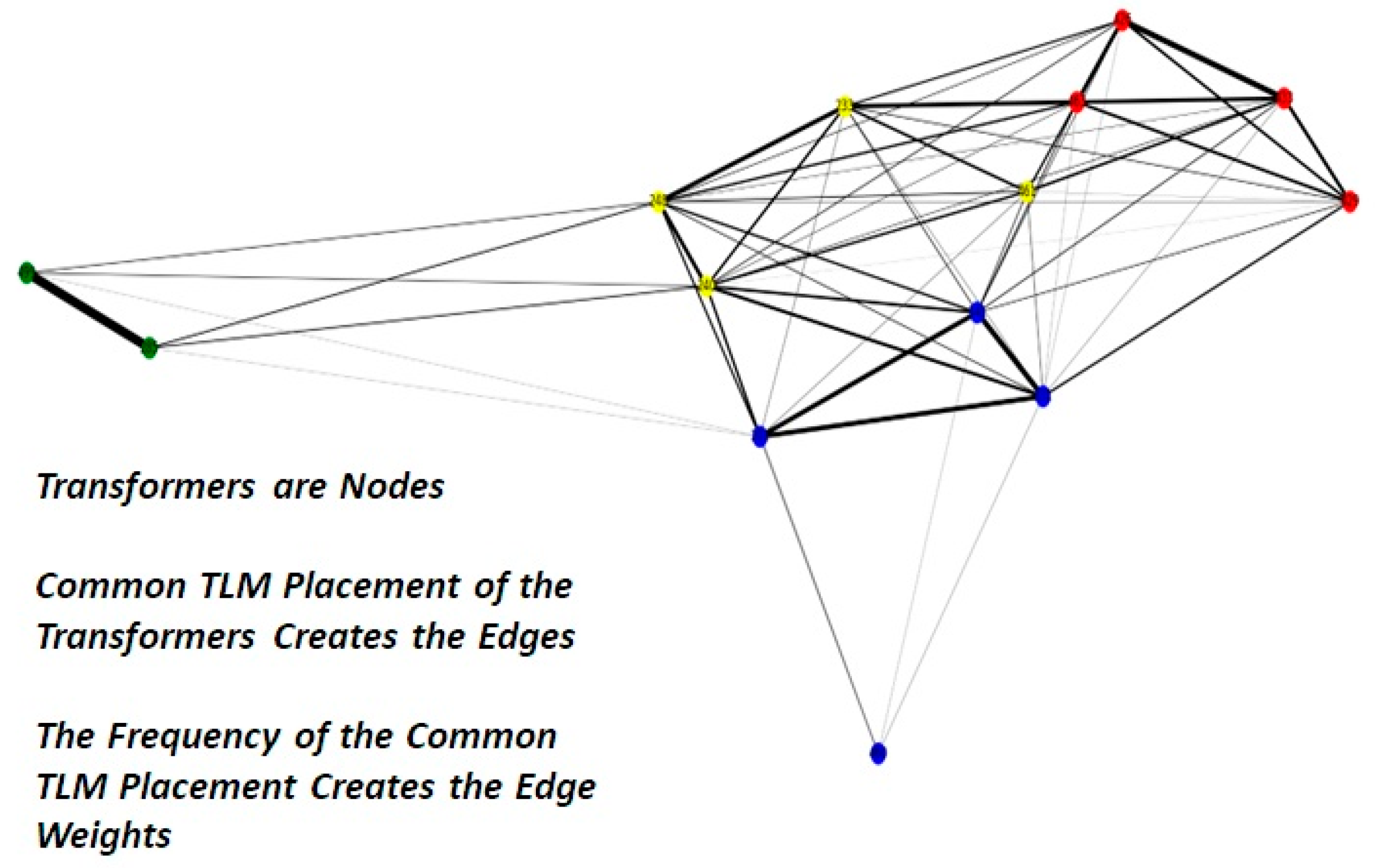
5.3. Community Detection
6. Results and Comprehensive Model
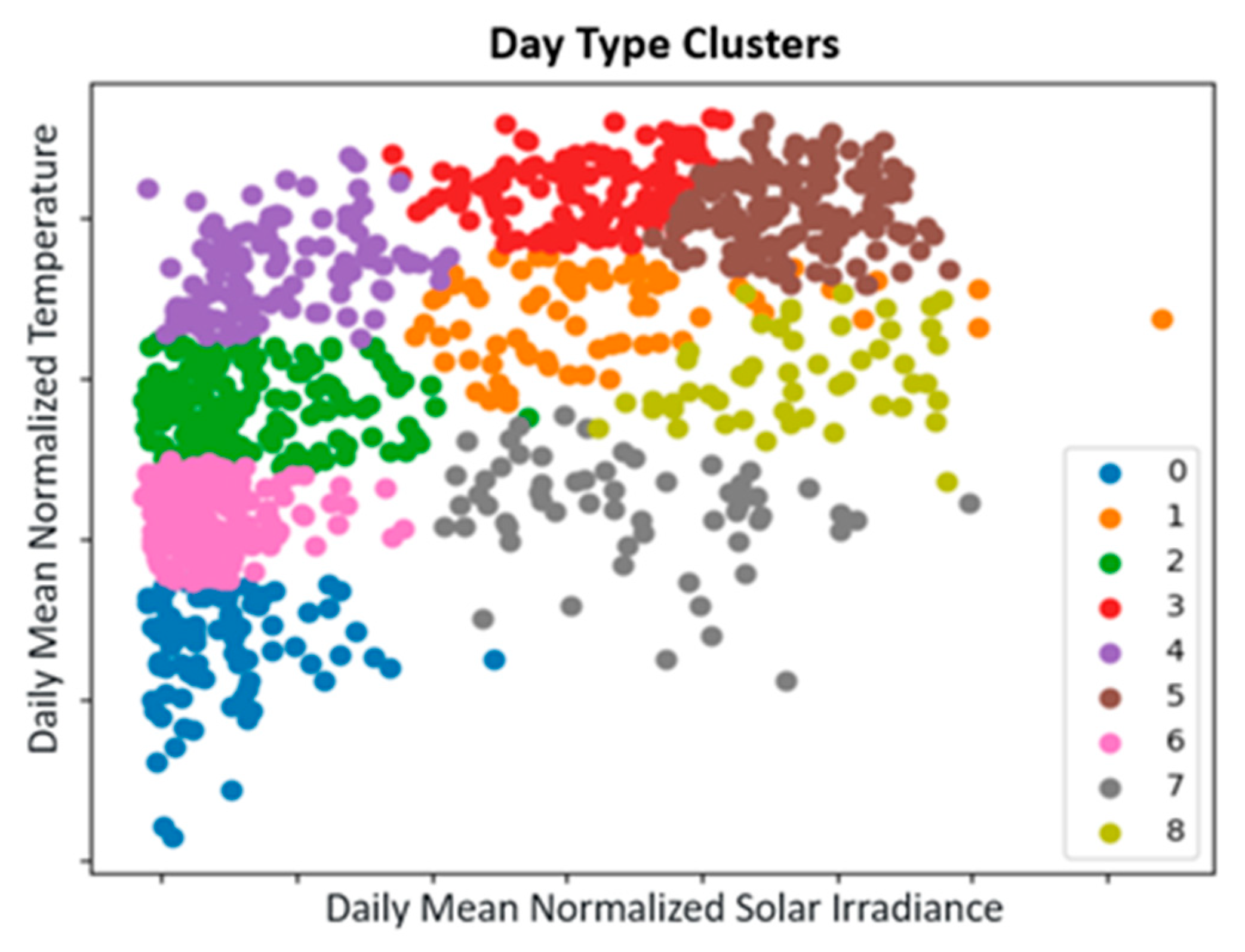
6.1. Clustering Results
6.2. Community Detection Results
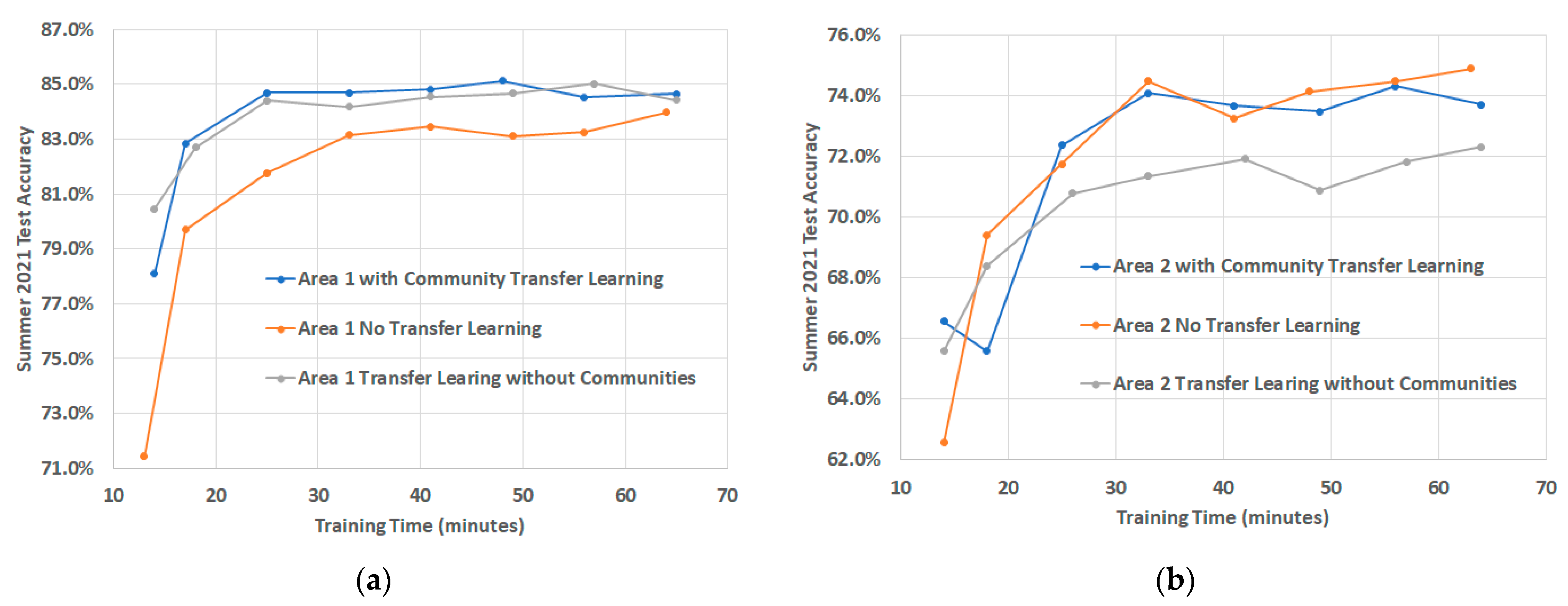
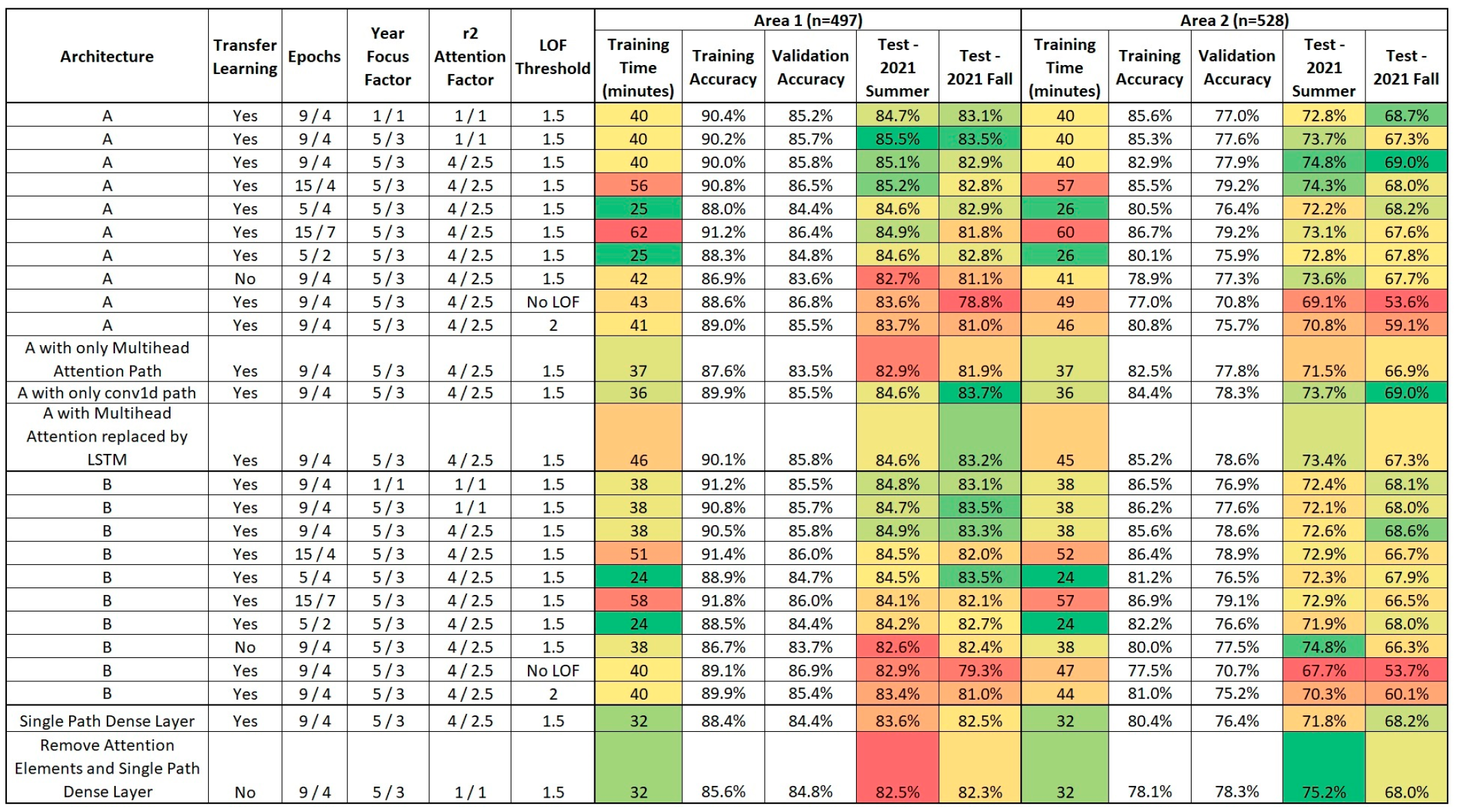
6.3. Neural Network Results
6.4. Overall Results
7. Research Findings and Future Work
7.1. Research Findings
7.2. Future Work
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Iravani, M.R.; Chaudhary, A.K.S.; Giesbrecht, W.J.; Hassan, I.E.; Keri, A.J.F.; Lee, K.C.; Martinez, J.A.; Morched, A.S.; Mork, B.A.; Parniani, M.; et al. Modeling and Analysis Guidelines for Slow Transients. III. The Study of Ferroresonance. IEEE Trans. Power Deliv. 2000, 15, 255–265. [Google Scholar] [CrossRef]
- Mork, B. Understanding and Dealing with Ferroresonance. In Proceedings of the Minnesota Power Systems Conference, St. Paul, MN, USA, 7–9 November 2006. [Google Scholar]
- Pinheiro, M.G.; Madeira, S.C.; Francisco, A.P. Short-Term Electricity Load Forecasting—A Systematic Approach from System Level to Secondary Substations. Appl. Energy 2023, 332, 120493. [Google Scholar] [CrossRef]
- Syed, D.; Refaat, S.S.; Abu-Rub, H.; Bouhali, O. Short-Term Power Forecasting Model Based on Dimensionality Reduction and Deep Learning Techniques for Smart Grid. In Proceedings of the 2020 IEEE Kansas Power and Energy Conference (KPEC), Manhattan, KS, USA, 13–14 July 2020; 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Lai, G.; Chang, W.-C.; Yang, Y.; Liu, H. Modeling Long- and Short-Term Temporal Patterns with Deep Neural Networks 2018. In Proceedings of the 41st International ACM SIGIR Conference on Research & Development in Information Retrieval, Ann Arbor, MI, USA, 8–12 July 2018. [Google Scholar] [CrossRef]
- Agarwal, K.; Dheekollu, L.; Dhama, G.; Arora, A.; Asthana, S.; Bhowmik, T. Deep Learning Based Time Series Forecasting. In Proceedings of the 2020 19th IEEE International Conference on Machine Learning and Applications (ICMLA), Miami, FL, USA, 14–17 December 2020; 2020; pp. 859–864. [Google Scholar] [CrossRef]
- Huang, Y.; Zhao, R.; Zhou, Q.; Xiang, Y. Short-Term Load Forecasting Based on a Hybrid Neural Network and Phase Space Reconstruction. IEEE Access 2022, 10, 23272–23283. [Google Scholar] [CrossRef]
- Farsi, B.; Amayri, M.; Bouguila, N.; Eicker, U. On Short-Term Load Forecasting Using Machine Learning Techniques and a Novel Parallel Deep LSTM-CNN Approach. IEEE Access 2021, 9, 31191–31212. [Google Scholar] [CrossRef]
- He, W. Load Forecasting via Deep Neural Networks. Procedia Comput. Sci. 2017, 122, 308–314. [Google Scholar] [CrossRef]
- Sun, W.; Zhang, X. Application of Self-Organizing Combination Forecasting Method in Power Load Forecast. In Proceedings of the 2007 International Conference on Wavelet Analysis and Pattern Recognition, Beijing, China, 2–4 November 2007; Volume 2, pp. 613–617. [Google Scholar] [CrossRef]
- Luo, S.; Rao, Y.; Chen, J.; Wang, H.; Wang, Z. Short-Term Load Forecasting Model of Distribution Transformer Based on CNN and LSTM. In Proceedings of the 2020 IEEE International Conference on High Voltage Engineering and Application (ICHVE), Beijing, China, 6–10 September 2020; pp. 1–4. [Google Scholar] [CrossRef]
- Kampezidou, S.I.; Grijalva, S. Distribution Transformers Short-Term Load Forecasting Models. In Proceedings of the 2016 IEEE Power and Energy Society General Meeting (PESGM), Boston, MA, USA, 17–21 July 2016; pp. 1–5. [Google Scholar] [CrossRef]
- Guo, J.; Zhang, Z.; Gao, W.; Hu, H.; Wang, D.; Mao, Y. Overheating Risk Warning Model Based on Thermal Circuit Model and Load Forecasting for Distribution Transformers. In Proceedings of the 2019 IEEE Sustainable Power and Energy Conference (iSPEC), Beijing, China, 21–23 November 2019; pp. 2891–2895. [Google Scholar] [CrossRef]
- Rashid, R.A.; Chin, L.; Sarijari, M.A.; Sudirman, R.; Ide, T. Machine Learning for Smart Energy Monitoring of Home Appliances Using IoT. In Proceedings of the 2019 Eleventh International Conference on Ubiquitous and Future Networks (ICUFN), Zagreb, Croatia, 2–5 July 2019; pp. 66–71. [Google Scholar] [CrossRef]
- Luo, A.; Yuan, J.; Liang, F.; Yang, Q.; Mu, D. Load Forecasting of Electric Vehicle Charging Station Based on Edge Computing. In Proceedings of the 2020 IEEE 3rd International Conference on Computer and Communication Engineering Technology (CCET), Beijing, China, 14–16 August 2020; pp. 34–38. [Google Scholar] [CrossRef]
- Zhang, L.; Tang, Y.; Zhou, T.; Tang, C.; Pang, B.; Liang, H. Research on Short-Term Power Load Forecasting in Distribution Station Area and Adjustable Load Participating in Demand-Side Cluster Control. In Proceedings of the 2021 IEEE 5th Conference on Energy Internet and Energy System Integration (EI2), Taiyuan, China, 22–24 October 2021; pp. 2353–2358. [Google Scholar] [CrossRef]
- Lekshmi, M.; Subramanya, K.N.A. Short-Term Load Forecasting of 400kV Grid Substation Using R-Tool and Study of Influence of Ambient Temperature on the Forecasted Load. In Proceedings of the 2019 Second International Conference on Advanced Computational and Communication Paradigms (ICACCP), Gangtok, India, 25–28 February 2019; pp. 1–5. [Google Scholar] [CrossRef]
- Eskandari, H.; Imani, M.; Moghadam, M.P. Correlation Based Convolutional Recurrent Network for Load Forecasting. In Proceedings of the 2020 28th Iranian Conference on Electrical Engineering (ICEE), Tabriz, Iran, 4–6 August 2020; pp. 1–5. [Google Scholar] [CrossRef]
- Hossen, T.; Nair, A.S.; Chinnathambi, R.A.; Ranganathan, P. Residential Load Forecasting Using Deep Neural Networks (DNN). In Proceedings of the 2018 North American Power Symposium (NAPS), Fargo, ND, USA, 9–11 September 2018; pp. 1–5. [Google Scholar] [CrossRef]
- Wang, J.; Liu, H.; Zheng, G.; Li, Y.; Yin, S. Short-Term Load Forecasting Based on Outlier Correction, Decomposition, and Ensemble Reinforcement Learning. Energies 2023, 16, 4401. [Google Scholar] [CrossRef]
- Alotaibi, M.A. Machine Learning Approach for Short-Term Load Forecasting Using Deep Neural Network. Energies 2022, 15, 6261. [Google Scholar] [CrossRef]
- Akhtar, S.; Shahzad, S.; Zaheer, A.; Ullah, H.S.; Kilic, H.; Gono, R.; Jasiński, M.; Leonowicz, Z. Short-Term Load Forecasting Models: A Review of Challenges, Progress, and the Road Ahead. Energies 2023, 16, 4060. [Google Scholar] [CrossRef]
- Xu, J. Research on Power Load Forecasting Based on Machine Learning. In Proceedings of the 2020 7th International Forum on Electrical Engineering and Automation (IFEEA), Hefei, China, 25–27 September 2020; pp. 562–567. [Google Scholar] [CrossRef]
- Ausmus, J.R.; Sen, P.K.P.; Wu, T.; Adhikari, U.; Zhang, Y.; Krishnan, V. Improving the Accuracy of Clustering Electric Utility Net Load Data Using Dynamic Time Warping. In Proceedings of the 2020 IEEE/PES Transmission and Distribution Conference and Exposition (T&D), Chicago, IL, USA, 12–15 October 2020; pp. 1–5. [Google Scholar] [CrossRef]
- Phetsangkat, P.; Chalermyanont, K.; Duangsoithong, R. Hierarchical Clustering Electric Load: Case Study in Lower South Region of Thailand. In Proceedings of the 2019 16th International Conference on Electrical Engineering/Electronics, Computer, Telecommunications and Information Technology (ECTI-CON), Pattaya, Thailand, 10–13 July 2019; pp. 881–884. [Google Scholar] [CrossRef]
- Yasin, Z.M.; Salim, N.A.; Ab Aziz, N.F. Long Term Load Forecasting Using Grey Wolf Optimizer—Artificial Neural Network. In Proceedings of the 2019 7th International Conference on Mechatronics Engineering (ICOM), Putrajaya, Malaysia, 30–31 October 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Mir, A.A.; Khan, Z.A.; Altmimi, A.; Badar, M.; Ullah, K.; Imran, M.; Kazmi, S.A.A. Systematic Development of Short-Term Load Forecasting Models for the Electric Power Utilities: The Case of Pakistan. IEEE Access 2021, 9, 140281–140297. [Google Scholar] [CrossRef]
- Agrawal, R.K.; Muchahary, F.; Tripathi, M.M. Long Term Load Forecasting with Hourly Predictions Based on Long-Short-Term-Memory Networks. In Proceedings of the 2018 IEEE Texas Power and Energy Conference (TPEC), College Station, TX, USA, 8–9 February 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Leou, R.-C.; Su, C.-L.; Lu, C.-N. Stochastic Analyses of Electric Vehicle Charging Impacts on Distribution Network. IEEE Trans. Power Syst. 2014, 29, 1055–1063. [Google Scholar] [CrossRef]
- Hwang, K.J.; Kim, G.W. Spatial Load Forecasting Model for Electrical Distribution Planning. In Proceedings of the 8th Russian-Korean International Symposium on Science and Technology, Tomsk, Russia, 26 June–3 July 2004; Volume 1, pp. 237–241. [Google Scholar] [CrossRef]
- Liu, D.; Li, Z.; Jiang, J.; Cheng, X.; Wu, G. Electric Vehicle Load Forecast Based on Monte Carlo Algorithm. In Proceedings of the 2020 IEEE 9th Joint International Information Technology and Artificial Intelligence Conference (ITAIC), Chongqing, China, 11–13 December 2020; Volume 9, pp. 1760–1763. [Google Scholar] [CrossRef]
- Hinojosa, V.; Gil, E.; Calle, I. A Stochastic Generation Capacity Expansion Planning Methodology Using Linear Distribution Factors and Hourly Load Modeling. In Proceedings of the 2018 IEEE International Conference on Probabilistic Methods Applied to Power Systems (PMAPS), Boise, ID, USA, 24–28 June 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Zhang, K.; Feng, X.; Tian, X.; Hu, Z.; Guo, N. Partial Least Squares Regression Load Forecasting Model Based on the Combination of Grey Verhulst and Equal-Dimension and New-Information Model. In Proceedings of the 2020 7th International Forum on Electrical Engineering and Automation (IFEEA), Hefei, China, 25–27 September 2020; pp. 915–919. [Google Scholar] [CrossRef]
- Chaturvedi, A.; Murthy, M.B.R.; Ranjan, R.; Prasad, K. A Novel Scheme of Load Forecasting Pertaining to Long Term Planning of a Distribution System. In Proceedings of the TENCON 2005—2005 IEEE Region 10 Conference, Melbourne, VIC, Australia, 21–24 November 2005; pp. 1–6. [Google Scholar] [CrossRef]
- Padmakumari, K.; Mohandas, K.P.; Thiruvengadam, S. Long Term Distribution Demand Forecasting Using Neuro Fuzzy Computations. Int. J. Electr. Power Energy Syst. 1999, 21, 315–322. [Google Scholar] [CrossRef]
- Kandilogiannakis, G.; Mastorocostas, P.; Voulodimos, A.; Hilas, C. Short-Term Load Forecasting of the Greek Power System Using a Dynamic Block-Diagonal Fuzzy Neural Network. Energies 2023, 16, 4227. [Google Scholar] [CrossRef]
- Chicco, G.; Napoli, R.; Piglione, F. Comparisons among Clustering Techniques for Electricity Customer Classification. IEEE Trans. Power Syst. 2006, 21, 933–940. [Google Scholar] [CrossRef]
- Zhu, Z.; Cai, R.; Cui, X.; Xu, L.; Xue, Y.; Zhang, G.; Wang, L.; Yu, X. Time Series Mining Based on Multilayer Piecewise Aggregate Approximation. In Proceedings of the 2016 International Conference on Audio, Language and Image Processing (ICALIP), Shanghai, China, 11–12 July 2016; pp. 174–179. [Google Scholar] [CrossRef]
- Pappa, L.; Karvelis, P.; Georgoulas, G.; Stylios, C. Slopewise Aggregate Approximation SAX: Keeping the Trend of a Time Series. In Proceedings of the 2021 IEEE Symposium Series on Computational Intelligence (SSCI), Orlando, FL, USA, 5–7 December 2021; pp. 1–8. [Google Scholar] [CrossRef]
- Xu, L.; Zhang, Y.; Shao, Z. An Approach to Cluster Electrical Load Profiles Based on Piecewise Symbolic Aggregation. In Proceedings of the 2021 6th Asia Conference on Power and Electrical Engineering (ACPEE), Chongqing, China, 8–11 April 2021; pp. 1000–1004. [Google Scholar] [CrossRef]
- Figueiredo, V.; Rodrigues, F.; Vale, Z.; Gouveia, J.B. An Electric Energy Consumer Characterization Framework Based on Data Mining Techniques. IEEE Trans. Power Syst. 2005, 20, 596–602. [Google Scholar] [CrossRef] [Green Version]
- Kwac, J.; Flora, J.; Rajagopal, R. Household Energy Consumption Segmentation Using Hourly Data. IEEE Trans. Smart Grid 2014, 5, 420–430. [Google Scholar] [CrossRef]
- Dong, M.; Nassif, A.B.; Li, B. A Data-Driven Residential Transformer Overloading Risk Assessment Method. IEEE Trans. Power Deliv. 2019, 34, 387–396. [Google Scholar] [CrossRef] [Green Version]
- Chicco, G.; Napoli, R.; Postolache, P.; Scutariu, M.; Toader, C. Customer Characterization Options for Improving the Tariff Offer. IEEE Trans. Power Syst. 2003, 18, 381–387. [Google Scholar] [CrossRef]
- Dow, L.; Marshall, M.; Xu, L.; Romero Agüero, J.; Willis, H.L. A Novel Approach for Evaluating the Impact of Electric Vehicles on the Power Distribution System. In Proceedings of the IEEE PES General Meeting, Minneapolis, MN, USA, 25–29 July 2010; pp. 1–6. [Google Scholar] [CrossRef]
- Imani, M.; Ghassemian, H. Electrical Load Forecasting Using Customers Clustering and Smart Meters in Internet of Things. In Proceedings of the 2018 9th International Symposium on Telecommunications (IST), Tehran, Iran, 17–19 December 2018; pp. 113–117. [Google Scholar] [CrossRef]
- Oliveira, A.C.; Lourenço, L.F.N.; Monaro, R.M.; Salles, M.B.C.; Cardoso, J.R. Probabilistic Assessment of Transformer Overcurrent in Distribution Systems with Increasing PV Penetration Levels. In Proceedings of the 2019 International Conference on Clean Electrical Power (ICCEP), Otranto, Italy, 2–4 July 2019; pp. 71–75. [Google Scholar] [CrossRef]
- Shen, S.k.; Liu, W.; Zhang, T. Load Pattern Recognition and Prediction Based on DTW K-Mediods Clustering and Markov Model. In Proceedings of the 2019 IEEE International Conference on Energy Internet (ICEI), Nanjing, China, 27–31 May 2019; pp. 403–408. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. In Advances in Neural Information Processing Systems; NeurIPS Proceedings: La Jolla, CA, USA, 2017. [Google Scholar] [CrossRef]
- Breunig, M.M.; Kriegel, H.-P.; Ng, R.T.; Sander, J. LOF: Identifying Density-Based Local Outliers. In Proceedings of the 2000 ACM SIGMOD International Conference on Management of Data, Dallas, TX USA, 15–18 May 2000; pp. 93–104. [Google Scholar] [CrossRef]
- Paparrizos, J.; Gravano, L. K-Shape: Efficient and Accurate Clustering of Time Series. In Proceedings of the 2015 ACM SIGMOD International Conference on Management of Data, Melbourne, VIC, Australia, 31 May–4 June 2015; pp. 1855–1870. [Google Scholar] [CrossRef]
- Zhang, Y.; Liu, Y.; Yu, Z.; Xiong, W.; Wang, L.; Ai, Q.; Li, Z.; Huang, K.; Hao, R.; Jiang, Z. Improving Aggregated Load Forecasting Using Evidence Accumulation K-Shape Clustering. In Proceedings of the 2020 IEEE Power & Energy Society General Meeting (PESGM), Montreal, QC, Canada, 2–6 August 2020; pp. 1–5. [Google Scholar] [CrossRef]
- RAPIDS Development Team RAPIDS: Libraries for End to End GPU Data Science. Available online: https://rapids.ai/ (accessed on 1 July 2023).
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-Learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Tslearn, a Machine Learning Toolkit for Time Series Data|The Journal of Machine Learning Research. Available online: https://dl.acm.org/doi/abs/10.5555/3455716.3455834 (accessed on 15 July 2023).
- Reback, J.; McKinney, W.; Jbrockmendel; Bossche, J.V.D.; Augspurger, T.; Cloud, P.; Gfyoung; Hawkins, S.; Sinhrks; Roeschke, M.; et al. Pandas-Dev/Pandas: Pandas 1.2.2. 2021. Available online: https://zenodo.org/record/4524629 (accessed on 1 July 2023). [CrossRef]
- Berardo de Sousa, F.; Zhao, L. Evaluating and Comparing the IGraph Community Detection Algorithms. In Proceedings of the 2014 Brazilian Conference on Intelligent Systems, Sao Paulo, Brazil, 18–22 October 2014; pp. 408–413. [Google Scholar] [CrossRef]
- Chejara, P.; Godfrey, W.W. Comparative Analysis of Community Detection Algorithms. In Proceedings of the 2017 Conference on Information and Communication Technology (CICT), Gwalior, India, 3–5 November 2017; pp. 1–5. [Google Scholar] [CrossRef]
- Csardi, G.; Nepusz, T. The Igraph Software Package for Complex Network Research. InterJournal Complex Syst. 2006, 1695, 1–9. [Google Scholar]
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. Tensorflow. Available online: https://zenodo.org/record/8118033 (accessed on 1 July 2023).
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Clustering Method * | R2 ** | Training Time (s) *** |
|---|---|---|
| K-Shape | 69.3% | 1716 |
| K-Means with Dynamic Time Warping (DTW) | 78.5% | 7175 |
| Agglomerative with Average Linkage | 78.1% | 69.92 |
| Agglomerative with Ward Linkage and PCA | 78.5% | 66.18 |
| Agglomerative with Ward Linkage and Piecewise Aggregate | 79% | 69.13 |
| Agglomerative with Ward Linkage and Slopewise Aggregate Approximation | 78.3% | 69.96 |
| Agglomerative with Ward Linkage, Piecewise Aggregate Approximation and Slopewise Aggregate Approximation | 79% | 72.27 |
| K-Means with Piecewise Aggregate Approximation and Slopewise Aggregate Approximation—Using a GPU | 79% | 66.84 |
| K-Means with Piecewise Aggregate Approximation—Using a GPU | 79% | 56.83 |
| Step | Time (min) | Area 1 R2 | Area 2 R2 |
|---|---|---|---|
| Weather and Load Clustering | 6 | Train: 90% | Train: 87% |
| Forecast: 78% | Forecast: 63% | ||
| Community Detection | 2 | N/A | N/A |
| Neural Network Refinement | 40 | Train: 90% | Train: 83% |
| Forecast: 85%/83% | Forecast: 75%/69% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
O’Donnell, J.; Su, W. Attention-Focused Machine Learning Method to Provide the Stochastic Load Forecasts Needed by Electric Utilities for the Evolving Electrical Distribution System. Energies 2023, 16, 5661. https://doi.org/10.3390/en16155661
O’Donnell J, Su W. Attention-Focused Machine Learning Method to Provide the Stochastic Load Forecasts Needed by Electric Utilities for the Evolving Electrical Distribution System. Energies. 2023; 16(15):5661. https://doi.org/10.3390/en16155661
Chicago/Turabian StyleO’Donnell, John, and Wencong Su. 2023. "Attention-Focused Machine Learning Method to Provide the Stochastic Load Forecasts Needed by Electric Utilities for the Evolving Electrical Distribution System" Energies 16, no. 15: 5661. https://doi.org/10.3390/en16155661