
A GPU-Accelerated Particle Advection Methodology for 3D Lagrangian Coherent Structures in High-Speed Turbulent Boundary Layers

Abstract
:1. Introduction
2. Problem Overview and Algorithmic Details
2.1. Finite-Time Lyapunov Exponent
2.1.1. Overview: FTLE
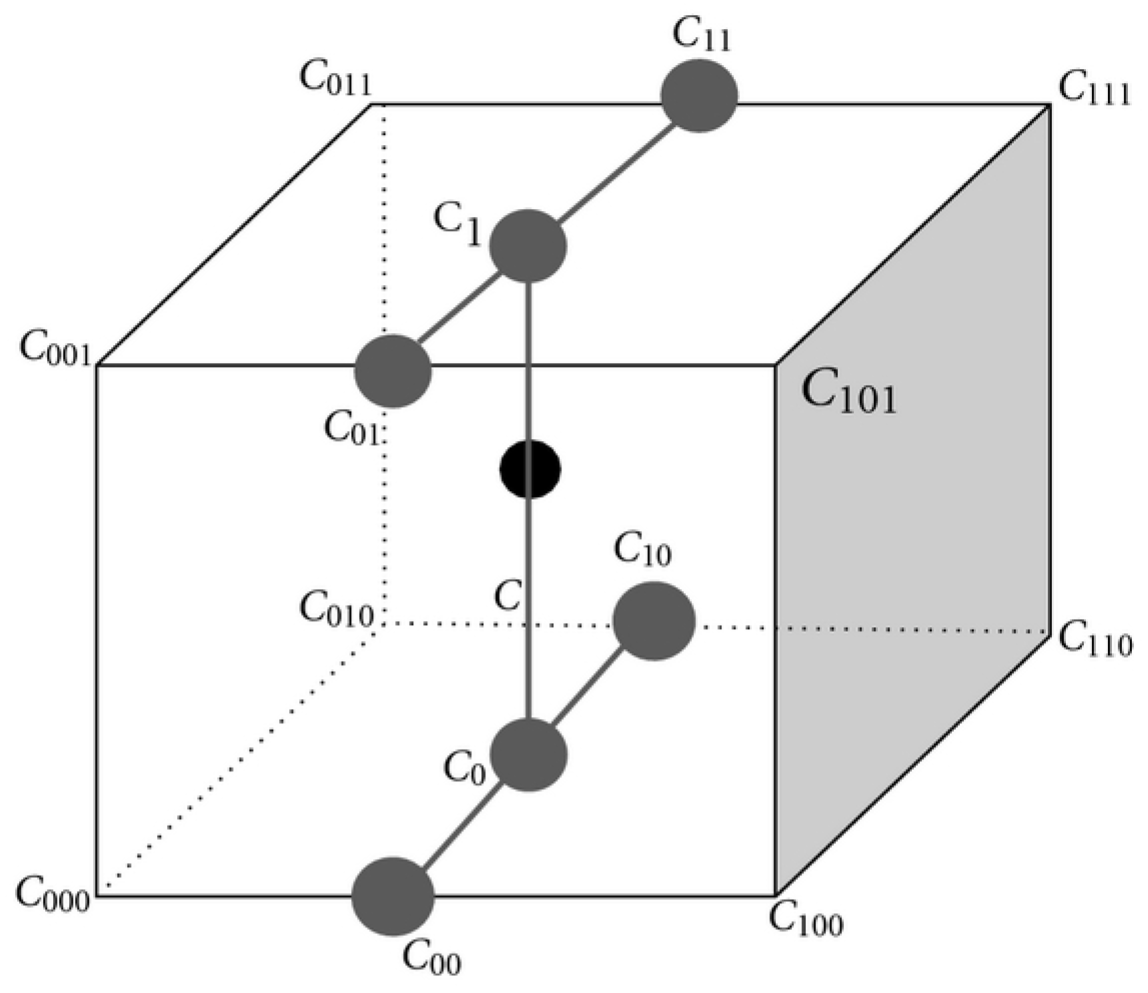
2.1.2. Algorithmic Details: Particle Advection
- Data input/output (reading flow fields and writing particle coordinates to disk).
- Flow field interpolation (interpolate between simulation flow fields to “improve” temporal resolution for the integration scheme).
- Cell locator (finding where a particle is w.r.t. the original computational domain).
- Flow field velocity interpolation (calculating particle velocity based on its location within a cell).
- Particle movements (advancing particles forward, or backward, in time).
| Algorithm 1 Multi-Level Best-First Search (ML-BFS) |
|
2.1.3. Algorithmic Details: Right Cauchy–Green Tensor and Eigenvalue Problem
- Choose an initial guess for the eigenvector (preferably with unit length).
- Compute the product of the matrix A and the initial guess vector to obtain a new vector .
- Normalize the new vector to obtain a new approximation for the eigenvector with unit length.
- Compute the ratio of the norm of the new approximation of the eigenvector and the norm of the previous approximation. If the ratio is less than a specified tolerance, then terminate the iteration and return the current approximation of the eigenvector as the dominant eigenvector. Otherwise, continue to the next step.
- Set the current approximation of the eigenvector to be the new approximation, and repeat steps 2–4 until the desired accuracy is achieved.
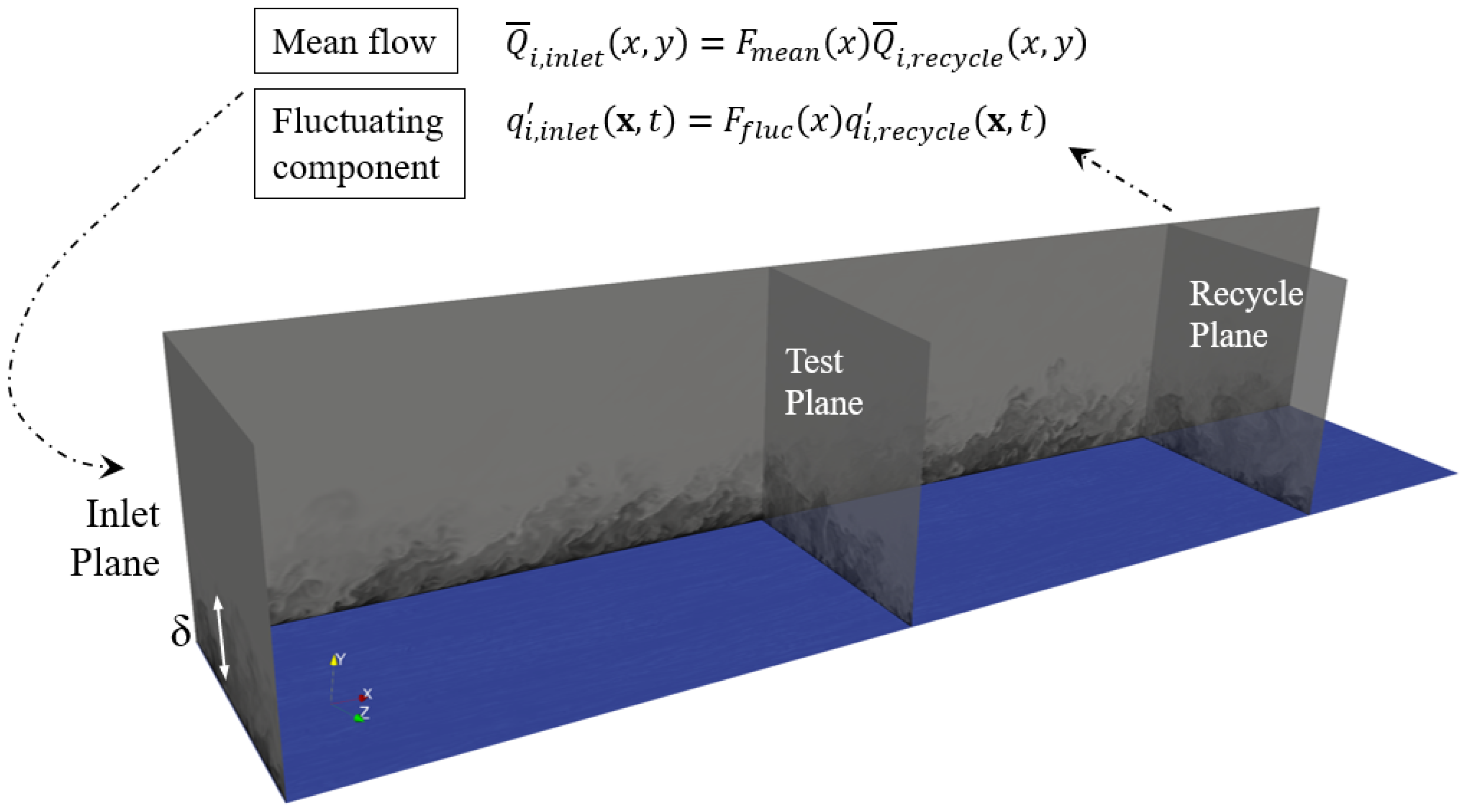
2.2. Direct Numerical Simulation: The Testbed Cases
2.3. Computing Resources
2.3.1. Cray XC40/50-Onyx
2.3.2. HPE Cray EX (Formerly Cray Shasta): Narwhal
2.3.3. Anvil
2.3.4. Chameleon A100 Node
2.3.5. Fair CPU and GPU Comparisons
2.3.6. Software
3. Results and Discussion
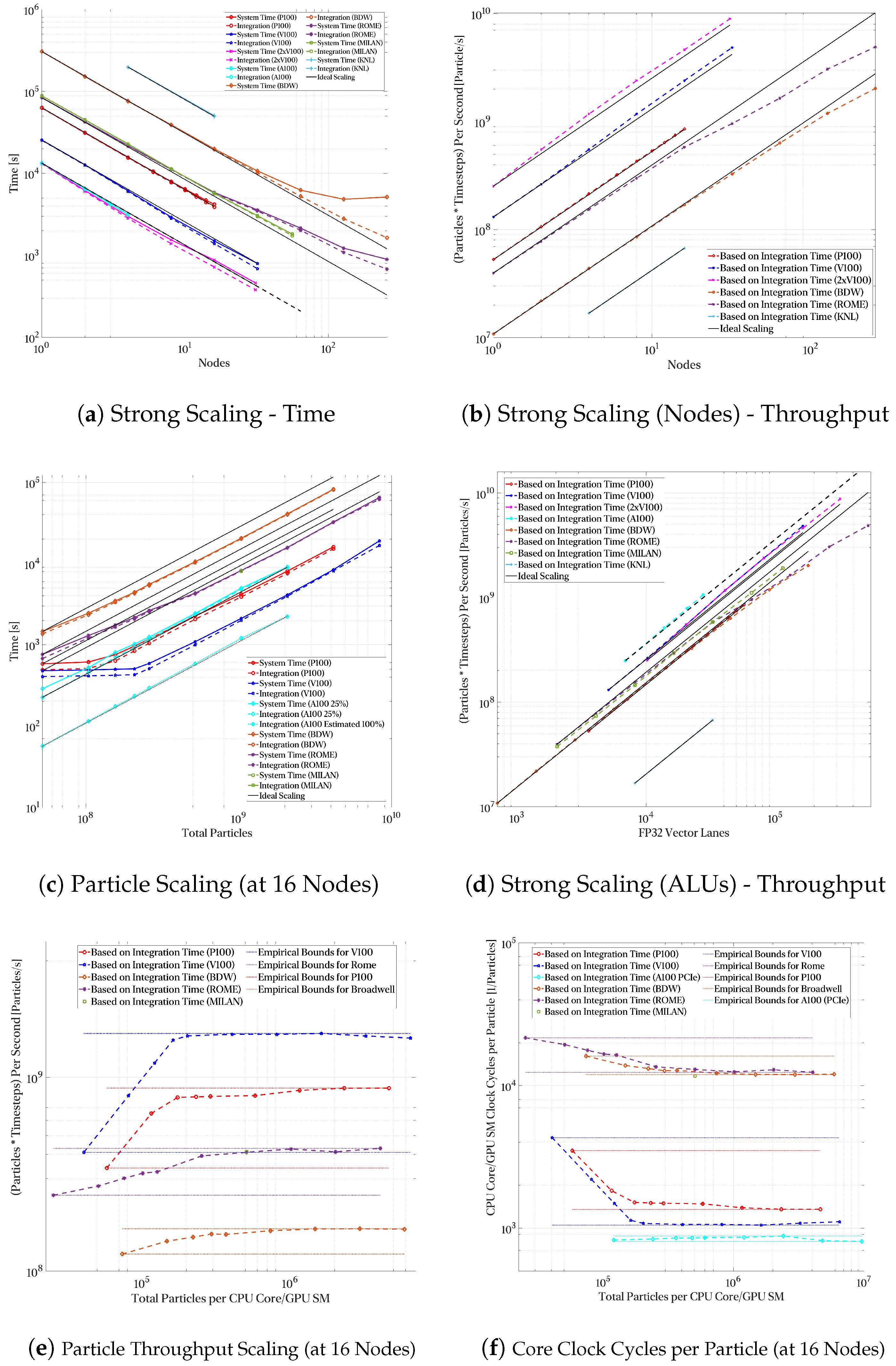
3.1. Performance Scaling Analysis
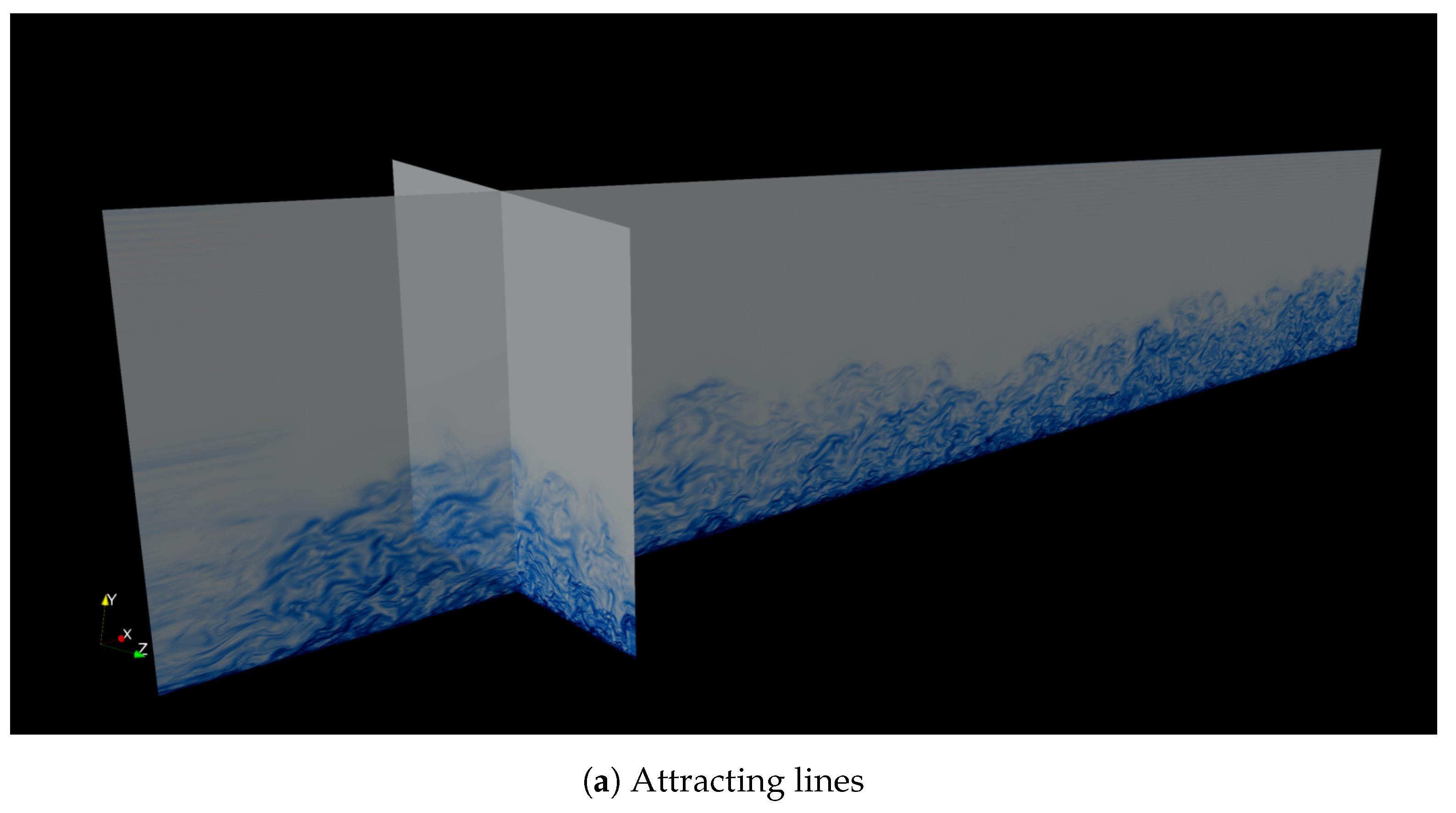
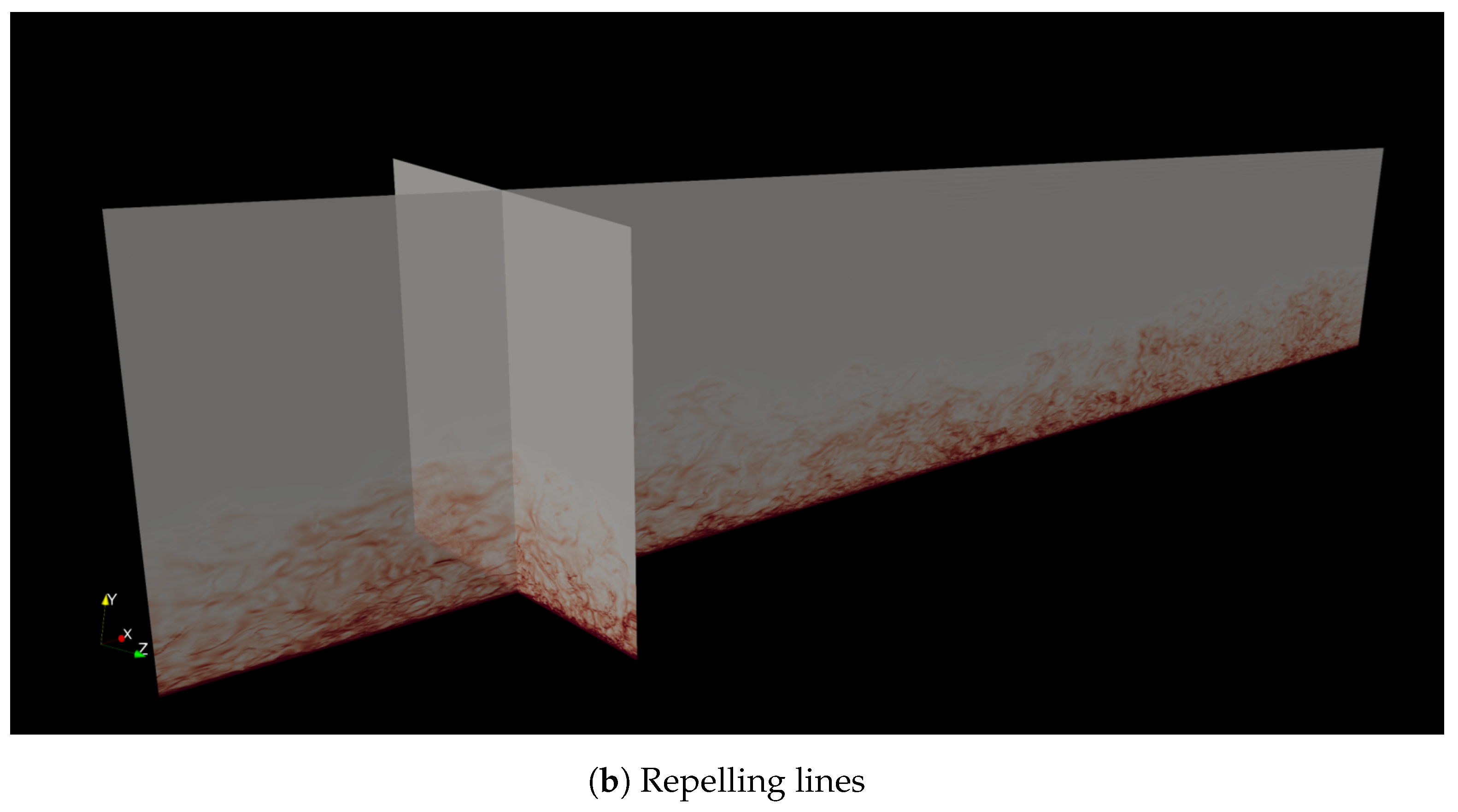
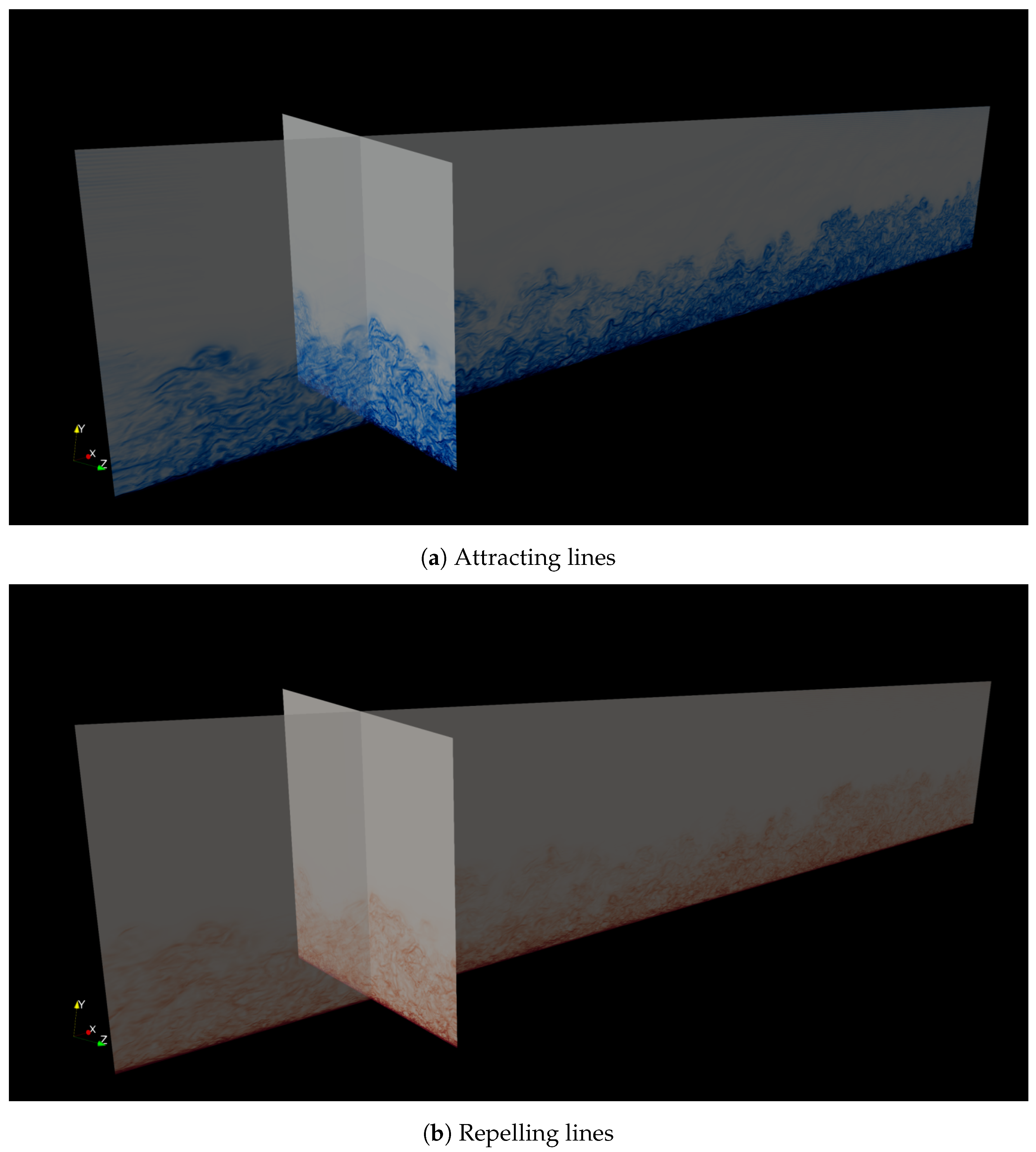
3.2. Case Study
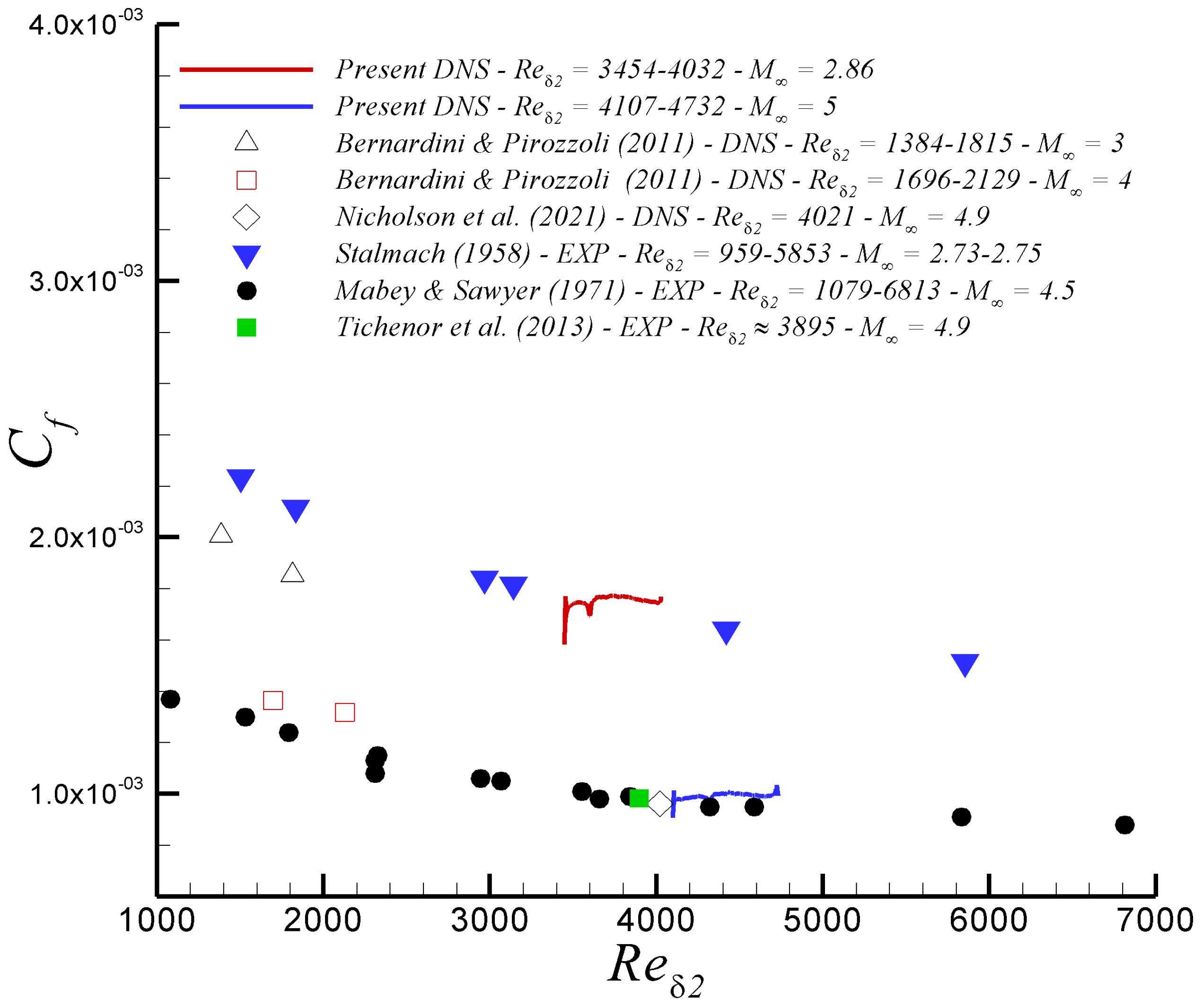
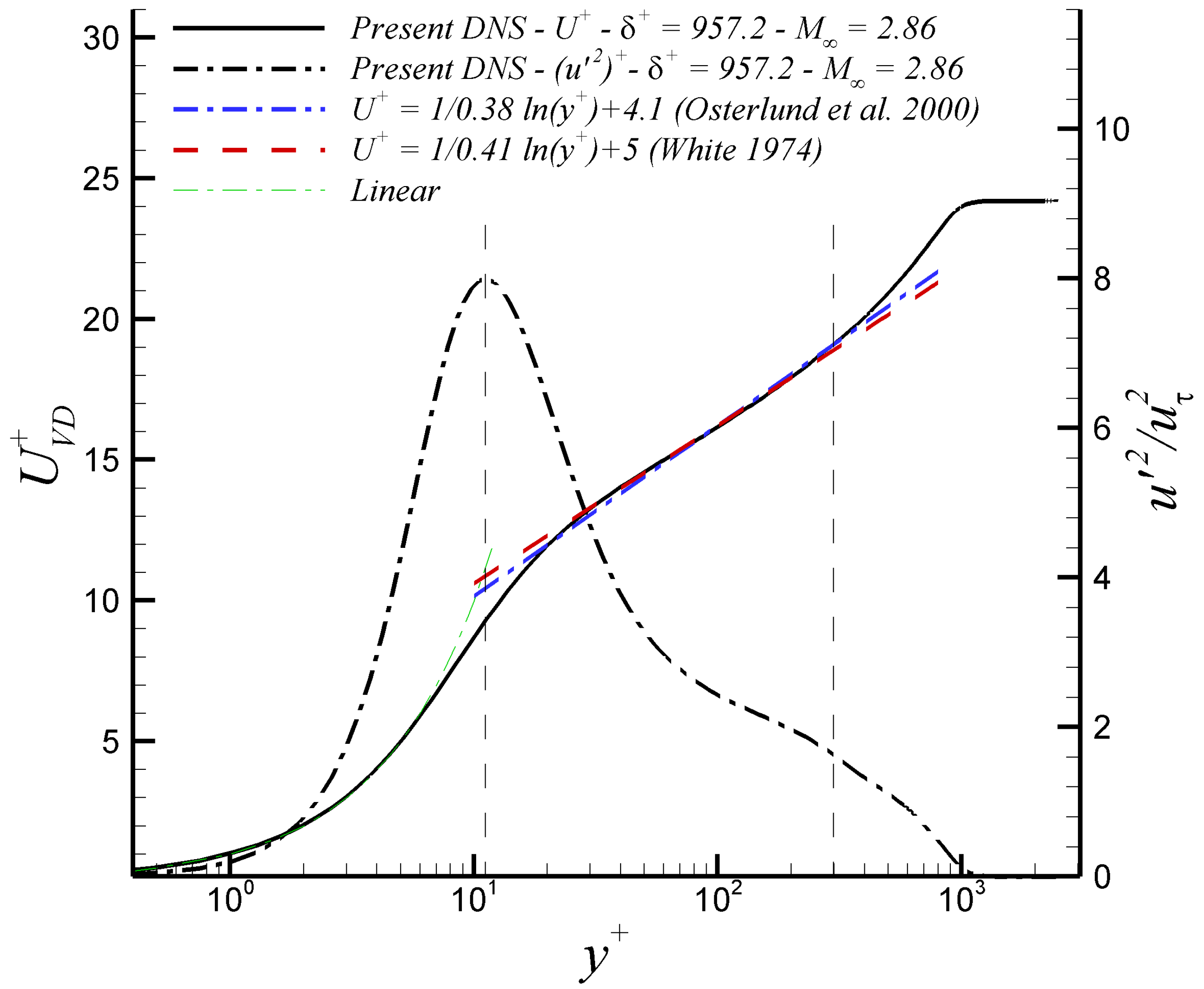
3.2.1. Compressibility Effects
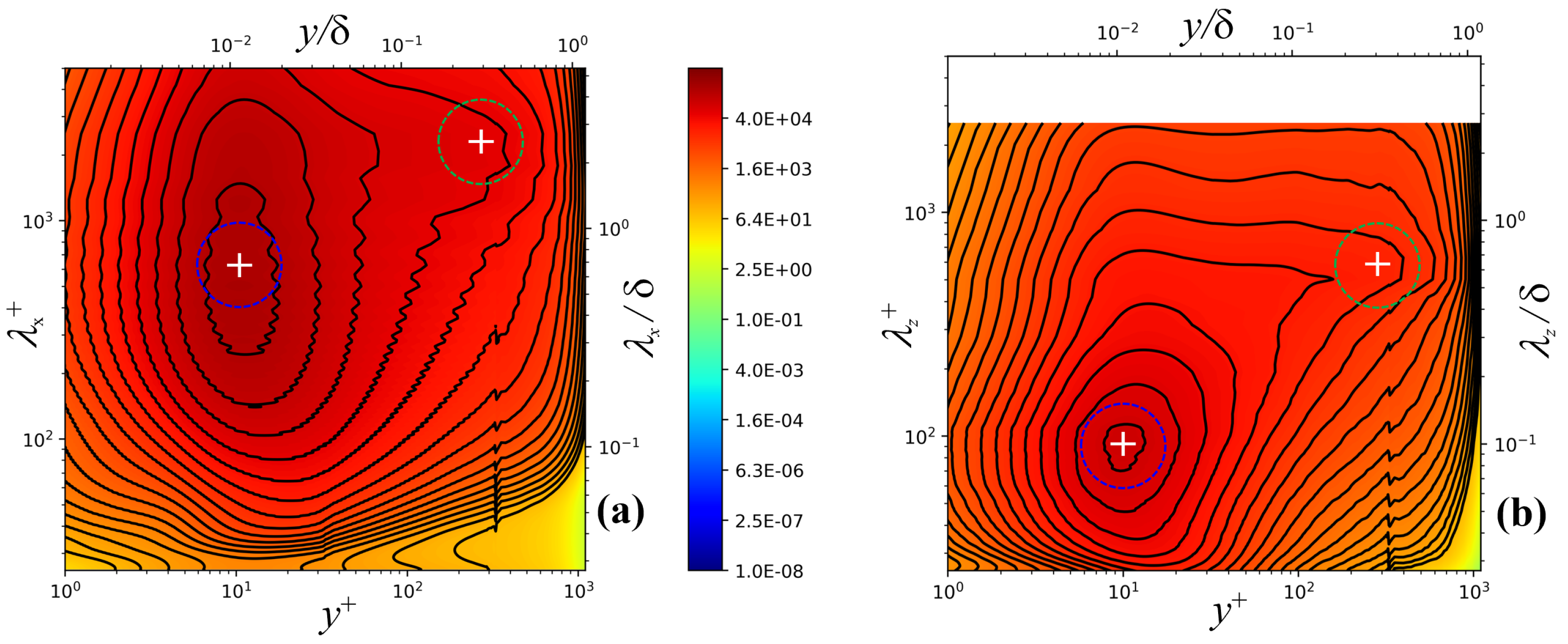
3.2.2. Reynolds Number Dependency Effects
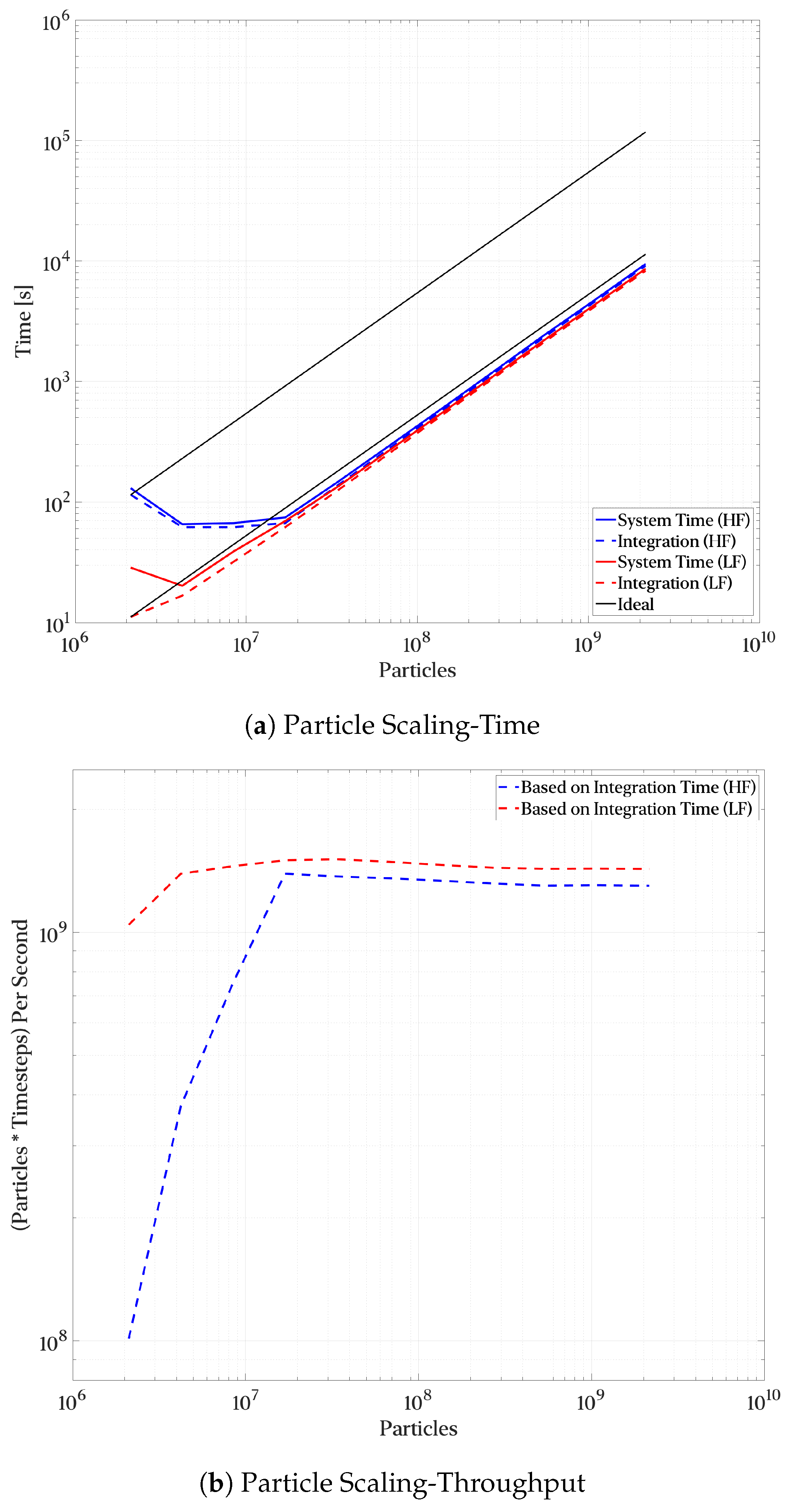
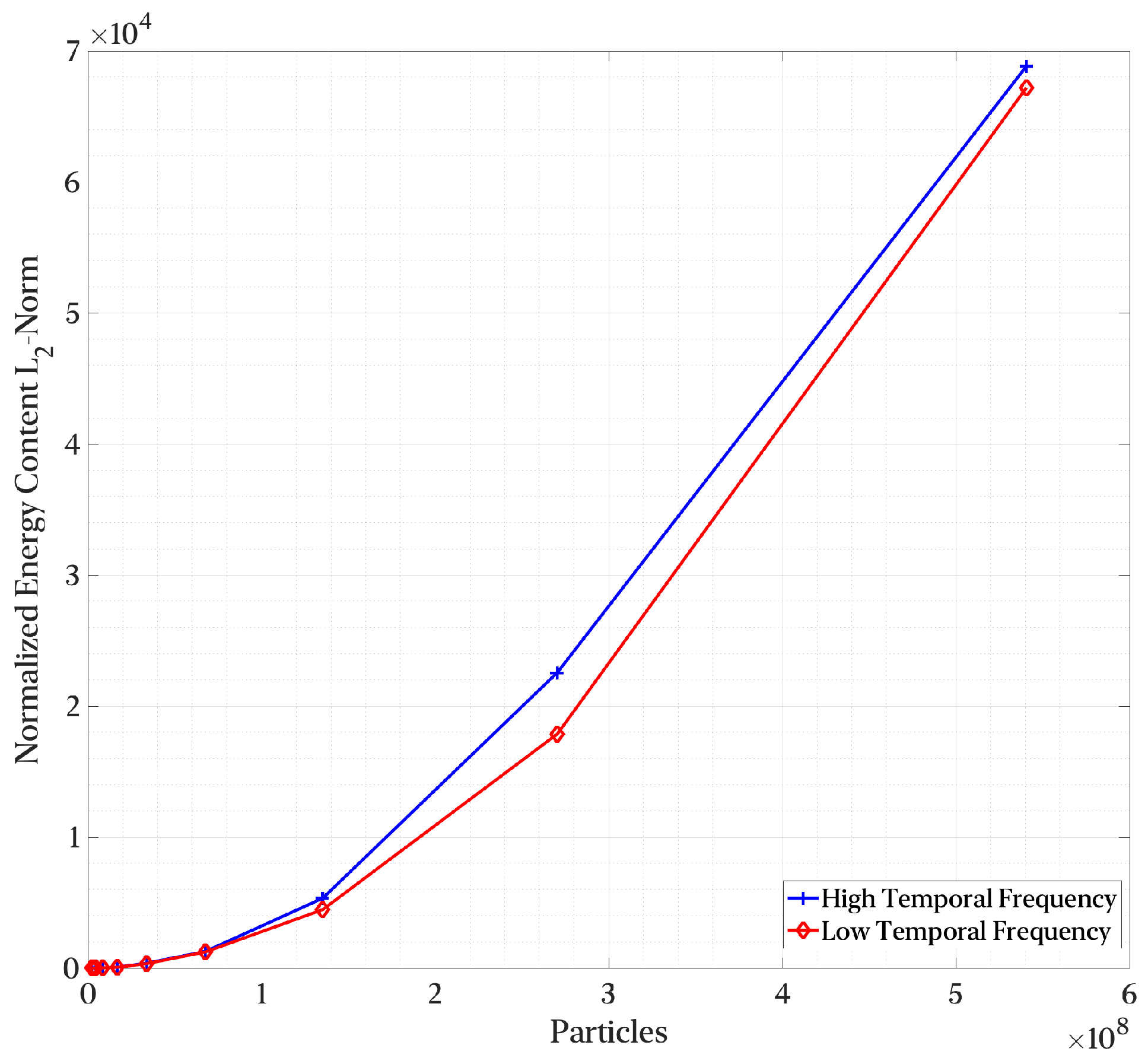
3.2.3. Temporal Interpolation and Particle Density Influence
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Hunt, J.C.R.; Wray, A.A.; Moin, P. Eddies, streams, and convergence zones in turbulent flows. In Studying Turbulence Using Numerical Simulation Databases, 2. Proceedings of the 1988 Summer Program; NASA Ames Research Center: Moffett Field, CA, USA, 1988; pp. 193–208. [Google Scholar]
- Jeong, J.; Hussain, F. On the identification of a vortex. J. Fluid Mech. 1995, 285, 69–94. [Google Scholar] [CrossRef]
- Lagares, C.; Araya, G. Compressibility effects on high-Reynolds coherent structures via two-point correlations. In Proceedings of the AIAA AVIATION 2021 FORUM, Online, 2–6 August 2021. [Google Scholar] [CrossRef]
- Araya, G.; Lagares, C.; Santiago, J.; Jansen, K. Wall temperature effect on hypersonic turbulent boundary layers via DNS. In Proceedings of the AIAA SciTech, Online, 11–15, 19–21 January 2021. [Google Scholar]
- Haller, G.; Yuan, G. Lagrangian coherent structures and mixing in two-dimensional turbulence. Phys. D Nonlinear Phenom. 2000, 147, 352–370. [Google Scholar] [CrossRef]
- Haller, G. Distinguished material surfaces and coherent structures in three-dimensional fluid flows. Phys. D Nonlinear Phenom. 2001, 149, 248–277. [Google Scholar] [CrossRef] [Green Version]
- Haller, G. Lagrangian Coherent Structures. Annu. Rev. Fluid Mech. 2015, 47, 137–162. [Google Scholar] [CrossRef] [Green Version]
- Haller, G.; Karrasch, D.; Kogelbauer, F. Barriers to the Transport of Diffusive Scalars in Compressible Flows. Siam J. Appl. Dyn. Syst. 2020, 19, 85–123. [Google Scholar] [CrossRef]
- Saltar, G.; Lagares, C.; Araya, G. Compressibility and Reynolds number effect on Lagrangian Coherent Structures (LCS). In Proceedings of the AIAA AVIATION 2022 Forum, Online, 27 June–1 July 2022. [Google Scholar] [CrossRef]
- Onu, K.; Huhn, F.; Haller, G. LCS Tool: A computational platform for Lagrangian coherent. J. Comput. Sci. 2015, 7, 26–36. [Google Scholar] [CrossRef] [Green Version]
- Töger, J.; Kanski, M.; Carlsson, M.; Kovacs, S.; Söderlind, G.; Arheden, H.; Heiberg, E. Vortex Ring Formation in the Left Ventricle of the Heart: Analysis by 4D Flow MRI and Lagrangian Coherent Structures. Ann. Biomed. Eng. 2012, 40, 2652–2662. [Google Scholar] [CrossRef] [PubMed]
- Shadden, S.; Astorino, M.; Gerbeau, J. Computational analysis of an aortic valve jet with Lagrangian coherent structures. Chaos 2010, 20, 017512. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Koh, T.Y.; Legras, B. Hyperbolic lines and the stratospheric polar vortex. Chaos 2002, 12, 382–394. [Google Scholar] [CrossRef] [PubMed]
- Beron-Vera, F.J.; Olascoaga, M.J.; Goni, G.J. Oceanic mesoscale eddies as revealed by Lagrangian coherent structures. In Geophysical Research Letters; Wiley: Hoboken, NJ, USA, 2008; Volume 35, p. L12603. [Google Scholar] [CrossRef]
- Beron-Vera, F.J.; Olascoaga, M.J.; Brown, M.G.; Rypina, I.I. Invariant-tori-like Lagrangian coherent structures in geophysical flows. Chaos 2010, 20, 017514. [Google Scholar] [CrossRef]
- Peng, J.; Dabiri, J. Transport of inertial particles by Lagrangian coherent structures: Application to predator–prey interaction in jellyfish feeding. J. Fluid Mech. 2009, 623, 75–84. [Google Scholar] [CrossRef] [Green Version]
- Tew Kai, E.; Rossi, V.; Sudre, J.; Weimerskirch, H.; Lopez, C.; Hernandez-Garcia, E.; Marsac, F.; Garçon, V. Top marine predators track Lagrangian coherent structures. Proc. Natl. Acad. Sci. USA 2009, 106, 8245–8250. [Google Scholar] [CrossRef] [Green Version]
- Lagares, C.; Rivera, W.; Araya, G. Aquila: A Distributed and Portable Post-Processing Library for Large-Scale Computational Fluid Dynamics. In Proceedings of the AIAA Scitech 2021 Forum, Online, 11–15, 19–21 January 2021. [Google Scholar] [CrossRef]
- Lagares, C.; Rivera, W.; Araya, G. Scalable Post-Processing of Large-Scale Numerical Simulations of Turbulent Fluid Flows. Symmetry 2022, 14, 823. [Google Scholar] [CrossRef]
- Nelson, D.A.; Jacobs, G.B. DG-FTLE: Lagrangian coherent structures with high-order discontinuous-Galerkin methods. J. Comput. Phys. 2015, 295, 65–86. [Google Scholar] [CrossRef]
- Fortin, A.; Briffard, T.; Garon, A. A more efficient anisotropic mesh adaptation for the computation of Lagrangian coherent structures. J. Comput. Phys. 2015, 285, 100–110. [Google Scholar] [CrossRef]
- Dauch, T.; Rapp, T.; Chaussonnet, G.; Braun, S.; Keller, M.; Kaden, J.; Koch, R.; Dachsbacher, C.; Bauer, H.J. Highly efficient computation of Finite-Time Lyapunov Exponents (FTLE) on GPUs based on three-dimensional SPH datasets. Comput. Fluids 2018, 175, 129–141. [Google Scholar] [CrossRef]
- Lagares, C.; Araya, G. Power spectrum analysis in supersonic/hypersonic turbulent boundary layers. In Proceedings of the AIAA SCITECH 2022 Forum, Online, 3–7 January 2022. [Google Scholar] [CrossRef]
- Araya, G.; Lagares, C. Implicit Subgrid-Scale Modeling of a Mach 2.5 Spatially Developing Turbulent Boundary Layer. Entropy 2022, 24, 555. [Google Scholar] [CrossRef]
- Araya, G.; Lagares, C.; Jansen, K. Reynolds number dependency in supersonic spatially-developing turbulent boundary layers. In Proceedings of the 2020 AIAA SciTech Forum (AIAA 3247313), Orlando, FL, USA, 6–10 January 2020. [Google Scholar]
- Karrasch, D.; Haller, G. Do Finite-Size Lyapunov Exponents detect coherent structures? Chaos 2013, 23, 043126. [Google Scholar] [CrossRef] [Green Version]
- Peikert, R.; Pobitzer, A.; Sadlo, F.; Schindler, B. A comparison of Finite-Time and Finite-Size Lyapunov Exponents. In Topological Methods in Data Analysis and Visualization III; Springer: Berlin/Heidelberg, Germany, 2014. [Google Scholar]
- Wang, B.; Wald, I.; Morrical, N.; Usher, W.; Mu, L.; Thompson, K.; Hughes, R. An GPU-accelerated particle tracking method for Eulerian–Lagrangian simulations using hardware ray tracing cores. Comput. Phys. Commun. 2022, 271, 108221. [Google Scholar] [CrossRef]
- Russell, S.; Norvig, P. Artificial Intelligence: A Modern Approach, 3rd ed.; Prentice Hall: Hoboken, NJ, USA, 2010. [Google Scholar]
- Bai, Y.; Guo, N.; Agbegha, G. Fuzzy Interpolation and Other Interpolation Methods Used in Robot Calibrations. J. Robot. 2012, 2012, 376293. [Google Scholar] [CrossRef] [Green Version]
- LeVeque, R.J. Finite Difference Methods for Ordinary and Partial Differential Equations: Steady-State and Time-Dependent Problems; SIAM: Philadelphia, PA, USA, 2007. [Google Scholar]
- Gustafson, J.L. Reevaluating Amdahl’s law. Commun. Acm 1988, 31, 532–533. [Google Scholar] [CrossRef] [Green Version]
- Hockney, R.W.; Eastwood, J.W. Computer Simulation Using Particles; CRC Press: Boca Raton, FL, USA, 1988. [Google Scholar]
- Demmel, J.W. Applied Numerical Linear Algebra; SIAM: Philadelphia, PA, USA, 1997. [Google Scholar] [CrossRef]
- Araya, G.; Castillo, L.; Meneveau, C.; Jansen, K. A dynamic multi-scale approach for turbulent inflow boundary conditions in spatially evolving flows. J. Fluid Mech. 2011, 670, 518–605. [Google Scholar] [CrossRef]
- Lund, T.; Wu, X.; Squires, K. Generation of turbulent inflow data for spatially-developing boundary layer simulations. J. Comput. Phys. 1998, 140, 233–258. [Google Scholar] [CrossRef] [Green Version]
- Urbin, G.; Knight, D. Large-Eddy Simulation of a supersonic boundary layer using an unstructured grid. AIAA J. 2001, 39, 1288–1295. [Google Scholar] [CrossRef]
- Stolz, S.; Adams, N. Large-eddy simulation of high-Reynolds-number supersonic boundary layers using the approximate deconvolution model and a rescaling and recycling technique. Phys. Fluids 2003, 15, 2398–2412. [Google Scholar] [CrossRef]
- Xu, S.; Martin, M.P. Assessment of inflow boundary conditions for compressible turbulent boundary layers. Phys. Fluids 2004, 16, 2623–2639. [Google Scholar] [CrossRef] [Green Version]
- Schlichting, H.; Gersten, K. Boundary-Layer Theory; Springer: Berlin/Heidelberg, Germany, 2016. [Google Scholar]
- Whiting, C.H.; Jansen, K.E.; Dey, S. Hierarchical basis in stabilized finite element methods for compressible flows. Comput. Methods Appl. Mech. Eng. 2003, 192, 5167–5185. [Google Scholar] [CrossRef]
- Jansen, K.E. A stabilized finite element method for computing turbulence. Comput. Methods Appl. Mech. Eng. 1999, 174, 299–317. [Google Scholar] [CrossRef]
- Araya, G.; Castillo, C.; Hussain, F. The log behaviour of the Reynolds shear stress in accelerating turbulent boundary layers. J. Fluid Mech. 2015, 775, 189–200. [Google Scholar] [CrossRef]
- Doosttalab, A.; Araya, G.; Newman, J.; Adrian, R.; Jansen, K.; Castillo, L. Effect of small roughness elements on thermal statistics of a turbulent boundary layer at moderate Reynolds number. J. Fluid Mech. 2015, 787, 84–115. [Google Scholar] [CrossRef]
- Stalmach, C. Experimental Investigation of the Surface Impact Pressure Probe Method Of Measuring Local Skin Friction at Supersonic Speeds. In Bureau of Engineering Research; University of Texas: Austin, TX, USA, 1958. [Google Scholar]
- Mabey, D.; Sawyer, W. Experimental Studies of the Boundary Layer on a Flat Plate at Mach Numbers from 2.5 to 4.5; HM Stationery Office: London, UK, 1976; Reports and Memoranda No. 3784.
- Tichenor, N.R.; Humble, R.A.; Bowersox, R.D.W. Response of a hypersonic turbulent boundary layer to favourable pressure gradients. J. Fluid Mech. 2013, 722, 187–213. [Google Scholar] [CrossRef]
- Nicholson, G.; Huang, J.; Duan, L.; Choudhari, M.M.; Bowersox, R.D. Simulation and Modeling of Hypersonic Turbulent Boundary Layers Subject to Favorable Pressure Gradients due to Streamline Curvature. In Proceedings of the AIAA Scitech 2021 Forum, Online, 11–15, 19–21 January 2021. [Google Scholar] [CrossRef]
- Bernardini, M.; Pirozzoli, S. Wall pressure fluctuations beneath supersonic turbulent boundary layers. Phys. Fluids 2011, 23, 085102. [Google Scholar] [CrossRef]
- Hutchins, N.; Marusic, I. Large-scale influences in near-wall turbulence. Phil. Trans. R. Soc. 2007, 365, 647–664. [Google Scholar] [CrossRef] [Green Version]
- Bernardini, M.; Pirozzoli, S. Inner/outer layer interactions in turbulent boundary layers: A refined measure for the large-scale amplitude modulation mechanism. Phys. Fluids 2011, 23, 061701. [Google Scholar] [CrossRef]
- White, F.M. Viscous Fluid Flow; McGraw-Hill Mechanical Engineering: New York, NY, USA, 2006. [Google Scholar]
- Osterlund, J.M.; Johansson, A.V.; Nagib, H.M.; Hites, M.H. A note on the overlap region in turbulent boundary layers. Phys. Fluids 2001, 12, 1–4. [Google Scholar] [CrossRef] [Green Version]
- Song, X.C.; Smith, P.; Kalyanam, R.; Zhu, X.; Adams, E.; Colby, K.; Finnegan, P.; Gough, E.; Hillery, E.; Irvine, R.; et al. Anvil-System Architecture and Experiences from Deployment and Early User Operations. In Proceedings of the PEARC ’22: Practice and Experience in Advanced Research Computing, Boston, MA, USA, 10–14 July 2020; Association for Computing Machinery: New York, NY, USA, 2022. [Google Scholar] [CrossRef]
- Keahey, K.; Anderson, J.; Zhen, Z.; Riteau, P.; Ruth, P.; Stanzione, D.; Cevik, M.; Colleran, J.; Gunawi, H.S.; Hammock, C.; et al. Lessons Learned from the Chameleon Testbed. In Proceedings of the 2020 USENIX Annual Technical Conference (USENIX ATC’20), Philadelphia, PA, USA, 15–17 July 2020. [Google Scholar]
- Alappat, C.L.; Hofmann, J.; Hager, G.; Fehske, H.; Bishop, A.R.; Wellein, G. Understanding HPC Benchmark Performance on Intel Broadwell And Cascade Lake Processors. In Proceedings of the High Performance Computing: 35th International Conference, ISC High Performance 2020, Frankfurt/Main, Germany, 22–25 June 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 412–433. [Google Scholar] [CrossRef]
- Velten, M.; Schöne, R.; Ilsche, T.; Hackenberg, D. Memory Performance of AMD EPYC Rome and Intel Cascade Lake SP Server Processors. In Proceedings of the ICPE ′22: ACM/SPEC on International Conference on Performance Engineering, Beijing China, 9–13 April 2022; Association for Computing Machinery: New York, NY, USA, 2022; pp. 165–175. [Google Scholar] [CrossRef]
- Harris, C.R.; Millman, K.J.; van der Walt, S.J.; Gommers, R.; Virtanen, P.; Cournapeau, D.; Wieser, E.; Taylor, J.; Berg, S.; Smith, N.J.; et al. Array programming with NumPy. Nature 2020, 585, 357–362. [Google Scholar] [CrossRef]
- Lam, S.K.; Pitrou, A.; Seibert, S. Numba: A LLVM-Based Python JIT Compiler. In Proceedings of the Second Workshop on the LLVM Compiler Infrastructure in HPC, LLVM’15, Austin, TX, USA, 15 November 2015; Association for Computing Machinery: New York, NY, USA, 2015. [Google Scholar] [CrossRef]
- Oden, L. Lessons learned from comparing C-CUDA and Python-Numba for GPU-Computing. In Proceedings of the 2020 28th Euromicro International Conference on Parallel, Distributed and Network-Based Processing (PDP), Västerås, Sweden, 11–13 March 2020; pp. 216–223. [Google Scholar] [CrossRef]
- Crist, J. Dask & Numba: Simple libraries for optimizing scientific python code. In Proceedings of the 2016 IEEE International Conference on Big Data (Big Data), Washington, DC, USA, 5–8 December 2016; pp. 2342–2343. [Google Scholar] [CrossRef]
- Betcke, T.; Scroggs, M.W. Designing a High-Performance Boundary Element Library With OpenCL and Numba. Comput. Sci. Eng. 2021, 23, 18–28. [Google Scholar] [CrossRef]
- Siket, M.; Dénes-Fazakas, L.; Kovács, L.; Eigner, G. Numba-accelerated parameter estimation for artificial pancreas applications. In Proceedings of the 2022 IEEE 20th Jubilee International Symposium on Intelligent Systems and Informatics (SISY), Subotica, Serbia, 15–17 September 2022; pp. 279–284. [Google Scholar] [CrossRef]
- Almgren-Bell, J.; Awar, N.A.; Geethakrishnan, D.S.; Gligoric, M.; Biros, G. A Multi-GPU Python Solver for Low-Temperature Non-Equilibrium Plasmas. In Proceedings of the 2022 IEEE 34th International Symposium on Computer Architecture and High Performance Computing (SBAC-PAD), Bordeaux, France, 2–5 November 2022; pp. 140–149. [Google Scholar] [CrossRef]
- Silvestri, L.G.; Stanek, L.J.; Choi, Y.; Murillo, M.S.; Dharuman, G. Sarkas: A Fast Pure-Python Molecular Dynamics Suite for Non-Ideal Plasmas. In Proceedings of the 2021 IEEE International Conference on Plasma Science (ICOPS), Lake Tahoe, NV, USA, 12–16 September 2021; p. 1. [Google Scholar] [CrossRef]
- Dogaru, R.; Dogaru, I. A Low Cost High Performance Computing Platform for Cellular Nonlinear Networks Using Python for CUDA. In Proceedings of the 2015 20th International Conference on Control Systems and Computer Science, Bucharest, Romania, 27–29 May 2015; pp. 593–598. [Google Scholar] [CrossRef]
- Dogaru, R.; Dogaru, I. Optimization of GPU and CPU acceleration for neural networks layers implemented in Python. In Proceedings of the 2017 5th International Symposium on Electrical and Electronics Engineering (ISEEE), Galati, Romania, 20–22 October 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Di Domenico, D.; Cavalheiro, G.G.H.; Lima, J.V.F. NAS Parallel Benchmark Kernels with Python: A performance and programming effort analysis focusing on GPUs. In Proceedings of the 2022 30th Euromicro International Conference on Parallel, Distributed and Network-based Processing (PDP), Valladolid, Spain, 9–11 March 2022; pp. 26–33. [Google Scholar] [CrossRef]
- Karnehm, D.; Sorokina, N.; Pohlmann, S.; Mashayekh, A.; Kuder, M.; Gieraths, A. A High Performance Simulation Framework for Battery Modular Multilevel Management Converter. In Proceedings of the 2022 International Conference on Smart Energy Systems and Technologies (SEST), Eindhoven, The Netherlands, 5–7 September 2022; pp. 1–6. [Google Scholar] [CrossRef]
- Yang, F.; Menard, J.E. PyISOLVER—A Fast Python OOP Implementation of LRDFIT Model. IEEE Trans. Plasma Sci. 2020, 48, 1793–1798. [Google Scholar] [CrossRef]
- Mattson, T.G.; Anderson, T.A.; Georgakoudis, G. PyOMP: Multithreaded Parallel Programming in Python. Comput. Sci. Eng. 2021, 23, 77–80. [Google Scholar] [CrossRef]
- Zhou, Y.; Cheng, J.; Liu, T.; Wang, Y.; Deng, H.; Xiong, Y. GPU-based SAR Image Lee Filtering. In Proceedings of the 2019 IEEE 7th International Conference on Computer Science and Network Technology (ICCSNT), Dalian, China, 19–20 October 2019; pp. 17–21. [Google Scholar] [CrossRef]
- Dogaru, R.; Dogaru, I. A Python Framework for Fast Modelling and Simulation of Cellular Nonlinear Networks and other Finite-difference Time-domain Systems. In Proceedings of the 2021 23rd International Conference on Control Systems and Computer Science (CSCS), Bucharest, Romania, 26–28 May 2021; pp. 221–226. [Google Scholar] [CrossRef]
- Alnaasan, N.; Jain, A.; Shafi, A.; Subramoni, H.; Panda, D.K. OMB-Py: Python Micro-Benchmarks for Evaluating Performance of MPI Libraries on HPC Systems. In Proceedings of the 2022 IEEE International Parallel and Distributed Processing Symposium Workshops (IPDPSW), Lyon, France, 30 May–3 June 2022; pp. 870–879. [Google Scholar] [CrossRef]
- Lattner, C.; Adve, V. LLVM: A compilation framework for lifelong program analysis & transformation. In Proceedings of the International Symposium on Code Generation and Optimization, San Jose, CA, USA, 20–24 March 2004; pp. 75–86. [Google Scholar] [CrossRef]
- Dagum, L.; Menon, R. OpenMP: An industry standard API for shared-memory programming. Comput. Sci. Eng. IEEE 1998, 5, 46–55. [Google Scholar] [CrossRef] [Green Version]
- Pheatt, C. Intel® Threading Building Blocks. J. Comput. Sci. Coll. 2008, 23, 298. [Google Scholar]
- Green, M.; Rowley, C.; Haller, G. Detection of Lagrangian Coherent Structures in 3D turbulence. J. Fluid Mech. 2007, 572, 111–120. [Google Scholar] [CrossRef] [Green Version]
- Pan, C.; Wang, J.J.; Zhang, C. Identification of Lagrangian coherent structures in the turbulent boundary layer. Sci. China Ser. G-Phys Mech. Astron. 2009, 52, 248–257. [Google Scholar] [CrossRef]
- Adrian, R. Hairpin vortex organization in wall turbulence. Phys. Fluids 2007, 19, 041301. [Google Scholar] [CrossRef] [Green Version]
- Pan, C.; Wang, J.; Zhang, P.; Feng, L. Coherent structures in bypass transition induced by a cylinder wake. J. Fluid Mech. 2008, 603, 367–389. [Google Scholar] [CrossRef]
- Lagares, C.; Araya, G. High-Resolution 4D Lagrangian Coherent Structures. 75th APS-DFD November 2022 (Virtual). 2022. Available online: https://doi.org/10.1103/APS.DFD.2022.GFM.V0025 (accessed on 14 May 2023).


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Case | ×× | ,/, | ||||
|---|---|---|---|---|---|---|
| Incomp. low | 0 | Isothermal | 306–578 | 146–262 | 14.7, 0.2/13, 8 | |
| Incomp. high | 0 | Isothermal | 2000–2400 | 752–928 | 11.5, 0.4/10, 10 | |
| Supersonic | 2.86 | 2.74 | 3454–4032 | 840–994 | 12.7, 0.4/11, 12 | |
| Hypersonic | 5 | 5.45 | 4107–4732 | 848–969 | × 3 × 3 | 12, 0.4/12, 11 |
| Device Name | P100 GPU (16 GB PCIe) | V100 GPU (32 GB PCIe) | A100 GPU (80 GB PCIe) | Intel Xeon E5-2699v4 | AMD EPYC 7H12 | AMD EPYC 7763 |
|---|---|---|---|---|---|---|
| Core (SM) Count | 56 | 80 | 108 | 22 | 64 | 64 |
| FP32 Vector Lanes (VL) | 3584 | 5120 | 6912 | 352 | 1024 | 1024 |
| Global Mem. Bandwidth [GB/s] | 732.2 | 897.0 | 1935 | 76.8 | 204.8 | 204.8 |
| Mem. Bandwidth per Core [GB/s] | 13.075 | 11.2125 | 17.917 | 3.49 | 3.2 | 3.2 |
| Mem. Bandwidth per VL [MB/s] | 204 | 175 | 280 | 218 | 200 | 200 |
| Shared Cache [KB] | 4096 | 6144 | 40,960 | 55,000 | 256,000 | 256,000 |
| Shared Cache Bandwidth [GB/s] | 1624 | 2155 | 4956 | [56] | [57] | N.P. |
| Base Frequency [GHz] | 1.190 | 1.230 | 0.765 | 2.2 | 2.6 | 2.45 |
| Boost Frequency [GHz] | 1.329 | 1.380 | 1.410 | 3.6 (SC) 2.8 (AC) | 3.3 (SC) All-core N.P. | 3.5 (SC) All-core N.P. |
| Est. TFLOPs/s Range [Min, Max] | 8.529 9.526 | 12.595 14.131 | 9.473 17.461 | 1.548 Variable | 5.324 Variable | 5.017 Variable |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lagares, C.; Araya, G. A GPU-Accelerated Particle Advection Methodology for 3D Lagrangian Coherent Structures in High-Speed Turbulent Boundary Layers. Energies 2023, 16, 4800. https://doi.org/10.3390/en16124800
Lagares C, Araya G. A GPU-Accelerated Particle Advection Methodology for 3D Lagrangian Coherent Structures in High-Speed Turbulent Boundary Layers. Energies. 2023; 16(12):4800. https://doi.org/10.3390/en16124800
Chicago/Turabian StyleLagares, Christian, and Guillermo Araya. 2023. "A GPU-Accelerated Particle Advection Methodology for 3D Lagrangian Coherent Structures in High-Speed Turbulent Boundary Layers" Energies 16, no. 12: 4800. https://doi.org/10.3390/en16124800