
Optimal Data-Driven Modelling of a Microbial Fuel Cell
 , and
, and
Abstract
:1. Introduction
- The performances of four different machine learning algorithms, namely support vector regression, Gaussian process regression, artificial neural networks, and ensemble learners, are evaluated in modeling a microbial fuel cell process.
- Two main model structures are investigated for evaluating the optimal performance of the microbial fuel cell. In the first model structure, current density and anolyte concentration were considered as model inputs, while current density and chemical oxygen demand were considered as model inputs in the second model structure.
- The performance of each ML algorithm was optimized with grid search, Bayesian optimization, and random search to determine the model parameters that yield the optimal results.
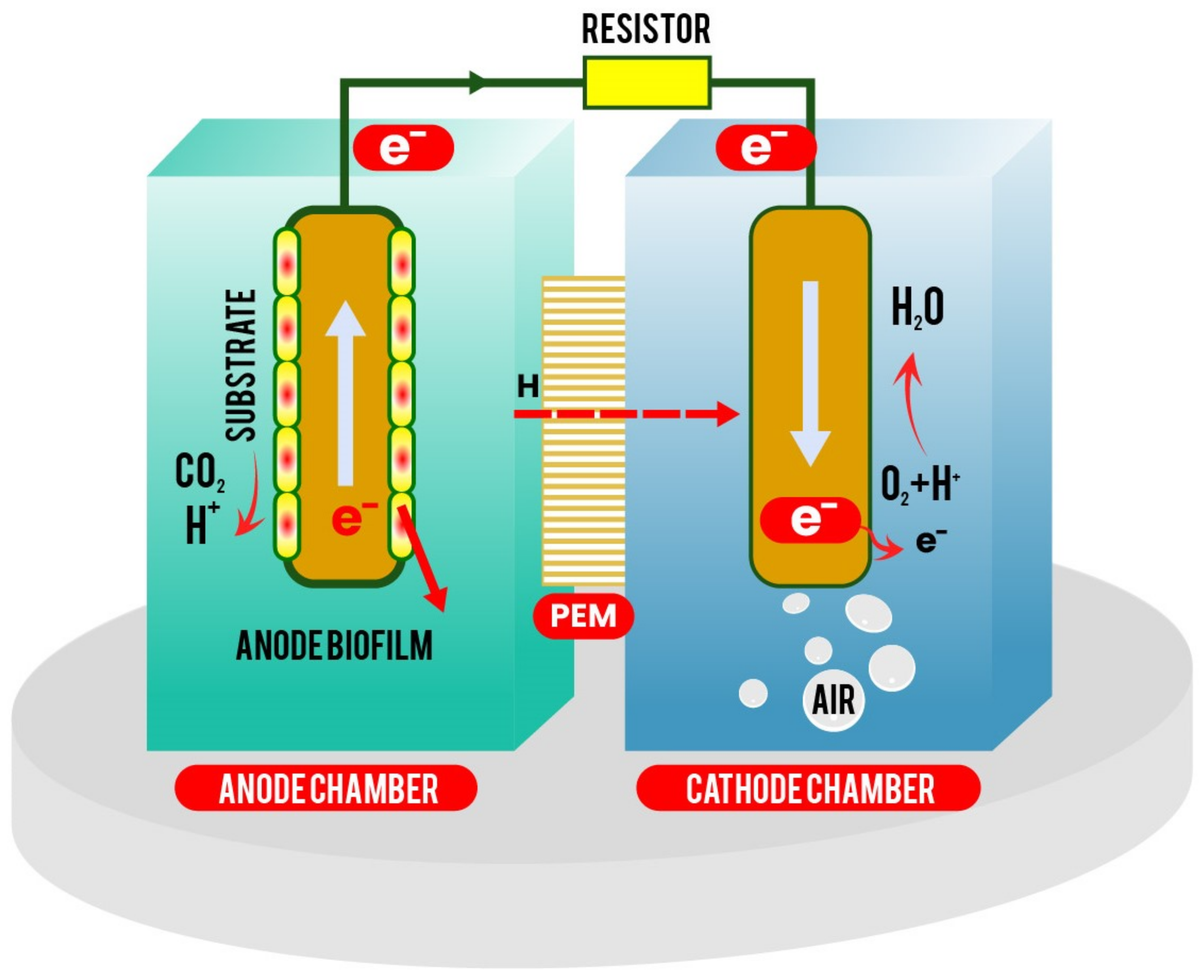
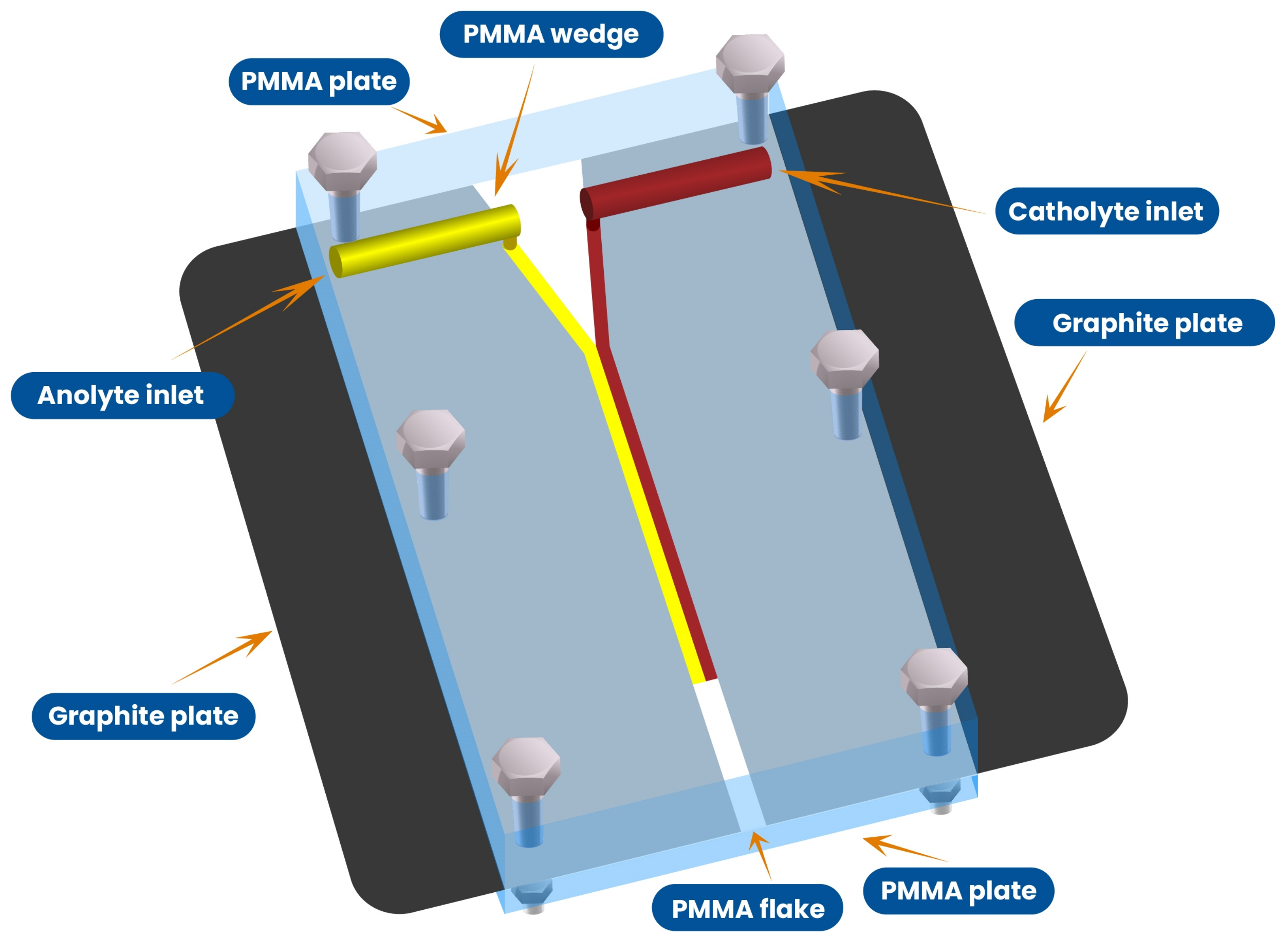
2. Data
3. Methodology
3.1. Model Structures
3.2. Modeling Algorithms
3.2.1. Artificial Neural Networks
3.2.2. Support Vector Regression
3.2.3. Gaussian Process Regression
3.2.4. Ensemble Learners
3.3. Hyperparameter Optimization
- The structure of f is typically unknown and cannot be described with attributes such as concavity or linearity.
- The nature of the optimization problem is derivative-free; this means that only the evaluation of is observed and not first or second derivatives, thus preventing the application of popular gradient descent methods.
- The size of input is typically not large, with .
- f is computationally expensive to evaluate; therefore, the number of objective function evaluations to be performed is limited to a few hundred.
- The membership of the feasibility set is assessable due to the simplicity of A.
4. Results and Discussion
4.1. Hyperparameter Optimization
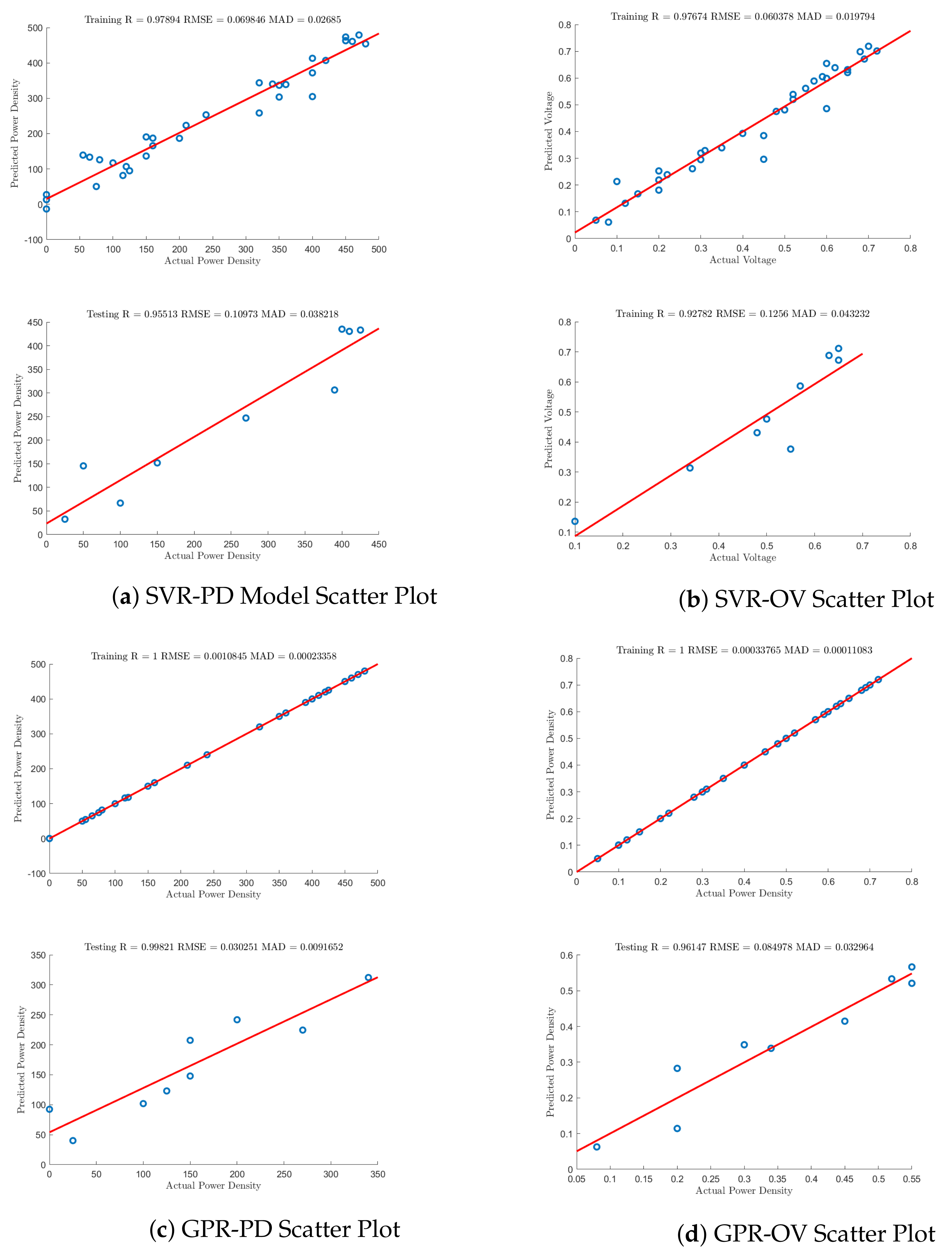
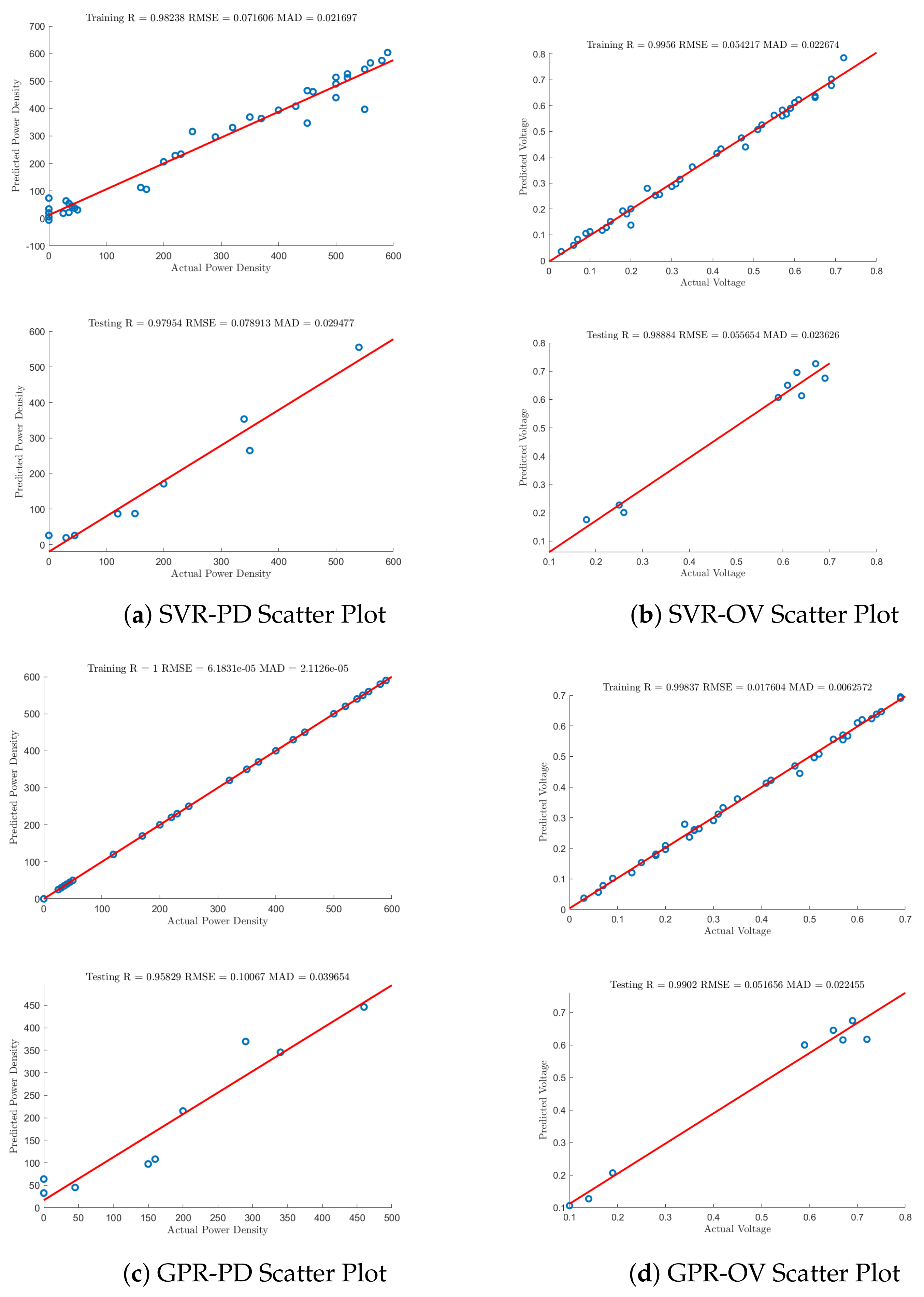
4.1.1. Support Vector Regression
4.1.2. Gaussian Process Regression
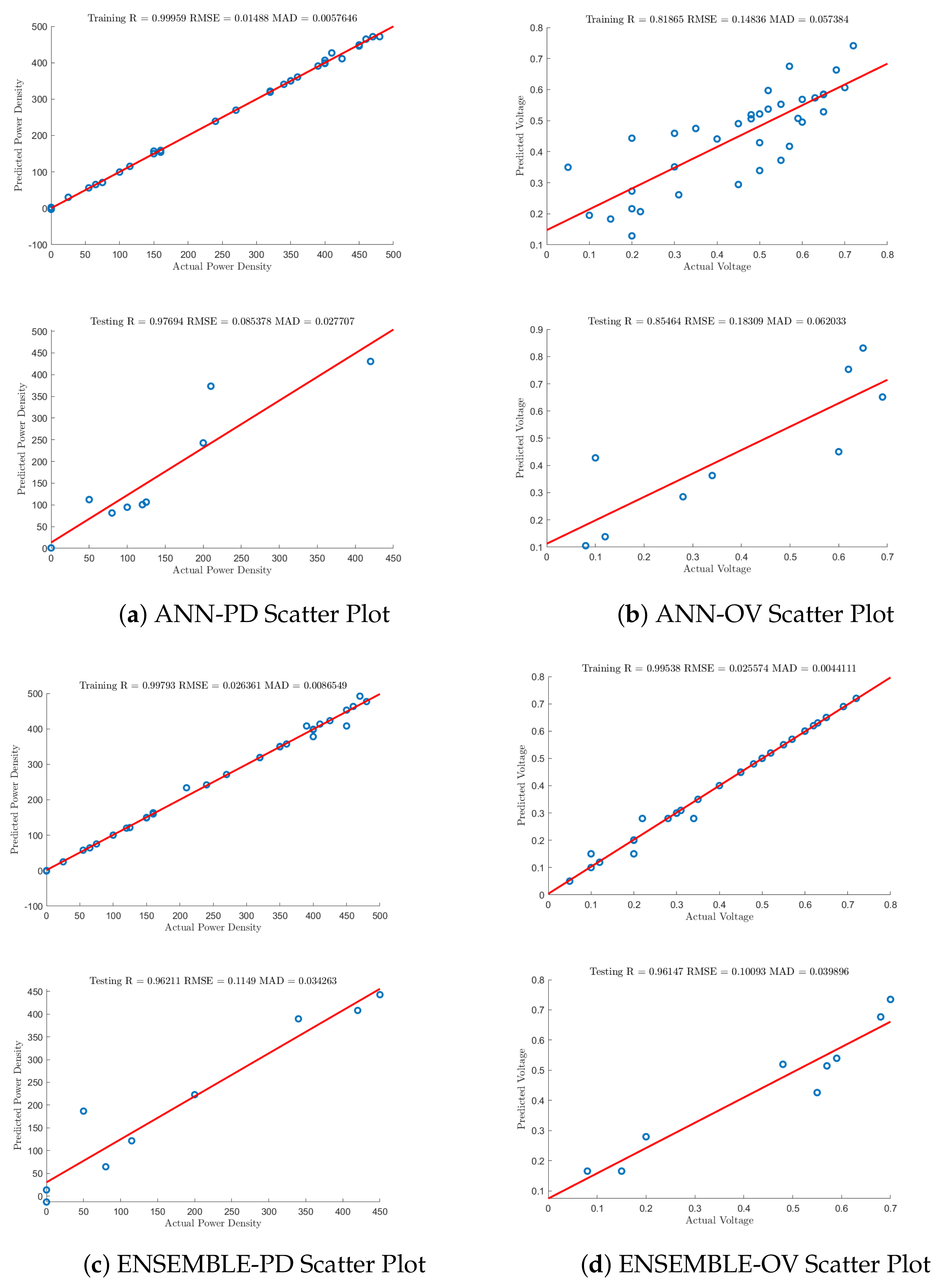
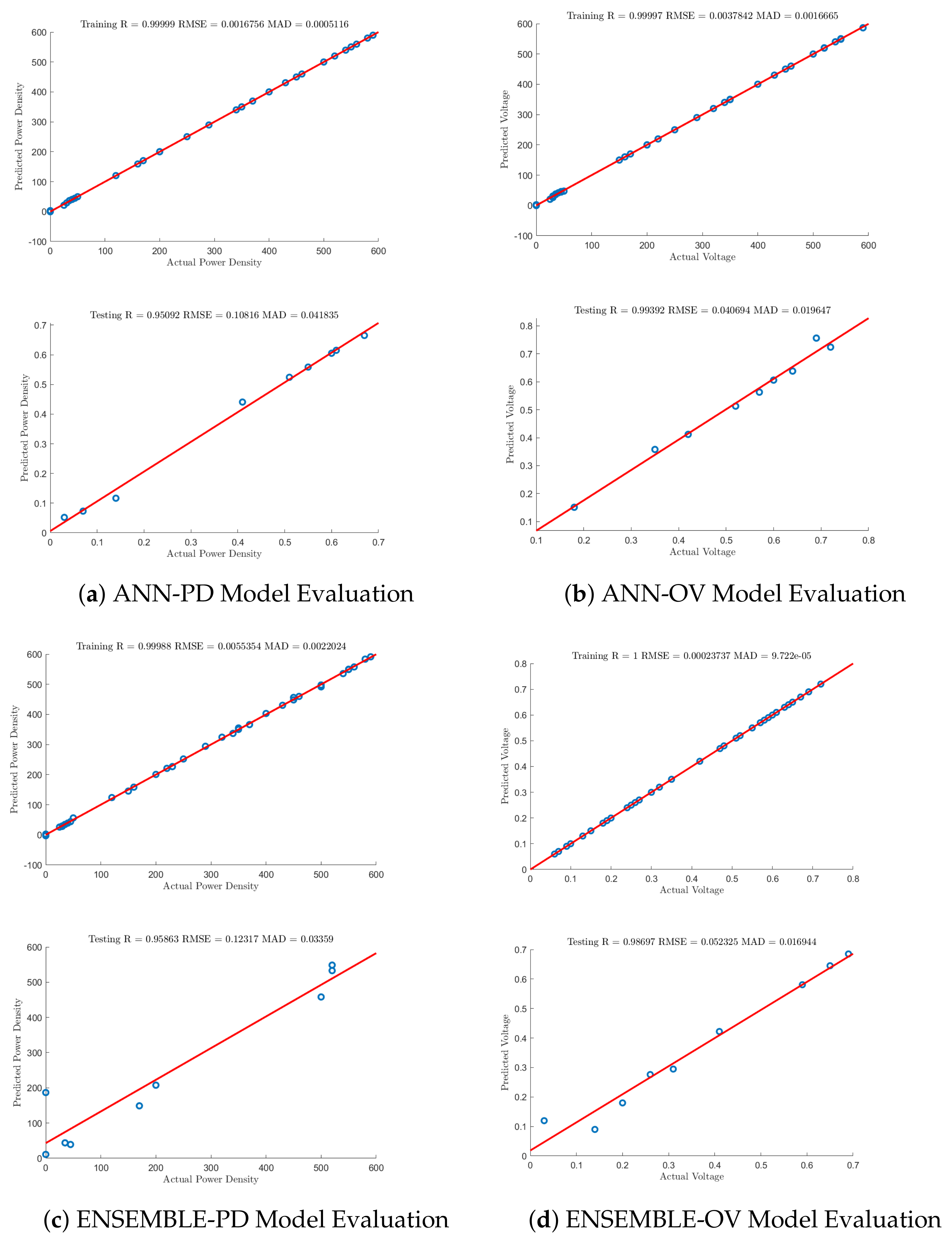
4.1.3. Artificial Neural Networks
4.1.4. Ensemble Learning
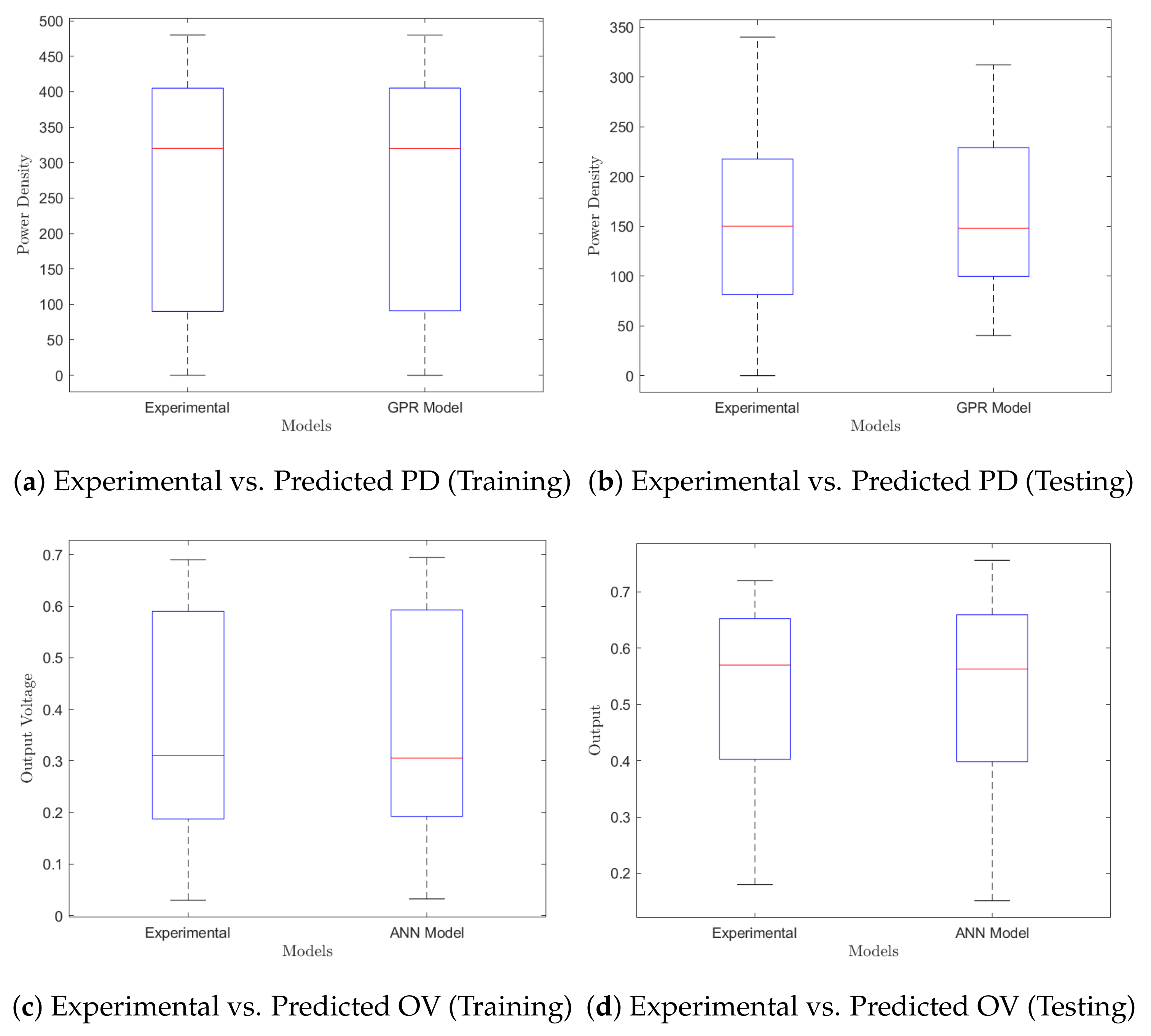
4.2. Model Comparisons
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Xia, C.; Zhang, D.; Pedrycz, W.; Zhu, Y.; Guo, Y. Models for Microbial Fuel Cells: A critical review. J. Power Sources 2018, 373, 119–131. [Google Scholar] [CrossRef]
- Garg, A.; Lam, J.S.L. Design of explicit models for estimating efficiency characteristics of microbial fuel cells. Energy 2017, 134, 136–156. [Google Scholar] [CrossRef]
- Mohamed, H.O.; Obaid, M.; Sayed, E.T.; Liu, Y.; Lee, J.; Park, M.; Barakat, N.A.M.; Kim, H.Y. Electricity generation from real industrial wastewater using a single-chamber air cathode microbial fuel cell with an activated carbon anode. Bioprocess Biosyst. Eng. 2017, 40, 1151–1161. [Google Scholar] [CrossRef]
- Min, B.; Logan, B.E. Continuous Electricity Generation from Domestic Wastewater and Organic Substrates in a Flat Plate Microbial Fuel Cell. Environ. Sci. Technol. 2004, 38, 5809–5814. [Google Scholar] [CrossRef] [PubMed]
- Jiang, J.; Zhao, Q.; Wei, L.; Wang, K.; Lee, D.J. Degradation and characteristic changes of organic matter in sewage sludge using microbial fuel cell with ultrasound pretreatment. Bioresour. Technol. 2011, 102, 272–277. [Google Scholar] [CrossRef]
- Nimje, V.R.; Chen, C.Y.; Chen, H.R.; Chen, C.C.; Huang, Y.M.; Tseng, M.J.; Cheng, K.C.; Chang, Y.F. Comparative bioelectricity production from various wastewaters in microbial fuel cells using mixed cultures and a pure strain of Shewanella oneidensis. Bioresour. Technol. 2012, 104, 315–323. [Google Scholar] [CrossRef] [PubMed]
- Asefi, B.; Li, S.L.; Moreno, H.A.; Sanchez-Torres, V.; Hu, A.; Li, J.; Yu, C.P. Characterization of electricity production and microbial community of food waste-fed microbial fuel cells. Process Saf. Environ. Prot. 2019, 125, 83–91. [Google Scholar] [CrossRef]
- Kebaili, H.; Kameche, M.; Innocent, C.; Ziane, F.; Sabeur, S.; Sahraoui, T.; Ouis, M.; Zerrouki, A.; Charef, M. Treatment of fruit waste leachate using microbial fuel cell: Preservation of agricultural environment. Acta Ecol. Sin. 2021, 41, 97–105. [Google Scholar] [CrossRef]
- Fujimura, S.; Kamitori, K.; Kamei, I.; Nagamine, M.; Miyoshi, K.; Inoue, K. Performance of stacked microbial fuel cells with Barley–Shochu waste. J. Biosci. Bioeng. 2022, 133, 467–473. [Google Scholar] [CrossRef]
- Chaturvedi, A.; Chaturvedi, A.; Nagaiah, T.C.; Kundu, P.P. Synthesis of Co/Ni @ Al2O3-GO as novel oxygen reduction electrocatalyst for sustainable bioelectricity production in single-chambered microbial fuel cells. J. Environ. Chem. Eng. 2021, 9, 106054. [Google Scholar] [CrossRef]
- Qavami, A.; Ghasemi, S. Nickel-cobalt manganate supported on reduced graphene oxide/carbon nanotube for improving air cathode performance in single chamber microbial fuel cell. Mater. Sci. Eng. B 2022, 275, 115492. [Google Scholar] [CrossRef]
- Kumar, V.; Rudra, R.; Hait, S. Sulfonated polyvinylidene fluoride-crosslinked-aniline-2-sulfonic acid as ion exchange membrane in single-chambered microbial fuel cell. J. Environ. Chem. Eng. 2021, 9, 106467. [Google Scholar] [CrossRef]
- Wang, H.; Chen, P.; Zhang, S.; Jiang, J.; Hua, T.; Li, F. Degradation of pyrene using single-chamber air-cathode microbial fuel cells: Electrochemical parameters and bacterial community changes. Sci. Total Environ. 2022, 804, 150153. [Google Scholar] [CrossRef] [PubMed]
- Esfandyari, M.; Fanaei, M.A.; Gheshlaghi, R.; Mahdavi, M.A. Neural network and neuro-fuzzy modeling to investigate the power density and Columbic efficiency of microbial fuel cell. J. Taiwan Inst. Chem. Eng. 2016, 58, 84–91. [Google Scholar] [CrossRef]
- Esfandyari, M.; Fanaei, M.A.; Gheshlaghi, R.; Mahdavi, M.A. Dynamic modeling of a continuous two-chamber microbial fuel cell with pure culture of Shewanella. Int. J. Hydrogen Energy 2017, 42, 21198–21202. [Google Scholar] [CrossRef]
- Xiao, B.; Yang, F.; Liu, J. Evaluation of electricity production from alkaline pretreated sludge using two-chamber microbial fuel cell. J. Hazard. Mater. 2013, 254–255, 57–63. [Google Scholar] [CrossRef]
- Nien, P.C.; Lee, C.Y.; Ho, K.C.; Adav, S.S.; Liu, L.; Wang, A.; Ren, N.; Lee, D.J. Power overshoot in two-chambered microbial fuel cell (MFC). Bioresour. Technol. 2011, 102, 4742–4746. [Google Scholar] [CrossRef]
- Wei, L.; Yuan, Z.; Cui, M.; Han, H.; Shen, J. Study on electricity-generation characteristic of two-chambered microbial fuel cell in continuous flow mode. Int. J. Hydrogen Energy 2012, 37, 1067–1073. [Google Scholar] [CrossRef]
- Wang, H.; Long, X.; Zhang, J.; Cao, X.; Liu, S.; Li, X. Relationship between bioelectrochemical copper migration, reduction and electricity in a three-chamber microbial fuel cell. Chemosphere 2020, 241, 125097. [Google Scholar] [CrossRef]
- Wang, C.; Shen, J.; Chen, Q.; Ma, D.; Zhang, G.; Cui, C.; Xin, Y.; Zhao, Y.; Hu, C. The inhibiting effect of oxygen diffusion on the electricity generation of three-chamber microbial fuel cells. J. Power Sources 2020, 453, 227889. [Google Scholar] [CrossRef]
- Yang, Z.; Li, J.; Chen, F.; Xu, L.; Jin, Y.; Xu, S.; Wang, J.; Shen, X.; Zhang, L.; Song, Y. Bioelectrochemical process for simultaneous removal of copper, ammonium and organic matter using an algae-assisted triple-chamber microbial fuel cell. Sci. Total Environ. 2021, 798, 149327. [Google Scholar] [CrossRef] [PubMed]
- Zhang, S.; Bao, R.; Lu, J.; Sang, W. Simultaneous sulfide removal, nitrification, denitrification and electricity generation in three-chamber microbial fuel cells. Sep. Purif. Technol. 2018, 195, 314–321. [Google Scholar] [CrossRef]
- Greenman, J.; Mendis, A.; You, J.; Gajda, I.; Horsfield, I.; Ieropoulos, I. Microbial Fuel Cell Based Thermosensor for Robotic Applications. Front. Robot. AI 2021, 8, 558953. [Google Scholar] [CrossRef]
- Tsompanas, M.A.I.; Adamatzky, A.; Sirakoulis, G.C.; Greenman, J.; Ieropoulos, I. Towards implementation of cellular automata in Microbial Fuel Cells. PLoS ONE 2017, 12, e0177528. [Google Scholar] [CrossRef] [Green Version]
- Kumar, R.; Singh, L.; Zularisam, A.W.; Hai, F.I. Microbial fuel cell is emerging as a versatile technology: A review on its possible applications, challenges and strategies to improve the performances. Int. J. Energy Res. 2017, 42, 369–394. [Google Scholar] [CrossRef] [Green Version]
- Santoro, C.; Arbizzani, C.; Erable, B.; Ieropoulos, I. Microbial fuel cells: From fundamentals to applications. A review. J. Power Sources 2017, 356, 225–244. [Google Scholar] [CrossRef]
- Philamore, H.; Rossiter, J.; Ieropoulos, I. Sub-millilitre Microbial Fuel Cell Power for Soft Robots. In Biomimetic and Biohybrid Systems; Springer: Berlin/Heidelberg, Germany, 2013; pp. 424–426. [Google Scholar]
- Feng, Y.; Barr, W.; Harper, W. Neural network processing of microbial fuel cell signals for the identification of chemicals present in water. J. Environ. Manag. 2013, 120, 84–92. [Google Scholar] [CrossRef]
- de Ramón-Fernández, A.; Salar-García, M.; Ruiz-Fernández, D.; Greenman, J.; Ieropoulos, I. Modelling the energy harvesting from ceramic-based microbial fuel cells by using a fuzzy logic approach. Appl. Energy 2019, 251, 113321. [Google Scholar] [CrossRef]
- Ghasemi, M.; Nassef, A.M.; Al-Dhaifallah, M.; Rezk, H. Performance improvement of microbial fuel cell through artificial intelligence. Int. J. Energy Res. 2020, 45, 342–354. [Google Scholar] [CrossRef]
- de Ramón-Fernández, A.; Salar-García, M.; Fernández, D.R.; Greenman, J.; Ieropoulos, I. Evaluation of artificial neural network algorithms for predicting the effect of the urine flow rate on the power performance of microbial fuel cells. Energy 2020, 213, 118806. [Google Scholar] [CrossRef] [PubMed]
- Ye, D.; Yang, Y.; Li, J.; Zhu, X.; Liao, Q.; Deng, B.; Chen, R. Performance of a microfluidic microbial fuel cell based on graphite electrodes. Int. J. Hydrogen Energy 2013, 38, 15710–15715. [Google Scholar] [CrossRef]
- Tardast, A.; Rahimnejad, M.; Najafpour, G.; Ghoreyshi, A.; Premier, G.C.; Bakeri, G.; Oh, S.E. Use of artificial neural network for the prediction of bioelectricity production in a membrane less microbial fuel cell. Fuel 2014, 117, 697–703. [Google Scholar] [CrossRef]
- Jaeel, A.J.; Al-wared, A.I.; Ismail, Z.Z. Prediction of sustainable electricity generation in microbial fuel cell by neural network: Effect of anode angle with respect to flow direction. J. Electroanal. Chem. 2016, 767, 56–62. [Google Scholar] [CrossRef]
- Tsompanas, M.A.; You, J.; Wallis, L.; Greenman, J.; Ieropoulos, I. Artificial neural network simulating microbial fuel cells with different membrane materials and electrode configurations. J. Power Sources 2019, 436, 226832. [Google Scholar] [CrossRef]
- King, S.T.; Sylvander, M.; Kheperu, M.; Racz, L.; Harper, W.F., Jr. Detecting recalcitrant organic chemicals in water with microbial fuel cells and artificial neural networks. Sci. Total Environ. 2014, 497–498, 527–533. [Google Scholar] [CrossRef]
- Vapnik, V. The Nature of Statistical Learning Theory; Information Science and Statistics; Springer: New York, NY, USA, 2000. [Google Scholar]
- Sahaluddin, M.; Alade, I.O.; Oyedeji, M.O.; Aliyu, U.S. A machine learning-based model to estimate the density of nanofluids of nitrides in ethylene glycol. J. Appl. Phys. 2020, 127, 205105. [Google Scholar] [CrossRef]
- Alade, I.O.; Rahman, M.A.A.; Saleh, T.A. Predicting the specific heat capacity of alumina/ethylene glycol nanofluids using support vector regression model optimized with Bayesian algorithm. Sol. Energy 2019, 183, 74–82. [Google Scholar] [CrossRef]
- Alade, I.O.; Oyedeji, M.O.; Rahman, M.A.A.; Saleh, T.A. Predicting the density of carbon-based nanomaterials in diesel oil through computational intelligence methods. J. Therm. Anal. Calorim. 2022, 147, 8699–8707. [Google Scholar] [CrossRef]
- Olumegbon, I.A.; Alade, I.O.; Sahaluddin, M.; Oyedeji, M.O.; Sa’ad, A.U. Modelling the viscosity of carbon-based nanomaterials dispersed in diesel oil: A machine learning approach. J. Therm. Anal. Calorim. 2021, 145, 1769–1777. [Google Scholar] [CrossRef]
- Wang, J.; Wang, Q.; Zhou, J.; Wang, X.; Cheng, L. Operation space design of microbial fuel cells combined anaerobic–anoxic–oxic process based on support vector regression inverse model. Eng. Appl. Artif. Intell. 2018, 72, 340–349. [Google Scholar] [CrossRef]
- Hossain, S.Z.; Sultana, N.; Mohammed, M.E.; Razzak, S.A.; Hossain, M.M. Hybrid support vector regression and crow search algorithm for modeling and multiobjective optimization of microalgae-based wastewater treatment. J. Environ. Manag. 2022, 301, 113783. [Google Scholar] [CrossRef] [PubMed]
- He, Y.J.; Ma, Z.F. A Data-Driven Gaussian Process Regression Model for Two-Chamber Microbial Fuel Cells. Fuel Cells 2016, 16, 365–376. [Google Scholar] [CrossRef]
- Cao, J.; Lin, Z.; Huang, G.B.; Liu, N. Voting based extreme learning machine. Inf. Sci. 2012, 185, 66–77. [Google Scholar] [CrossRef]
- Lan, Y.; Soh, Y.C.; Huang, G.B. Ensemble of online sequential extreme learning machine. Neurocomputing 2009, 72, 3391–3395. [Google Scholar] [CrossRef]
- Cao, J.J.; Kwong, S.; Wang, R.; Li, K. A weighted voting method using minimum square error based on Extreme Learning Machine. In Proceedings of the 2012 International Conference on Machine Learning and Cybernetics, Xi’an, China, 15–17 July 2012; IEEE: Piscataway, NJ, USA, 2012. [Google Scholar] [CrossRef]
- Frazier, P.I. A Tutorial on Bayesian Optimization. arXiv 2018, arXiv:1807.02811. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Chemical Formula and Quantity | |
|---|---|
| NaCl | 0.5 g/L |
| CH3COONa·3H2O | 1.13 g/L |
| NH4Cl | 0.1 g/L |
| MgSO4·7H2O | 0.1 g/L |
| NH2HPO4·12H20 | 15.3 g/L |
| KH2PO4 | 3 g/L |
| CaCl2 | 11 mg/L |
| Trace Elements | 1.0 mL/L |
| Model | BC | KS | Epsilon | KF | PO | Standardize | MO |
|---|---|---|---|---|---|---|---|
| Bayesian Optimization | |||||||
| PD-I | 97.01 | - | 15.83 | polynomial | 4 | true | 8.22 |
| OV-I | 0.64 | - | 0.000804 | polynomial | 4 | true | 0.0082 |
| PD-II | 432.28 | - | 8.49 | polynomial | 3 | true | 7.71 |
| OV-II | 245.92 | - | 0.013731 | polynomial | 4 | true | 0.0026 |
| Grid Search | |||||||
| PD-I | 215.44 | - | 0.23351 | polynomial | 4 | true | 8.4966 |
| OV-I | 2.1544 | - | 0.00021497 | polynomial | 2 | true | 0.0088 |
| PD-II | 215.44 | - | 15.01 | polynomial | 4 | true | 7.8279 |
| OV-II | 0.46416 | - | 0.047607 | polynomial | 3 | true | 0.0057 |
| Random Search | |||||||
| PD-I | 210.61 | - | 69.337 | polynomial | 2 | true | 8.3156 |
| OV-I | 314.43 | 2.2181 | 0.018786 | gaussian | - | true | 0.0067 |
| PD-II | 79.263 | - | 29.712 | polynomial | 3 | true | 7.9745 |
| OV-II | 1.7538 | - | 0.00074444 | polynomial | 4 | true | 0.0030 |
| Model | Sigma | Basis Function | Kernel Function | Kernel Scale | Standardize | MO |
|---|---|---|---|---|---|---|
| Bayesian Optimization | ||||||
| PD-I | 0.12 | pureQuadratic | ardmatern32 | - | true | 8.11 |
| OV-I | 0.0035 | linear | ardexponential | - | false | 0.0026 |
| PD-II | 0.013542 | pureQuadratic | ardmatern32 | - | false | 7.9363 |
| OV-II | 0.00010833 | pureQuadratic | matern52 | 1916.4 | false | 0.0012 |
| Grid Search | ||||||
| PD-I | 1.0276 | constant | matern32 | 10.444 | true | 8.0036 |
| OV-I | 0.07247 | none | matern32 | 2.25 | true | 0.0050103 |
| PD-II | 0.18217 | none | exponential | 928.32 | false | 7.7791 |
| OV-II | 0.024824 | pureQuadratic | ardsquaredexponential | - | true | 0.00056799 |
| Random Search | ||||||
| PD-I | 0.00028081 | none | ardmatern52 | - | true | 7.6804 |
| OV-I | 0.00062233 | linear | ardmatern32 | - | true | 0.0027988 |
| PD-II | 13.057 | none | ardrationalquadratic | - | true | 7.9585 |
| OV-II | 0.020 | linear | ardmatern52 | - | true | 0.00070001 |
| Model | Activations | Lambda | LWI | LBI | LayerSize | Standardize | MO |
|---|---|---|---|---|---|---|---|
| Bayesian Optimization | |||||||
| PD-I | tanh | 0.545 | he | zeros | [87 255 127] | true | 7.85 |
| OV-I | sigmoid | he | ones | [287 119] | true | 0.0024 | |
| PD-II | relu | he | zeros | [214 241] | true | 7.04 | |
| OV-II | relu | he | zeros | [33] | true | 0.0012 | |
| Grid Search | |||||||
| PD-I | tanh | 0.099828 | glorot | ones | [13] | true | 8.1602 |
| OV-I | sigmoid | glorot | ones | [300 159 159] | true | 0.0043 | |
| PD-II | relu | 16.202 | glorot | zeros | [24 159] | true | 7.8778 |
| OV-II | tanh | he | ones | [4 2 7] | true | 0.0013415 | |
| Random Search | |||||||
| PD-I | relu | he | ones | [5 190] | true | 7.7136 | |
| OV-I | sigmoid | glorot | ones | [89 2] | true | 0.003678 | |
| PD-II | tanh | 0.052638 | he | ones | [52 155] | true | 8.0649 |
| OV-II | tanh | he | ones | [5 11] | true | 0.00056841 | |
| Model | Method | NLC | LR | MLS | MNS | VS | MO |
|---|---|---|---|---|---|---|---|
| Bayesian Optimization | |||||||
| PD-I | LSBoost | 288 | 0.14 | 1 | 34 | 1 | 8.14 |
| OV-I | LSBoost | 432 | 0.89 | 3 | 2 | 2 | 0.019 |
| PD-II | LSBoost | 16 | 0.4303 | 1 | 36 | 1 | 8.2865 |
| OV-II | LSBoost | 155 | 0.0827 | 4 | 2 | 1 | 0.0021 |
| Grid Search | |||||||
| PD-I | LSBoost | 324 | 0.046416 | 2 | 11 | 2 | 8.6515 |
| OV-I | LSBoost | 324 | 0.46416 | 4 | 7 | 2 | 0.0033 |
| PD-II | LSBoost | 37 | 0.46416 | 1 | 36 | 2 | 7.7934 |
| OV-II | LSBoost | 324 | 0.21544 | 1 | 24 | 2 | 0.0014 |
| Random Search | |||||||
| PD-I | LSBoost | 389 | 0.21924 | 3 | 8 | 1 | 8.2468 |
| OV-I | LSBoost | 251 | 0.14145 | 2 | 9 | 1 | 0.0044 |
| PD-II | LSBoost | 317 | 0.042925 | 1 | 10 | 1 | 7.9872 |
| OV-II | LSBoost | 65 | 0.39092 | 1 | 35 | 2 | 0.0016 |
| Training | Testing | |||||
|---|---|---|---|---|---|---|
| Model | RMSE | MAD | RMSE | MAD | ||
| PD-SVR | 0.9789 | 0.0698 | 0.0268 | 0.9153 | 0.1097 | 0.0382 |
| PD-GPR | 1.0000 | 0.0010 | 0.0002 | 0.9982 | 0.0302 | 0.0091 |
| PD-ANN | 0.9995 | 0.0148 | 0.0057 | 0.9769 | 0.0854 | 0.0277 |
| PD-ENSEMBLE | 0.9973 | 0.0263 | 0.0086 | 0.9621 | 0.1149 | 0.0342 |
| OV-SVR | 0.9767 | 0.0600 | 0.0197 | 0.9278 | 0.1256 | 0.0432 |
| OV-GPR | 1.0000 | 0.0003 | 0.0001 | 0.9614 | 0.0850 | 0.0330 |
| OV-ANN | 0.8186 | 0.1483 | 0.0057 | 0.8546 | 0.1831 | 0.0620 |
| OV-ENSEMBLE | 0.9953 | 0.0255 | 0.0044 | 0.9614 | 0.1009 | 0.0399 |
| Training | Testing | |||||
|---|---|---|---|---|---|---|
| Model | RMSE | MAD | RMSE | MAD | ||
| PD-SVR | 0.9824 | 0.0716 | 0.0217 | 0.9795 | 0.0789 | 0.0295 |
| PD-GPR | 1.0000 | 0.00006 | 0.00002 | 0.9583 | 0.1006 | 0.0039 |
| PD-ANN | 0.9995 | 0.01488 | 0.0057 | 0.9769 | 0.0854 | 0.0277 |
| PD-ENSEMBLE | 0.9979 | 0.0263 | 0.0086 | 0.9621 | 0.1149 | 0.0342 |
| OV-SVR | 0.9956 | 0.0542 | 0.0223 | 0.9888 | 0.0556 | 0.0236 |
| OV-GPR | 0.9983 | 0.0176 | 0.0062 | 0.9902 | 0.0516 | 0.0224 |
| OV-ANN | 0.9999 | 0.0003 | 0.0016 | 0.9939 | 0.0406 | 0.0196 |
| OV-ENSEMBLE | 1.0000 | 0.0002 | 0.00009 | 0.9869 | 0.0523 | 0.01694 |
| Current Density | Anolyte Concentration | Power Density (Exp) | Power Density (Pred) |
|---|---|---|---|
| Training | |||
| 0 | 5 | 0 | 0.34339813 |
| 100 | 5 | 75 | 74.2800234 |
| 150 | 5 | 100 | 99.88043377 |
| 300 | 5 | 120 | 117.9662687 |
| 400 | 5 | 80 | 81.67882275 |
| 450 | 5 | 65 | 64.99960065 |
| 750 | 5 | 50 | 50.02761297 |
| 0 | 10 | 0 | −0.041741094 |
| 500 | 10 | 320 | 319.9249303 |
| 750 | 10 | 400 | 399.9600416 |
| 1000 | 10 | 350 | 350.0020362 |
| 0 | 20 | 0 | 0.027481016 |
| 500 | 20 | 360 | 359.9074023 |
| 750 | 20 | 410 | 410.1444232 |
| 1250 | 20 | 400 | 400.0602652 |
| 1500 | 20 | 320 | 319.9797993 |
| 0 | 40 | 0 | −0.005480526 |
| 250 | 40 | 160 | 160.0652346 |
| 500 | 40 | 350 | 349.9075691 |
| 1000 | 40 | 450 | 450.0548606 |
| 1250 | 40 | 480 | 479.9573814 |
| 1750 | 40 | 210 | 210.0434299 |
| 250 | 60 | 150 | 149.9998696 |
| 1000 | 60 | 400 | 400.0033257 |
| 1500 | 60 | 470 | 470.0090551 |
| 1750 | 60 | 450 | 449.9858254 |
| 2250 | 60 | 390 | 389.980239 |
| 200 | 5 | 115 | 116.3443356 |
| 750 | 40 | 425 | 425.0127718 |
| 1250 | 60 | 460 | 459.9801203 |
| 1000 | 20 | 450 | 449.8780158 |
| 250 | 10 | 160 | 160.113909 |
| 500 | 5 | 55 | 54.51161768 |
| 1500 | 40 | 400 | 399.9589216 |
| 2000 | 60 | 420 | 420.0173303 |
| 1250 | 10 | 240 | 240.0113957 |
| Testing | |||
| 50 | 5 | 25 | 40.19067673 |
| 250 | 5 | 125 | 123.0486118 |
| 1500 | 10 | 150 | 147.878756 |
| 1750 | 20 | 200 | 241.7814819 |
| 0 | 60 | 0 | 92.46039675 |
| 500 | 60 | 270 | 224.54181 |
| 750 | 60 | 340 | 312.1917304 |
| 350 | 5 | 100 | 101.8892903 |
| 250 | 20 | 150 | 207.4972159 |
| Current Density | Chemical Oxygen Demand | Voltage (Exp) | Voltage (Pred) |
|---|---|---|---|
| Training | |||
| 0 | 100 | 0.3 | 0.301292574 |
| 50 | 100 | 0.27 | 0.270779805 |
| 100 | 100 | 0.25 | 0.240441584 |
| 200 | 100 | 0.18 | 0.181072746 |
| 250 | 100 | 0.15 | 0.152516957 |
| 300 | 100 | 0.14 | 0.12507906 |
| 400 | 100 | 0.07 | 0.074770924 |
| 450 | 100 | 0.06 | 0.052516078 |
| 500 | 100 | 0.03 | 0.032575835 |
| 250 | 500 | 0.67 | 0.668121708 |
| 750 | 500 | 0.61 | 0.607594451 |
| 1000 | 500 | 0.58 | 0.578752368 |
| 1500 | 500 | 0.24 | 0.240130435 |
| 1750 | 500 | 0.13 | 0.129828615 |
| 250 | 1000 | 0.65 | 0.651108508 |
| 500 | 1000 | 0.61 | 0.60898659 |
| 1750 | 1000 | 0.26 | 0.260703735 |
| 0 | 1500 | 0.69 | 0.69378588 |
| 250 | 1500 | 0.65 | 0.647309106 |
| 750 | 1500 | 0.57 | 0.566099365 |
| 1500 | 1500 | 0.32 | 0.323114972 |
| 1750 | 1500 | 0.26 | 0.256997405 |
| 2000 | 1500 | 0.2 | 0.200363296 |
| 0 | 2000 | 0.69 | 0.686585999 |
| 750 | 2000 | 0.55 | 0.554208041 |
| 1250 | 2000 | 0.41 | 0.409063645 |
| 1500 | 2000 | 0.31 | 0.305269093 |
| 1750 | 2000 | 0.19 | 0.196320251 |
| 2000 | 2000 | 0.1 | 0.096873135 |
| 150 | 100 | 0.2 | 0.210465426 |
| 350 | 100 | 0.09 | 0.099060228 |
| 500 | 500 | 0.63 | 0.633262151 |
| 1000 | 2000 | 0.51 | 0.508001665 |
| 750 | 1000 | 0.59 | 0.592736549 |
| 1250 | 1000 | 0.47 | 0.470245135 |
| 500 | 2000 | 0.59 | 0.592277611 |
| 1250 | 500 | 0.48 | 0.480093074 |
| Testing | |||
| 0 | 500 | 0.72 | 0.72386166 |
| 0 | 1000 | 0.69 | 0.756116272 |
| 1000 | 1000 | 0.57 | 0.562841991 |
| 1500 | 1000 | 0.35 | 0.357919862 |
| 2000 | 1000 | 0.18 | 0.151244441 |
| 500 | 1500 | 0.6 | 0.605950688 |
| 1000 | 1500 | 0.52 | 0.512822799 |
| 250 | 2000 | 0.64 | 0.638189001 |
| 1250 | 1500 | 0.42 | 0.411916742 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Oyedeji, M.O.; Alharbi, A.; Aldhaifallah, M.; Rezk, H. Optimal Data-Driven Modelling of a Microbial Fuel Cell. Energies 2023, 16, 4740. https://doi.org/10.3390/en16124740
Oyedeji MO, Alharbi A, Aldhaifallah M, Rezk H. Optimal Data-Driven Modelling of a Microbial Fuel Cell. Energies. 2023; 16(12):4740. https://doi.org/10.3390/en16124740
Chicago/Turabian StyleOyedeji, Mojeed Opeyemi, Abdullah Alharbi, Mujahed Aldhaifallah, and Hegazy Rezk. 2023. "Optimal Data-Driven Modelling of a Microbial Fuel Cell" Energies 16, no. 12: 4740. https://doi.org/10.3390/en16124740