
Abnormal Data Detection and Identification Method of Distribution Internet of Things Monitoring Terminal Based on Spatiotemporal Correlation

Abstract
:1. Introduction
2. Cluster-Based LTU Anomaly Detection Method
2.1. Source of Abnormal State of LTU in Low-Voltage Distribution Network
- ①
- Hardware faults: Hardware faults are mostly caused by the failure of the internal communication module of the LTU, the exhaustion of battery power, or the failure of some types of A/D conversion modules. Measurement data usually show data interruption or measurement data at a positive/negative limit.
- ②
- Stuck-at faults: Stuck-at faults are characterized by a series of offset and continuous readings, and these sampling data may persist in subsequent sampling cycles. The offset is maintained or may return to normal after a period of time. The offset sampling data may be within the normal sampling data range or may exceed the range of the normal sampling data. Such faults are generally caused by the abnormality of the internal sampling module of the LTU.
- ③
- Low-voltage faults: Typical low-voltage faults usually manifest as a result of constant sampling data or offset values, which significantly increase the data noise. This type of fault is generally caused by an abnormal drop in battery power due to an internal/external short-circuit of the battery when the LTU is in battery power supply mode.
- ④
- Calibration failure: The reason for this failure is a calibration error, which is manifested as a relatively fixed offset between the sampled data and the actual data, which may be large or small.
2.2. Anomaly Detection Method Based on Clustering
2.2.1. Improved Composite Timeseries Similarity Measure
- The calculation speed is fast and can be used for larger datasets;
- It can find classes of any shape in the dataset;
- The clustering effect is better when the density gap between various types is small.
2.2.2. Improved DBSCAN Algorithm for Adaptive Generation of Clustering Parameters
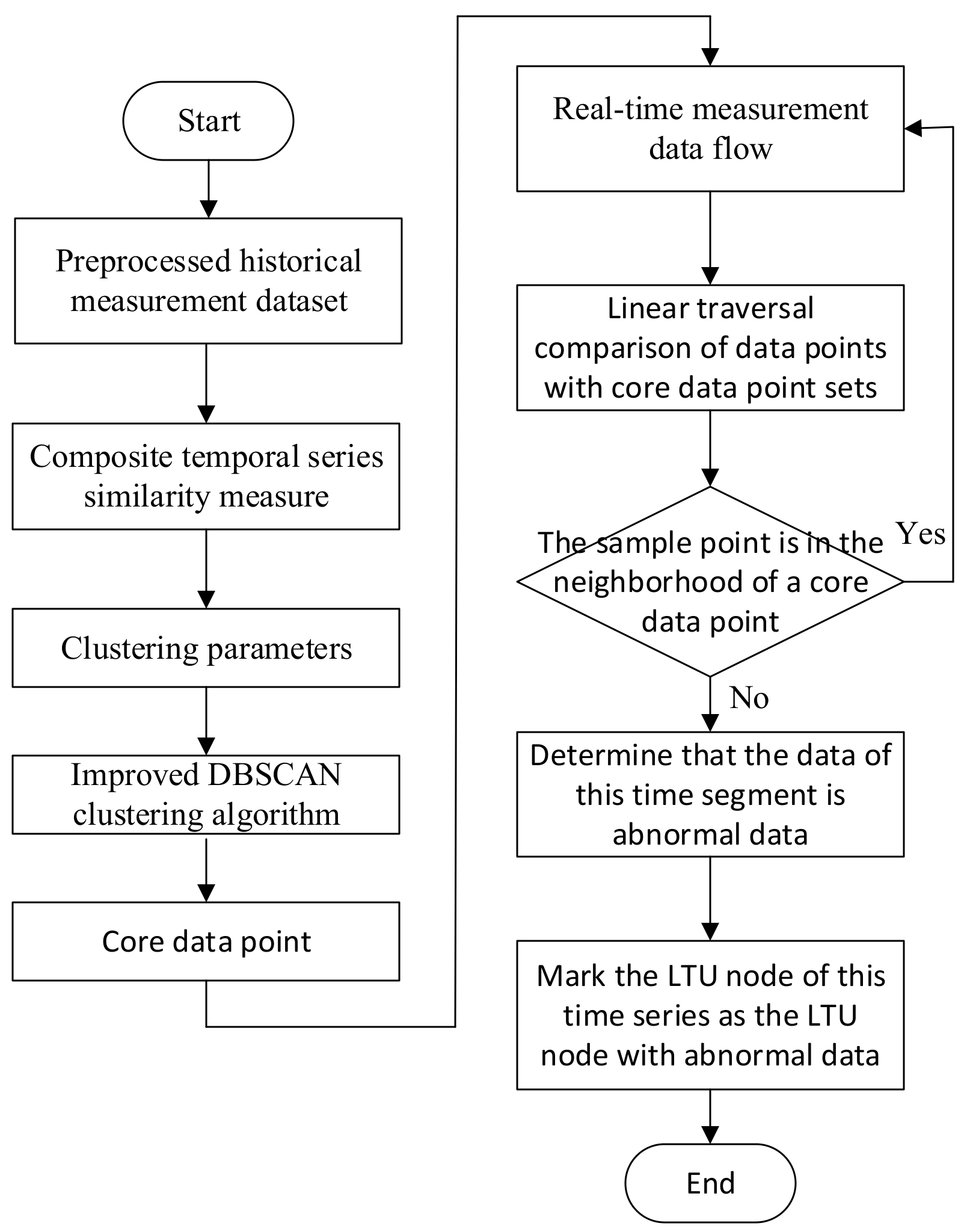
2.2.3. Anomaly Identification Method Design
3. Anomaly Source Detection Based on Fuzzy Logic System
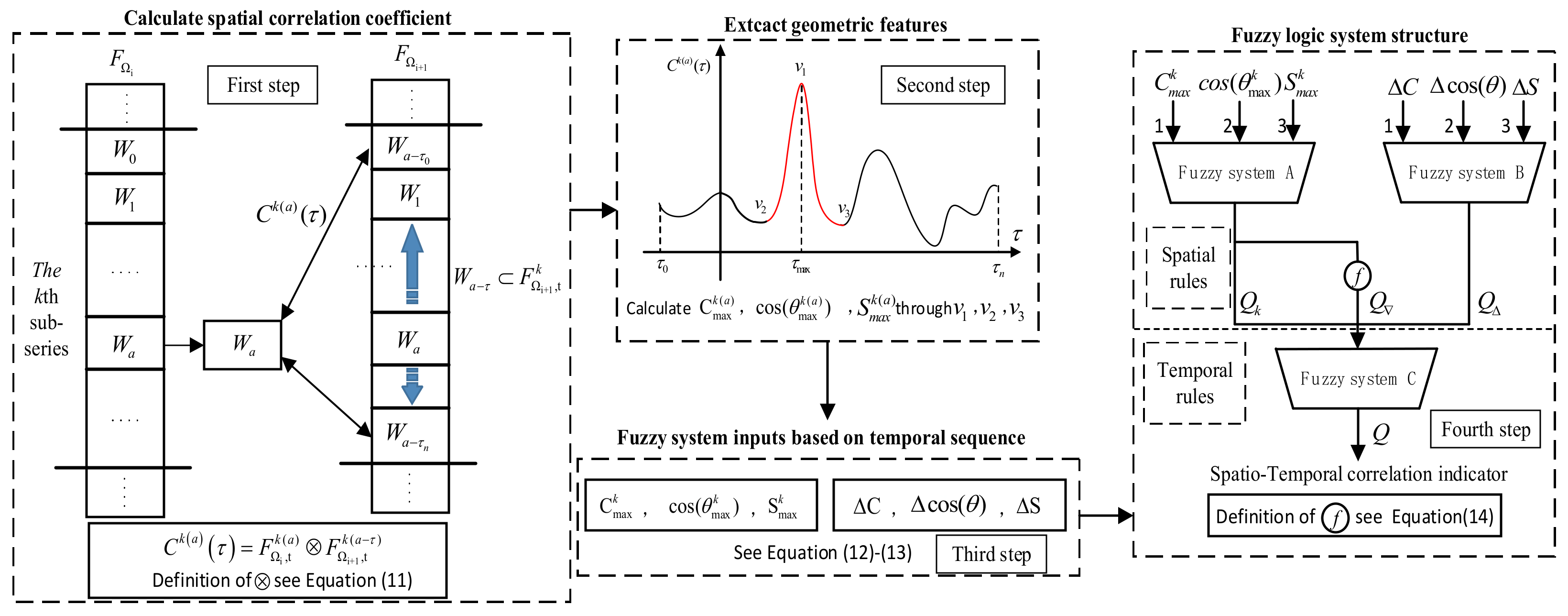
3.1. Extract System Inputs from Correlations
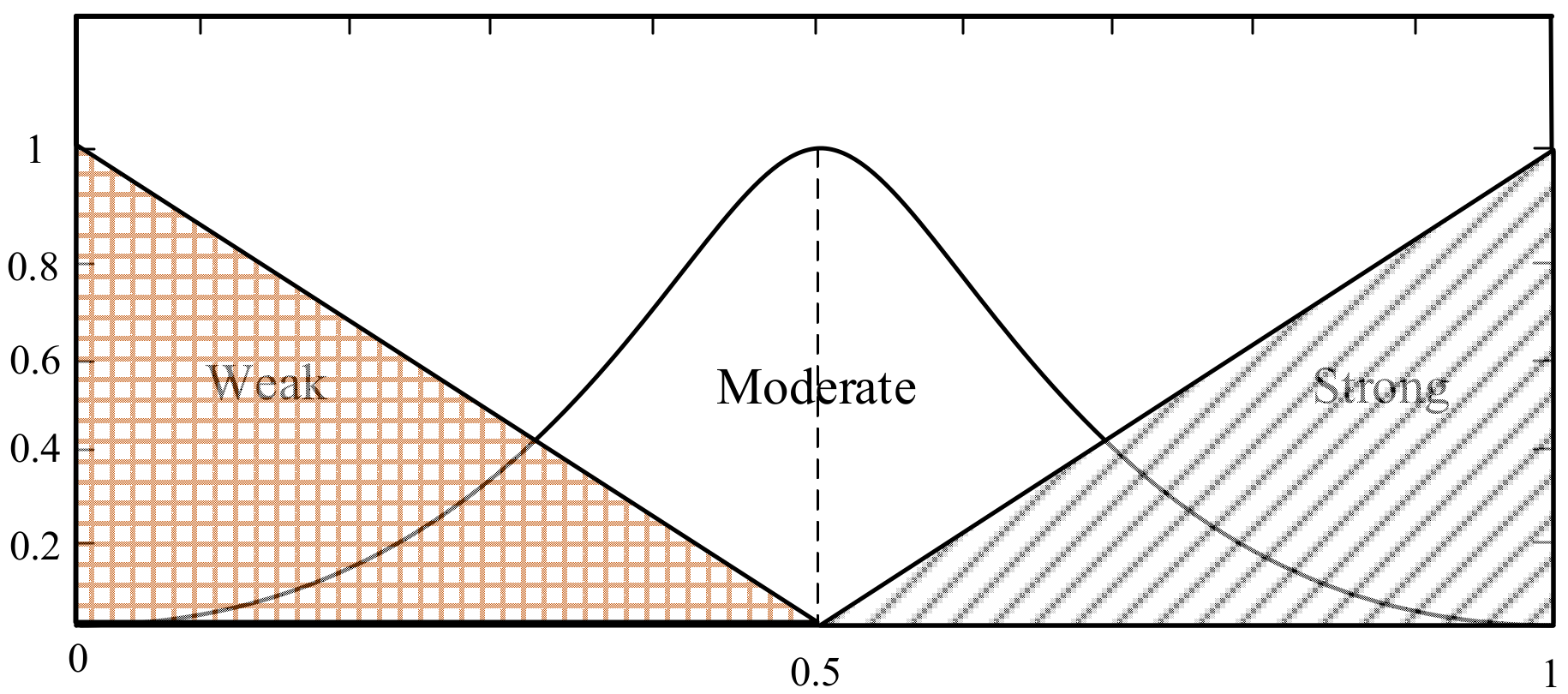
3.2. Design Fuzzy Logic System Structure
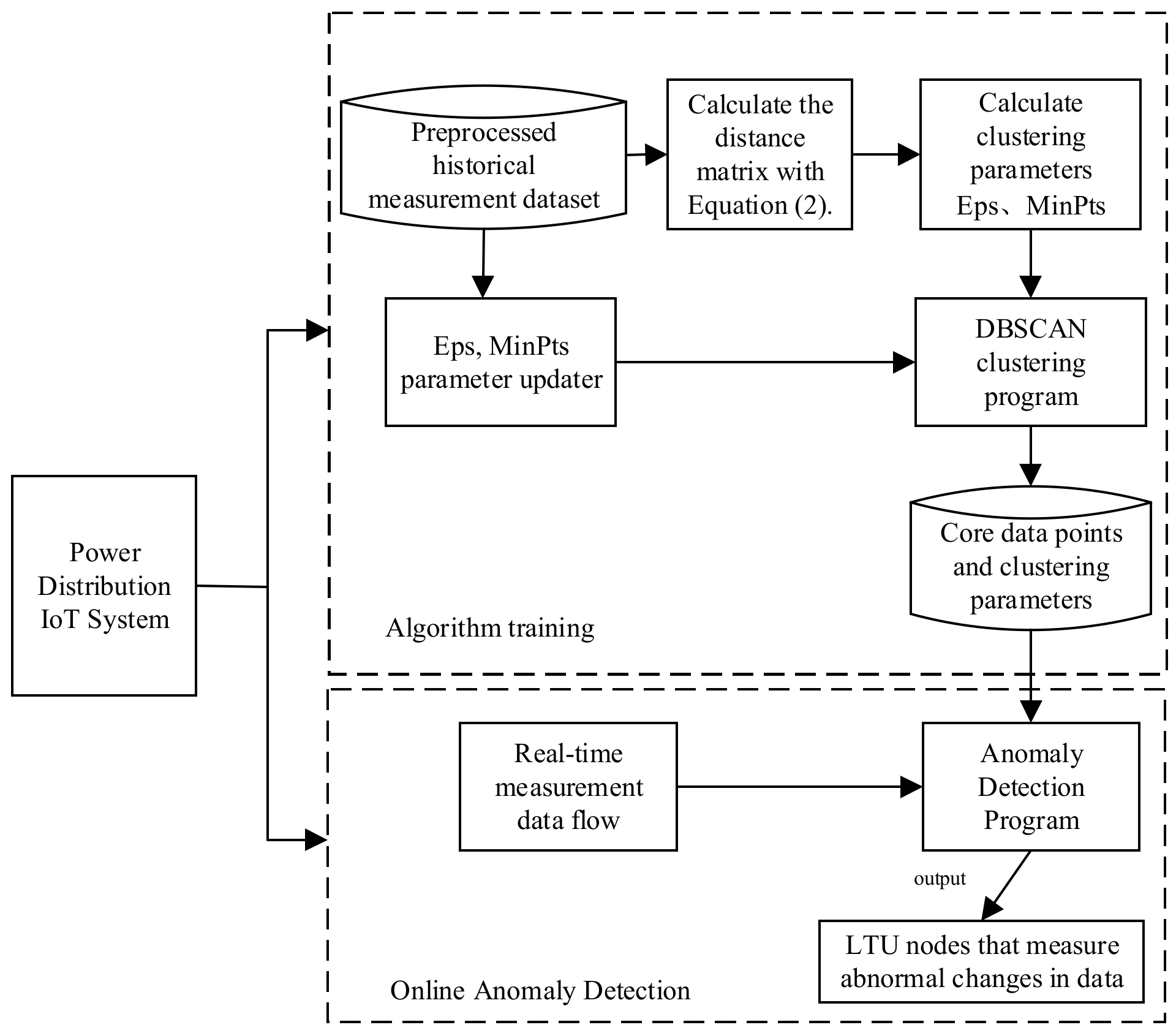
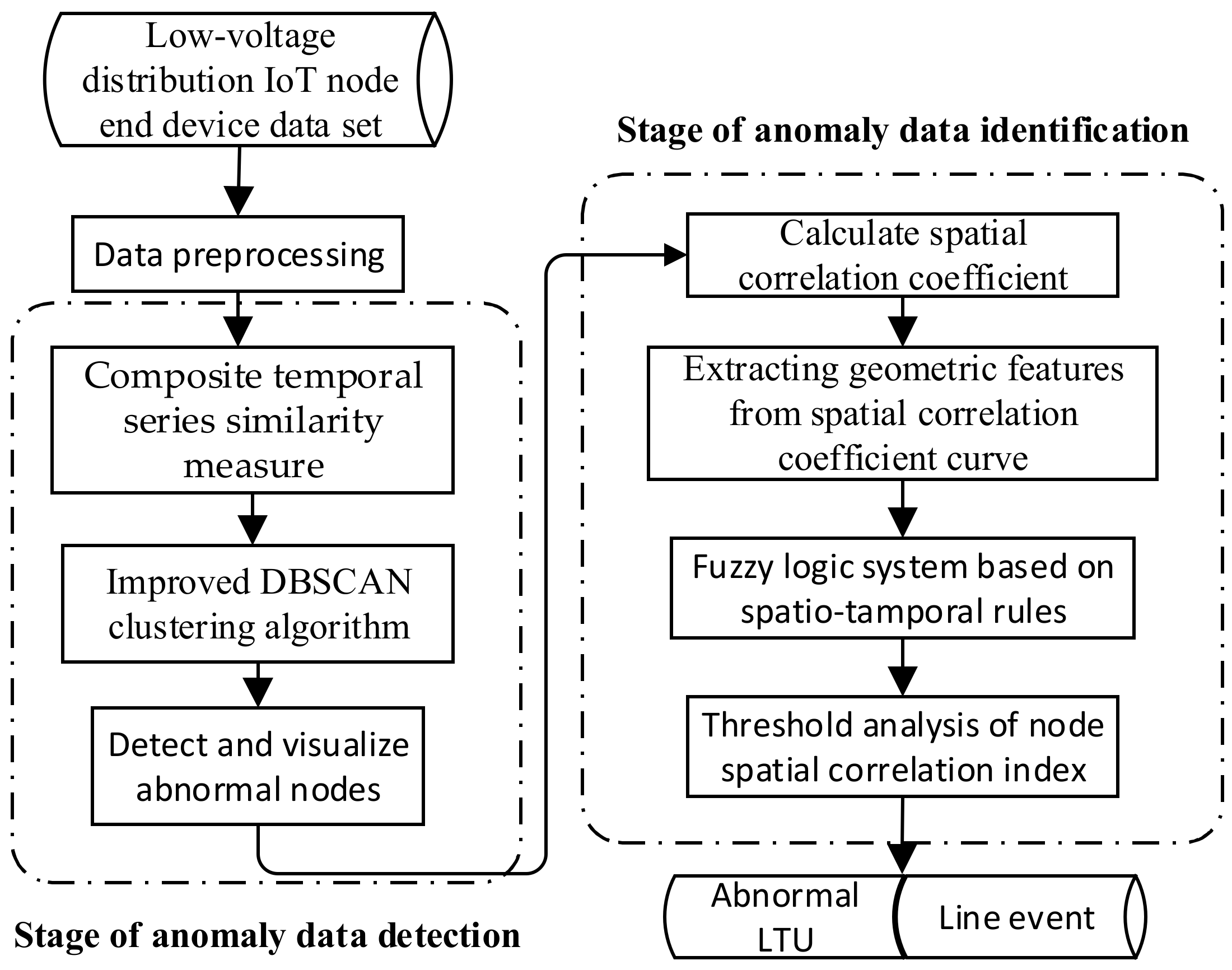
4. Overall Structure of the Algorithm
- (I)
- For the measured data of a single LTU, the distance matrix was calculated according to the composite temporal series similarity measured in Section 2.2.1. Then, the above distance matrix was used as the input for clustering the data of LTU nodes, and the noise points detected in the clustering results were the data with abnormal changes.
- (II)
- For the LTU with abnormal data changes detected, the LTU with the closest physical distance was searched, and the spatial correlation curves between the two LTUs were calculated through the sliding time window, from which the geometric features of the spatial correlation numbers were extracted.
- (III)
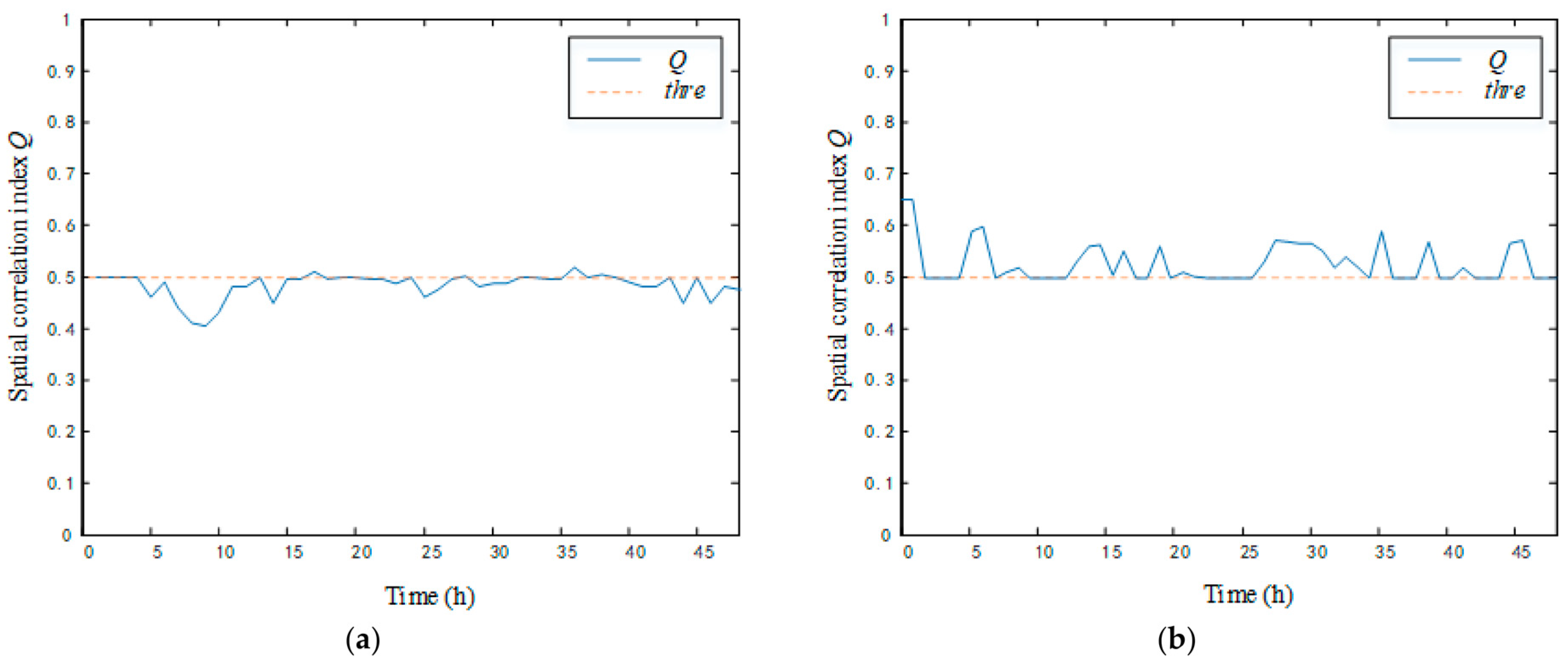
- The geometric features of spatial correlation numbers were input into the fuzzy logic system to obtain the spatial correlation index Q of LTU nodes, and the relationship between Q and the threshold thre was judged.
- (1IV)
- According to the data of abnormal changes in (III), the source of abnormal changes was analyzed according to the following logic:
- ①
- If the time length of the spatial correlation index Q lower than the threshold thre was continuously greater than or equal to two sliding windows, then it was determined that the abnormal data came from the LTU failure.
- ②
- If Q was continuously lower than the threshold thre for less than two sliding windows, the LTU was judged to work normally, and it was determined that the abnormal change data came from the line event within the LTU monitoring range.
5. Experimental Results
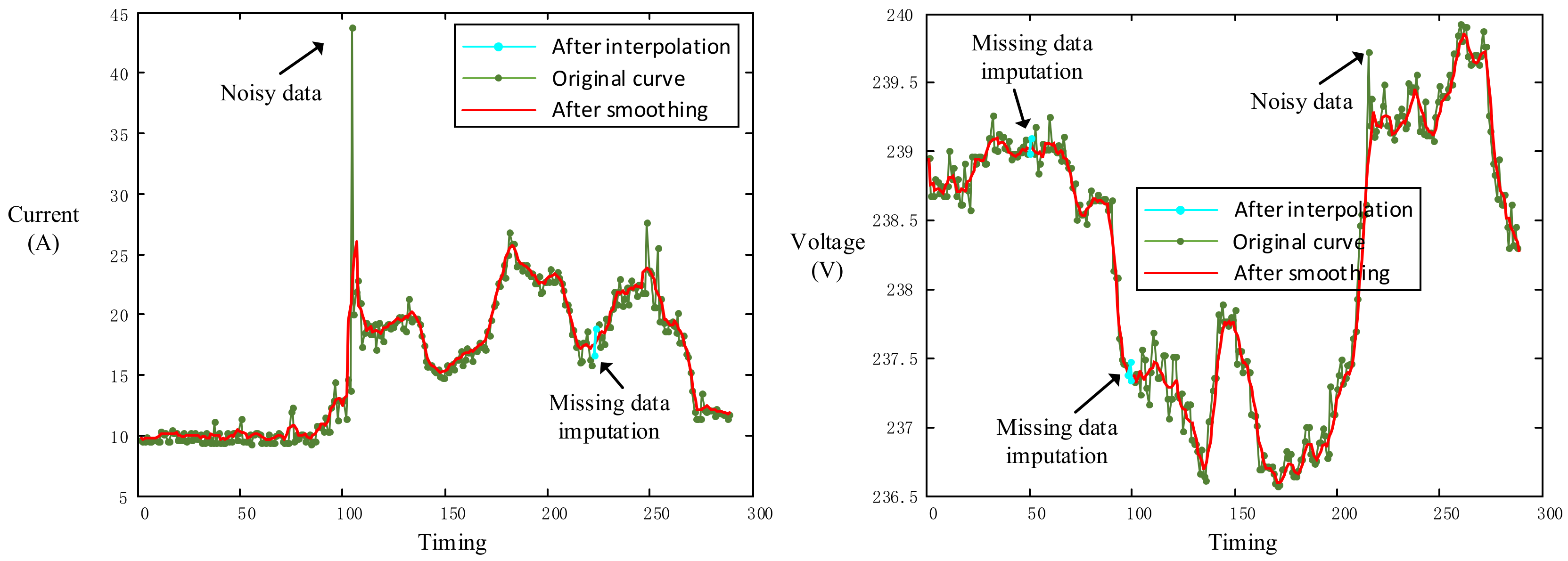
5.1. Data Preprocessing
5.2. Experimental Settings
5.3. Evaluation Standard
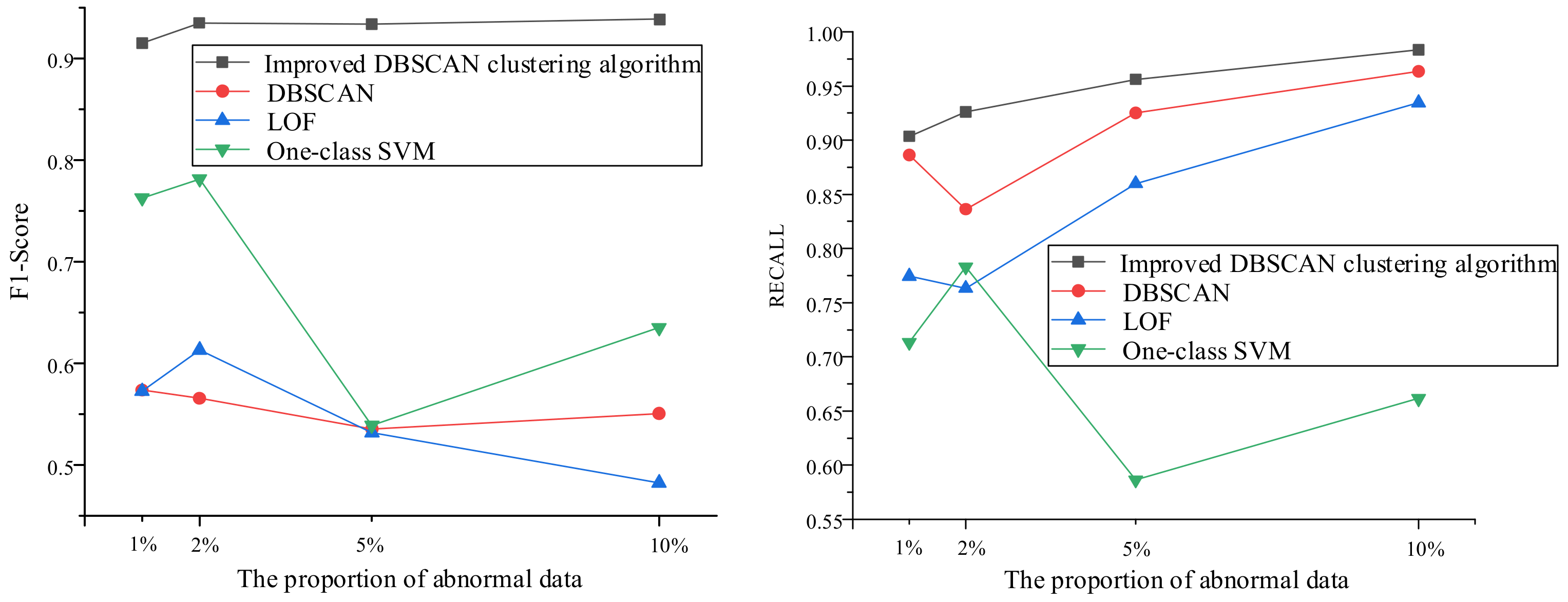
5.4. Results
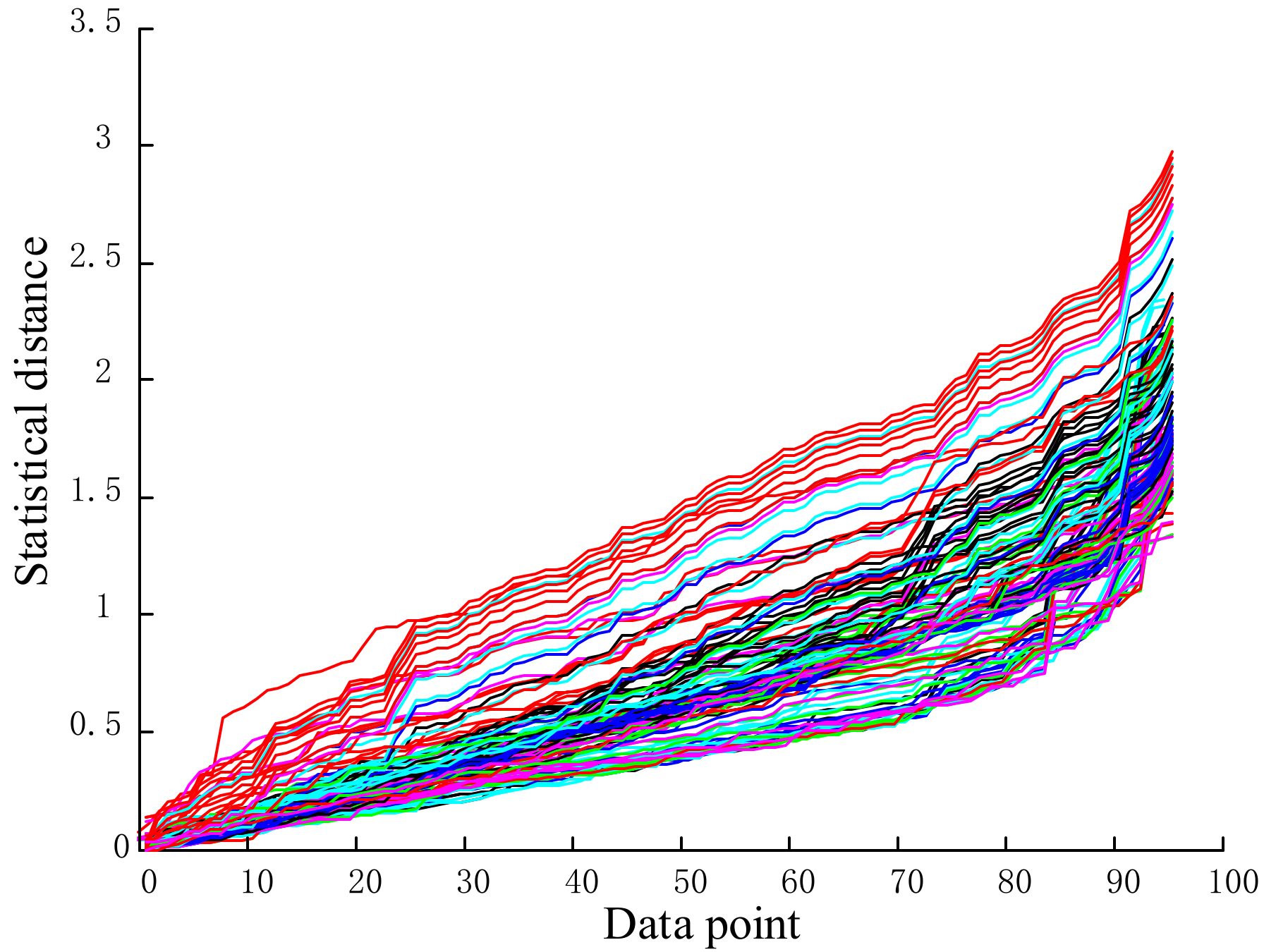
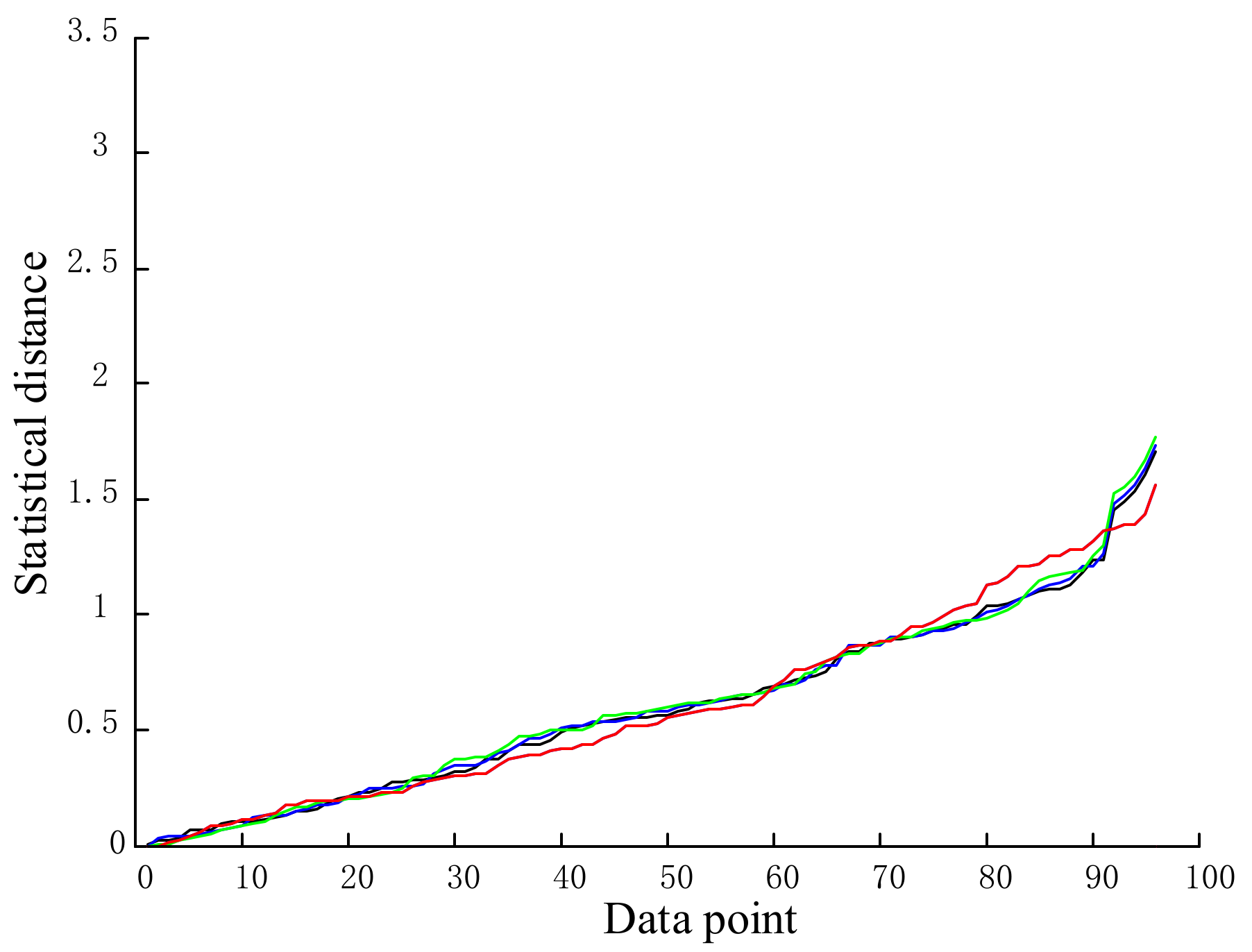
5.4.1. Anomaly Data Detection
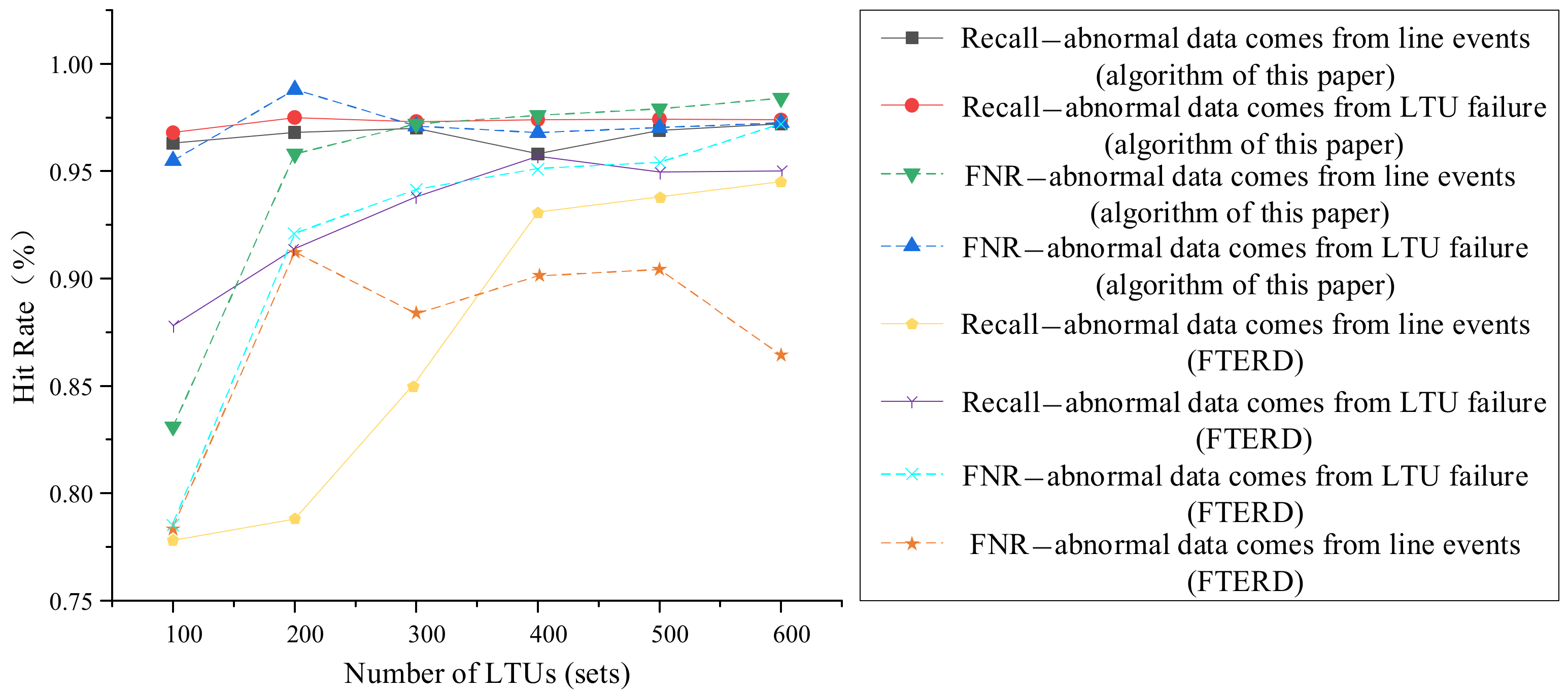
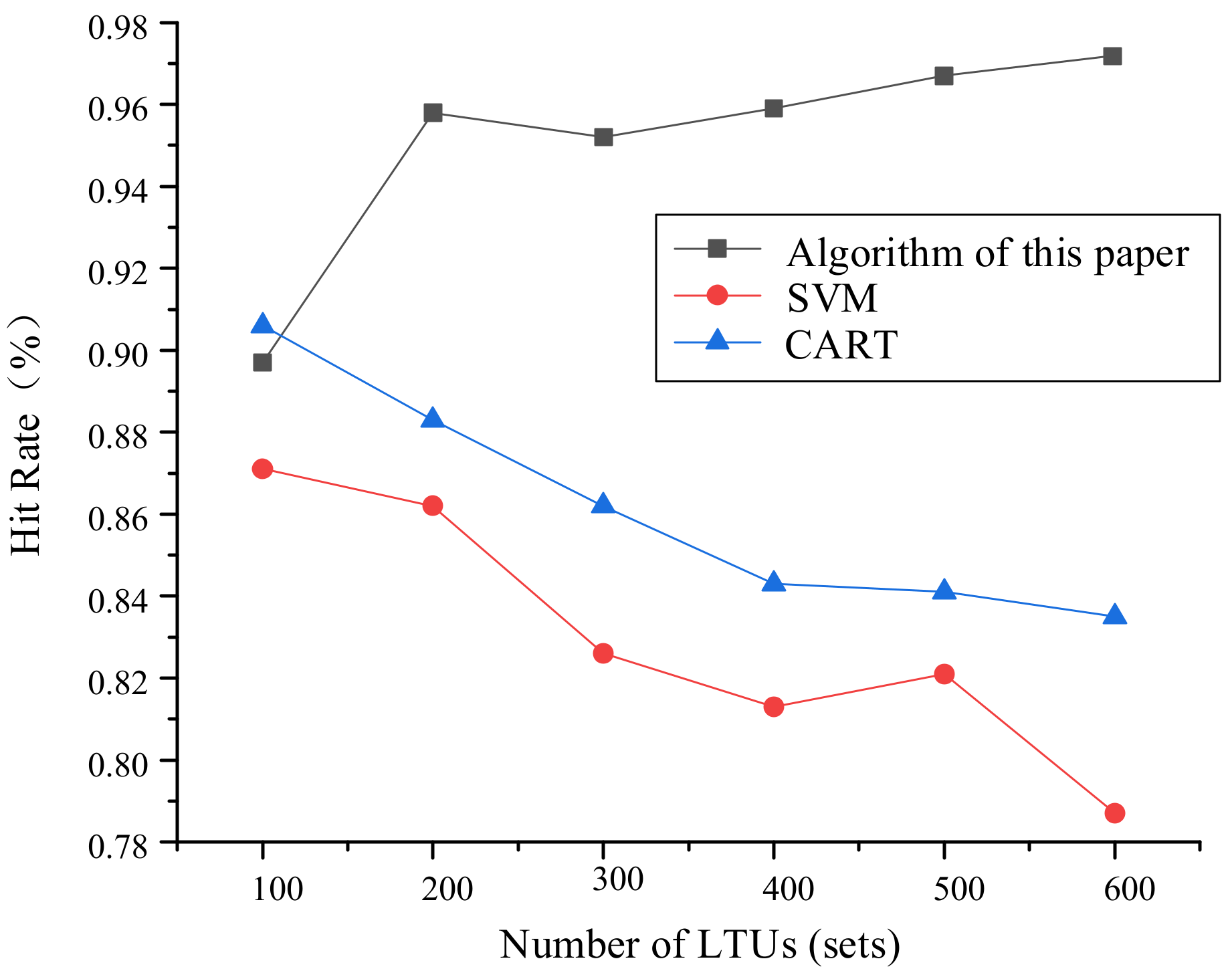
5.4.2. Source Identification of Anomaly Data
6. Conclusions
- (1)
- The algorithm proposed using the composite rule of the temporal sequence distance measurement from the probability distribution, amplitude, and error model enabled comprehensive measures in three aspects: the LTU sampling data of the timeseries similarity, the improvement of the traditional Euclidean distance similarity measure for high-dimensional data, and the improvement of the DBSCAN clustering analysis as a function of the accuracy of the information input.
- (2)
- Using the spatial correlation of data between adjacent LTUs in the low-voltage distribution network, the geometric characteristics of spatial correlation between abnormal data changed nodes and their adjacent nodes were extracted as the input of the fuzzy system, which successfully dealt with the complexity and relationship fuzziness of the LTU abnormal state.
- (3)
- The improved DBSCAN clustering algorithm based on adaptive parameter determination overcame the problem of sensitivity to the selection of global density parameters, as well as improved the flexibility and adaptability of the detection model.
- (4)
- Compared with traditional equipment self-inspection and equipment working state monitoring, the method in this paper could not only simplify the complex correlation of multidimensional parameters, but also identify small step anomalies, thereby enabling accurate detection.
- (5)
- It can be seen from the comparative simulation results that the precision and recall of the detection of abnormal data caused by LTU failures remained above 95%, while the overall accuracy remained above 90% under different LTU scales.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Liu, Q.; Zhu, Y.; Liu, G. Integrating the Power Distribution Terminals into the Power Distribution Internet of Things. In Proceedings of the 2021 Power System and Green Energy Conference (PSGEC), Online, 21–22 August 2021; pp. 62–67. [Google Scholar]
- Lu, L.; Liu, J.; Ju, D.; Zhu, K.; Jia, Y.; Zou, D.; Chen, Y.; Qin, J.; Dai, J.; Xiang, C.; et al. Research on Security Protection Measures of the Perception Layer of Power Distribution Internet of Things. In Proceedings of the 2020 12th International Conference on Intelligent Human-Machine Systems and Cybernetics (IHMSC), Online, 22–23 August 2020; Volume 1, pp. 142–145. [Google Scholar]
- Ma, X.; Shao, S.; Zhang, W. Research on Key Technologies of Power Distribution Internet of Things. In Proceedings of the 2020 12th IEEE PES Asia-Pacific Power and Energy Engineering Conference (APPEEC), Xiamen, China, 14–16 August 2020; pp. 1–4. [Google Scholar]
- Fan, H.; Weng, L.; Yu, B.; Feng, X.; Chen, J.; Shou, T.; Qi, W.; Wang, D. Fault Interval Judgment of Urban Distribution Grid Based on Edge Computing of Distribution Internet of Things. In Proceedings of the 2021 Power System and Green Energy Conference (PSGEC), Shanghai, China, 20–22 August 2021; pp. 18–24. [Google Scholar]
- Yunshuo, L.; Jian, D.; Jun, L.; Min, F.; Qing, Y. Research on distribution power quality monitoring based on distribution internet of things. In Proceedings of the 2019 14th IEEE International Conference on Electronic Measurement & Instruments (ICEMI), Nanjing, China, 1–3 November 2019; pp. 1849–1854. [Google Scholar]
- Samparthi, V.K.; Verma, H.K. Outlier Detection of Data in Wireless Sensor Networks Using Kernel Density Estimation. Int. J. Comput. Appl. 2010, 5, 28–32. [Google Scholar] [CrossRef]
- Sharma, K.P.; Sharma, T.P. rDFD: Reactive Distributed Fault Detection in Wireless Sensor Networks. Wirel. Netw. 2017, 23, 1145–1160. [Google Scholar] [CrossRef]
- Zhang, K.; Shi, S.; Gao, H.; Li, J. Unsupervised outlier detection in sensor networks using aggregation tree. In International Conference on Advanced Data Mining and Applications; Springer: Berlin/Heidelberg, Germany, 2007; Volume 2007, pp. 158–169. [Google Scholar]
- Ghorbel, O.; Ayedi, W.; Snoussi, H.; Abid, M. Fast and Efficient Outlier Detection Method in Wireless Sensor Networks. IEEE Sens. J. 2015, 15, 3403–3411. [Google Scholar] [CrossRef]
- Karimian, S.H.; Kelarestaghi, M.; Hashemi, S. I-inclof: Improved Incremental Local Outlier Detection for Data Streams. In Proceedings of the 16th CSI International Symposium on Artificial Intelligence and Signal Processing (AISP 2012), Shiraz, Iran, 2–3 May 2012; pp. 023–028. [Google Scholar]
- Xu, S.; Liu, H.; Duan, L.; Wu, W. An Improved LOF Outlier Detection Algorithm. In Proceedings of the 2021 IEEE International Conference on Artificial Intelligence and Computer Applications (ICAICA), Dalian, China, 28–30 June 2021; pp. 113–117. [Google Scholar]
- Rassam, M.A.; Maarof, M.A.; Zainal, A. A Distributed Anomaly Detection Model for Wireless Sensor Networks Based on the One-class Principal Component Classifier. IJSNet 2018, 27, 200–214. [Google Scholar] [CrossRef]
- Su, J.; Long, Y.; Qiu, X.; Li, S.; Liu, D. Anomaly Detection of Single Sensors Using OCSVM_KNN. In International Conference on Big Data Computing and Communications; Springer: Cham, Switzerland, 2015; pp. 217–230. [Google Scholar]
- Prodanoff, Z.G.; Penkunas, A.; Kreidl, P. Anomaly Detection in RFID Networks Using Bayesian Blocks and DBSCAN. In 2020 SoutheastCon; IEEE: Piscataway, NJ, USA, 2020; pp. 1–7. [Google Scholar]
- De Vita, F.; Bruneo, D.; Das, S.K. A Semi-Supervised Bayesian Anomaly Detection Technique for Diagnosing Faults in Industrial IoT Systems. In Proceedings of the 2021 IEEE International Conference on Smart Computing (SMARTCOMP), Irvine, CA, USA, 23–27 August 2021; pp. 31–38. [Google Scholar]
- Ullah, I.; Mahmoud, Q.H. An Anomaly Detection Model for IoT Networks based on Flow and Flag Features using a Feed-Forward Neural Network. In Proceedings of the 2022 IEEE 19th Annual Consumer Communications & Networking Conference (CCNC), Las Vegas, NV, USA, 8–11 January 2022; pp. 363–368. [Google Scholar]
- Aslam, S.; Herodotou, H.; Mohsin, S.M.; Javaid, N.; Ashraf, N.; Aslam, S. A Survey on Deep Learning Methods for Power Load and Renewable Energy Forecasting in Smart Microgrids. Renew. Sustain. Energy Rev. 2021, 144, 110992. [Google Scholar] [CrossRef]
- Kiss, I.; Genge, B.; Haller, P.; Sebestyen, G. Data Clustering-based Anomaly Detection in Industrial Control Systems. In Proceedings of the 2014 IEEE 10th International Conference on Intelligent Computer Communication and Processing (ICCP), Cluj, Romania, 4–6 September 2014; pp. 275–281. [Google Scholar]
- Wu, W.; Cheng, X.; Ding, M.; Xing, K.; Liu, F.; Deng, P. Localized Outlying and Boundary Data Detection in Sensor Networks. IEEE Trans. Knowl. Data Eng. 2007, 19, 1145–1157. [Google Scholar] [CrossRef]
- Arena, E.; Corsini, A.; Ferulano, R.; Iuvara, D.; Miele, E.; Celsi, L.R.; Sulieman, N.; Villari, M. Anomaly Detection in Photovoltaic Production Factories via Monte Carlo Pre-Processed Principal Component Analysis. Energies 2021, 14, 3951. [Google Scholar] [CrossRef]
- Li, X.; Zhang, P.; Zhu, G. DBSCAN Clustering Algorithms for Non-Uniform Density Data and Its Application in Urban Rail Passenger Aggregation Distribution. Energies 2019, 12, 3722. [Google Scholar] [CrossRef] [Green Version]
- Breunig, M.M.; Kriegel, H.P.; Ng, R.T.; Sander, J. LOF: Identifying Density-based Local Outliers. In Proceedings of the 2000 ACM SIGMOD International Conference on Management of Data, Dallas, TX, USA, 16–18 May 2000; pp. 93–104. [Google Scholar]
- Schölkopf, B.; Williamson, R.C.; Smola, A.; Shawe-Taylor, J.; Platt, J. Support Vector Method for Novelty Detection. Adv. Neural Inf. Processing Syst. 1999, 12, 582–588. [Google Scholar]
- Peng, N.; Zhang, W.; Zhang, Y.; Huang, Z.; Zheng, L. Anomaly Detection Method for Wireless Sensor Network Based on Time Series Data. J. Sens. Technol. 2018, 31, 595–601. [Google Scholar]
- Suthaharan, S.; Alzahrani, M.; Rajasegarar, S.; Leckie, C.; Palaniswami, M. Labelled Data Collection for Aomaly Detection in Wireless Sensor Networks. In Proceedings of the 2010 Sixth International Conference on Intelligent Sensors, Sensor Networks and Information Processing, Brisbane, Australia, 7–10 December 2010; pp. 269–274. [Google Scholar]
- Nesa, N.; Ghosh, T.; Banerjee, I. Outlier Detection in Sensed Data Using Statistical Learning Models for IoT. In Proceedings of the 2018 IEEE Wireless Communications and Networking Conference (WCNC), Barcelona, Spain, 15–18 April 2018; pp. 1–6. [Google Scholar]
- Florkowski, M. Anomaly Detection, Trend Evolution, and Feature Extraction in Partial Discharge Patterns. Energies 2021, 14, 3886. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Serial Number | Input 1 | Input 2 | Input 3 | Output |
|---|---|---|---|---|
| 1 | Strong | Weak | Strong | Strong |
| 2 | Strong | Moderate | Weak | Strong |
| 3 | Strong | Weak | Moderate | Strong |
| 4 | Moderate | Weak | Weak | Weak |
| 5 | Strong | Weak | Weak | Weak |
| 6 | Moderate | Strong | Strong | Strong |
| 7 | Weak | Strong | Strong | Strong |
| 8 | Strong | Strong | Strong | Strong |
| 9 | Moderate | Moderate | Moderate | Moderate |
| 10 | Weak | Weak | Weak | Weak |
| Serial Number | Input 1 | Input 2 | Input 3 | Output |
|---|---|---|---|---|
| 1 | Weak | Weak | Weak | Weak |
| 2 | Weak | Moderate | Weak | Weak |
| 3 | Weak | Strong | Weak | Weak |
| 4 | Moderate | Weak | Weak | Moderate |
| 5 | Moderate | Moderate | Weak | Moderate |
| 6 | Moderate | Strong | Weak | Weak |
| 7 | Moderate | Weak | Moderate | Moderate |
| 8 | Moderate | Strong | Moderate | Weak |
| 9 | Moderate | Moderate | Moderate | Moderate |
| 10 | Moderate | Weak | Strong | Moderate |
| 11 | Moderate | Moderate | Strong | Weak |
| 12 | Moderate | Strong | Strong | Weak |
| 13 | Strong | Weak | Weak | Strong |
| 14 | Strong | Moderate | Weak | Strong |
| 15 | Strong | Strong | Weak | Moderate |
| 16 | Strong | Weak | Moderate | Strong |
| 17 | Strong | Moderate | Moderate | Strong |
| 18 | Strong | Strong | Moderate | Moderate |
| 19 | Strong | Weak | Strong | Moderate |
| 20 | Strong | Moderate | Strong | Moderate |
| 21 | Strong | Strong | Strong | Weak |
| Detect Result | Positive | Negative | |
|---|---|---|---|
| Deal Result | |||
| Positive | True positive (TP) | False negative (FN) | |
| Negative | False positive (FP) | True negative (TN) | |
| The Proportion of Abnormal Data | 1% | 2% | 5% | 10% | ||||
|---|---|---|---|---|---|---|---|---|
| Algorithm | F1 | Recall | F1 | Recall | F1 | Recall | F1 | Recall |
| Improved DBSCAN clustering algorithm | 0.9152 | 0.9035 | 0.9352 | 0.9260 | 0.9340 | 0.9560 | 0.9388 | 0.9833 |
| DBSCAN | 0.5737 | 0.8861 | 0.5656 | 0.8362 | 0.5354 | 0.9251 | 0.5506 | 0.9635 |
| LOF | 0.5726 | 0.7745 | 0.6133 | 0.7632 | 0.5319 | 0.8599 | 0.4824 | 0.9345 |
| One-class SVM | 0.7630 | 0.7131 | 0.7816 | 0.7829 | 0.5392 | 0.5863 | 0.6352 | 0.6616 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shao, N.; Chen, Y. Abnormal Data Detection and Identification Method of Distribution Internet of Things Monitoring Terminal Based on Spatiotemporal Correlation. Energies 2022, 15, 2151. https://doi.org/10.3390/en15062151
Shao N, Chen Y. Abnormal Data Detection and Identification Method of Distribution Internet of Things Monitoring Terminal Based on Spatiotemporal Correlation. Energies. 2022; 15(6):2151. https://doi.org/10.3390/en15062151
Chicago/Turabian StyleShao, Nan, and Yu Chen. 2022. "Abnormal Data Detection and Identification Method of Distribution Internet of Things Monitoring Terminal Based on Spatiotemporal Correlation" Energies 15, no. 6: 2151. https://doi.org/10.3390/en15062151