1. Introduction
Energy consumption analysis and forecasting in buildings are prerequisites for building energy efficiency improvement. In the design planning stage, the design of building energy use systems can be improved. In the operation stage, reasonable energy consumption forecasting can help operators identify energy-saving potential and implement scientific management policies. Usually, the model for building energy consumption prediction is composed of three components [
1]: input data (e.g., architectural design parameters such as orientation [
2], shape [
3], the window-to-wall ratio [
4], shading [
5], and weather variables), system structure (e.g., thermal properties of the exterior walls [
6,
7], parameters of the cooling or heating system [
8,
9]), and output data (i.e., energy use).
Currently, there are numerous methods for predicting building energy consumption, which can be grouped into 2 categories depending on the analysis method [
10]: simulation techniques based on physics principles and data-driven approaches utilizing artificial intelligence algorithms.
Simulation techniques are used to predict building energy consumption by building physical models. Currently, there are several software tools for building energy consumption simulation, such as DOE-2 [
11], Energy Plus [
12], ESP-r [
13], TRNSYS [
14], Design Builder [
15] and EQUEST [
16], etc. These tools can calculate the changes in building energy consumption on a time-by-time basis and are easy and convenient to operate.
The data-driven approach applies statistical analysis approaches to build mathematical models of energy consumption systems based on known input and output data. Data-driven models used in the field of energy prediction involve Multiple Linear Regression (MLR) [
17], Time Series Model (TSM) [
18] and machine learning-based methods, e.g., Back Propagation (BP) neural network [
19] and Random Forest (RF) [
20].
The Joinpoint−Multiple Linear Regression (JP–MLR) model proposed in this study is a regression model based on a data-driven approach. Each algorithm has its advantages and disadvantages, and choosing the right method for a specific case is the key to ensuring the success of building energy operation management. However, different models in the data-driven method have different prediction accuracy. Sretenović [
21] used different inverse modelling methods, including MLR, SVM and neural network models, to compare the prediction of cooling electricity consumption in a commercial building in Belgrade. The results show that the MLR model has the lowest accuracy than the neural network and SVM.
The following authors have also used regression models for energy forecasting. Fumo et al. [
22] analyzed the energy consumption of residential buildings using MLR and quadratic regression. Two explanatory variables were used in the model: solar radiation and outdoor temperature. However, they found that the root mean square error values deteriorate with the inclusion of the solar radiation variable in the model. The prediction accuracy of the model for daily data R
2 = 74%. Amiri et al. [
23] demonstrated the advantages and potential of the MLR regression model for building energy prediction through 150,000 computer simulations. The model contains 13 screened building parameters, of which occupancy schedule and exterior wall construction are the two most dominant parameters. The R
2 values of the models given in the study vary between 95% and 98%, but there are no other parameters for model evaluation that can be discussed. Marwen et al. [
24] used an MLR regression model to predict the future electricity consumption in Florida. The results show that month, cooling and heating degree days and GDP are the important variables in the regression model. Venkataramana et al. [
25] found that the MLR method can predict the electricity demand of a substation located in Warangal with good accuracy. YANG et al. [
26] found a strong relationship between outdoor temperature and building energy usage utilizing a regression method and established a cubic equation with R
2 = 70.27%. Capozzoli et al. [
27] analyzed the annual heating energy consumption of 80 schools and developed an MLR model with 9 variables to estimate the energy consumption of these schools. The final model showed R
2 = 85% and MAPE = 15%. Aranda [
28] developed three different MLR models using building characteristics and climatic areas to assess the energy performance of bank buildings in Spain. The R
2 values for the three models were 56.8%, 65.2% and 68.5%, respectively.
Based on the above discussion, we found four deficiencies in the existing regression prediction model studies.
First, previous regression analysis studies have been based on MLR analysis, and the Joinpoint Regression (JPR) method has not been addressed. The JPR model is a special regression model [
29] that is typically employed in the field of medicine [
30].
Second, the accuracy of regression models is relatively low compared to other data-driven models. To increase the accuracy of regression models, researchers have to find more input variables. As the input variables to the regression model are critical, the number and validity of the variables can significantly influence the predictive accuracy of the model. However, the variables affecting the model cannot always be obtained effectively. Moreover, some variables are difficult to measure in practical applications. Therefore, the issue of using the current regression modelling techniques logically and producing great predicted performance is still present given the small number of critical variables.
Again, previous research has shown a significant relationship between energy use and meteorological variables, and the models they constructed used meteorological variables like air temperature, but the impact of rain or shine is often overlooked. Rainy (or sunny) weather affects people’s travel plans and indirectly affects the use of indoor appliances, thus affecting energy consumption. Therefore, in this study, the input parameters of the model are studied by considering whether it rains or not on the same day.
Finally, previous studies have included the key meteorological variable, i.e., outdoor air temperature, in the input variables of the model. However, most of them ignored the effect of balance point temperatures on energy consumption. The balance point temperature is the turning point at which the correlation between a building’s energy consumption and outdoor temperature changes. For example, rising temperatures would raise the need for interior cooling and vice versa. The electricity usage changes at different rates above or below the temperature point. Thus, when predicting building energy consumption, it is important to take into account the influence of the balance point temperature and perform the analysis in segments.
In order to overcome the problems mentioned above, this study analyzes the daily electricity consumption data of 8 apartment buildings in Xiamen, China, and proposes a building energy consumption prediction model based on Joinpoint−Multiple Linear Regression (JP–MLR). To the best of the authors’ knowledge, this work is the first to apply the JPR model to the field of electricity prediction. A total of 8 variables are screened in the pre-analysis phase of the study, and 6 parameters are finally selected as model variables.
The rest of the paper is structured as follows.
Section 2 introduces the methodology of this study.
Section 3 is a case study that demonstrates the application of the proposed method.
Section 4 presents a comparison and discussion of the model’s performance. Finally,
Section 5 gives concluding remarks.
3. Results and Analysis
Air temperature is the most important factor affecting energy consumption [
45,
46]. A good prediction can be achieved by establishing a one-dimensional equation using outdoor air temperature as the independent variable, R
2 = 0.7027 [
26]. Therefore, as shown in the review in Section Introduction, most of the MLR models developed by previous authors include air temperature among the explanatory variables. However, the simple MLR prediction model has a large error and does not consider the effect of balance point temperatures on energy consumption.
Xiamen is located in China’s hot summer and warm winter climate zone, with cooling in summer and almost no heating in winter. In addition, campus administrators procured air conditioners in the rooms without heating functions to save energy. This results in a significant correlation between electricity use and the outdoor air temperature during the hot season, and no significant correlation during the cold season. The trend of electrical consumption should be different at different temperature conditions. Therefore, a segmented regression approach should be used for the temperature parameter-driven electric consumption prediction model according to the balance point temperatures.
The JPR analysis is carried out with average energy usage as the dependent parameter and temperature as the independent parameter, the results are shown in
Figure 7. Additionally,
Table 1 shows their parameters. Model B is chosen because it fits better and has more significant parameters than Model A. It can be expressed as
where f(T) is the predicted mean daily electricity usage, T is mean daily temperature. The range of T is 6.31−31.45 °C.
From Model B, it can be observed that two balance point temperatures exist that influence the energy usage curve of the buildings, 20.5 °C and 26.0 °C, respectively. The average outdoor air temperature can be divided into three segments based on these two turning points. The Segment Ⅰ is the low-temperature segment, where the average outdoor air temperature value is lower than 20.5 °C. Segment Ⅱ is the transition segment, where the temperature is between 20.5 and 26.0 °C. Segment Ⅲ belongs to the high-temperature segment, the temperature is greater than 26.0 °C. At lower temperatures (<20.5 °C), the room does not need to be cooled and only basic energy consumption such as lighting or sockets is included, so energy consumption is independent of temperature. The energy consumption remains almost at a stable value because the users have the same daily habits. At high temperatures (>26.0 °C), the energy use is significantly correlated with temperature because the daily energy consumption is mainly cooling energy consumption. Additionally, in the transition temperature segment (20.5–26.0 °C), such as spring or fall, the temperature change significantly affects the occupants’ hot and cold sensations. It is the key stage to decide whether to turn on the air conditioner or not, so there is a clear rising curve here.
The R
2 value of model B is 94.34%, which is already much better than the simple MLR model (R
2 = 72% in [
17]), while 5.66% of the variables (ΔE
d) are still influenced by unknown or potential factors. So the perfect prediction model can be expressed as Equation (15).
Therefore, to further refine the model, ΔEd is analyzed using the MLR method, where ΔEd is the difference between Ed and f(T). Ed is the predicted daily electricity consumption. The ΔEd of three Segments are analyzed using the MLR method, respectively, and continuous-type independent variables are used with normalized data.
Firstly, the significance between the 8 explanatory variables and the dependent variable (ΔE
d) is identified in
Table 2. After preliminary tests, explanatory variables that are not significantly linearly related to the dependent variable are excluded (
p-value > 0.05). In Segment Ⅰ, global solar irradiance, average outdoor air temperature, relative humidity, and wind speed are excluded. In Segment Ⅱ, all explanatory variables are significantly correlated with the dependent variable, so no explanatory variables are excluded. In Segment Ⅲ, the sunny day index and global solar irradiance are excluded.
Then, the explanatory variables suitable for inclusion in the model are selected based on the collinearity analysis, as shown in
Table 3. Collinearity is a phenomenon in which independent variables (explanatory variables) are correlated with each other. High collinearity between any two variables indicates that only one of them can be used because they affect the dependent variable in a similar way. In Segment I of the model, 2 explanatory variables are chosen: gender (X
2) and sunny day index(X
3). In the Segment II, 3 explanatory variables are selected: holiday index (X
1), gender (X
2) and sunny day index (X
3). In the Segment III, 3 explanatory variables are selected: holiday index (X
1), gender (X
2) and relative humidity (X
6).
MLR analysis is performed using the selected explanatory variables, and the pa-rameters of the models for the 3 segments are calculated as shown in
Table 4. All three segments of the model use the gender variable and have a positive slope. This indicates that males use more electricity than females, both in winter and summer, which is in line with previous works [
34]. The sunny day index is used in both Segment I and II with a positive slope. This indicates that at relatively low temperatures, rainy days re-duce the occupants’ outside activities and thus increase indoor electricity usage. In Segments Ⅱ and Ⅲ, when the temperature is relatively high, the day type (i.e., working or not-working day) will also affect the electricity consumption of the day. The positive slope of the holiday index indicates that on non-working days, occupants do not have to go out to work or class, which leads to an increase in indoor electricity consumption. In addition, in Segment Ⅲ, i.e., at high temperatures, the relative humidity also affects the electricity consumption. A positive slope indicates that the higher the humidity, the higher the electricity consumption of the air conditioner will be.
The ΔE
d is evaluated by the MLR method. The final integrated prediction model, i.e., the JP–MLR model, can be expressed as:
when T ≤ 20.5 °C:
when 20.5 °C < T ≤ 26.0:
when T > 26.0 °C:
which implies that E
d = f (T, x
1, x
2, x
3, x
6, x
8), where T is average outdoor air temperature, x
1 is holiday index, x
2 is gender, x
3 is sunny day index, x
6 is normalized daily average relative humidity, x
8 is normalized daily temperature amplitude and E
d is the predicted daily electricity consumption,.
4. Discussion and Comparison of Data-Driven Models Performance
Using data from the training set, five different data-driven algorithm methods are employed to predict the average daily electricity consumption in Building 1# (the test set). These five methods are: the JP–MLR model, JPR model, MLR model, BP model and RF model. Among them, JP–MLR, JPR and MLR are models based on regression algorithms, and BP and RF are models based on machine learning algorithms.
The analysis process and results of the JP–MLR model are shown in
Section 3.
The JPR model derived using the training set data is f(T).
The algorithm of the MLR model is the same as when analyzing ΔE
d in
Section 3. The analysis process is divided into three steps: preliminary analysis, collinearity analysis and regression analysis. Preliminary and collinearity analyses are shown in
Table 5. The
p-value of the holiday index is greater than 0.05, so it can be excluded and thus collinearity is analyzed for the remaining seven variables. Gender (x
2) has no collinearity with any of the other variables. In contrast, the collinearity between the six climate-related variables is more severe, so only one variable could be selected, and the average outdoor air temperature (x
5) is chosen for this study.
MLR analysis is performed based on the two selected variables (x
2, x
5) and the results are shown in
Table 6. The final model is shown in Equation (5), where x
2 is the gender and x
5 is the normalized average outdoor temperature.
The BP model uses the 8 explanatory variables mentioned in this study as input variables, and the output variable is the average daily electricity consumption. The number of hidden layers, the number of neurons in the hidden layers, and the number of iterations are three hyperparameters that influence how well the BP model performs. Since there is no universal unique value for these hyper parameters, this study uses trial-and-error method for parameter tuning.
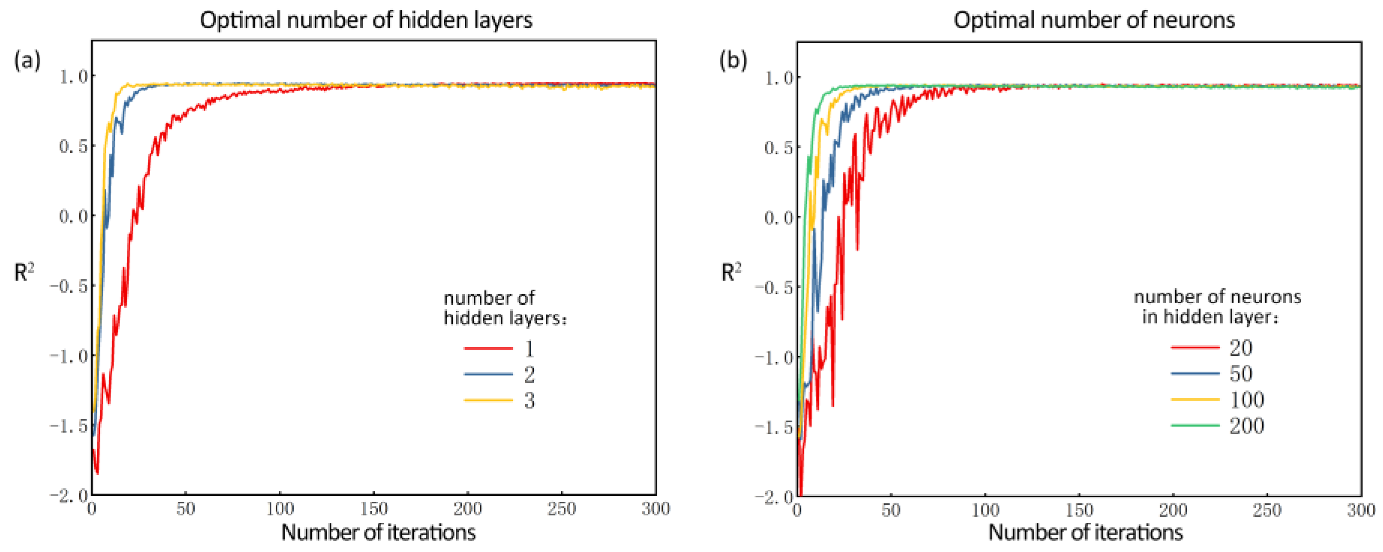
Firstly, the number of hidden layers is debugged. When the number of hidden layers is 1, 2 and 3, respectively, the R
2 value of the BP model varies with the number of iterations, as shown in
Figure 8a. The other parameters in the iterative process are set as follows: the number of neurons in the hidden layer is 100, and the number of iterations is 300. As the number of iterations increases, R
2 increases continuously and the prediction accuracy improves, and the increase in the number of hidden layers speeds up the convergence of R
2 to some extent. However, the effect of the number of hidden layers on the model accuracy tends to stabilize after a threshold (i.e., 40 for 1 hidden layer, 50 for 2 hidden layers and 150 for 3 hidden layers). To save training time at computation, 2 hidden layers with moderate convergence speed are chosen, since an increase in the number of hidden layers would cause a significant increase in training time.
Then, the number of neurons in each hidden layer is debugged. The number of neurons in the hidden layer is set to 20, 50, 100 and 200, respectively, and the effect of the number of neurons in the hidden layer on the prediction accuracy is analyzed. The other parameters in the iterative process are set as follows: the number of hidden layers is 2 and the number of iterations is 300. The change of R
2 is shown in
Figure 8b. With the increase of the neurons, the convergence speed of R
2 accelerates to different degrees. The convergence speed at the neuron number of 200 is much higher than that at 20. But again, after many iterations, the accuracy of the model (R
2) tends to be stable, and the prediction errors are the same for different numbers of neurons. Therefore, the hyper parameters of the BP model used as a comparison in this study are set as follows: the number of hidden layers is 3, the number of neurons is 200, and the number of iterations is 300.
The RF model also uses the eight explanatory variables mentioned in this study as input variables and the output variable is the average daily electricity consumption. The main parameter that affects the performance of the RF model is the number of decision trees. The same, trial-and-error method is used to find the optimal number of trees. The model prediction accuracy is calculated sequentially for the number of trees from 1 to 300, still using R
2 as the evaluation metric. As shown in
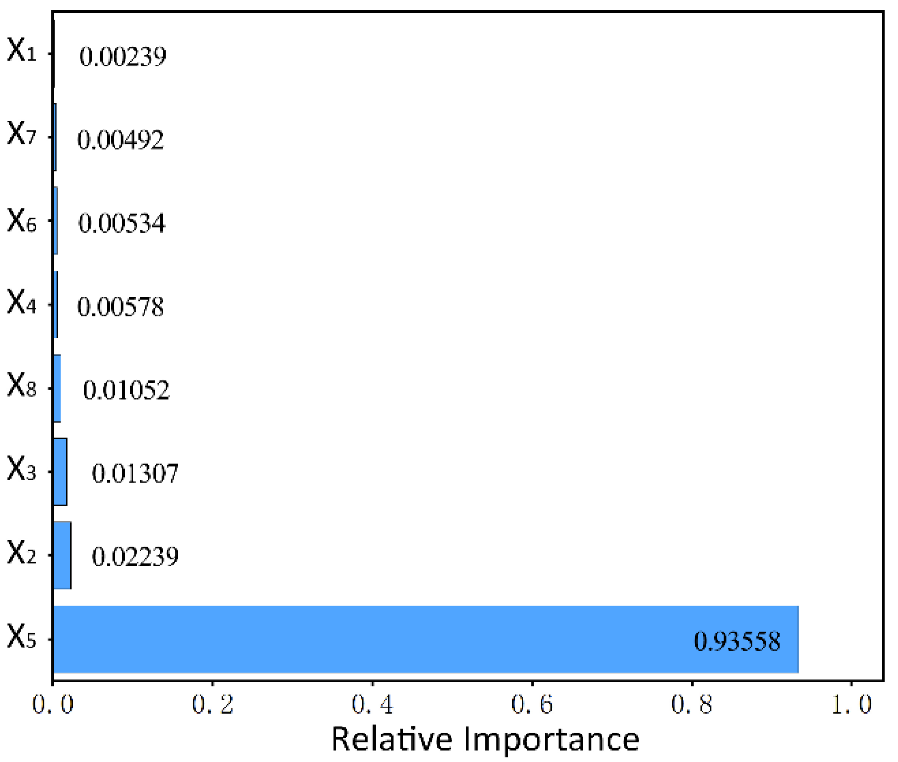
Figure 9, the model is optimal when the number is 22, so this study uses this parameter setting to build the RF model. The importance of the eight input variables is shown in
Figure 10, and the importance of temperature (x
5) is much higher than the other variables. This also indicates that temperature is the most important factor affecting building energy consumption.
The final prediction results of the five models for Building #1 (test set) are shown in
Figure 11, and their evaluation metrics are shown in
Table 7. The predictive performance of the JP–MLR model far exceeded that of the conventional regression models (JPR and MLR), where all six evaluated metrics far outperformed them. The R
2 values of the JP–MLR model were 8.11% and 24.79% higher than JPR and MLR, respectively. Compared to the machine learning models, the JP–MLR model outperforms the BP model and is basically on par with the RF model. The JP–MLR model outperformed BP in all six metrics, with CVRMSE and NMBE being 2.47% and 3.61% lower than BP, respectively. Even though the BP algorithm can be derived as neural networks for the task of regression, its prediction performance will be inferior to the JP–MLR model be-cause the influence of balance point temperature is not taken into account. CVRMSE and NMBE are the only metrics recommended by the American Society of Heating, Refrigerating and Air-Conditioning Engineers (ASHRAE) for the evaluation of energy forecasting models. Although the CVRMSE of JP–MLR is 1.13% higher than that of RF, the NMBE is 3.03% lower. Moreover, the R
2 of JP–MLR and RF are nearly the same, with only a 0.19% difference, so the prediction performance of both models is the same. The reason is that the RF algorithm can be also regarded as a special type of segmented regression, which divides the data set into segments and analyzes them segment by segment. However, the JP–MLR model is simpler and does not require complex programming knowledge for building managers, so JP–MLR is more valuable for promotion.
In addition, according to the recommendation of ASHRAE [
47], the prediction model of building monthly energy consumption should have an NMBE of 5%. However, the prediction granularity of the JP–MLR model is 24 h (one day), but its NMBE value reaches 4.05%, which is sufficient to show its excellent performance. The prediction accuracy of the same model for a day will be lower than that for a month.
Not surprisingly, the MLR model has the worst evaluation results, a result that is consistent with the findings of [
21]. The JPR model, however, outperformed the MLR model, with an R
2 16.68% higher. Because the JPR model is actually a combination of several MLR models, so it fits better than the MLR model. It is the JPR that has the advantage of segmental analysis and is therefore chosen to be used in this study to identify the balance point temperature that influence energy usage. Additionally, the R
2 of the JP–MLR model is 7.67% higher than that of the JPR model, which is because the JP–MLR model evaluates the residual (ΔE
d) on top of the JPR model and therefore improves the accuracy.
It is worth noticing that the subject of this study is in a hot summer-warm winter area, while the magnitude or number of balance point temperatures in other climatic zones may be different. However, the research method proposed can be used as a reference. Similarly, although the subject of this paper is apartment buildings, the research methodology and modelling process could be applied to other kinds of buildings, for example, residential or industrial buildings.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}