

Energy Price Prediction Integrated with Singular Spectrum Analysis and Long Short-Term Memory Network against the Background of Carbon Neutrality
Abstract
:1. Introduction
2. Research Methods and Theoretical Model Construction
2.1. Theoretical Basis
2.1.1. SSA Decomposition
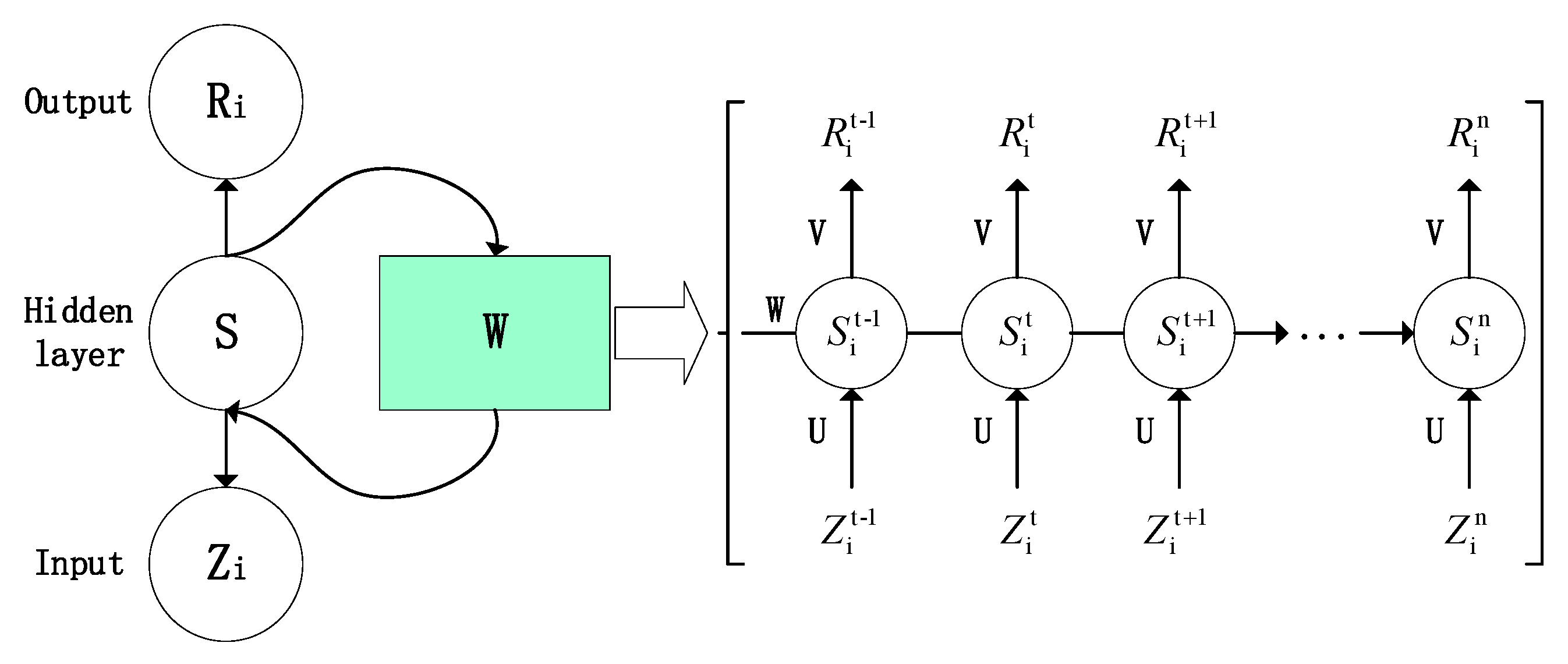
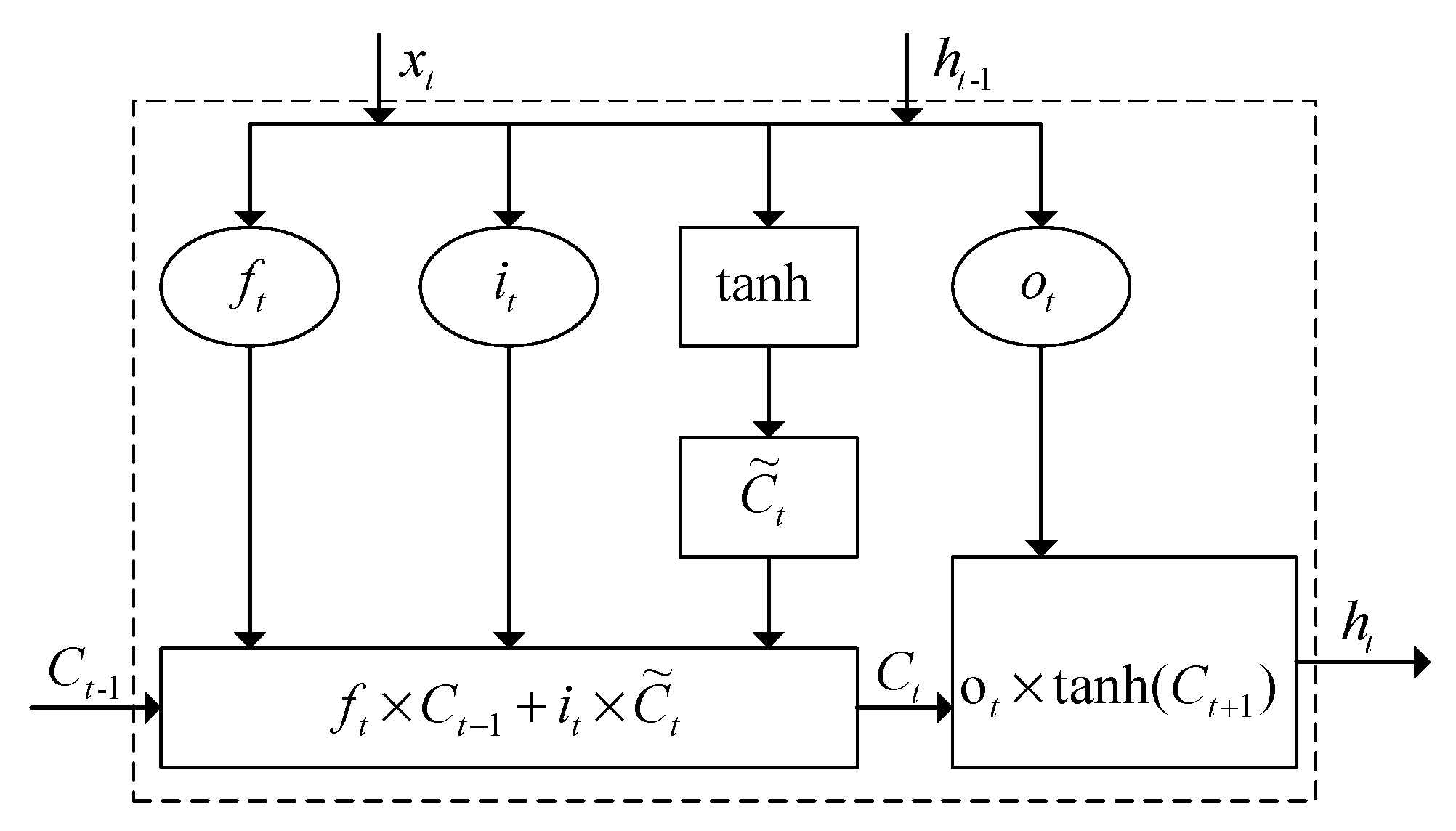
2.1.2. LSTM Neural Network
2.1.3. Calculation of Carbon Intensity
2.1.4. LVQ Cluster Technology
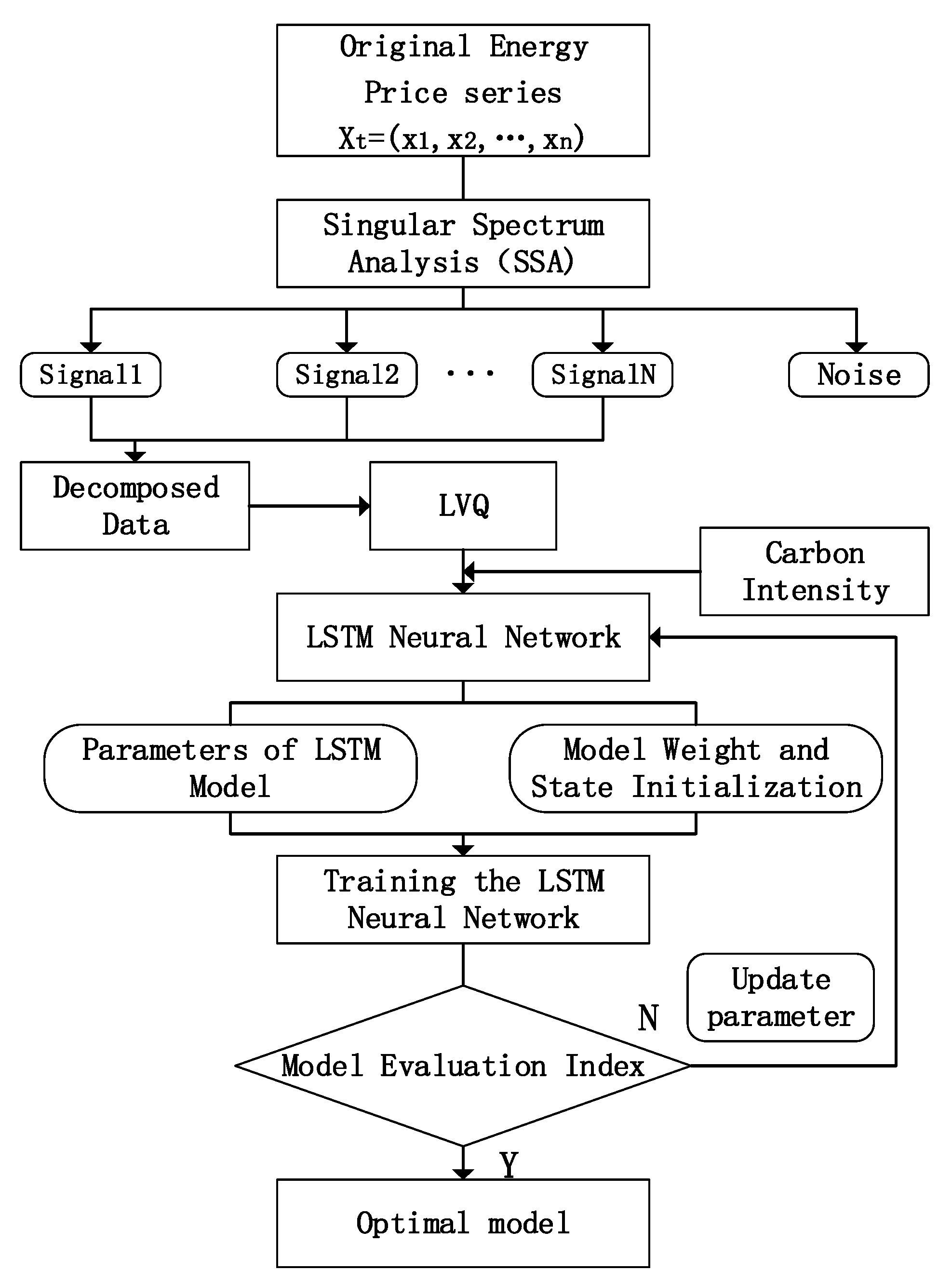
2.2. Construction of SSA-LSTM Model
2.3. Model Optimization and Comparison
3. Empirical Analysis
3.1. Selection of Data Samples and Related Parameters
3.2. Empirical Results
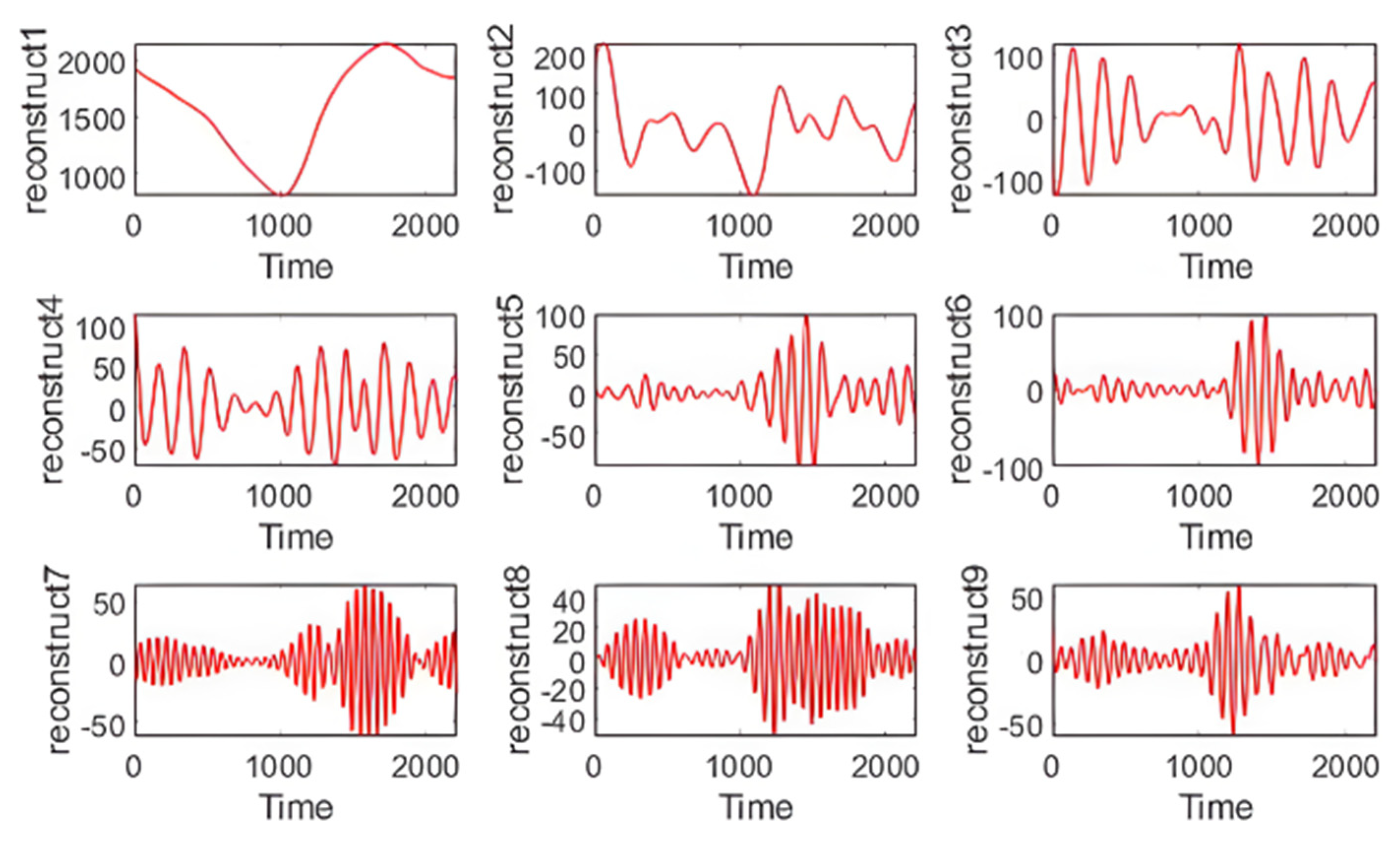
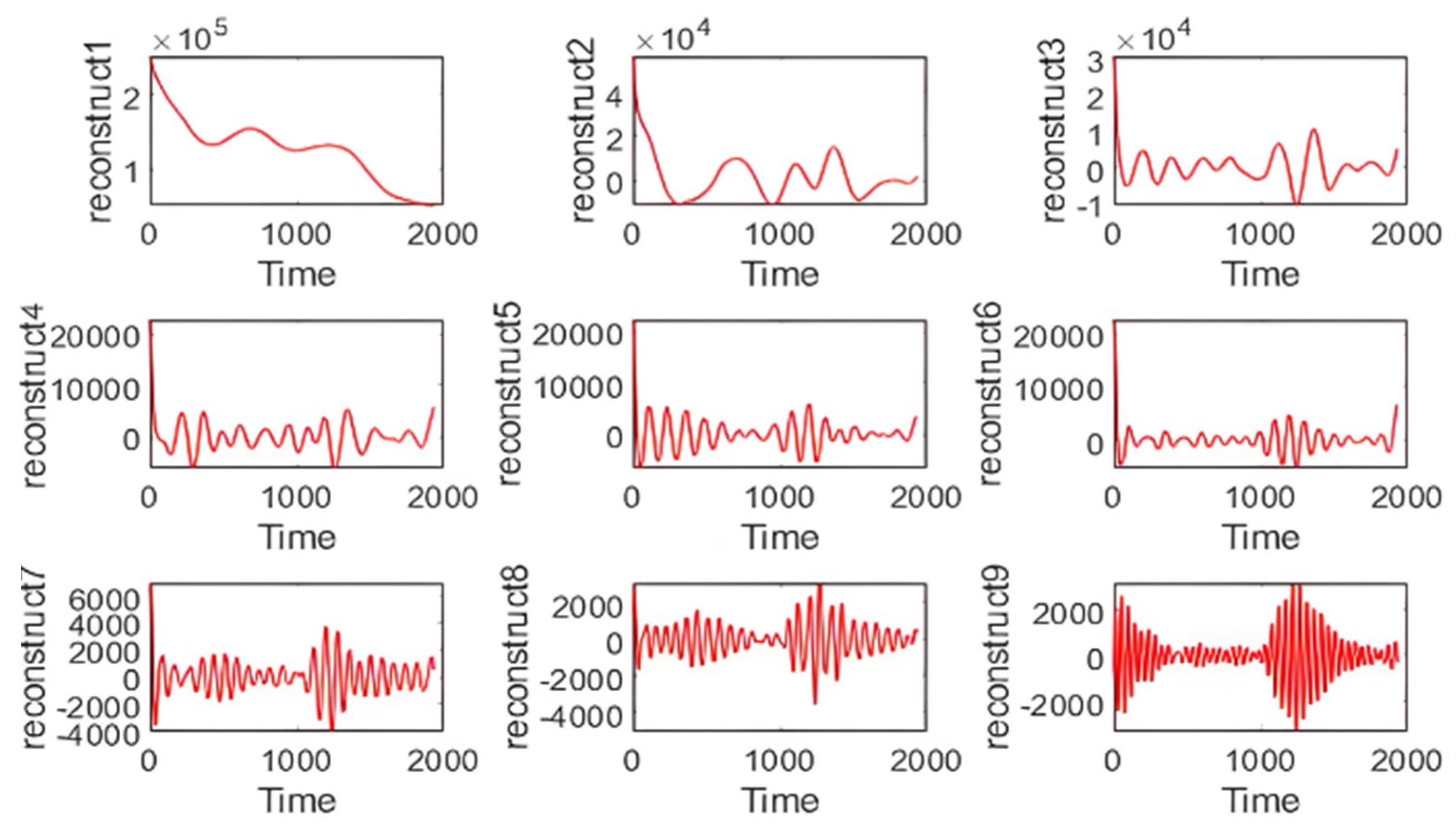
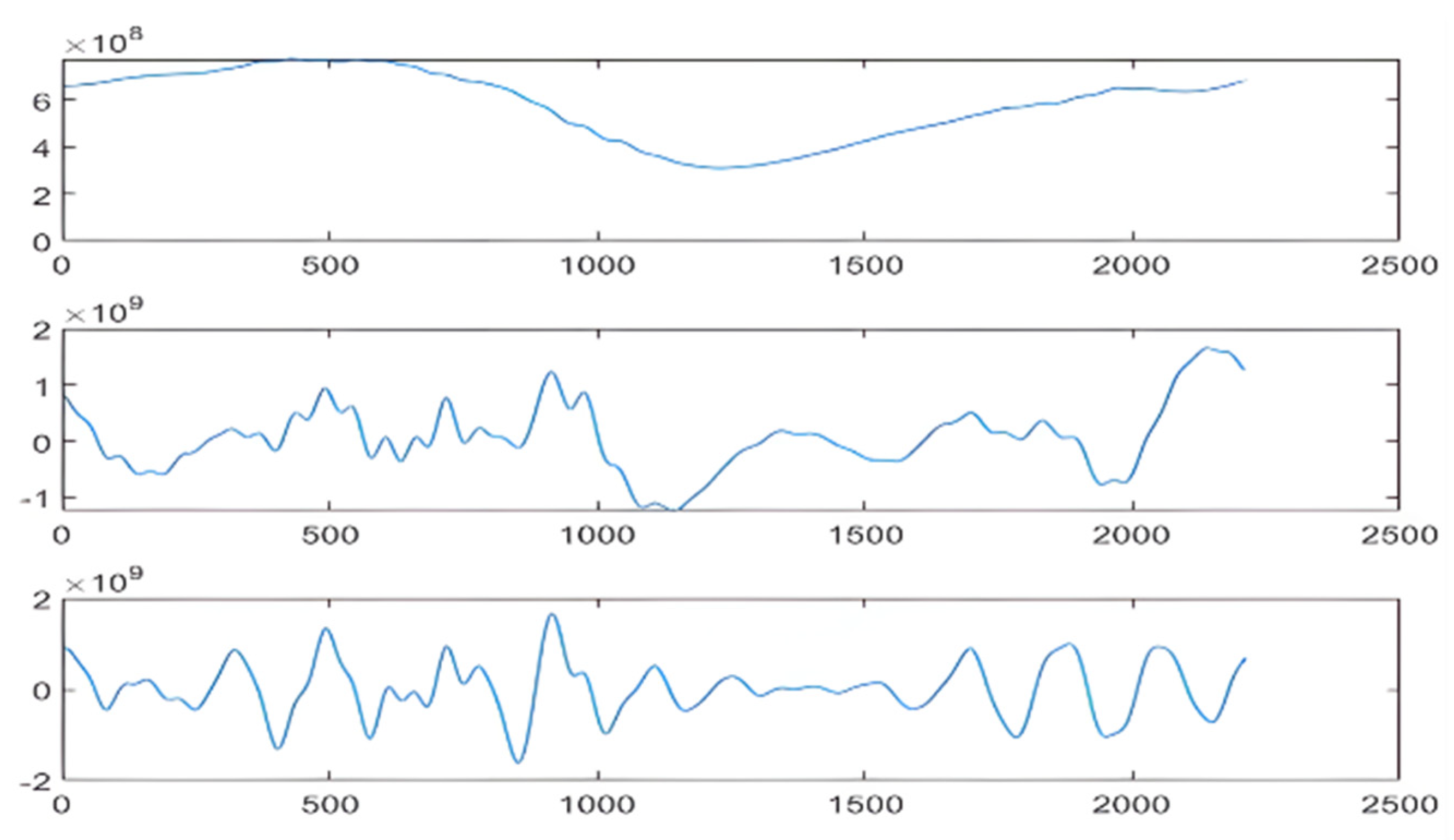
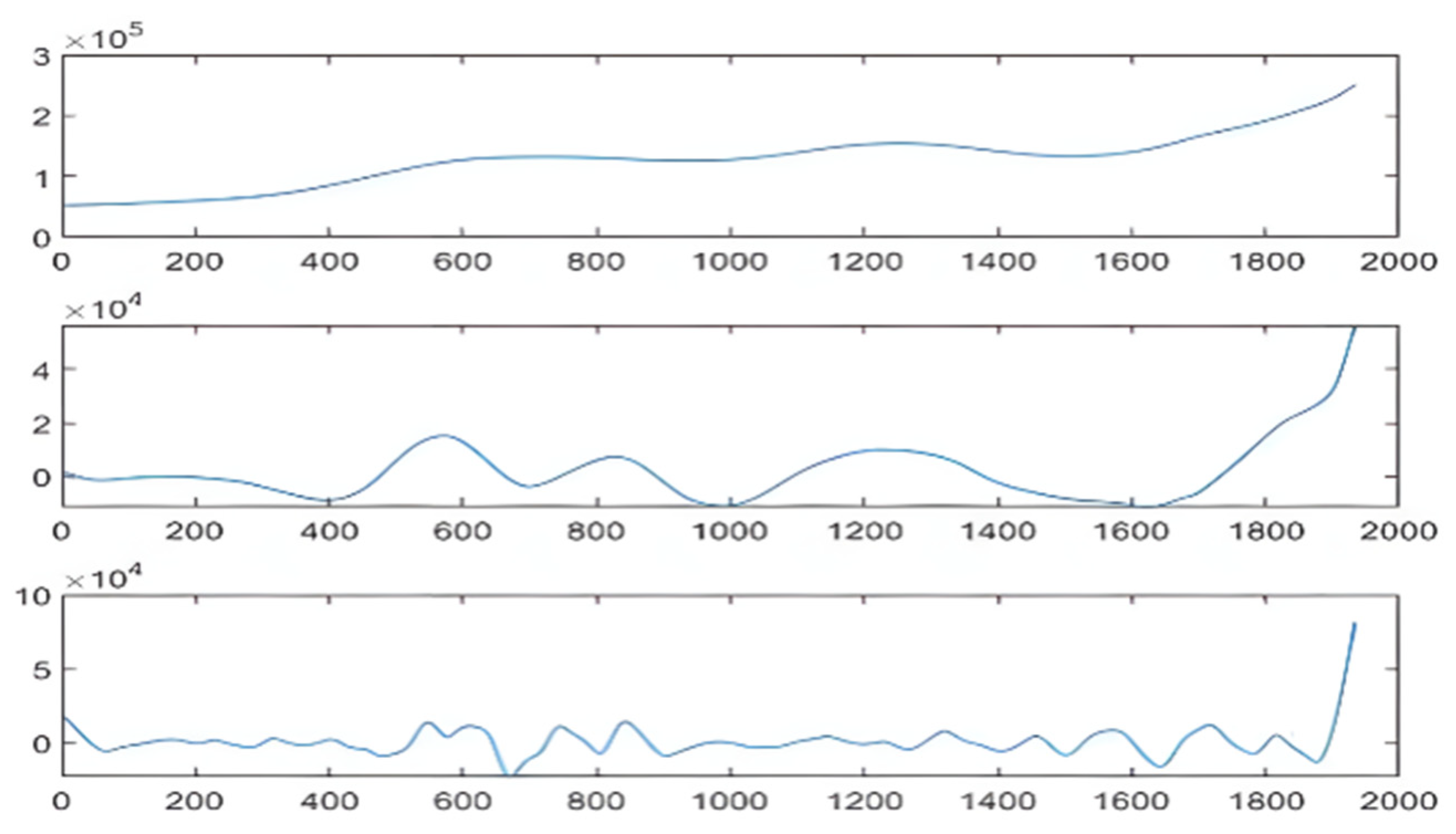
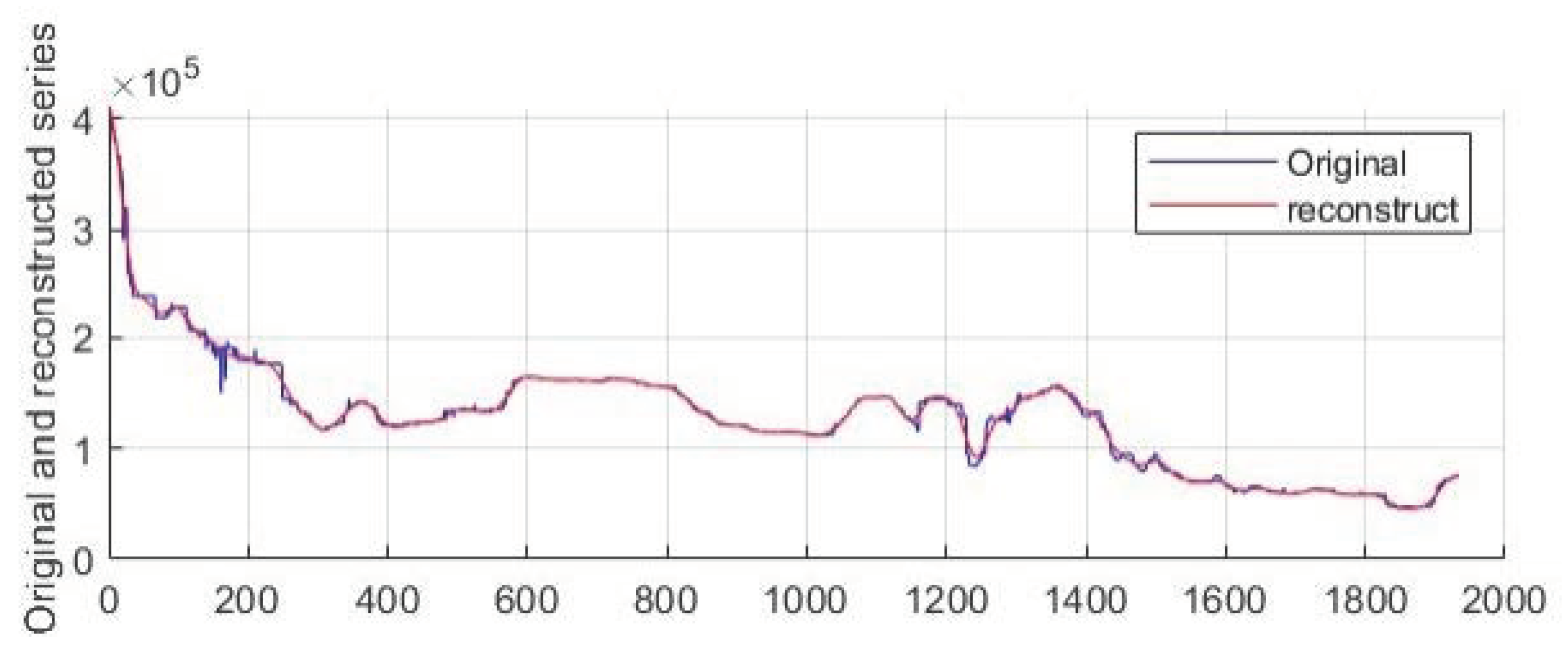
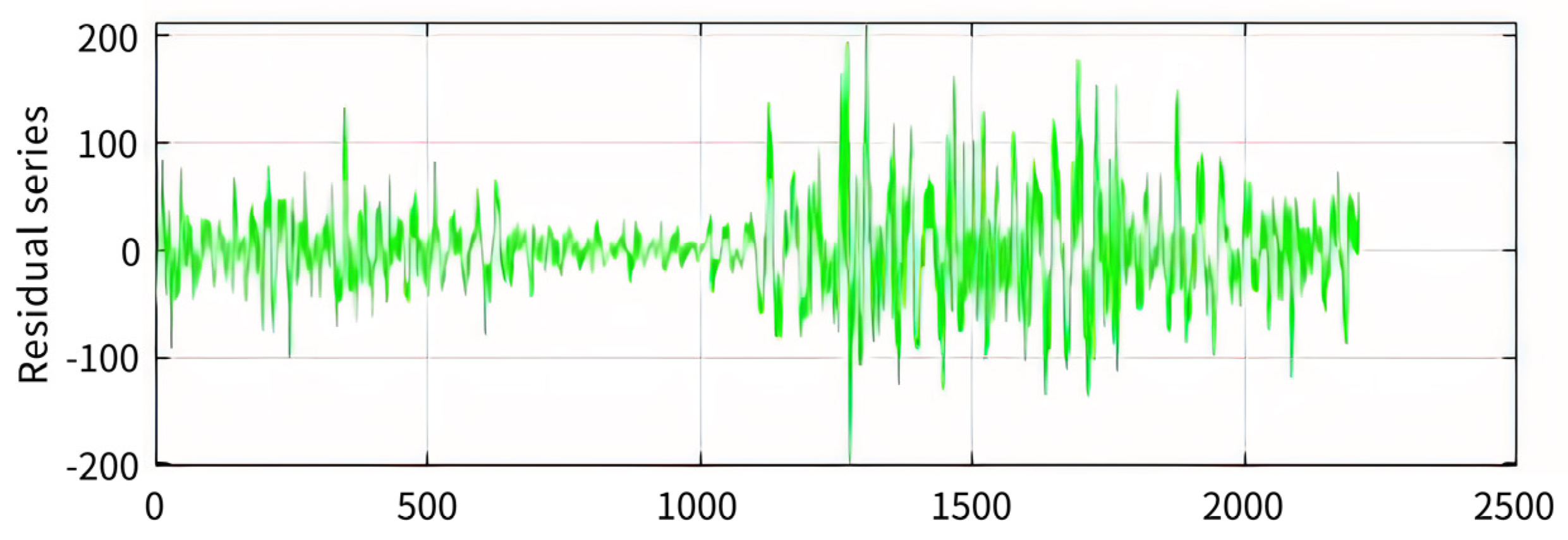
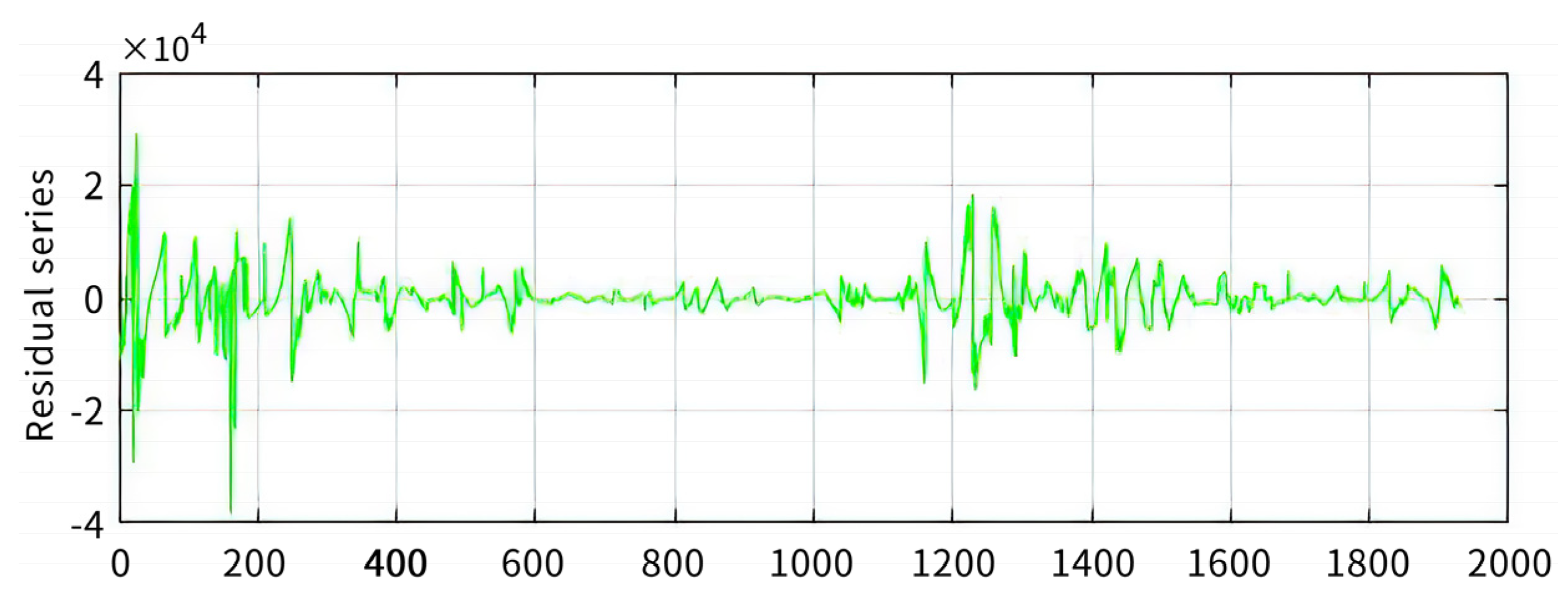
3.2.1. SSA Decomposition and LVQ Cluster
3.2.2. Calculation of Carbon Intensity
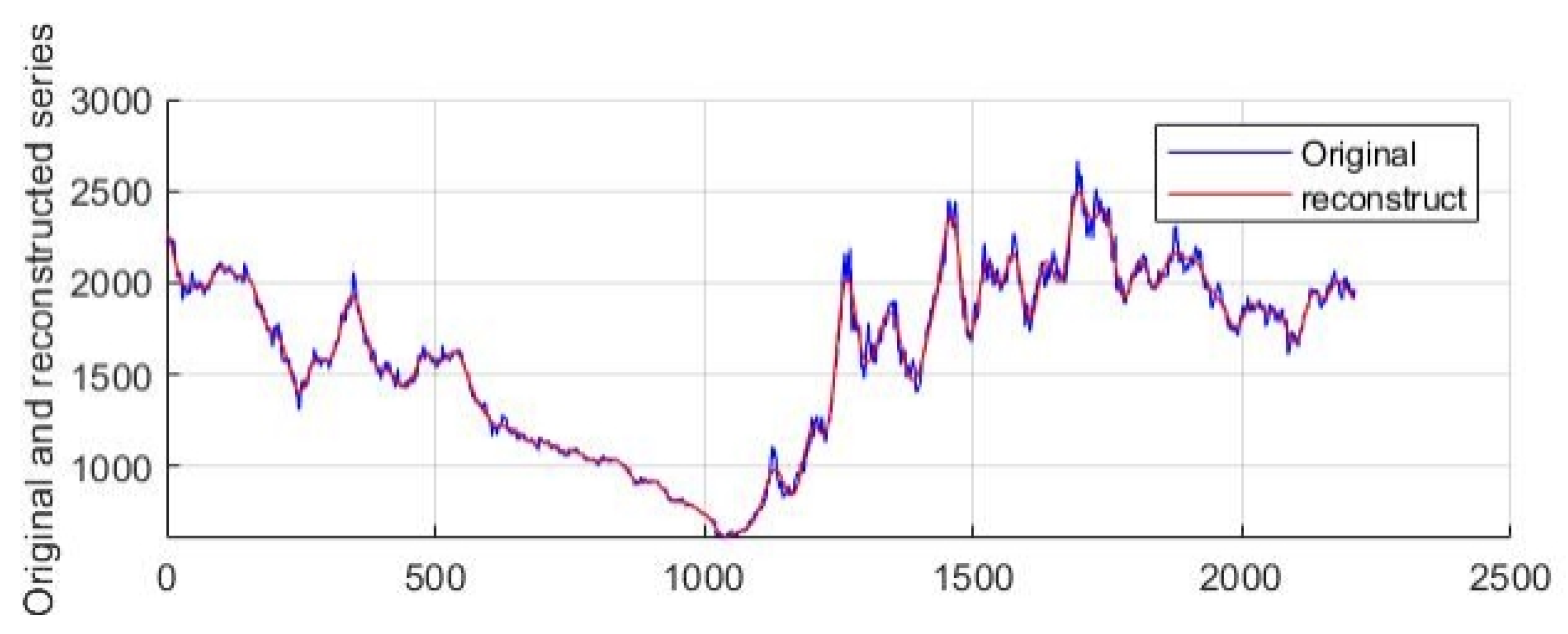
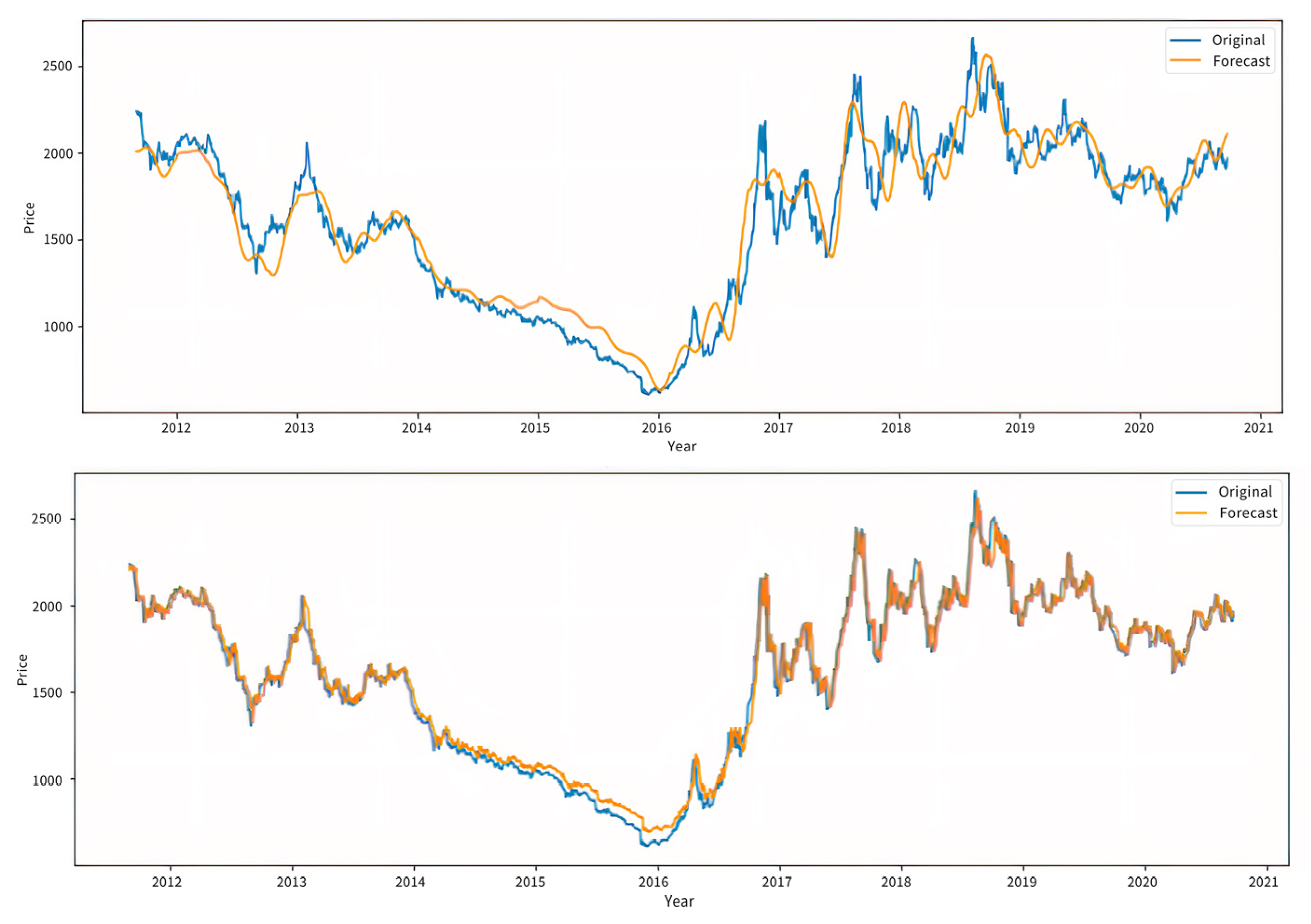
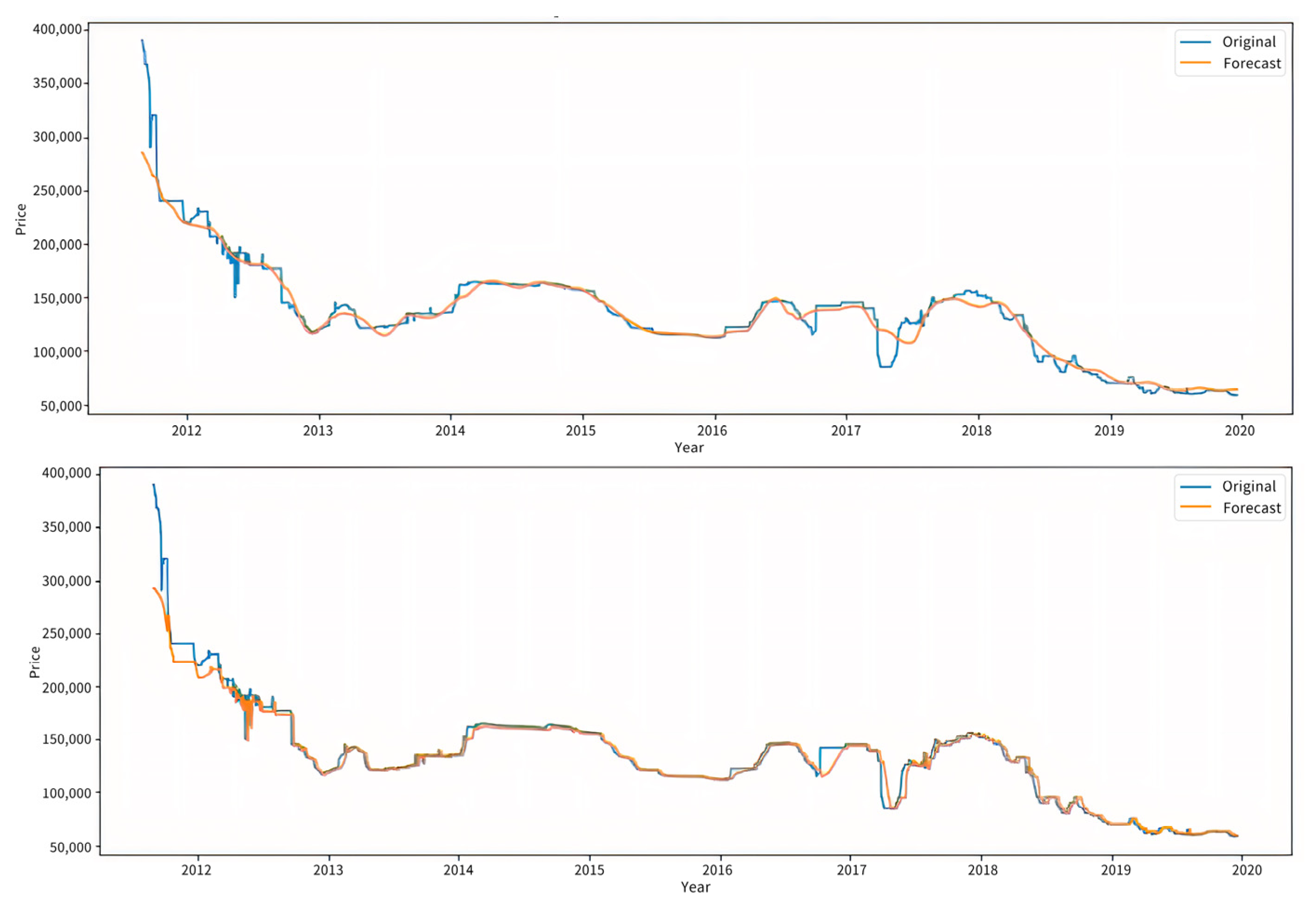
3.2.3. Analysis of Forecast Results
4. Comparative Analysis with Other Mainstream Time Series Prediction Models
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Birkenberg, A.; Narjes, M.E.; Weinmann, B.; Birner, R. The potential of carbon neutral labeling to engage coffee consumers in climate change mitigation. J. Clean. Prod. 2021, 278, 123621. [Google Scholar] [CrossRef]
- Wu, S.; Hu, S.; Frazier, A.E. Spatiotemporal variation and driving factors of carbon emissions in three industrial land spaces in China from 1997 to 2016. Technol. Forecast. Soc. Change 2021, 169, 120837. [Google Scholar] [CrossRef]
- Cheng, J.; Yi, J.; Dai, S.; Xiong, Y. Can Low-Carbon city construction facilitate green growth? Evidence from China’s pilot Low-Carbon city initiative. J. Clean. Prod. 2019, 231, 1158–1170. [Google Scholar] [CrossRef]
- Li, Y.; Shen, J.; Xia, C.; Xiang, M.; Cao, Y.; Yang, J. The impact of urban scale on carbon metabolism—A case study of Hangzhou, China. J. Clean. Prod. 2021, 292, 126055. [Google Scholar] [CrossRef]
- Xu, G.; Schwarz, P.; Yang, H. Determining China’s CO2 emissions peak with a dynamic nonlinear artificial neural network approach and scenario analysis. Energy Policy 2019, 128, 752–762. [Google Scholar] [CrossRef]
- Zeng, S.; Su, B.; Zhang, M.; Gao, Y.; Liu, J.; Luo, S.; Tao, Q. Analysis and forecast of China’s energy consumption structure. Energy Policy 2021, 159, 112630. [Google Scholar] [CrossRef]
- Gao, J.; Guan, C.; Zhang, B.; Li, K. Decreasing methane emissions from China’s coal mining with rebounded coal production. Environ. Res. Lett. 2021, 16, 1–10. [Google Scholar] [CrossRef]
- Yang, F.-f.; Zhao, X.-g. Policies and economic efficiency of China’s distributed photovoltaic and energy storage industry. Energy 2018, 154, 221–230. [Google Scholar] [CrossRef]
- Si, R.; Aziz, N.; Raza, A. Short and long-run causal effects of agriculture, forestry, and other land use on greenhouse gas emissions: Evidence from China using VECM approach. Environ. Sci. Pollut. Res. 2021, 28, 64419–64430. [Google Scholar] [CrossRef]
- Coppola, A. Forecasting oil price movements: Exploiting the information in the futures market. J. Futures Mark. 2008, 28, 34–56. [Google Scholar] [CrossRef]
- Zhang, Y.-J.; Wang, J. Exploring the WTI crude oil price bubble process using the Markov regime switching model. Phys. A-Stat. Mech. Its Appl. 2015, 421, 377–387. [Google Scholar] [CrossRef]
- Li, Y.; Zhu, Z.; Kong, D.; Han, H.; Zhao, Y. EA-LSTM: Evolutionary attention-based LSTM for time series prediction. Knowl. -Based Syst. 2019, 181, 104785. [Google Scholar] [CrossRef] [Green Version]
- Garcia-Martos, C.; Caro, E.; Sanchez, M.J. Electricity price forecasting accounting for renewable energies: Optimal combined forecasts. J. Oper. Res. Soc. 2015, 66, 871–884. [Google Scholar] [CrossRef] [Green Version]
- Wang, J.; Wang, J. Forecasting energy market indices with recurrent neural networks: Case study of crude oil price fluctuations. Energy 2016, 102, 365–374. [Google Scholar] [CrossRef]
- Chatvorawit, P.; Sattayatham, P.; Premanode, B. Improving Stock Price Prediction with SVM by Simple Transformation: The Sample of Stock Exchange of Thailand (SET). Thai J. Math. 2016, 14, 553–563. [Google Scholar]
- Chiroma, H.; Abdulkareem, S.; Herawan, T. Evolutionary neural network model for west texas intermediate crude oil price prediction. Appl. Energy 2015, 142, 266–273. [Google Scholar] [CrossRef]
- Wang, J.; Li, X. A combined neural network model for commodity price forecasting with SSA. Soft Comput. 2018, 22, 5323–5333. [Google Scholar] [CrossRef]
- Jing, N.; Wu, Z.; Wang, H. A hybrid model integrating deep learning with investor sentiment analysis for stock price prediction. Expert Syst. Appl. 2021, 178, 115019. [Google Scholar] [CrossRef]
- Rezaei, H.; Faaljou, H.; Mansourfar, G. Stock price prediction using deep learning and frequency decomposition. Expert Syst. Appl. 2021, 169, 114332. [Google Scholar] [CrossRef]
- Zhang, J.-L.; Zhang, Y.-J.; Zhang, L. A novel hybrid method for crude oil price forecasting. Energy Econ. 2015, 49, 649–659. [Google Scholar] [CrossRef]
- Reboredo, J.C.; Rivera-Castro, M.A. A wavelet decomposition approach to crude oil price and exchange rate dependence. Econ. Model. 2013, 32, 42–57. [Google Scholar] [CrossRef]
- Qu, X.M.; Liu, T.T.; Destech Publicat, I. The Impulse Response Analysis of Energy Price on Carbon Intensity Based on VAR Model-Taking Shanxi Province as an Example. In Proceedings of the International Conference on Advanced Management Science and Information Engineering (AMSIE), Hong Kong, China, 20–21 September 2015; ISBN 978-1-60595-246-8. [Google Scholar]
- Li, W.; Sun, W.; Li, G.; Jin, B.; Wu, W.; Cui, P.; Zhao, G. Transmission mechanism between energy prices and carbon emissions using geographically weighted regression. Energy Policy 2018, 115, 434–442. [Google Scholar] [CrossRef]
- Jiang, S.; Guo, J.; Yang, C.; Ding, Z.; Tian, L. Analysis of the relative price in China’s energy market for reducing the emissions from consumption. Energies 2017, 10, 656. [Google Scholar] [CrossRef] [Green Version]
- Sadorsky, P. Forecasting solar stock prices using tree-based machine learning classification: How important are silver prices? North Am. J. Econ. Financ. 2022, 61, 101705. [Google Scholar] [CrossRef]
- Meng, A.; Wang, P.; Zhai, G.; Zeng, C.; Chen, S.; Yang, X.; Yin, H. Electricity price forecasting with high penetration of renewable energy using attention-based LSTM network trained by crisscross optimization. Energy 2022, 254, 124212. [Google Scholar] [CrossRef]
- Wu, Y.X.; Wu, Q.B.; Zhu, J.Q. Improved EEMD-based crude oil price forecasting using LSTM networks. Phys. A: Stat. Mech. Its Appl. 2019, 516, 114–124. [Google Scholar] [CrossRef]
- Siddiqui, A.W. Predicting natural gas spot prices using artificial neu-ral network. In Proceedings of the 2019 2nd International Conference on Computer Applications & Information Security (ICCAIS), Riyadh, Saudi Arabia, 1–3 May 2019; pp. 1–6. [Google Scholar]
- Windler, T.; Busse, J.; Rieck, J. One month-ahead electricity price forecasting in the context of production planning. J. Cleaner Prod. 2019, 238, 117910. [Google Scholar] [CrossRef]
- Lu, H.; Ma, X.; Huang, K.; Azimi, M. Carbon trading volume and price forecasting in China using multiple machine learning models. J. Cleaner Prod. 2020, 249, 119386. [Google Scholar] [CrossRef]
- Zhang, H.; Yang, Y.; Zhang, Y.; He, Z.; Yuan, W.; Yang, Y.; Qiu, W.; Li, L. A combined model based on SSA, neural networks and LSSVM for short-term electric load and price forecasting. Neural Comput. Appl. 2021, 33, 773–788. [Google Scholar] [CrossRef]
- Yang, Y.; Dong, J.; Sun, X.; Lima, E.; Mu, Q.; Wang, X. A CFCC-LSTM Model for Sea Surface Temperature Prediction. IEEE Geosci. Remote Sens. Lett. 2018, 15, 207–211. [Google Scholar] [CrossRef]
- Ma, C.; Li, S.; Wang, A.; Yang, J.; Chen, G. Altimeter Observation-Based Eddy Nowcasting Using an Improved Conv-LSTM Network. Remote Sens. 2019, 11, 783. [Google Scholar] [CrossRef]
- Zhang, Y.; Tao, P.; Wu, X.; Yang, C.; Han, G.; Zhou, H.; Hu, Y. Hourly Electricity Price Prediction for Electricity Market with High Proportion of Wind and Solar Power. Energies 2022, 15, 1345. [Google Scholar] [CrossRef]
- Afshar, K.; Bigdeli, N. Data analysis and short term load forecasting in Iran electricity market using singular spectral analysis (SSA). Energy 2011, 36, 2620–2627. [Google Scholar] [CrossRef]
- Sun, M.; Li, X.; Kim, G. Precipitation analysis and forecasting using singular spectrum analysis with artificial neural networks. Clust. Comput. J. Netw. Softw. Tools Appl. 2019, 22, 12633–12640. [Google Scholar] [CrossRef]
- Liu, H.; Mi, X.; Li, Y.; Duan, Z.; Xu, Y. Smart wind speed deep learning based multi-step forecasting model using singular spectrum analysis, convolutional Gated Recurrent Unit network and Support Vector Regression. Renew. Energy 2019, 143, 842–854. [Google Scholar] [CrossRef]
- Urolagin, S.; Sharma, N.; Datta, T.K. A combined architecture of multivariate LSTM with Mahalanobis and Z-Score transformations for oil price forecasting. Energy 2021, 231, 120963. [Google Scholar] [CrossRef]
- Zhu, Q.; Peng, X.; Lu, Z.; Wu, K. Factors decomposition and empirical analysis of variations in energy carbon emission in China. Resources Science 2009, 31, 2072–2079. [Google Scholar]
- Peng, L.; Li, N.; Zheng, Z.; Li, F.; Wang, Z. Spatial-temporal heterogeneity of carbon emissions and influencing factors on household consumption of China. China Environ. Sci. 2021, 41, 463–472. [Google Scholar]
- Chen, H.; Qi, S.; Tan, X. Decomposition and prediction of China’s carbon emission intensity towards carbon neutrality: From perspectives of national, regional and sectoral level. Sci. Total Environ. 2022, 825, 153839. [Google Scholar] [CrossRef]
- Zeng, S.; Zhang, M. Green investment, carbon emission intensity and high-quality economic development: Testing non-linear relationship with spatial econometric model. West Forum 2021, 31, 69–84. [Google Scholar]
- Wang, Y.; Liao, M.; Wang, Y.; Xu, L.; Malik, A. The impact of foreign direct investment on China’s carbon emissions through energy intensity and emissions trading system. Energy Econo. 2021, 97, 105212. [Google Scholar] [CrossRef]
- Stratigakos, A.; Bachoumis, A.; Vita, V.; Zafiropoulos, E. Short-Term Net Load Forecasting with Singular Spectrum Analysis and LSTM Neural Networks. Energies 2021, 14, 4107. [Google Scholar] [CrossRef]
- Han, M.; Zhong, J.; Sang, P.; Liao, H.; Tan, A. A Combined Model Incorporating Improved SSA and LSTM Algorithms for Short-Term Load Forecasting. Electronics 2022, 11, 1835. [Google Scholar] [CrossRef]
- Luo, Y.; Zhang, Y.; Cai, X.; Yuan, X. E2GAN: End-to-End Generative Adversarial Network for Multivariate Time Series Imputation. In Proceedings of the 28th International Joint Conference on Artificial Intelligence, Macao, China, 10–16 August 2019; pp. 3094–3100. [Google Scholar]
- Zhao, J.; Cai, R.; Sun, W. Regional sea level changes prediction integrated with singular spectrum analysis and long-short-term memory network. Adv. Space Res. 2021, 68, 4534–4543. [Google Scholar] [CrossRef]
- Lu, H.F.; Ma, X.; Ma, M.D.; Zhu, S.L. Energy price prediction using data-driven models: A decade review. Comput. Sci. Rev. 2021, 39, 100356. [Google Scholar] [CrossRef]
- Duan, H.; Liu, Y. Research on a grey prediction model based on energy prices and its applications. Comput. Ind. Eng. 2021, 162, 107729. [Google Scholar] [CrossRef]
- Ma, Y.; Zhang, L.; Song, S.; Yu, S. Impacts of Energy Price on Agricultural Production, Energy Consumption, and Carbon Emission in China: A Price Endogenous Partial Equilibrium Model Analysis. Sustainability 2022, 14, 3002. [Google Scholar] [CrossRef]
- Zeng, S.; Zhang, H.; Qu, Y.; Zeng, B. Study on Price Fluctuation and Influencing Factors of Regional Carbon Emission Trading in China under the Background of High-quality Economic Development. Int. Energy J. 2021, 21, 201–211. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Unit | Mean | Std. Dev. | Min | Max |
|---|---|---|---|---|---|
| Coal price | CNY 10,000 | 12.933 | 5.259 | 4.590 | 40.010 |
| Polysilicon price | CNY 10,000 | 0.159 | 0.048 | 0.061 | 0.267 |
| Parameters of the Category | Numerical |
|---|---|
| Epochs | 2000 |
| Learning rate | 0.07 |
| Error performance target value | 10−6 |
| Hidden layers | 7 |
| Hidden units | 128 |
| Serial Number | Year | GDP (CNY trillion) | Total Amount of CO2 Emission (Ten Million Tons) | Carbon Intensity | Primary Sector of the Economy | Secondary Sector of the Economy | Tertiary Sector of the Economy |
|---|---|---|---|---|---|---|---|
| 1 | 2011 | 47.156 | 945.940 | 0.021 | 0.970 | 87.150 | 11.880 |
| 2 | 2012 | 51.932 | 1002.690 | 0.019 | 0.950 | 86.980 | 12.070 |
| 3 | 2013 | 58.802 | 1019.770 | 0.016 | 1.010 | 86.410 | 12.580 |
| 4 | 2014 | 63.646 | 1004.830 | 0.015 | 1.060 | 85.900 | 13.030 |
| 5 | 2015 | 67.671 | 975.760 | 0.013 | 1.110 | 84.670 | 14.220 |
| 6 | 2016 | 74.413 | 961.160 | 0.012 | 1.160 | 84.180 | 14.660 |
| 7 | 2017 | 82.712 | 971.450 | 0.010 | 1.180 | 84.000 | 14.830 |
| 8 | 2018 | 91.928 | 1002.750 | 0.009 | 1.200 | 83.750 | 15.050 |
| 9 | 2019 | 99.087 | 1025.670 | 0.008 | 1.180 | 84.070 | 14.760 |
| 10 | 2020 | 101.599 | 1052.020 | 0.009 | 1.220 | 84.510 | 14.280 |
| Energy Category | Lag Days | 1 | 3 | 5 | 7 | 10 | 14 |
|---|---|---|---|---|---|---|---|
| Coal | RMSE | 0.102 | 0.097 | 0.095 | 0.096 | 0.113 | 0.102 |
| MAE | 0.052 | 0.054 | 0.051 | 0.048 | 0.068 | 0.063 | |
| MAPE | 0.059 | 0.062 | 0.058 | 0.058 | 0.063 | 0.077 | |
| R-squared | 0.714 | 0.685 | 0.755 | 0.734 | 0.721 | 0.611 | |
| Polysilicon | RMSE | 0.092 | 0.086 | 0.087 | 0.094 | 0.102 | 0.099 |
| MAE | 0.073 | 0.058 | 0.059 | 0.064 | 0.074 | 0.101 | |
| MAPE | 0.051 | 0.043 | 0.042 | 0.039 | 0.071 | 0.094 | |
| R-squared | 0.812 | 0.825 | 0.852 | 0.771 | 0.688 | 0.652 |
| Energy Category | Input Value | RMSE | MAE | MAPE | R-Squared |
|---|---|---|---|---|---|
| Coal | P1 | 0.135 | 0.087 | 0.072 | 0.643 |
| P2 | 0.118 | 0.064 | 0.067 | 0.654 | |
| P3 | 0.098 | 0.054 | 0.065 | 0.725 | |
| P4 | 0.095 | 0.051 | 0.058 | 0.755 | |
| Polysilicon | P1 | 0.121 | 0.068 | 0.069 | 0.732 |
| P2 | 0.086 | 0.061 | 0.053 | 0.812 | |
| P3 | 0.086 | 0.064 | 0.048 | 0.824 | |
| P4 | 0.087 | 0.059 | 0.042 | 0.831 |
| Energy Category | Index | “Decomposition-Integration” Model | “Decomposition-Reconstruction-Integration” Model | ||||||
|---|---|---|---|---|---|---|---|---|---|
| SSA- LSTM | SSA- BPNN | SSA- RNN | SSA- SVR | SSA- LSTM | SSA- BPNN | SSA- RNN | SSA- SVR | ||
| Coal | RMSE | 0.118 | 0.284 | 0.269 | 0.331 | 0.095 | 0.205 | 0.2213 | 0.309 |
| MAE | 0.064 | 0.198 | 0.184 | 0.275 | 0.051 | 0.152 | 0.162 | 0.268 | |
| R-squared | 0.654 | 0.658 | 0.598 | 0.501 | 0.755 | 0.559 | 0.601 | 0.590 | |
| Polysilicon | RMSE | 0.086 | 0.191 | 0.221 | 0.224 | 0.087 | 0.197 | 0.213 | 0.212 |
| MAE | 0.061 | 0.166 | 0.171 | 0.298 | 0.059 | 0.160 | 0.171 | 0.268 | |
| R-squared | 0.812 | 0.832 | 0.604 | 0.543 | 0.831 | 0.735 | 0.684 | 0.595 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhu, D.; Wang, Y.; Zhang, F. Energy Price Prediction Integrated with Singular Spectrum Analysis and Long Short-Term Memory Network against the Background of Carbon Neutrality. Energies 2022, 15, 8128. https://doi.org/10.3390/en15218128
Zhu D, Wang Y, Zhang F. Energy Price Prediction Integrated with Singular Spectrum Analysis and Long Short-Term Memory Network against the Background of Carbon Neutrality. Energies. 2022; 15(21):8128. https://doi.org/10.3390/en15218128
Chicago/Turabian StyleZhu, Di, Yinghong Wang, and Fenglin Zhang. 2022. "Energy Price Prediction Integrated with Singular Spectrum Analysis and Long Short-Term Memory Network against the Background of Carbon Neutrality" Energies 15, no. 21: 8128. https://doi.org/10.3390/en15218128