1. Introduction
With the continuous progress of social science and technology, the application of electric power is becoming increasingly extensive, and there are more and more factors affecting the electric load, which leads to the non-smoothness and complexity of the electric load. Accurate prediction of power load data is beneficial to the relevant departments for policy making and power dispatching, and it is of great significance to the development of power systems. Therefore, determining how to accurately forecast the power load is a topic worthy of study.
Prediction by artificial intelligence algorithms is a current research hotspot in the field of load prediction, and artificial intelligence algorithms are more suitable for nonlinear data, such as random forests [
1,
2], artificial neural networks [
3,
4], and support vector machines [
5]. Among them, long short-term memory (LSTM) network is optimized on the basis of RNN. LSTM has a unique gate structure design that effectively overcomes the problem of gradient explosion or disappearance in RNN; it can effectively explore the intrinsic relationship between temporal data and has better accuracy when processing temporal data compared with other intelligent algorithms [
6]. Currently, LSTM is studied and applied in many fields, such as load prediction [
7], action recognition [
8], and speech recognition [
9].
However, with the continuous intensification of research, people have found that it is difficult to obtain ideal results using only a single algorithm, and a single algorithm generally has disadvantages such as slow calculation speed and large resource consumption [
10]. Based on this, combined prediction methods have been proposed, of which load decomposition plus prediction is among the better ideas.
Zhu et al. [
11] used EMD-Fbprophet-LSTM to predict the daily electricity consumption of enterprises to address the nonstationary nature of electricity consumption data. Semero et al. [
12] used empirical modal decomposition (EMD) to decompose the short-term load in a microgrid to obtain better prediction results. Although EMD can reduce the randomness and volatility of the data, it is recursive in nature, and modal confusion occurs when intermittent signals are present in the original signal. Later, based on EMD, ensemble empirical modal decomposition (EEMD) was established by adding white noise to the original signal, and this modification can avoid the phenomenon of modal confusion in the decomposition process. Tang et al. [
13] combined ensemble empirical modal decomposition (EEMD) with a deep belief network (DBN) and a bidirectional recurrent neural network (BIRNN) to establish the EEMD-DBN-BIRNN electric load model.
Azam et al. [
14] combined ensemble empirical modal decomposition (EEMD) with a bidirectional long short-term memory network (BiLSTM) to obtain more accurate results for forecasting the electricity load one day ahead. Although EEMD can solve the modal mixing phenomenon in EMD, it adds white noise to the original signal, which can contaminate the fluctuation trend of the original signal. Variable modal decomposition (VMD) can choose the number of modal components after decomposition according to the actual situation, and it adopts a nonrecursive processing strategy to decompose the original signal by constructing and solving the constrained variational problem, which has the advantages of better signal decomposition accuracy and anti-interference. At present, VMD is widely used in power load forecasting [
15,
16,
17], wind speed forecasting [
18,
19], energy price forecasting [
20], etc. Although the decomposition algorithm to decompose the original load is helpful to reduce the non-smoothness of the data and thus improve the accuracy of the model, it requires each component of the decomposition to be modeled separately for prediction, which not only makes the model computationally intensive and the training time longer but also makes the extraction of common features among each component inadequate.
The accuracy of load forecasting generally depends on two major aspects: the forecasting method and feature processing. The forecasting method is continuously optimized, while feature processing is also studied in depth. Feature processing generally refers to the analysis of various features affecting the load to identify the features that have a greater impact on the load, after which the optimal set of features is selected, which reduces interference by features that have a smaller impact on the load in the model. Previous studies [
13,
21] used the Pearson correlation coefficient (PCC) to analyze the correlation between power data and features, and several features with greater correlation with the load were selected as the input feature set to realize dimensionality reduction and the selection of data. Ge et al. [
22] quantified the correlation between load and input features using the maximum information criterion (MIC) and used FA to filter the features and eliminate invalid features. The above methods mainly use a number of features with a high correlation with the load data as input features; however, the feature-to-feature redundancy is not taken into account. In order to solve the problem of redundancy, people started to use the maximum correlation minimum redundancy [
23,
24] (mRMR) algorithm to select the optimal feature set based on the principle of maximizing the correlation between the feature set and the load data while minimizing the redundancy between the features and using incremental search to select the features.
Most of the existing methods use only linear analysis methods to analyze features, but there is a complex, nonlinear relationship between features and load data, so such methods still have major limitations. The Shapley value [
25] is a method in cooperative game theory that distributes benefits fairly to each member of a team based on the contribution of the members to the total benefit. Shapley values have been used in feature selection [
26,
27]. If each power impact factor is abstracted as a team member and the result of load forecasting is taken as the total benefit, the result of each feature for load impact forecasting can be measured by the Shapley value, and since Shapley is interpretable and can reflect the contribution of each feature, it is more able to reflect the nonlinear relationship between features and load compared to the traditional linear analysis method [
26]. Based on the above related research, this paper proposes a VMD-WSLSTM load prediction model based on Shapley values. First, Shapley values are used for feature selection. Then, VMD is used to decompose the load data into several smooth components, and finally, the WSLSTM prediction model is constructed to predict the components.
Table 1 shows the differences between the conventional load forecasting methods and the forecasting methods proposed in this paper. The innovation and contribution of this paper lie in the following aspects:
- (1)
Considering the complex nonlinear relationship between the electric load and the features, we use the Shapley value for feature selection.
- (2)
Considering the non-smoothness of the electric load, we use VMD to decompose the electric load and reduce the non-smoothness of the load.
- (3)
Considering that the traditional load forecasting model based on the combination of decomposition and prediction will lead to too many model parameters and overly complicated training, we introduce the idea of weight sharing to LSTM and construct the WSLSTM model.
2. Materials and Methods
In this section, firstly, the feature selection method used in this paper is introduced, and the specific process and formulas are described in
Section 2.1. Secondly, the VMD decomposition model is introduced, and the specific process and formulas are described in
Section 2.2. Finally, the main prediction model, the WSLSTM model, is introduced, and the specific process and formulas are described in
Section 2.3.
2.1. Feature Selection
In load forecasting studies, there are many factors that affect load fluctuations, and the relationship between factors and the load is highly complex and nonlinear. The Shapley value can effectively quantify the nonlinear relationship between features and the load [
28]. The Shapley value is essentially a measure of marginal contribution. Based on this concept, the contribution of each feature to the load can be expressed by the Shapley value, and the average value of the marginal contribution of the
jth feature of each n-dimensional sample in different feature subsets is the Shapley value of the feature. Its calculation formula is as follows.
where
is the Shapley value of the
jth feature in sample
x,
S is the subset of features not included in
,
is the number of features included in
S, and
is the prediction result based on the set of
S features.
From the formula, we know that to calculate the Shapley value of
, we need to calculate all combinations of features with and without
, and when the number of features is
N, the combination of features to be considered is
. Obviously, when the number of features to be considered is large, it will lead to an exponential increase in computation. Therefore, in this paper, the Shapley value of the features is estimated using the Monte Carlo sampling method [
29]. It is assumed that the input set of the model is
, and the samples to be computed are denoted by
.
Step 1: Set the number of samples to M and reset the initial iterations to m = 1.
Step 2: Realign the features in
to obtain a new alignment
.
where
n is the number of features in
, and
is the
jth feature in
.
Step 3: Sort the features in the selected sample
v according to the order of
, yielding
.
where
n is the number of features in
, and
denotes the
jth feature in
.
Step 4: Construct two new samples from the aligned
and
.
Step 5: Input the two newly generated samples
and
into the trained GWO-LSTM prediction model to calculate the prediction results and further obtain the marginal contribution of feature
to the prediction results
.
Step 6: Set m = m + 1 and loop through step (3) to step (8) until m > M when the loop stops.
Step 7: Calculate the average value of the marginal contribution of feature
obtained in
M cycles, which is the Shapley value of
.
For dataset
D, the average absolute value of the Shapley value
of the feature in dataset
D can be considered the Shapley value of the feature for the total load prediction result, which is calculated as:
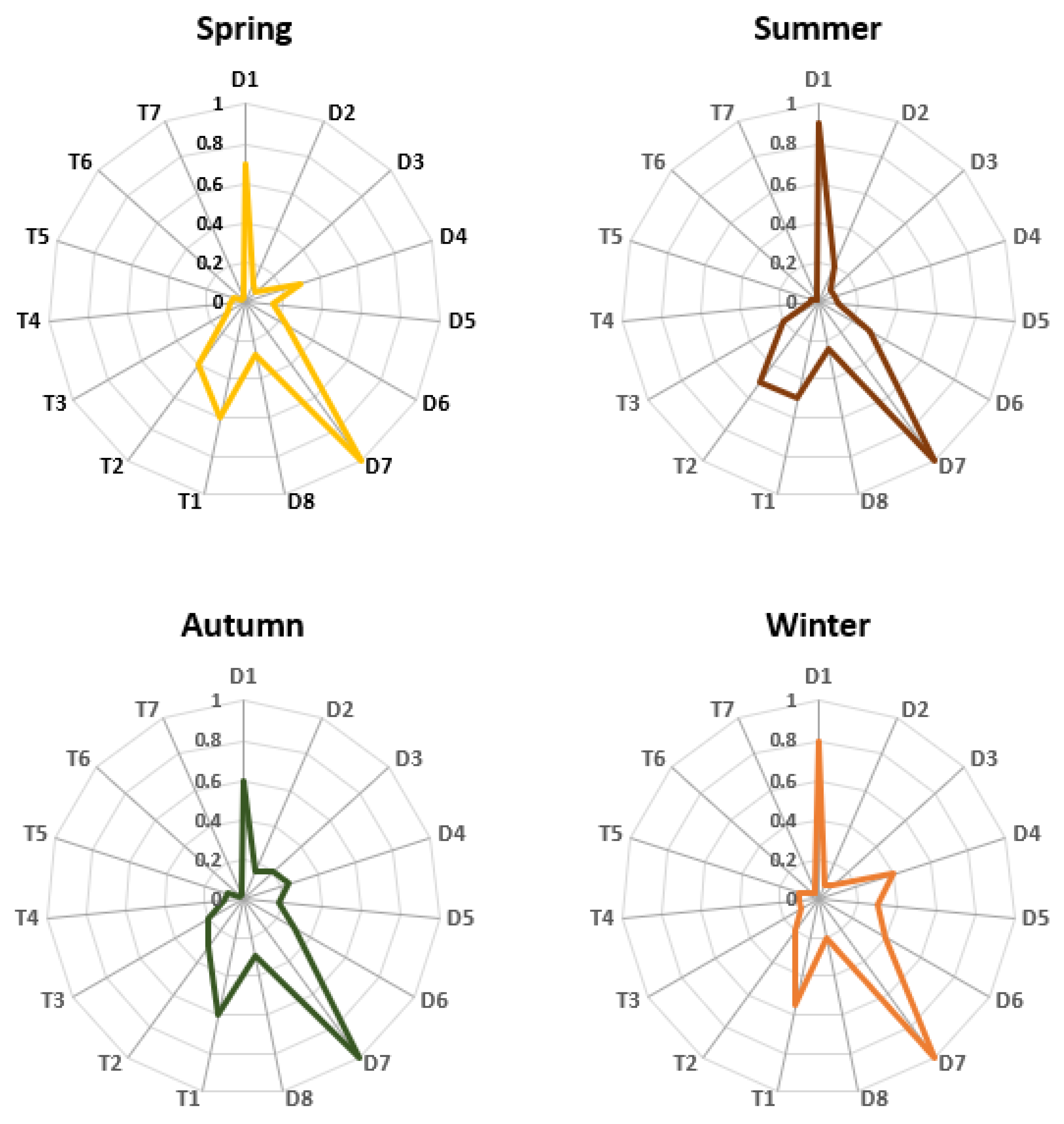
The Shapley value measures the importance of a feature for the load, and the larger the Shapley value of a feature, the greater the impact on the load.
2.2. Variable Modal Decomposition
Variable modal decomposition [
30] was proposed by Dragomiretskiy et al. on the basis of empirical modal decomposition. It is a nonrecursive, adaptive method for decomposing nonsmooth signals and is able to choose the number of modes for decomposition autonomously. The decomposed modal component (IMF) is a bandwidth-constrained amplitude modulation function with good noise robustness.
The VMD first calculates the analyzed signal for each modal component
by Hilbert transform to obtain the one-sided spectrum.
The signal resolved in each mode and its corresponding center frequency index
are mixed to shift the spectrum of each mode to the corresponding fundamental frequency band.
The gradient-squared L-parameter is calculated by demodulating the Gaussian smoothness of the signal and the gradient-squared criterion, from which the bandwidth of each modal signal is estimated with the variational constraint model as:
where
is the Dirac function,
is the decomposition of the modal components,
is the corresponding central frequency of each modal component, and ∗ is the convolution operation.
Introducing the Lagrange multiplier operator
λ(
t) and the quadratic penalty factor
α turns it into an unconstrained variational model.
In order to obtain the optimal value of Equation (11), VMD applies the multiplicative operator alternation method to cyclically update each decomposition signal
and its corresponding center frequency
with the cyclic update of Equations (14) and (15).
when the loop iteration satisfies Equation (16), the loop terminates, and the final modal component is obtained as follows.
2.3. WSLSTM
Long short-term memory networks [
31] (LSTM) were first proposed in 1997. Compared with RNN, the LSTM model introduces the concepts of memory cells and gates, replaces the neurons in the traditional neural network with memory cells, and adds forget gates, input gates, and output gates. The LSTM structure is able to store more long-term information and remove the unimportant information, so it can process the temporal data efficiently.
Figure 1 shows the basic structure of LSTM.
The calculation process is shown in Equations (17)–(22):
First, we calculate the state of the forget gate , which takes values from 0 to 1, and determines the extent to which the last moment of the model’s memory state is preserved. is the output of the previous moment, is the new input information, and is the weight matrix of the forget gate. After the model retains the relevant information from the memory state of the previous moment through the forget gate, it then determines the new information to be added through the input gate . is the weight matrix of the input gates. is the updated memory cell state, and is the preparatory information to be input into . Finally, the output of the current moment is calculated through the output gate , b is the bias matrix, and tanh is the activation function.
The weight-sharing mechanism [
32,
33] (WS) is a new idea that has emerged in recent years and is involved in image recognition, language interaction, etc. WSLSTM applies the idea of weight sharing, the essence of which lies in reducing parameters, simplifying the model, and extracting common features by sharing part of the structure of multiple independent LSTMs. The structure is similar to the stacked LSTM network structure, with the difference that WSLSTM shares one layer of the network structure. Specifically, after the original data are decomposed by the decomposition algorithm to obtain n modal components, it enters the corresponding independent LSTM, which is responsible for extracting the intrinsic features of each component. Then, it enters the LSTM layer with shared weights, which is responsible for resolving the common features of the components. Finally, it enters the independent LSTM layer, which is responsible for the final correction of the data, and the final prediction results are obtained by reconstructing the prediction results of each component after the correction. The existence of shared weights reduces the parameters of the model and improves its training speed.
Figure 2 shows the structure of WSLSTM.
The forward calculation of WSLSTM is similar to that of an ordinary multilayer LSTM, and the neuron update at moment t of the nth layer LSTM network is formulated as follows:
WSLSTM backpropagation is similar to the ordinary neural network when updating the weights. Error backpropagation is used to calculate the error between the model output data and the original load data, and the loss is recorded as the sum of the errors of all outputs. The minimum error method is used to adjust the weights.
2.4. The Framework of the Proposed Model
Figure 3 is the framework of the proposed method. Firstly, feature selection is performed using Shapley values, then the load data are decomposed into several modal components using VMD, and the component data are input to the WSLSTM model for prediction. Finally, the predicted values of each component are superimposed to obtain the final predicted values.
5. Conclusions
Accurate load forecasting can ensure the healthy operation of the power grid. In this paper, in order to improve the accuracy of the power load forecasting model, firstly, starting from the feature analysis, the Shapley value analysis method, which is different from the traditional feature analysis, is used to thoroughly explore the relationship between features and the load. Secondly, the idea of weight sharing is used to solve the problems of slow training and insufficient extraction of common features among components in the traditional model based on the combination of decomposition plus prediction. Controlled experiments using four datasets and multiple control groups led to the following conclusions:
- (1)
Compared with the traditional method of feature selection using correlation, the Shapley value method proposed in this paper is more able to measure the importance of features to the load. The prediction accuracy of the model using Shapley values for feature selection is also improved compared with the traditional method.
- (2)
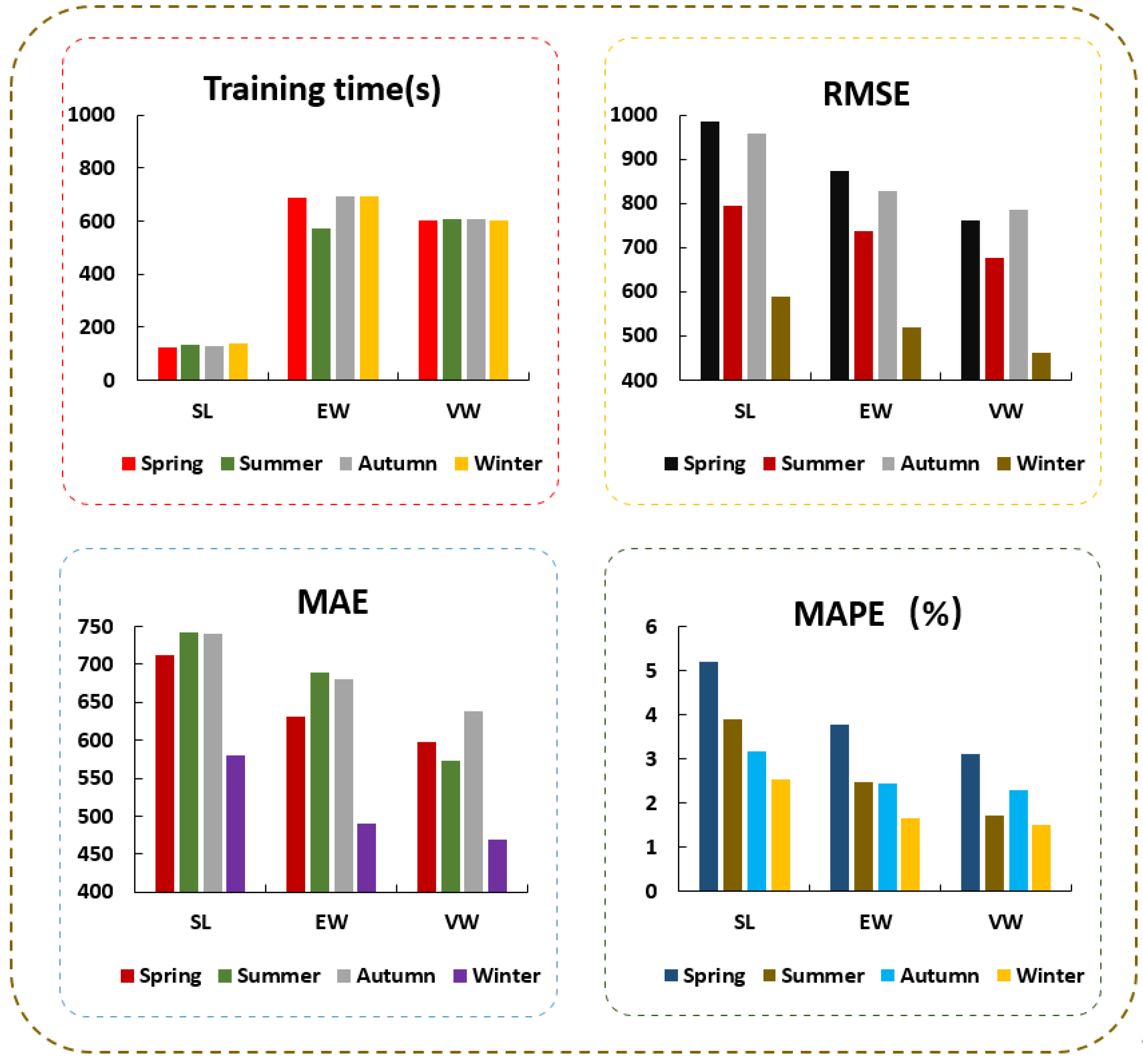
The decomposition of the original load data using the decomposition algorithm can effectively reduce the complexity of the data, and the separate prediction of the decomposed components also helps to improve the prediction accuracy of the model. Compared with the EMD algorithm, the accuracy of the model decomposed by using the VMD algorithm is generally higher.
- (3)
The training speed of the WSLSTM prediction model built by using the weight-sharing mechanism is significantly faster than the traditional LSTM model and GRU model. In addition, the WSLSTM model also has higher prediction accuracy than the traditional LSTM model and GRU model because it can extract common features among the components.
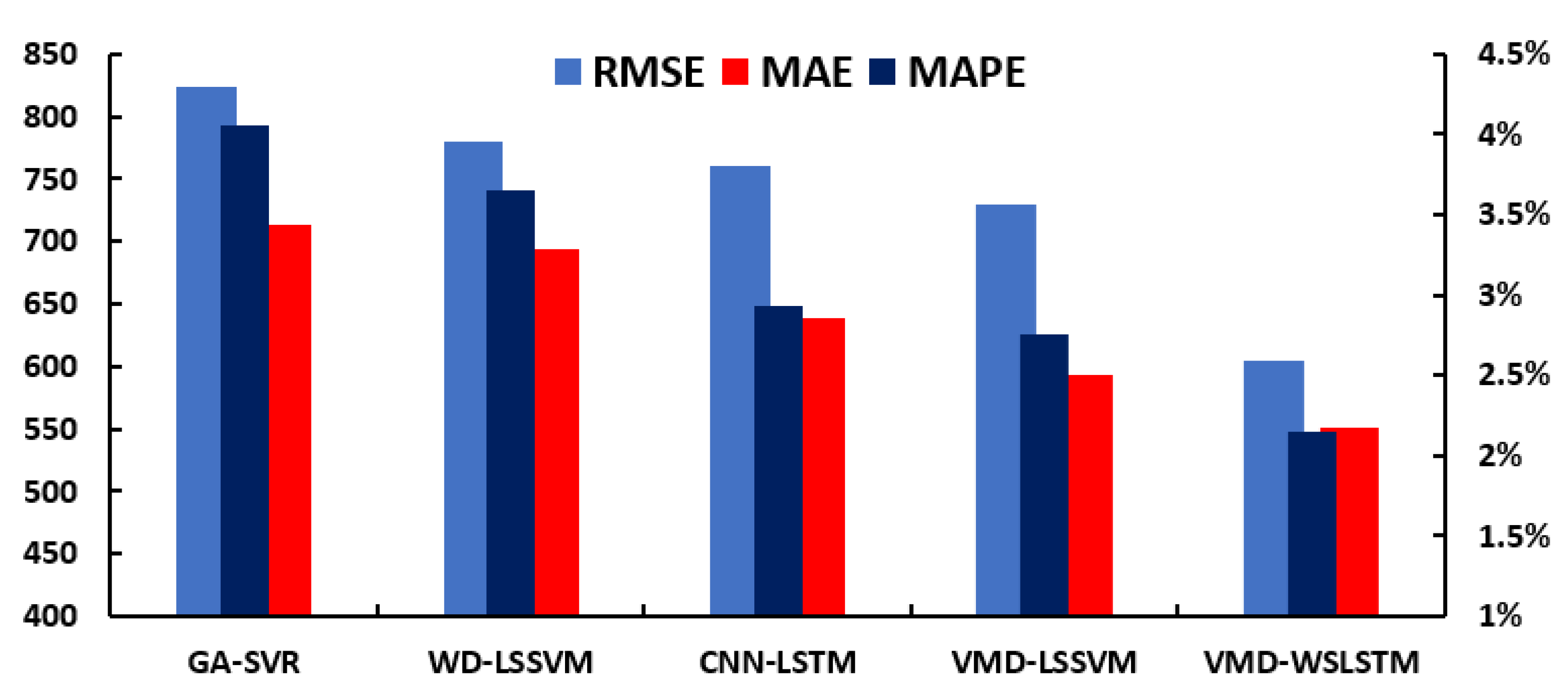
- (4)
The model in this paper has better prediction accuracy compared with traditional models such as GA-SVR, WD-LSSVM, CNN-LSTM, and VMD-LSSVM.
Therefore, feature selection using Shapley values and the prediction model using the weight-sharing mechanism proposed in this paper can improve the accuracy and speed of the prediction model. However, the model also has some shortcomings. For example, feature selection can take a lot of time when there are more features to be considered. Secondly, the Shapley threshold value when performing feature selection also needs further exploration.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}