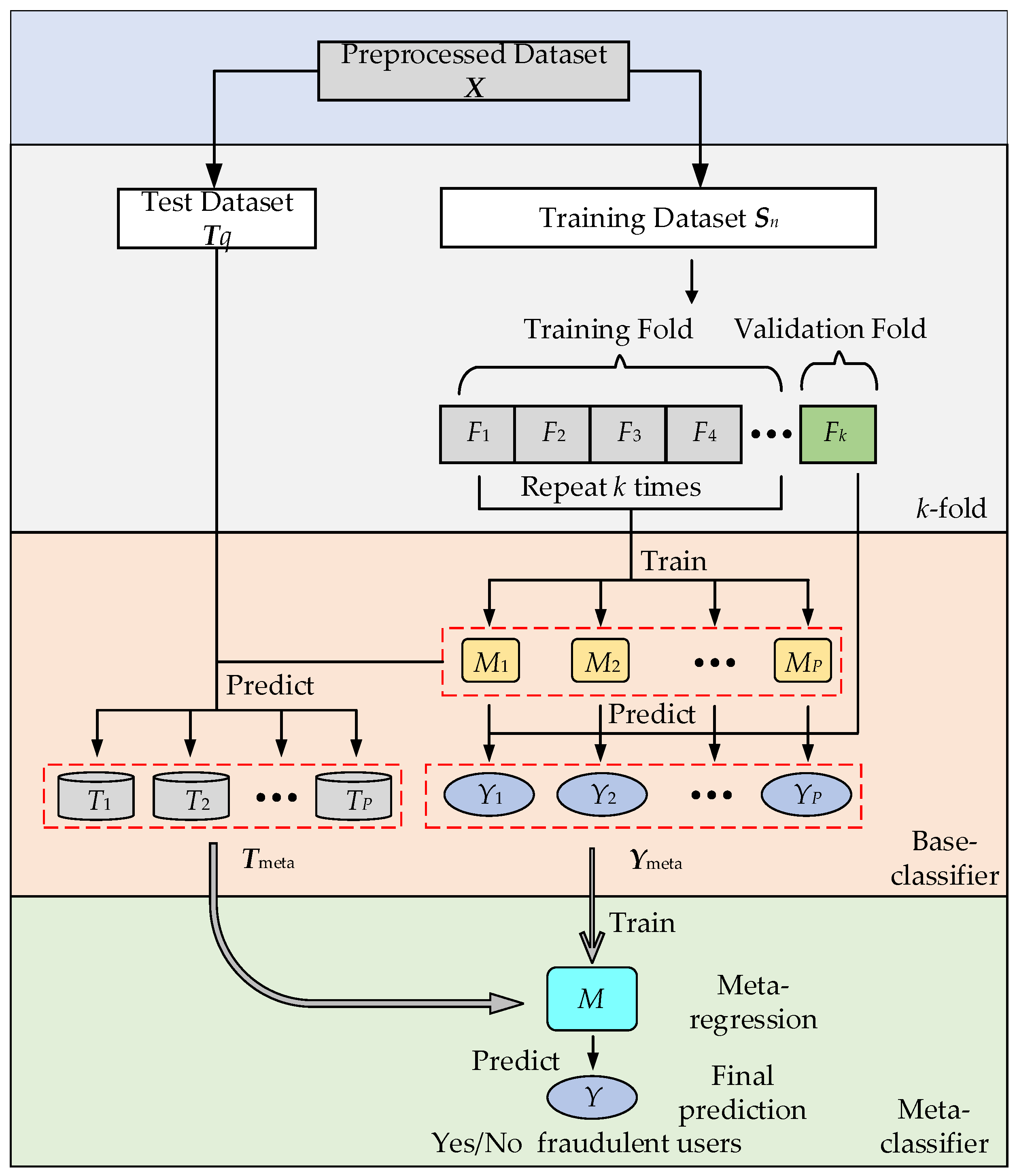
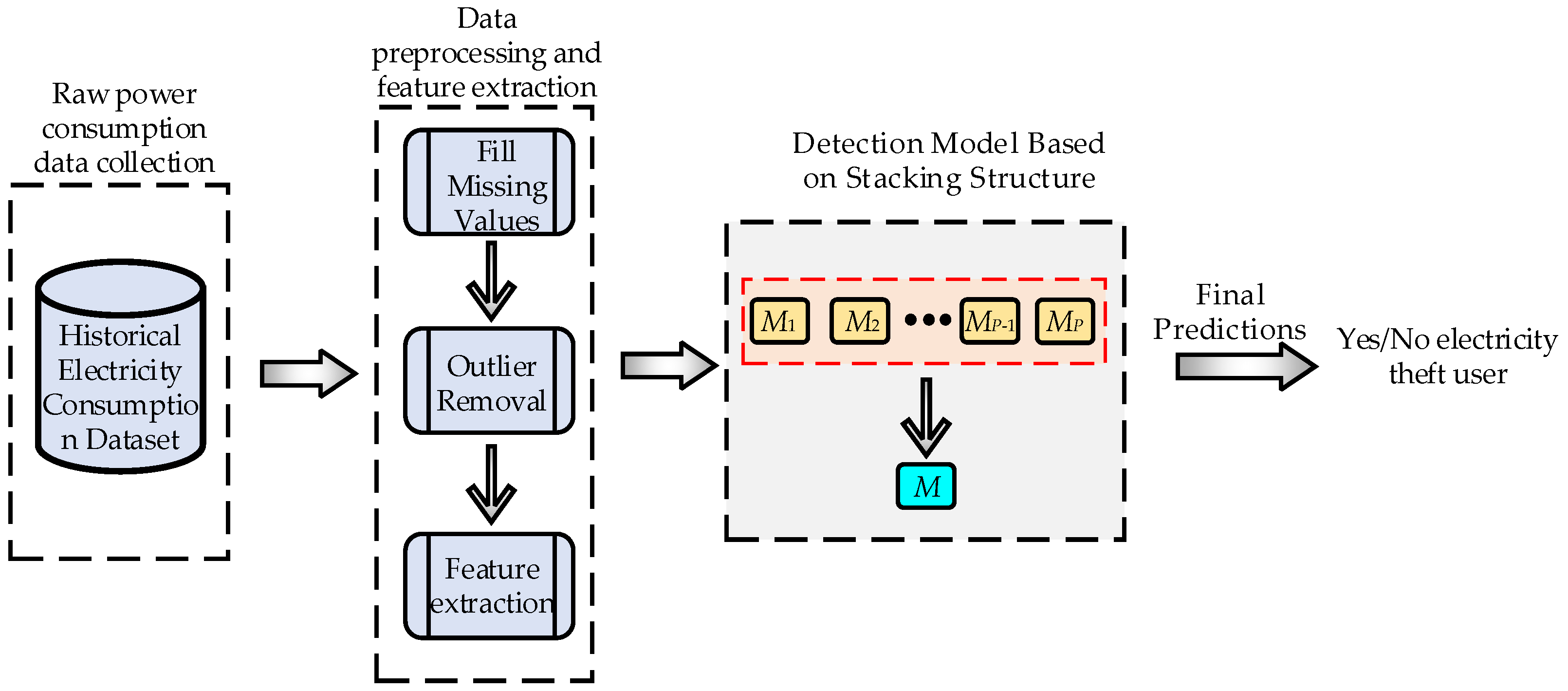
4.1. Construction of Base Model Layer in Stacking Structure
According to the experimental flow of the electricity theft detection model based on stacking structure in
Figure 4, the data preprocessing, including missing value complement and outlier value repair, has been described in detail in
Section 2 of the article, and the principle of feature extraction (i.e., load sequence feature extraction) for electricity consumption data has been described in detail in
Section 2.3 of the article, where the load sequence feature extraction is performed on the SGCC dataset to obtain time series features [
D1,…,
D49]. The newly dimensionality-reducing features of the extracted high-dimensional time series [
D1,…,
D49] were then treated by the PCA method described above to obtain the new dimensionality-reducing feature values from largest to smallest:
λ = [
λ1,
λ2,
λ3,…,
λ48,
λ49]. Calculate the value of l when the principal component contribution rate
r ≥ 95% is calculated by Formula (10), and
l = 6 is obtained after calculation, that is, the first six principal component eigenvalues are selected as the new feature set
Y.
The selection of the base model layer and the metamodel layer in
Figure 3 is the most important part of building the stacking structure, and the principle of the selection of the base model layer and the metamodel layer has been described in detail in
Section 3.3, where the base model layer is more complex than the metamodel because of the large number of classifiers in this layer. The base model layer determines the weight values of a single performance index of the classifier by using a combined weight method of subjective weights and objective weights based on GRA, of which the subjective weight method obtains the weights of Recall, MAP@100, F
1-score and AUC through the AHP as shown in
Table 4, and the weights of the four indicators are further calculated to be:
w′ = (0.0598, 0.2933, 0.1786, 0.4683).
In order to obtain the objective weight
w″ obtained by the EWM, the decision matrix
R = (
ri,j)
m×n of each classifier or a combination of classifiers (that is, each scheme) is first required, that is, the different classifications in the stacking structure are selected. The combined base model has four performance indicators: Recall, MAP@100, F
1-score, and AUC under the new feature set
Y after preprocessing, feature extraction and dimensionality reduction of the SGCC dataset, at this time, the meta-model of the stacking structure chooses a relatively simple linear regression (LR) model [
38]. According to the classifier, selection of the base model layer, as in
Section 3.3, should be strong and numerous, so the performance index values of eight existing classifiers commonly used for electricity theft detection under the new feature set
Y are compared, and the eight classifiers are: random forest (RF) [
39], eXtreme gradient boosting (XGBoost) [
25], light gradient boosting machine (LightGBM) [
40], support vector machine (SVM) [
22], CART decision tree (DT) [
23], deep forest (DF) [
41], long short-term memory (LSTM) [
28], and K-nearest neighbor (KNN) [
42].
The hyperparameters of the above eight classifier algorithms are set to: In the RF model, the number of decision trees and the maximum depth of the tree are set to 101 and 15, respectively. The XGBoost model sets the learning rate to 0.5, the random sampling ratio to 0.08, and the maximum depth and optimal number of iterations to 3 and 10, respectively. The LightGBM model sets the number of leaf nodes to 10, the learning rate to 0.05, the feature selection scale and sample sampling ratio of the tree to 0.8, and the number of iterations required to perform bagging is 5. The SVM model sets the kernel function as a radial basis function, and the penalty coefficient C = 15. The DT model sets the confidence parameter θ = 0.25, the minimum number of instances on the leaf node ρ = 2. The number of decision trees required for the DF model to set up multi-granular scanning is K = 30, and the slicing window size is 15. The LSTM model sets the number of neurons to 32, the number of hidden layers to 2, the learning rate to 0.1, and the number of trees to 300. The KNN model sets the initial K value to 3.
The new feature set
Y data samples are divided, and 50% of the data is randomly selected as the training sample (corresponding to 50% of the data as the test sample), and
Table 5 is the experimental results of the above eight classifiers, that is, the decision matrix
R. Therefore, the objective weight method obtains call, MAP@100, F
1-score, and AUC through the EWM, and the four performance index weights are:
w″ = (0.25899, 0.24321, 0.24851, 0.24929).
The combined weight vectors of each index of the combined weighting method can be obtained in three steps based on GRA:
Wj = [0.0598, 0.2432, 0.2287, 0.4683]. According to the combined weight vector
Wj, the comprehensive evaluation index values of the above eight classifiers are calculated:
η1 = [0.8273, 08107, 0.7991, 0.7318, 0.6863, 0.7962, 0.8110, 0.6848]
T, from which the comprehensive evaluation index of the above 8 classifiers is sorted as: RF > LSTM > XG > LG > DF > SVM > DT > KNN. The classifiers of the base model layer are combined according to the above eight classifiers, and the classifier combinations are combined from 2 to 8, where the number of combination types is:
+
+
+
+
+
+
= 247, due to the many combinations, as shown in
Table 6.
The experimental results only list some valuable classifier combinations (each quantity combination classifier selects relatively good displays according to the performance index values) and its corresponding Recall, MAP@100, F1-score, and AUC of the four performance index values. At this point, the meta-model of the stacking structure selects a linear regression model, and the k-fold setting k = 5.
The comprehensive evaluation index values of stacking structure integration learning method of each of the above classifier combinations were calculated by the combined weight vector Wj based on gray correlation degree analysis, and the results were: η2 = [0.8746, 0.8804, 0.8912, 0.9526, 0.9729, 0.9867, 0.9576, 0.9746, 0.9879, 0.9389, 0.9380, 0.9355, 0.9324]T. The η2 corresponds to the comprehensive evaluation index values of each of the above classifier combinations, from which the comprehensive evaluation indexes of the above 13 classifier combinations can be sorted as follows: ix > vi > viii > v > vii > iv > x > xi > xii > xiii > iii > ii > i, that is, the top three combinations of the comprehensive evaluation index values of the 13 classifier combinations are: LG + LSTM + KNN + SVM, LG + LSTM + KNN and XG + LSTM + KNN + SVM, the corresponding comprehensive evaluation index values are 0.9879, 0.9867 and 0.9746, respectively. So, the stacking structure integration learning method of the three classifiers combination base model layers has a better effect on the detection and classification of electricity theft behavior.
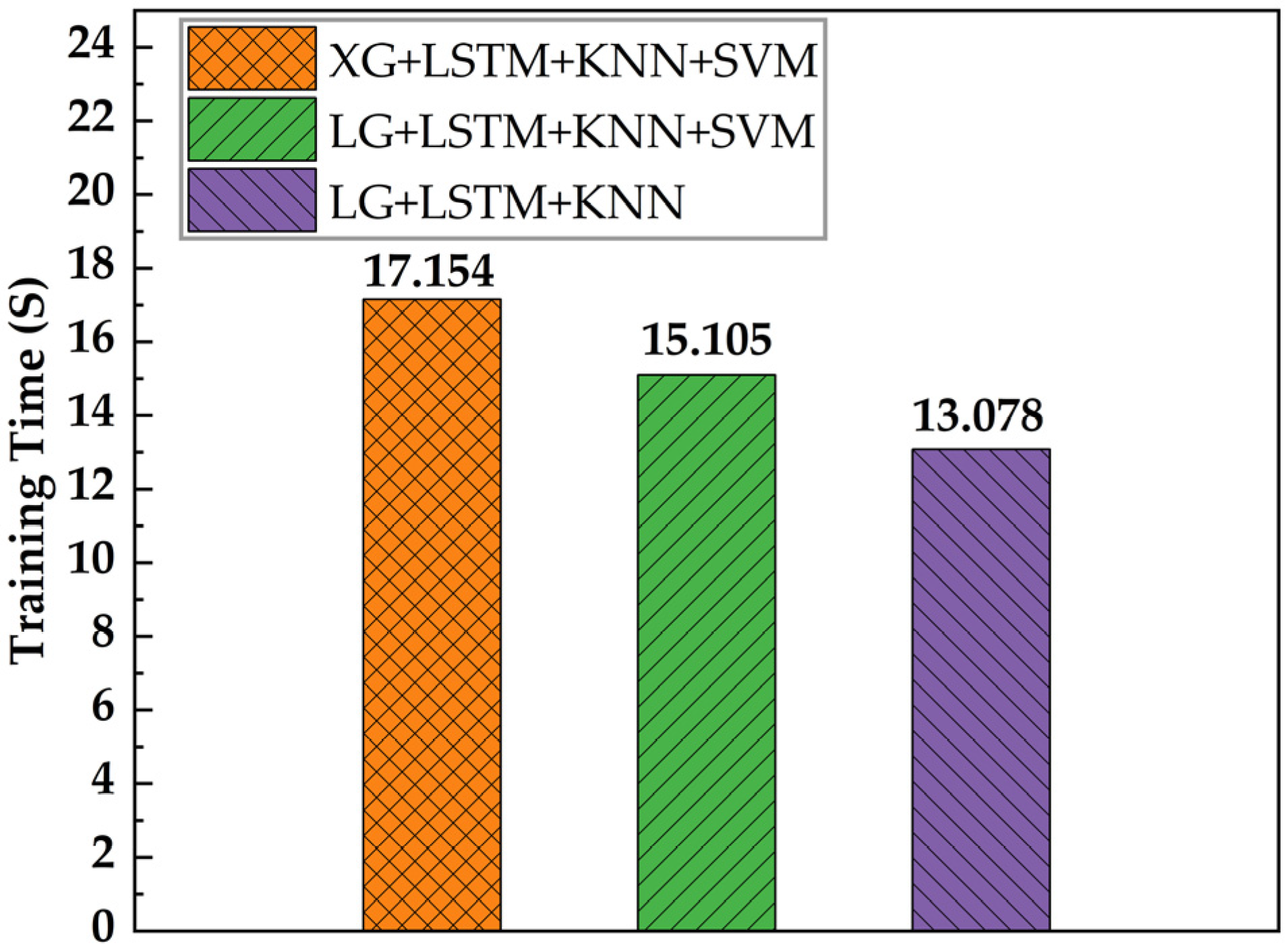
Through the above method, three classifier combinations with relatively good comprehensive evaluation index values were selected, but the comprehensive evaluation index values were relatively close (the difference was about 0.001). In order to select the optimal classifier combination, the training time of the model is also an important reference index for the real-time detection of electricity theft, so the training time of the stacking structure integration learning model under different classifier combinations is considered (at this time, the metamodel still uses a linear regression model). As shown in
Figure 5, given the training time of the stacking structure integration learning model under different classifier combinations, it can be clearly concluded that when the base model layer adopts the LG + LSTM + KNN combination, the model training time of the stacking structure is the least, only 13.078 s. The longest model training time is the XG + LSTM + KNN + SVM combination, and the training time is 17.154 s.
Taking into account the accuracy of the model and the training time of the model, the base model layer of the stacking structure ensemble learning model selects LG + LSTM + KNN. The comprehensive evaluation index value of stacking structure ensemble learning model detection based on this base model layer is only 0.0012 different from the comprehensive evaluation index value of stacking structure ensemble learning model detection based on the combination of LG + LSTM + KNN + SVM. The training time difference is 2.027 s. Therefore, considering the above factors, the combination of LG + LSTM + KNN is selected as the base model of the stacking structure ensemble learning model.
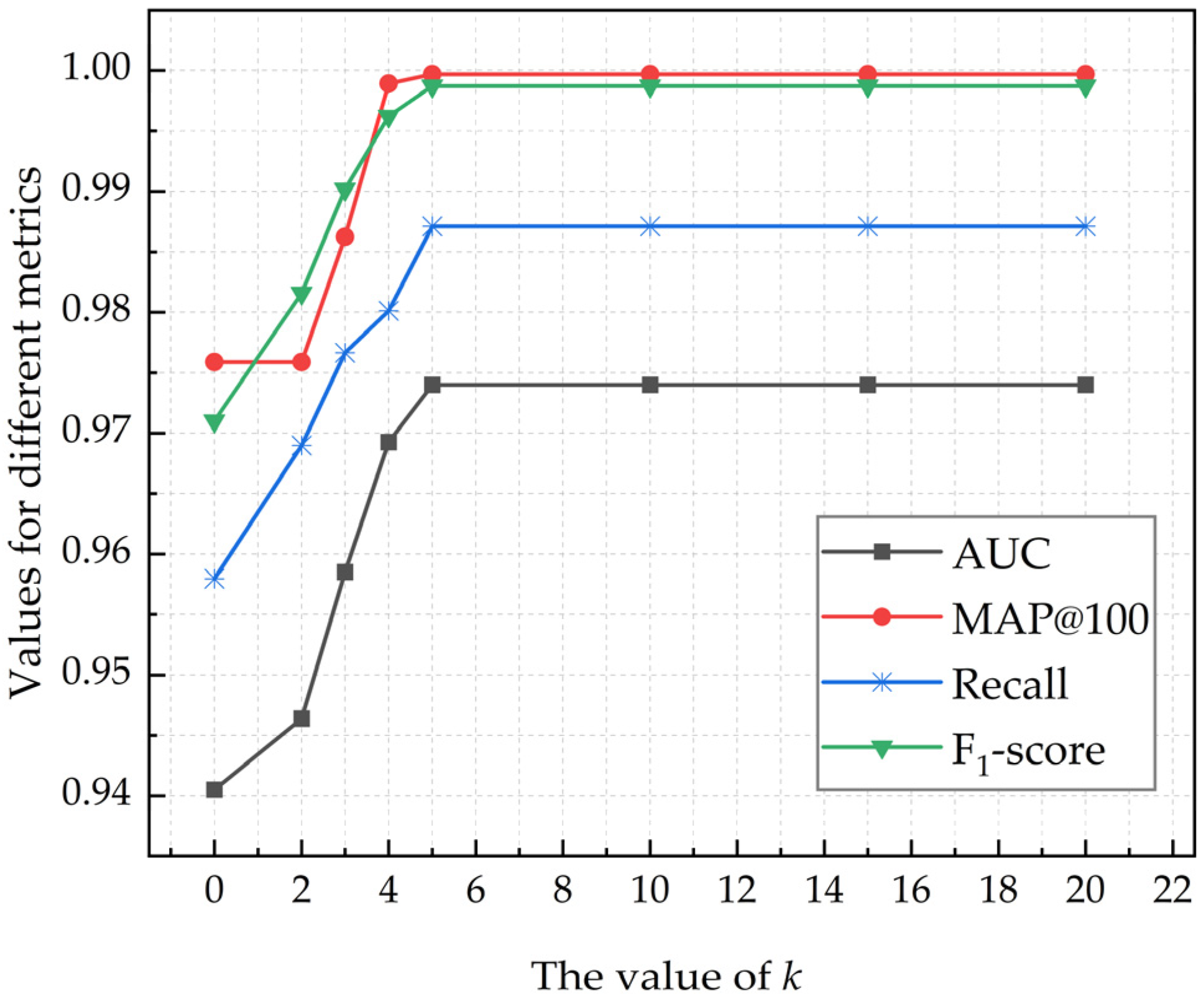
The above experiments set
k = 5 in the k-fold layer, and different
k values will greatly affect the detection effect of the stacking structure. According to the above experiments, the combination of LG + LSTM + KNN is selected as the base model of the stacking structure ensemble learning model, and the linear regression model is selected for the meta-model layer, and the
k values are set to 2, 3, 4, 5, 10, 15, and 20 pairs of models respectively. After training,
Figure 6 shows the experimental results under different
k values, in which the experimental results are the four performance index values of Recall, MAP@100, F
1-score, and AUC. As can be seen from
Figure 6, as the value of
k increases, the values of the four performance indicators also increase. When the value of
k is 5, each indicator value reaches the maximum value. On the other hand, the experimental results with
k-fold cross-training are better than those without
k-fold cross-training, so
k-fold cross-training significantly improves the detection performance of the model. Therefore, when the combination of LG + LSTM + KNN constitutes a stacking structure, five-fold cross-training is selected, that is,
k = 5 is set as the best parameter in the
k-fold layer.
The stacking structure integration learning method integrates a variety of detection algorithms, which can make full use of each algorithm to observe data from different data spaces and structures. Therefore, the classifier of the base model layer should try to choose an algorithm with excellent performance and should also add different types or properties of classification algorithms as much as possible. In order to further verify and analyze the optimal base model combination selected, each base learner separately compares the classification prediction of the new feature set
Y, and the Pearson correlation coefficient matrix is used to analyze the correlation of the classification prediction index values (AUC), and its calculation formula is as follows [
33]:
where
is the sample mean. The larger value of |
r|, the more correlated it is.
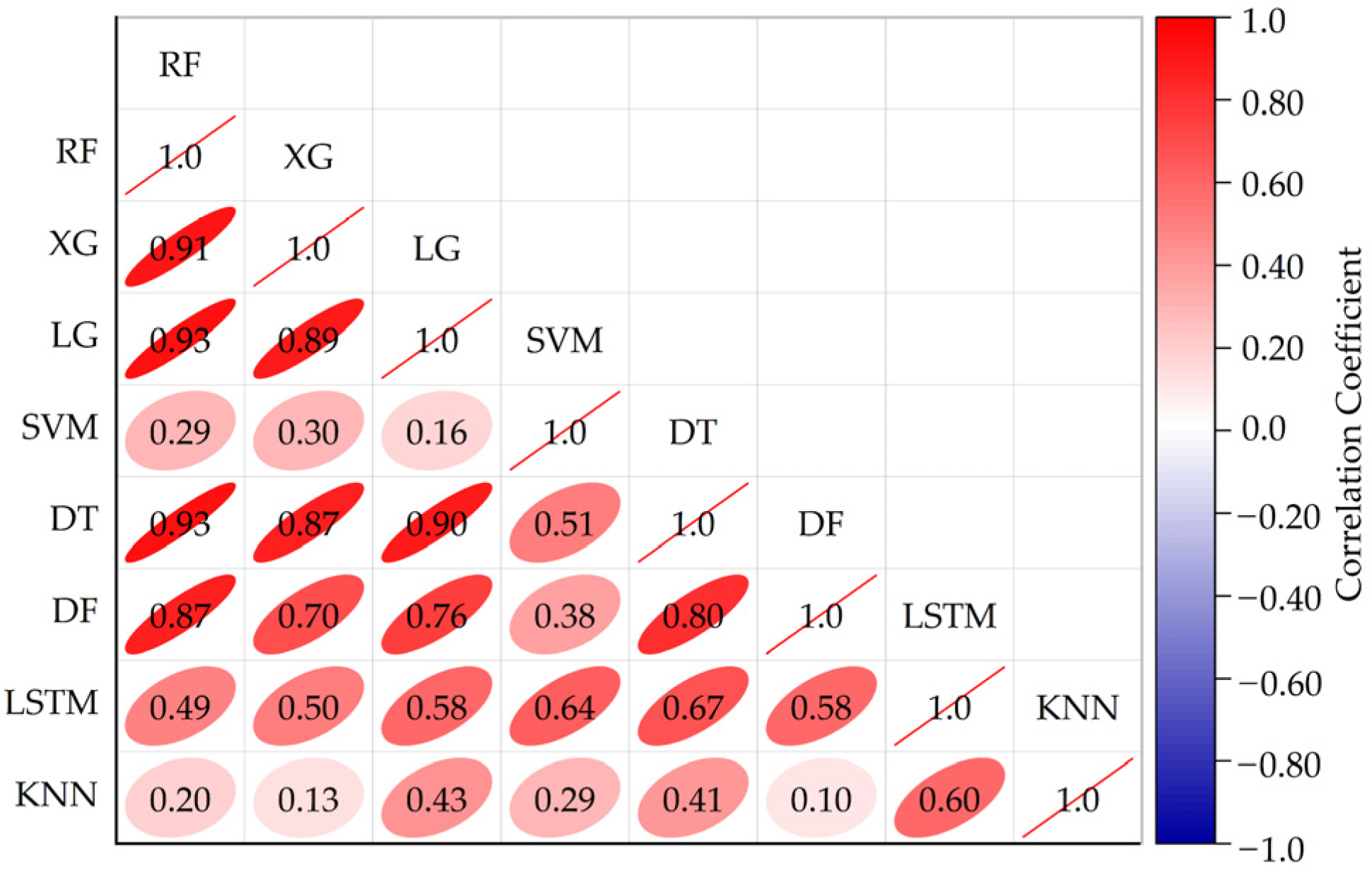
Figure 7 shows the correlation coefficient matrix between each classifier.
It can be seen from
Figure 7 that the correlation degree of the value of the classification prediction index of each algorithm is generally high, which is due to the strong learning ability of each algorithm, and the inherent laws learned in the data during training are similar to the data observation angles. Among them, the classification prediction index values of RF, XG, LG, DF, and DT algorithms have the highest correlation, which is due to the fact that although the principles of the five types of algorithms are slightly different, they still belong to the integrated algorithms of the tree, and there are strong similarities in their data observation methods. The training mechanisms of LSTM, SVM, and KNN have a large gap, so the correlation of classification prediction index values is also low. Therefore, the effectiveness of the base model layer in choosing LG + LSTM + KNN algorithm combination as the base model in stacking integration learning is further verified.
4.2. Construction of Meta Model Layer in Stacking Structure
As described in
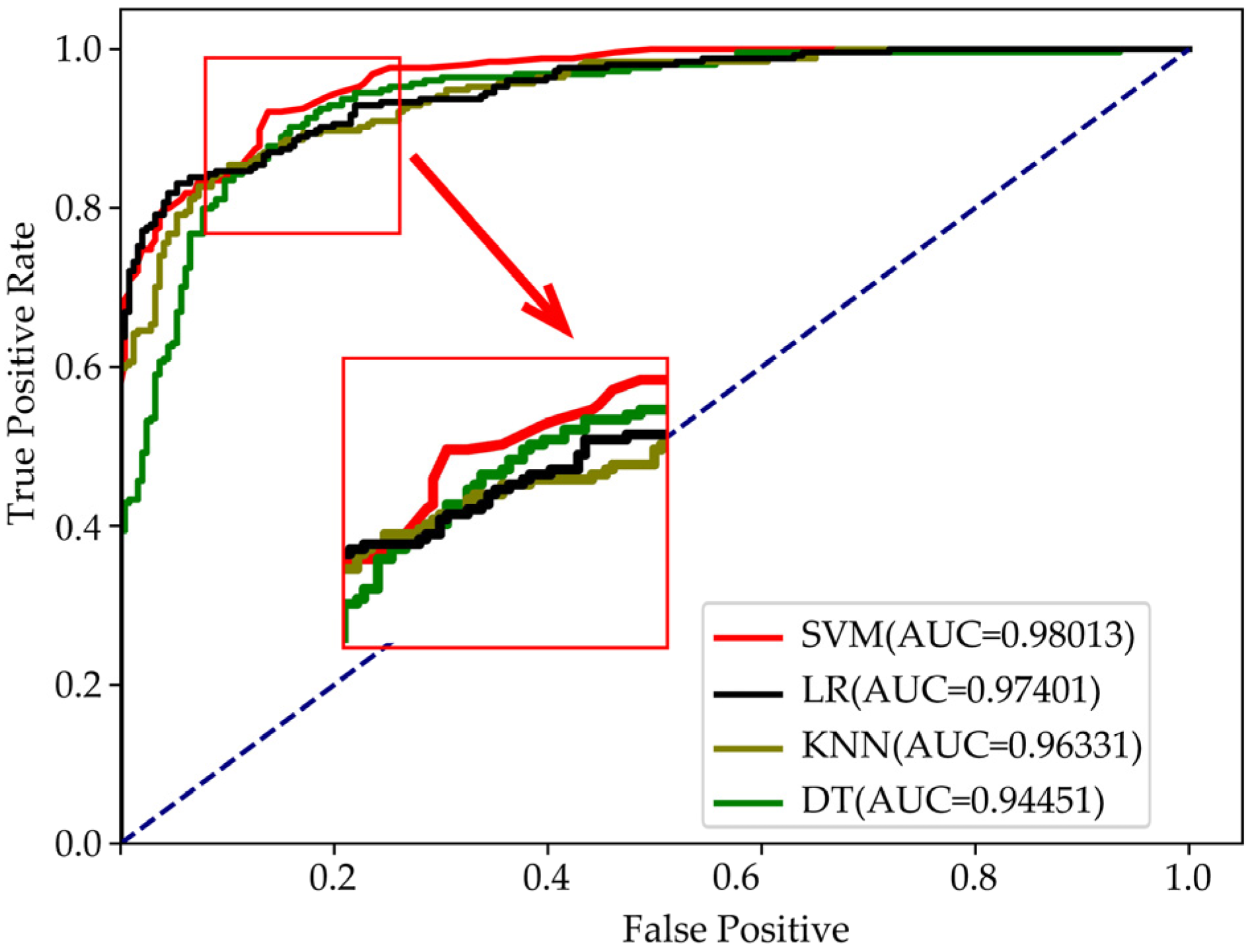
Section 3.2, the meta-model layer usually chooses a relatively simple model to prevent the overfitting problem of the collation model, so this section selects several relatively simple models at the meta-classifier layer to compare the experimental results of the stacking structural integration learning method, including the SVM, DT, KNN, and LR. The ROC curves of the experimental results of the stacking structure under the above four different meta-models are shown in
Figure 8.
It can be clearly seen from
Figure 8 that when SVM is selected for the meta-model layer, the overall detection effect of Stacking ensemble learning is the best, and its AUC value is 0.98013. When the meta-model layer adopts decision tree, the sorting and detection effect of the stacking ensemble learning is slightly worse than the other three. Therefore, considering the detection effect, this paper adopts SVM as the model of the stacking integrated learning meta-model layer.
Since the recognition accuracy of the SVM algorithm is limited to a large extent by the selection of parameters, and the parameter optimization algorithm generally has problems, such as slow convergence speed and a tendency to fall into local extremums, the particle swarm optimization (PSO) algorithm [
43] with strong optimization ability, fast convergence speed, and short calculation time is selected in this experiment to optimize the penalty coefficient
C and kernel function (i.e., radial basis function) parameter σ values in the stacking integrated learning model metaclassifier SVM hyperparameter.
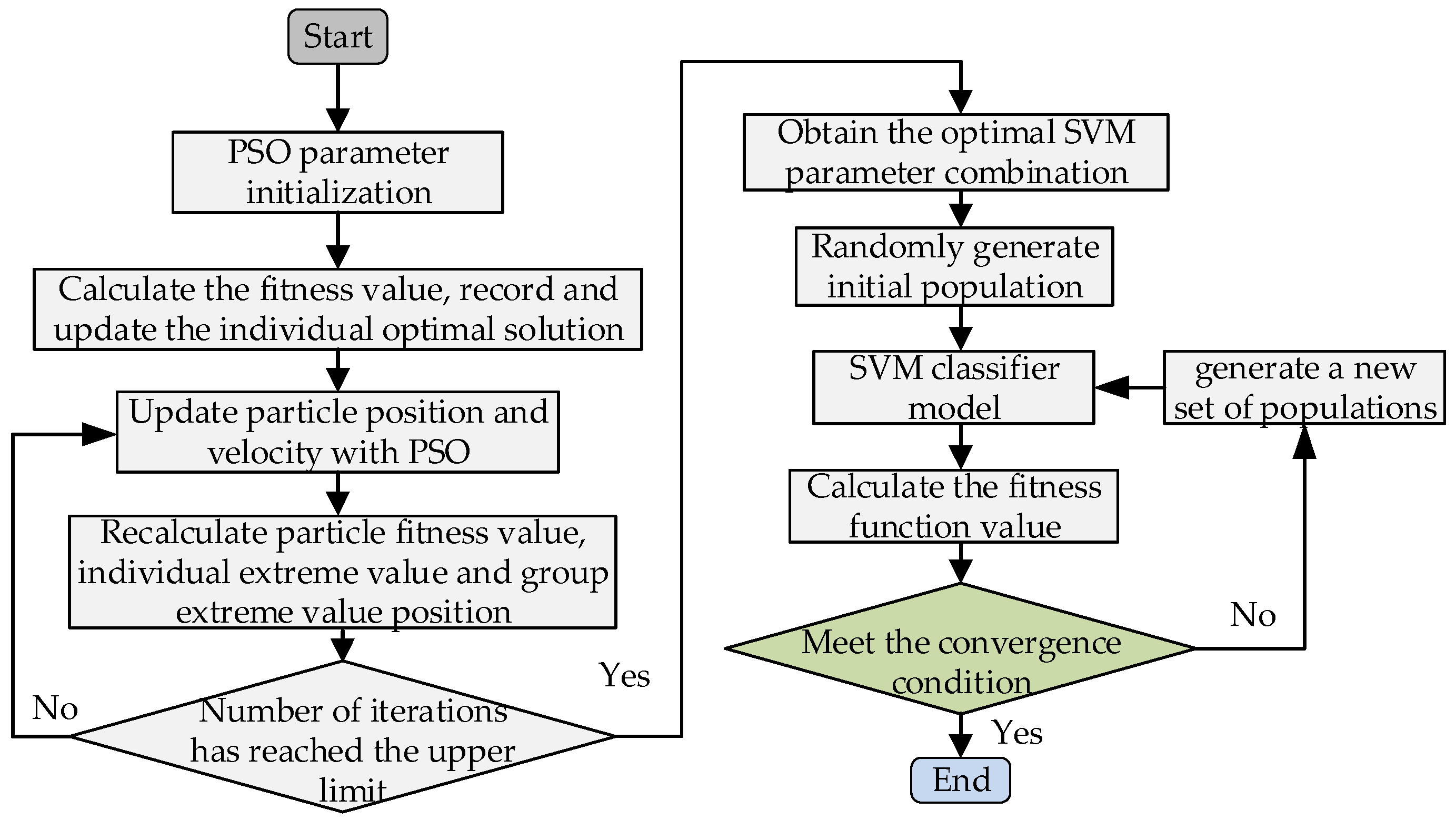
Figure 9 shows the particle swarm optimization metaclassifier SVM hyperparameter flowchart, which is implemented as follows:
First of all, the initialization stage of the PSO parameter sets the step size and upper and lower boundaries of the search parameters, and the local optimal solution of the particles, the global optimal solution of the particle swarm, and its corresponding position are obtained by calculating the fitness function, and the fitness function adopts the cross-validation scores (CVS) method, which is calculated as follows [
43]:
where
k is the number of cross-validations,
y represents the number of training samples,
yi is the number of training samples that are correctly divided, and the higher the CVS value, the higher the accuracy of the model.
Second, the velocity and position of the individual particle swarm are iteratively updated according to the local optimal and global optimal solutions, and the cycle is reached until the maximum number of iterations is reached.
Finally, the parameters corresponding to the global optimal particle swarm individuals obtained above are trained as the initial parameters of the SVM, and the fitness value of each particle is calculated by the k-fold cross-validation value method again. If the adaptability of the new position is better than that of the local optimal particle, the local optimal particle is replaced with the new particle. If the optimal particle in the population is superior to the global optimal particle, the global optimal particle is replaced by the best particle in the population. The global optimal parameter C and σ values are returned after the above is completed.
The above particle swarm algorithm optimizes the stacking ensemble learning model meta-classifier SVM hyperparameter, and the basic parameters of PSO setting are: acceleration factor
c1 and
c2 are both 2, inertia factor
ω = 1, the number of particle swarms is 20, and the maximum number of iterations is 50.
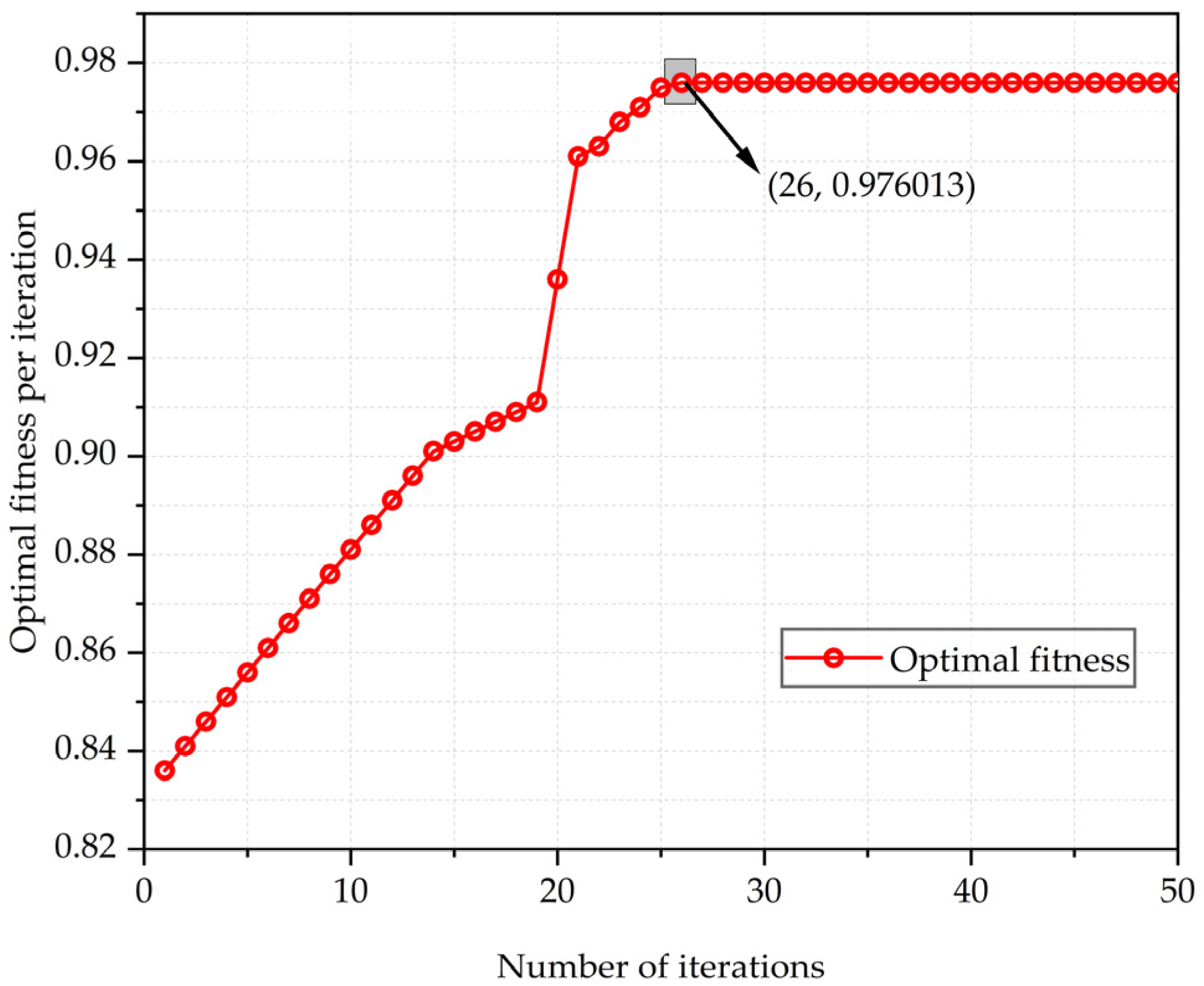
Figure 10 shows an evolutionary iteration plot that represents the resulting change in fitness values over different evolutionary algebras. As can be seen from
Figure 10, PSO optimizes the SVM process, the fitness value remains unchanged after 26 iterations, and the final optimal fitness value is 0.976013, at which time the optimal parameter combination of the trained SVM is
C = 21.375 and
σ = 1.43.
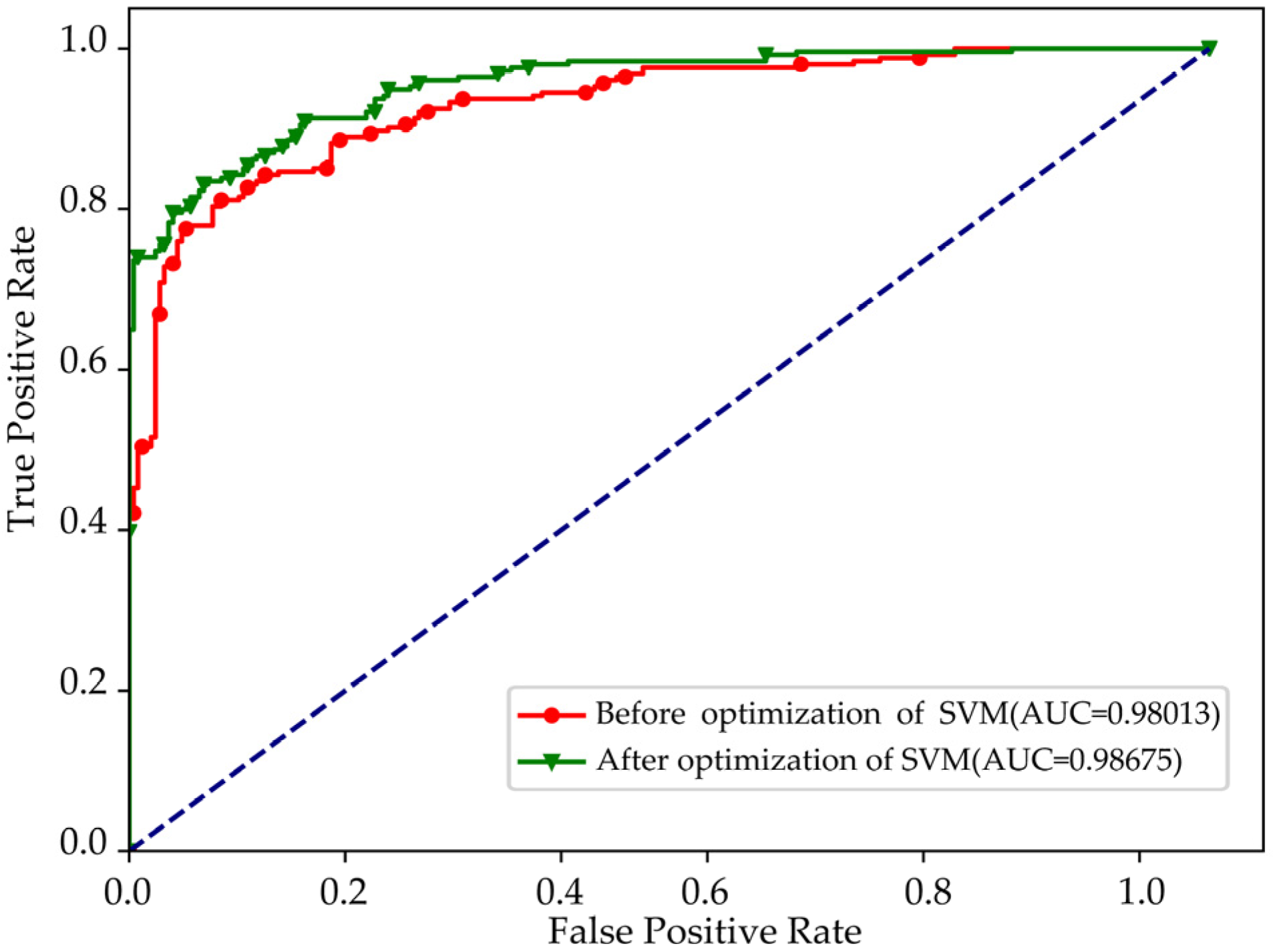
When the PSO optimization SVM obtains the best adaptability value, the AUC value is compared with the different effects before and after the optimization of the SVM parameters, as shown in
Figure 11, which is the ROC curve of the stacking integration learning model before and after optimization.
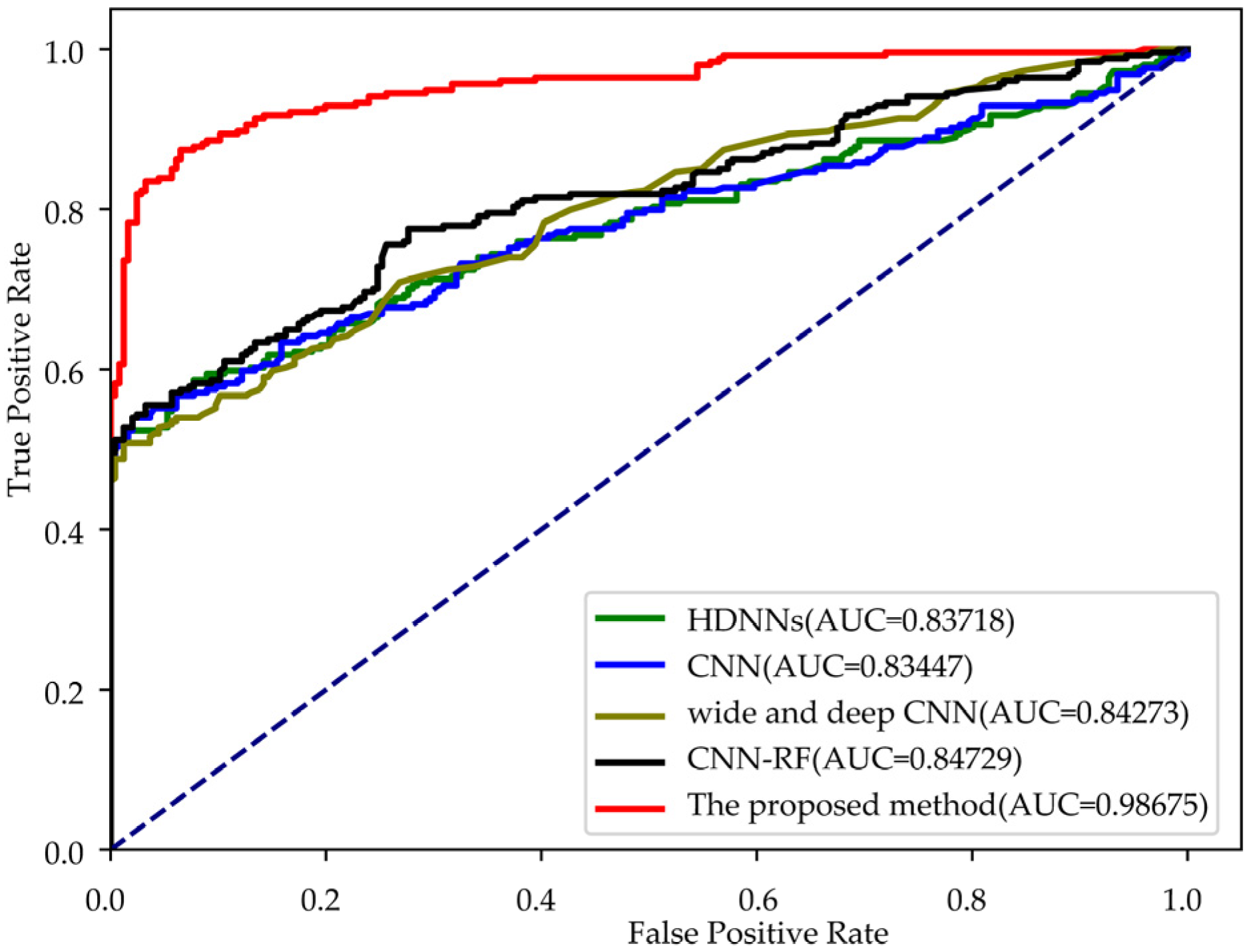
It can be clearly seen from the ROC curve that the AUC value before optimization is 0.98013, while that after optimization is 0. 98675, and the AUC value is increased by about 0.007, because the detection effect of the stacking integrated learning model is relatively satisfactory, and the room for improvement is effective. So, SVM can relatively effectively improve the overall performance of the algorithm.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}