
Ultra-Short-Term Wind Speed Forecasting Using the Hybrid Model of Subseries Reconstruction and Broad Learning System


Abstract
:1. Introduction
- (1)
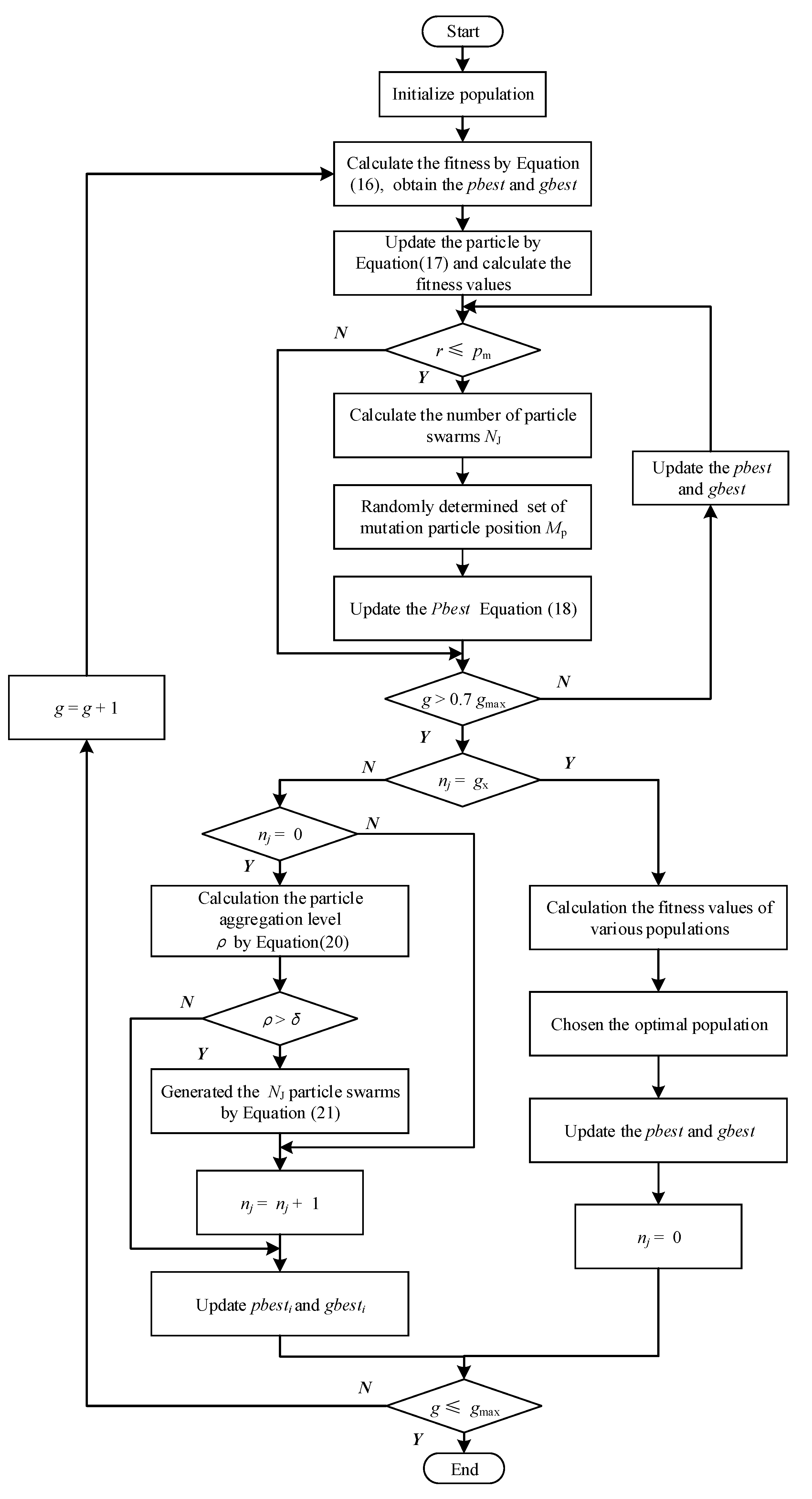
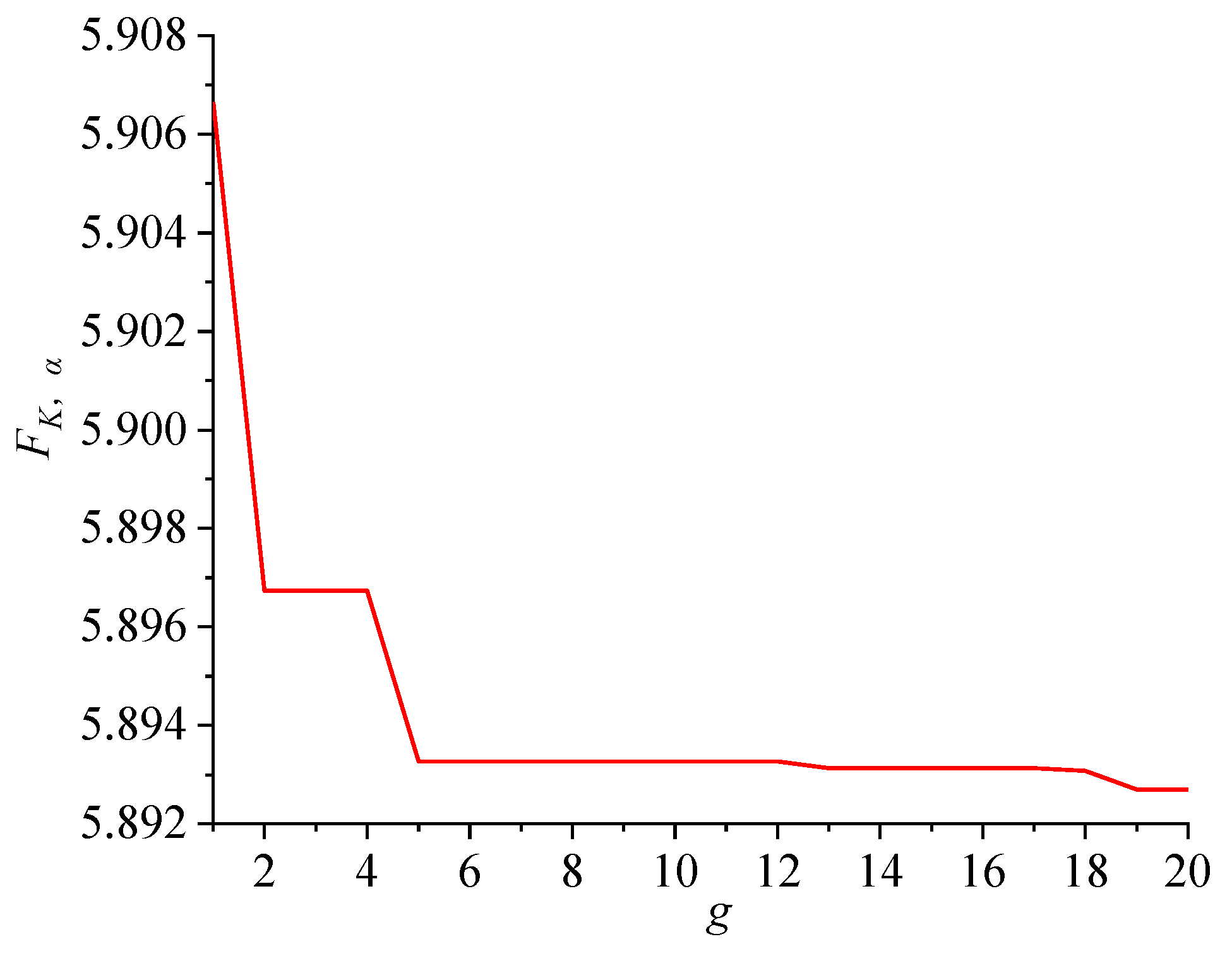
- In the proposed EVMD, the minimum mean envelope entropy (MMEE) and enhanced particle swarm optimization (EPSO) algorithm are introduced in order to solve the optimal value of K and α and improve the computational convergence.
- (2)
- SR is applied to recombine the subseries obtained by EVMD. The sample entropy (SE) is used to quantify the complexity of the subseries, which are then adaptively divided into new high-entropy and low-entropy subseries. The adjacent high-entropy subseries of approximate entropy values are merged to obtain a new group of reconstructed high-entropy subseries, while the low-entropy subseries are merged into a new subseries as well.
- (3)
- A novel and robust hybrid prediction model (EVMD-SR-BLS-ARIMA) is proposed and employed for ultra-short-term wind power forecasting. This avoids the time-consuming training of a deep structures model. This paper introduces BLS, which is time-efficient and constantly updates the parameters of the forecasting model, to ultra-short-term wind speed forecasting. The forecasting results of nascent high- and low-entropy subseries are calculated using the BLS and ARIMA models. In order to improve the forecasting accuracy, an error-corrected EVMD-SR-BLS-ARIMA model is developed to post-process the errors.
2. Related Work
2.1. Variational Mode Decomposition
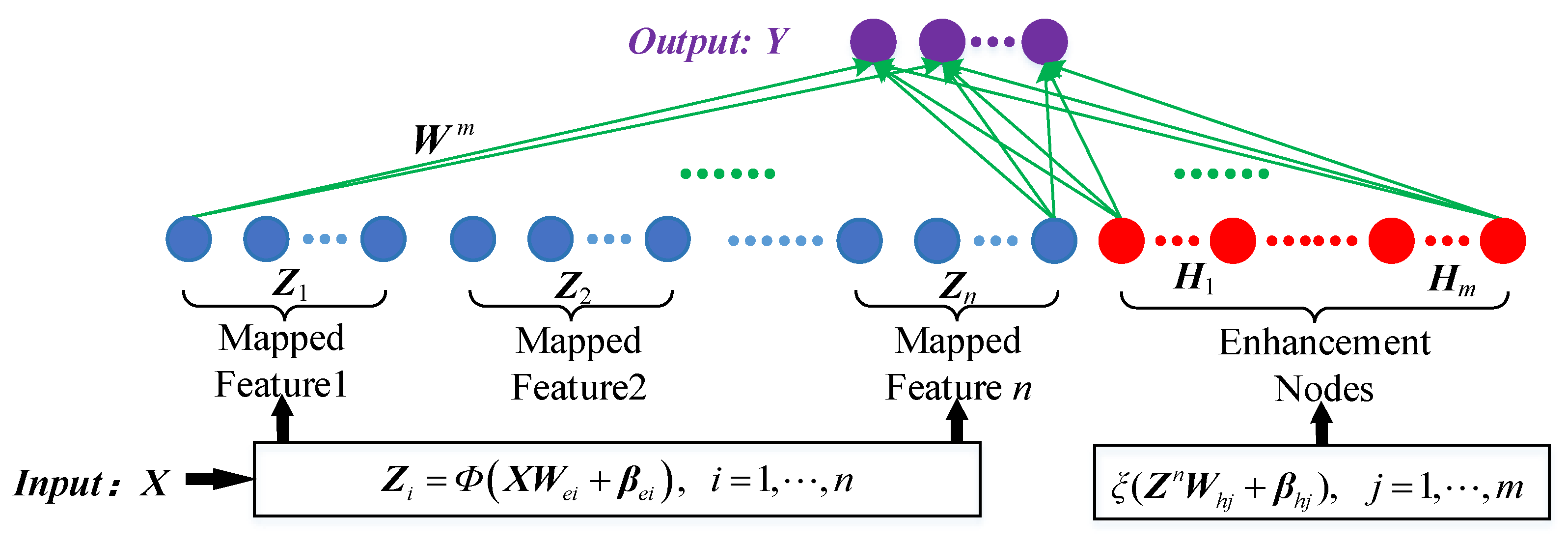
2.2. Broad Learning System
3. EVMD-SR-BLS-ARIMA Hybrid Wind Speed Forecasting Model
3.1. Improved Variational Mode Decomposition (EVMD)
3.2. Subseries Reconstruction Method (SR)
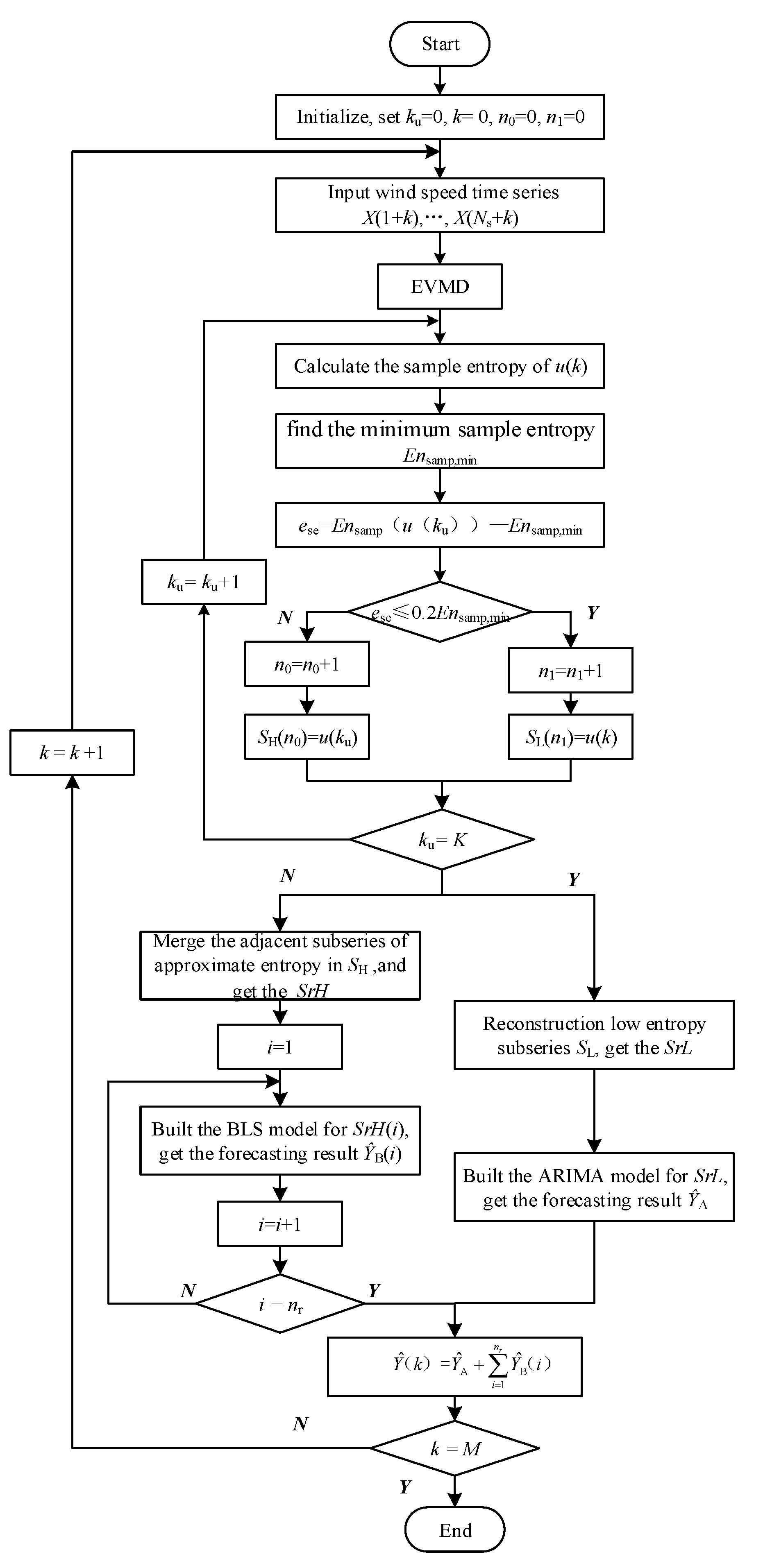
3.3. Hybrid Wind Speed Forecasting Framework
3.4. Evaluation Index
4. Case Study
4.1. Data Collection
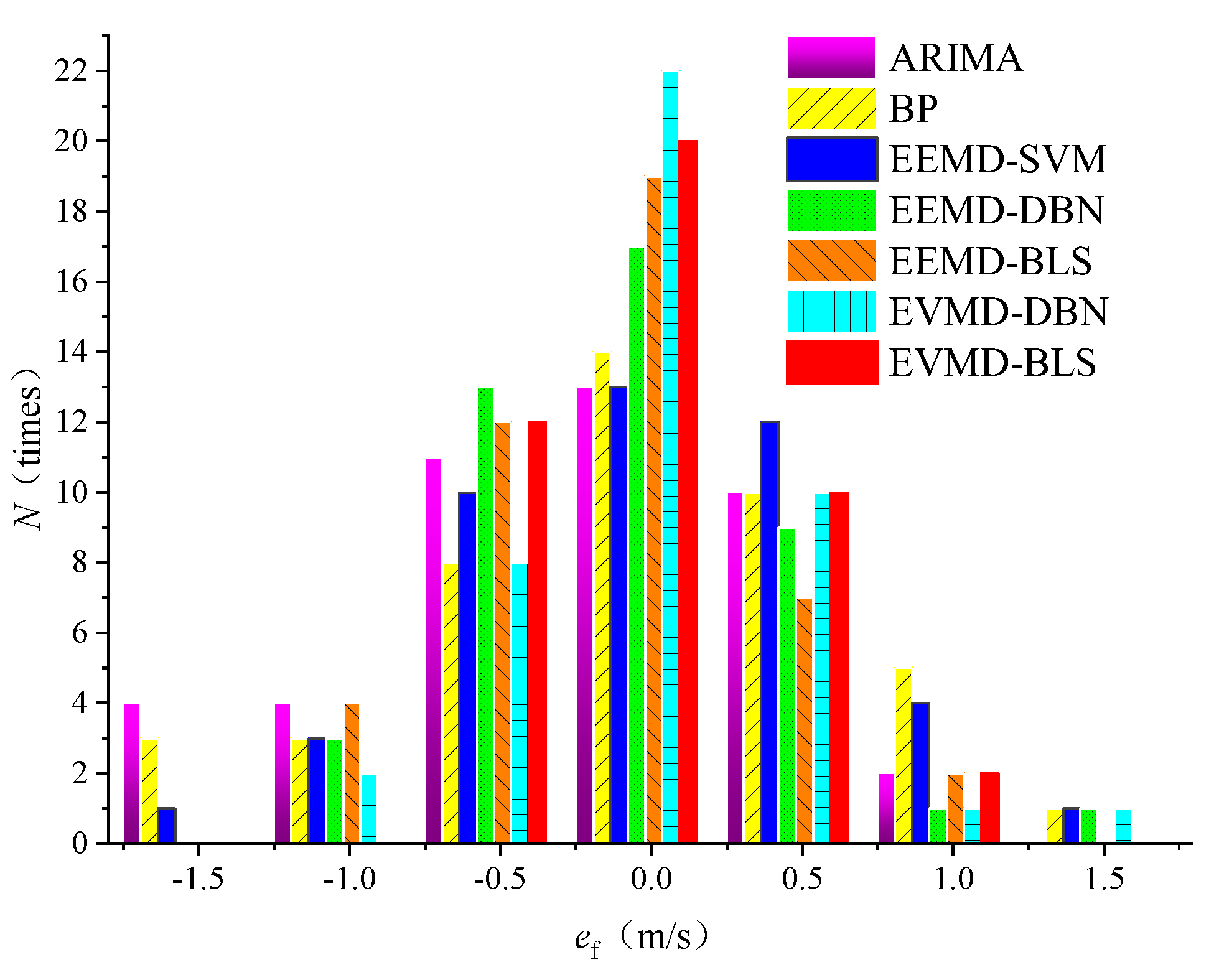
4.2. Experiment 1: EVMD-BLS Forecasting Model
4.3. Experiment 2: EVMD-SR-BLS-ARIMA Hybrid Forecasting Model
5. Conclusions
- EVMD was used to decompose the wind speed time series, while the minimum mean envelope entropy (MMEE) and enhanced particle swarm optimization (EPSO) algorithms were introduced to attain the optimal values of K and α of EVMD.
- SR was applied to recombine the subseries obtained by EVMD. The subseries of EVMD were adaptively divided into high-entropy and low-entropy subseries. Adjacent high-entropy subseries of approximate entropy values were merged to obtain a new group of reconstructed high-entropy subseries, and the low-entropy subseries were merged into a new subseries as well.
- The EVMD-SR-BLS-ARIMA hybrid wind speed forecasting model was constructed to obtain the reconstructed subseries forecasting results. Experimental results showed that the proposed method can significantly improve the forecasting accuracy and reduce the time required.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Liu, H.; Chen, C. Data Processing Strategies in Wind Energy Forecasting Models and Applications: A Comprehensive Review. Appl. Energy 2019, 249, 392–408. [Google Scholar] [CrossRef]
- Zuo, H.; Bi, K.; Hao, H. A State-of-the-Art Review on the Vibration Mitigation of Wind Turbines. Renew. Sustain. Energy Rev. 2020, 121, 109710. [Google Scholar] [CrossRef]
- Tascikaraoglu, A.; Uzunoglu, M. A Review of Combined Approaches for Prediction of Short-Term Wind Speed and Power. Renew. Sustain. Energy Rev. 2014, 34, 243–254. [Google Scholar] [CrossRef]
- Okumus, I.; Dinler, A. Current Status of Wind Energy Forecasting and a Hybrid Method for Hourly Predictions. Energ. Convers. Manag. 2016, 123, 362–371. [Google Scholar] [CrossRef]
- Tascikaraoglu, A.; Sanandaji, B.M.; Poolla, K.; Varaiya, P. Exploiting Sparsity of Interconnections in Spatio-Temporal Wind Speed Forecasting Using Wavelet Transform. Appl. Energy 2016, 165, 735–747. [Google Scholar] [CrossRef] [Green Version]
- Wang, H.Z.; Wang, G.B.; Li, G.Q.; Peng, J.C.; Liu, Y.T. Deep Belief Network Based Deterministic and Probabilistic Wind Speed Forecasting Approach. Appl. Energy 2016, 182, 80–93. [Google Scholar] [CrossRef]
- Liu, H.; Tian, H.; Li, Y. An Emd-Recursive Arima Method to Predict Wind Speed for Railway Strong Wind Warning System. J. Wind Eng. Ind. Aerod. 2015, 141, 27–38. [Google Scholar] [CrossRef]
- An, N.; Zhao, W.; Wang, J.; Shang, D.; Zhao, E. Using Multi-Output Feedforward Neural Network with Empirical Mode Decomposition Based Signal Filtering for Electricity Demand Forecasting. Energy 2013, 49, 279–288. [Google Scholar] [CrossRef]
- Huang, Y.; Yang, L.; Liu, S.; Wang, G. Multi-Step Wind Speed Forecasting Based on Ensemble Empirical Mode Decomposition, Long Short Term Memory Network and Error Correction Strategy. Energies 2019, 12, 1822. [Google Scholar] [CrossRef] [Green Version]
- Sun, B.; Yao, H. Short-Term Wind Speed Forecasting Based on Local Mean Decomposition and Multi-Kernel Support Vector Machine. Acta Energ. Solaris Sin. 2013, 34, 1567–1573. [Google Scholar]
- Dragomiretskiy, K.; Zosso, D. Variational Mode Decomposition. IEEE Trans. Signal. Process 2014, 62, 531–544. [Google Scholar] [CrossRef]
- Sun, W.; Gao, Q. Short-Term Wind Speed Prediction Based on Variational Mode Decomposition and Linear–Nonlinear Combination Optimization Model. Energies 2019, 12, 2322. [Google Scholar] [CrossRef] [Green Version]
- Han, L.; Zhang, R.; Wang, X.; Bao, A.; Jing, H. Multi-Step Wind Power Forecast Based on Vmd-Lstm. Iet Renew. Power Gen. 2019, 13, 1690–1700. [Google Scholar] [CrossRef]
- Zhu, L.; Lian, C. Wind Speed Forecasting Based on a Hybrid Emd-Bls Method; Institute of Electrical and Electronics Engineers Inc.: Hangzhou, China, 2019; pp. 2191–2195. [Google Scholar]
- Zhu, L.; Lian, C.; Zeng, Z.; Su, Y. A Broad Learning System with Ensemble and Classification Methods for Multi-Step-Ahead Wind Speed Prediction. Cogn. Comput. 2020, 12, 654–666. [Google Scholar] [CrossRef]
- Bai, Y.; Liu, M.; Ding, L.; Ma, Y. Double-Layer Staged Training Echo-State Networks for Wind Speed Prediction Using Variational Mode Decomposition. Appl. Energy 2021, 301, 117461. [Google Scholar] [CrossRef]
- Chen, C.L.P.; Liu, Z. Broad Learning System: An Effective and Efficient Incremental Learning System without the Need for Deep Architecture. IEEE Trans Neur. Net. Learn. 2018, 29, 10–24. [Google Scholar] [CrossRef] [PubMed]
- Zhang, G.; Liu, H.; Zhang, J.; Yan, Y.; Zhang, L.; Wu, C.; Hua, X.; Wang, Y. Wind Power Prediction Based on Variational Mode Decomposition Multi-Frequency Combinations. J. Mod. Power Syst. Clean 2019, 7, 281–288. [Google Scholar] [CrossRef] [Green Version]
- Tang, G.; Wang, X. Parameter Optimized Variational Mode Decomposition Method with Applicaltion to Incipient Fault Diagnosis of Rolling Bearing. J. Xi’an Jiaotang Univ. 2015, 49, 73–81. [Google Scholar]
- Ramadan, H.S.; Bendary, A.F.; Nagy, S. Particle Swarm Optimization Algorithm for Capacitor Allocation Problem in Distribution Systems with Wind Turbine Generators. Int. J. Electr. Power Energy Syst. 2017, 84, 143–152. [Google Scholar] [CrossRef]
- Alcaraz, R.; Rieta, J.J. A Review on Sample Entropy Applications for the Non-Invasive Analysis of Atrial Fibrillation Electrocardiograms. Biomed. Signal. Proces. 2010, 5, 1–14. [Google Scholar] [CrossRef]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Np | wmin | wmax | c1 | c2 | pm,min | pm,max |
|---|---|---|---|---|---|---|---|
| Value | 30 | 0.4 | 0.9 | 1.497 | 1.497 | 0.1 | 0.6 |
| Model | δRMSE (m/s) | δMAE (m/s) | δsMAPE (%) | t (s) |
|---|---|---|---|---|
| ARIMA | 0.64 | 0.54 | 12.19 | 91.07 |
| BP | 0.68 | 0.53 | 12.77 | 101.85 |
| EEMD-SVM | 0.62 | 0.48 | 12.24 | 226.43 |
| EEMD-DBN | 0.46 | 0.37 | 9.49 | 478.99 |
| EEMD-BLS | 0.49 | 0.37 | 9.20 | 203.01 |
| EVMD-DBN | 0.46 | 0.34 | 8.85 | 235.92 |
| EVMD-BLS | 0.38 | 0.31 | 7.85 | 190.45 |
| BP | EEMD-SVM | EEMD-DBN | EEMD-BLS | EVMD-DBN | EVMD-BLS | ||
|---|---|---|---|---|---|---|---|
| p-value | ARIMA | 0.647 | 0.597 | 0.018 | 0.03 | 0.015 | 0.003 |
| BP | / | 0.476 | 0.015 | 0.036 | 0.007 | 0.003 | |
| EEMD-SVM | / | / | 0.107 | 0.17 | 0.102 | 0.021 | |
| EEMD-DBN | / | / | / | 0.445 | 0.986 | 0.014 | |
| EEMD-BLS | / | / | / | / | 0.559 | 0.034 | |
| EVMD-DBN | / | / | / | / | / | 0.088 | |
| DM-value | ARIMA | −0.461 | 0.533 | 2.467 | 2.239 | 2.524 | 3.195 |
| BP | / | 0.719 | 2.547 | 2.167 | 2.807 | 3.195 | |
| EEMD-SVM | / | / | 1.646 | 1.397 | 1.67 | 2.389 | |
| EEMD-DBN | / | / | / | −0.771 | −0.017 | 2.565 | |
| EEMD-BLS | / | / | / | / | 0.589 | 2.191 | |
| EVMD-DBN | / | / | / | / | / | 1.744 |
| Model | δRMSE (m/s) | δMAE (m/s) | δsMAPE (%) | t (s) |
|---|---|---|---|---|
| EVMD-SR-BLS-ARIMA | 0.45 | 0.32 | 8.25 | 126.94 |
| Error-corrected EVMD-SR-BLS-ARIMA | 0.34 | 0.30 | 7.99 | 172.67 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pang, M.; Zhang, L.; Zhang, Y.; Zhou, A.; Dou, J.; Deng, Z. Ultra-Short-Term Wind Speed Forecasting Using the Hybrid Model of Subseries Reconstruction and Broad Learning System. Energies 2022, 15, 4492. https://doi.org/10.3390/en15124492
Pang M, Zhang L, Zhang Y, Zhou A, Dou J, Deng Z. Ultra-Short-Term Wind Speed Forecasting Using the Hybrid Model of Subseries Reconstruction and Broad Learning System. Energies. 2022; 15(12):4492. https://doi.org/10.3390/en15124492
Chicago/Turabian StylePang, Ming, Lei Zhang, Yajun Zhang, Ao Zhou, Jianming Dou, and Zhepeng Deng. 2022. "Ultra-Short-Term Wind Speed Forecasting Using the Hybrid Model of Subseries Reconstruction and Broad Learning System" Energies 15, no. 12: 4492. https://doi.org/10.3390/en15124492