
Electricity Consumption Forecast of High-Rise Office Buildings Based on the Long Short-Term Memory Method



Abstract
:1. Introduction
2. Data Analysis Methodology
2.1. Research Route
2.2. Data Description
2.3. Data Processing
2.3.1. Data Cleaning
2.3.2. Data Analysis
2.3.3. Correlation Analysis
2.4. LSTM Algorithm
- (1)
- ‘Forget’ stage. Here, the input of the previous node is selectively ‘forgotten’. This stage controls the information from the previous state that needs to be retained and the previous state that needs to be forgotten.
- (2)
- ‘Storage’ stage. Here, the inputs of this stage are selectively ‘remembered’. Based on the results of previous calculations, this stage selectively stores and inputs the current amount of information.
- (3)
- ‘Output’ stage. This stage determines the output of the current state. At this stage, the results obtained in the previous stage are scaled (changed by the tanh activation function) and the amount of current information flowing into the subsequent network is controlled. The results obtained in the first and second steps for transmission are added to the next network. This is the first formula shown in the figure above.
3. Results
3.1. Correlation Analysis of Auxiliary Variables
3.1.1. Correlation Analysis
3.1.2. Meteorological Parameters
3.1.3. Schedule Parameters
3.2. Model Description
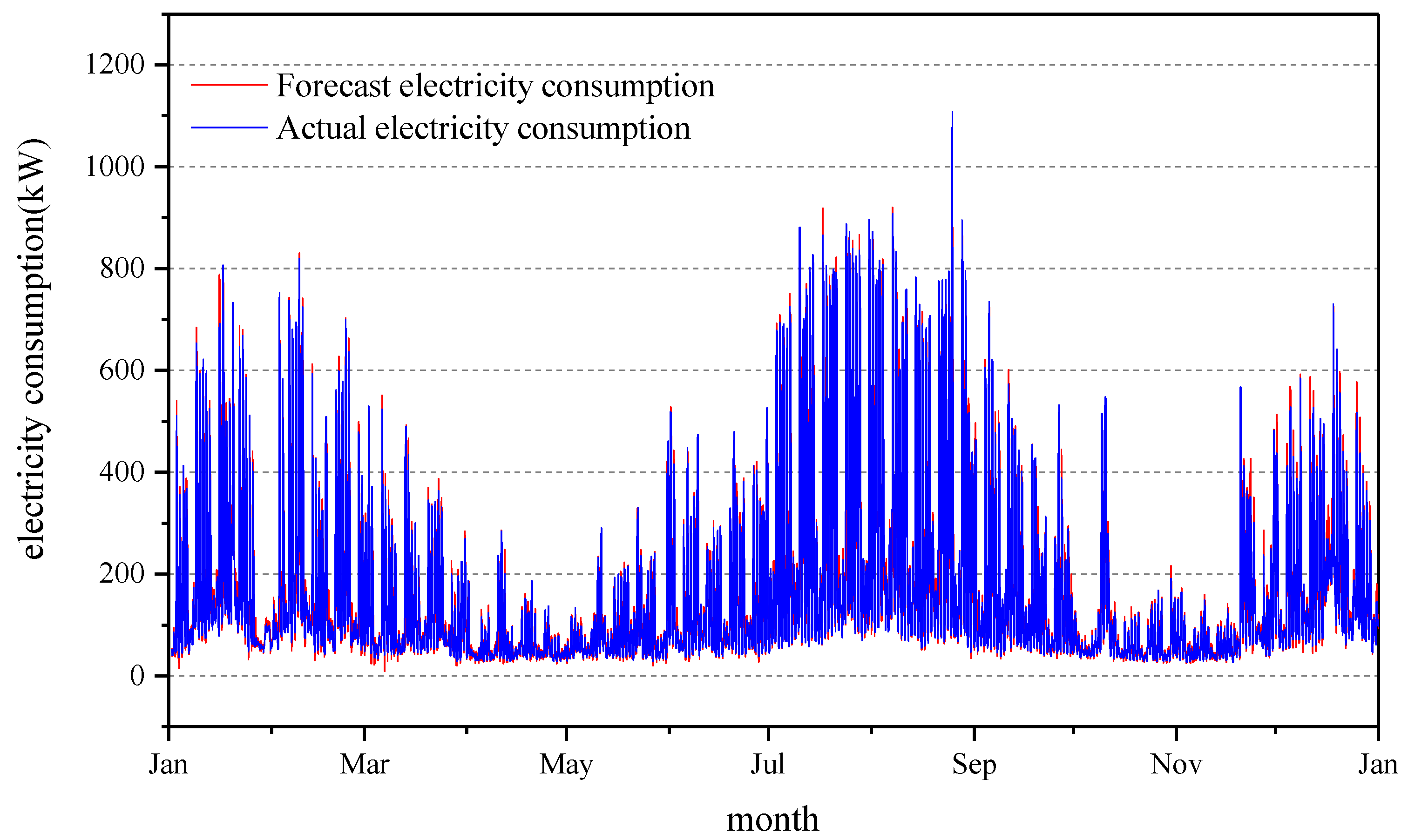
3.3. Forecast Results Analysis
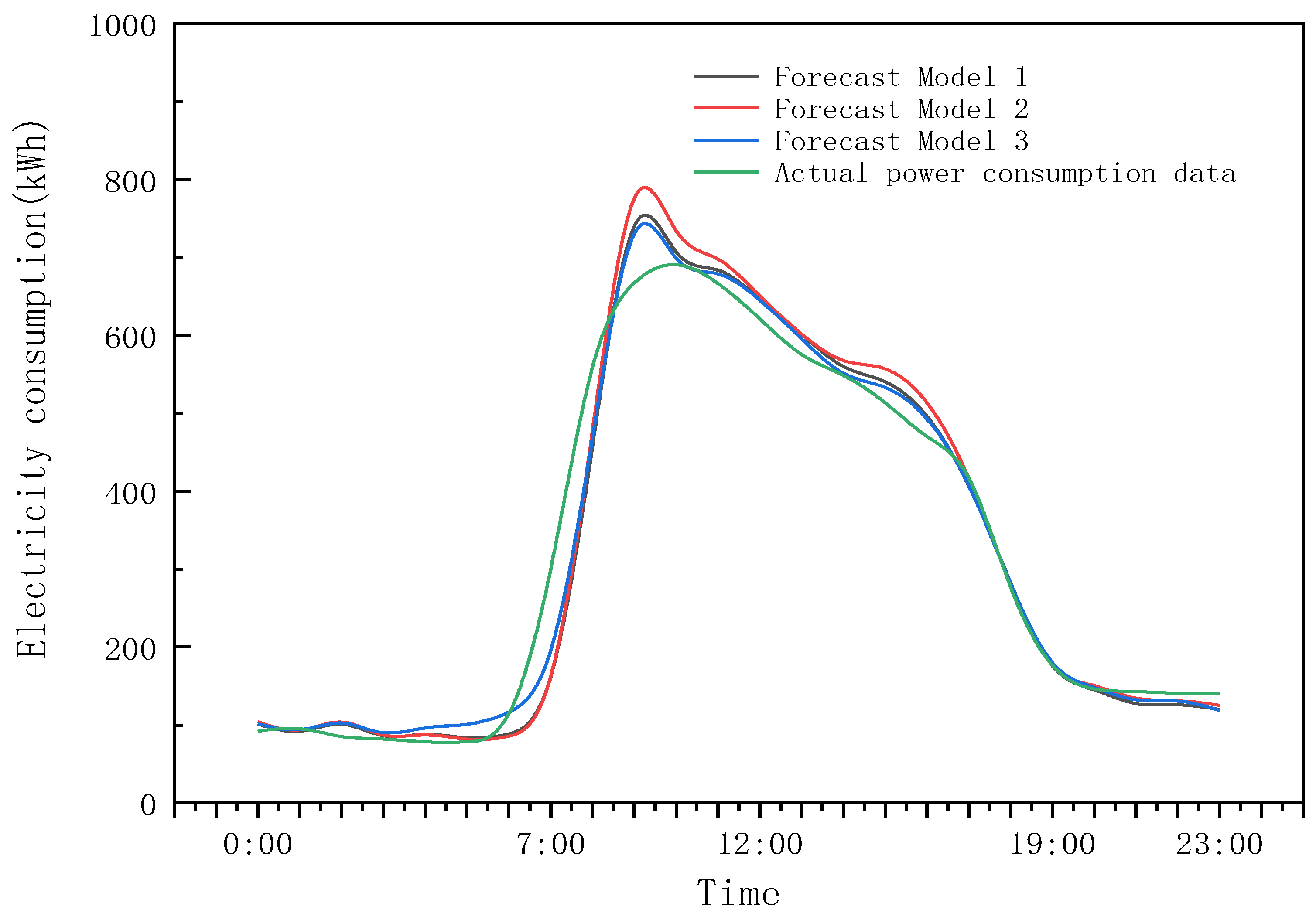
3.3.1. Model Comparison of Hourly Energy Consumption Prediction
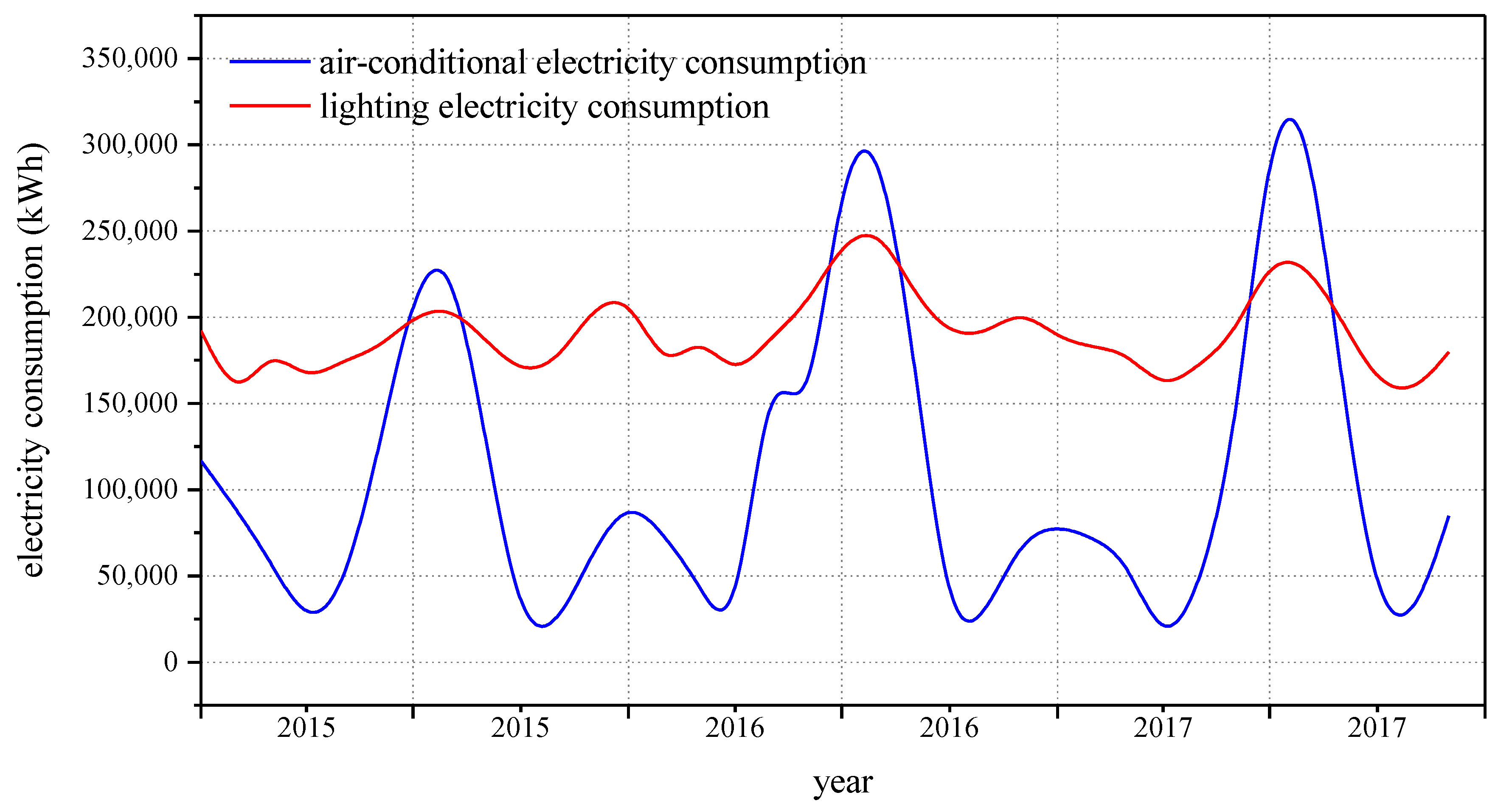
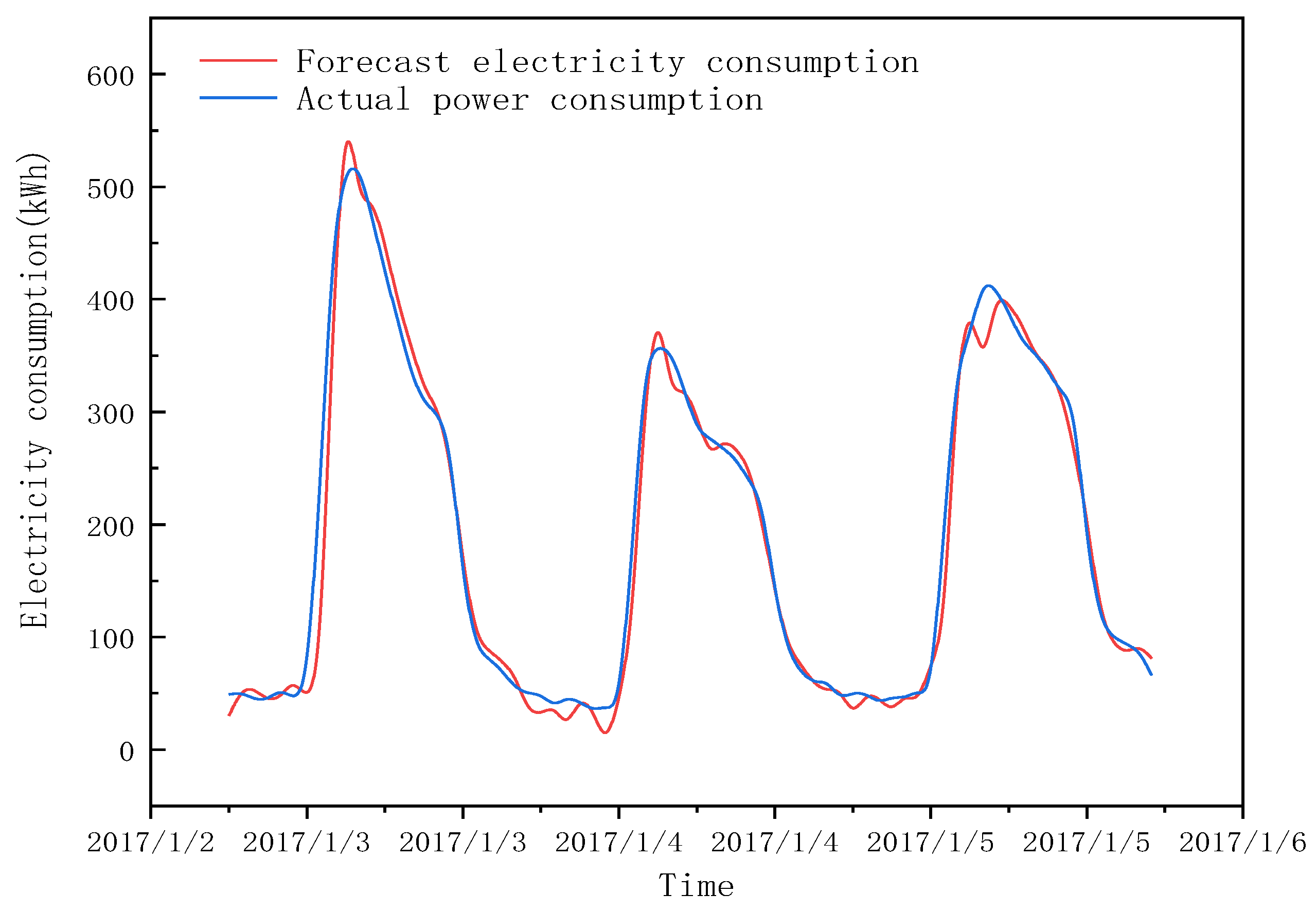
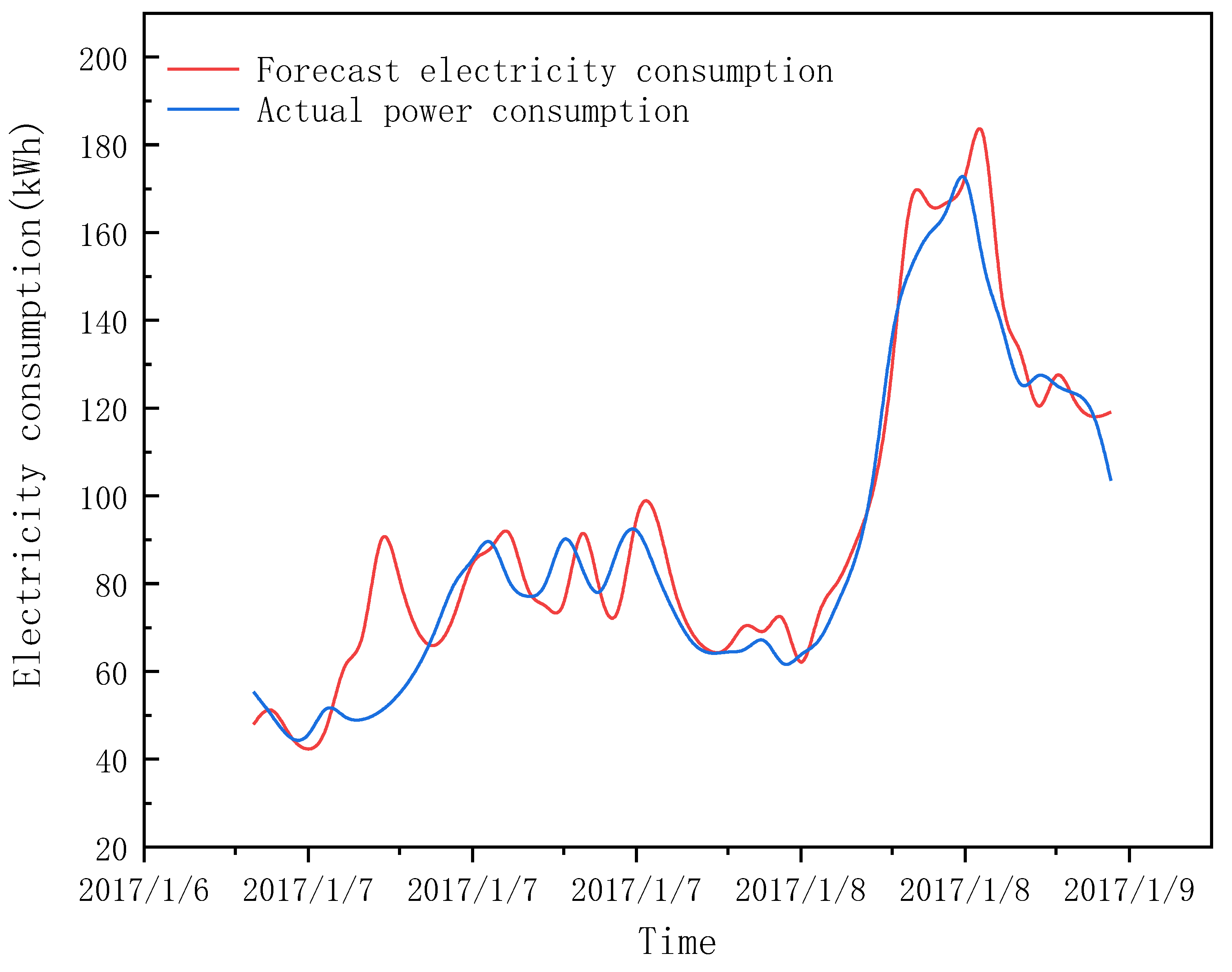
3.3.2. Air-Conditioning Electricity Consumption Forecast
3.3.3. Validation of Air-Conditioning Electricity Consumption Prediction Model
3.3.4. Lighting Electricity Consumption Forecast
4. Limitations
- (1)
- This study only used the LSTM algorithm for the long-term energy consumption prediction of office building air conditioning. Due to the limitations of article length, methods other than the ARIMA and BP algorithms were not compared with the LSTM method. Whether LSTM is the best method for long-term energy consumption prediction in office buildings remains to be verified.
- (2)
- The research results of this study are limited to the prediction of office buildings in Shanghai. Whether it can be widely used in office buildings remains to be verified. The prediction model, in this case, was tested on a high-rise office building and the algorithm was not suitable for low-rise office buildings. Owing to the deviation of the prediction model, this study did not show the prediction results of low-rise office buildings. It can be seen from this that using the LSTM algorithm for long-term air-conditioning power consumption forecast has a certain scope of application.
- (3)
- Among the input variables considered in this study, only meteorological parameters and schedule parameters are considered, and other parameters that affect building air conditioning energy consumption, such as building maintenance structural parameters and the amount of fresh air entering the building, are not considered. Whether the inclusion of other input variables affects the accuracy of predictions, requires further investigation.
5. Conclusions
- (1)
- It is feasible to use the LSTM method to train the hourly electricity consumption data of the first two years to predict the hourly electricity consumption data of the office building in the next year, and the model has better prediction accuracy. However, the prediction accuracy of the model for air-conditioning electricity consumption is not so high, and the error of the prediction mainly appears in the morning from 7:00 to 8:00 on weekdays.
- (2)
- To further improve the air-conditioning prediction accuracy, we considered adding three other variables for model verification. When the dry bulb temperature is added as an input variable for prediction, the prediction accuracy decreases. This may be because the power consumption of the air conditioner is also affected by the building envelope; thus, the temperature has no direct influence on the power consumption of the air conditioner. When adding the “schedule” and “relative humidity” as input variables for prediction, the prediction accuracy can be slightly improved. This conclusion can be applied to other office buildings.
- (3)
- The increase in the accuracy of forecasting with the addition of other variables is mainly due to the improvement of the forecasting accuracy at the beginning of working hours (7 a.m.–8 a.m.) on weekdays, not the improvement of the accuracy of peak load forecasting.
- (4)
- Using the LSTM model, the prediction of lighting power consumption is very accurate, and only using historical power consumption data can well predict the lighting power consumption of buildings.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
Nomenclature
| Abbreviations | |
| ANN | Artificial neural network |
| ARIMA | Auto regressive integrated moving Average model |
| COR | Correlation coefficient |
| CV-RMSE | Coefficient of variation of the root mean square error |
| HVAC | Heating, ventilation and air conditioning systems |
| LSTM | Long Short-Term Memory |
| KNN | k-nearest neighbors |
| MAE | Mean absolute error |
| MSE | Mean square error |
| NA | Not available |
| PCC | Pearson correlation coefficient |
| SCC | Spearman correlation coefficient |
| SVM | Support vector machine |
| RNN | Recurrent Neural Networks |
| Superscripts/Subscripts | |
| b | Bias of LSTM |
| ct | Cell input received by the previous node |
| ht | Hidden layer input received by the previous node |
| P | Pressure |
| RH | Relative humidity |
| Ta | Dry bulb temperature |
| Td | Wet bulb temperature |
| W | Weight of LSTM |
| WS | Wind speed |
| xt | Data input in the current state |
| yt | Data output in the current state |
| Y(k) | Actual value |
| Yp(k) | Predicted value |
| Average value | |
| Z | Gate control signal converted by tanh activation function |
| Zi | ‘Memory’ gate control |
| Zf | ‘Forget’ gate control |
| Zo | ‘Output’ gate control |
References
- Lund, H.; Mathiesen, B.V. Energy system analysis of 100% renewable energy systems—The case of Denmark in years 2030 and 2050. Energy 2009, 34, 524–531. [Google Scholar] [CrossRef]
- Mendizabal, M.; Heidrich, O.; Feliu, E.; García-Blanco, G.; Mendizabal, A. Stimulating urban transition and transformation to achieve sustainable and resilient cities. Renew. Sustain. Energy Rev. 2018, 94, 410–418. [Google Scholar] [CrossRef]
- Wei, Y.; Zhang, X.; Shi, Y.; Xia, L.; Pan, S.; Wu, J.; Han, M.; Zhao, X. A review of data-driven approaches for prediction and classification of building energy consumption. Renew. Sustain. Energy Rev. 2018, 82, 1027–1047. [Google Scholar] [CrossRef]
- Moradi, M.; Dyer, B.; Nazem, A.; Nambiar, M.K.; Nahian, M.R.; Bueno, B.; Mackey, C.; Vasanthakumar, S.; Nazarian, N.; Krayenhoff, E.S.; et al. The Vertical City Weather Generator (VCWG v1.3.2). Geosci. Model Dev. 2021, 14, 961–984. [Google Scholar] [CrossRef]
- Zhang, L.; Wen, J.; Li, Y.; Chen, J.; Ye, Y.; Fu, Y.; Livingood, W. A review of machine learning in building load prediction. Appl. Energy 2021, 285, 116452. [Google Scholar] [CrossRef]
- Aliabadi, A.A.; Moradi, M.; McLeod, R.M.; Calder, D.; Dernovsek, R. How Much Building Renewable Energy Is Enough? The Vertical City Weather Generator (VCWG v1.4.4). Atmosphere 2021, 12, 882. [Google Scholar] [CrossRef]
- Ahmad, M.I. Seasonal Decomposition of Electricity Consumption Data. Rev. Integr. Bus Econ. Res. 2017, 6, 271–275. [Google Scholar]
- Li, X.; Wen, J. Review of building energy modeling for control and operation. Renew. Sustain. Energy Rev. 2014, 37, 517–537. [Google Scholar] [CrossRef]
- Fumo, N. A review on the basics of building energy estimation. Renew. Sustain. Energy Rev. 2014, 31, 53–60. [Google Scholar] [CrossRef]
- Pan, S.; Wang, X.; Wei, Y.; Zhang, X.; Gal, C.; Ren, G.; Yan, D.; Shi, Y.; Wu, J.; Xia, L.; et al. Cluster analysis for schedule based electricity load patterns in buildings: A case study in Shanghai residences. Build. Simul. 2017, 10, 889–898. [Google Scholar] [CrossRef]
- Niu, F.; O’Neill, Z.; O’Neill, C. Data-driven based estimation of HVAC energy consumption using an improved Fourier series decomposition in buildings. Build. Simul. 2018, 11, 633–645. [Google Scholar] [CrossRef]
- De Nadai, M.; Van Someren, M. Short-term anomaly detection in gas consumption through ARIMA and Artificial Neural Network forecast. In Proceedings of the 2015 IEEE Workshop on Environmental, Energy, and Structural Monitoring Systems (EESMS 2015), Trento, Italy, 9–10 July 2015; pp. 250–255. [Google Scholar] [CrossRef]
- Wang, J.Q.; Du, Y.; Wang, J. LSTM based long-term energy consumption prediction with periodicity. Energy 2020, 197, 117197. [Google Scholar] [CrossRef]
- Valgaev, O. Building Power Demand Forecasting Using K-Nearest Neighbors Model—Initial Approach. In Proceedings of the 2016 IEEE PES Asia-Pacific Power and Energy Engineering Conference (APPEEC), Xi’an, China, 25–28 October 2016; pp. 1055–1060. [Google Scholar]
- Li, Z.; Dai, J.; Chen, H.; Lin, B. An ANN-based fast building energy consumption prediction method for complex architectural form at the early design stage. Build. Simul. 2019, 12, 665–681. [Google Scholar] [CrossRef]
- Ferlito, S.; Atrigna, M.; Graditi, G.; De Vito, S.; Salvato, M.; Buonanno, A.; Di Francia, G. Predictive models for building’s energy consumption: An Artificial Neural Network (ANN) approach. In Proceedings of the 2015 Xviii Aisem Annual Conference, Trento, Italy, 3–5 February 2015; pp. 3–6. [Google Scholar]
- Ahmad, A.S.; Hassan, M.Y.; Abdullah, M.P.; Rahman, H.A.; Hussin, F.; Abdullah, H.; Saidur, R. A review on applications of ANN and SVM for building electrical energy consumption forecasting. Renew. Sustain. Energy Rev. 2014, 33, 102–109. [Google Scholar] [CrossRef]
- Zhao, H.X.; Magoulès, F. A review on the prediction of building energy consumption. Renew. Sustain. Energy Rev. 2012, 16, 3586–3592. [Google Scholar] [CrossRef]
- Dong, B.; Cao, C.; Eang, S. Applying support vector machines to predict building energy consumption in tropical region. Energy Build. 2005, 37, 545–553. [Google Scholar] [CrossRef]
- Wang, Z.; Hong, T.; Piette, M.A. Building thermal load prediction through shallow machine learning and deep learning. Appl. Energy 2020, 263, 114683. [Google Scholar] [CrossRef] [Green Version]
- Salehinejad, H.; Sankar, S.; Barfett, J.; Colak, E.; Valaee, S. Recent Advances in Recurrent Neural Networks. arXiv 2017, arXiv:1801.01078. [Google Scholar]
- Fan, C.; Xiao, F.; Zhao, Y. A short-term building cooling load prediction method using deep learning algorithms. Appl. Energy 2017, 195, 222–233. [Google Scholar] [CrossRef]
- Sendra-Arranz, R.; Gutiérrez, A. A long short-term memory artificial neural network to predict daily HVAC consumption in buildings. Energy Build. 2020, 216, 109952. [Google Scholar] [CrossRef]
- Zhou, C.; Fang, Z.; Xu, X.; Zhang, X.; Ding, Y.; Jiang, X. Using long short-term memory networks to predict energy consumption of air-conditioning systems. Sustain. Cities Soc. 2020, 55, 102000. [Google Scholar] [CrossRef]
- Satre-Meloy, A.; Diakonova, M.; Grünewald, P. Cluster analysis and prediction of residential peak demand profiles using occupant activity data. Appl. Energy 2020, 260, 114246. [Google Scholar] [CrossRef]
- Dutilleul, P.; Stockwell, J.D.; Frigon, D.; Legendre, P. The Mantel test versus Pearson’s correlation analysis: Assessment of the differences for biological and environmental studies. J. Agric. Biol. Environ. Stat. 2000, 5, 131–150. [Google Scholar] [CrossRef]
- Adhianto, L.; Banerjee, S.; Fagan, M.; Krentel, M.; Marin, G.; Mellor-Crummey, J.; Tallent, N.R. HPCTOOLKIT: Tools for performance analysis of optimized parallel programs. Concurr. Comput. Pract. Exp. 2010, 22, 685–701. [Google Scholar] [CrossRef]
- Kim, T.Y.; Cho, S.B. Predicting residential energy consumption using CNN-LSTM neural networks. Energy 2019, 182, 72–81. [Google Scholar] [CrossRef]
- Wangpattarapong, K.; Maneewan, S.; Ketjoy, N.; Rakwichian, W. The impacts of climatic and economic factors on residential electricity consumption of Bangkok Metropolis. Energy Build. 2008, 40, 1419–1425. [Google Scholar] [CrossRef]
- Peng, L.; Liu, S.; Liu, R.; Wang, L. Effective long short-term memory with differential evolution algorithm for electricity price prediction. Energy 2018, 162, 1301–1314. [Google Scholar] [CrossRef]
- Huang, L.; Wang, J. Global crude oil price prediction and synchronization based accuracy evaluation using random wavelet neural network. Energy 2018, 151, 875–888. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Correlation Coefficient | Electricity Consumption | Humidity | Dry-Bulb Temperature | Wet-Bulb Temperature | Pressure | Schedule Parameter |
|---|---|---|---|---|---|---|
| electricity consumption | 1.000 | |||||
| humidity | −0.301 | 1.000 | ||||
| dry-bulb temperature | 0.171 | −0.040 | 1.000 | |||
| wet-bulb temperature | 0.074 | 0.355 | 0.900 | 1.000 | ||
| pressure | −0.059 | −0.223 | −0.855 | −0.876 | 1.000 | |
| schedule parameter | 0.365 | −0.008 | −0.006 | −0.004 | −0.004 | 1.000 |
| Evaluation Index | MSE | MAE | CV-RMSE |
|---|---|---|---|
| LSTM | 618.40 | 15.34 | 0.147 |
| ARIMA | 650.51 | 21.73 | 0.183 |
| BP | 721.36 | 35.32 | 0.276 |
| Experiments | Index | 0 | 1 | 2 | 3 | 1&2 | 1&3 | 2&3 | 1&2&3 |
|---|---|---|---|---|---|---|---|---|---|
| a | MSE | 618.4007 | 639.2804 | 611.8292 | 521.6249 | 628.3102 | 621.6918 | 525.8993 | 580.7773 |
| CV-RMSE | 0.1472 | 0.1497 | 0.1464 | 0.1352 | 0.1484 | 0.1476 | 0.1357 | 0.1427 | |
| MAE | 15.3412 | 15.4008 | 15.0831 | 14.5979 | 15.1707 | 15.8855 | 14.6078 | 14.8953 | |
| b | MSE | 637.9738 | 642.9971 | 620.1647 | 529.0256 | 638.2404 | 616.0422 | 530.3914 | 610.0158 |
| CV-RMSE | 0.1495 | 0.1501 | 0.1474 | 0.1361 | 0.1495 | 0.1469 | 0.1363 | 0.1462 | |
| MAE | 15.6836 | 15.4158 | 15.2198 | 14.6996 | 15.5829 | 15.7330 | 14.7353 | 15.4975 | |
| c | MSE | 634.4595 | 654.3532 | 609.4524 | 524.1977 | 624.5042 | 613.2818 | 533.1998 | 598.2004 |
| CV-RMSE | 0.1491 | 0.1514 | 0.1461 | 0.1355 | 0.1479 | 0.1466 | 0.1367 | 0.1448 | |
| MAE | 15.6369 | 15.7573 | 15.0483 | 14.6299 | 15.01581 | 15.6632 | 14.7882 | 15.2544 | |
| d | MSE | 627.5367 | 646.9769 | 617.9012 | 522.8939 | 641.9141 | 642.3194 | 527.0063 | 618.1331 |
| CV-RMSE | 0.1483 | 0.1506 | 0.1471 | 0.1354 | 0.1499 | 0.1500 | 0.1359 | 0.1472 | |
| MAE | 15.4419 | 15.5479 | 15.1449 | 14.5952 | 15.5305 | 16.2132 | 14.6679 | 15.7004 | |
| e | MSE | 632.7266 | 634.7069 | 615.5522 | 527.4990 | 653.2188 | 600.0877 | 519.7688 | 599.0087 |
| CV-RMSE | 0.1489 | 0.1491 | 0.1469 | 0.1359 | 0.1513 | 0.1450 | 0.1349 | 0.1449 | |
| MAE | 15.5905 | 15.3135 | 15.1968 | 14.6927 | 15.7624 | 15.3513 | 14.5183 | 15.3066 |
| Experiments | Index | 0 | 1 | 2&3 |
|---|---|---|---|---|
| a | MSE | 207.6466 | 236.1434 | 175.5794 |
| CV-RMSE | 0.0565 | 0.06029 | 0.0519 | |
| MAE | 10.4367 | 11.1318 | 9.7602 | |
| b | MSE | 202.2124 | 228.3745 | 174.7428 |
| CV-RMSE | 0.0558 | 0.05929 | 0.05186968 | |
| MAE | 10.3585 | 11.0803 | 9.7443 | |
| c | MSE | 203.2862 | 231.5124 | 170.6705 |
| CV-RMSE | 0.0559 | 0.05970 | 0.0513 | |
| MAE | 10.3066 | 10.9787 | 9.6480 | |
| d | MSE | 209.9991 | 223.4955 | 172.8036 |
| CV-RMSE | 0.0568 | 0.05866 | 0.0516 | |
| MAE | 10.5164 | 10.9168 | 9.7492 | |
| e | MSE | 205.2349 | 245.4507 | 166.9035 |
| CV-RMSE | 0.05621 | 0.06147 | 0.0507 | |
| MAE | 10.4451 | 11.4452 | 9.5268 |
| Index | Only Historical Data | With Schedule | With Dry-Bulb Temperature |
|---|---|---|---|
| MSE | 215.264 | 202.712 | 208.542 |
| CV-RMSE | 0.058 | 0.056 | 0.057 |
| MAE | 10.698 | 10.665 | 10.65 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lin, X.; Yu, H.; Wang, M.; Li, C.; Wang, Z.; Tang, Y. Electricity Consumption Forecast of High-Rise Office Buildings Based on the Long Short-Term Memory Method. Energies 2021, 14, 4785. https://doi.org/10.3390/en14164785
Lin X, Yu H, Wang M, Li C, Wang Z, Tang Y. Electricity Consumption Forecast of High-Rise Office Buildings Based on the Long Short-Term Memory Method. Energies. 2021; 14(16):4785. https://doi.org/10.3390/en14164785
Chicago/Turabian StyleLin, Xiaoyu, Hang Yu, Meng Wang, Chaoen Li, Zi Wang, and Yin Tang. 2021. "Electricity Consumption Forecast of High-Rise Office Buildings Based on the Long Short-Term Memory Method" Energies 14, no. 16: 4785. https://doi.org/10.3390/en14164785