Where Will You Park? Predicting Vehicle Locations for Vehicle-to-Grid




Abstract
:1. Introduction
2. Materials and Methods
2.1. Dataset Processing
- The stationary period, p, was calculated as the set of full minutes between the end_time of and the start_time of
- The co-ordinates of the end location of were retrieved, i.e., end_latv and end_lngv
- Vehicle availability, av, for period p was calculated using Equation (2)
- Each half-hour period, , for which all 30 min fell within p was added to set
- Where , the vehicle was deemed to be available for each period within
- The day number (d); from 0 to 6, i.e., Sunday to Saturday
- Half-hour (hh); the index of the half-hour period from 1 to 48
- Public holidays (ph); i.e., national holidays
- University holidays (uh); other days—when the University was closed—that were typically contiguous to public holidays
- Holidays (hol); days that were either a public holiday or a University holiday
- Term days (term), i.e., whether the day fell within a University term period
2.2. Learning Approaches
2.2.1. Automated Machine Learning
- AutoML on Microsoft Azure [21]: At the time of writing, this implementation supported the automated evaluation of up to 16 different algorithms for classification problems, including variations of popular approaches, such as decision trees and gradient boosting. Accuracy was chosen as the primary metric for the optimiser, i.e., the percentage of the training dataset for which availability was correctly predicted, and a typical AutoML run evaluated around 100 different frameworks to produce the final optimised classifier. For the problem explored in this work, the eXtreme Gradient Boosting (XGBoost) classifier was consistently the best performer [22]. This approach is based on gradient boosted decision trees, which is a fast and efficient technique that creates a strong classifier from an ensemble of weak decision tree classifiers.
- AutoML Tables on the Google Cloud Platform [23]: In addition to considering standard machine learning algorithms, this technique also used neural architecture search (NAS) [24] to assess the efficacy of artificial neural networks. As for other types of machine learning, design of an appropriate neural network for a given problem often requires much trial and error with the number of hidden layers, the number of nodes within each layer, network connectivity and other hyperparameters being key decisions. Best results were achieved by the adaptive structural learning of artificial neural Networks (AdaNet) technique, which progressively builds a network architecture form an ensemble of subnetworks [25].
2.2.2. Cumulative Moving Average
2.2.3. Exponential Moving Average
3. Results and Discussion
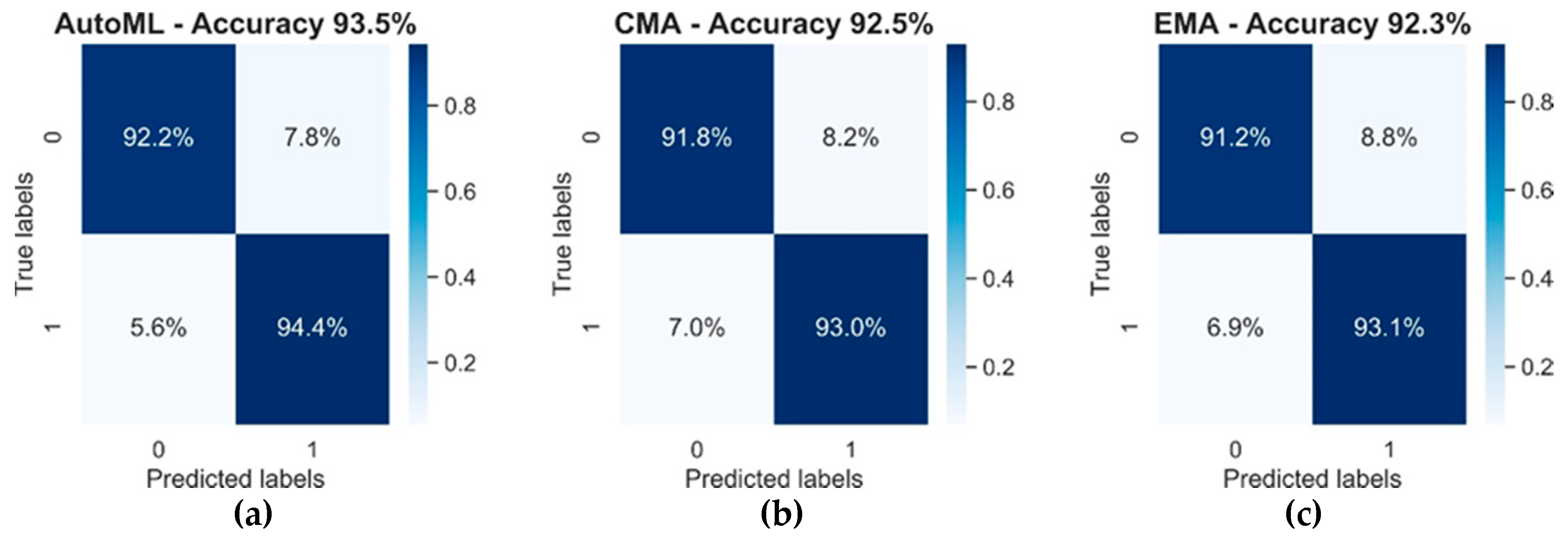
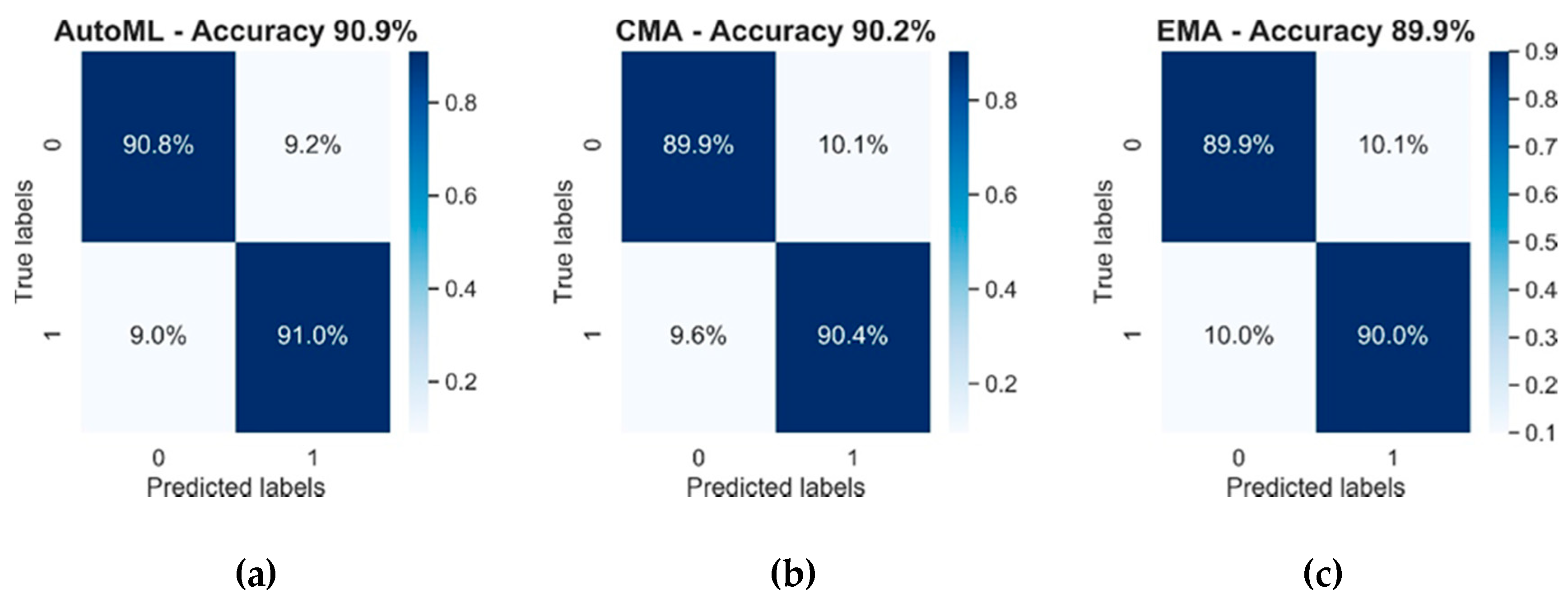
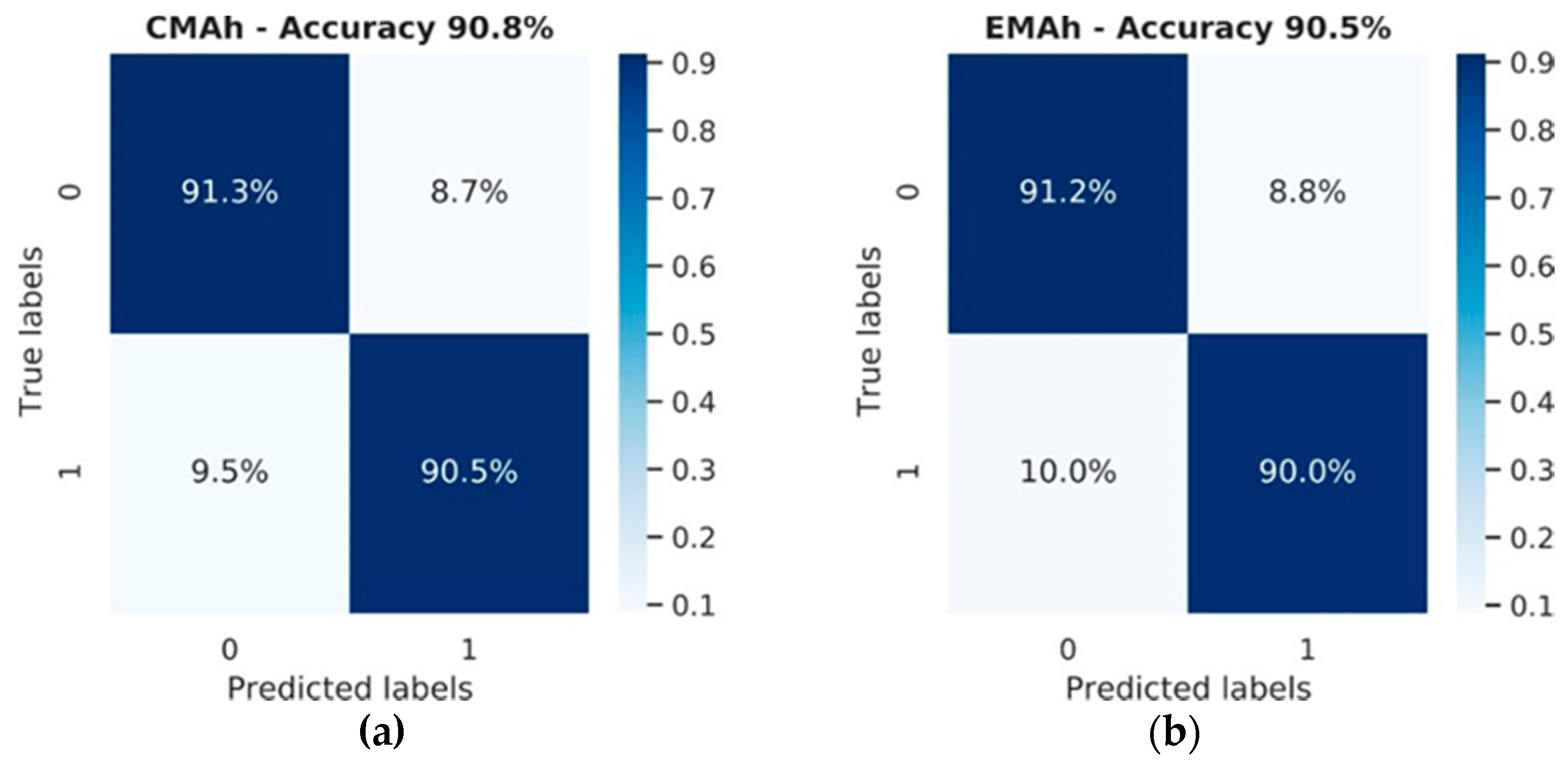
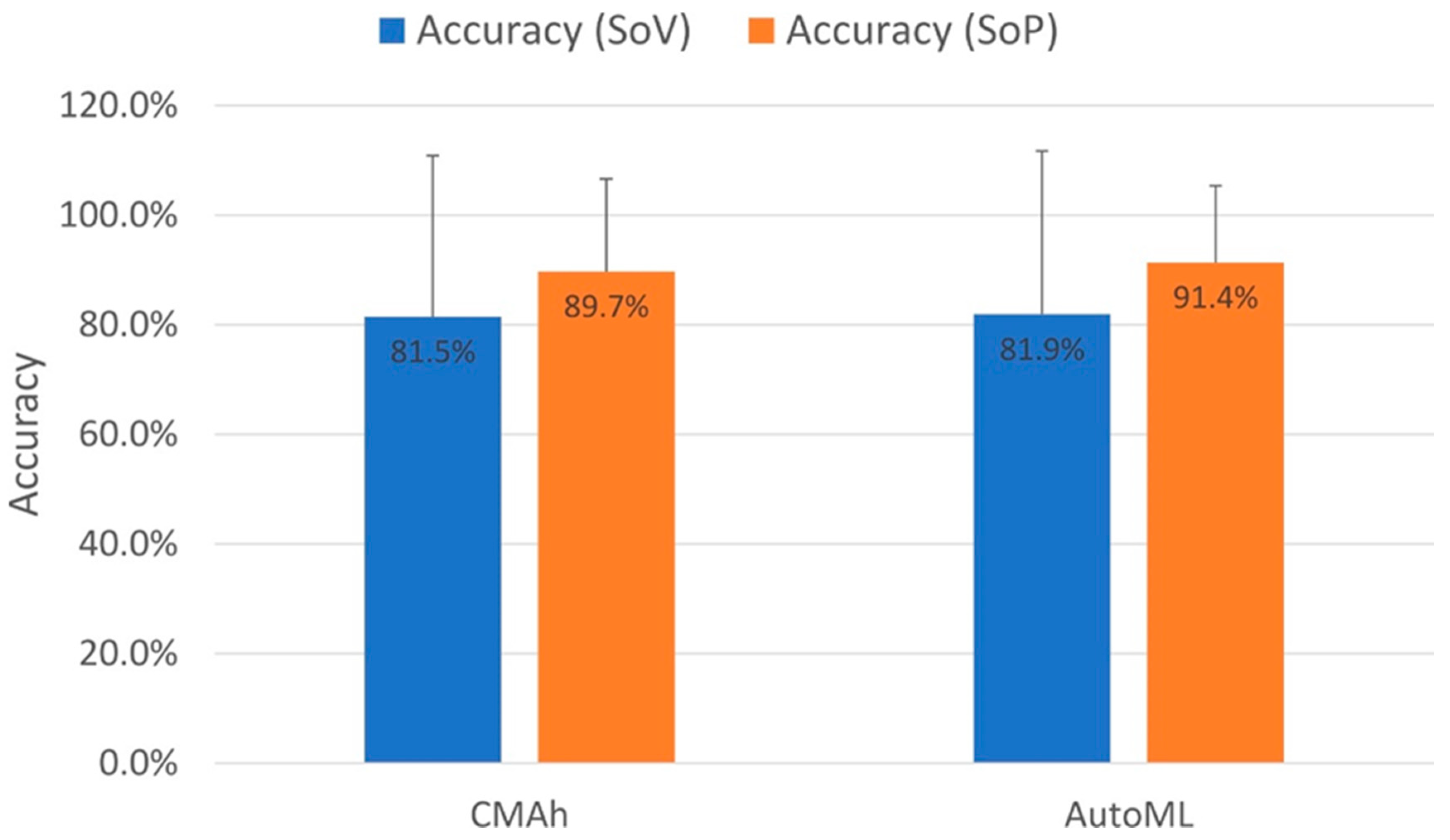
3.1. Model Analysis
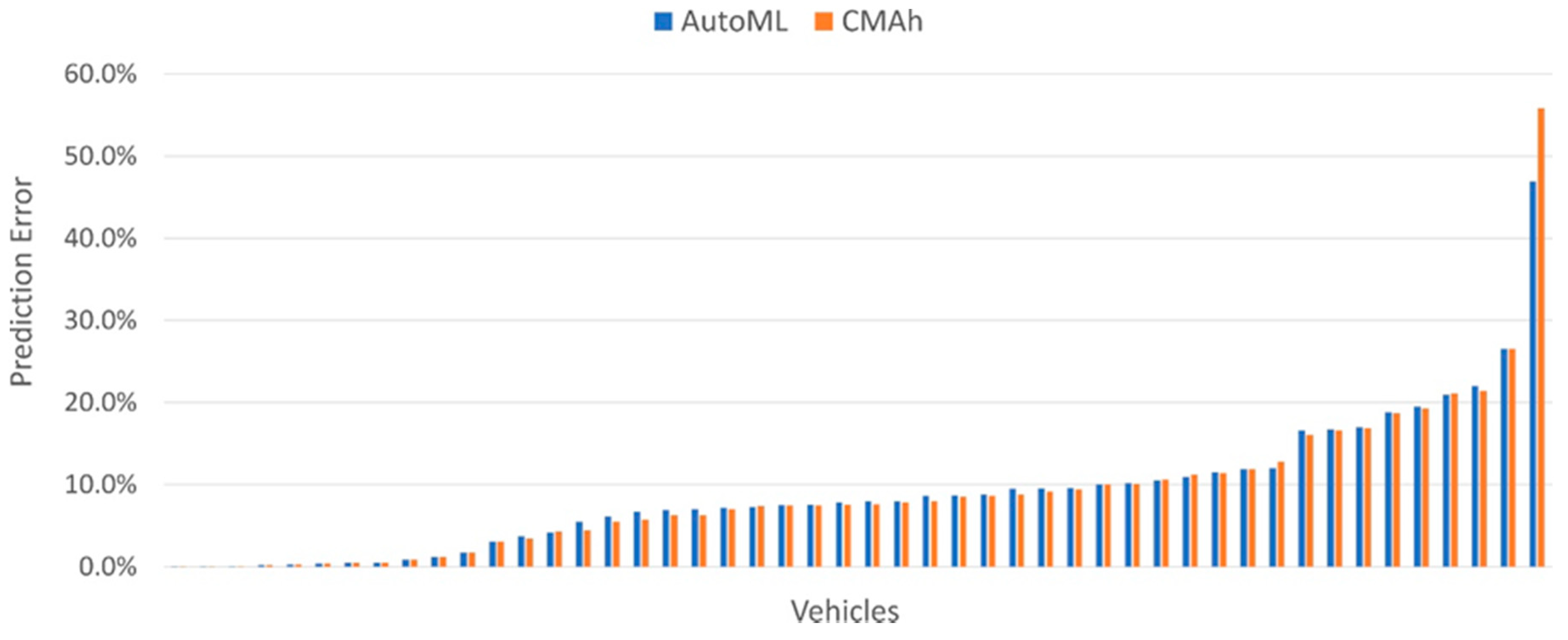
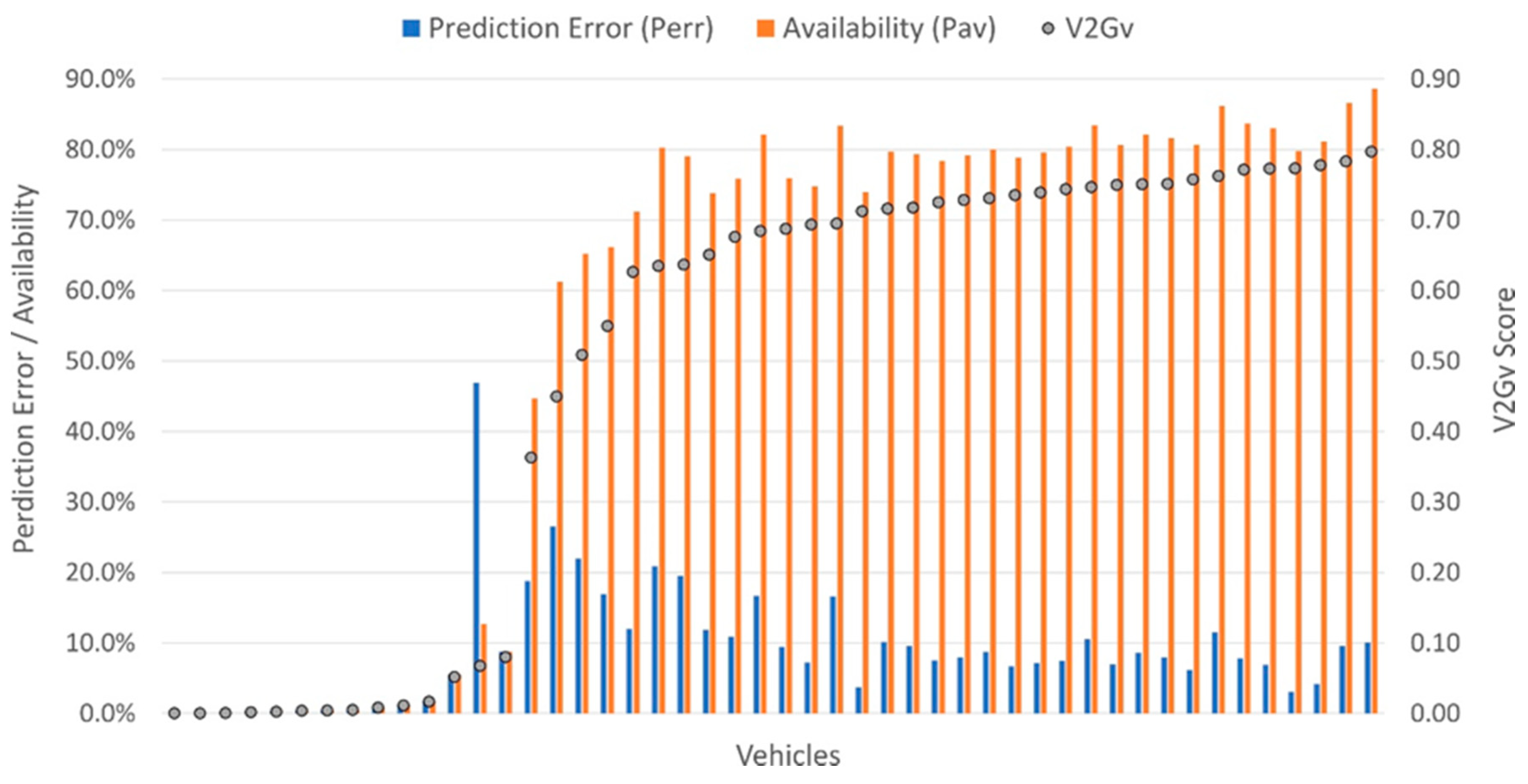
3.2. Vehicle Analysis
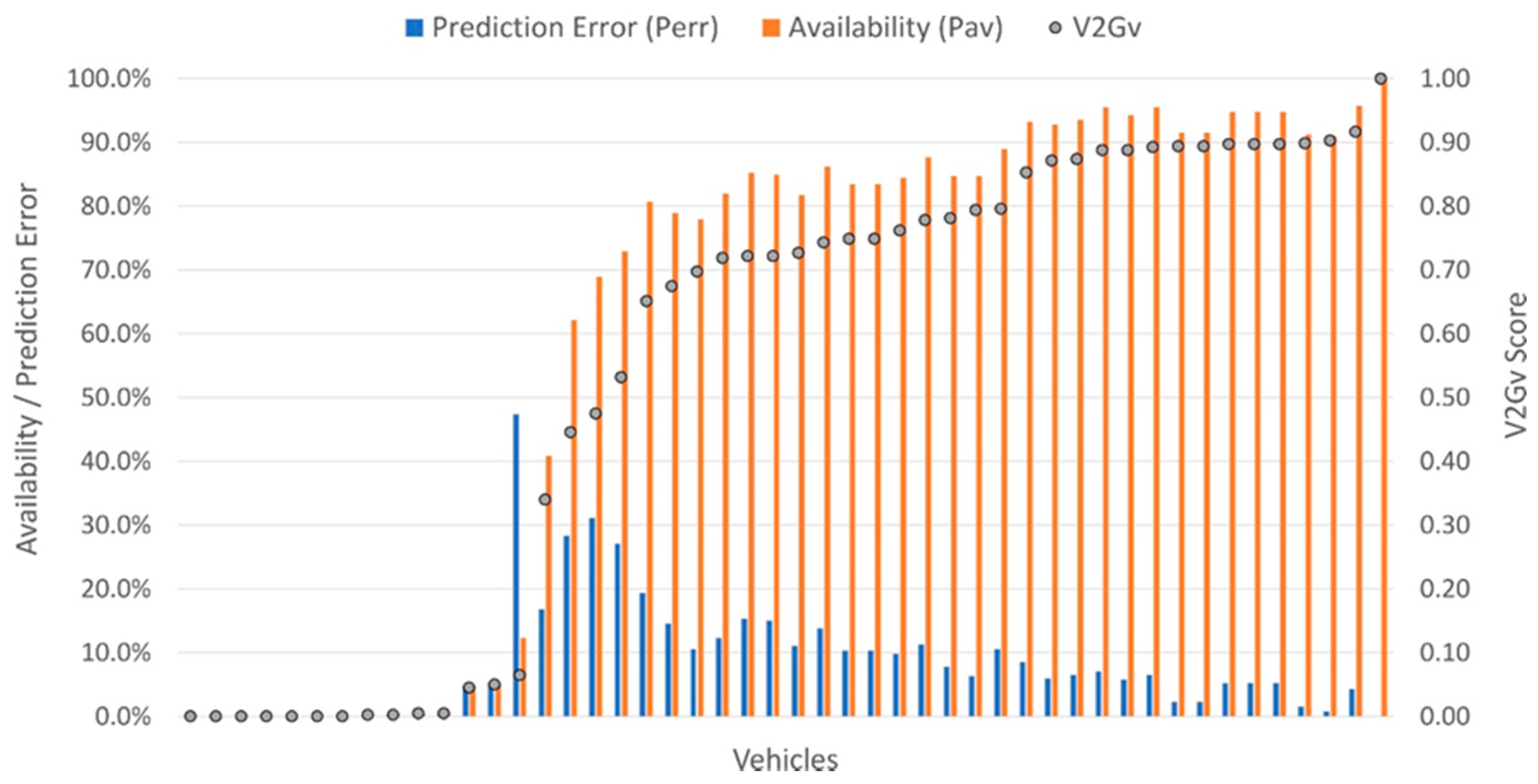
3.3. Fleet Analysis
3.4. Discussion
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Villar, J.; Bessa, R.; Matos, M. Flexibility products and markets: Literature review. Electr. Power Syst. Res. 2018, 154, 329–340. [Google Scholar] [CrossRef]
- Waldron, J.; Rodrigues, L.; Gillott, M.; Naylor, S.; Shipman, R. Towards an electric revolution: a review on vehicle- to-grid, smart charging and user behaviour. In Proceedings of the 18th International Conference on Sustainable Energy Technologies (SET 2019), Kuala Lumpur, Malaysia, 20–22 August 2019; Volume 3, pp. 1–9. [Google Scholar]
- Kempton, W.; Tomić, J. Vehicle-to-grid power implementation: From stabilizing the grid to supporting large-scale renewable energy. J. Power Sources 2005, 144, 280–294. [Google Scholar] [CrossRef]
- Nottingham City Council. Nottingham’s 2028 Carbon Neutral Charter; 2019. Available online: http://documents.nottinghamcity.gov.uk/download/7536 (accessed on 14 April 2020).
- Pudjianto, D.; Ramsay, C.; Strbac, G. Virtual power plant and system integration of distributed energy resources. IET Renew. Power Gener. 2007, 1, 10. [Google Scholar] [CrossRef]
- Nuvve V2G Technology. Available online: https://nuvve.com/technology/ (accessed on 27 February 2020).
- Payne, G. Understanding the True Value of V2G; Cenex: Loughborough, UK, 2019; p. 62. Available online: https://www.cenex.co.uk/app/uploads/2019/10/True-Value-of-V2G-Report.pdf (accessed on 14 April 2020).
- Powerloop V2G. Available online: https://www.octopusev.com/powerloop (accessed on 27 February 2020).
- OVO Vehicle-to-Grid Charger. Available online: https://www.ovoenergy.com/electric-cars/vehicle-to-grid-charger (accessed on 27 February 2020).
- Bates, J.; Leibling, D. Spaced Out Perspectives on Parking Policy; RAC Foundation: London, UK, 2012; p. 118. Available online: https://www.racfoundation.org/assets/rac_foundation/content/downloadables/spaced_out-bates_leibling-jul12.pdf (accessed on 14 April 2020).
- Zhou, Y.; Cao, S.; Hensen, J.L.M.; Lund, P.D. Energy integration and interaction between buildings and vehicles: A state-of-the-art review. Renew. Sustain. Energy Rev. 2019, 114, 109337. [Google Scholar] [CrossRef]
- Iversen, E.B.; Morales, J.M.; Madsen, H. Optimal charging of an electric vehicle using a Markov decision process. Appl. Energy 2014, 123, 1–12. [Google Scholar] [CrossRef] [Green Version]
- Shimizu, O.; Kawashima, A.; Inagaki, S.; Suzuki, T. Vehicle Fleet Prediction for V2G System - Based on Left to Right Markov Model. In Proceedings of the 4th International Conference on Vehicle Technology and Intelligent Transport Systems, Madeira, Portugal, 16–18 March 2018; pp. 417–422. [Google Scholar]
- Hou, Y.; Edara, P. Network Scale Travel Time Prediction using Deep Learning. Transp. Res. Rec. 2018, 2672, 115–123. [Google Scholar] [CrossRef]
- Awan, F.M.; Saleem, Y.; Minerva, R.; Crespi, N. A Comparative Analysis of Machine/Deep Learning Models for Parking Space Availability Prediction. Sensors 2020, 20, 322. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Trakm8 Limited. Telematic Solutions. 2019. Available online: https://static.trakm8.com/static/downloads/trakm8-telematics-solutions-brochure.pdf (accessed on 14 April 2020).
- Hutter, F.; Kotthoff, L.; Vanschoren, J. Automated Machine Learning, 1st ed.; Springer International Publishing: New York, NY, USA, 2019; p. 242. ISBN 9783030053178. [Google Scholar]
- Waldron, J.; Rodrigues, L.; Gillott, M.; Naylor, S.; Shipman, R. Decarbonising Our Transport System: User Behaviour Analysis to Assess the Transition to Electric Mobility. In Proceedings of the 35th PLEA conference sustainable architecture and urban design (to appear), A Coruña, Spain, 1–3 September 2020. [Google Scholar]
- Fusi, N.; Sheth, R.; Elibol, M. Probabilistic matrix factorization for automated machine learning. In Proceedings of the 32nd Conference on Neural Information Processing Systems (NeurIPS 2018), Montréal, Canada, 3–8 December 2018; pp. 3348–3357. [Google Scholar]
- Feurer, M.; Klein, A.; Eggensperger, K.; Springenberg, J.; Blum, M.; Hutter, F. Efficient and Robust Automated Machine Learning. In Advances in Neural Information Processing Systems, 28th ed.; Cortes, C., Lawrence, N.D., Lee, D.D., Sugiyama, M., Garnett, R., Eds.; Curran Associates, Inc.: New York, NY, USA, 2015; pp. 2962–2970. [Google Scholar]
- Microsoft Corporation. What is Automated Machine Learning? Available online: https://docs.microsoft.com/en-us/azure/machine-learning/concept-automated-ml (accessed on 28 February 2020).
- Chen, T.; Guestrin, C. XGBoost: A scalable tree boosting system. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Google AutoML Tables. Available online: https://cloud.google.com/automl-tables (accessed on 6 February 2020).
- Zoph, B.; Le, Q.V. Neural architecture search with reinforcement learning. In Proceedings of the 5th International Conference on Learning Representations ICLR 2017, Toulon, France, 24–26 April 2017; pp. 1–6. [Google Scholar]
- Cortes, C.; Gonzalvo, X.; Kuznetsov, V.; Mohri, M.; Yang, S. AdaNet: Adaptive Structural Learning of Artificial Neural Networks. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; Volume 70, pp. 874–883. [Google Scholar]
- Dietterich, T.G. Approximate Statistical Tests for Comparing Supervised Classification Learning Algorithms. Neural Comput. 1998, 10, 1895–1923. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gama, J.; Žliobaitundefined, I.; Bifet, A.; Pechenizkiy, M.; Bouchachia, A. A Survey on Concept Drift Adaptation. ACM Comput. Surv. 2014, 46, 1–37. [Google Scholar] [CrossRef]
- Shipman, R.; Naylor, S.; Pinchin, J.; Gough, R.; Gillott, M. Learning capacity: predicting user decisions for vehicle-to-grid services. Energy Informatics 2019, 2, 1–22. [Google Scholar] [CrossRef] [Green Version]
- Sovacool, B.K.; Noel, L.; Axsen, J.; Kempton, W. The neglected social dimensions to a vehicle-to-grid (V2G) transition: a critical and systematic review. Environ. Res. Lett. 2018, 13, 13001. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Description | Example |
|---|---|---|
| vid | Unique identifier for this vehicle | 12 |
| start_lat | Latitude at the start of the journey | 52.95282 |
| start_lng | Longitude at the start of the journey | −1.18652 |
| start_time | Timestamp at the start of the journey | 2019-11-21T13:53:10+00:00 |
| end_lat | Latitude at the end of the journey | 52.94025 |
| end_lng | Longitude at the end of the journey | −1.192132 |
| end_time | Timestamp at the end of the journey | 2019-11-21T14:00:16+00:00 |
| Vehicle (v) | Department | d | hh | ph | uh | hol | term | av |
|---|---|---|---|---|---|---|---|---|
| 1 | A | 1 | 1 | 0 | 1 | 1 | 0 | 0 |
| 2 | B | 3 | 35 | 0 | 0 | 0 | 1 | 1 |
| 3 | C | 5 | 26 | 1 | 0 | 1 | 0 | 0 |
| 3 | C | 5 | 27 | 1 | 0 | 1 | 0 | 1 |
| 4 | D | 4 | 20 | 0 | 0 | 0 | 1 | 1 |
| Feature | Training | Test |
|---|---|---|
| Availability (av = 1) | 57.4% | 55.7% |
| Term days (term = 1) | 54.4% (129 days) | 47.4% (27 days) |
| Public Holiday (ph = 1) | 3.0% (7 days) | 1.8% (1 day) |
| University Holiday (uh = 1) | 1.7% (1 day) | 1.8% (1 day) |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shipman, R.; Waldron, J.; Naylor, S.; Pinchin, J.; Rodrigues, L.; Gillott, M. Where Will You Park? Predicting Vehicle Locations for Vehicle-to-Grid. Energies 2020, 13, 1933. https://doi.org/10.3390/en13081933
Shipman R, Waldron J, Naylor S, Pinchin J, Rodrigues L, Gillott M. Where Will You Park? Predicting Vehicle Locations for Vehicle-to-Grid. Energies. 2020; 13(8):1933. https://doi.org/10.3390/en13081933
Chicago/Turabian StyleShipman, Rob, Julie Waldron, Sophie Naylor, James Pinchin, Lucelia Rodrigues, and Mark Gillott. 2020. "Where Will You Park? Predicting Vehicle Locations for Vehicle-to-Grid" Energies 13, no. 8: 1933. https://doi.org/10.3390/en13081933