The Impact of Imperfect Weather Forecasts on Wind Power Forecasting Performance: Evidence from Two Wind Farms in Greece


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- We measure the impact of imperfect weather forecasts on the wind power forecasting accuracy and the estimation of uncertainty through the evaluation of the point forecasts and the prediction intervals produced by various types of forecasting methods;
- We compare the suitability of statistical versus ML approaches in the task of estimating highly volatile variables when the accuracy of external information varies;
- Assuming varying levels of inaccuracy in the independent variable, we perform a sensitivity analysis with varying distributional assumptions to conclude on the robustness [24] of the forecasting approaches considered and make relevant recommendations.
2. Forecasting Methods Considered
2.1. Training and Testing
2.2. Scaling
2.3. Statistical and Machine Learning Methods
- Linear Regression (LR): LR is a linear method for modeling the relationships between the target and the predictor variables. The parameters of the forecasting model are estimated directly from the data using closed forms. LR was the first type of regression method to be studied rigorously, and is therefore widely used because of its simplicity, low computational cost, and intuitiveness. Since in this study we consider N weather variables as predictors, LR is implemented in the form of multiple linear regression, as follows:where a is the intercept of the model, and is the coefficient of the weather variable used for predicting the wind power. Note that LR methods, in contrast to ML methods, assume additive, linear relationships between the target and the predictor variables. Thus, it was expected to result in suboptimal forecasts when used for modeling complex, nonlinear data patterns;
- Multi-Layer Perceptron (MLP): A simple, single hidden layer NN of N input and input nodes, constructed so that accurate, yet computationally affordable forecasts are provided [27]. The Scaled Conjugate Gradient method is used for estimating the weights [28] which are initialized randomly. The learning rate is selected between 0.1 and 1 using a tenfold cross-validation procedure (mean squared error minimization), while the maximum iterations are set to 500. The sigmoid activation function is used both for the hidden and the output layers given the lack of trend in the data. We trained 10 models and use the median of their forecasts to mitigate possible variations due to poor weight initializations [29]. The method was implemented using the RSNNS R statistical package [30];
- Bayesian Neural Network (BNN): This method is similar to the MLP method but optimizes the weights according to the Bayesian concept, as suggested by [31,32]. The Nguyen and Widrow algorithm [33] is used to assign initial weights and the Gauss–Newton algorithm to perform the optimization. Once again, an ensemble of 10 models was considered with a maximum of 500 iterations each. The method was implemented using the brnn R statistical package [34];
- Random Forest (RF): RTs can be used to perform a treelike recursive partitioning of the input space, thus dividing it into regions, called the terminal leaves [35]. Then, on the basis of the inputs provided, tests are applied to decision nodes in order to define which leave should be used for forecasting. The RF method expands this concept by combining the results of multiple RTs, each one depending on the values of a random vector sampled independently and with the same distribution [36]. In this regard, RF is more robust to outliers and overfitting, even for limited samples of data. In this study, we considered a total of 500 nonpruned trees and sampled the data with replacement. The method was implemented using the randomForest R statistical package [37];
- Gradient Boosting Trees (GBT): This method is similar to RF, but instead of generating multiple independent trees, it builds one tree at a time, each new tree correcting the errors made by the previously trained one [38]. Thus, although GBT is more specialized than RF in forecasting the target variable, is more sensitive to overfitting [39]. In this study, we constructed a slow learning model with a learning rate of 0.01 and a maximum tree depth of 5. We considered 1000 trees but pruned the constructed model by employing a tenfold cross-validation procedure to mitigate overfitting. The method was implemented using the gbm R statistical package [40];
- K-Nearest Neighbor Regression (KNNR): KNNR is a similarity-based method, generating forecasts according to the Euclidean distance computed between the points used for training and testing. Given a test sample of N predictor variables, the method picks the closest K observations of the training sample to them and then sets the prediction equal to the average of their corresponding target values. K was selected between 3 and 300 with a step of 3 using a tenfold cross-validation procedure. The method was implemented using the caret R statistical package [41];
- Support Vector Regression (SVR): SVR generates forecasts by identifying the hyperplane that maximizes the margin between two classes and minimizes the total error under tolerance [42]. We considered -regression, with being equal to 0.01 and a radial basis kernel. The method was implemented using the e1071 R statistical package [43].
3. Empirical Evaluation
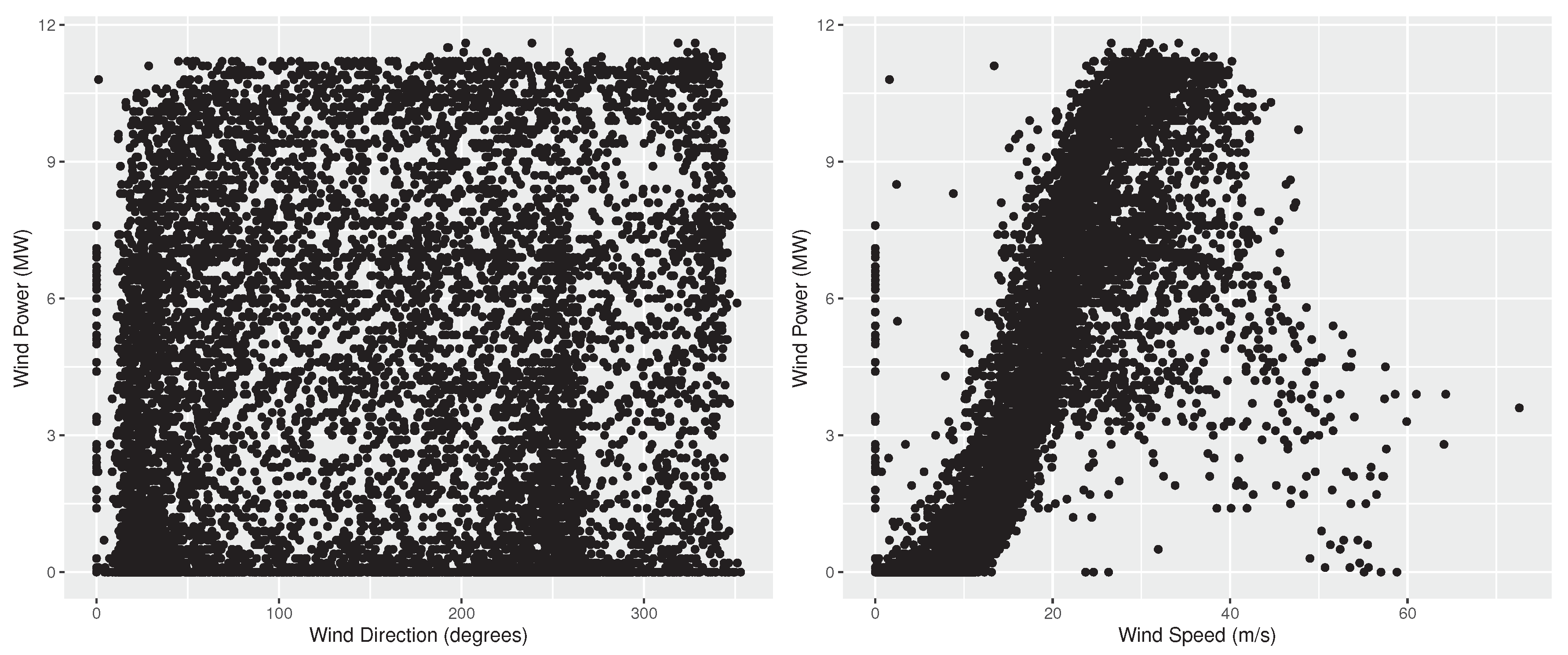
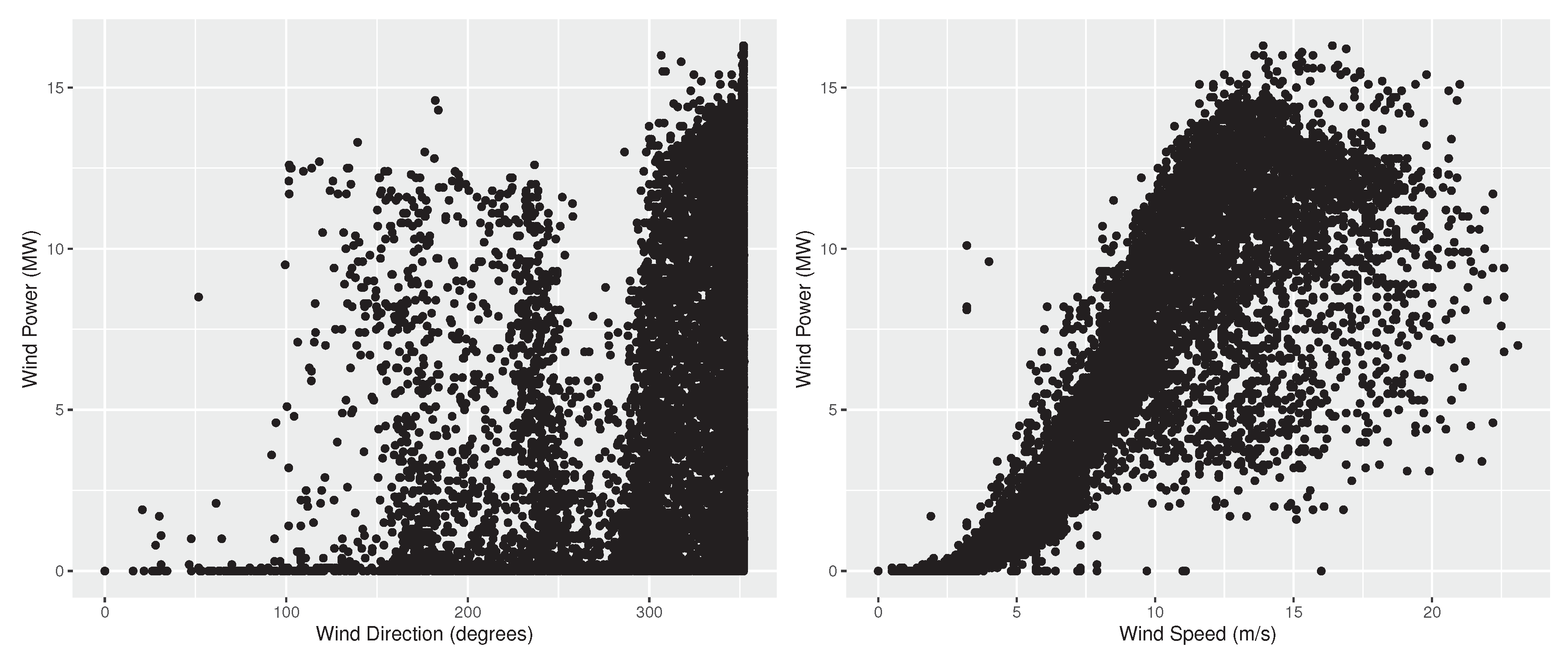
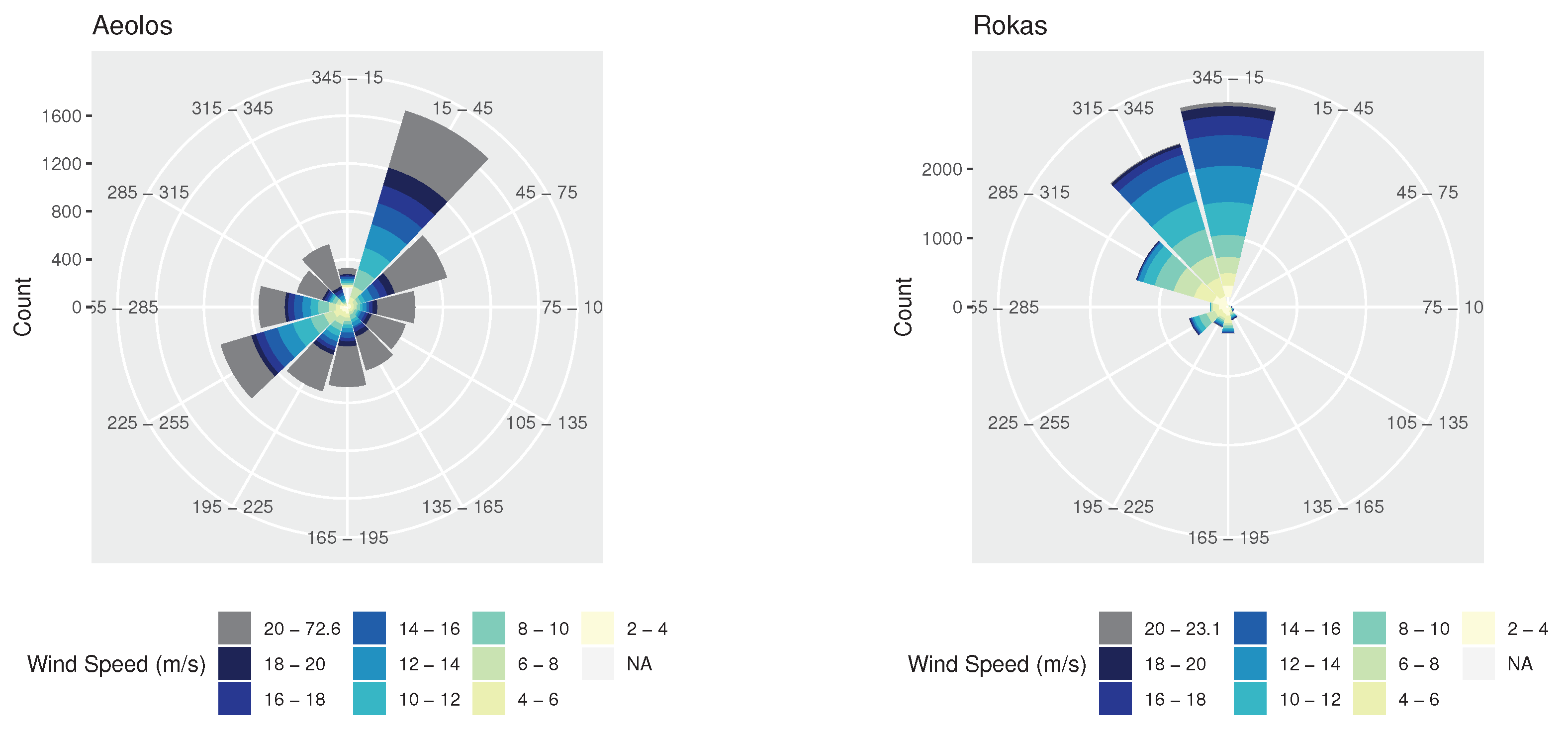
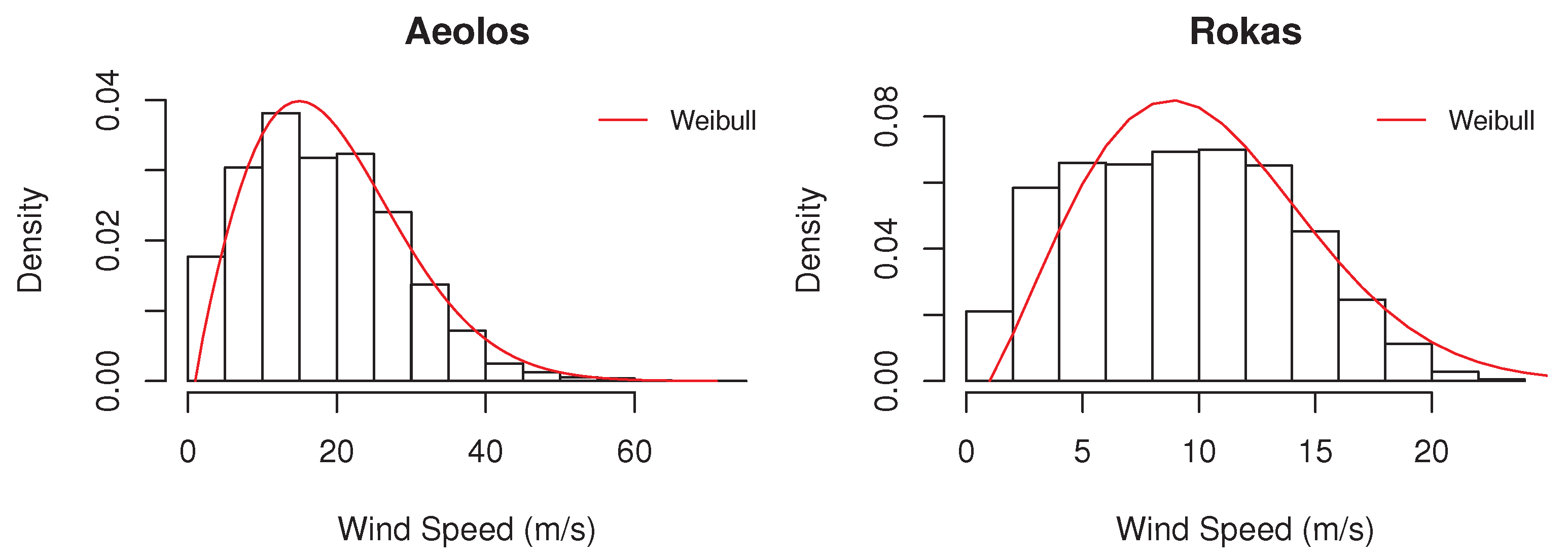
3.1. Dataset
3.2. Experimental Setup
- Wind speed. Given that wind speed must be positive, the adjustment was performed by (i) multiplying the original values of the variable with the computed factors and (ii) setting all nonzero forecasts (if any) to zero;
- Wind direction. Given that wind direction must range between 0 and 360 degrees, the adjustment was performed by (i) adding the computed factors, multiplied by 360, to the original values of the variable, and (ii) adding or subtracting 360 to all forecasts that were lower than zero or higher than 360, respectively.
- Given the sample used for training the forecasting methods when producing point forecasts, the random samples are created without replacement (observations used for validation purposes remain unobserved while training);
- For each of the ten random samples, 90% of the observations are used for training the forecasting methods and 10% for estimating the corresponding errors of the point forecasts;
- The empirical distribution of the errors (actual-forecast) is computed using a Kernel density estimator, and the 0.025 and 0.975 quantities of the distribution are determined;
- The forecasting methods are retrained using the complete training sample so that point forecasts are produced for the test sample of interest;
- The 95% prediction intervals are computed by adding the 0.025 and 0.975 quantities to the point forecasts produced in the previous step.
- We randomly split the original dataset of each wind farm into five samples of equal sizes;
- Four out of the five samples are used for constructing a training dataset, which is then scaled;
- The training dataset is randomly split into ten subsamples;
- Nine out of the ten subsamples are used for training the seven forecasting methods considered in this study, with the last one used for producing forecasts and computing the corresponding forecast errors of each method;
- Step 4 is repeated for all the ten possible combinations of subsamples;
- A Kernel density estimator is used to approximate the 0.025 and 0.975 quantities of the error distribution of the methods, as specified through Steps 3, 4, and 5;
- The forecasting models are retrained using the complete training dataset, as specified in Step 2, so that point forecasts are produced for the respective test sample;
- 95% prediction intervals are computed by adding the 0.025 and 0.975 quantities to the point forecasts produced in Step 7;
- Point forecasts and prediction intervals are evaluated using the MAE and MIS measures, respectively;
- Steps 2 to 9 are repeated for all the five possible combinations of samples;
- The results are summarized by averaging the forecasting performance of the forecasting methods for all five samples considered.
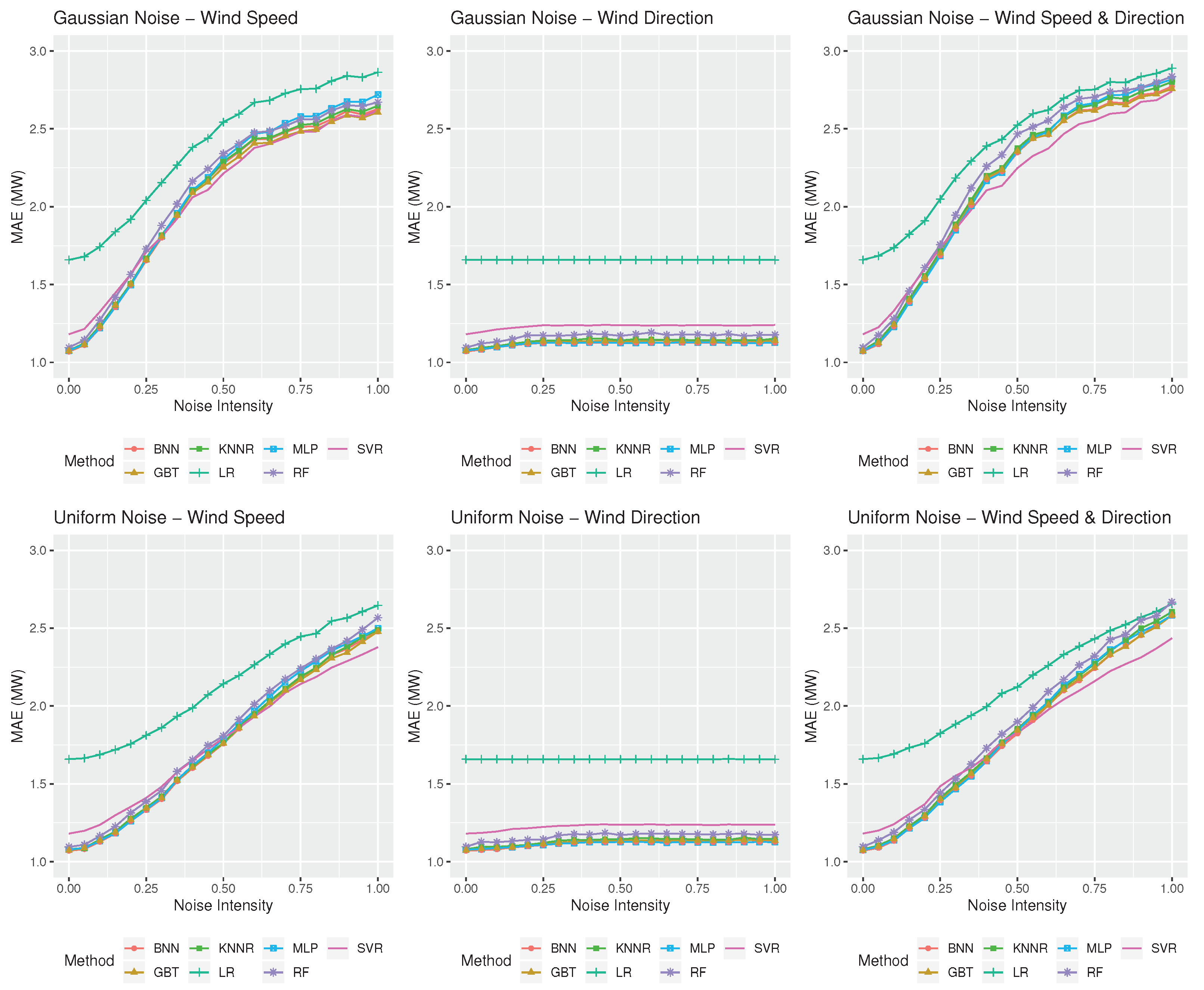
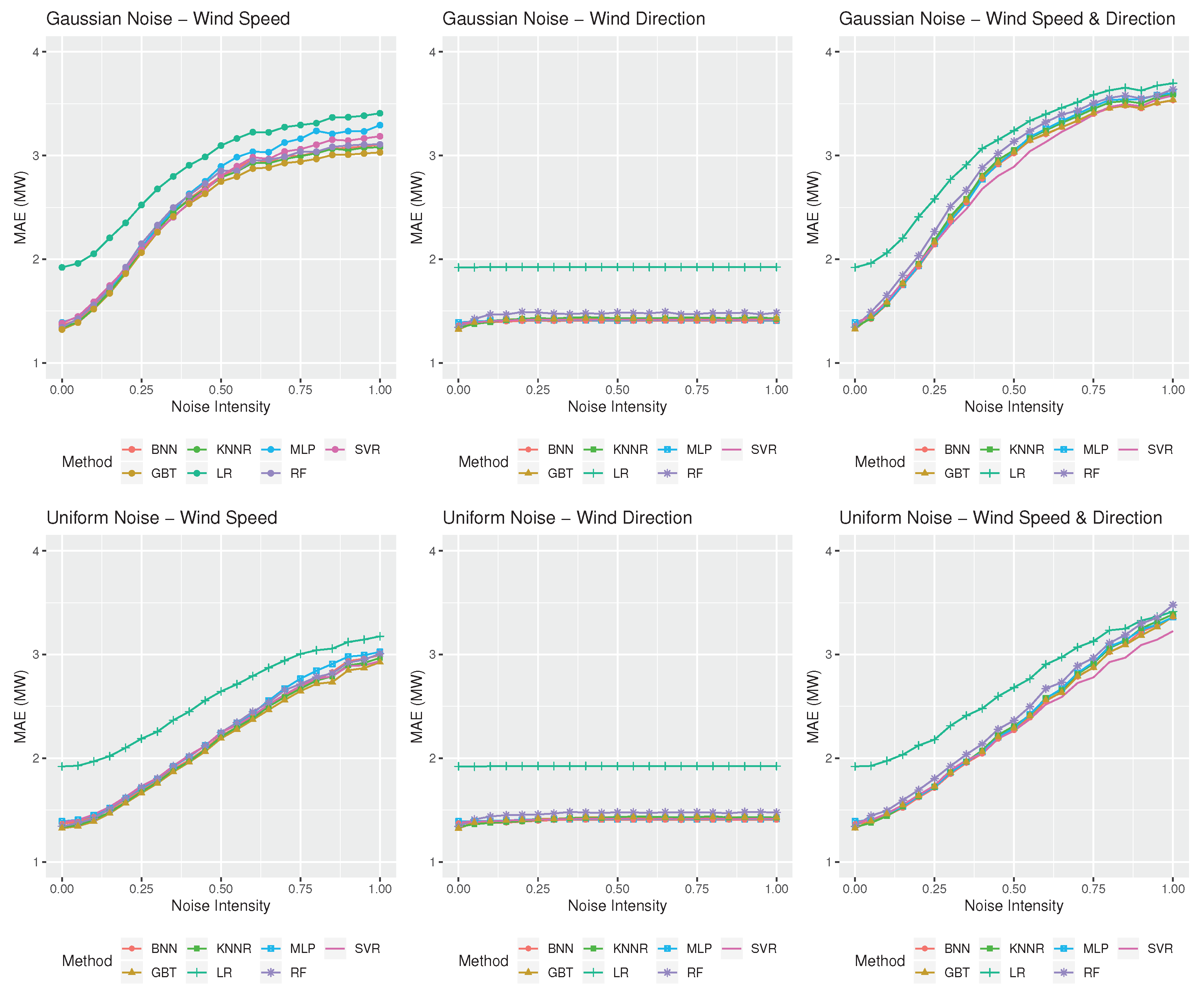
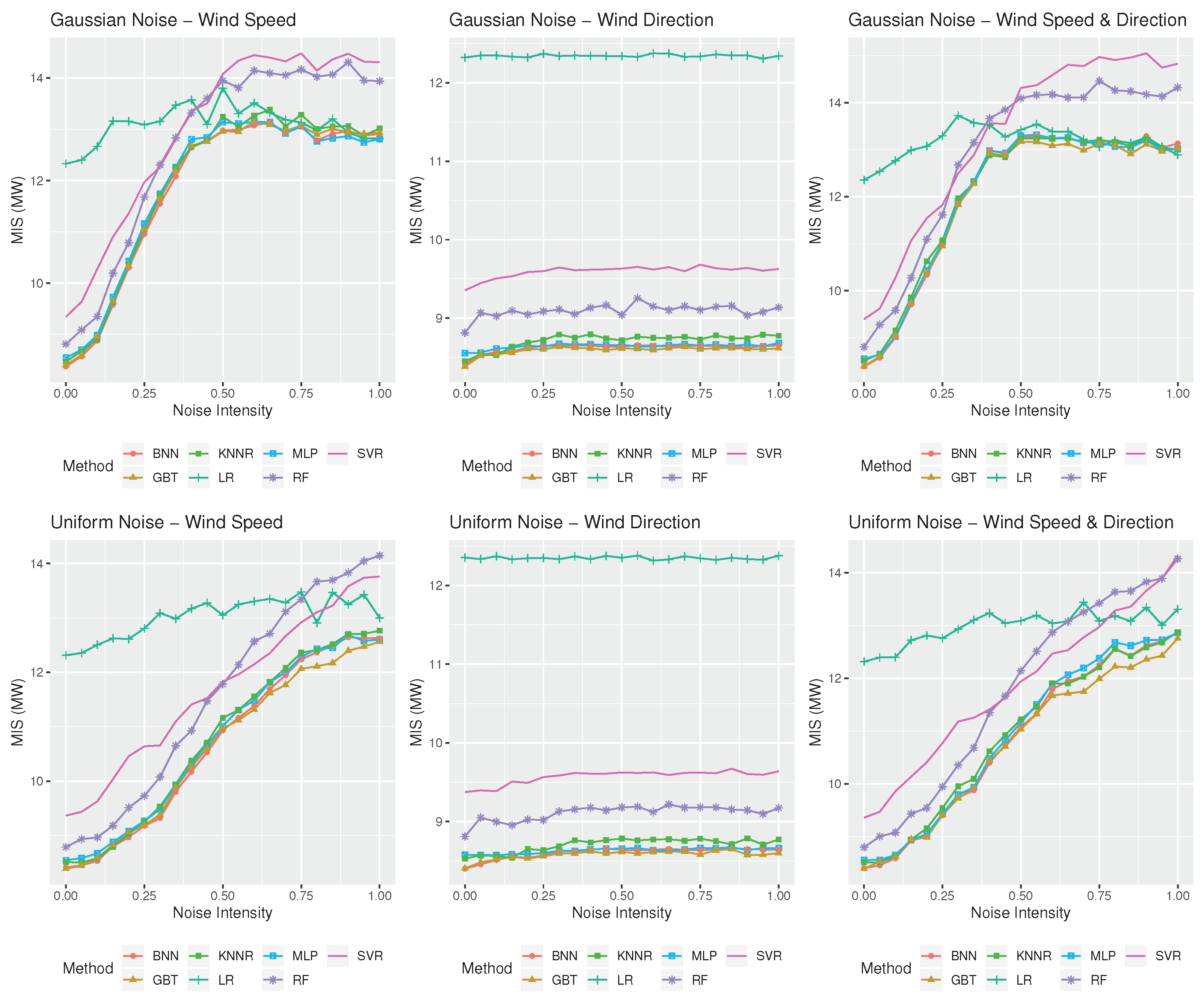
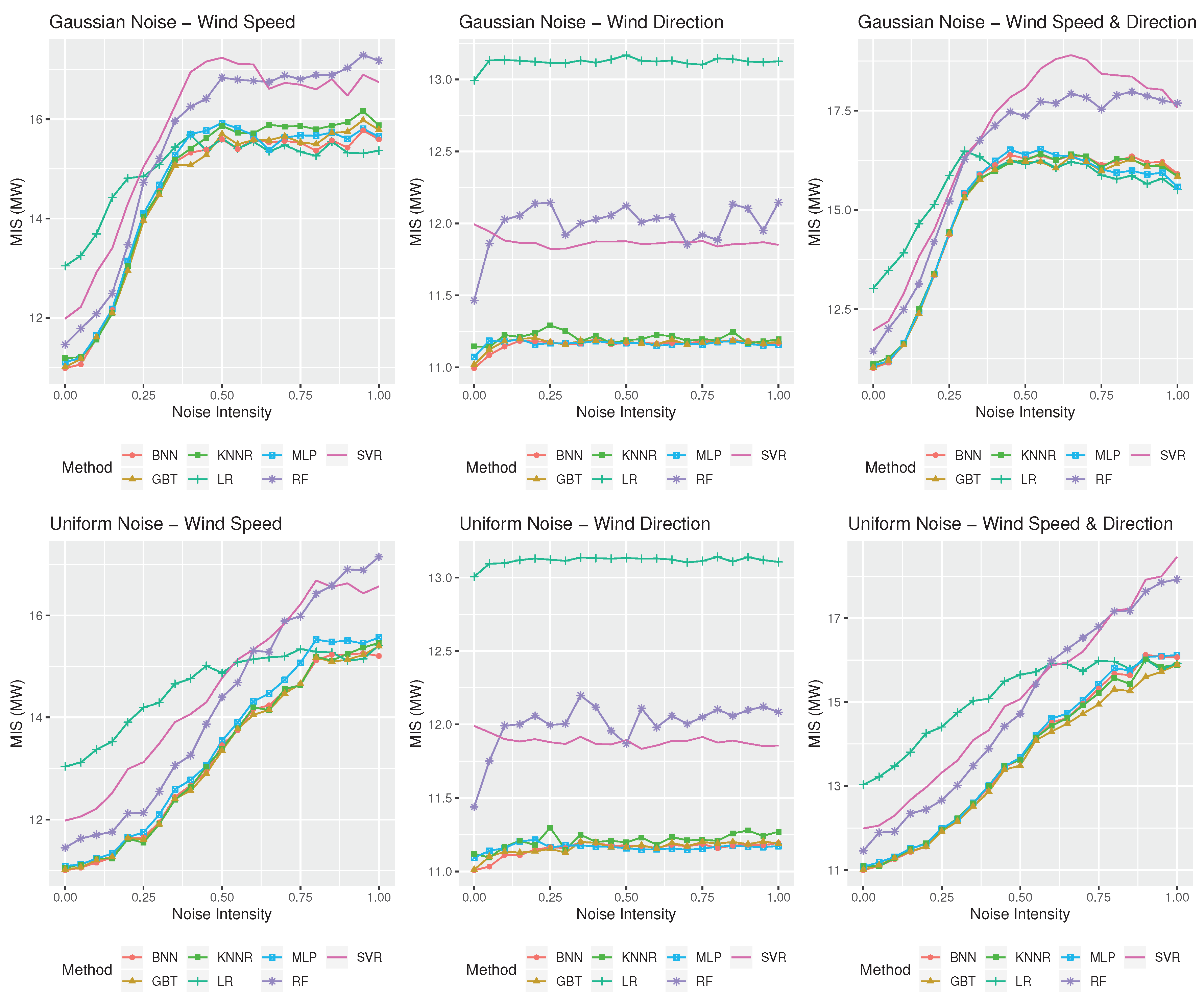
3.3. Results
4. Discussion
5. Conclusions
- The “forecasting horserace” should be expanded to include more methods and accuracy measures;
- Given that the examined dataset includes two predictor variables, i.e., wind speed and direction, bivariate models, inspired by econometric approaches, like VAR models, should be explored;
- “When in doubt combine”: combinations of all (or the top-three methods) for each forecast case should be tested (for both point forecasts and prediction intervals). Alternatively, one could try to go for a clever selection algorithm in between those ML and statistical methods (see for example [59]), or even hybrid approaches [60];
- Temporal aggregation is always a way to self-improve any forecasting method (times series or cross-sectional) and this alternative should be employed in any context, especially when it involves a lot of uncertainty or complexity [61]. This could be achieved either via selecting a single aggregation level [62] or via combining the forecasts produced for multiple aggregation levels [63];
- The provided forecasts should be evaluated “on the money” with real-life (and asymmetric) utility functions.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| BNN | Bayesian Neural Network |
| GBT | Gradient Boosting Trees |
| KNNR | K-Nearest Neighbor Regression |
| LR | Linear Regression |
| ML | Machine Learning |
| NN | Neural Network |
| MLP | Multi-Layer Perceptron |
| RF | Random Forest |
| RT | Regression Tree |
| SVM | Support Vector Machine |
| SVR | Support Vector Regression |
References
- Cai, L.; Gu, J.; Ma, J.; Jin, Z. Probabilistic Wind Power Forecasting Approach via Instance-Based Transfer Learning Embedded Gradient Boosting Decision Trees. Energies 2019, 12, 159. [Google Scholar] [CrossRef] [Green Version]
- Bojer, C.; Meldgaard, J. Learnings from Kaggle’s Forecasting Competitions. Work. Paper 2020. [Google Scholar] [CrossRef]
- Jeon, J.; Panagiotelis, A.; Petropoulos, F. Probabilistic forecast reconciliation with applications to wind power and electric load. Eur. J. Oper. Res. 2019. [Google Scholar] [CrossRef]
- Agüera-Pérez, A.; Palomares-Salas, J.C.; González de la Rosa, J.J.; Florencias-Oliveros, O. Weather forecasts for microgrid energy management: Review, discussion and recommendations. Appl. Energy 2018, 228, 265–278. [Google Scholar] [CrossRef]
- Shi, J.; Qu, X.; Zeng, S. Short-Term Wind Power Generation Forecasting: Direct Versus Indirect Arima-Based Approaches. Int. J. Green Energy 2011, 8, 100–112. [Google Scholar] [CrossRef]
- Jeon, J.; Taylor, J.W. Using Conditional Kernel Density Estimation for Wind Power Density Forecasting. J. Am. Stat. Assoc. 2012, 107, 66–79. [Google Scholar] [CrossRef] [Green Version]
- Cheng, W.Y.Y.; Liu, Y.; Bourgeois, A.J.; Wu, Y.; Haupt, S.E. Short-term wind forecast of a data assimilation/weather forecasting system with wind turbine anemometer measurement assimilation. Renew. Energy 2017, 107, 340–351. [Google Scholar] [CrossRef]
- Zhang, W.; Maleki, A.; Rosen, M.A.; Liu, J. Sizing a stand-alone solar-wind-hydrogen energy system using weather forecasting and a hybrid search optimization algorithm. Energy Convers. Manag. 2019, 180, 609–621. [Google Scholar] [CrossRef]
- Dupré, A.; Drobinski, P.; Alonzo, B.; Badosa, J.; Briard, C.; Plougonven, R. Sub-hourly forecasting of wind speed and wind energy. Renew. Energy 2020, 145, 2373–2379. [Google Scholar] [CrossRef]
- Hong, T.; Wang, P.; White, L. Weather station selection for electric load forecasting. Int. J. Forecast. 2015, 31, 286–295. [Google Scholar] [CrossRef]
- Lai, S.H.; Hong, T. When One Size No Longer Fits All: Electric Load Forecasting with a Geographic Hierarchy; SAS White Paper; SAS: Cary, NC, USA, 2013. [Google Scholar]
- Barbounis, T.G.; Theocharis, J.B.; Alexiadis, M.C.; Dokopoulos, P.S. Long-term wind speed and power forecasting using local recurrent neural network models. IEEE Trans. Energy Convers. 2006, 21, 273–284. [Google Scholar] [CrossRef]
- Sun, W.; Liu, M. Wind speed forecasting using FEEMD echo state networks with RELM in Hebei, China. Energy Convers. Manag. 2016, 114, 197–208. [Google Scholar] [CrossRef]
- Al-Zadjali, S.; Al Maashri, A.; Al-Hinai, A.; Al-Yahyai, S.; Bakhtvar, M. An Accurate, Light-Weight Wind Speed Predictor for Renewable Energy Management Systems. Energies 2019, 12, 4355. [Google Scholar] [CrossRef] [Green Version]
- Ren, Y.; Li, H.; Lin, H.C. Optimization of Feedforward Neural Networks Using an Improved Flower Pollination Algorithm for Short-Term Wind Speed Prediction. Energies 2019, 12, 4126. [Google Scholar] [CrossRef] [Green Version]
- Cassola, F.; Burlando, M. Wind speed and wind energy forecast through Kalman filtering of Numerical Weather Prediction model output. Appl. Energy 2012, 99, 154–166. [Google Scholar] [CrossRef]
- Ding, M.; Zhou, H.; Xie, H.; Wu, M.; Nakanishi, Y.; Yokoyama, R. A gated recurrent unit neural networks based wind speed error correction model for short-term wind power forecasting. Neurocomputing 2019, 365, 54–61. [Google Scholar] [CrossRef]
- Sun, S.; Fu, J.; Li, A. A Compound Wind Power Forecasting Strategy Based on Clustering, Two-Stage Decomposition, Parameter Optimization, and Optimal Combination of Multiple Machine Learning Approaches. Energies 2019, 12, 3586. [Google Scholar] [CrossRef] [Green Version]
- Demolli, H.; Dokuz, A.S.; Ecemis, A.; Gokcek, M. Wind power forecasting based on daily wind speed data using machine learning algorithms. Energy Convers. Manag. 2019, 198, 111823. [Google Scholar] [CrossRef]
- Liu, H.; Shi, J.; Erdem, E. An Integrated Wind Power Forecasting Methodology: Interval Estimation of Wind Speed, Operation Probability Of Wind Turbine, And Conditional Expected Wind Power Output of A Wind Farm. Int. J. Green Energy 2013, 10, 151–176. [Google Scholar] [CrossRef]
- Liu, H.; Shi, J.; Qu, X. Empirical investigation on using wind speed volatility to estimate the operation probability and power output of wind turbines. Energy Convers. Manag. 2013, 67, 8–17. [Google Scholar] [CrossRef]
- Salfate, I.; López-Caraballo, C.H.; Sabín-Sanjulián, C.; Lazzús, J.A.; Vega, P.; Cuturrufo, F.; Marín, J. 24-hours wind speed forecasting and wind power generation in La Serena (Chile). Wind Eng. 2018, 42, 607–623. [Google Scholar] [CrossRef]
- Makridakis, S.; Spiliotis, E.; Assimakopoulos, V. Statistical and Machine Learning forecasting methods: Concerns and ways forward. PLoS ONE 2018, 13, e0194889. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Spiliotis, E.; Nikolopoulos, K.; Assimakopoulos, V. Tales from tails: On the empirical distributions of forecasting errors and their implication to risk. Int. J. Forecast. 2019, 35, 687–698. [Google Scholar] [CrossRef]
- Kohavi, R. A Study of Cross-Validation and Bootstrap for Accuracy Estimation and Model Selection. In The 14th International Joint Conference on Artificial Intelligence; Morgan Kaufmann: San Francisco, CA, USA, 1995; Volume 2, pp. 1137–1143. [Google Scholar]
- Zhang, G.; Patuwo, B.E.; Hu, M.Y. Forecasting with artificial neural networks: The state of the art. Int. J. Forecast. 1998, 14, 35–62. [Google Scholar] [CrossRef]
- Lippmann, R.P. An Introduction to Computing with Neural Nets. IEEE ASSP Mag. 1987, 4, 4–22. [Google Scholar] [CrossRef]
- Møller, M.F. A scaled conjugate gradient algorithm for fast supervised learning. Neural Netw. 1993, 6, 525–533. [Google Scholar] [CrossRef]
- Kourentzes, N.; Barrow, D.K.; Crone, S.F. Neural network ensemble operators for time series forecasting. Expert Syst. Appl. 2014, 41, 4235–4244. [Google Scholar] [CrossRef] [Green Version]
- Bergmeir, C.; Benítez, J.M. Neural Networks in R Using the Stuttgart Neural Network Simulator: RSNNS. J. Stat. Softw. 2012, 46, 1–26. [Google Scholar] [CrossRef] [Green Version]
- MacKay, D.J.C. Bayesian Interpolation. Neural Comput. 1992, 4, 415–447. [Google Scholar] [CrossRef]
- Dan Foresee, F.; Hagan, M.T. Gauss-Newton approximation to bayesian learning. In Proceedings of the IEEE International Conference on Neural Networks, Houston, TX, USA, 12 June 1997; Volume 3, pp. 1930–1935. [Google Scholar] [CrossRef]
- Nguyen, D.; Widrow, B. Improving the learning speed of 2-layer neural networks by choosing initial values of the adaptive weights. IJCNN Int. Jt. Conf. Neural Netw. 1990, 13, 21–26. [Google Scholar] [CrossRef]
- Rodriguez, P.P.; Gianola, D. brnn: Bayesian Regularization for Feed-Forward Neural Networks. 2018. R Package Version 0.7. Available online: https://CRAN.R-project.org/package=brnn (accessed on 15 February 2020).
- Breiman, L. Classification and Regression Trees; Chapman & Hall: Boca Raton, FL, USA, 1993. [Google Scholar]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Liaw, A.; Wiener, M. Classification and Regression by randomForest. R News 2002, 2, 18–22. [Google Scholar]
- Freund, Y.; Schapire, R.E. A Decision-Theoretic Generalization of On-Line Learning and an Application to Boosting. J. Comput. Syst. Sci. 1997, 55, 119–139. [Google Scholar] [CrossRef] [Green Version]
- Friedman, J.H. Stochastic gradient boosting. Comput. Stat. Data Anal. 2002, 38, 367–378. [Google Scholar] [CrossRef]
- Greenwell, B.; Boehmke, B.; Cunningham, J.; Developers, G. gbm: Generalized Boosted Regression Models. 2019. R Package Version 2.1.5. Available online: https://CRAN.R-project.org/package=gbm (accessed on 15 February 2020).
- Kuhn, M. Caret: Classification and Regression Training. 2018. R Package Version 6.0-81. Available online: https://CRAN.R-project.org/package=caret (accessed on 15 February 2020).
- Schölkopf, B.; Smola, A.J. Learning with kernel: Support Vector Machines, Regularization, Optimization and Beyond; The MIT Press: Cambridge, MA, USA, 2001. [Google Scholar]
- Meyer, D.; Dimitriadou, E.; Hornik, K.; Weingessel, A.; Leisch, F. e1071: Misc Functions of the Department of Statistics, Probability Theory Group (Formerly: E1071), TU Wien. 2019. R Package Version 1.7-1. Available online: https://CRAN.R-project.org/package=e1071 (accessed on 15 February 2020).
- Vahidzadeh, M.; Markfort, C.D. An Induction Curve Model for Prediction of Power Output of Wind Turbines in Complex Conditions. Energies 2020, 13, 891. [Google Scholar] [CrossRef] [Green Version]
- Luo, J.; Hong, T.; Fang, S.C. Benchmarking robustness of load forecasting models under data integrity attacks. Int. J. Forecast. 2018, 34, 89–104. [Google Scholar] [CrossRef]
- Khosravi, A.; Nahavandi, S.; Creighton, D.; Atiya, A.F. Comprehensive Review of Neural Network-Based Prediction Intervals and New Advances. IEEE Trans. Neural Netw. 2011, 22, 1341–1356. [Google Scholar] [CrossRef]
- Spiliotis, E.; Assimakopoulos, V.; Makridakis, S. Generalizing the Theta method for automatic forecasting. Eur. J. Oper. Res. 2020. [Google Scholar] [CrossRef]
- Efron, B. Bootstrap methods: Another look at the jackknife. Ann. Stat. 1979, 7, 1–26. [Google Scholar] [CrossRef]
- Heskes, T. Practical confidence and prediction intervals. Neural Inf. Process. Syst. 1997, 9, 176–182. [Google Scholar]
- Gneiting, T.; Raftery, A. Strictly proper scoring rules, prediction, and estimation. J. Am. Stat. Assoc. 2007, 102, 359–378. [Google Scholar] [CrossRef]
- Makridakis, S.; Spiliotis, E.; Assimakopoulos, V. The M4 Competition: 100,000 time series and 61 forecasting methods. Int. J. Forecast. 2020, 36, 54–74. [Google Scholar] [CrossRef]
- Yu, X.; Zhang, W.; Zang, H.; Yang, H. Wind Power Interval Forecasting Based on Confidence Interval Optimization. Energies 2018, 11, 3336. [Google Scholar] [CrossRef] [Green Version]
- Petropoulos, F.; Makridakis, S.; Assimakopoulos, V.; Nikolopoulos, K. ‘Horses for Courses’ in demand forecasting. Eur. J. Oper. Res. 2014, 237, 152–163. [Google Scholar] [CrossRef] [Green Version]
- Nikolopoulos, K.; Petropoulos, F. Forecasting for big data: Does suboptimality matter? Comput. Oper. Res. 2018, 98, 322–329. [Google Scholar] [CrossRef] [Green Version]
- Makridakis, S.; Hyndman, R.J.; Petropoulos, F. Forecasting in social settings: The state of the art. Int. J. Forecast. 2020, 36, 15–28. [Google Scholar] [CrossRef]
- Kim, Y.; Hur, J. An Ensemble Forecasting Model of Wind Power Outputs based on Improved Statistical Approaches. Energies 2020, 13, 1071. [Google Scholar] [CrossRef] [Green Version]
- Petropoulos, F.; Svetunkov, I. A simple combination of univariate models. Int. J. Forecast. 2020, 36, 110–115. [Google Scholar] [CrossRef]
- Kourentzes, N.; Barrow, D.; Petropoulos, F. Another look at forecast selection and combination: Evidence from forecast pooling. Int. J. Prod. Econ. 2019, 209, 226–235. [Google Scholar] [CrossRef] [Green Version]
- Nikolopoulos, K. Forecasting with quantitative methods: The impact of special events in time series. Appl. Econ. 2010, 42, 947–955. [Google Scholar] [CrossRef]
- Shi, J.; Guo, J.; Zheng, S. Evaluation of hybrid forecasting approaches for wind speed and power generation time series. Renew. Sustain. Energy Rev. 2012, 16, 3471–3480. [Google Scholar] [CrossRef]
- Spiliotis, E.; Petropoulos, F.; Kourentzes, N.; Assimakopoulos, V. Cross-temporal aggregation: Improving the forecast accuracy of hierarchical electricity consumption. Appl. Energy 2020, 261, 114339. [Google Scholar] [CrossRef]
- Nikolopoulos, K.; Syntetos, A.A.; Boylan, J.E.; Petropoulos, F.; Assimakopoulos, V. An aggregate–disaggregate intermittent demand approach (ADIDA) to forecasting: An empirical proposition and analysis. J. Oper. Res. Soc. 2011, 62, 544–554. [Google Scholar] [CrossRef] [Green Version]
- Kourentzes, N.; Petropoulos, F.; Trapero, J.R. Improving forecasting by estimating time series structural components across multiple frequencies. Int. J. Forecast. 2014, 30, 291–302. [Google Scholar] [CrossRef] [Green Version]








© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Spiliotis, E.; Petropoulos, F.; Nikolopoulos, K. The Impact of Imperfect Weather Forecasts on Wind Power Forecasting Performance: Evidence from Two Wind Farms in Greece. Energies 2020, 13, 1880. https://doi.org/10.3390/en13081880
Spiliotis E, Petropoulos F, Nikolopoulos K. The Impact of Imperfect Weather Forecasts on Wind Power Forecasting Performance: Evidence from Two Wind Farms in Greece. Energies. 2020; 13(8):1880. https://doi.org/10.3390/en13081880
Chicago/Turabian StyleSpiliotis, Evangelos, Fotios Petropoulos, and Konstantinos Nikolopoulos. 2020. "The Impact of Imperfect Weather Forecasts on Wind Power Forecasting Performance: Evidence from Two Wind Farms in Greece" Energies 13, no. 8: 1880. https://doi.org/10.3390/en13081880