Prediction of Air-Conditioning Energy Consumption in R&D Building Using Multiple Machine Learning Techniques

Abstract
:
1. Introduction
2. CTIC Background Information
2.1. Building Information
2.1.1. Location
2.1.2. Mission and Main Functions
2.1.3. Building Features
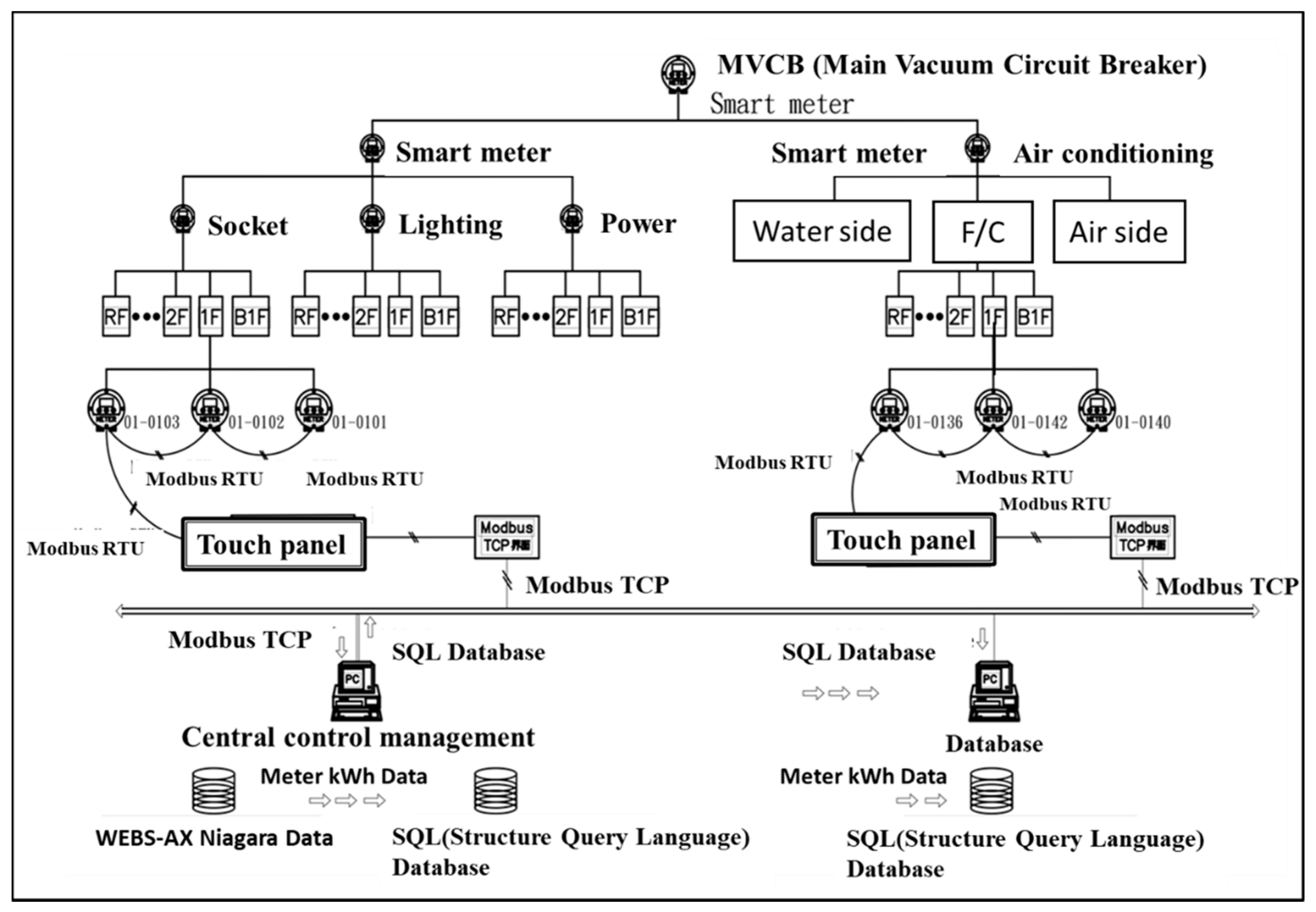
2.1.4. Building Energy Management System
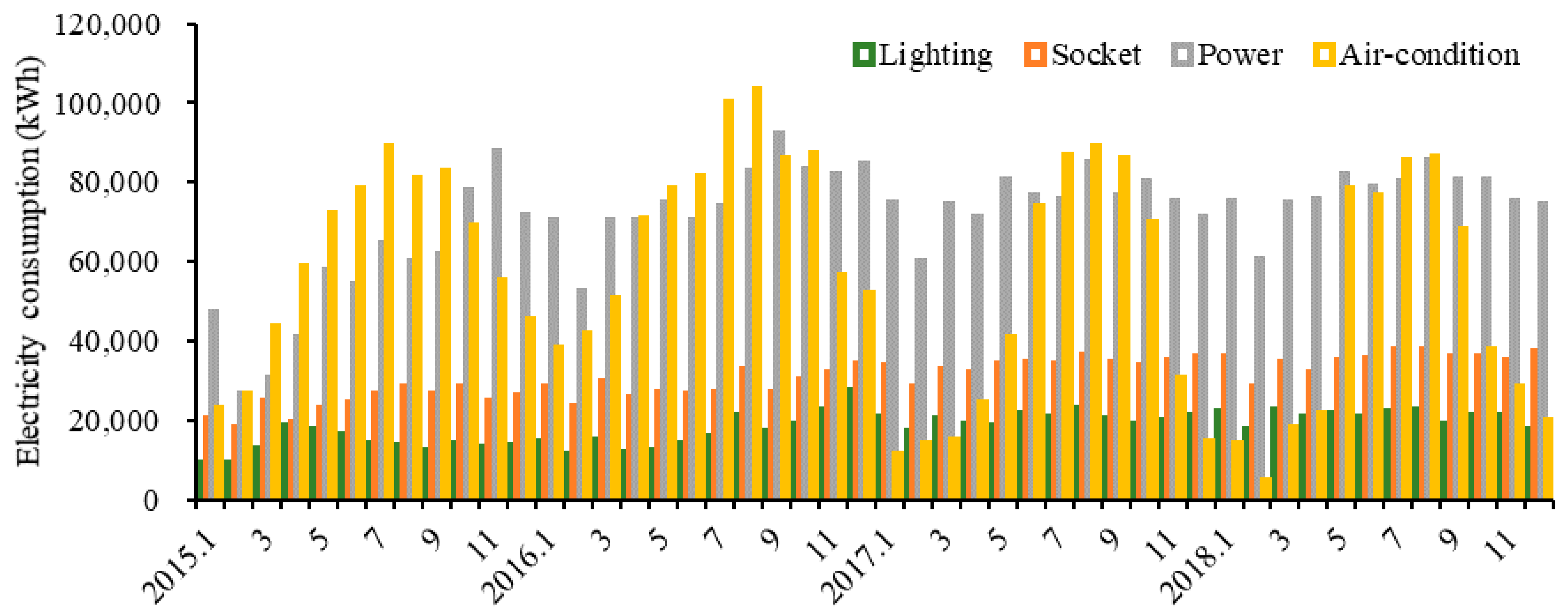
2.2. Electricity Consumption Data
2.3. Energy Consumption Factors
3. Research Methodology
3.1. Linear Regression
3.2. Earlier Machine Learning
3.2.1. Random Forest
3.2.2. Support Vector Machine
3.2.3. Multilayer Perceptron
3.3. Deep Learning
3.3.1. Deep Neural Network
3.3.2. Recurrent Neural Network
3.3.3. Long Short-Term Memory
3.3.4. Gated Recurrent Unit
3.4. Model Constructing and Data Processing
4. Data Analysis, Results, and Discussion
4.1. Factor Screening and Parameter Calibration
4.2. Model Results and Comparison
4.3. Prediction
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| Order | Abbreviation | Full Form |
| 1 | BEM | Building energy management |
| 2 | BIM | Building information modeling |
| 3 | CC | Correlation coefficient |
| 4 | CE | Coefficient of efficiency |
| 5 | CTIC | Central Taiwan Innovation Campus |
| 6 | DL | Deep learning |
| 7 | EBC | Energy in Buildings and Communities |
| 8 | GRU | Gated recurrent unit |
| 9 | ICT | Information and communications technologies |
| 10 | IEA | International Energy Agency |
| 11 | ITRI | Industrial Technology Research Institute |
| 12 | Lbfgs | Limited-memory broyden–fletcher–goldfarb–shanno algorithm |
| 13 | LN | Linear kernel fuction |
| 14 | LSTM | Long short-term memory |
| 15 | MAE | Mean absolute error |
| 16 | MLP | Machine learning |
| 17 | MLP | Multilayer perceptron |
| 18 | MSLE | Mean squared logarithmic error |
| 19 | NN | Neural network |
| 20 | OOB | Out of bag |
| 21 | PL | Polynomial kernel fuction |
| 22 | R&D | Research and development |
| 23 | R2 | Determination coefficient |
| 24 | RBF | Radial basis function kernel function |
| 25 | RBM | Boltzmann machine |
| 26 | Relu | Rectified linear unit |
| 27 | RF | Random forest |
| 28 | RMSE | Root mean square error |
| 29 | RMSprop | Root mean square propagation |
| 30 | RNN | Recurrent neural network |
| 31 | Sgd | Stochastic gradient descent |
| 32 | SIG | Sigmoid kernel fuction |
| 33 | Sqrt | Square root of a number of inputs |
References
- British Petroleum. Statistical Review of World Energy. p. 2. Available online: https://www.bp.com/content/dam/bp/business-sites/en/global/corporate/pdfs/energy-economics/statistical-review/bp-stats-review-2019-full-report.pdf (accessed on 1 March 2020).
- International Energy Agency (IEA). World Energy Outlook 2019. Available online: http://www.worldenergyoutlook.org/ (accessed on 1 March 2020).
- Ministry of Economic Affairs Bureau of Energy. Ministry of Economic Affairs 2019 Annual Report; Taiwan. Available online: https://www.moea.gov.tw/MNS/english/home/English.aspx (accessed on 1 March 2020).
- Architecture and Building Research Institute. Collaborative research project on innovative low-Carbon green building environmental technology plan–Research on Guiding Principles of Sub-metering Design of Building Electricity System; Architecture and Building Research Institute: New Taipei City, Taiwan, 2015; p. 1. [Google Scholar]
- Cho, S.; Lee, J.; Baek, J.; Kim, G.S.; Leigh, S.B. Investigating Primary Factors A_ecting Electricity Consumption in Non-Residential Buildings Using a Data-Driven Approach. Energies 2019, 12, 4046. [Google Scholar] [CrossRef] [Green Version]
- Zhou, J.; Huo, X.; Xu, X.; Li, Y. Forecasting the Carbon Price Using Extreme-Point Symmetric Mode Decomposition and Extreme Learning Machine Optimized by the Grey Wolf Optimizer Algorithm. Energies 2019, 12, 950. [Google Scholar] [CrossRef] [Green Version]
- Underwood, C.P.; Yik, F.W.H. Modeling Methods for Energy in Buildings; Blackwell Science: Oxford, UK, 2004. [Google Scholar]
- Paudel, S.; Elmitri, M.; Couturier, S.; Nguyen, P.H.; Kamphuis, R.; Lacarrière, B.; Le Corre, O. A relevant data selection method for energy consumption prediction of low energy building based on support vector machine. Energy Build. 2017, 138, 240–256. [Google Scholar] [CrossRef]
- Kristopher, T.W.; Juan, D.G. Predicting future monthly residential energy consumption using building characteristics and climate data: A statistical learning approach. Energy Build. 2016, 128, 1–11. [Google Scholar]
- Molina-Solana, M.; Ros, M.; Ruiz, M.D.; Gómez-Romero, J.; Martín-Bautista, M.J. Data science for building energy management: A review. Renew. Sustain. Energy Rev. 2017, 70, 598–609. [Google Scholar] [CrossRef] [Green Version]
- Jang, J.; Lee, J.; Son, E.; Park, K.; Kim, G.; Lee, J.H.; Leigh, S.B. Development of an Improved Model to Predict Building Thermal Energy Consumption by Utilizing Feature Selection. Energies 2019, 12, 4187. [Google Scholar] [CrossRef] [Green Version]
- Khalil, A.J.; Barhoom, A.M.; Abu-Nasser, B.S.; Musleh, M.M.; Abu-Naser, S.S. Energy Efficiency Predicting using Artificial Neural Network. Int. J. Acad. Pedagog. Res. 2019, 3, 1–7. [Google Scholar]
- Mocanu, E.; Nguyen, P.H.; Gibescu, M.; Kling, W.L. Deep learning for estimating building energy consumption. Sustain. Energy Grids Netw. 2016, 6, 91–99. [Google Scholar] [CrossRef]
- Marino, D.L.; Amarasinghe, K.; Manic, M. Building energy load forecasting using deep neural networks. In Proceedings of the IECON 2016–42nd Annual Conference of the IEEE Industrial Electronics Society, Florence, Italy, 24–27 October 2016. [Google Scholar]
- Liu, B.; Fu, C.; Bielefield, A.; Liu, Y.Q. Forecasting of Chinese primary energy consumption in 2021 with GRU artificial neural network. Energies 2017, 10, 1453. [Google Scholar] [CrossRef]
- Taiwan Architecture and Building Center. Grading Book; Taiwan; Available online: https://eewh.tw/ (accessed on 1 March 2020).
- Hiroshi Yoshino. Final Report Annex 53–Total Energy Use in Buildings–Analysis and Evaluation Methods; Institute for Building Environment and Energy Conservation: Kojimachi, Tokyo, 2013. [Google Scholar]
- Deb, C.; Zhang, F.; Yang, J.; Lee, S.E.; Shah, K.W. A review on time series forecasting techniques for building energy consumption. Renew. Sustain. Energy Rev. 2017, 74, 902–924. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Liu, C.B.; Chamberlain, B.P.; Little, D.A.; Cardoso, Â. Generalising random forest parameter optimisation to include stability and cost. In Joint European Conference on Machine Learning and Knowledge Discovery in Databases; Springer: Skopje, Macedonia, September 2017. [Google Scholar]
- Peters, J.; Baets, B.D.; Verhoest, N.E.C.; Samson, R.; Degroeve, S.; Becker, P.D.; Huybrechts, W. Random forests as a tool for ecohydrological distribution modeling. Ecol. Modell. 2007, 207, 304–318. [Google Scholar] [CrossRef]
- Naghibi, S.A.; Pourghasemi, H.R.; Dixon, B. GIS-Based groundwater potential mapping using boosted regression tree, classification and regression tree, and random forest machine learning models in Iran. Environ. Monit. Assess. 2016, 188, 44. [Google Scholar] [CrossRef] [PubMed]
- Pourghasemi, H.R.; Kerle, N. Random forests and evidential belief function-based landslide susceptibility assessment in Western Mazandaran Province, Iran. Environ. Earth Sci. 2016, 75, 185. [Google Scholar] [CrossRef]
- Brad, J.F. An efficient point algorithm for a linear two-Stage optimization problem. Oper. Res. 1983, 31, 670–684. [Google Scholar] [CrossRef]
- Zhao, L.; Zha, Y.; Zhuang, Y.; Liang, L. Data envelopment analysis for sustainability evaluation in China: Tackling the economic, environmental, and social dimensions. Eur. J. Oper. Res. 2019, 275, 1083–1095. [Google Scholar] [CrossRef]
- Vapnik, V.N. The Nature of Statistical Learning Theory; Springer: New York, NY, USA, 1995. [Google Scholar]
- Cristianini, N.; Shaw–Taylor, J. An Introduction to Support Vector Machines and Other Kernel-Based Learning Methods; Cambridge University Press: New York, NY, USA, 2000. [Google Scholar]
- Chang, M.J.; Chang, H.K.; Chen, Y.C.; Lin, G.F.; Chen, P.A.; Lai, J.S.; Tan, Y.C. A Support Vector Machine Forecasting Model for Typhoon Flood Inundation Mapping and Early Flood Warning Systems. Water 2018, 10, 1734. [Google Scholar] [CrossRef] [Green Version]
- Lin, G.F.; Chang, M.J.; Huang, Y.C.; Ho, J.Y. Assessment of susceptibility to rainfall-induced landslides using improved self-Organizing linear output map, support vector machine, and logistic regression. Eng. Geol. 2017, 224, 62–74. [Google Scholar] [CrossRef]
- Trigila, A.; Iadanza, C.; Esposito, C.; Scarascia-Mugnozza, G. Comparison of Logistic Regression and Random Forests techniques for shallow landslide susceptibility assessment in Giampilieri (NE Sicily, Italy). Geomorphology 2015, 249, 119–136. [Google Scholar] [CrossRef]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning internal representations by backpropagating errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- Hinton, G.; Salakhutdinov, R. Reducing the dimensionality of data with neural networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Nair, V.; Hinton, G.E. Rectified linear units improve restricted boltzmann machines. In Proceedings of the 27th international conference on machine learning (ICML-10), Haifa, Israel, 21–24 June 2010. [Google Scholar]
- Bottou, L. Large-Scale machine learning with stochastic gradient descent. In Proceedings of the COMPSTAT’2010: 19th International Conference on Computational Statistics, Paris, France, 22–27 August 2010; pp. 177–186. [Google Scholar]
- Elman, J.L. Finding structure in time. Wiley Interdiscip. Rev. Cognit. Sci. 1990, 14, 179–211. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-Term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Cho, K.; Van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder-Decoder for statistical machine translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]
- Lin, G.F.; Chang, M.J.; Wu, J.T. A hybrid statistical downscaling method based on the classification of rainfall patterns. Water Resour. Manag. 2017, 31, 377–401. [Google Scholar] [CrossRef]
- Wang, J.H.; Lin, G.F.; Chang, M.J.; Huang, I.H.; Chen, Y.R. Real-Time water-Level forecasting using dilated causal convolutional neural networks. Water Resour. Manag. 2019, 33, 3759–3780. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Space | Public Space (53.3%) | Independent Space (46.7%) | |||||
|---|---|---|---|---|---|---|---|
| Parking Lot | Service | Office | Laboratory | Pilot Plant | Conference | Total | |
| Room | 1 | 238 | 59 | 65 | 14 | 9 | 383 |
| Area (m2) | 6133 | 10,906 | 6003 | 4987 | 1971 | 1967 | 31,967 |
| Order | Room | Floor Area | Floor | Orientation | Space Category | Maximum Monthly Electricity Consumption |
|---|---|---|---|---|---|---|
| R1 | A110 | 175 | 1 | 1 | office | 2803.8 |
| R2 | A315 | 136 | 3 | 1 | office | 4921.8 |
| R3 | A316 | 84 | 3 | 1 | office | 2068.0 |
| R4 | B220 | 158 | 2 | 3 | office | 2023.2 |
| R5 | B230 | 80 | 2 | 2 | office | 1615.6 |
| R6 | B231 | 76 | 2 | 2 | office | 1530.5 |
| R7 | B237 | 53 | 2 | 4 | office | 1907.2 |
| R8 | B301 | 520 | 3 | 1 | office | 6310.0 |
| R9 | B303 | 63 | 3 | 4 | office | 568.0 |
| R10 | B304 | 59 | 3 | 4 | office | 1331.7 |
| R11 | B318 | 169 | 3 | 4 | office | 1842.7 |
| R12 | B329 | 45 | 3 | 2 | office | 544.3 |
| R13 | B410 | 56 | 4 | 4 | office | 1214.0 |
| R14 | B430 | 57 | 4 | 3 | office | 1052.1 |
| R15 | B447 | 52 | 4 | 4 | office | 281.4 |
| R16 | A108 | 161 | 1 | 1 | laboratory | 1962.8 |
| R17 | A121 | 138 | 1 | 1 | laboratory | 17,517.9 |
| R18 | A323 | 75 | 3 | 4 | laboratory | 1090.3 |
| R19 | A324 | 83 | 3 | 4 | laboratory | 1634.8 |
| R20 | B223 | 93 | 2 | 3 | laboratory | 1978.1 |
| R21 | B408 | 76 | 4 | 4 | laboratory | 1283.3 |
| R22 | B421 | 52 | 4 | 4 | laboratory | 321.0 |
| R23 | B423 | 56 | 4 | 1 | laboratory | 950.4 |
| R24 | B425 | 50 | 4 | 1 | laboratory | 1052.1 |
| R25 | B439 | 84 | 4 | 2 | laboratory | 822.4 |
| R26 | B441 | 38 | 4 | 2 | laboratory | 1148.0 |
| R27 | B445 | 49 | 4 | 2 | laboratory | 731.8 |
| R28 | B446 | 53 | 4 | 2 | laboratory | 697.3 |
| R29 | B102 | 149 | 1 | 1 | pilot plant | 1586.3 |
| R30 | B104 | 67 | 1 | 1 | pilot plant | 1533.7 |
| R31 | B114 | 217 | 1 | 1 | pilot plant | 9023.3 |
| Category | Factor | Explanation |
|---|---|---|
| Outdoor environmental factor | Air pressure | Monthly average pressure |
| Temperature | Average temperature during monthly working hours (8:00–18:00) | |
| Humidity | Average humidity during monthly working hours (8:00–18:00) | |
| Wind speed | Monthly average wind speed | |
| Rainfall | Monthly average rainfall | |
| Sunshine hours | Monthly average hours of sunshine | |
| Wet bulb temperature | Temperature recorded by a thermometer that has its bulb wrapped in cloth and moistened with distilled water | |
| Season | Spring (March, April, May), Summer (June, July, August), Autumn (September, October, November) and Winter (December, January, February) | |
| Month | January–December | |
| Building characteristics | Floor area | Area of each room |
| Floor location | Ground, middle and roof | |
| Orientation | 1, 2, 3 and 4 | |
| Use behavior | Days of use | Working days of the month |
| Model | Parameter | ||||||
|---|---|---|---|---|---|---|---|
| SVM | Kernel function | Gamma | Cost | Epsilon | Degree | ||
| RBF, LN, PL, SIG | (2−7, 27, 2) | (2−7, 27, 2) | (2−7, 27, 2) | (2, 3, 1) | |||
| RF | Number of trees | Max feature | |||||
| (50, 1000, 50) | All inputs, Sqrt | ||||||
| MLP | Hidden layer | Activation | Optimizer | Batch | Initial learning rate | ||
| {[8]}, {[16]}, {[32]}, {[64]}, {[128]}, {[256]}, {[512]} | Tanh, Relu | Adam, Sgd, Lbfgs | 200 | 0.001, 0.0001 | |||
| DNN RNN GRU LSTM | Hidden layer | Activation | Optimizer | Batch | Dropout | Epoch | Loss |
| {[32]}, {[64]}, {[128]}, {[256]}, {[512]} | Tanh, Relu | Nadam, Adam, Rmsprop | 32, 64, 128 | 80%, 90%, 100% | 30, 50 | MAE, MSLE | |
| {[32], [64]}, {[64], [128]}, {[128], [256]} | |||||||
| {[32], [64], [128]}, {[64], [128], [256]} | |||||||
| {[32], [64], [128], [256]}, {[64], [128], [256], [512]} | |||||||
| {[32], [64], [128], [256], [512]} | |||||||
| Input | Lag Length | ||
|---|---|---|---|
| t | t − 1 | t − 2 | |
| Monthly mean temperature | 1 | 1 | 1 |
| Monthly mean humidity | 1 | 1 | 1 |
| Season | 1 | ||
| Floor area | 1 | ||
| Floor location | 1 | ||
| Orientation | 1 | ||
| Air-conditioning electricity consumption | 1 | 1 | 1 |
| Model | Parameter | ||||||
|---|---|---|---|---|---|---|---|
| SVM | Kernel function | Gamma | Cost | Epsilon | Degree | ||
| RBF | 2 | 0.5 | 0.00781 | − | |||
| RF | Number of trees | Max feature | Max depth | ||||
| 350 | Number of inputs | 22 | |||||
| MLP | Hidden layer | Activation | Optimizer | Batch | Initial learning rate | ||
| {[256]} | Relu | Lbfgs | 200 | 0.0001 | |||
| Hidden layer | Activation | Optimizer | Batch | Dropout | Epoch | Loss | |
| DNN | {[32], [64], [128]} | Relu | Rmsprop | 32 | 100% | 300 | MSLE |
| RNN | {[64], [128]} | ||||||
| GRU | {[128], [256]} | ||||||
| LSTM | {[32], [64]} | ||||||
| Model | Training Phase | Testing Phase | ||||||
|---|---|---|---|---|---|---|---|---|
| RMSE | MAE | CE | R2 | RMSE | MAE | CE | R2 | |
| LR | 404.7 | 288.8 | −0.21 | 0.42 | 309.8 | 230.6 | −6.14 | 0.57 |
| MLP | 272.9 | 202.2 | 0.27 | 0.53 | 267.5 | 209 | −3.19 | 0.57 |
| SVM | 352.4 | 230.9 | 0.45 | 0.6 | 246 | 187.5 | −1.85 | 0.77 |
| RF | 131.6 | 87.9 | 0.92 | 0.94 | 189.8 | 141.4 | 0.75 | 0.88 |
| DNN | 157.5 | 113.5 | 0.66 | 0.77 | 239.5 | 182.4 | −0.56 | 0.7 |
| RNN | 150.3 | 108.7 | 0.76 | 0.81 | 221.5 | 174.9 | −0.95 | 0.73 |
| LSTM | 249.5 | 175.7 | 0.49 | 0.63 | 244 | 190.2 | −0.45 | 0.73 |
| GRU | 118.4 | 86.4 | 0.82 | 0.87 | 202.3 | 152.1 | −1.23 | 0.76 |
| Lead Time | Training Phase | Testing Phase | ||||||
|---|---|---|---|---|---|---|---|---|
| RMSE | MAE | CE | R2 | RMSE | MAE | CE | R2 | |
| 1 | 131.6 | 87.9 | 0.92 | 0.94 | 189.8 | 141.4 | 0.75 | 0.88 |
| 2 | 148.8 | 99.0 | 0.92 | 0.93 | 230.5 | 180.7 | 0.52 | 0.84 |
| 3 | 157.4 | 108.4 | 0.91 | 0.93 | 267.6 | 212.2 | −1.53 | 0.81 |
| 4 | 156.2 | 108.8 | 0.92 | 0.94 | 269.6 | 226.1 | −1.88 | 0.78 |
| 5 | 160.2 | 111.5 | 0.92 | 0.94 | 337.6 | 277.2 | −2.49 | 0.70 |
| 6 | 163.0 | 115.7 | 0.92 | 0.94 | 363.3 | 296.3 | −3.01 | 0.68 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liao, J.-M.; Chang, M.-J.; Chang, L.-M. Prediction of Air-Conditioning Energy Consumption in R&D Building Using Multiple Machine Learning Techniques. Energies 2020, 13, 1847. https://doi.org/10.3390/en13071847
Liao J-M, Chang M-J, Chang L-M. Prediction of Air-Conditioning Energy Consumption in R&D Building Using Multiple Machine Learning Techniques. Energies. 2020; 13(7):1847. https://doi.org/10.3390/en13071847
Chicago/Turabian StyleLiao, Jun-Mao, Ming-Jui Chang, and Luh-Maan Chang. 2020. "Prediction of Air-Conditioning Energy Consumption in R&D Building Using Multiple Machine Learning Techniques" Energies 13, no. 7: 1847. https://doi.org/10.3390/en13071847