1. Introduction
Until recently, automated smart wiring was the privilege of commercial buildings. However, more and more people want to take advantage of the smart installation options in their homes. There are already many companies on the market involved in smart installations. The prices of such systems with high level of reliability are becoming more affordable in relation to what the customer gains. One of the customer’s motivations for monitoring and controlling the operational and technical conditions of the building can be tracking the events in the building. By measuring various physical quantities, for example, a window left open, unauthorized entry or the presence of people in a building can be inferred. Another motivation for space monitoring can be care for disabled people or seniors. The IoT is increasingly being used to monitor and control the operational status of a building today, which greatly facilitates remote communication with the building from anywhere in the world. This is an area that is relatively new and constantly developing. However, multinational companies such as Google, IBM, Amazon, etc. are becoming increasingly important players in the IoT world. They come with their services, which they run on their servers and offer to customers. These services are generally referred to as Cloud Computing (CC). IB and IoT are two distinct concepts that are closely related, as IB requires real-time interaction with different technological processes. The interactions take place within the system on the basis of a programmed model or directly with the users, and IoT inherently helps. This research is focused on current trends in building automation and monitoring of operational and technical conditions in IB within IoT. The authors of [
1,
2,
3,
4,
5,
6,
7,
8,
9,
10,
11,
12,
13,
14,
15,
16,
17,
18,
19,
20,
21,
22,
23] focused on new approaches for home automation solutions within IoT. The authors investigated the new possibilities and trends of IB and smart home (SH) automation solutions with appropriate use of IBM IoT tools [
2,
3,
4,
5,
6], with ensuring appropriate security in IB and SH automatization [
7,
8,
9], and with the possible overlap of applications within the Smart Cities (SC) [
10,
11] and Smart Home Care (SHC) [
12] platforms.
The above-stated articles contain technical terms such as SH, IB, IoT, communication technology, data transfer in connection with communication protocols, CC, “Cloud of Things”. etc. SH is an automated or intelligent home. This is an expression for a modern living space in contrast to existing conventional buildings. SH is characterized by a high degree of automation of operational and technical processes, which are operated by people in standard households. These include lighting control, air temperature and air-conditioning control, kitchen equipment, security technology, door and window control, energy management, multimedia, and consumer electronics control, among many others. SH connects a number of automated systems and appliances with interoperability among the decentralized or centralized management technologies used. One of the main objectives is to increase the required level of user comfort while saving energy costs [
24]. SH should, of course, also offer the possibility of an additional configuration of functionality.
IoT is a network of interconnected devices that can exchange information with each other and be mutually interactive. Each of these devices must be clearly identifiable and addressable. Standardized communication protocols are used for communication. The aim is to create autonomous systems that are able to perform the expected activities completely independently on the basis of data obtained from the equipment. In practice, this means that the more data are collected, the better they can be analyzed, which may be useful in IoT implementation in specific fields [
25]. In his article on the introduction to the IoT, Vojacek described IoT architecture as a model consisting of three basic elements [
26]. The first block includes the “things” themselves, which are all devices connected to the network, whether cable or wireless, providing completely independent data. The second block represents the network, which serves as a means of communication between the things themselves and the control system. The third block includes data processing, which can be on the cloud, i.e. a remote server on which the data are further processed. The development of the Internet of Things is now mainly driven by the rapid development of new IoT-enabled devices and their ever-decreasing price. By 2020, it is estimated that the number of connected IoT devices may exceed 30 billion [
27]. However, this figure varies for different sources, but it is certain that the numbers go to tens of billions. This brings about the issue of Internet addressing, because addresses from the IPv4 address space were depleted in 2011, but, with the advent of IPv6, address depletion should not occur as there are
addresses in this address space, which is a huge number; for your information, it is about 66 trillion IP addresses per square centimeter of the Earth’s surface, including the oceans [
28,
29]. The Internet of Things may be used in many sectors of human activities. Smart Cities (SC) and Smart Grids (SG) can also be included in the current IoT application areas.
Obviously, it is necessary to transfer the data collected effectively. When it comes to wireless data transmissions, the most important parameters include especially range, energy intensity, the security of transmission, format, intensity of data processing, and transmission speed. Competition in this segment is relatively high [
30,
31,
32,
33]. Several communication protocols, such as MQTT, Constrained Application Protocol (CoAP), and Extensible Messaging and Presence Protocol (XMPP), are available for IoT data transmission [
34]. In this work, the MQTT protocol is used. Aazam et al. described the topic of CC in the work “Cloud of Things: Integrating the Internet of Things and CC and the issues involved” [
35]. This is a growing trend in IT technologies, which is also used in IoT. The characteristic feature of CC is the provision of services, software, and hardware of servers that are accessible to the users via the Internet from anywhere in the world. The cloud technology provider will enable the user to use their computing power, data storage, and the software offered. For the users, these services are appealing because they may not have the knowledge of the intrinsic functionality of the hardware and software leased. It also offers high-level data security or a high-quality, user-friendly web interface. Depending on the use of services, CC can be divided into groups [
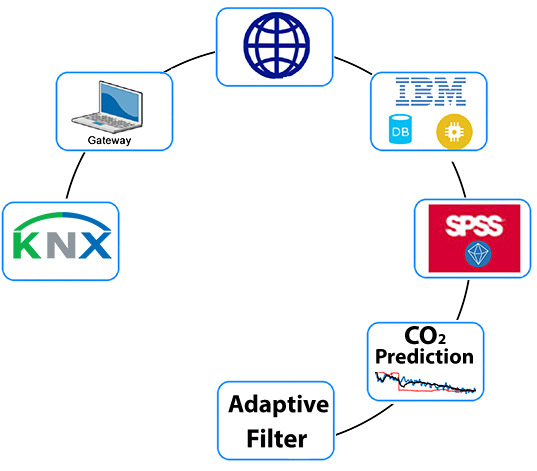
36]: IaaS (Infrastructure as a Service), SaaS (Software as a Service), PaaS (Platform as a Service), and NaaS (Network as a Service). The basic idea behind CC is to move application logic to remote servers. The individual devices in SH with an Internet connection can be connected directly to the cloud. The data received are collected and processed here. Based on the data evaluated, there is a feedback interaction with the devices in SH. It is often necessary to connect a device that does not have an Internet connection to the system. This can be performed using a gateway that is connected to the Internet. This gateway does not have to mediate communication to only one device. Often, cloud services also offer their own applications for visualization of the data processed and their storage in the database. There is a huge amount of data that can be used for other complex calculations, such as machine learning. Leading providers of these cloud technologies include IBM, which, inter alia, offers IBM Watson IoT, and Amazon with its Amazon Web Services.
Similar to this study, the obtained results in [
12,
18,
37,
38] showed that the accuracy of CO
2 prediction can possibly exceed 90%. Khazaei [
39] employed a multilayer perceptron neural network for the purpose of indoor CO
2 concentration levels, where relative humidity and temperature were used as inputs. The most accurate model (based on the calculated mean-square-error (MSE)) was five steps ahead of the reference signal. On average, the difference between reference and prediction signals was less than 17 ppm. Wang [
40] used a recurrent neural network (RNN) based dynamic backpropagation (BP) algorithm model with historical internal inputs. The models were developed to predict the temperature and humidity of a solar greenhouse. The obtained results demonstrate that the RNN-BP model provides reasonably good predictions. One of the benefits of the prediction of CO
2 concentration levels is low-cost indirect occupancy monitoring. Szczurek et al. proposed a method to provide occupancy determination in intermittently occupied space in real-time and with predefined temporal resolution [
41]. Galda et al. discovered insignificant difference between a room with and without plants, while measuring values of CO
2 concentration, inner temperature, and relative humidity [
42]. In our article, we used KNX technology for IB–IoT connectivity by means of the MQTT protocol within the IBM Watson IoT platform. The target of this article is to propose and verify a novel method for predicting CO
2 concentration (ppm) course from the temperature (T
indoor (°C)) and relative humidity (rH
indoor (%)) courses measured with operational accuracy to monitor occupancy in SH using conventional KNX operating sensors with the least investment cost. To achieve the goal, it is necessary to program the required KNX modules in the ETS 5 SW tool. Next, a software application is created to ensure connectivity between the KNX technology and the IoT IBM platform for real-time storage and visualization of the data measured. To predict the course of CO
2 concentration, it is necessary to verify and compare mathematical methods (linear regression (LR), random trees (RT), and multilayer perceptron’s (MLP)), and to select the method with the best results achieved. To increase the accuracy of CO
2 prediction, it is necessary to implement the LMS AF in an application for suppressing the additive noise from the CO
2 signal predicted and to assess the advantages and disadvantages of using AF in the newly proposed method. The proposed method was verified using the measured data in springtime with day-long and week-long intervals (2–10 May 2019). The proposed method can save investment costs in the design of large office buildings. Recognition of occupancy of monitored premises in the building leads to the optimization of IB automation in connection with the reduction of operating costs of IB.
4. Discussion
In the first part of the practical work, the development of a dedicated console application for KNX installation and IBM Watson IoT platform connectivity was described. When creating this program, the emphasis was placed on simplicity and reliability. Continuous running of the program was controlled by a web browser with an Internet connection, as the Watson IoT IBM platform provides a friendly web interface for visualizing the data received. After satisfactory verification of reliability, the development of a desktop version, which provides the user with a clear user interface, was commenced. Its core function, i.e., connectivity of the KNX and IoT IBM technologies, is the same as in the case of the console application. In the second part of the practical work, based on the data obtained from the KNX installation, a visualization application allowing the user both to display the values measured, namely their historical values depending on the database size and to visualize and process the data transmitted in real-time, was being developed. Emphasis was placed on information about the current occupancy of the room monitored. The user can monitor the measured values of the course of the CO2 sensor concentration, from the development of which the occupancy of the space monitored can be derived. When designing the new method for predicting the course of CO2 concentration based on temperature and humidity measurements, one of the motivations for CO2 prediction was to save the initial investment resources for the acquisition of CO2 sensors, which are significantly more expensive compared to temperature and humidity sensors. For prediction, IBM offers the SPSS modeler desktop application or the Watson Studio cloud service. Both options were used during the implementation. When working with the SPSS modeler, the prediction was conducted based on the input data in the form of a csv file. Using Watson Studio, which also offers many features that can be used to process data for CO2 prediction, there was also a successful connection with the Cloudant database for the access to historical data and, at the same time, there was a connection of this service with the Watson IoT platform for real-time data transfer from the KNX installation.
By reviewing the obtained results from LR, it becomes apparent that changing the algorithms of the models does not have any major impact on the results. Furthermore, day-long intervals showed significantly better accuracy. By summing up the tabulated and graphical results, it was concluded that the predictions obtained from this method would be accurate enough for the detection of presence. The prediction results included some inaccurate predictions. Therefore, it is not suitable for accurate CO2 concentration level predictions. The RT method showed significantly improved generalizations of CO2 concentration levels. Unlike the previous method, model settings affected the result noticeably. The general trend of the prediction pointed toward better accuracy with an increase in the number of trees. Specifically, the region between 10 and 18 trees appeared to be optimal for accurate predictions. Except for 6 May 2019, the prediction results from day-long intervals showed better overall characteristics. Further investigations found that 6 May 2019 showed short occupancy day-long intervals. Despite the fact the prediction waveform contained few minor inaccuracies and small noisy sections, it was still considered as a suitable method for both occupancy monitoring and accurate CO2 waveform predictions. The NN (MLP) showed the best numerical characteristics. The visual investigation verified the good generalization of the trained models. All models and methods showed noisy predictions at late hours of the day. Nevertheless, these noise levels were reduced in NN (MLP). Similar to previous methods, the day-long training intervals were more accurate. Overall, the NN (MLP) proved to be the most accurate method for both occupancy monitoring and accurate CO2 waveform predictions.
The use of an LMS AF in an application for suppressing the additive noise in the CO
2 concentration course predicted significantly improved the resulting CO
2 concentration course compared to the reference course measured for all of the above-stated LR, RT, NN (MLP) prediction methods (
Figure 11,
Figure 12 and
Figure 13). The best results, in terms of prediction accuracy using the LMS AF, were obtained for the NN method, where the calculated correlation coefficient between the courses of CO
2 reference (ppm) and the LMS adaptive CO
2 filtration (ppm) (
Figure 13) reached 99.29% for the adaptive LMS filter order set (filter order
M = 48, step size parameter
) (
Table 6). It can be compared with the correlation coefficient values calculated, as shown in
Table 5 and
Table 6, or the with other methods in
Table 1,
Table 2,
Table 3 and
Table 4. The disadvantage of the LMS AF is the initial peak (
Figure 11,
Figure 12 and
Figure 13) when the AF does not know the signal course processed. This is due to the vector of the weighting filtration coefficients
w, which was set to zero for the initial conditions and the start-up of the predicted CO
2 course processing by the LMS AF (Equation (
23)).
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}