

AcquisitionFocus: Joint Optimization of Acquisition Orientation and Cardiac Volume Reconstruction Using Deep Learning
 , , , , , and
, , , , , and
Abstract
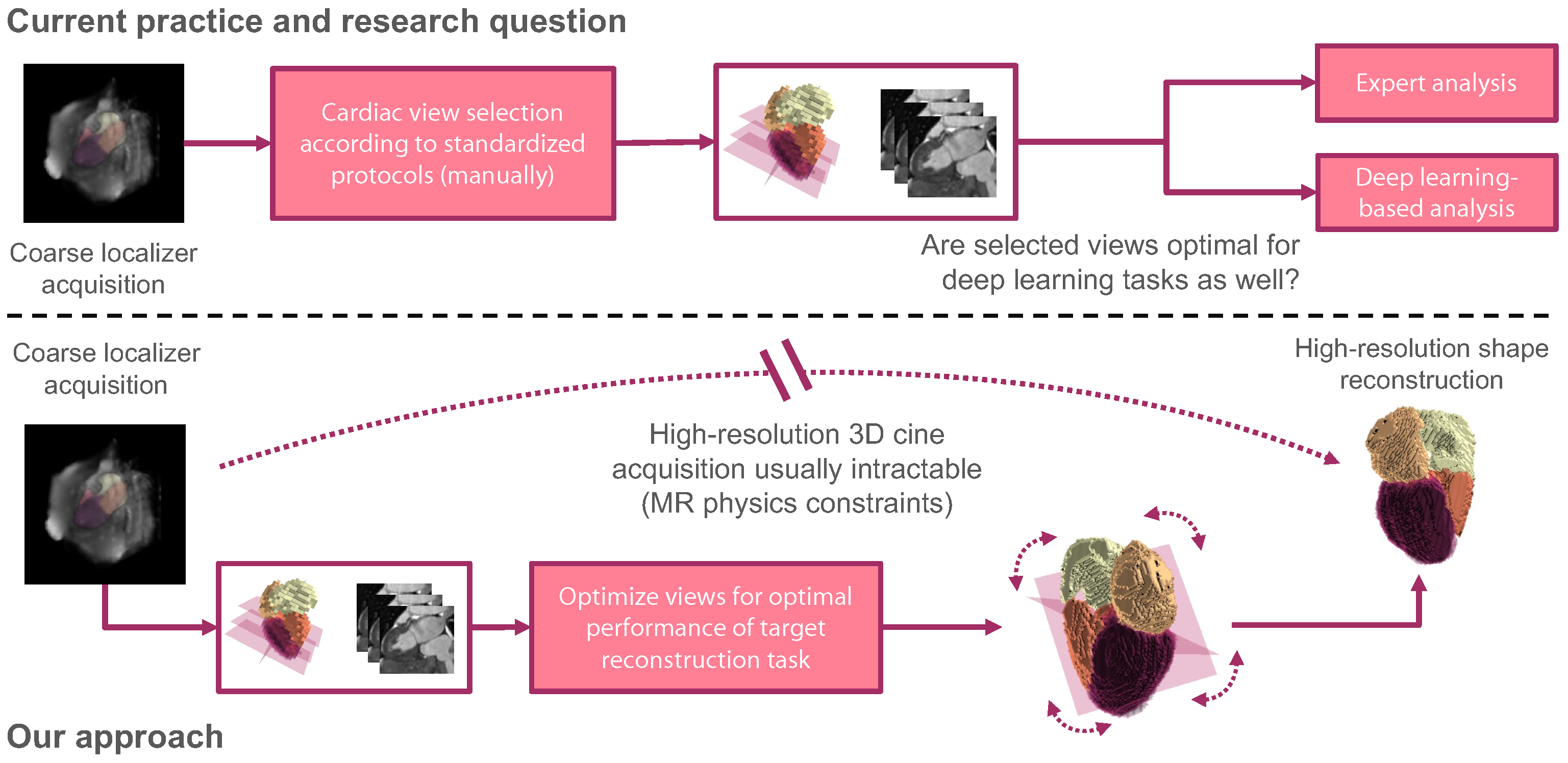
:1. Introduction
1.1. MR Physics Constraints and Timing
1.2. Shape Reconstruction and Imaging Plane Optimization
1.3. Contribution
- In a challenging target scenario, we reconstruct the full cardiac shape of five structures from only two slices.
- We study the joint optimization of shape reconstruction and view-plane orientation to derive optimal sparse slice configurations.
- The optimized slice configurations lead to superior reconstruction quality compared to standard clinical imaging planes, which we demonstrate for synthetic and clinically acquired cardiac MRI data.
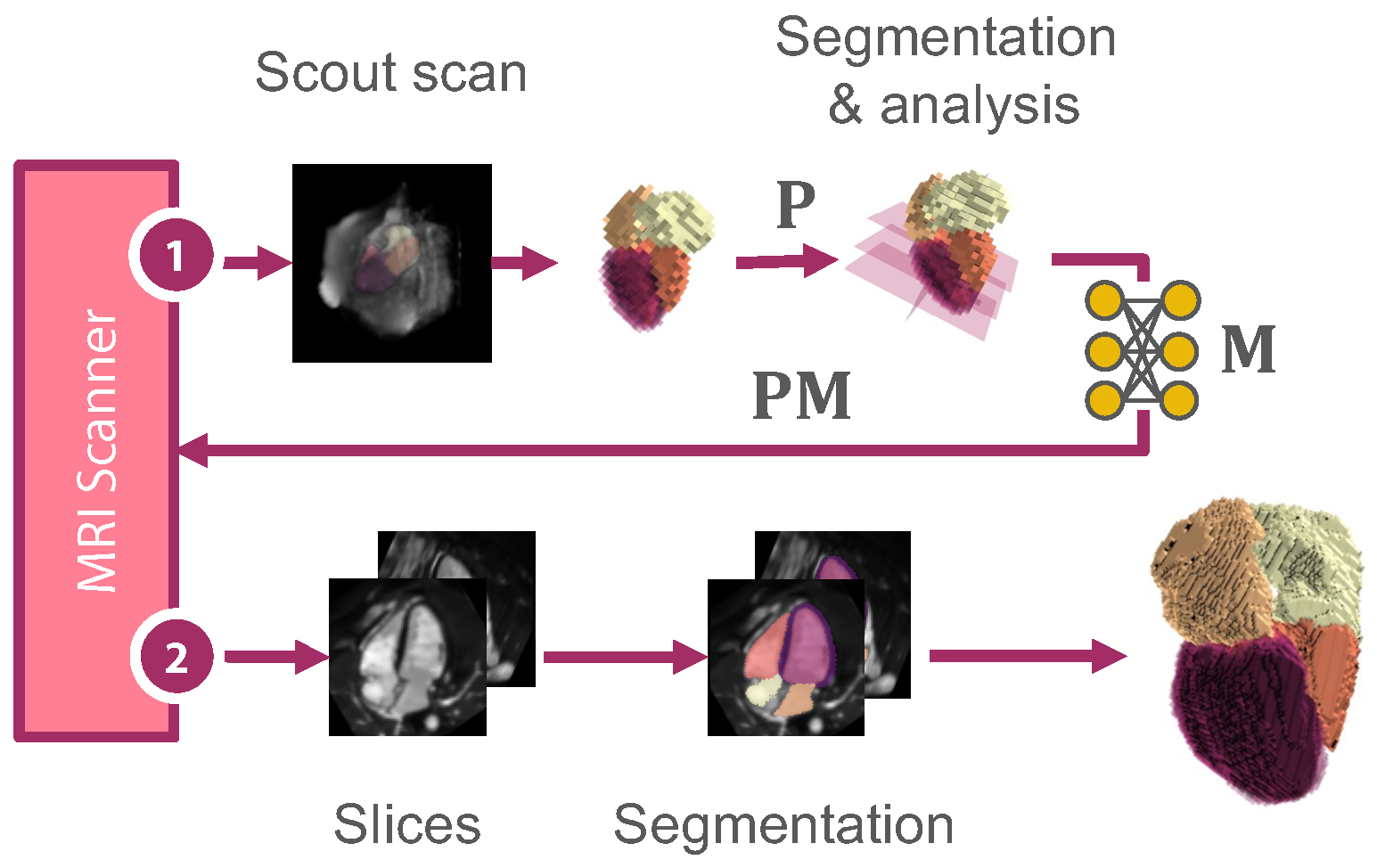
2. Materials and Methods
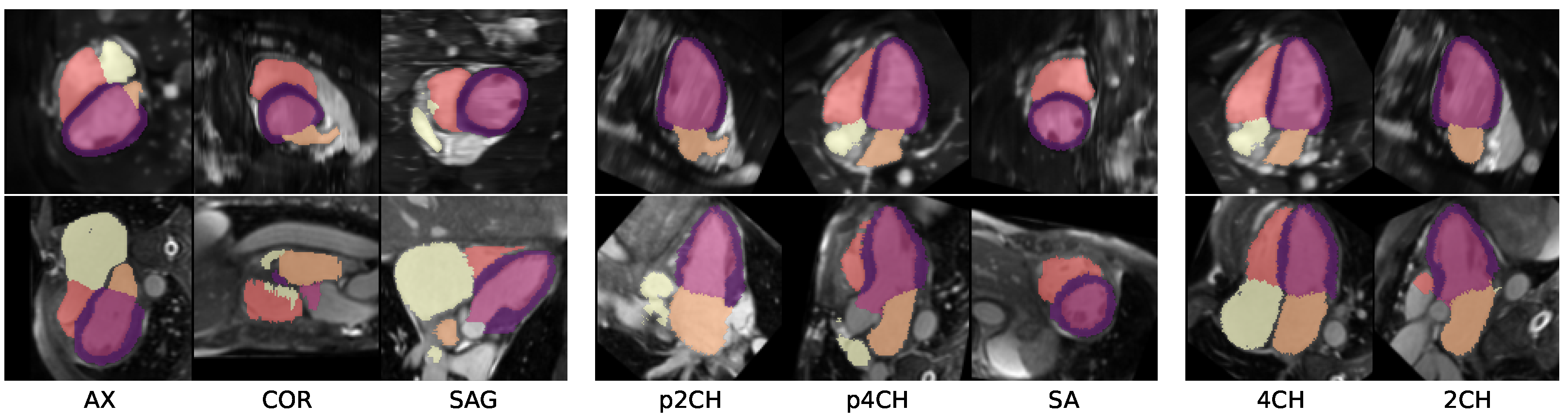
2.1. Extraction of Clinical Views
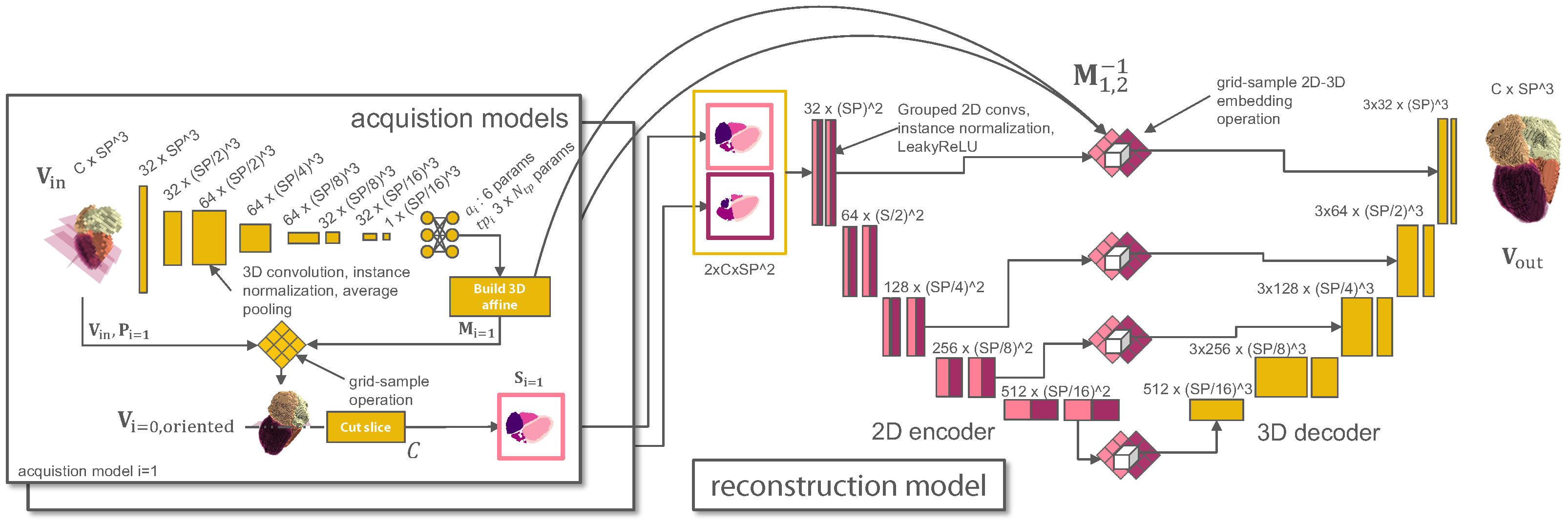
2.2. Slicing View Optimization
2.3. Reconstruction Model
2.4. Joint Optimization
2.5. Datasets
2.6. Experimental Setup and Evaluation
2.7. Implementation Details
3. Results
3.1. Experiment I
3.2. Experiment II
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| 2CH | two-chamber |
| 4CH | four-chamber |
| AX | axial |
| CMR | cardiac magnetic resonance imaging |
| CNN | convolutional neural network |
| COR | coronal |
| CT | computed tomography |
| GT | ground-truth |
| HD95 | 95th percentile of the Hausdorff distance |
| LSTM | long short-term memory |
| LA | left atrium |
| LV | left ventricle |
| MRI | magnetic resonance imaging |
| MYO | left myocardium |
| N/A | not applicable |
| OPT | optimized |
| p2CH | pseudo two-chamber view |
| p4CH | pseudo four-chamber view |
| RV | right ventricle |
| RA | right atrium |
| RND | random |
| SA | short axis |
| SAG | sagittal |
| SNR | signal-to-noise ratio |
| TR | repetition time |
References
- Ismail, T.F.; Strugnell, W.; Coletti, C.; Božić-Iven, M.; Weingärtner, S.; Hammernik, K.; Correia, T.; Küstner, T. Cardiac MR: From theory to practice. Front. Cardiovasc. Med. 2022, 9, 137. [Google Scholar] [CrossRef] [PubMed]
- Macovski, A. Noise in MRI. Magn. Reson. Med. 1996, 36, 494–497. [Google Scholar] [CrossRef]
- Ridgway, J.P. Cardiovascular magnetic resonance physics for clinicians: Part I. J. Cardiovasc. Magn. Reson. 2010, 12, 1–28. [Google Scholar] [CrossRef]
- Pruessmann, K.P.; Weiger, M.; Scheidegger, M.B.; Boesiger, P. SENSE: Sensitivity encoding for fast MRI. Magn. Reson. Med. Off. J. Int. Soc. Magn. Reson. Med. 1999, 42, 952–962. [Google Scholar] [CrossRef]
- Griswold, M.A.; Jakob, P.M.; Heidemann, R.M.; Nittka, M.; Jellus, V.; Wang, J.; Kiefer, B.; Haase, A. Generalized autocalibrating partially parallel acquisitions (GRAPPA). Magn. Reson. Med. Off. J. Int. Soc. Magn. Reson. Med. 2002, 47, 1202–1210. [Google Scholar] [CrossRef]
- Balaban, R.S.; Peters, D.C. Basic principles of cardiovascular magnetic resonance. In Cardiovascular Magnetic Resonance; Elsevier: Amsterdam, The Netherlands, 2019; pp. 1–14. [Google Scholar]
- Lustig, M.; Donoho, D.; Pauly, J.M. Sparse MRI: The application of compressed sensing for rapid MR imaging. Magn. Reson. Med. Off. J. Int. Soc. Magn. Reson. Med. 2007, 58, 1182–1195. [Google Scholar] [CrossRef] [PubMed]
- Raman, S.V.; Markl, M.; Patel, A.R.; Bryant, J.; Allen, B.D.; Plein, S.; Seiberlich, N. 30-minute CMR for common clinical indications:  a Society for Cardiovascular Magnetic Resonance white paper. J. Cardiovasc. Magn. Reson. 2022, 24, 13. [Google Scholar] [CrossRef]
- American Heart Association Writing Group on Myocardial Segmentation and Registration for Cardiac Imaging; Cerqueira, M.D.; Weissman, N.J.; Dilsizian, V.; Jacobs, A.K.; Kaul, S.; Laskey, W.K.; Pennell, D.J.; Rumberger, J.A.; Ryan, T.; et al. Standardized myocardial segmentation and nomenclature for tomographic imaging of the heart: A statement for healthcare professionals from the Cardiac Imaging Committee of the Council on Clinical Cardiology of the American Heart Association. Circulation 2002, 105, 539–542. [Google Scholar] [PubMed]
- Stojanovski, D.; Hermida, U.; Muffoletto, M.; Lamata, P.; Beqiri, A.; Gomez, A. Efficient Pix2Vox++ for 3D Cardiac Reconstruction from 2D echo views. In Proceedings of the Simplifying Medical Ultrasound: Third International Workshop, ASMUS 2022, Held in Conjunction with MICCAI 2022, Singapore, 18 September 2022; Springer: Cham, Switzerland, 2022; pp. 86–95. [Google Scholar]
- Watkins, M.P.; Williams, T.A.; Caruthers, S.D.; Wickline, S.A. Cardiovascular MR function and coronaries: CMR 15 min express. J. Cardiovasc. Magn. Reson. 2013, 15, T11. [Google Scholar] [CrossRef]
- Luo, M.; Yang, X.; Wang, H.; Du, L.; Ni, D. Deep Motion Network for Freehand 3D Ultrasound Reconstruction. In Proceedings of the Medical Image Computing and Computer Assisted Intervention–MICCAI 2022: 25th International Conference, Singapore, 18–22 September 2022; Proceedings, Part IV. Springer: Cham, Switzerland, 2022; pp. 290–299. [Google Scholar]
- Jokeit, M.; Kim, J.H.; Snedeker, J.G.; Farshad, M.; Widmer, J. Mesh-based 3D Reconstruction from Bi-planar Radiographs. In Proceedings of the Medical Imaging with Deep Learning, Zurich, Switzerland, 6–8 July 2022. [Google Scholar]
- Amiranashvili, T.; Lüdke, D.; Li, H.; Menze, B.; Zachow, S. Learning Shape Reconstruction from Sparse Measurements with Neural Implicit Functions. In Proceedings of the Medical Imaging with Deep Learning, Zurich, Switzerland, 6–8 July 2022. [Google Scholar]
- Beetz, M.; Banerjee, A.; Grau, V. Reconstructing 3D Cardiac Anatomies from Misaligned Multi-View Magnetic Resonance Images with Mesh Deformation U-Nets. In Proceedings of the Geometric Deep Learning in Medical Image Analysis, Amsterdam, The Netherlands, 18 November 2022; pp. 3–14. [Google Scholar]
- Xie, H.; Yao, H.; Sun, X.; Zhou, S.; Zhang, S. Pix2vox: Context-aware 3d reconstruction from single and multi-view images. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2019; pp. 2690–2698. [Google Scholar]
- Lee, K.; Yang, J.; Lee, M.H.; Chang, J.H.; Kim, J.Y.; Hwang, J.Y. USG-Net: Deep Learning-based Ultrasound Scanning-Guide for an Orthopedic Sonographer. In Proceedings of the Medical Image Computing and Computer Assisted Intervention–MICCAI 2022: 25th International Conference, Singapore, 18–22 September 2022; Proceedings, Part VII. Springer: Cham, Switzerland, 2022; pp. 23–32. [Google Scholar]
- Natalia, F.; Young, J.C.; Afriliana, N.; Meidia, H.; Yunus, R.E.; Sudirman, S. Automated selection of mid-height intervertebral disc slice in traverse lumbar spine MRI using a combination of deep learning feature and machine learning classifier. PLoS ONE 2022, 17, e0261659. [Google Scholar] [CrossRef]
- Chen, Z.; Rigolli, M.; Vigneault, D.M.; Kligerman, S.; Hahn, L.; Narezkina, A.; Craine, A.; Lowe, K.; Contijoch, F. Automated cardiac volume assessment and cardiac long-and short-axis imaging plane prediction from electrocardiogram-gated computed tomography volumes enabled by deep learning. Eur. Heart-J.-Digit. Health 2021, 2, 311–322. [Google Scholar] [CrossRef] [PubMed]
- Nitta, S.; Shiodera, T.; Sakata, Y.; Takeguchi, T.; Kuhara, S.; Yokoyama, K.; Ishimura, R.; Kariyasu, T.; Imai, M.; Nitatori, T. Automatic 14-plane slice-alignment method for ventricular and valvular analysis in cardiac magnetic resonance imaging. J. Cardiovasc. Magn. Reson. 2014, 16, P1. [Google Scholar] [CrossRef]
- Odille, F.; Bustin, A.; Liu, S.; Chen, B.; Vuissoz, P.A.; Felblinger, J.; Bonnemains, L. Isotropic 3D cardiac cine MRI allows efficient sparse segmentation strategies based on 3 D surface reconstruction. Magn. Reson. Med. 2018, 79, 2665–2675. [Google Scholar] [CrossRef] [PubMed]
- Herzog, B.; Greenwood, J.; Plein, S.; Garg, P.; Haaf, P.; Onciul, S. Cardiovascular Magnetic Resonance Pocket Guide, 2017. Available online: https://www.escardio.org/static-file/Escardio/Subspecialty/EACVI/Publications%20and%20recommendations/Books%20and%20booklets/CMR%20pocket%20guides/CMR_guide_2nd_edition_148x105mm_03May2017_last%20version.pdf (accessed on 7 February 2024).
- Czichos, H.; Hennecke, M. HÜTTE—Das Ingenieurwissen; Springer: Berlin/Heidelberg, Germany, 2012; Volume 34, p. E35. [Google Scholar] [CrossRef]
- Jaderberg, M.; Simonyan, K.; Zisserman, A. Spatial transformer networks. Adv. Neural Inf. Process. Syst. 2015, 28, 2017–2025. [Google Scholar]
- Zhou, Y.; Barnes, C.; Lu, J.; Yang, J.; Li, H. On the continuity of rotation representations in neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 5745–5753. [Google Scholar]
- Segars, W.P.; Sturgeon, G.; Mendonca, S.; Grimes, J.; Tsui, B.M. 4D XCAT phantom for multimodality imaging research. Med. Phys. 2010, 37, 4902–4915. [Google Scholar] [CrossRef] [PubMed]
- Buoso, S.; Joyce, T.; Schulthess, N.; Kozerke, S. MRXCAT2. 0: Synthesis of realistic numerical phantoms by combining left-ventricular shape learning, biophysical simulations and tissue texture generation. J. Cardiovasc. Magn. Reson. 2023, 25, 25. [Google Scholar] [CrossRef] [PubMed]
- Zhuang, X.; Shen, J. Multi-scale patch and multi-modality atlases for whole heart segmentation of MRI. Med. Image Anal. 2016, 31, 77–87. [Google Scholar] [CrossRef] [PubMed]
- Kellman, P.; Lu, X.; Jolly, M.P.; Bi, X.; Kroeker, R.; Schmidt, M.; Speier, P.; Hayes, C.; Guehring, J.; Mueller, E. Automatic LV localization and view planning for cardiac MRI acquisition. J. Cardiovasc. Magn. Reson. 2011, 13, P39. [Google Scholar] [CrossRef]
- Isensee, F.; Jaeger, P.F.; Kohl, S.A.; Petersen, J.; Maier-Hein, K.H. nnU-Net: A self-configuring method for deep learning-based biomedical image segmentation. Nat. Methods 2021, 18, 203–211. [Google Scholar] [CrossRef]
- Loshchilov, I.; Hutter, F. Decoupled weight decay regularization. arXiv 2017, arXiv:1711.05101. [Google Scholar]
- Loshchilov, I.; Hutter, F. Sgdr: Stochastic gradient descent with warm restarts. arXiv 2016, arXiv:1608.03983. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
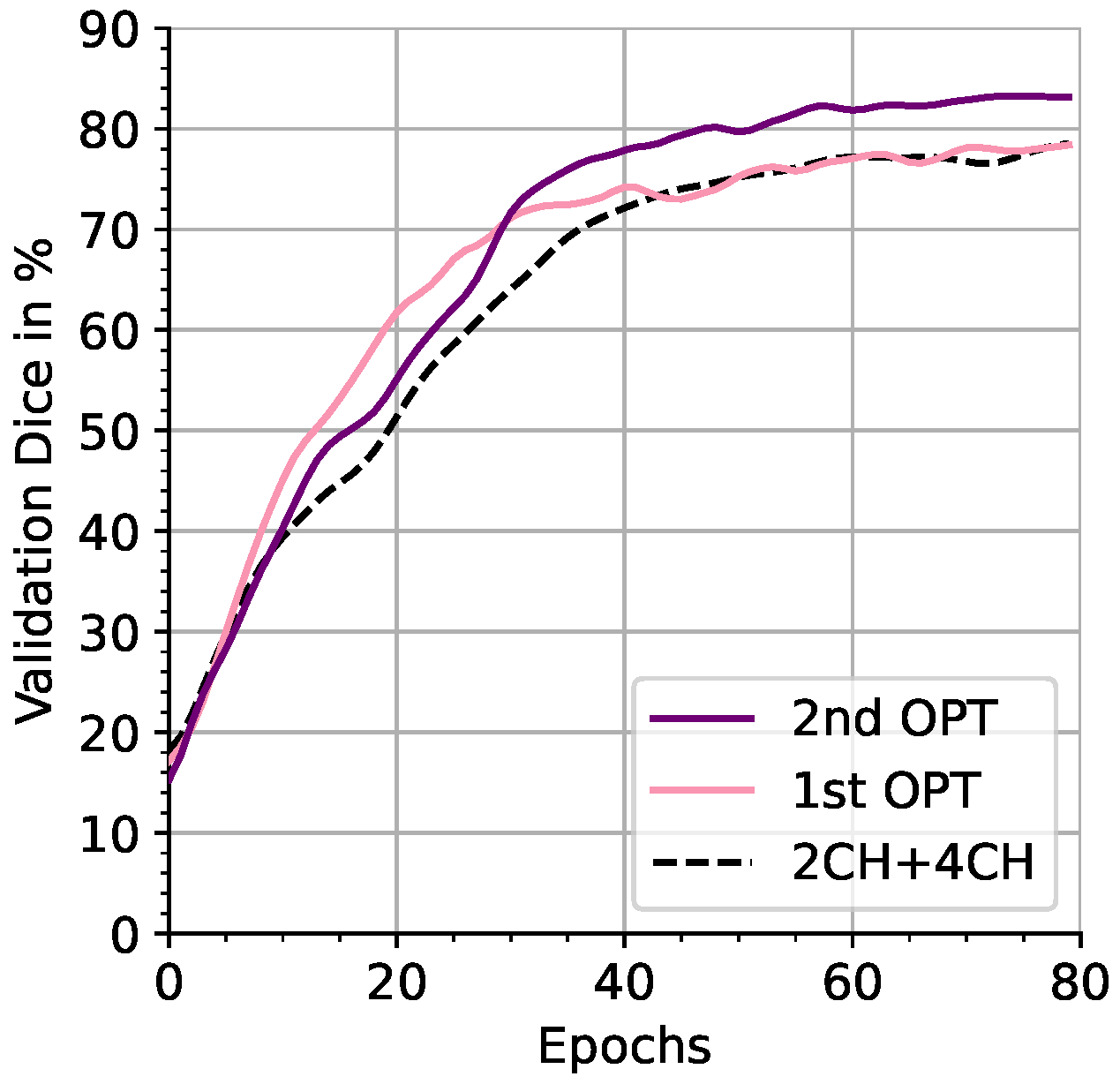{kind=link}
{kind=link}
| Synthetic Cine MRXCAT Data | HD95 in mm ↓ | Dice in % ↑ | ||
|---|---|---|---|---|
| 1st View | 2nd View | Model | ||
| p2CH | p4CH | P2V [16] | 6.7 ± 2.9 | 95.4 ± 3.2 |
| EP2V [10] | 7.2 ± 4.6 | 94.3 ± 4.5 | ||
| Ours | 4.7 ± 1.7 | 96.6 ± 1.4 | ||
| 2CH | 4CH | P2V [16] | 7.7 ± 5.5 | 93.6 ± 6.8 |
| EP2V [10] | 5.6 ± 2.4 | 96.2 ± 2.1 | ||
| Ours | 5.2 ± 2.8 | 95.9 ± 2.2 | ||
| 2CH | SA | P2V [16] | 4.6 ± 1.1 | 97.1 ± 0.8 |
| EP2V [10] | 6.2 ± 4.5 | 95.1 ± 4.8 | ||
| Ours | 4.3 ± 2.4 | 96.4 ± 2.4 | ||
| Clinically acq. MMWHS Data | HD95 in mm ↓ | Dice in % ↑ | ||
|---|---|---|---|---|
| 1st View | 2nd View | Model | ||
| p2CH | p4CH | P2V [16] | 20.1 ± 6.2 | 83.0 ± 5.0 |
| EP2V [10] | 22.1 ± 7.2 | 80.0 ± 7.8 | ||
| Ours | 20.0 ± 6.4 | 86.4 ± 4.1 | ||
| 2CH | 4CH | P2V [16] | 21.8 ± 5.9 | 82.5 ± 4.3 |
| EP2V [10] | 22.1 ± 8.4 | 81.5 ± 7.2 | ||
| Ours | 18.1 ± 6.5 | 87.6 ± 3.5 | ||
| 2CH | SA | P2V [16] | 22.6 ± 7.7 | 82.6 ± 5.4 |
| EP2V [10] | 20.8 ± 8.1 | 83.3 ± 5.2 | ||
| Ours | 23.7 ± 6.7 | 85.4 ± 4.5 | ||
| Synthetic Cine MRXCAT Data | HD95 in mm ↓ | Dice in % ↑ | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Type of: Scout—Slices | 1st View | 2nd View | MYO | LV | RV | LA | RA | MYO | LV | RV | LA | RA | ||
| 1.5 mm3 GT—1.5 mm2 GT | p2CH | p4CH | 6.2 | 5.3 | 11.9 | 5.3 | 13.9 | 8.5 ± 14.7 | 82.4 | 90.0 | 84.2 | 90.6 | 83.4 | 86.1 ± 8.5 |
| 1.5 mm3 GT —1.5 mm2 GT | 2CH | 4CH | 6.5 | 7.1 | 8.0 | 5.1 | 7.7 | 6.9 ± 2.0 | 79.9 | 86.8 | 83.5 | 90.7 | 85.2 | 85.2 ± 5.9 |
| 1.5 mm3 GT—1.5 mm2 GT | 2CH | SA | 6.5 | 7.2 | 8.6 | 6.9 | 8.7 | 7.6 ± 2.6 | 79.3 | 86.5 | 83.9 | 88.6 | 82.9 | 84.2 ± 6.2 |
| 1.5 mm3 GT—1.5 mm2 GT | RND | RND | 7.2 | 8.4 | 9.6 | 8.0 | 6.9 | 8.0 ± 5.4 | 78.9 | 86.3 | 84.9 | 87.1 | 88.6 | 85.2 ± 7.0 |
| 1.5 mm3 GT—1.5 mm2 GT | >OPT< | >OPT< | 6.3 | 6.6 | 7.1 | 4.6 | 6.3 | 6.2 ± 2.0 | 80.7 | 87.8 | 86.3 | 91.0 | 88.9 | 86.9 ± 5.4 |
| 6.0 mm3 GT—1.5 mm2 GT | 2CH | 4CH | 6.3 | 7.3 | 10.3 | 5.1 | 7.6 | 7.3 ± 3.0 | 79.1 | 86.9 | 80.7 | 91.3 | 86.4 | 84.9 ± 6.7 |
| 6.0 mm3 GT—1.5 mm2 GT | >OPT< | >OPT< | 6.8 | 7.2 | 6.8 | 6.6 | 7.4 | 7.0 ± 1.8 | 78.7 | 85.7 | 87.3 | 88.7 | 87.2 | 85.5 ± 6.0 |
| 6.0 mm3 SG—N/A | N/A | N/A | (5.3) | (5.3) | (5.5) | (5.6) | (5.8) | (5.5 ± 0.3) | (79.6) | (91.5) | (90.1) | (85.5) | (86.5) | (86.6 ± 4.2) |
| 6.0 mm3 SG—1.5 mm2 SG | 2CH | 4CH | 10.3 | 10.2 | 31.7 | 7.3 | 7.7 | 13.5 ± 17.4 | 68.6 | 82.1 | 82.4 | 86.0 | 85.9 | 81.0 ± 8.0 |
| 6.0 mm3 SG—1.5 mm2 SG | >OPT< | >OPT< | 9.4 | 9.8 | 10.0 | 11.7 | 7.7 | 9.7 ± 3.0 | 69.9 | 81.8 | 84.0 | 76.4 | 87.4 | 79.9 ± 8.7 |
| Clinically acquired MMWHS data | HD95 in mm ↓ | Dice in % ↑ | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Type of: Scout—Slices | 1st View | 2nd View | MYO | LV | RV | LA | RA | MYO | LV | RV | LA | RA | ||
| 1.5 mm3 GT—1.5 mm2 GT | p2CH | p4CH | 7.7 | 8.2 | 30.3 | 27.6 | 38.7 | 22.5 ± 25.4 | 78.7 | 88.3 | 69.4 | 75.7 | 65.4 | 75.5 ± 16.2 |
| 1.5 mm3 GT—1.5 mm2 GT | 2CH | 4CH | 6.8 | 8.2 | 19.5 | 8.9 | 27.1 | 14.1 ± 10.2 | 81.8 | 88.7 | 77.2 | 86.5 | 74.9 | 81.8 ± 9.5 |
| 1.5 mm3 GT—1.5 mm2 GT | 2CH | SA | 7.8 | 10.2 | 16.5 | 13.8 | 31.6 | 16.0 ± 10.0 | 79.9 | 87.7 | 77.0 | 79.7 | 61.3 | 77.1 ± 12.1 |
| 1.5 mm3 GT—1.5 mm2 GT | RND | RND | 12.0 | 13.9 | 18.0 | 18.1 | 23.2 | 17.1 ± 10.0 | 69.3 | 82.1 | 80.4 | 78.0 | 75.5 | 77.1 ± 9.2 |
| 1.5 mm3 GT—1.5 mm2 GT | >OPT< | >OPT< | 8.6 | 9.7 | 15.1 | 13.8 | 12.1 | 11.9 ± 3.9 | 79.7 | 87.8 | 79.8 | 81.1 | 85.0 | 82.7 ± 6.5 |
| 6.0 mm3 GT—1.5 mm2 GT | 2CH | 4CH | 7.5 | 8.1 | 18.9 | 11.0 | 22.7 | 13.6 ± 9.2 | 81.0 | 89.4 | 78.9 | 85.2 | 76.4 | 82.2 ± 8.6 |
| 6.0 mm3 GT—1.5 mm2 GT | >OPT< | >OPT< | 8.9 | 10.2 | 14.8 | 16.2 | 14.4 | 12.9 ± 7.2 | 77.1 | 86.1 | 81.0 | 81.3 | 81.1 | 81.3 ± 9.3 |
| 6.0 mm3 SG—N/A | N/A | N/A | (10.8) | (12.8) | (16.3) | (12.8) | (13.0) | (13.2 ± 11.5) | (72.3) | (87.6) | (81.7) | (80.0) | (81.0) | (80.5 ± 9.3) |
| 6.0 mm3 SG—1.5 mm2 SG | 2CH | 4CH | 17.1 | 19.1 | 51.4 | 64.8 | 103.8 | 51.2 ± 50.7 | 56.2 | 71.6 | 56.3 | 35.2 | 38.8 | 51.6 ± 25.2 |
| 6.0 mm3 SG—1.5 mm2 SG | >OPT< | >OPT< | 35.0 | 32.7 | 39.9 | 53.9 | 51.6 | 42.6 ± 23.4 | 43.8 | 69.0 | 56.5 | 39.6 | 61.3 | 54.0 ± 19.6 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Weihsbach, C.; Vogt, N.; Al-Haj Hemidi, Z.; Bigalke, A.; Hansen, L.; Oster, J.; Heinrich, M.P. AcquisitionFocus: Joint Optimization of Acquisition Orientation and Cardiac Volume Reconstruction Using Deep Learning. Sensors 2024, 24, 2296. https://doi.org/10.3390/s24072296
Weihsbach C, Vogt N, Al-Haj Hemidi Z, Bigalke A, Hansen L, Oster J, Heinrich MP. AcquisitionFocus: Joint Optimization of Acquisition Orientation and Cardiac Volume Reconstruction Using Deep Learning. Sensors. 2024; 24(7):2296. https://doi.org/10.3390/s24072296
Chicago/Turabian StyleWeihsbach, Christian, Nora Vogt, Ziad Al-Haj Hemidi, Alexander Bigalke, Lasse Hansen, Julien Oster, and Mattias P. Heinrich. 2024. "AcquisitionFocus: Joint Optimization of Acquisition Orientation and Cardiac Volume Reconstruction Using Deep Learning" Sensors 24, no. 7: 2296. https://doi.org/10.3390/s24072296