
Scalable Learning Framework for Detecting New Types of Twitter Spam with Misuse and Anomaly Detection

Abstract
:1. Introduction
- (1)
- We propose a spam detection framework based on an autoencoder and a one-class SVM, which are typical anomaly detection methods, to respond to new types of spam that pose a significant threat.
- (2)
- We use a DT to respond to known spam and enhance the low spam detection rate of anomaly detection.
- (3)
- We increase the detection rate of known spam and normal tweets by performing tailored anomaly detection for each subset containing data not classified as spam by the DT.
- (4)
- We propose a scalable spam detection framework that focuses on known or unknown spam, depending on the current situation.
2. Literature Review
2.1. Misuse Detection
2.2. Anomaly Detection
3. Materials and Methods
3.1. Model Design Overview
3.2. Known Spam Detection Using DT
3.3. Unknown Spam Detection Using Anomaly Detection
3.3.1. One-Class SVM
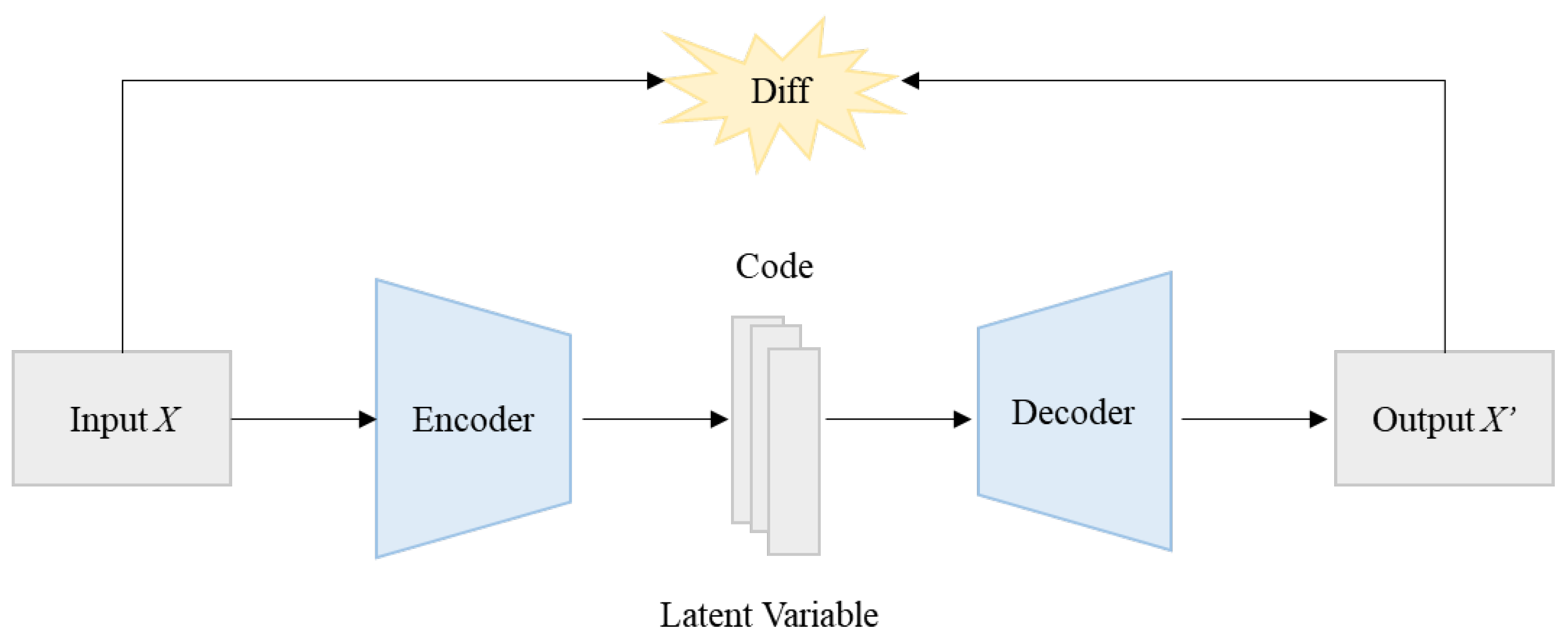
3.3.2. Autoencoder
3.4. Scalable Spam Detection System
4. Results
4.1. Dataset Description and Evaluation Metrics
4.2. Performance Comparison of the Proposed Framework
4.3. Performance Comparison Based on Cost Changes
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Statista. Available online: https://www.statista.com/statistics/617136/digital-population-worldwide/ (accessed on 25 January 2024).
- Rao, S.; Verma, A.K.; Bhatia, T. A review on social spam detection: Challenges, open issues, and future directions. Expert Syst. Appl. 2021, 186, 115742. [Google Scholar] [CrossRef]
- Imam, N.H.; Vassilakis, V.G. A survey of attacks against Twitter spam detectors in an adversarial environment. Robotics 2019, 8, 50. [Google Scholar] [CrossRef]
- Ferrara, E.; Varol, O.; Davis, C.; Menczer, F.; Flammini, A. The rise of social bots. Commun. ACM 2016, 59, 96–104. [Google Scholar] [CrossRef]
- Bindu, P.; Mishra, R.; Thilagam, P.S. Discovering spammer communities in Twitter. J. Intell. Inf. Syst. 2018, 51, 503–527. [Google Scholar] [CrossRef]
- Reuters. Available online: https://www.reuters.com/article/us-usa-twitter-disinformation/twitter-suspends-accounts-claiming-to-be-black-trump-supporters-over-spam-manipulation-idUSKBN26Y2ZM (accessed on 25 January 2024).
- The Washington Post. Available online: https://www.washingtonpost.com/technology/2020/07/30/twitter-hack-phone-attack/ (accessed on 25 January 2024).
- Vice. Available online: https://www.vice.com/en/article/5d9bvn/ai-spam-is-already-flooding-the-internet-and-it-has-an-obvious-tell (accessed on 11 March 2024).
- Grier, C.; Thomas, K.; Paxson, V.; Zhang, M. @ spam: The underground on 140 characters or less. In Proceedings of the 17th ACM Conference on Computer and Communications Security, Chicago, IL, USA, 4–8 October 2010. [Google Scholar]
- Lee, K.; Eoff, B.D.; Caverlee, J. Seven months with the devils: A long-term study of content polluters on Twitter. Proc. Int. AAAI Conf. Web Soc. Media 2011, 5, 185–192. [Google Scholar] [CrossRef]
- Stringhini, G.; Kruegel, C.; Vigna, G. Detecting spammers on social networks. In Proceedings of the 26th Annual Computer Security Applications Conference (ACSAC), Austin, TX, USA, 6–10 December 2010. [Google Scholar]
- Choi, J.; Jeon, C. Cost-based heterogeneous learning framework for real-time spam detection in social networks with expert decisions. IEEE Access 2021, 9, 103573–103587. [Google Scholar] [CrossRef]
- Wu, T.; Wen, S.; Xiang, Y.; Zhou, W. Twitter spam detection: Survey of new approaches and comparative study. Comput. Secur. 2017, 76, 265–284. [Google Scholar] [CrossRef]
- Liu, S.; Wang, Y.; Zhang, J.; Chen, C.; Xiang, Y. Addressing the class imbalance problem in twitter spam detection using ensemble learning. Comput. Secur. 2017, 69, 35–49. [Google Scholar] [CrossRef]
- Chalapathy, R.; Chawla, S. Deep learning for anomaly detection: A survey. arXiv 2019, arXiv:1901.03407. [Google Scholar]
- Benevenuto, F.; Magno, G.; Rodrigues, T.; Almeida, V. Detecting spammers on Twitter. In Proceedings of the Collaboration, Electronic Messaging, Anti-Abuse and Spam Conference (CEAS), Washington, DC, USA, 13–14 July 2010. [Google Scholar]
- Chen, C.; Zhang, J.; Xiang, Y.; Zhou, W. Asymmetric self-learning for Tackling twitter spam drift. In Proceedings of the 2015 IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS), Hong Kong, China, 26 April–1 May 2015. [Google Scholar]
- Dutta, S.; Ghatak, S.; Dey, R.; Das, A.K.; Ghosh, S. Attribute selection for improving spam classification in online social networks: A rough set theory-based approach. Soc. Netw. Anal. Min. 2018, 8, 7. [Google Scholar] [CrossRef]
- Gupta, H.; Jamal, M.S.; Madisetty, S.; Desarkar, M.S. A framework for real-time spam detection in Twitter. In Proceedings of the 2018 10th International Conference on Communication Systems and Networks (COMSNETS), Bengaluru, India, 3–7 January 2018. [Google Scholar]
- Feng, B.; Fu, Q.; Dong, M.; Guo, D.; Li, Q. Multistage and elastic spam detection in mobile social networks through deep learning. IEEE Netw. 2018, 32, 15–21. [Google Scholar] [CrossRef]
- Ban, X.; Chen, C.; Liu, S.; Wang, Y.; Zhang, J. Deep-learnt features for Twitter spam detection. In Proceedings of the 2018 International Symposium on Security and Privacy in Social Networks and Big Data (SocialSec), Santa Clara, CA, USA, 10–11 December 2018. [Google Scholar]
- Min, M.; Lee, J.J.; Lee, K.; You, I. Detecting illegal online gambling (IOG) services in the mobile environment. Secur. Commun. Netw. 2022, 2022, 3286623. [Google Scholar] [CrossRef]
- Sawsan, A.; Shatnawi, A.; AlSobeh, A.M.R.; Magableh, A.A. Beyond Word-Based Model Embeddings: Contextualized Representations for Enhanced Social Media Spam Detection. Appl. Sci. 2024, 14, 2254. [Google Scholar] [CrossRef]
- Ahmed, F.; Abulaish, M. A generic statistical approach for spam detection in online social networks. Comput. Commun. 2013, 36, 1120–1129. [Google Scholar] [CrossRef]
- Chen, C.; Zhang, J.; Chen, X.; Xiang, Y.; Zhou, W. 6 million spam tweets: A large ground truth for timely Twitter spam detection. In Proceedings of the 2015 IEEE International Conference on Communications (ICC), London, UK, 8–12 June 2015. [Google Scholar]
- Liu, S.; Zhang, J.; Xiang, Y. Statistical detection of online drifting Twitter spam. In Proceedings of the 11th ACM Asia Conference on Computer and Communications Security, Xi’an, China, 30 May–3 June 2016. [Google Scholar]
- Madisetty, S.; Desarkar, M.S. A neural network-based ensemble approach for spam detection in Twitter. IEEE Trans. Comput. Soc. Syst. 2018, 5, 973–984. [Google Scholar] [CrossRef]
- Jain, G.; Sharma, M.; Agarwal, B. Spam detection on social media using semantic convolutional neural network. Int. J. Knowl. Discov. Bioinform. 2018, 8, 12–26. [Google Scholar] [CrossRef]
- Wu, Y.; Fang, Y.; Shang, S.; Jin, J.; Wei, L.; Wang, H. A novel framework for detecting social bots with deep neural networks and active learning. Knowl.-Based Syst. 2021, 211, 106525. [Google Scholar] [CrossRef]
- Singh, V.; Varshney, A.; Akhtar, S.S.; Vijay, D.; Shrivastava, M. Aggression detection on social media text using deep neural networks. In Proceedings of the 2nd Workshop on Abusive Language Online (ALW2), Brussels, Belgium, 31 October 2018. [Google Scholar]
- Nguyen, H.M.; Derakhshani, R. Eyebrow recognition for identifying deepfake videos. In Proceedings of the 2020 International Conference of the Biometrics Special Interest Group (BIOSIG), Darmstadt, Germany, 16–18 September 2020. [Google Scholar]
- Jung, T.; Kim, S.; Kim, K. Deepvision: Deepfakes detection using human eye blinking pattern. IEEE Access 2020, 8, 83144–83154. [Google Scholar] [CrossRef]
- Costa, H.; Benevenuto, F.; Merschmann, L.H. Detecting tip spam in location-based social networks. In Proceedings of the 28th Annual ACM Symposium on Applied Computing, New York, NY, USA, 18–22 March 2013. [Google Scholar]
- Hu, X.; Tang, J.; Zhang, Y.; Liu, H. 2013 Social spammer detection in microblogging. In Proceedings of the 23rd International Joint Conference on Artificial Intelligence, Beijing, China, 3–9 August 2013. [Google Scholar]
- Yang, C.; Harkreader, R.; Gu, G. Empirical evaluation and new design for fighting evolving Twitter spammers. IEEE Trans. Inf. Forensics Secur. 2013, 8, 1280–1293. [Google Scholar] [CrossRef]
- Abdallah, G.; Alohaly, M. Enhancing Spam Message Classification and Detection Using Transformer-Based Embedding and Ensemble Learning. Sensors 2023, 23, 3861. [Google Scholar] [CrossRef]
- Sen, J.; Sidra, M. Machine learning applications in misuse and anomaly detection. In Security and Privacy from a Legal, Ethical, and Technical Perspective; BoD—Books on Demand: Norderstedt Germany, 2020; Volume 155. [Google Scholar]
- Agrawal, S.; Agrawal, J. Survey on anomaly detection using data mining techniques. Procedia Comput. Sci. 2015, 60, 708–713. [Google Scholar] [CrossRef]
- Sohrabi, M.K.; Karimi, F. A feature selection approach to detect spam in the Facebook social network. Arab. J. Sci. Eng. 2018, 43, 949–958. [Google Scholar] [CrossRef]
- Tajalizadeh, H.; Boostani, R. A novel stream clustering framework for spam detection in Twitter. IEEE Trans. Comput. Soc. Syst. 2019, 6, 525–534. [Google Scholar] [CrossRef]
- Xia, T. A constant time complexity spam detection algorithm for boosting throughput on rule-based filtering systems. IEEE Access 2020, 8, 82653–82661. [Google Scholar] [CrossRef]
- Singh, A.; Batra, S. Ensemble based spam detection in social IoT using probabilistic data structures. Future Gener. Comput. Syst. 2018, 81, 359–371. [Google Scholar] [CrossRef]
- Yilmaz, C.M.; Durahim, A.O. SPR2EP: A semi-supervised spam review detection framework. In Proceedings of the 2018 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining (ASONAM), Barcelona, Spain, 28–31 August 2018. [Google Scholar]
- Rahman, M.S.; Halder, S.; Uddin, M.A.; Acharjee, U.K. An efficient hybrid system for anomaly detection in social networks. Cybersecurity 2021, 4, 10. [Google Scholar] [CrossRef]
- Sedhai, S.; Sun, A. Semi-supervised spam detection in Twitter stream. IEEE Trans. Comput. Soc. Syst. 2017, 5, 169–175. [Google Scholar] [CrossRef]
- Géron, A. Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow: Concepts, Tools, and Techniques to Build Intelligent Systems; O’Reilly Media, Inc.: Newton, MA, USA, 2019. [Google Scholar]
- Lewis, R.J. An introduction to classification and regression tree (CART) analysis. In Proceedings of the Annual Meeting of the Society for Academic Emergency Medicine, San Francisco, CA, USA, 22–25 May 2000. [Google Scholar]
- Quinlan, J.R. C4.5: Programs for Machine Learning; Elsevier: Amsterdam, The Netherlands, 2014. [Google Scholar]
- Wang, Z.; Cha, Y.-J. Unsupervised deep learning approach using a deep auto-encoder with a one-class support vector machine to detect damage. Struct. Health Monit. 2021, 20, 406–425. [Google Scholar] [CrossRef]
- Saari, J.; Strömbergsson, D.; Lundberg, J.; Thomson, A. Detection and identification of windmill bearing faults using a one-class support vector machine (SVM). Measurement 2019, 137, 287–301. [Google Scholar] [CrossRef]
- Binbusayyis, A.; Vaiyapuri, T. Unsupervised deep learning approach for network intrusion detection combining convolutional autoencoder and one-class SVM. Appl. Intell. 2021, 51, 7094–7108. [Google Scholar] [CrossRef]
- Schölkopf, B.; Platt, J.C.; Shawe-Taylor, J.; Smola, A.J.; Williamson, R.C. Estimating the support of a high-dimensional distribution. Neural Comput. 2001, 13, 1443–1471. [Google Scholar] [CrossRef] [PubMed]
- Castellini, J.; Poggioni, V.; Sorbi, G. Fake Twitter followers detection by denoising autoencoder. In Proceedings of the International Conference on Web Intelligence, Leipzig, Germany, 23–26 August 2017. [Google Scholar]
- Sinha, S.; Giffard-Roisin, S.; Karbou, F.; Deschatres, M.; Karas, A.; Eckert, N.; Coléou, C.; Monteleoni, C. Variational autoencoder anomaly-detection of avalanche deposits in satellite SAR imagery. In Proceedings of the 10th International Conference on Climate Informatics, Virtual, 22–25 September 2020. [Google Scholar]
- Chen, Z.; Yeo, C.K.; Lee, B.S.; Lau, C.T. Autoencoder-based network anomaly detection. In Proceedings of the 2018 Wireless Telecommunications Symposium (WTS), Phoenix, AZ, USA, 17–20 April 2018. [Google Scholar]
- Chow, J.K.; Su, Z.; Wu, J.; Tan, P.S.; Mao, X.; Wang, Y.-H. Anomaly detection of defects on concrete structures with the convolutional autoencoder. Adv. Eng. Inform. 2020, 45, 101105. [Google Scholar] [CrossRef]
- Zhang, C.; Liu, J.; Chen, W.; Shi, J.; Yao, M.; Yan, X.; Xu, N.; Chen, D. Unsupervised anomaly detection based on deep autoencoding and clustering. Secur. Commun. Netw. 2021, 2021, 7389943. [Google Scholar] [CrossRef]
- Zhang, H.; Guo, W.; Zhang, S.; Lu, H.; Zhao, X. Unsupervised deep anomaly detection for medical images using an improved adversarial autoencoder. J. Digit. Imaging 2022, 35, 153–161. [Google Scholar] [CrossRef] [PubMed]
- Shafiq, U.; Shahzad, M.K.; Anwar, M.; Shaheen, Q.; Shiraz, M.; Gani, A. Transfer learning auto-encoder neural networks for anomaly detection of DDoS generating IoT devices. Secur. Commun. Netw. 2022, 2022, 8221351. [Google Scholar] [CrossRef]
- Zhang, Y.; Chen, W.; Yeo, C.K.; Lau, C.T.; Lee, B.S. Detecting rumors on online social networks using multi-layer autoencoder. In Proceedings of the 2017 IEEE Technology and Engineering Management Conference (TEMSCON), Santa Clara, CA, USA, 8–10 June 2017. [Google Scholar]
- Hawkins, S.; He, H.; Williams, G.; Baxter, R. Outlier detection using replicator neural networks. In Proceedings of the International Conference on Data Warehousing and Knowledge Discovery, Aix-en-Provence, France, 4–6 September 2002. [Google Scholar]
- Domingos, P. Metacost: A general method for making classifiers cost-sensitive. In Proceedings of the Fifth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Diego, CA, USA, 15–18 August 1999. [Google Scholar]
- Choi, J.; Kim, Y. A heterogeneous learning framework for over-the-top consumer analysis reflecting the actual market environment. Appl. Sci. 2021, 11, 4783. [Google Scholar] [CrossRef]
- Zhao, C.; Xin, Y.; Li, X.; Yang, Y.; Chen, Y. A heterogeneous ensemble learning framework for spam detection in social networks with imbalanced data. Appl. Sci. 2020, 10, 936. [Google Scholar] [CrossRef]
- Kohonen, T. Essentials of the self-organizing map. Neural Netw. 2013, 37, 52–65. [Google Scholar] [CrossRef]
- Eibe, F.; Hall, M.A.; Witten, I.H. The WEKA Workbench. Online Appendix for Data Mining: Practical Machine Learning Tools and Techniques; Morgan Kaufmann: Burlington, MA, USA, 2016. [Google Scholar]
- Datawrapper. Available online: https://www.datawrapper.de (accessed on 11 March 2024).











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Actual Positive | Actual Negative | |
|---|---|---|
| Predicted Positive | ||
| Predicted Negative |
| Type | Feature Name | Feature Description |
|---|---|---|
| Tweet-Based Features | no_userfavourites | Number of likes received by the user who posted the tweet |
| no_lists | Number of lists added by the user who posted the tweet | |
| no_tweet | Number of tweets posted by the user who posted the tweet | |
| no_retweet | Number of retweets of the tweet | |
| no_hashtags (#) | Number of hashtags included in the tweet | |
| no_usermention (@) | Number of user mentions included in the tweet | |
| no_url | Number of URLs included in the tweet | |
| no_char | Number of characters in the tweet | |
| no_digit | Number of numerical digits in the tweet | |
| Account-Based Features | account_age | Number of days between the date the account was first created and the date the most recent tweet was posted |
| no_follwer | Number of followers of the user who posted the tweet | |
| no_following | Number of accounts the user who posted the tweet follows |
| Cluster | Main Characteristics | Number | Dataset 1 | Dataset 2 |
|---|---|---|---|---|
| Cluster 1 |
| 1829 | Known Spam | Known Spam |
| Cluster 2 |
| 1562 | Known Spam | Known Spam |
| Cluster 3 |
| 861 | Unknown Spam | Known Spam |
| Cluster 4 |
| 748 | Known Spam | Unknown Spam |
| Framework | Tweet Type | Dataset 1 | Dataset 2 | ||||
|---|---|---|---|---|---|---|---|
| Precision | Recall | F-Measure | Precision | Recall | F-Measure | ||
| DT–SVM | Known Spam | 0.945 | 0.895 | 0.920 | 0.937 | 0.847 | 0.890 |
| Unknown Spam | 0.873 | 0.864 | 0.868 | 0.860 | 0.816 | 0.837 | |
| Normal | 0.994 | 0.997 | 0.995 | 0.992 | 0.997 | 0.994 | |
| DT–Autoencoder | Known Spam | 0.949 | 0.907 | 0.928 | 0.942 | 0.862 | 0.900 |
| Unknown Spam | 0.897 | 0.878 | 0.887 | 0.879 | 0.854 | 0.867 | |
| Normal | 0.995 | 0.997 | 0.996 | 0.993 | 0.997 | 0.995 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Choi, J.; Jeon, B.; Jeon, C. Scalable Learning Framework for Detecting New Types of Twitter Spam with Misuse and Anomaly Detection. Sensors 2024, 24, 2263. https://doi.org/10.3390/s24072263
Choi J, Jeon B, Jeon C. Scalable Learning Framework for Detecting New Types of Twitter Spam with Misuse and Anomaly Detection. Sensors. 2024; 24(7):2263. https://doi.org/10.3390/s24072263
Chicago/Turabian StyleChoi, Jaeun, Byunghwan Jeon, and Chunmi Jeon. 2024. "Scalable Learning Framework for Detecting New Types of Twitter Spam with Misuse and Anomaly Detection" Sensors 24, no. 7: 2263. https://doi.org/10.3390/s24072263