This section presents the experimental results used to evaluate the performance of the proposed AFCM method.
6.2. Comparative Analysis of Method Performance
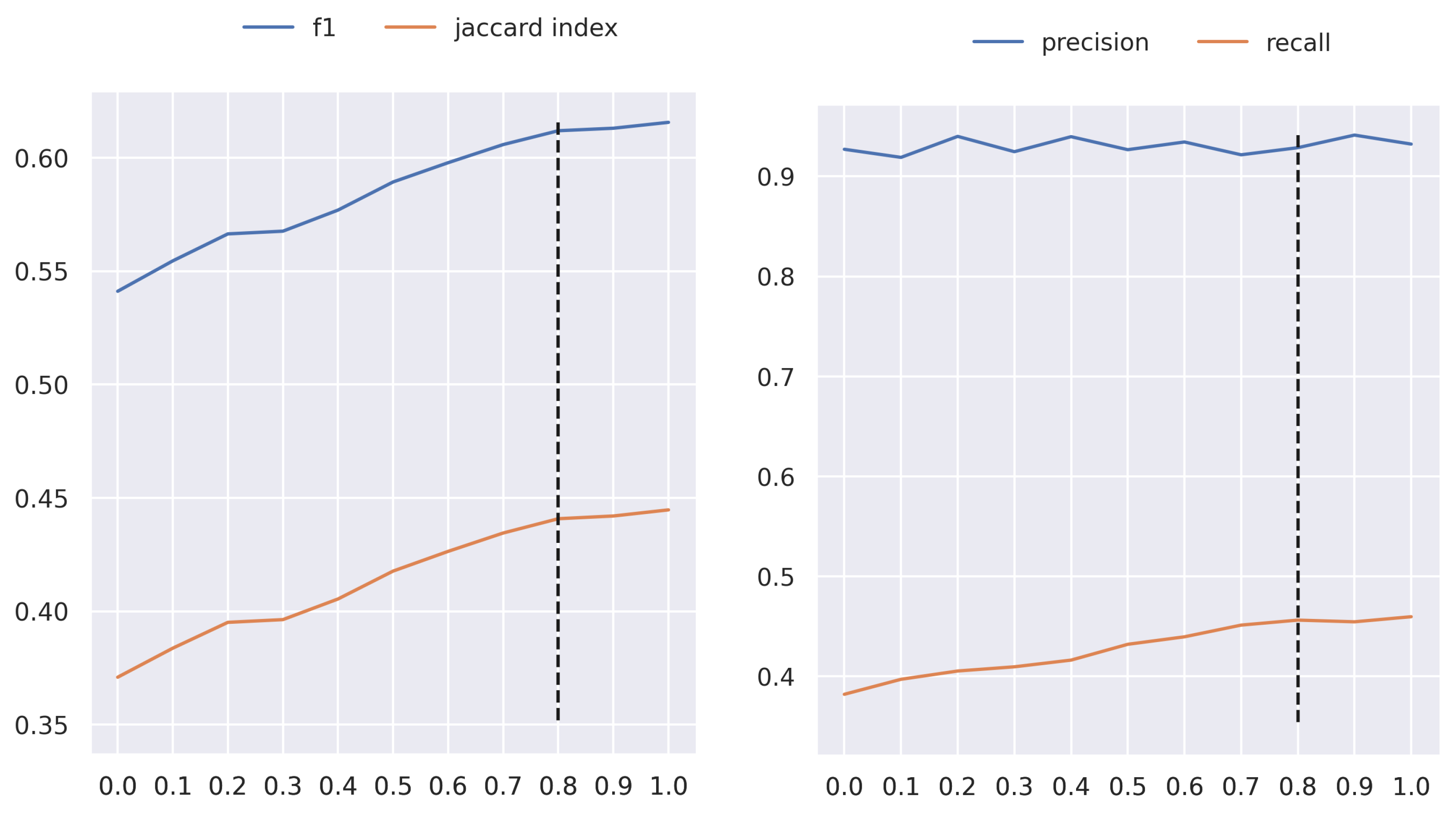
The AFCM method is validated on two food datasets, UNIMIB2016-N and MLChileanFood, and compared with ResNet-50 (considered as baseline) and the AFM corresponding to the method used as the basis of our proposal. The results in terms of recall (R), precision (P),
score, and Jaccard index (JI) can be seen in
Table 1 in UNIMIB2016-N. From this, it is observed that using AFM * for the multi-label problem, i.e., changing the loss function to binary cross-entropy and activation to sigmoid, immediately shows an improvement in all metrics of approximately 3%, except for P, which remains almost the same. This reinforces our assertion that the components involved in AFM are also useful for noisy multi-label learning. The improvement is even more remarkable with the proposed AFCM, where it outperforms the other methods by far. Specifically, the increase is more than 10% in all metrics, except for P, where performance drops by around 2%. Therefore, knowing whether the ingredients are mixed with other ingredients or with the background positively influences the model’s performance.
To further analyze the model results, five confusion matrices were generated for the ingredients with the most true positives (TPs) and false negatives (FNs), selected according to the AFCM results. TPs and FNs can be observed in the first and second row, respectively, of
Figure 5 for AFCM and
Figure 6 for ResNet-50. In each confusion matrix, the upper left cell corresponds to true negative (TN), the upper right cell to false positive (FP), the lower left cell to FN, and the lower right cell to TP. In most cases, the FP is observed to be relatively small, which is consistent with the high P achieved by both models. In terms of TP, there is a great improvement in the ingredients in which AFCM provides its best performance. Most of these ingredients are side dishes, desserts, and bread, which have the most instances in the dataset. In terms of FNs, AFCM tends to have fewer than ResNet-50. All these aspects highlight the advantages of the proposed approach to learning with multi-label noise.
In addition to UNIMIB2016-N, the models were evaluated at MLChileanFood. Unlike UNIMIB2016-N, where noise was introduced synthetically to the labels, in MLChileanFood, it is assumed that noise can occur by the traditional labeling procedure. Furthermore, MLChileanFood is more challenging because the data are acquired from the Google search engine and therefore under unrestricted conditions.
Table 2 shows the mean and standard deviation of the results obtained by the methods. Again, an improvement is observed with AFM * compared to ResNet-50 in all metrics except for P, where the performance drops about 3%. This suggests that the AFM can find more ingredients present in the image than ResNet-50, but in some cases, it predicts a few more ingredients that do not appear there. With AFCM, even better performance was observed for multi-label classification by providing a better balance between R and P and also a higher JI. The latter means that the models tend to produce fewer false predictions and more true predictions compared to the other methods.
The proposed AFCM was also compared with SoA methods developed to deal with noisy multi-label learning and validated on non-food image datasets. HLC [
17] and CLMSU [
18] were trained on UNIMIB2016-N and MLChileanFood using the same experimental setting proposed by the authors. The only change made was a reduction of the batch size used in HLC to 32 images to perform the training on the UNIMIB2016-N dataset, and a different number of samples was considered to generate the head, middle, and tail subsets in CLMSU, depending on the target dataset. Specifically, in UNIMIB2016-N, classes with more than 75 samples, less than 15 samples, and between 15–75 samples were considered to form the head, tail, and middle subsets. In MLChileanFood, more than 1000, less than 100, and between 100–1000 were considered to form the head, tail, and middle subsets. All methods (HLC, CLMSU, and AFCM) use the same backbone (ResNet-50) but differ in the optimizer or the training procedure. The results in terms of R, P,
, and JI are reported in
Table 3. Although HLC and CLMSU provide comparable results on the MS-COCO object recognition benchmark dataset, the performance obtained on images belonging to the food domain differs over a wide range. CLMSU stands out for its ability to adapt to data from different domains. Overall, our AFCM method outperforms CLMSU in UNIMIB2016-N and provides comparable (slightly better) results in MLChileanFood. Focusing on P and R, it can be seen that AFCM provides about 9% less recall but more than 15% improvement in P for both datasets. These results show that our method provides a better trade-off in the reduction of false positive and false negative predictions, prioritizing the former. In summary, the proposed AFCM was able to provide better performance compared to the baseline (ResNet-50), the basis model (AFM), and the two SoA object recognition models.
In addition to the standard multi-label recognition metrics, a statistical significance analysis was performed using the Bonferroni-Dunns [
45] test. The objective of this test is to determine whether the performance of the proposed AFCM method is significantly different from the other methods evaluated.
Table 4 shows the test results when evaluating two classifiers, the proposed AFCM compared to ResNet-50, AFM, HLC, and CLMSU. To perform the test, sample-level food recognition results were obtained in terms of
for UNIMIB2016-N and MLChileanFood. In most cases, the results provided by AFCM are significantly different. Interestingly, it is noted that, for MLChileanFood, although AFCM has almost the same performance difference as AFM and CLMSU (see
Table 2 and
Table 3), statistical significance is observed in CLMSU but not in AFM. This is in agreement with the precision and recall obtained by these methods. Specifically, CLMSU shows a completely different behavior, providing similar results in both metrics, unlike AFM and AFCM, which present a wide distance between them. Therefore, although CLMU has a slightly worse overall
performance, at the sample level, the results are very different. In the case of the AFM, the increase in precision achieved by the AFCM was not sufficient to pass the statistical test.
Some examples of successes and failures of the prediction provided by AFCM in MLChileanFood are presented in
Figure 7. The images were selected according to the Jaccard index. The top two images correspond to those with the highest scores and the bottom two to those with median scores. It can be deduced that the model tends to work best when few ingredients are present in the image (e.g., less than 4). This is the case of the images in the first row, in which there are few and very distinguishable ingredients. Looking at the second row, some errors occur because the ingredients are not in the main content of the image (e.g., celery); there is too little quantity (e.g., peas); the visual appearance is very similar to another (e.g., bell pepper and green beans); or they are occluded by other ingredients (e.g., pizza dough). It is interesting to note that the proposed AFCM can recognize ingredients that correspond to the ground truth but that the annotator did not identify (e.g., the onion in the food image bottom right).
6.4. Evaluation of the Robustness to Data Perturbation
Robustness advantages have been observed when using the posterior probability distribution in deep neural methods to provide predictions. For this reason, the proposed PAFCM, which incorporates the Laplace approximation to compute the posterior probability distribution, has been evaluated. In addition, the evaluation of AFCM using MC-Dropout is considered for comparative purposes. For the latter case, we include in the AFCM a Dropout layer with a probability of 0.1 after each residual block. This configuration was used in both cases: AFCM + Laplace and AFCM + MC-Dropout. Both are used in inference time as a post-hoc method for the proposed AFCM method.
Table 6 summarizes the results in terms of the
score and Jaccard index (JI), considering various data augmentation strategies for perturbing the input data (see
Figure 8). As can be seen in this table, the performance between AFCM concerning PAFCM is comparable when using the Laplace approximation but decreases considerably with MC-Dropout. Unlike Laplace, the MC-Dropout prediction is made by several thin versions of the original model. This could be one reason why, for this task, the thin models achieve an under-fitting of the data distribution, and calculating the mean of all of them to obtain the final prediction does not achieve a gain in performance. Since AFCM with Laplace provides better performance, the rest of the comparison is performed based on this model.
Four rotations and four color adjustments were performed on the data to analyze the behavior of the model in response to this perturbation. In some cases, the changes are imperceptible, but they affect the performance of the model just the same. Changes in rotation and hue make a big difference in performance compared to using the original data. Both are reasonable due to the characteristics of UNIMIB2016-N and the nature of the food itself, where color is one of the most important characteristics. In most cases, PAFCM achieves a small improvement in performance concerning AFCM, which in some cases is more than 0.5%. If computational resources are not a constraint, it can be considered a variant of the proposed method to increase robustness a little.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}