1. Introduction
Human Activity Recognition (HAR) and Human Behavior Recognition (HBR) technologies are integral components of Human-Computer Interaction (HCI) systems. They enable computers to interpret and respond to human actions and behaviors, enhancing the overall user experience. HAR and HBR systems [
1] utilize various sensors and algorithms to analyze data such as movement patterns, gestures and physiological signals, facilitating seamless interaction between humans and computers. However, they raise security concerns about potential misuse or unauthorized access to users’ data. Through robust user identification methods such as biometrics, passwords, or behavioral analysis, HCI systems can mitigate the risk of unauthorized access. Vision technology [
2,
3] can identify different users through physical activity characteristics captured from image frames using high resolution cameras, but it is susceptible to failure in the presence of luminous changes and obstacles within the line-of-sight (LoS) [
4], thus exacerbating significant concerns regarding user privacy. In stark contrast, RF sensors (such as WiFi, RFID, and Zigbee) offer numerous advantages, including freedom from illumination constraints, reduced privacy apprehensions, equitable penetration and widespread availability on IoT devices. As a result, they are widely proposed to enable advanced device-free behavioral sensing [
5,
6]. Towards RF-based behavioral sensing, existing systems propose a variety of behavioral characteristics including daily activities [
7,
8,
9,
10], vital signs [
11,
12] and gestures [
13,
14,
15]. Although these systems have demonstrated their effectiveness with fair accuracy in laboratory settings, they may still encounter real-world constraints. Extracting biometric features from daily activities usually require users consistently performing a set of pre-defined activities for long-term tracking [
5]. The motion of vital signs (e.g., heartbeats [
16] and respiration rate [
17]) remains fragile, and identification may be prone to failure due to body movement artifacts and ambient noise. In contrast, performing gestures (e.g., finger gesture) for identification can practically mitigate the impact of motion noise and offer considerable user-friendliness [
18,
19,
20]. Gesture-based interaction stands as the most common and efficient method of HCI [
21,
22,
23]. Gesture recognition technology is mature and capable of achieving high accuracy. When users write in the air, they commonly use their forefinger naturally. In our experiment, we adhere to this habit by employing forefinger gestures for user identification. Enabling user identification through finger gestures with high accuracy is a non-trivial challenge, which requires addressing two key challenges.
Firstly, as the movement of the finger motion is quite small, the amplitude change in the RF reflected signal caused by finger motion could be very faint, hence it is difficult to identify minor variance among users’ biometrics extracted from the limited signal variance. According to the theory of the Fresnel model [
24,
25], when a user moves his/her hand across the boundaries of Fresnel zones, the CSI of the signal will form a series of peaks and valleys. We regard this variance pattern as a kind of RF signal resolution. If we have more peak values in an unit area we can say that the RF signal resolution is higher. Once the motion becomes smaller, like finger motion, the number of peak values is reduced and the amplitude change in CSI diminishes much smaller, resulting in low accuracy for identification. The key question we have is how to fundamentally improve the RF signal resolution (i.e., CSI variance). Inspired by Young’s double-slit interference experiment [
26], we use a pair of transmitters (double-source) in the same frequency to induce the signal interference. The double-source interference produces numerous dense narrow beams. In other word, it greatly increases the number of boundaries in the same unit area compared with traditional methods. By setting up two orthogonal double-source pairs, the sensing area will be covered by a dense signal mesh, hence the signal resolution is enormously improved.
Secondly, due to user heterogeneity (e.g., different users, preferences, and surroundings), in reality, the data distribution of users’ biometrics may become complex and un-predictable to fail user identification. The performance of the traditional deep learning(DL) technique relies heavily on collecting a large amount of user data as a prerequisite, especially assuming that the represented data distribution is relatively stationary without dynamic changes. Towards robust and efficient model retraining, we utilize a one-shot learning approach based on the Siamese network [
27,
28,
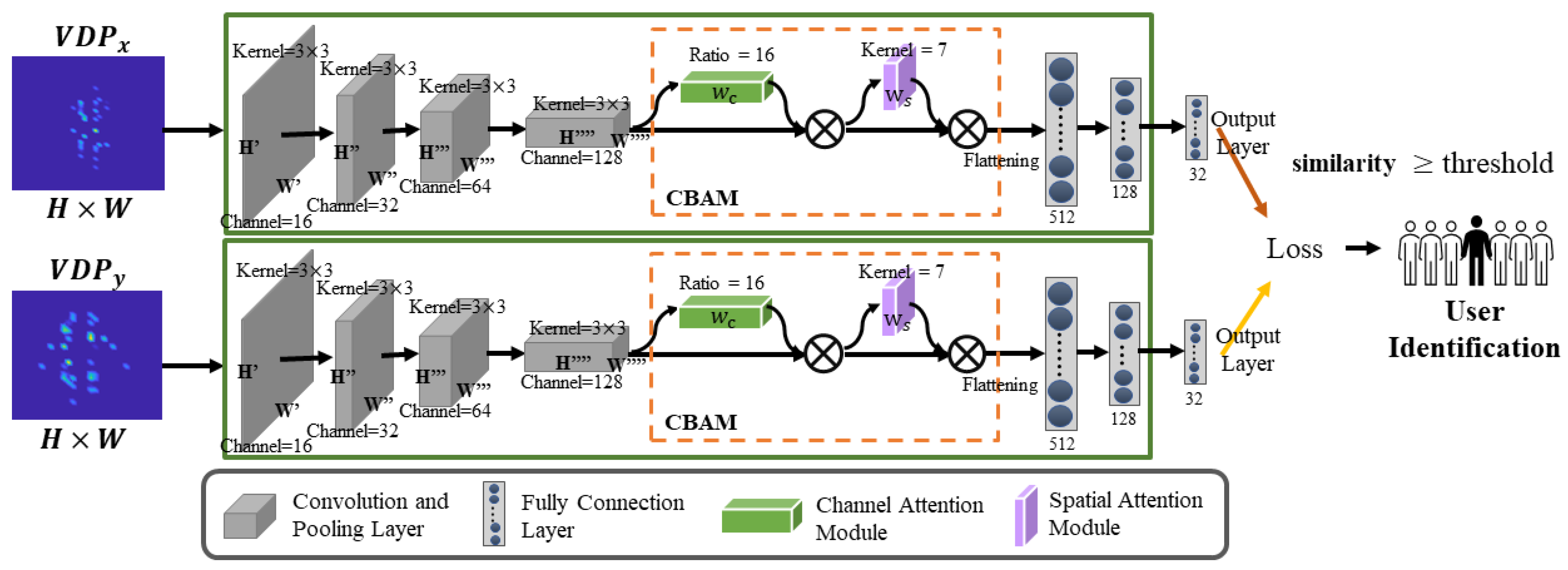
29], with two core techniques: first component reverse (FCR) extraction and convolution block attention module (CBAM), achieving high model robustness and performance in heterogeneous scenarios (e.g., identifying unseen users). A unique velocity distribution profiling (VDP) is calculated from a double-source interference pattern, reflecting the personal motion features.
When users perform finger gestures in a complex environment, the input feature space of extracted biometrics contains both non-related features (i.e., common features shared by the same gestures of users and ambient noise) and user-specific features (i.e., personal features), but the issue is that the non-related features may strongly affect the performance of identifying users. To improve it, we design a first component reverse (FCR) extraction, inspired by principal component analysis (FCR) extraction, inspired by principal component analysis (PCA), hat removes the non-related features (i.e., first component in PCA) and helps extract user-specific features from the input feature space, boosting our CBAM-based Siamese network with a superior identification capability.
To address the above issues, we propose MeshID, a novel RF-based user identification approach leveraging signal interference for accurate finger gesture tracking. MeshID is able to significantly improve the sensing sensitivity by leveraging double-source signal interference and extracting subtle individual biometrics from less distinct finger motions. Due to the effect of enhancing CSI variance, our mesh approach can mitigate the multipath effects and contribute to resisting the interference from ambient environments. By applying an efficient CBAM-based few-shot deep learning framework with FCR extraction, MeshID achieves high model robustness and can be easily adapted to new users with complex surroundings.
The main contribution are summarized as follows:
We present MeshID, an RF-based user identification approach based on a beam structure caused by double-source orthogonal signal interference. The system is able to detect user in-air finger motion with high accuracy, which could support for a variety of smart home/building applications especially for user identification.
To the best of our knowledge, MeshID is the first solution that derives the unique velocity distribution profiling (VDP) features from signal patterns leveraging the novel mesh beam structure. It fully enables user identification by essentially enhancing the signal sensing sensitivity compared to traditional RF-based approaches
We design a first component reverse (FCR) extraction method to emphasize user-specific features and remove non-related features, hence improving the identification accuracy and model capability. We propose a one-shot learning framework with CBAM in a Siamese network for model retraining robustness and efficiency.
We evaluate MeshID in comprehensive real-world experiments. The results demonstrate that MeshID is able to achieve an average identification accuracy of on average by performing single finger gestures in three indoor environments.
The rest of the paper is organized as follows.
Section 2 discusses the preliminary knowledge of the method.
Section 3 presents the design of MeshID.
Section 4 demonstrates the comprehensive evaluation results.
Section 5 shows the key discussions.
Section 6 reviews the related works.
Section 7 concludes the paper and discusses future works.
2. Preliminary
In this section, we introduce the fundamental concept of Channel State Information (CSI) and then explore the double-source interference phenomenon for finger gesture-based user identification.
CSI is a fine-grained physical layer that depicts how RF signals propagate between a transmitter and a receiver [
30,
31]. It captures the slight change in the surrounding objects in both the time domain and spatial domains. The CSI channel
H is modeled by
, where
is the received signal,
is the pre-defined modulated signal and
is the noise vector.
Empirical Study of double-source interference. In tradition, for a pair of transmitters and receivers, as shown in
Figure 1a, the signal variance pattern caused by the reflection of target activity is usually identified as Fresnel zones. Small finger motions in the same zone usually have a small impact on the signal variance, while user activity across different zones causes a large signal variance. We may regard these zones as a kind of “sensing sensitivity”. The zone number can be a measure of sensitivity to sensing. For example, in a
m area (without losing generality, the frequency is set as
GHz), roughly we may have only seven Fresnel zones.
To increase the boundaries of sensing, our intuition is to apply RF signal interference. Inspired by Young’s double-slit interference experiment [
26], we use a pair of transmitters with same frequency to induce the signal interference, resulting in a stripe pattern in a parallel way. The simulation results of signal reflection are depicted in
Figure 1b. The reason why we can see such a fringes pattern is that multiple sources signals can interfere with each other constructively, where the amplitude of combined signal is greater than the individual one, while interference destructively where the amplitude of the combined signal is smaller than the individual one or same with the original. We call the above phenomenon double-source interference. Double-source interference obeys the Huygens-Fresnel Principle [
32], hence the Fresnel zones still exist under this double-source setting, as shown in
Figure 1d. The double-source fringes pattern and the Fresnel zones are overlapping with each other, the Fresnel zones will be divided into several “mesh” cells. Within this dense mesh, if use activity is crosses the cell borders, it also causes a larger signal variance. That is, in the same
m area, we may roughly have more than 83 separated areas in total. The boundaries of “mesh” with fringes are notably increased by interference compared to the Fresnel zones, which indicates that the sensing sensitivity on RF signal interference increases. The interference of multiple waves are generally regarded as a not-so-trivial negative effect leading to unpredictable signal patterns and poor signal quality in wireless sensing, many studies aim to mitigate interference for better accuracy. However, our objective is to utilize such negative effect in user identification and change the effect from “negative” to “positive”.
User identification based on orthogonal double-source interference: Since that a finger gesture may lead to motions in different directions (e.g., drawing a digit “0”), one transmitter pair may only be sensitive to the motions in the perpendicular direction to the transmitters, hence it may lose useful motion features. To address this, we propose a new setup of orthogonal antenna pairs to enable a dense interference pattern (i.e., dense mesh) from both vertical and horizontal directions. Our basic idea is that if we deploy another pair of transmitters with the same distance, but in another direction (e.g., parallel to the
x-axis) and with a slight frequency difference, such transmitters also cause a stripe result but in a vertical way. The amplitude of the received signal appears like a dense mesh with two orthogonal interference transmitter pairs, as shown in
Figure 1c. We name such pairs of transmitters as orthogonal antenna pairs. To observe the mesh pattern of orthogonal double-source interference clearly, the Fresnel zone is omitted from this figure. Consequently, we are able to achieve a higher sensing sensitivity on RF signal compared to traditional methods.
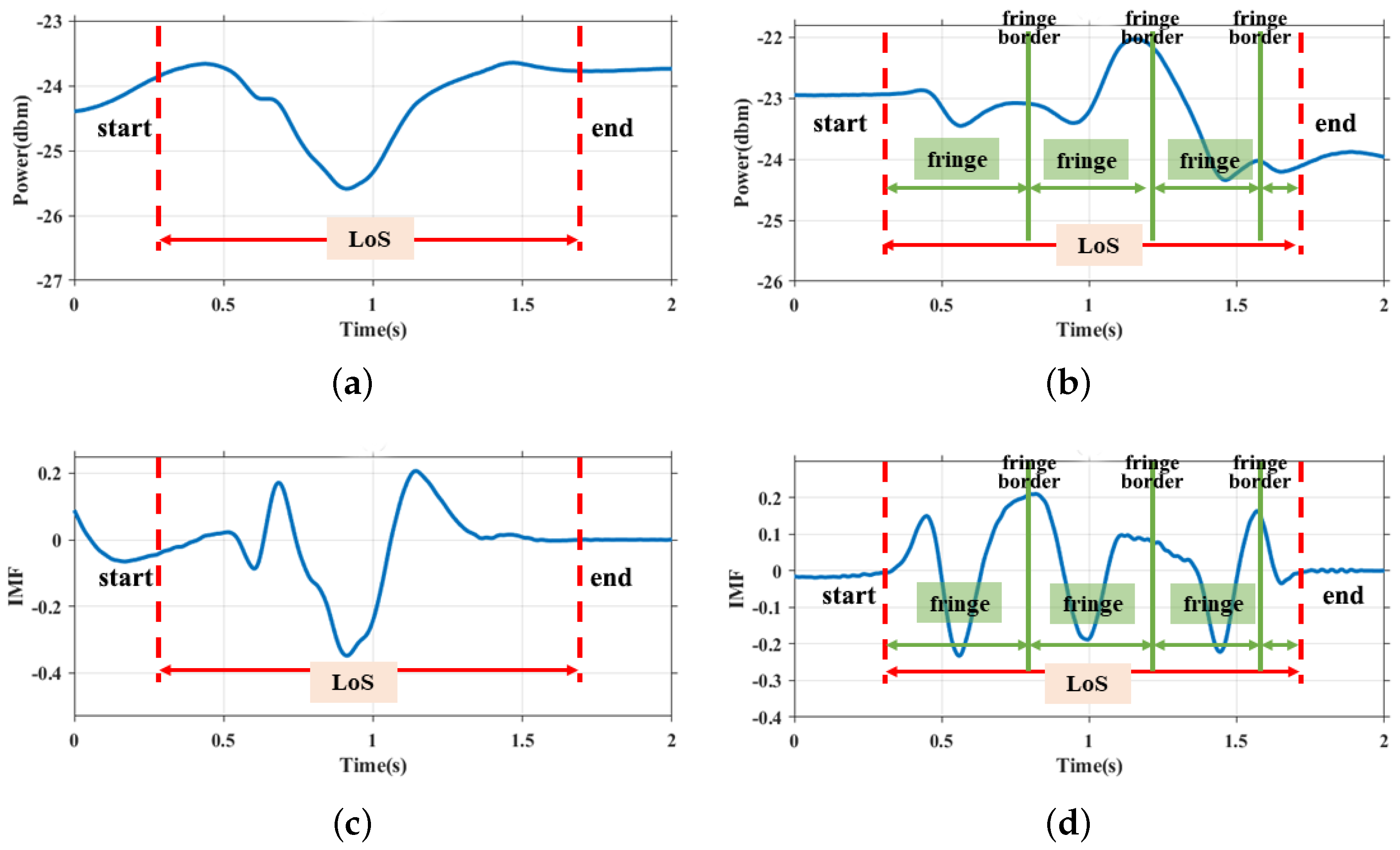
The received CSI comprises a mixture of signals, including the line-of-sight component, double-source component, and others. We utilize the Complementary Ensemble Empirical Mode Decomposition (CEEMD) to separate the double-source interference component from the CSI data. With this feature, we propose a noval VDP feature to capture the fine-grained finger motions of users within the sensing area. The VDP encapsulates the motion change pattern of the user and the corresponding potential biometric features such as the motion speed. Since users have diversity motion habits and behavioral habits (e.g., drawing digit “0” clockwise or anticlockwise, different pauses and speeds when performing gesture), even when executing the same gesture, the moving finger interacts with RF signals differently, resulting in distinct patterns. As shown in
Figure 2,
Figure 2a–c are the CSI variances of three different users drawing the same digit “0” based on their own writing habits.
Figure 2d–f are the corresponding VDPs that have different velocity patterns. Therefore, we can depict users’ behavioral characteristics by leveraging biometric feature extraction methods and bring the opportunity for user authentication.
4. Evaluation
In this section, we begin by outlining our experimental equipment, setup and system workflow. Subsequently, we present our experimental results and comparison with other algorithms. Finally, we conduct an assessment of each component of MeshID.
4.1. Experiment Setup
In principle, our approach is fundamentally applicable to a wide range of RF-based devices, e.g., WiFi, Universal Software Radio Peripheral (USRP), Bluetooth and RFID. To flexibly design carrier signals and baseband waveforms, we utilize USRP devices (Ettus Research, Austin, United States) for system implementation. Specifically, we have two USRP N210 devices (RX1 and RX2), each equipped with an omnidirectional receiver antenna. At the same time, we have two NI USRP 2953R devices with two omnidirectional antenna transmitter pairs. The transmitter sends a simple sinusoidal waveform at a fixed frequency. The transmitters are connected to the PXI Chassis(Ettus Research, Austin, United States). All of the devices are synchronized to the CDA-2990 Clock Distribution Device(Ettus Research, Austin, United States).
To capture two-dimensional CSI variance, we set the two transmitter pairs orthogonally. When performing gestures, the drawing area typically aligns parallel to the user’s orientation. Therefore, the optimal orientation is that placing two transmitter pairs and two receivers orthogonally in front of the user so that the finger could cross more double-source interference fringes. Utilizing only one transmitter pair would render the system sensitive primarily to motions perpendicular to the transmitter pair.
Specifically, the transmitter pair 1 (
) operates at
GHz is placed horizontally positioned with a 50 cm apart, while the transmitter pair 2 (TX2) operates at
GHz is placed vertically positioned, also with a 50 cm apart, as shown in
Figure 9a. The optimal node distance of a transmitter pair is 50 cm, which will be discussed in later
Section 4.2. The distances between TX1 and RX1, TX2 and RX2 are both 1 m. Since the frequency of the TX1 pair and TX2 pair have a slight difference, the transmitted signals only interfere with each other inside each transmitter pair. The devices are shown in
Figure 9b. Both receivers and transmitters are deployed on a customized shelve with an orthogonal setting. Our algorithms are performed in a DELL server with an i7-6850K
GHz Processor and 64 G RAM. The operation system of the server is Windows 10 with 64-bit.
We thoroughly evaluate our prototype across three different indoor environments: a standard office (3.4 m × 3.8 m), a meeting room (5 m × 7 m), and a hallway (2.8 m × 35 m), as shown in
Figure 10. During data collection, ambient individuals within these environments were not required to vacate the premises.
Our experiments involve the collection of two datasets. During data collection, users are instructed to freely perform in-air gestures at their desired speed and size. The first dataset contains 2268 gesture samples (6 users × 3 scenes × 6 gestures × 21 samples). We select 6 in-air finger gestures from three categories: digits, letters, and symbols for user identification, as they are the most commonly used in passwords. Specifically, we use “3” and “6” for digits, “d” and “M” for letters, and “@” and “&” for symbols. The second dataset serves to evaluate the system. The data is collected from another 18 users. This dataset comprises a total of 3600 gestures samples (18 users × 10 gestures × 20 samples). Users are instructed to perform 10 Arabic numerals “0–9” to further analyze user-to-user feature variations. Digits are a basic and familiar form of characters for most people. They are universally understood and accepted across different languages and cultures, making them accessible to a wide range of users without language barriers. In total, our dataset comprises 24 users, including 18 males and 6 females with heights ranging from 155 cm to 185 cm and weights ranging from 45 kg to 80 kg. Standard cross-validation techniques are employed in our evaluation process.
4.2. Impact of Node Distance between Transmitters
In MeshID, the resolution of the signal is determined by the density of the mesh, which in turn relies on the node distance between each transmitter pair. This subsection explores the impact of such node distance on the mesh pattern. Since the interference setting mandates the node distance to be a multiple of the wavelength (approximately 5 cm in our setup), within the 100 cm × 100 cm area, we varied the node distance from
to
, incremented by
. The theoretical interference patterns are illustrated in
Figure 11a–c. The findings indicate a direct proportional relationship between the node distance of each transmission pair and its density when the radio frequency remains constant. Opting for a denser mesh pattern necessitates a larger node distance, and vice versa.
We employ the first dateset for the subsequent two subsections, where six users are tasked with performing six gestures across three categories. To be specific, “3” and “6” for digits, “d” and “M” for digits, and “@” and “&” for symbols. Performance evaluation for gesture recognition and user identification is conducted using the standard cross-validation method. Few samples (4 in our model) of the one user are used for retraining and the rest of the samples from this users are used for testing. The data from another five users are only used for pretraining).
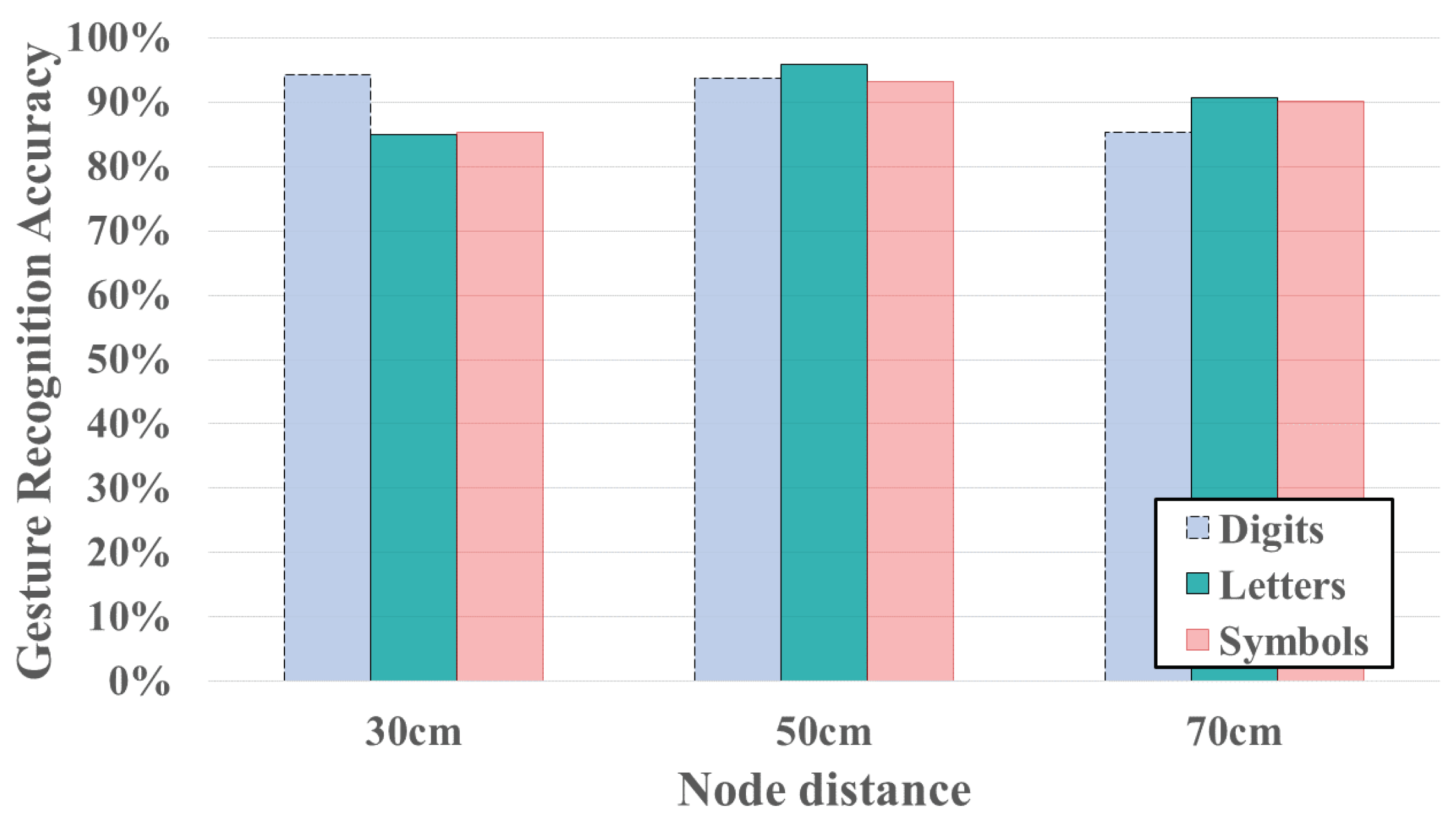
The experiments results for three different transmitter node distances (e.g., 30 cm, 50 cm and 70 cm) are shown in
Figure 12 and
Figure 13. The results demonstrate that using 5 cm node distance setting achieve the highest average accuracy for both gesture recognition accuracy and user identification. In
Figure 12, with the node distance set to 50 cm, the gesture recognition accuracy of three types of symbols are
,
and
, respectively. The average accuracy of gesture recognition across the three different transmitter node distances is
,
and
, respectively.
Figure 13 illustrates the impact of employing three different node distances on user identification. The average accuracy for user identification in different settings is
,
and
, respectively. The system may fail in gesture recognition, but it still possible to identify user successfully. This is attributed to the fact that although the FCR extraction is trained based on the result of gesture recognition, but we transformed CSI time series to several components, only few top components (the first component in our FCR design) is removed. Consequently, user-specified features for user identification may still be retained. Hence, the user identification could has better performance than gesture recognition.
Additionally, the results indicate minor differences between different node distances in MeshID. Hence, the antennas placement in MeshID is flexible to accommodate various real-world scenarios with practicability. Considering our scenario is to identify the users through finger gestures, we need to make sure that the mesh cell size is able to match the finger width (approximately 2–3 cm) of an average person. Therefore, we default to setting node distance as ( cm) by default in our subsequent experiments.
4.3. Performance of MeshID
Table 1 presents the results of gesture recognition and user identification across three different environments, spanning from a compact office space to an expansive hallway. These assessments utilize the first dataset and adhere to the standard cross-validation procedure. Results reveal that the gesture recognition accuracy of MeshID achieves
in an office,
in a meeting room and
in a hallway. Notably, since the differences of the results across these environments are minor, MeshID is able to achieve a fair robustness in adapting to diverse indoor settings. MeshID attains identification accuracy of
in an office,
in a meeting room and
in a hallway, respectively. Notably, the highest identification accuracy is recorded in the hallway environment, attributed to the minimal presence of multipath effects. On average, MeshID system achieves an identification accuracy of
. According to the results, the identification accuracy on average of three gesture categories is
for digits,
for letters, and
for symbols. It can be observed that all types of gestures perform well in three indoor environments. Delving into specific gestures, the average accuracy of gesture “3” is
, gesture “6” is
, gesture “
d” is
, gesture “
M” is
, gesture “@” is
and gesture “&” is
. Digits are universally understood and accepted across different languages and cultures, making them accessible to a wide range of users without language barriers. Therefore, to make the evaluation more general, we choose digits as the identification gestures for the following experiments.
4.4. Performance of User Identification
To further investigate the performance of our user identification system, we employ a larger second dataset for subsequent evaluations. 18 users are asked to perform the same finger gestures 20 times. Data from the remaining 6 users are only used for intrude detection in later. Other 12 users are evaluated using the standard cross-validation method. Without loss of generality, we test digital numbers (“0” to “9”) 20 times for each user. Consistency was maintained in the stroke order for each digit, with users instructed to write the digits in a clockwise manner (e.g., writing digit “0” clockwise). The user identification results are shown in
Figure 14. The average identification accuracy across the 10 gestures stands at
. With the exception of digit “1”, the accuracy of all other digits exceeds
. Specifically, four digits demonstrate outstanding accuracy:
for digit “0”,
for digit “4”,
for digit “5”, and
for digit “8”. Conversely, the identification accuracy for finger gesture "1" and "9" is comparatively lower than others. This discrepancy could be attributed to the simplicity of the strokes for “1” and “9”, where different users might not exhibit significant variations in their finger gestures. Conversely, for the remaining finger gestures, we observe a notably high identification accuracy.
To further evaluate the security level of the system, we conducted an intrusion detection scenario where we enlist 6 unseen users to act as spoofers. These 6 spoofers are replicate the gestures of target users in an attempt to bypass the user identification process. We employ the true negative value to measures the probability that MeshID correctly identifies an unauthorized user. The results, presented in
Table 2, reveal a detection accuracy exceeding
for all 6 spoofers, with four of the six users achieving approximately
. While our primary focus lies on user identification rather than binary classification, the framework of MeshID could still achieves an overall detection accuracy of
with no prior information of the testing environments.
4.5. Impact of Signal Interference
As mentioned in
Section 3, we have learned in theory why signal interference can improve the sensing sensitivity. To further understand how the signal interference affects the performance, we conducted a comparative analysis of experimental results using spectrograms based on our double-source interference setting and the traditional single-source setup. We transform the CSI signals obtained from both settings to Continuous Wavelet Transform (CWT) spectrograms. Since the VDPs serve as a unique feature based on interference patterns, we opted for the more commonly used CWT for the comparison.
In single-source experiments, only one ominidirectional antenna is connected to a transmitter, resulting in no signal interference within the finger movement area, in contrast to the double-source setup. In double-source interference scenario, two ominidirectional antennas, referred to as an antenna pair, are connected to a transmitter. Both antennas operate under the same transmission settings, including frequency. Data from 10 users of second dataset are used in this experiment. The other setting remains consistent with those previously introduced.
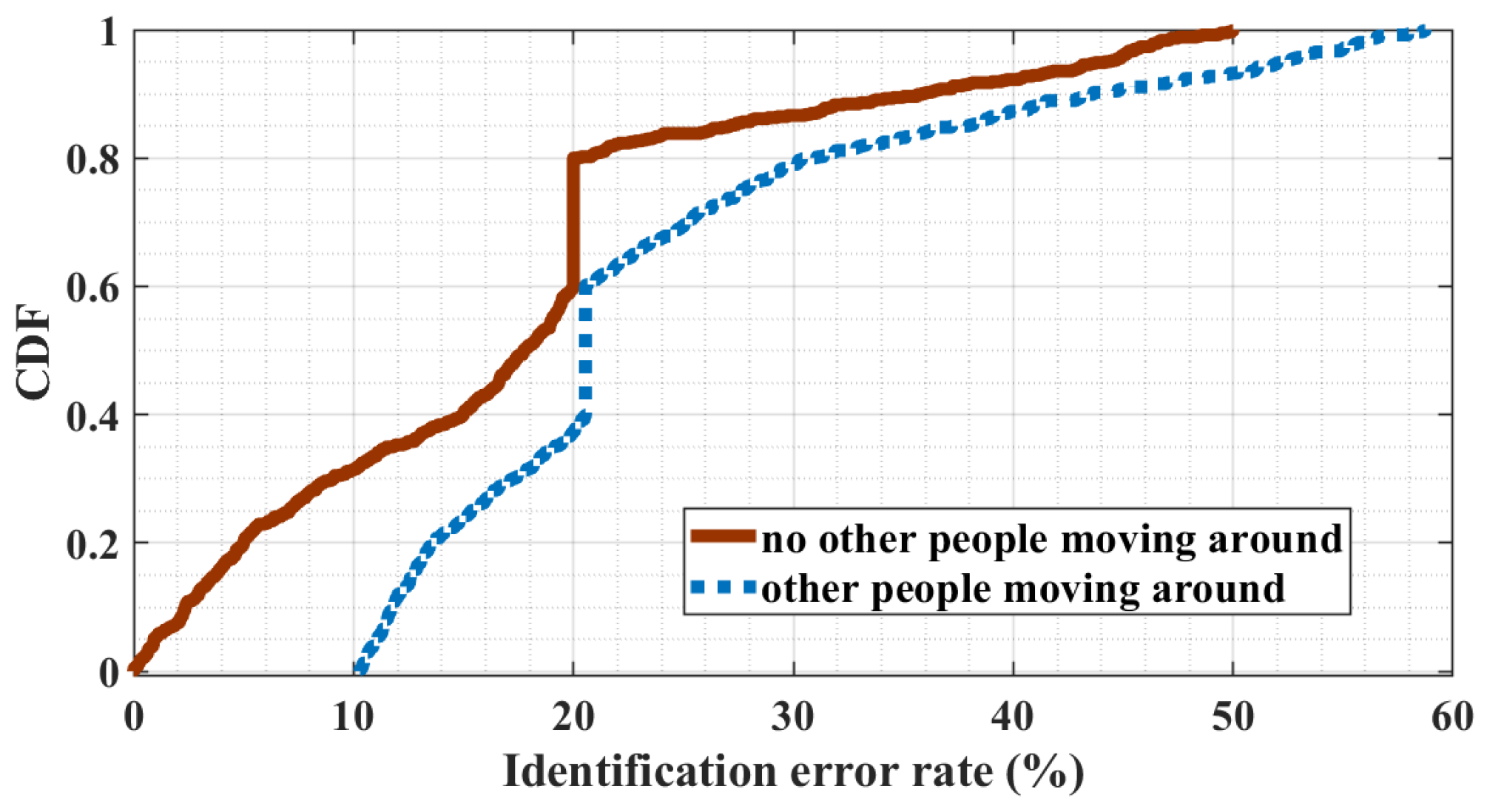
Figure 15 illustrates the Cumulative Distribution Function (CDF) of the identification error rate with interference and without interference. We can see that the average accuracy of double-source interference setting significantly surpasses that of the single-source setup. Specifically, the inclusion of interference in the signal enhances the system’s identification accuracy by
compared to scenarios without interference. Therefore, double-source interference setup creates a fine-grained signal mesh within the designated area, leading to high user identification accuracy.
4.6. Impact of Ambient People Moving
In a typical public room, it is a common condition that other people may dynamically move around when the user is performing finger gestures. Since the wireless signal is sensitive to ambient environment changes, ambient people moving may easily affect the CSI variances, which may have a side effect on user identification. We study the performance of MeshID under the impact of ambient people moving.
Figure 16 showcases identification results when a single gesture is performed while an individual moves within a 3-m range. Similarly,
Figure 17 depicts results when two consecutive gestures are executed amidst ambient movement. The presence of ambient movement causes a slight decrease in identification error rates, which remain within acceptable bounds for most scenarios. Furthermore, increasing the number of finger gestures performed by the user enhances identification accuracy. This result demonstrates that MeshID is performed as robust to the impact of ambient people moving. Theoretically, the proposed interference wave, comprising a superposition of two waveforms with same frequency, results in stronger CSI variances, facilitating more resilient feature extraction for user identification compared to traditional single-wave setups. Consequently, MeshID effectively mitigates the adverse effects of ambient movement, enhancing overall robustness.
4.7. Performance of FCR Extraction and CBAM
FCR extraction and the CBAM Module are two key components of MeshID. The former removes the non-related features from the input feature space, while the latter extracts features from both channel and spatial axes and focuses on the places with more important information. In order to investigate how these two components affect the performance, we compare our algorithm with a traditional CNN and test the impact of each component.
As shown in
Figure 14, employing only the basic CNN yields an average accuracy of
. Introducing the PCA reverse extraction algorithm enhances the average accuracy to
, surpassing the basic CNN by
. Furthermore, integrating both the PCA reverse extraction algorithm and the CBAM Module elevates the average accuracy to
, marking a
improvement. Therefore, both components significantly contribute to enhancing user identification accuracy.
4.8. Comparison with Baseline Approaches
MeshID could be a more robust and flexible extended authentication component in existing recognition systems. We evaluated our system on user identification by comparing it with two alternative state-of-the-art approaches, FingerPass [
38] and FreeAuth [
18]. Both of them are leveraging wireless information for user authentication. Specifically, FingerPass utilizes segmented CSI time series as learning features and adopts the LSTM-based DNN model. FreeAuth proposes a CNN-based method for extracting CSI features. FreeAuth applies a Recurrent Neural Network (RNN) model to extract users’ gesture characteristics and maximize the individual uniqueness characterized by a Gaussian Mixture Model (GMM). To control the variable, the training and evaluation process for the baselines follow the same rules of MeshID (e.g., the number of training epoch). We utilize the same dataset, which is our first dataset, for training and evaluation purposes. The comparison results of user identification are summarized in
Table 3. Both MeshID and FreeAuth exhibit superior identification results, achieving over
accuracy, compared to FingerPass when tested with seven users.
To ascertain the relationship between system performance and the number of users, we evaluated the three systems with varying numbers of users, ranging from 7 to 12. FingerPass and FreeAuth experience a significant degradation in identification accuracy as the number of users increases. However, our system maintains an average identification accuracy of over for up to 12 users. MeshID achieves better overall performance than the other two approaches, specifically, outperforming FingerPass by about and FreeAuth by nearly with up to 12 users. We noticed that emphasizing user-specified features can mitigate the side effect of the same gesture, and improve the robustness of the system with a larger user number.
It satisfies the demands of most families and some small groups. The performance of MeshID keeps consistency as the number of users increases from 7 to 12. In reality, the challenge of user heterogeneity increases significantly with a large number of users (e.g., thousands of users). However, collecting and labeling finger gestures from such a massive user pool for evaluation purposes poses considerable‘difficulties.
5. Discussion
Impact of user height. Different user height may impact the identification accuracy. To investigate the relationship between identification accuracy and user height, we analyzed the height distribution of users. As the statistical result shows in
Figure 18, shorter users tend to achieve higher identification accuracy. The height distribution, ranging from 155 cm to 185 cm, is represented on the left axis. In our experiments, we fixed antenna pairs at relatively low positions to accommodate users of different heights. Consequently, taller users may experience more reflected signals from lower parts of their body, such as the chest. Despite this challenge, MeshID maintains a high capability of identification, as gesture pattern retain their uniqueness with interference settings. However, it’s worth noting that antenna height adjustments can be made to suit different scenarios.
Impact of user weight. The weight of the users varies from 45 kg to 80 kg. The right axis in
Figure 18 represents the weight of the user. The figure shows that the identification decrease is not caused primarily by user weight. Although some of the statistical values show that identification accuracy is better when user has lower weight. That is because user who is shorter usually has lower weight. To delve deeper into this relationship, we conducted a focused analysis on data from users within the same height range. Surprisingly, our findings reveal no discernible pattern in the distribution of identification accuracy, indicating that weight alone does not dictate accuracy levels.
Impact of motion speed. In our experiments, users are free to perform gestures de-pending on their habits. Different motion speeds may result in different sample lengths.However, RF devices usually have a related high sampling rate (e.g., more than 250 Hz), hence the sampling interval is less than 0.004 s. It is short enough to capture the normal motion finger. The sampling rate of USRP is much higher; it could be up to 200 MHz. In our setup, the signal sampling rate is 651 Hz, It is adequate for different motion speed samples. There-fore, the motion speed is not the significant factor that affects the identification accuracy.
Impact of different environments. The multipath effect is a phenomenon prevalent in radio frequency applications where signals travel multiple paths from transmitter, encountering reflections, diffraction, and scattering off objects and surfaces in the environment. Consequently, the receiver detects various versions of the transmitted signal, each arriving at slightly different times and exhibiting diverse amplitudes and phases. In principle, RF systems in outdoor environments usually perform better than indoor. Since in indoor environments, with numerous reflective surfaces and obstacles, the multipath effect becomes particularly pronounced, leading to signal degradation and complicating signal processing. We conducts MeshID in three environments: an office, a meeting room and a hallway. According to the identification results, which are in the office, in the meeting room and in the hallway. These outcomes suggest that reduced multipath effects likely contribute to the system’s enhanced performance.
Latency. It takes about 1 s to 30 s to perform a gesture in our evaluation. This timeframe is sufficient to satisfy most users, including those with physical limitations who can only draw gestures slowly. We also implement MeshID on a desktop with 12th Gen Intel(R) Core(TM) i3-12100F 3.30 GHz. The time consumption of MeshID mainly comes from the noise removal module and the data transformation module. It demands, on average, 1.743 s to identify the user when eight users are in the database after segmenting the gesture. We believe it is adequate for the majority of identification application scenarios for users.
From the results, it is convincing that the proposed mesh and one-shot DL approach can address the challenge of user heterogeneity, enabling MeshID with high robustness.






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}