
Vision-Based On-Road Nighttime Vehicle Detection and Tracking Using Improved HOG Features
Abstract
:1. Introduction
2. Proposed Method
2.1. Object Proposal Generation Method
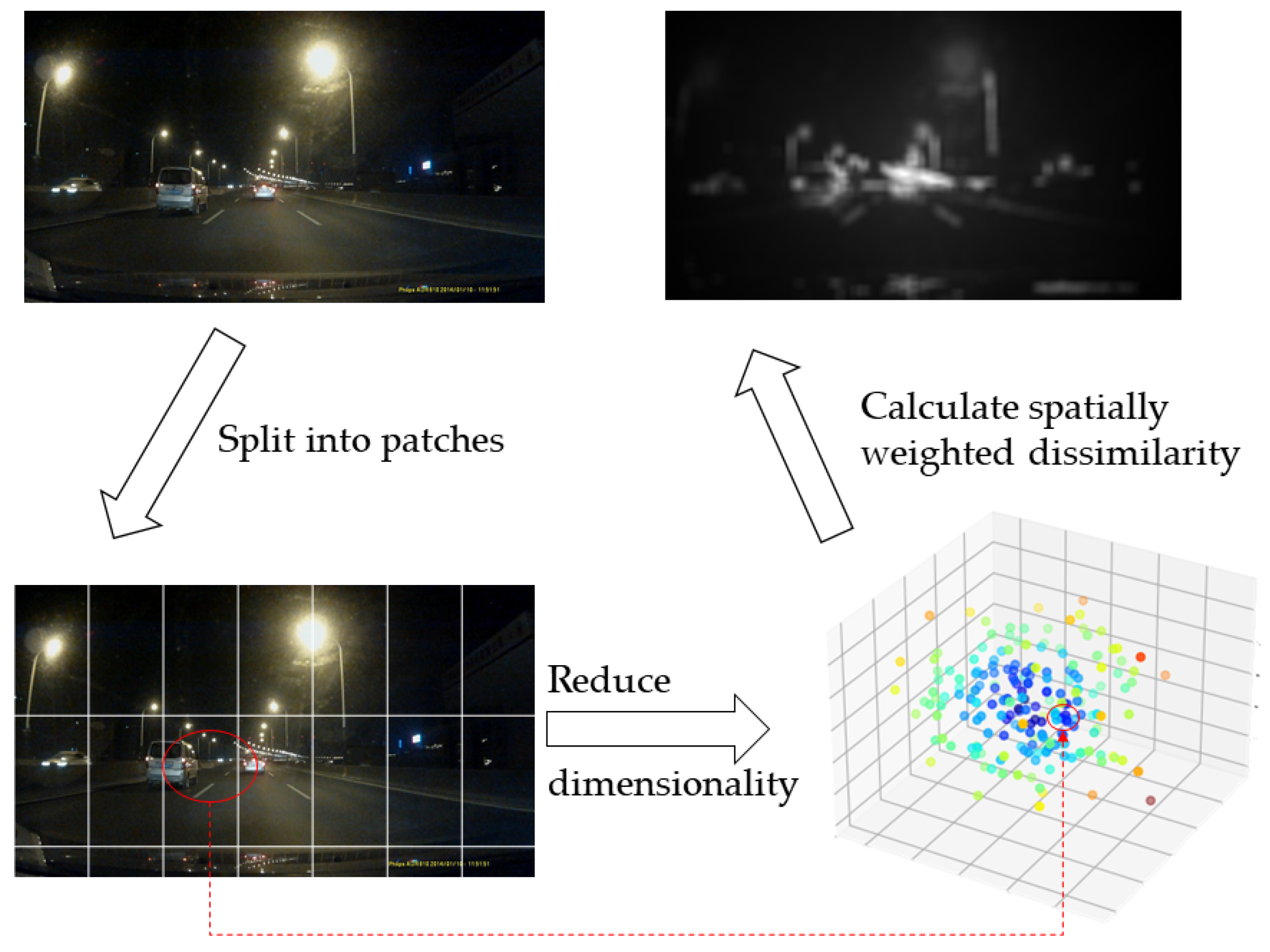
2.1.1. Background Light Removing Based on Saliency Segmentation
2.1.2. Segmentation Method Based on Template
2.2. Hypotheses Verification
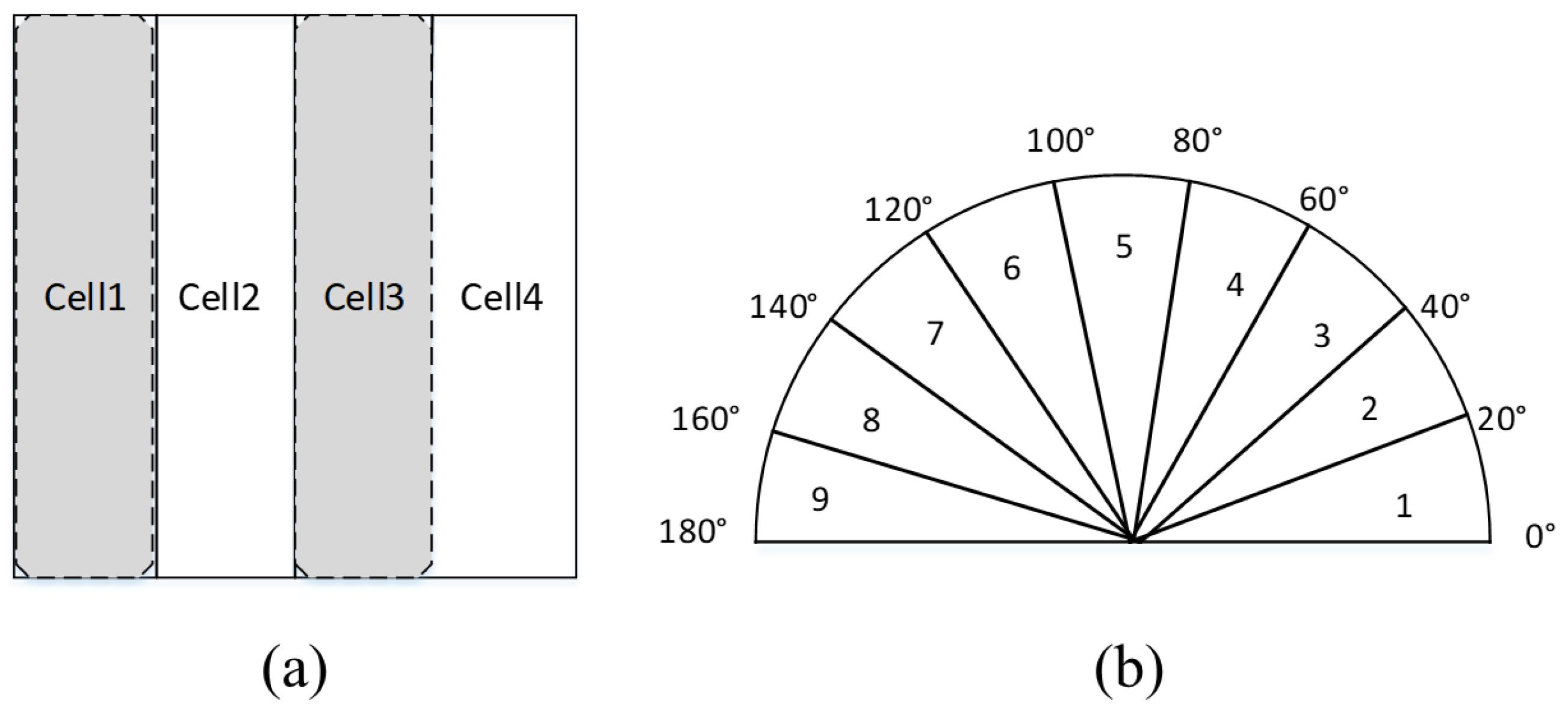
2.2.1. S-HOG Feature Extraction
2.2.2. SVM Training
2.2.3. Overlapped Area Removal
2.2.4. Vehicle Tracking
3. Results and Discussion
3.1. Comparison of Different Saliency Methods
3.2. Comparison of Different Feature Extraction Methods
3.3. Deep Learning Algorithm Detection and Comparison
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Shabestari, Z.B.; Hosseininaveh, A.; Remondino, F. Motorcycle Detection and Collision Warning Using Monocular Images from a Vehicle. Remote Sens. 2023, 15, 5548. [Google Scholar] [CrossRef]
- Mu, K.; Hui, F.; Zhao, X.; Prehofer, C. Multiscale edge fusion for vehicle detection based on difference of Gaussian. Optik 2016, 11, 127. [Google Scholar] [CrossRef]
- Toney, G.; Bhargava, C. Adaptive headlamps in automobile: A review on the models, detection techniques, and mathematical models. IEEE Access 2021, 9, 87462–87474. [Google Scholar] [CrossRef]
- Yang, Z.; Pun-Cheng, L.S. Vehicle detection in intelligent transportation systems and its applications under varying environments: A review. Image Vision Comput. 2018, 69, 143–154. [Google Scholar] [CrossRef]
- Ibarra-Arenado, M.; Tjahjadi, T.; Perez-Oria, J.; Robla-Gomez, S.; Jimenez-Avello, A. Shadow-based vehicle detection in urban traffic. Sensors 2017, 17, 975. [Google Scholar] [CrossRef] [PubMed]
- Wang, X.; Tang, J.; Niu, J.; Zhao, X.J.N. Vision-based two-step brake detection method for vehicle collision avoidance. Neurocomputing 2016, 173, 450–461. [Google Scholar] [CrossRef]
- Huang, D.Y.; Chen, C.H.; Chen, T.Y.; Hu, W.C.; Feng, K.W. Vehicle detection and inter-vehicle distance estimation using single-lens video camera on urban/suburb roads. J. Vis. Commun. Image Represent. 2017, 46, 250–259. [Google Scholar] [CrossRef]
- Pradeep, C.S.; Ramanathan, R. An improved technique for night-time vehicle detection. In Proceedings of the 2018 International Conference on Advances in Computing, Communications and Informatics (ICACCI), Karnataka, India, 19–22 September 2018; pp. 508–513. [Google Scholar] [CrossRef]
- Gao, F.; Ge, Y.; Lu, S.; Zhang, Y. On-line vehicle detection at nighttime-based tail-light pairing with saliency detection in the multi-lane intersection. IET Intell. Transp. Syst. 2019, 13, 515–522. [Google Scholar] [CrossRef]
- Satzoda, R.K.; Trivedi, M.M. Looking at vehicles in the night: Detection and dynamics of rear lights. IEEE Trans. Intell. Transp. Syst. 2019, 20, 4297–4307. [Google Scholar] [CrossRef]
- Tang, Y.; Zhang, C.; Gu, R.; Li, P.; Yang, B. Vehicle Detection and recognition for intelligent traffic surveillance system. Multimed. Tools. Appl. 2017, 76, 5817–5832. [Google Scholar] [CrossRef]
- Song, J.f. Vehicle detection using spatial relationship gmm for complex urban surveillance in daytime and nighttime. Int. J. Parallel Program. 2018, 46, 859–872. [Google Scholar] [CrossRef]
- Chien, J.C.; Chen, Y.S.; Lee, J.D. Improving night time driving safety using vision-based classification techniques. Sensors 2017, 17, 2199. [Google Scholar] [CrossRef] [PubMed]
- Kuang, H.; Zhang, X.; Li, Y.J.; Chan, L.L.H.; Yan, H. Nighttime vehicle detection based on bio-inspired image enhancement and weighted score-level feature fusion. IEEE Trans. Intell. Transp. Syst. 2017, 18, 927–936. [Google Scholar] [CrossRef]
- Dai, X.; Liu, D.; Yang, L.; Liu, Y. Research on headlight technology of night vehicle intelligent detection based on hough transform. In Proceedings of the 2019 International Conference on Intelligent Transportation, Big Data & Smart City (ICITBS), Changsha, China, 12–13 January 2019; pp. 49–52. [Google Scholar] [CrossRef]
- Tang, J.; Li, S.; Liu, P.J.P.R. A review of lane detection methods based on deep learning. Pattern Recognit. 2021, 111, 107623. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 10–16 October 2016; pp. 21–37. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar] [CrossRef]
- Gao, H.; Cheng, B.; Wang, J.; Li, K.; Zhao, J.; Li, D. Object Classification Using CNN-Based Fusion of Vision and LIDAR in Autonomous Vehicle Environment. IEEE Trans. Industr. Inform. 2018, 14, 4224–4231. [Google Scholar] [CrossRef]
- Mo, Y.; Han, G.; Zhang, H.; Xu, X.; Qu, W.J.N. Highlight-assisted nighttime vehicle detection using a multi-level fusion network and label hierarchy. Neurocomputing 2019, 355, 13–23. [Google Scholar] [CrossRef]
- Zhang, X.X.; Zhu, X. Moving vehicle detection in aerial infrared image sequences via fast image registration and improved YOLOv3 network. Int. J. Remote Sens 2020, 41, 4312–4335. [Google Scholar] [CrossRef]
- Wang, H.; Yu, Y.; Cai, Y.; Chen, X.; Chen, L.; Liu, Q. A Comparative Study of State-of-the-Art Deep Learning Algorithms for Vehicle Detection. IEEE Intell. Transp. Syst. Mag. 2019, 11, 82–95. [Google Scholar] [CrossRef]
- Jeong, K.M.; Song, B.C. Night time vehicle detection using rear-lamp intensity. In Proceedings of the 2016 IEEE International Conference on Consumer Electronics-Asia (ICCE-Asia), Seoul, Republic of Korea, 26–28 October 2016; pp. 1–3. [Google Scholar] [CrossRef]
- Gautam, S.; Kumar, A.J.M.T. Applications. Image-based automatic traffic lights detection system for autonomous cars: A review. Multimed. Tools. Appl. 2023, 82, 26135–26182. [Google Scholar] [CrossRef]
- Ding, Z.; Mo, W. Vehicle Type and Sub-type Recognition by Lamp Pairs Distance and Lamp Contour in ITS. In Proceedings of the 2020 IEEE 8th International Conference on Computer Science and Network Technology (ICCSNT), Dalian, China, 20–22 November 2020; pp. 134–138. [Google Scholar] [CrossRef]
- Arunmozhi, A.; Park, J. Comparison of HOG, LBP and Haar-Like Features for On-Road Vehicle Detection. In Proceedings of the 2018 IEEE International Conference on Electro/Information Technology (EIT), Rochester, NY, USA, 3–5 May 2018; pp. 0362–0367. [Google Scholar] [CrossRef]
- Chien, C.L.; Hang, H.M.; Tseng, D.C.; Chen, Y.S. An image based overexposed taillight detection method for frontal vehicle detection in night vision. In Proceedings of the 2016 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA), Jeju, Republic of Korea, 13–16 December 2016; pp. 1–9. [Google Scholar] [CrossRef]
- Laopracha, N. The Combination of Different Cell Sizes of HOG with KELM for Vehicle Detection. In Proceedings of the Recent Advances in Information and Communication Technology 2019: Proceedings of the 15th International Conference on Computing and Information Technology (IC2IT 2019), Bangkok, Thailand, 4–5 July 2019; pp. 180–190. [Google Scholar] [CrossRef]
- Yin, G.; Yu, M.; Wang, M.; Hu, Y.; Zhang, Y. Research on highway vehicle detection based on faster R-CNN and domain adaptation. Appl. Intell. 2022, 52, 3483–3498. [Google Scholar] [CrossRef]
- Ju, Z.; Zhang, H.; Li, X.; Chen, X.; Han, J.; Yang, M. A Survey on Attack Detection and Resilience for Connected and Automated Vehicles: From Vehicle Dynamics and Control Perspective. IEEE TIV. 2022, 7, 815–837. [Google Scholar] [CrossRef]
- Chen, X.; Wang, Z.; Hua, Q.; Shang, W.L.; Luo, Q.; Yu, K. AI-Empowered Speed Extraction via Port-Like Videos for Vehicular Trajectory Analysis. IEEE Trans. Intell. Transp. Syst. 2023, 24, 4541–4552. [Google Scholar] [CrossRef]
- Wu, J.; Shen, T.; Wang, Q.; Tao, Z.; Zeng, K.; Song, J. Local Adaptive Illumination-Driven Input-Level Fusion for Infrared and Visible Object Detection. Remote Sens. 2023, 15, 660. [Google Scholar] [CrossRef]
- Lee, D.H.; Liu, J.L. End-to-end deep learning of lane detection and path prediction for real-time autonomous driving. Signal Image Video Process. 2022, 17, 199–205. [Google Scholar] [CrossRef]
- Nadeem, H.; Javed, K.; Nadeem, Z.; Khan, M.J.; Rubab, S.; Yon, D.K.; Naqvi, R.A.J.S. Road feature detection for advance driver assistance system using deep learning. Sensors 2023, 23, 4466. [Google Scholar] [CrossRef] [PubMed]
- Li, S.; Zhao, L. A low-cost and fast vehicle detection algorithm with a monocular camera for adaptive driving beam systems. IEEE Access 2021, 9, 26147–26155. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hue | Saturation | Value |
|---|---|---|
| 0–30 and 150–180 | 10–80 | 190–255 |
| Scenario | Method | TP | FP | FN | Precision (%) | Recall (%) | Train Time (h) | Model Size (MB) | Image Label Size |
|---|---|---|---|---|---|---|---|---|---|
| Urban | Template | 1765 | 469 | 211 | 79.01 | 89.32 | 0.50 | 0.11 | 500 |
| HOG | 1676 | 284 | 300 | 85.51 | 84.82 | 0.51 | 0.15 | ||
| Proposed | 1854 | 147 | 122 | 92.65 | 93.83 | 0.53 | 0.16 | ||
| Highway | Template | 472 | 42 | 28 | 91.83 | 94.40 | 0.49 | 0.11 | 500 |
| HOG | 465 | 24 | 35 | 95.09 | 93.00 | 0.52 | 0.13 | ||
| Proposed | 482 | 28 | 18 | 94.51 | 96.40 | 0.52 | 0.14 |
| Model | mAP (%) | Precision (%) | Recall (%) | Param (M) | GFLOPs | FPS | Train Time (h) | Model Size (MB) | Image Label Size |
|---|---|---|---|---|---|---|---|---|---|
| YOLO v5 | 98.0 | 97.8 | 96.3 | 6.7 | 15.8 | 84.7 | 12.582 | 14.4 | 10,000 |
| YOLO v6 | 99.5 | 99.4 | 99.0 | 4.0 | 11.8 | 87.7 | 10.950 | 8.7 | |
| YOLO v7 | 99.8 | 99.0 | 99.0 | 5.7 | 13.1 | 89.3 | 21.829 | 12.3 | |
| YOLO v8 | 99.5 | 98.9 | 98.7 | 3.0 | 8.1 | 303.03 | 7.202 | 6.3 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, L.; Xu, W.; Shen, C.; Huang, Y. Vision-Based On-Road Nighttime Vehicle Detection and Tracking Using Improved HOG Features. Sensors 2024, 24, 1590. https://doi.org/10.3390/s24051590
Zhang L, Xu W, Shen C, Huang Y. Vision-Based On-Road Nighttime Vehicle Detection and Tracking Using Improved HOG Features. Sensors. 2024; 24(5):1590. https://doi.org/10.3390/s24051590
Chicago/Turabian StyleZhang, Li, Weiyue Xu, Cong Shen, and Yingping Huang. 2024. "Vision-Based On-Road Nighttime Vehicle Detection and Tracking Using Improved HOG Features" Sensors 24, no. 5: 1590. https://doi.org/10.3390/s24051590