1. Introduction
With the rapid development of Artificial Intelligence (AI) and Deep Learning (DL) technology, traffic sign detection, as a part of intelligent transportation, has become a popular research topic. In real-world scenes, traffic sign detection can assist drivers in accurately assessing information and reduce cases of neglect and misidentification caused by fatigue or inattention to avoid accidents. However, practical traffic sign detection can be affected by several factors, such as illumination, bad weather, and occlusion. Therefore, it is important to design a robust traffic sign detector with high detection accuracy.
For increased driver perceptibility, traffic signs usually have striking colors and special shapes. Traditional traffic sign detection focuses on feature extraction and classification. Color or shape features are extracted by different approaches for traffic sign recognition through a classifier. Benallal et al. [
1] performed traffic sign detection through color segmentation by comparing the differences between the RGB components. However, the RGB color space is highly sensitive to changes in the lighting environment, making it difficult to achieve stable results. Ruta et al. [
2] employed a normalization process to enhance the RGB color space, to better extract and detect the differences between the three colors (red, yellow, and blue). Nguwi et al. [
3] converted traffic sign images from the RGB to the HSI color space and segmented the images with a fixed threshold due to the insensitivity of the latter to illumination changes. Fleyeh et al. [
4] employed an AdaBoost binary classifier-based color segmentation approach. Yang et al. [
5] proposed a model based on a color probability map in the Ohta space. Loy et al. [
6] attempted to establish the possible center of mass location through the symmetry of the image and the edge information to detect traffic signs. However, this method does not apply to all shapes and has poor generalization. The Hough transform approach utilized by Zaklouta et al. [
7] to extract specific shape features achieved better detection results. Abukhait et al. [
8] utilized both traffic sign color and shape features and demonstrated a strong detection performance, even when the traffic sign shape was distorted or obscured by foreign objects. Although traditional methods for traffic sign detection demonstrated satisfactory performance at the time, they still face the following limitations: Firstly, traditional approaches often rely on manually designed features to represent traffic signs. This may overlook some complex textures, shapes, or background variations since manually designed features struggle to capture intricate linear relationships. Secondly, factors such as lighting conditions, different perspectives, and occlusion pose challenges to traditional traffic sign detection. Under these circumstances, traffic signs exhibit varying appearances, making it difficult for traditional methods to adapt to such changes. Thirdly, due to the diversity in the appearance of traffic signs and backgrounds, traditional methods struggle to generalize across different scenes and datasets, challenging their robustness in practical applications. Lastly, the computational complexity of traditional methods is relatively high, rendering them unsuitable for meeting real-time requirements.
Since the achievements of AlexNet [
9] in the field of visual recognition in 2012, an increasing number of DL methods have been proposed and applied to object detection, replacing the traditional algorithms. These DL-based object detection methods can be broadly categorized into two groups, namely Two-Stage and One-Stage algorithms. The first ever Two-Stage object detection algorithm with industrial-grade accuracy, Regions with CNN features (R-CNN), was introduced by Girshick et al. [
10]. A selective search approach was utilized by R-CNN to extract 2000 candidate regions, which were subsequently predicted individually. However, despite its breakthrough accuracy, R-CNN is plagued by significant speed limitations due to the generation of candidate regions and extensively repetitive computations. The efficiency of R-CNN has been optimized by Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition (SPP-Net) [
11], which extracts features from the entire feature map and uses a spatial pyramid pooling layer to handle features of arbitrary sizes. The SPP-Net training process remains complex, although it has been improved compared with R-CNN. Fast R-CNN [
12] unifies the classification and regression problems with a deep network implementation, eliminating the need for additional storage and dramatically improving the training speed. Faster R-CNN [
13] became the first object detector with near real-time performance, integrating the four main steps, i.e., feature extraction, candidate region generation, regression of predicted edge position parameters, and object category determination, into the Region Proposal Network (RPN). Libra R-CNN [
14] solves the imbalance problem during training with high accuracy improvement by introducing Intersection over Union (IoU) balanced sampling, balanced pyramid, and balanced Mean Absolute Error (L1 loss). Despite the significant enhancements in detection performance brought about by these Two-Stage algorithms, their speed still does not meet the demands of real-time object detection. This issue is tackled by the introduction of One-Stage object detection algorithms. You Only Look Once (YOLO) [
15] transforms object detection into a regression problem and adopts CNNs to complete the prediction of bounding boxes and category determination, truly ushering in the era of real-time object detection. A detection accuracy on par with Faster R-CNN is achieved by Single Shot MultiBox Detector (SSD) [
16], while maintaining the detection speed through the prediction of multi-scale features and the introduction of an anchor mechanism. In YOLOv2 [
17], batch normalization is incorporated into the network to expedite model convergence, and the K-Means algorithm is utilized to determine the size and position of prior frames, resulting in better-matching detection frames for real objects. Darknet-53 is employed as the YOLOv3 [
18] backbone, and the concept of Feature Pyramid Network (FPN) [
19] is introduced for feature fusion at different scales, further enhancing detection performance. YOLOv4 [
20] employs a new backbone, CSPDarknet53, by combining the Cross Stage Partial Network (CSPNet) [
21] with Darknet-53. This model additionally incorporates Spatial Pyramid Pooling (SPP) and Path Aggregation Network (PANet) [
22] to expand the receptive field of features and improve feature fusion. In YOLOv5 [
23], the feature fusion capabilities are enhanced by incorporating the CSP structure into the fusion network. Simultaneously, the Focus structure is added to the backbone network to perform slicing operations on feature maps, reducing algorithm computation and accelerating processing speed. Gui et al. [
24] achieved a more lightweight model in YOLOv5 by introducing lightweight convolutional operations. Simultaneously, the incorporation of the bottleneck attention module was employed to extract effective information, thereby enhancing the accuracy of the model. Recently, breakthroughs have been achieved in the field of computer vision with models based on Transformer [
25] architecture. The Vision Transformer (ViT) [
26] applies the Transformer architecture to sequences of image patches, further advancing image classification tasks. ViT-FRCNN [
27] integrates ViT with RPN to accomplish object detection tasks based on the transformer backbone. Xie et al. [
28] proposed a novel integrated network, ViT-MVT, designed for joint optimization of image classification tasks and other downstream tasks, such as object detection and semantic segmentation. ViT-MVT demonstrates exceptional performance across multiple visual tasks, surpassing existing methods while requiring considerably less total storage. Wang et al. [
29] proposed an MDL-NAS framework based on ViT, achieving high performance across various vision tasks and maintaining storage efficiency for model deployment through a coarse-to-fine searching space design and a joint-subnet search algorithm.
As a sub-type of object detection, traffic sign detection can benefit from the application of DL-based algorithms. However, this task has higher requirements for detection accuracy and speed. As a result, various studies have attempted to improve these algorithms in order to achieve improved traffic sign detection. Gavrilescu et al. [
30] revealed that compared with Fast R-CNN, Faster R-CNN exhibited superior real-time traffic sign detection performance. Based on Faster R-CNN, Yang et al. [
31] proposed a method utilizing an attention network to replace the RPN, improving the accuracy for both the TT100k [
32] and BTSD [
33] datasets. Additionally, Zhang et al. [
34] introduced a cascaded R-CNN [
35] approach to acquire multi-scale features from the pyramid and weighted them through dot products and softmax operations, thereby emphasizing traffic sign features and enhancing detection accuracy. The aforementioned algorithms are all formulated based on the Two-Stage object detection approach, and despite the significant improvement in accuracy, meeting real-time requirements is challenging due to the slower speed inherent in Two-Stage object detection. Mohd-Isa et al. [
36] incorporated SPP into the YOLOv3 framework, enabling traffic sign recognition for real-world images of varying sizes through multi-scale pooling. This modification results in improved detection accuracy along with increased detection speed. Wang et al. [
37] developed a lightweight YOLOv4 algorithm by replacing the backbone with a lightweight architecture, MobileNetv2 [
38], and attention mechanisms were also employed to enhance the model’s detection capabilities. In summary, DL-based traffic sign detection algorithms are characterized by increased robustness and higher detection accuracy compared with traditional methods. Simultaneously, One-Stage algorithms offer advantages in real-time processing, better aligning with the requirements of traffic sign detection.
Despite the better traffic sign detection results and faster speeds offered by the YOLO-series-based One-Stage algorithms, the problem of the high leakage rates of small objects persists. Detecting small objects has always been a challenging task in object detection. Firstly, small objects typically exhibit low-resolution with limited visual information, making the extraction of effective features more challenging. Secondly, detection methods based on neural networks typically extract deep-level features with rich semantic information for object detection. The dimensions of these features progressively diminish, causing the network to gradually lose spatial resolution and detailed information during the forward propagation process, thereby affecting the detection of small objects. In recent years, several methods have been proposed to achieve breakthroughs in the field of small object detection. Liang et al. [
39] introduced FS-SSD as a method for small object detection in UAV images. However, the algorithm introduces hyperparameters that are not conducive to optimization. Liu et al. [
40] employed contextual information, encompassing object and scene features, as well as relationships between coexisting objects, to enhance the performance of small object detection. The approach relying on context fusion enhances the accuracy of object detection to a certain extent. However, identifying contextual information from a global scene that is beneficial for enhancing small object detection remains a challenging research problem. Li et al. [
41] employed generative adversarial learning by mapping the features of small low-resolution objects into features equivalent to those of high-resolution objects to attain the same detection performance as that of larger-size objects. Nevertheless, training generative adversarial networks poses challenges, and achieving a well-balanced relationship between generators and discriminators is not easily realized. Zhu et al. [
42] utilized Transformer Prediction Heads (TPH) to globally model the feature maps. While it enhances the detection capabilities for small objects, the complex structure of the Transformer also introduces a certain degree of redundancy to the model. In addition to the problem of small object detection, the number of feature channels can be directly reduced by the feature map extraction process using a 1 × 1 convolution, potentially leading to the loss of feature channel information. At the same time, the detection accuracy can be affected by insufficient feature fusion. Therefore, a traffic sign detection model, YOLOv7-Traffic Sign (YOLOv7-TS), based on sub-pixel convolution [
43] and feature fusion is proposed in this study. Firstly, the up-sampling capability of sub-pixel convolution is utilized to integrate the channel dimension pixels and preserve channel information, thus extracting feature maps with richer features. Additionally, a small object detection layer is introduced to the feature fusion network, and the integration map is employed to enhance information interaction among all feature layers, which reduces the rate of small object omissions and improves the effectiveness of feature fusion. Furthermore, the highest-layer feature enhancement is accomplished by the addition of global average pooling and global max pooling, which provide the highest-layer feature with global information and significant information. Feature fusion is then employed to impart the benefits of the highest-layer feature to every other layer, ultimately enhancing the detection accuracy of the model. The major contributions of this study can be summarized as follows:
A Feature Map Extraction Module (FMEM) is devised to mitigate channel information loss during feature map extraction by employing sub-pixel convolution.
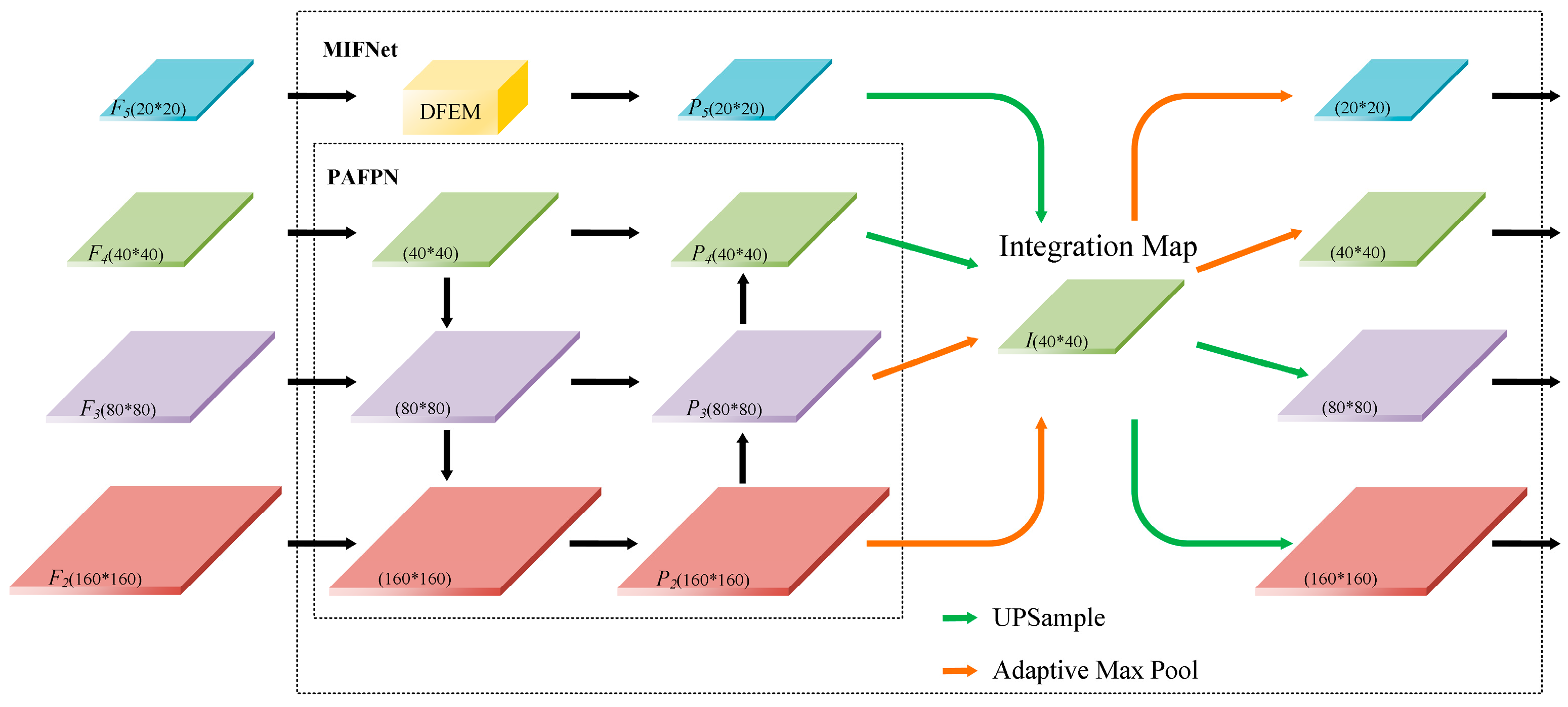
A Multi-feature Interactive Fusion Network (MIFNet) is developed to leverage the rich details of the small object detection layer and employ the integration map to enhance the interaction of information across all feature layers. The perceivability for small traffic sign objects is enhanced, and the effect of feature fusion is improved while reducing the model parameters.
A Deep Feature Enhanced Module (DFEM) is established, in which the highest feature is enriched by integrating global average pooling and global max pooling within the Spatial Pyramid Pooling Cross-Stage Partial Channel (SPPCSPC). Simultaneously, pooling is accelerated without altering the size of the original receptive field, thereby speeding up the inference of DFEM.
To validate the effectiveness of YOLOv7-TS, a substantial number of experiments are conducted on the CCTSDB2021 [
44] and TT100K traffic sign datasets. These experiments demonstrate the commendable detection performance of YOLOv7-TS.
5. Conclusions
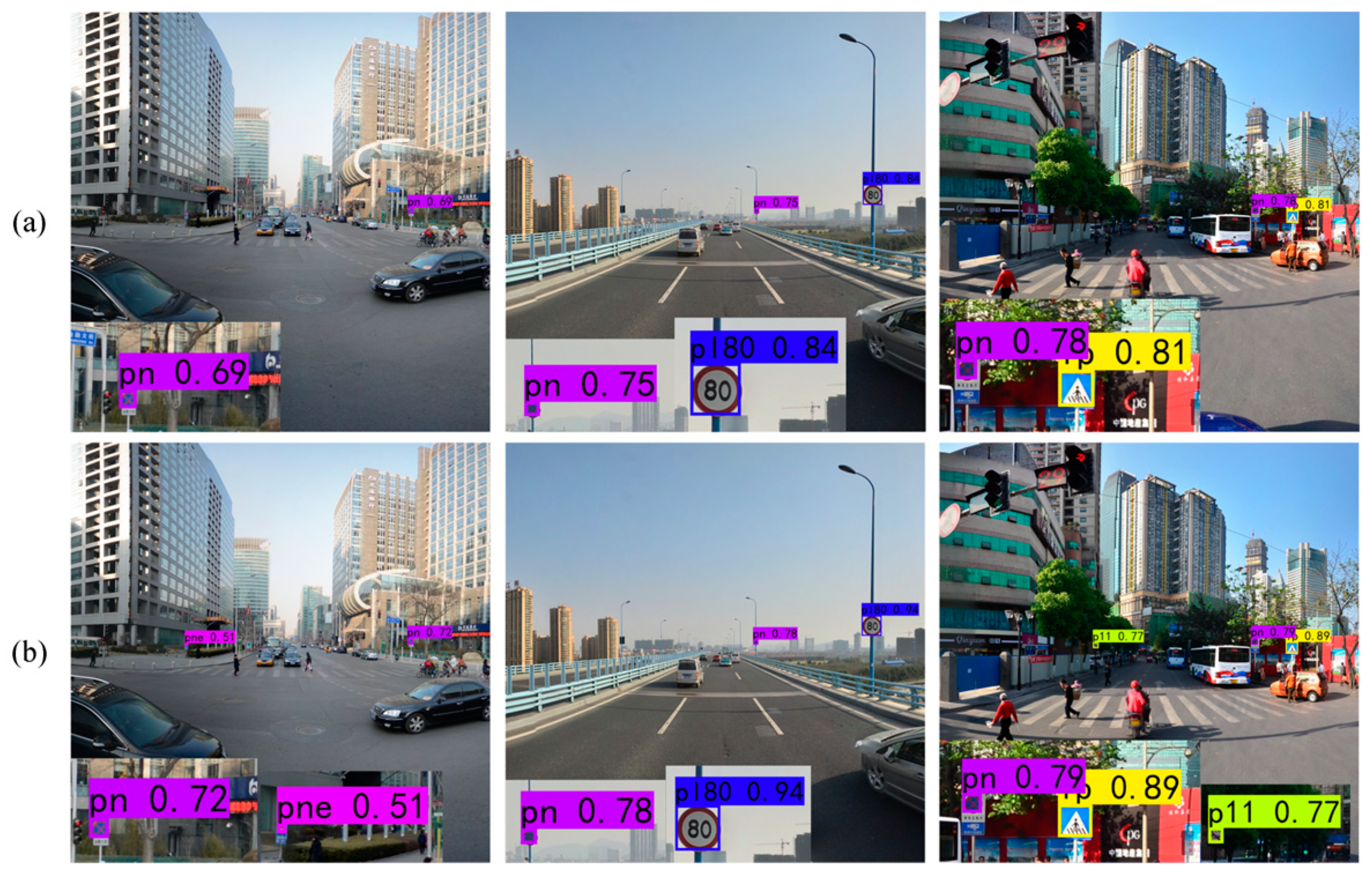
In this study, we propose a traffic sign detection model named YOLOv7-TS, building upon YOLOv7 as its foundation. Firstly, the issue of feature channel information loss caused by the 1 × 1 convolution for feature map extraction is addressed through the introduction of FMEM. The feature maps extracted through FMEM simultaneously encompass high-level semantic information and low-level detailed information, actively promoting both object recognition and localization. Secondly, MIFNet is designed to enhance the feature fusion by promoting information interaction among all feature layers. Simultaneously, the rich detail information in the high-resolution feature map is combined to locate small objects and alleviate the problem of missing detection of small objects. Thirdly, DFEM enriches the highest-layer feature and improves the inference speed of the whole module. The highest-level feature containing global information and crucial information improves the detection accuracy of the model through feature fusion. In summary, YOLOv7-TS leverages the rich channel semantic information and spatial detail information in multi-scale features. Through feature enhancement and a more effective feature fusion network, the entire model benefits from these aspects. The analysis in the experimental section shows that YOLOv7-TS achieves higher F1 scores and mAP values compared with YOLOv7 and other common models. This fully demonstrates the excellent performance and highest detection accuracy of the model in traffic sign detection. The comparison of the results and heatmaps between YOLOv7-TS and YOLOv7 indicates that YOLOv7-TS alleviates the shortcomings of YOLOv7 in small object detection, showing a stronger ability to perceive small objects. However, in terms of FPS, our model lags behind YOLOv7 and YOLOv5s. This is attributed to the more complex architecture of YOLOv7-TS, requiring larger computational resources, resulting in a relatively slower inference speed. Our future work will focus on optimizing the model architecture, exploring the use of lightweight backbone networks and lightweight convolutions, while refining module details to reduce computational overhead and improve model speed.
This study was conducted based on traffic sign datasets. There are still many potential challenges and factors that should be considered when applying the model to real-world scenarios for traffic sign detection: Firstly, real-world environments exhibit diverse conditions. Changes in lighting due to different times of day and weather conditions may lead to variations in the appearance of traffic signs. Adverse weather, such as rain, snow, or haze, can blur or partially obstruct signs, making them more challenging to detect. Seasonal changes may alter road and environmental conditions, impacting sign visibility. Different road situations, such as wet, slippery, uneven, or dirty roads, may affect the clarity of traffic signs. Secondly, specific regions in the dataset may have distinct geographical and cultural characteristics compared with the target deployment area, posing challenges in detection due to regional variations. Thirdly, dynamic context adaptation is essential. Real-world scenarios often encompass dynamic contexts, such as urban versus rural environments or highways versus local roads. The model should dynamically adjust based on specific circumstances, considering factors such as traffic density, speed limits, and road infrastructure. Addressing these potential challenges requires the model to have higher robustness and stronger generalization capabilities when detecting in real-world scenarios. Several strategies can be employed: Firstly, data augmentation is crucial. Utilizing diverse data augmentation techniques, including random rotation, flipping, scaling, and brightness adjustments, helps simulate the diversity present in real-world scenarios. This aids in enhancing the model’s robustness to different environments and backgrounds. Secondly, training with multi-source data is essential. Integrating data from various regions and diverse scenarios ensures that the model encounters a broader range of contexts during the training phase. This contributes to improving the model’s generalization performance in different geographical and cultural environments. Thirdly, transfer learning is a valuable approach. Employing transfer learning methods allows the model to transfer knowledge learned in one region or scenario to another. This accelerates the adaptation process of the model to new environments. Fourth, it is beneficial to include an environment awareness module and real-time feedback. An environment awareness module is introduced into the model to capture and deal with environmental changes and adjust the detection strategy. The real-time feedback mechanism continuously monitors the performance of the model in real-world scenarios, enabling online adjustment based on actual feedback. Beyond adapting to diverse environments and backgrounds, deploying the model in real-world scenarios necessitates considerations of integration with existing systems, ethical concerns, and adherence to legal regulations. Seamless integration ensures effective deployment and collaboration with other components of traffic infrastructure. As artificial intelligence applications become more prevalent in real-world settings, compliance with ethical standards and legal regulations becomes paramount. Ensuring the model’s privacy compliance in public spaces is essential. In our future research, we will focus on addressing the potential challenges associated with deploying the model in real-world scenarios, continually enhancing the model’s robustness and generalization to deliver outstanding performance in various environments and contexts.


























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}