

J-Net: Improved U-Net for Terahertz Image Super-Resolution
 ,
,  and
and
Abstract
:1. Introduction
2. Proposed Method
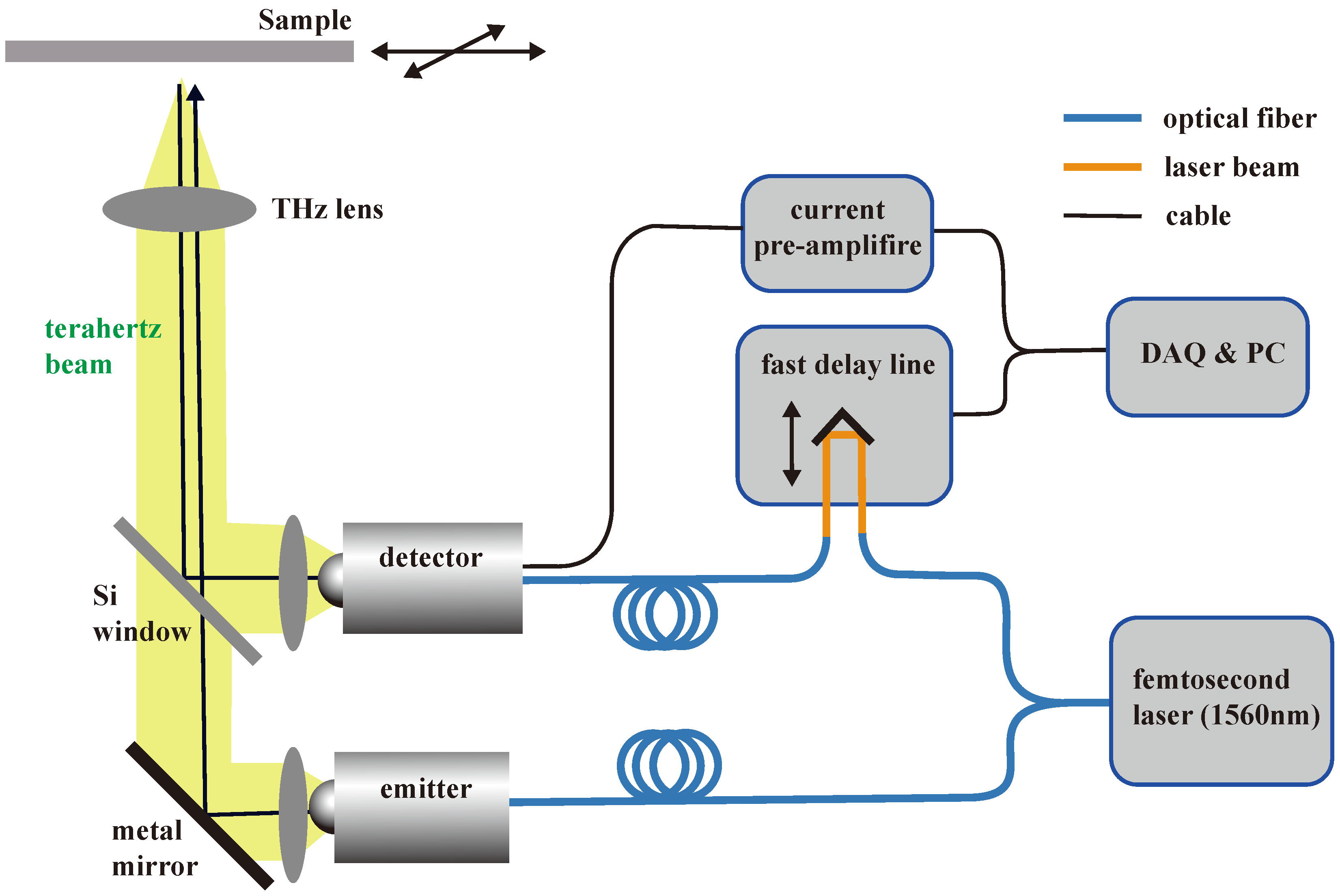
2.1. Terahertz Imaging System
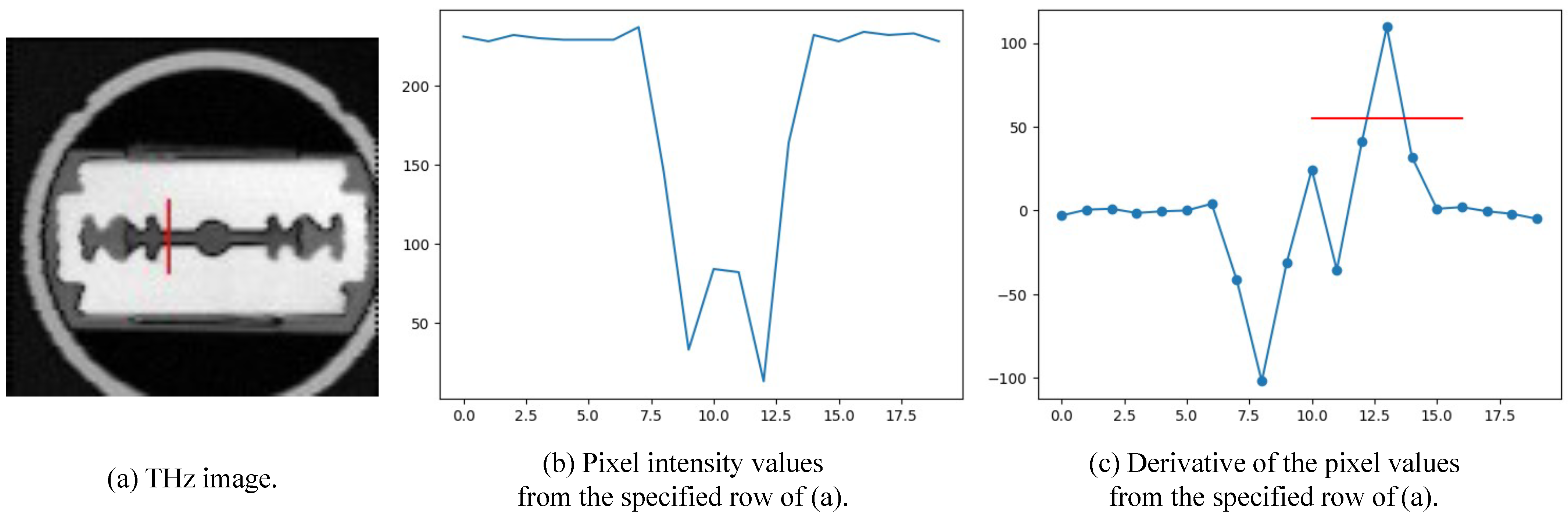
2.2. Degradation Model
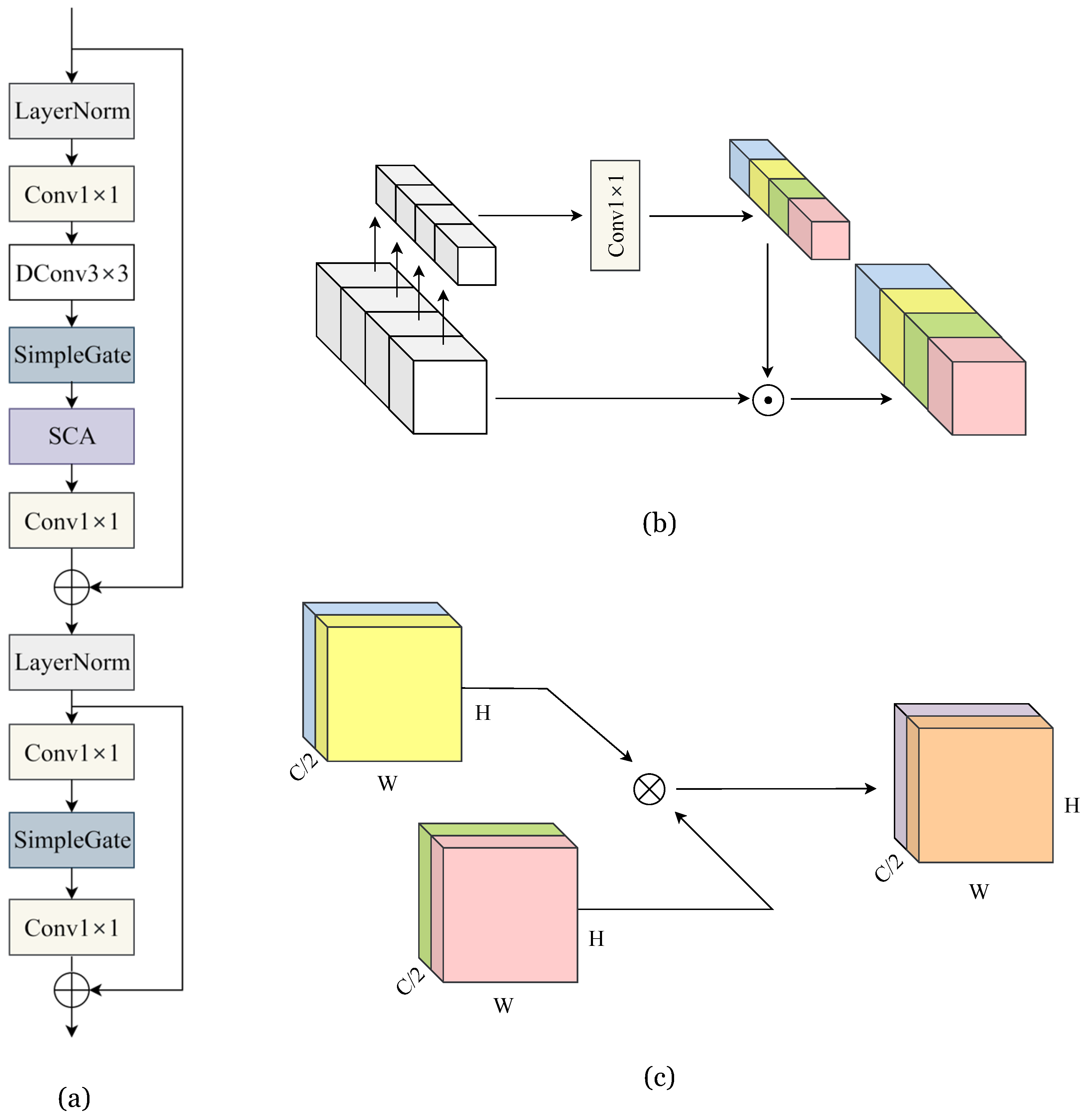
2.3. Network Architecture
- Contraction path: This section captures contextual information from the image, utilizing convolutional layers followed by max pooling. This process reduces the image’s spatial dimensions, enabling the network to extract essential features, which is crucial for restoring degraded parts of an image.
- Expansive path: In this part, the network upscales the feature maps to reconstruct the image at its original resolution. The use of transposed convolutions or up-convolution layers is common here. This path also involves the concatenation of feature maps from the contraction path, allowing the network to utilize both high-level and detailed information, which is critical for accurately restoring image details.
- Skip connections: A standout feature of U-Net is its use of skip connections. These connections help transfer detailed information by linking feature maps from the contraction path directly to the expansive path. This feature is particularly beneficial in image restoration as it allows for the preservation and incorporation of fine details in the restored image.
2.4. Building Block
3. Experimental Results
3.1. Datasets
3.2. Implementation Details
3.3. Results and Discussion
3.3.1. U-Net vs. J-Net
3.3.2. Variation of Degradation Parameter
3.3.3. Model Comparison
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| THz | Terahertz |
| PSNR | Peak signal-to-noise ratio |
References
- Li, Y.; Hu, W.; Zhang, X.; Xu, Z.; Ni, J.; Ligthart, L.P. Adaptive terahertz image super-resolution with adjustable convolutional neural network. Opt. Express 2020, 28, 22200–22217. [Google Scholar] [CrossRef] [PubMed]
- Guo, Y.; Ling, F.; Li, H.; Zhou, S.; Ji, J.; Yao, J. Super-resolution reconstruction for terahertz imaging based on sub-pixel gradient field transform. Appl. Opt. 2019, 58, 6244–6250. [Google Scholar] [CrossRef] [PubMed]
- Yang, X.; Zhang, D.; Wang, Z.; Zhang, Y.; Wu, J.; Wu, B.; Wu, X. Super-resolution reconstruction of terahertz images based on a deep-learning network with a residual channel attention mechanism. Appl. Opt. 2022, 61, 3363–3370. [Google Scholar] [CrossRef] [PubMed]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Learning a deep convolutional network for image super-resolution. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Proceedings, Part IV 13. Springer: Berlin/Heidelberg, Germany, 2014; pp. 184–199. [Google Scholar]
- Kim, J.; Lee, J.K.; Lee, K.M. Accurate image super-resolution using very deep convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1646–1654. [Google Scholar]
- Shi, W.; Caballero, J.; Huszár, F.; Totz, J.; Aitken, A.P.; Bishop, R.; Rueckert, D.; Wang, Z. Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1874–1883. [Google Scholar]
- Long, Z.; Wang, T.; You, C.; Yang, Z.; Wang, K.; Liu, J. Terahertz image super-resolution based on a deep convolutional neural network. Appl. Opt. 2019, 58, 2731. [Google Scholar] [CrossRef] [PubMed]
- Ruan, H.; Tan, Z.; Chen, L.; Wan, W.; Cao, J. Efficient sub-pixel convolutional neural network for terahertz image super-resolution. Opt. Lett. 2022, 47, 3115. [Google Scholar] [CrossRef] [PubMed]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; Proceedings, Part III 18. Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Chen, L.; Chu, X.; Zhang, X.; Sun, J. Simple baselines for image restoration. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 17–33. [Google Scholar]
- Wang, Z.; Cun, X.; Bao, J.; Zhou, W.; Liu, J.; Li, H. Uformer: A general u-shaped transformer for image restoration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 17683–17693. [Google Scholar]
- Zamir, S.W.; Arora, A.; Khan, S.; Hayat, M.; Khan, F.S.; Yang, M.H. Restormer: Efficient transformer for high-resolution image restoration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 5728–5739. [Google Scholar]
- Chu, X.; Chen, L.; Chen, C.; Lu, X. Improving image restoration by revisiting global information aggregation. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 53–71. [Google Scholar]
- Mao, X.; Liu, Y.; Shen, W.; Li, Q.; Wang, Y. Deep residual fourier transformation for single image deblurring. arXiv 2021, arXiv:2111.11745. [Google Scholar]
- Van Exter, M.; Grischkowsky, D.R. Characterization of an optoelectronic terahertz beam system. IEEE Trans. Microw. Theory Tech. 1990, 38, 1684–1691. [Google Scholar] [CrossRef]
- Jepsen, P.U.; Jacobsen, R.H.; Keiding, S. Generation and detection of terahertz pulses from biased semiconductor antennas. JOSA B 1996, 13, 2424–2436. [Google Scholar] [CrossRef]
- Ba, J.L.; Kiros, J.R.; Hinton, G.E. Layer normalization. arXiv 2016, arXiv:1607.06450. [Google Scholar]
- Hendrycks, D.; Gimpel, K. Gaussian error linear units (gelus). arXiv 2016, arXiv:1606.08415. [Google Scholar]
- Agustsson, E.; Timofte, R. Ntire 2017 challenge on single image super-resolution: Dataset and study. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 126–135. [Google Scholar]
- Lim, B.; Son, S.; Kim, H.; Nah, S.; Mu Lee, K. Enhanced deep residual networks for single image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 136–144. [Google Scholar]
- Loshchilov, I.; Hutter, F. Sgdr: Stochastic gradient descent with warm restarts. arXiv 2016, arXiv:1608.03983. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Advances in Neural Information Processing Systems 32; Curran Associates, Inc.: San Francisco, CA, USA, 2019; pp. 8024–8035. Available online: http://papers.neurips.cc/paper/9015-pytorch-animperative-style-high-performance-deep-learning-library.pdf (accessed on 11 December 2023).
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Zamir, S.W.; Arora, A.; Khan, S.; Hayat, M.; Khan, F.S.; Yang, M.H.; Shao, L. Multi-stage progressive image restoration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 14821–14831. [Google Scholar]
- Zamir, S.W.; Arora, A.; Khan, S.; Hayat, M.; Khan, F.S.; Yang, M.H.; Shao, L. Learning enriched features for real image restoration and enhancement. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XXV 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 492–511. [Google Scholar]
- Zhang, K.; Li, Y.; Zuo, W.; Zhang, L.; Van Gool, L.; Timofte, R. Plug-and-play image restoration with deep denoiser prior. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 6360–6376. [Google Scholar] [CrossRef] [PubMed]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Flat U-Net | U-Net | J-Net | |
|---|---|---|---|
| PSNR | 30.17 | 31.38 | 31.53 |
| PSNR | ||
|---|---|---|
| 0 | 1 | 34.96 |
| 0 | 3 | 34.41 |
| 0 | 5 | 33.13 |
| 0 | 10 | 30.09 |
| 0.1 | 1 | 35.44 |
| 0.1 | 3 | 35.32 |
| 1 | 2 | 35.08 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yeo, W.-H.; Jung, S.-H.; Oh, S.J.; Maeng, I.; Lee, E.S.; Ryu, H.-C. J-Net: Improved U-Net for Terahertz Image Super-Resolution. Sensors 2024, 24, 932. https://doi.org/10.3390/s24030932
Yeo W-H, Jung S-H, Oh SJ, Maeng I, Lee ES, Ryu H-C. J-Net: Improved U-Net for Terahertz Image Super-Resolution. Sensors. 2024; 24(3):932. https://doi.org/10.3390/s24030932
Chicago/Turabian StyleYeo, Woon-Ha, Seung-Hwan Jung, Seung Jae Oh, Inhee Maeng, Eui Su Lee, and Han-Cheol Ryu. 2024. "J-Net: Improved U-Net for Terahertz Image Super-Resolution" Sensors 24, no. 3: 932. https://doi.org/10.3390/s24030932