1. Introduction
Mechanical rotating components play a pivotal role in various domains of modern industry, encompassing engines, motors, turbines, and more [
1,
2,
3]. Among these components, bearings, serving as the essential supporting elements of mechanical rotating parts, bear the crucial functions of load transmission and friction mitigation. However, when operating for extended periods under complex conditions, mechanical rotating components often experience an array of failures, such as bearing Rolling element wear, loose cages, and inner Ring fracture, among other issues [
4,
5]. These failures not only lead to interruptions in industrial production, but also pose the risk of severe consequences, including equipment damage, accidents, and even personnel injuries. Therefore, accurate and timely monitoring and diagnosis are critical in ensuring equipment reliability and maintaining production efficiency [
6].
In real industrial production, machines operate in a healthy state for the majority of their operational time, and the probabilities of failures in rotating mechanical components vary. Moreover, it is crucial to note that the diagnostic learning direction of deep learning (DL) models tends to shift towards categories with abundant Samples; thus, neglecting the minority Classes that it cannot adequately grasp, this phenomenon results in model overfitting [
7], ultimately impacting the diagnostic efficiency of model Classification and increasing equipment maintenance costs. Hence, the exploration of fault diagnosis in the context of rotating mechanical components, while dealing with the constraints of small and imbalanced data, carries profound practical significance [
8,
9].
The primary objective of feature-based methods is to enhance the model’s ability to extract features, particularly the capacity to extract critical information from limited Samples. The introduction of attention mechanisms has alleviated this issue to some extent [
10,
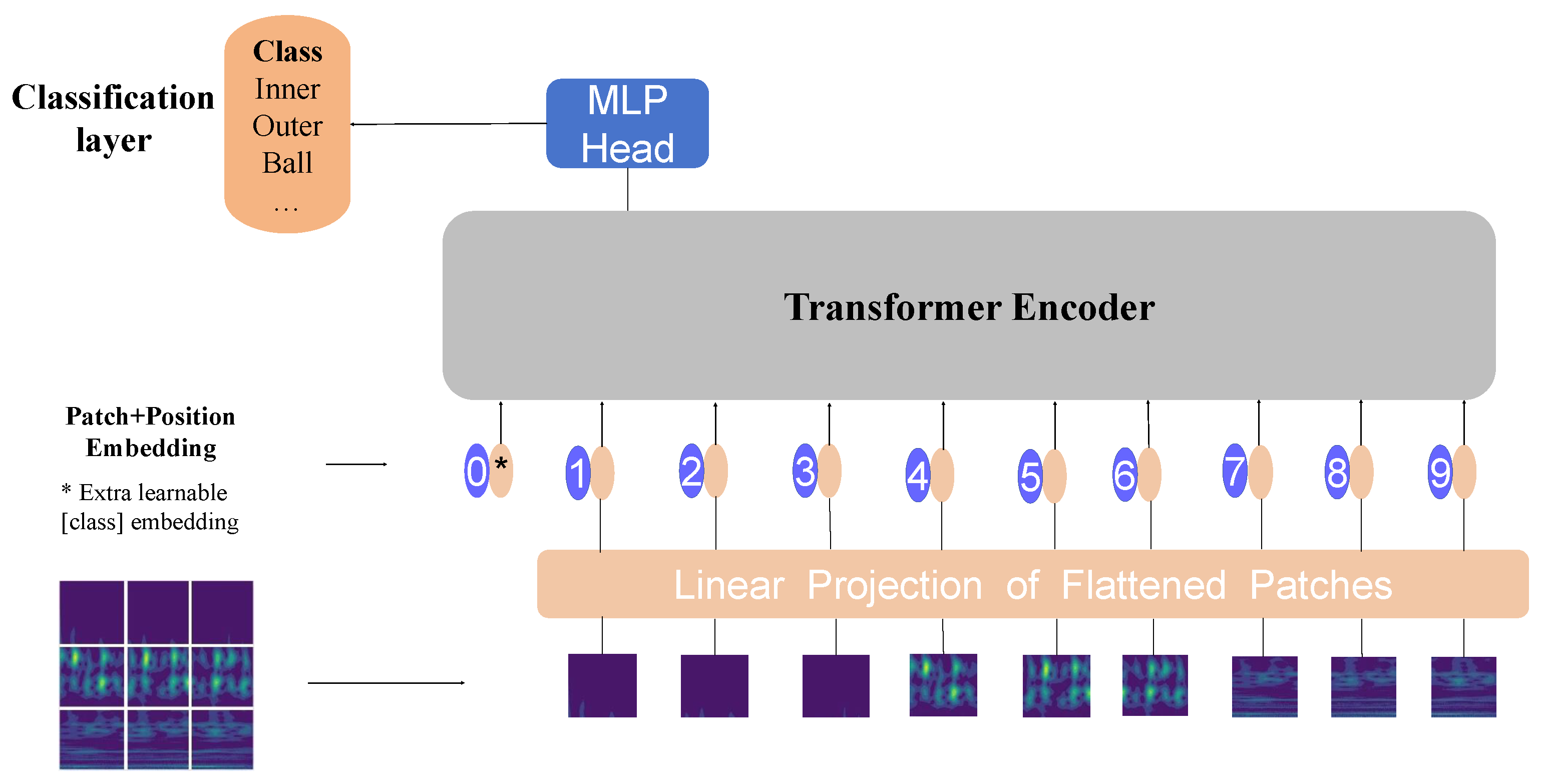
11], but existing attention-based methods may lack modeling of internal relationships within signal sequences. The Vision Transformer (ViT) architecture [
12], which has robust Global feature extraction capabilities by modeling internal data information, has gained favor among many researchers. ViT models can be categorized into pure attention-based ViT models and convolutional ViT models, depending on whether convolutional operations are incorporated into the ViT architecture. In the former category, ViT mainly relies on the self-attention mechanism, enabling the model to establish long-distance dependencies between different locations, which helps to recognize complex patterns and correlations and, thus, diagnose faults more accurately [
13]. In addition, some researchers have used ViT to achieve long-distance-dependent modeling of signals in complex environments in real industrial production. Zhou et al. [
14] proposed an Industrial Process Optimization ViT (IPO-ViT) method, which significantly enhances the robustness of the model by exploring the Global receptive field. Exclusively attention-driven ViT models, as mentioned above, often lack further precise analysis of local features in vibration signals, leading to essential features being submerged in redundant information.
In modeling local features and filtering out redundant information from the signal, filters play a pivotal role in this process. Convolutional Neural Networks (CNNs) excel at capturing the local details of an image, while ViT excels at understanding the Global context of an image. This multimodal fusion model provides a more-comprehensive understanding of the image content, which improves the Accuracy of recognition and Classification. Therefore, attention mechanisms must be combined with CNNs to address their limitations in computer vision [
15,
16]. Moreover, the incorporation of the Wavelet transform into the Transformer framework has been undertaken to attenuate persistent noise from the signal. Tian et al. [
17] introduced a Wavelet-based self-attention Network, which utilizes self-attention mechanisms through multiple frequency-oriented fusion modules to extract signal features hidden in interference information. Furthermore, considering the complexity of equipment operating environments, mixed-load complex data are more aligned with modern industrial production settings. The Deep Residual Shrinkage Network (DRSN) has been proven to have the ability to model features in complex data in the field of fault diagnosis. Pei et al. [
18] proposed an improved Deep Residual Shrinkage Network that can judge whether bearing performance is deteriorating based on the ratio of the fault features to the noise capability. Some scholars have combined the DRSN and Transformer to improve the fault-detection performance of target machines. Chen et al. [
19] introduced a new Transformer-based Deep Residual Shrinkage Network, which eliminates potential interference features in the input signal through the DRSN and, then, feeds them into an enhanced Transformer model to determine their category through Sample comparison.
Classifier-based strategies, aimed at improving model recognition rates, involve the use of Loss functions to assign different weights to Classes, thereby ensuring the efficient extraction of relevant information from Samples across various categories. However, in the case of imbalanced Datasets, it is discriminative features, and it is indeed challenging to capture highly discriminative features, particularly for fault categories with scarce representation. In such scenarios, the characteristics of certain fault types may overlap significantly with others, complicating the model’s ability to discern distinct patterns. These ambiguous Samples, which we term “difficult Samples”, pose a substantial challenge to the effectiveness of the Classification model. Therefore, a series of cost functions have been proposed, such as the Label-Distribution-Aware Margin Loss (LDAML) [
20], Class-Balanced Loss (CB) [
21], Focal Loss (FL) [
22], etc., In the field of fault diagnosis, Zhao et al. [
23] introduced a novel approach that combines Focal Loss with random oversampling to address Class imbalance in deep Neural Networks. Xiao et al. [
24] combined cost learning with a symmetric regularization criterion and proposed a Selective Deep Ensemble model based on the Group Method of Data Handling (GMDH) technology for cost-sensitive selective Deep Ensemble prediction. These functions often exhibit sensitivity to the proportions of different Classes, overlooking the presence of difficult Samples within Classes. Moreover, in the face of severe imbalance with extremely limited small Samples, the features of Intraclass difficult Samples cannot be fully exploited, further restraining the superiority of cost-sensitive cost functions.
In summary, the limitations of the above methods in addressing the challenges of small and imbalanced cases can be attributed to two main reasons: Regarding the issue of small Samples, while attention mechanisms can help Networks focus on essential parts of the input signals, they tend to overlook the complex associations and dependencies between different elements within the signals. This limitation makes it challenging to learn the dependency relationships of Global features in the signals, resulting in some attention being erroneously directed toward local redundant features. Concerning the problem of Class imbalance, the currently proposed Class imbalanced cost functions often prioritize the quantity proportions of different Class Samples. However, they tend to overlook the persistence of Intraclass difficult Samples, particularly when dealing with severely imbalanced Datasets. This oversight can lead to model overfitting.
To address the first issue, we introduce a Neural Network module designed to selectively eliminate redundant signal data in an adaptive manner. This module, referred to as the Dual-Stream Adaptive Deep Residual Shrinkage Block (DSA-DRSB), is proposed. Specifically, to mitigate the suboptimal performance of one-dimensional data in the CNN [
25], the raw vibration signals are transformed into two-dimensional time–frequency maps using the Continuous Wavelet Transform (CWT) to capture fine temporal resolution and frequency changes. Furthermore, to tackle the challenges posed by small Sample Datasets, the DSA-DRSB is introduced. More specifically, we improved and merged two different Deep Residual Shrinkage Blocks. One Branch, with a threshold fusion mechanism, excels at eliminating redundant information within the data, while the other Branch outperforms in extracting detailed fault features. The extracted features from both Branches are then fused, enabling the Network to dynamically adjust its output based on the adaptive input data under conditions of extremely limited Samples.
Addressing the second issue, which involves the challenge of adapting to severely imbalanced Datasets, a novel Loss function is introduced, referred to as Interclass–Intraclass Rebalancing Loss (IIRL). While existing imbalance-Aware Loss functions have been extensively researched, they primarily focus on adjusting the contributions between different Classes and do not fully exploit the crucial features of individual difficult Samples within Classes. IIRL introduces online Hard Sample mining techniques within CB Loss. Specifically, for challenging Samples, the top n most-difficult Samples are selected for in-depth mining of potential fault information. Ultimately, during model training, IIRL decouples the contributions of Interclass and Intraclass Samples, thereby enabling the deep exploration of Sample-specific fault features. The primary contributions of this work are as follows:
- 1.
A method is proposed for small and imbalanced intelligent fault diagnosis, namely DSADRSViT-IIRL. This method exhibits high diagnostic Accuracy and strong robustness in scenarios with extremely limited Samples and severe Class imbalance cases, whose application prospect is promising.
- 2.
A new DSA-DRSB Branch with threshold fusion is designed. The pathway with threshold fusion adeptly captures locally key-sensitive feature vectors, which have a significant impact on the outcome, while skillfully modeling Global features. In parallel, the other pathway employs a shared-threshold strategy to alleviate the impact of redundant information, enabling the model to capture critical fault discrimination features from exceedingly limited Samples.
- 3.
A novel Loss function, IIRL, is proposed to address Class imbalance issues. This is achieved by introducing online Hard Sample mining techniques into the Class imbalanced cost function, aiming to tackle the persistence of difficult Samples within the same category. It allows for a thorough exploration of challenging Intraclass Samples, to decouple the contributions of Interclass and Intraclass Samples during model training. This is especially crucial in scenarios characterized by seriously imbalanced and extremely limited Sample sizes.
- 4.
The experimental results on the CWRU bearing Dataset and the Laboratory bearing Datasets, conducted under complex operating conditions, demonstrate that the model exhibits good generalization abilities compared to the most-recent relevant algorithms.
The remainder of the paper is organized as follows:
Section 2 briefly introduces the fundamental theory of fault diagnosis models. The DSADRSViT-IIRL, DSA-DRSB, and IIRL are detailed in
Section 3.
Section 4 validates the effectiveness of the proposed method using the CWRU and Laboratory bearing Datasets. Finally, conclusions are drawn in
Section 5.
5. Conclusions
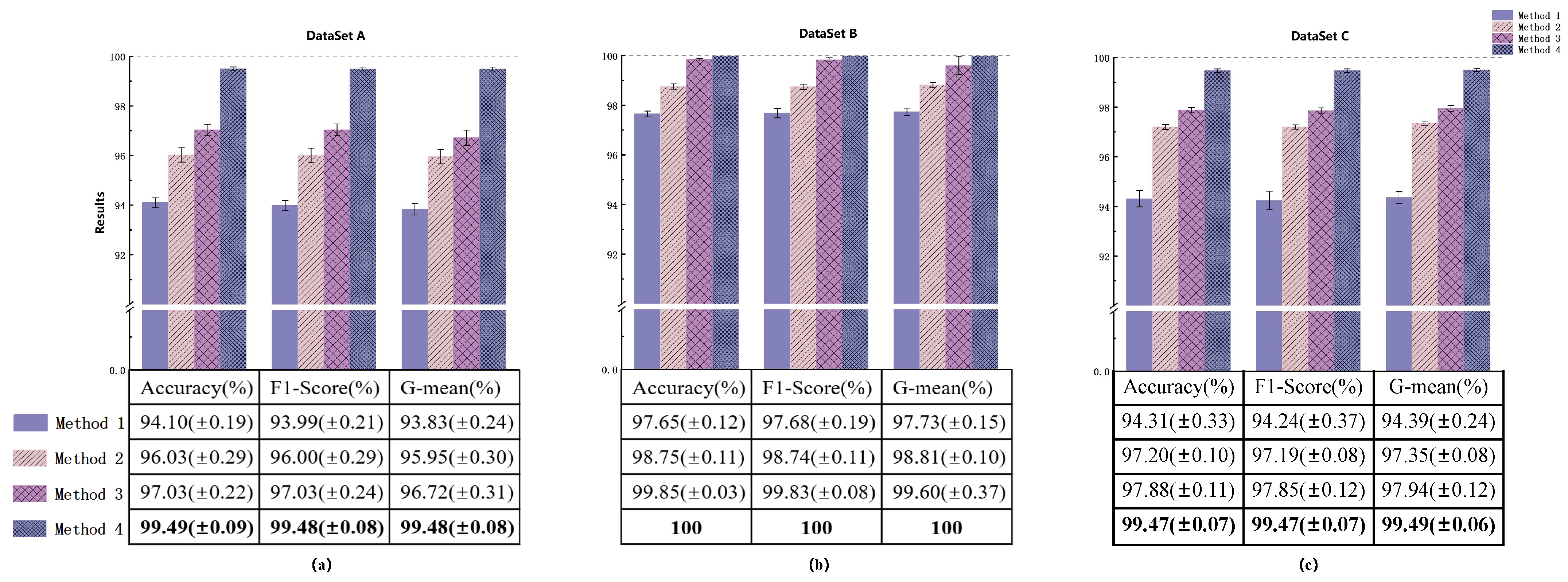
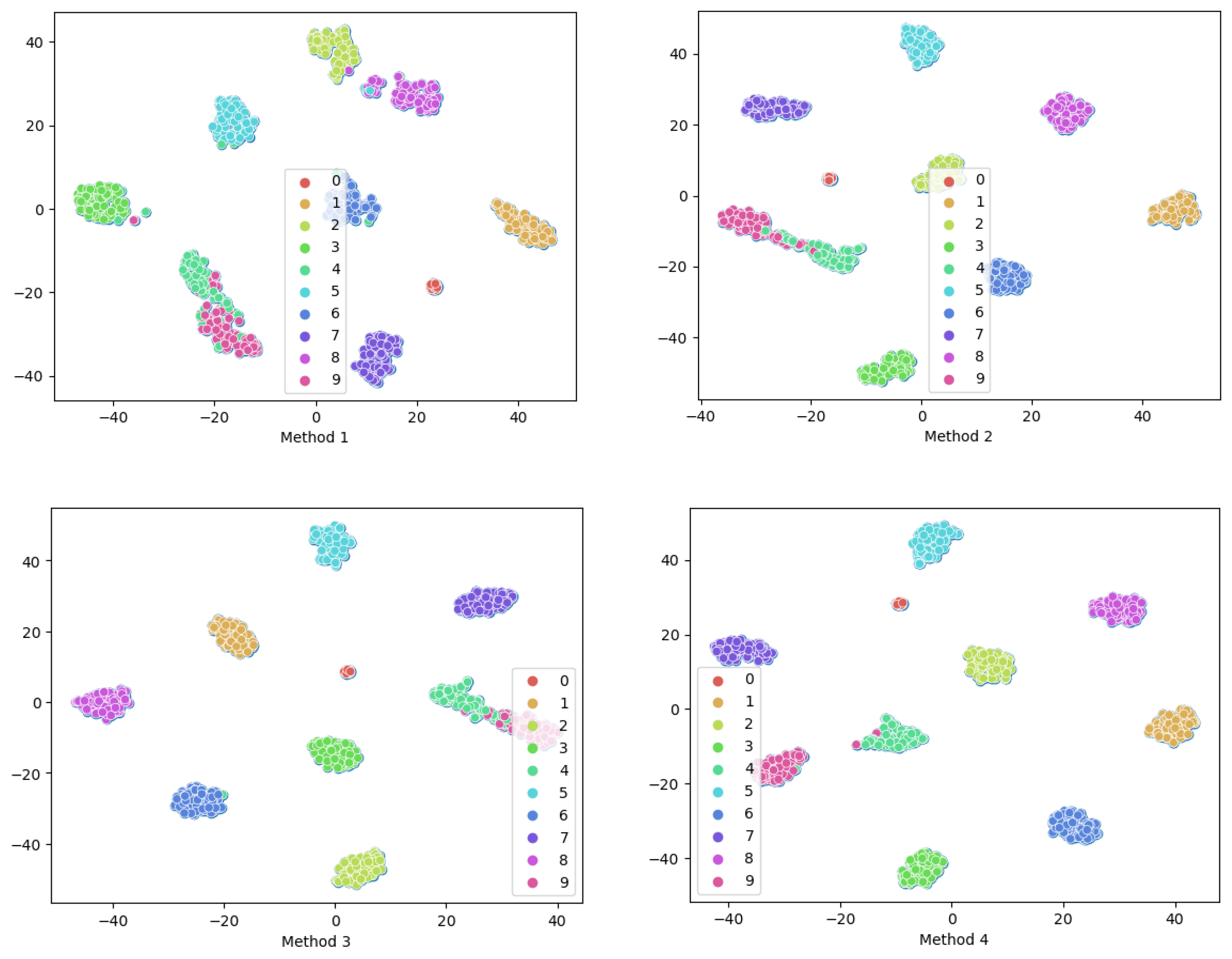
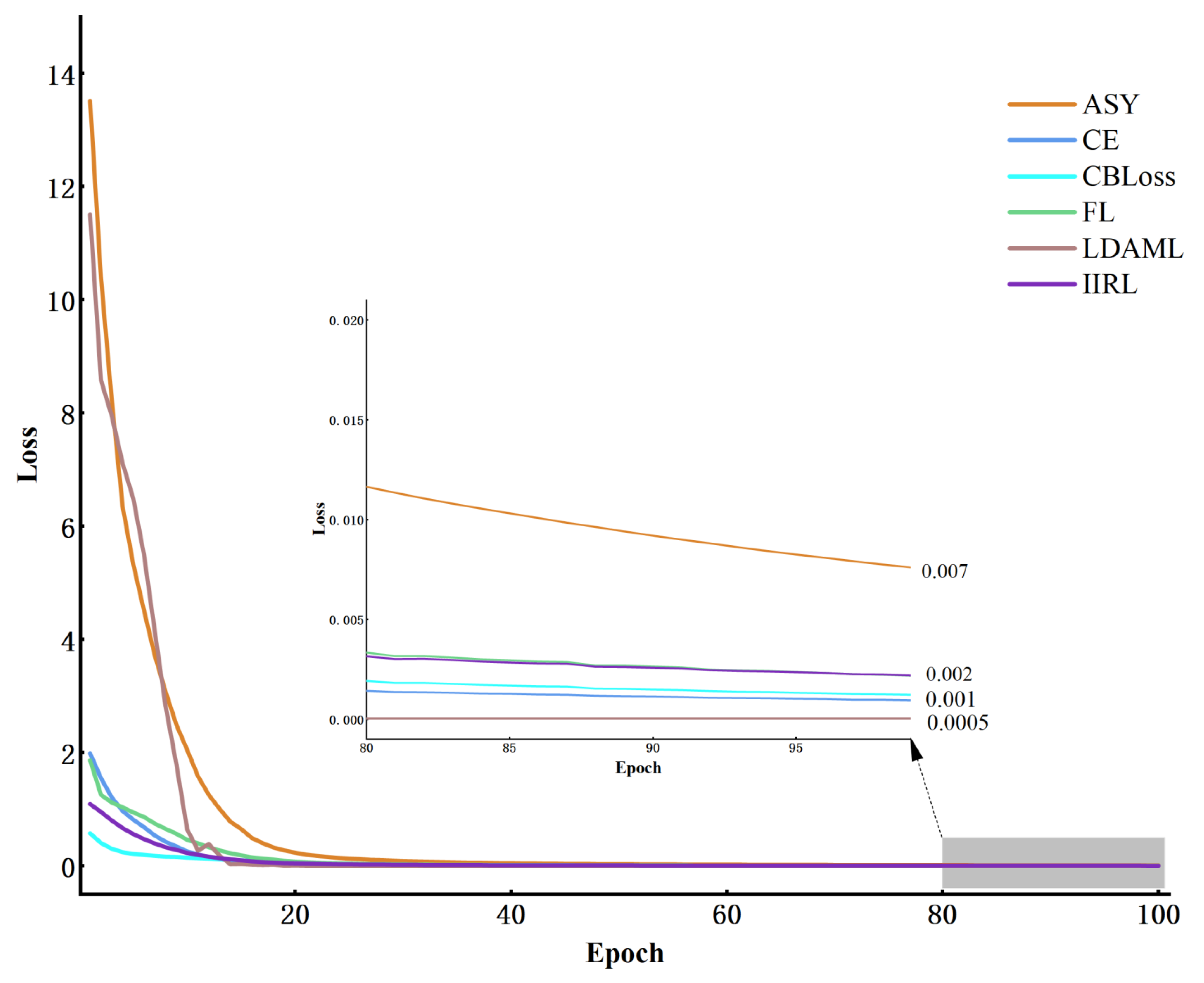
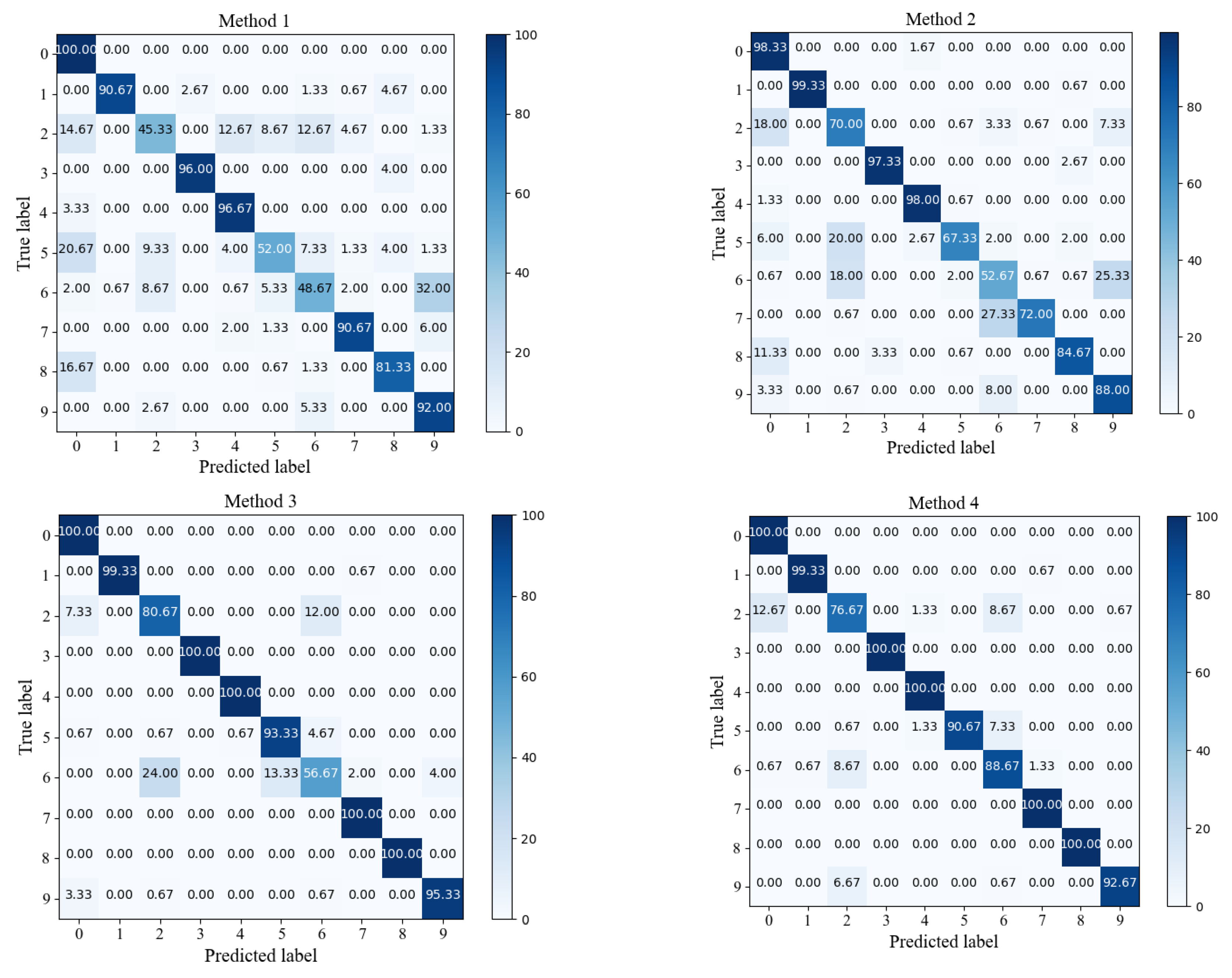
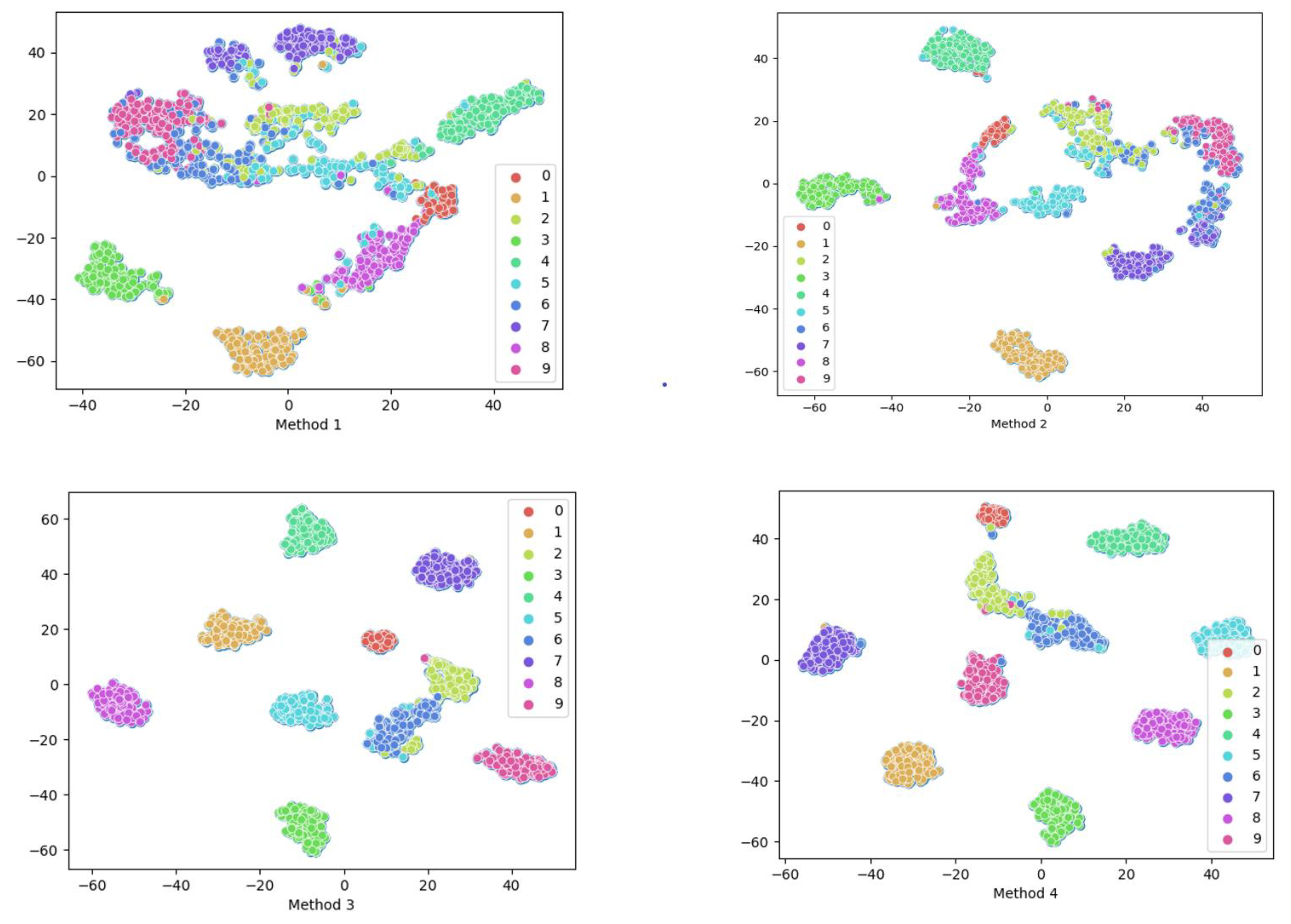
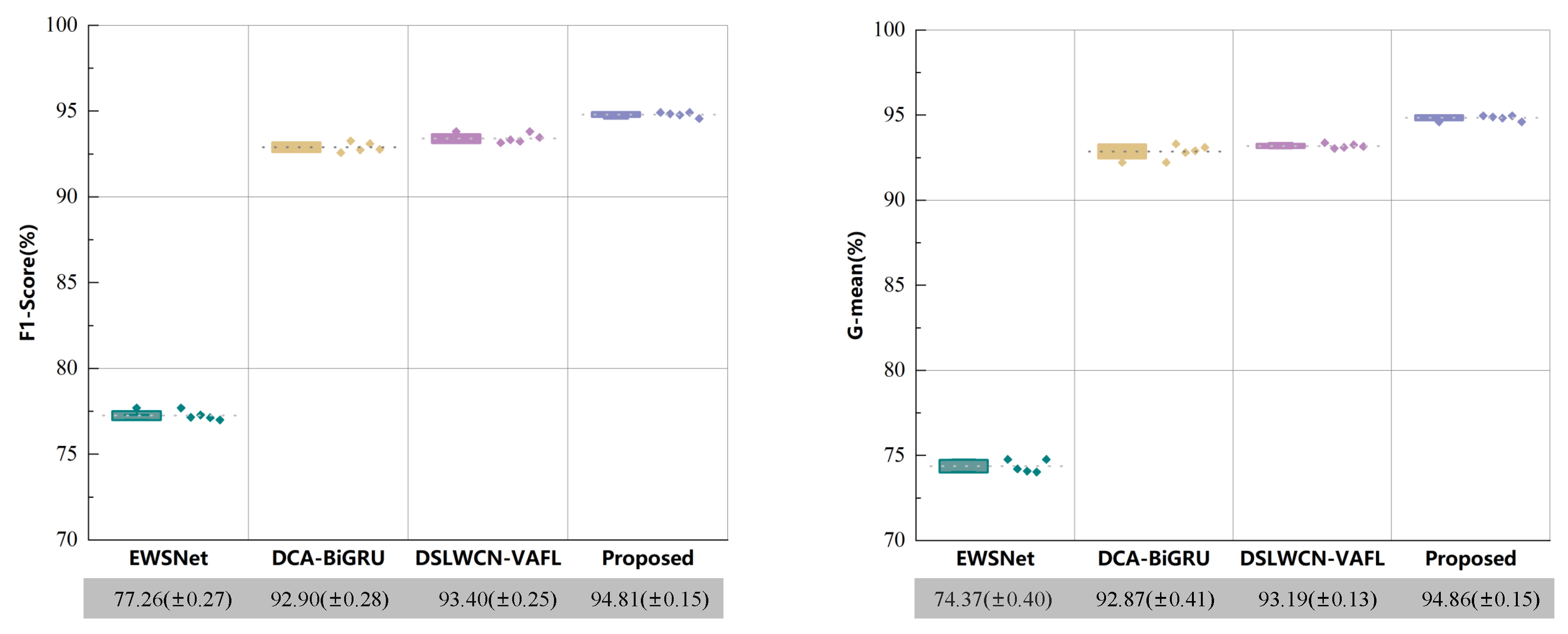
We introduced a Neural Network framework called DSADRSViT-IIRL to address the problem of small and imbalanced Datasets. To the best of our knowledge, this is the first implementation of combining the DRSN with ViT and proposing the DSA-DRSB. The ViT equipped with the DBA-DRSN blocks can identify local critical time–frequency bands that impact model Classification while emphasizing the Global fault information. We explored the superiority of the DSADRSViT-IIRL algorithm over other methods on two different bearing Datasets. In particular, the strategy of combining fusion thresholds and shared thresholds was used to alleviate the training pressure caused by redundant information and, at the same time, mining potential local key feature vectors, which enables the model to capture discriminative features in extremely limited Samples. Furthermore, we designed a novel cost Loss, IIRL, to address severe Class imbalance, rebalancing the contributions of both Interclass and Intraclass Samples to model convergence. Through comparative experiments, we found that the compared methods exhibited overfitting issues, further demonstrating the practicality of the IIRL. Finally, through ablation experiments, we validated the effectiveness of each module in the proposed method. Additionally, recent fault diagnosis methods were compared to demonstrate the viability of the proposed approach. The DSADRSViT-IIRL can effectively handle extremely limited and severely imbalanced signal Samples, aligning with the demands of modern industrial production and offering promising applications.
For future developments, lightweight architectures are worth exploring. Additionally, the DSADRSViT-IIRL may struggle to handle variable-speed Datasets. In the future, meta-learning, transfer learning, or reinforcement learning, when combined with ViT or other structures, can be employed to tackle more-complex variable-speed bearing data scenarios.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}











