

Cross-Video Pedestrian Tracking Algorithm with a Coordinate Constraint
 and
and
Abstract
:1. Introduction
- The introduction of spatial affinity improves the accuracy and reliability of pedestrian re-identification.
- The proposed linear weighted algorithm enhances the precision and robustness of cross-video tracking effectively.
2. Related Work
2.1. Pedestrian Localization
2.2. Across-Video Pedestrian Tracking
3. Materials and Methods
3.1. Mapping the Coordinates of Pedestrians in the Video
3.1.1. Coordinate System Transformation
- The internal and external parameters of the camera are obtained using camera calibration, such as the focal length of the camera, pixel size, rotation matrix, and the translation vector of the camera. In this paper, Zhang Zhengyou’s checkerboard camera calibration method [36] is used to obtain the internal and external parameters of the surveillance.
- The relationship between the pixel and the image coordinate system is a process of continuation [37].
- The relationship between the camera and the image coordinate system is based on perspective and can be calculated using the principle of similar triangles.
- The relationship between the world and the camera coordinate system is a rigid transformation involving rotation and translation.
3.1.2. Coordinate System Unity
3.2. Cross-Video Pedestrian Tracking Method
3.2.1. Traditional Pedestrian Detection and Matching
3.2.2. Pedestrian Matching by Introducing the Coordinate Constraint
3.2.3. Cross-Video Pedestrian Tracking with Linear Weighting
3.2.4. Cross-Video Pedestrian Tracking Algorithm Workflow
- Pedestrian X is detected and tracked using the CSRT algorithm to acquire its position in each frame.
- The coordinates of the two surveillance systems are unified using an overlapping view, principles of photography, and rotation and translation matrices.
- When pedestrian X enters the overlapping view, surveillance A obtains the position of X, and the candidate pedestrians in surveillance B are matched using the positional features and the features extracted via the neural network.
- Using the position of pedestrian X that projects onto the weighted auxiliary line, weights are assigned to determine the positions of pedestrian X obtained from surveillances A and B.
- The weights of both surveillances are adjusted as the distance of pedestrian X changes from Cam_A to Cam_B, enhancing the tracking robustness of pedestrians between the two surveillances.
4. Results
4.1. Experimental Protocol
4.1.1. Experimental Scene
4.1.2. Experimental Hardware and Parameters
4.1.3. Pedestrian Tracking Performance Metrics
4.2. Pedestrian Detection and Matching
4.3. Cross-Video Pedestrian Tracking Experiment Results
4.3.1. Cross-Video Pedestrian Tracking without Coordinate Constraints
4.3.2. Cross-Video Pedestrian Tracking with Coordinate Constraint
5. Discussion
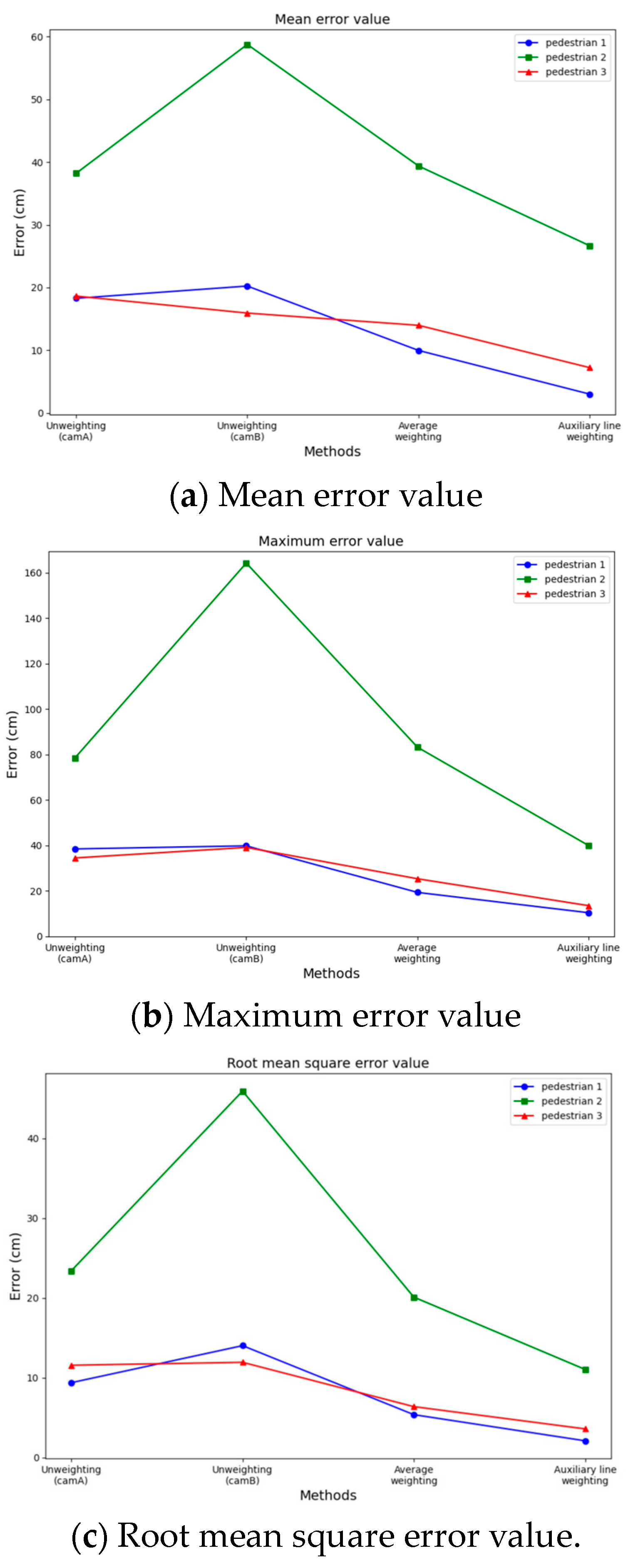
- The clarity and color of the surveillance affect the appearance features of the monitored pedestrians, but by introducing coordinates as pedestrian feature information, the matching process not only follows similarity but also considers the closeness of the pedestrian locations. In addition, when monitoring numerous pedestrians, the probability of incorrect matching is greatly decreased.
- In monitoring the location of a pedestrian from multiple monitors, pedestrian tracking is not limited to one monitor and has strong robustness. Simultaneously, the weights of pedestrian locations are assigned based on a weighted auxiliary line, which weakens the values with large tracking errors and yields more precise results for pedestrian tracking.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Valera, M.; Velastin, S.A. Intelligent Distributed Surveillance Systems: A Review. IEE Proc. Vis. Image Process. 2005, 152, 192. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. arXiv 2013, arXiv:1311.2524. [Google Scholar]
- Marvasti-Zadeh, S.M.; Cheng, L.; Ghanei-Yakhdan, H.; Kasaei, S. Deep Learning for Visual Tracking: A Comprehensive Survey. IEEE Trans. Intell. Transport. Syst. 2022, 23, 3943–3968. [Google Scholar] [CrossRef]
- Marčetić, D.; Maleš, L.; Ribarić, S. Crowd Motion Pattern Detection at the Microscopic Level. In Proceedings of the 2019 42nd International Convention on Information and Communication Technology, Electronics and Microelectronics (MIPRO), Opatija, Croatia, 20–24 May 2019; pp. 1093–1098. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Sun, Y.; Zheng, L.; Yang, Y.; Tian, Q.; Wang, S. Beyond Part Models: Person Retrieval with Refined Part Pooling (and a Strong Convolutional Baseline). In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 480–496. [Google Scholar]
- Wei, L.; Zhang, S.; Yao, H.; Gao, W.; Tian, Q. Glad: Global-Local-Alignment Descriptor for Pedestrian Retrieval. In Proceedings of the 25th ACM International Conference on Multimedia, Mountain View, CA, USA, 23–27 October 2017; pp. 420–428. [Google Scholar]
- Yan, W.; Forsyth, D.A. Learning the Behavior of Users in a Public Space through Video Tracking. In Proceedings of the 2005 Seventh IEEE Workshops on Applications of Computer Vision (WACV/MOTION’05)—Volume 1, Breckenridge, CO, USA, 5–7 January 2005; pp. 370–377. [Google Scholar]
- Rao, J.; Xu, K.; Chen, J.; Lei, J.; Zhang, Z.; Zhang, Q.; Giernacki, W.; Liu, M. Sea-Surface Target Visual Tracking with a Multi-Camera Cooperation Approach. Sensors 2022, 22, 693. [Google Scholar] [CrossRef] [PubMed]
- Zhou, S.; Ke, M.; Qiu, J.; Wang, J. A Survey of Multi-Object Video Tracking Algorithms. In Proceedings of the International Conference on Applications and Techniques in Cyber Security and Intelligence ATCI 2018, Shanghai, China, 11–13 July 2018; Abawajy, J., Choo, K.-K.R., Islam, R., Xu, Z., Atiquzzaman, M., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 351–369. [Google Scholar]
- Han, S.; Miao, S.; Hao, X.; Chen, R. Spatial Localization Method for Dynamic Objects in Surveillance Videos. Bull. Surv. Mapp. 2022, 87–92. [Google Scholar] [CrossRef]
- Milosavljević, A.; Rančić, D.; Dimitrijević, A.; Predić, B.; Mihajlović, V. A Method for Estimating Surveillance Video Georeferences. ISPRS Int. J. Geo-Inf. 2017, 6, 211. [Google Scholar] [CrossRef]
- Gündoğdu, E.; Alatan, A.A. The Visual Object Tracking VOT2016 Challenge Results. In Proceedings of the Computer Vision–ECCV 2016 Workshops, Amsterdam, The Netherlands, 8–10, 15–16 October 2016; Proceedings, Part II. Springer International Publishing: Cham, Switzerland, 2016; pp. 777–823. [Google Scholar]
- Kristan, M.; Leonardis, A.; Matas, J.; Felsberg, M.; Pflugfelder, R.; Zajc, L.Č.; Vojír, T.; Bhat, G.; Lukežič, A.; Eldesokey, A.; et al. The Sixth Visual Object Tracking VOT2018 Challenge Results. In Computer Vision–ECCV 2018 Workshops; Leal-Taixé, L., Roth, S., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2019; Volume 11129, pp. 3–53. ISBN 978-3-030-11008-6. [Google Scholar]
- Li, S.; Yeung, D.-Y. Visual Object Tracking for Unmanned Aerial Vehicles: A Benchmark and New Motion Models. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; Volume 31. [Google Scholar] [CrossRef]
- Zhang, R.; Xu, L.; Yu, Z.; Shi, Y.; Mu, C.; Xu, M. Deep-IRTarget: An Automatic Target Detector in Infrared Imagery Using Dual-Domain Feature Extraction and Allocation. IEEE Trans. Multimed. 2021, 24, 1735–1749. [Google Scholar] [CrossRef]
- Sreenu, G.; Saleem Durai, M.A. Intelligent Video Surveillance: A Review through Deep Learning Techniques for Crowd Analysis. J. Big Data 2019, 6, 48. [Google Scholar] [CrossRef]
- Yang, L.; Hu, G.; Song, Y.; Li, G.; Xie, L. Intelligent Video Analysis: A Pedestrian Trajectory Extraction Method for the Whole Indoor Space without Blind Areas. Comput. Vis. Image Underst. 2020, 196, 102968. [Google Scholar] [CrossRef]
- Gupta, S.; Arbelaez, P.; Girshick, R.; Malik, J. Aligning 3D Models to RGB-D Images of Cluttered Scenes. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 4731–4740. [Google Scholar]
- Koppanyi, Z.; Toth, C.; Soltesz, T. Deriving Pedestrian Positions from Uncalibrated Videos. In Proceedings of the ASPRS Imaging & Geospatial Technology Forum (IGTF), Tampa, FL, USA, 4–8 May 2017. [Google Scholar]
- Varga, D.; Szirányi, T.; Kiss, A.; Spórás, L.; Havasi, L. A Multi-View Pedestrian Tracking Method in an Uncalibrated Camera Network. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Santiago, Chile, 7–13 December 2015; pp. 37–44. [Google Scholar]
- Guo, Y.; Liu, Z.; Luo, H.; Pu, H.; Tan, J. Multi-Person Multi-Camera Tracking for Live Stream Videos Based on Improved Motion Model and Matching Cascade. Neurocomputing 2022, 492, 561–571. [Google Scholar] [CrossRef]
- Wang, Q.; Zhang, W.; Yang, W.; Xu, C.; Cui, Z. Prototype-Guided Instance Matching for Multiple Pedestrian Tracking. Neurocomputing 2023, 538, 126207. [Google Scholar] [CrossRef]
- Yang, H.; Cai, J.; Liu, C.; Ke, R.; Wang, Y. Cooperative Multi-Camera Vehicle Tracking and Traffic Surveillance with Edge Artificial Intelligence and Representation Learning. Transp. Res. Part C Emerg. Technol. 2023, 148, 103982. [Google Scholar] [CrossRef]
- Rajjak, S.S.A.; Kureshi, A.K. Multiple-Object Detection and Segmentation Based on Deep Learning in High-Resolution Video Using Mask-RCNN. Int. J. Patt. Recogn. Artif. Intell. 2021, 35, 2150038. [Google Scholar] [CrossRef]
- Wu, Y.-C.; Chen, C.-H.; Chiu, Y.-T.; Chen, P.-W. Cooperative People Tracking by Distributed Cameras Network. Electronics 2021, 10, 1780. [Google Scholar] [CrossRef]
- Gheissari, N.; Sebastian, T.B.; Hartley, R. Person Reidentification Using Spatiotemporal Appearance. In Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition—Volume 2 (CVPR’06), New York, NY, USA, 21–23 June 2006; Volume 2, pp. 1528–1535. [Google Scholar]
- Liu, C.; Zhang, L.; Huang, H. Visualization of Cross-View Multi-Object Tracking in Traffic Intersection Surveil-lance Videos. J. Comput. Sci. 2018, 41, 221–235. [Google Scholar]
- Khan, S.; Shah, M. Consistent Labeling of Tracked Objects in Multiple Cameras with Overlapping Fields of View. IEEE Trans. Pattern Anal. Mach. Intell. 2003, 25, 1355–1360. [Google Scholar] [CrossRef]
- Yang, X. A Moving Target Tracking Algorithm Based on Multi-Camera Coordination. In Proceedings of the 2021 IEEE 3rd Eurasia Conference on IOT, Communication and Engineering (ECICE), Yunlin, Taiwan, 29–31 October 2021; pp. 182–185. [Google Scholar]
- Xu, X.; Li, X.; Zhao, H.; Liu, M.; Xu, A.; Ma, Y. A Real-Time, Continuous Pedestrian Tracking and Positioning Method with Multiple Coordinated Overhead-View Cameras. Measurement 2021, 178, 109386. [Google Scholar] [CrossRef]
- Luhmann, T.; Fraser, C.; Maas, H.-G. Sensor Modelling and Camera Calibration for Close-Range Photogrammetry. ISPRS J. Photogramm. Remote Sens. 2016, 115, 37–46. [Google Scholar] [CrossRef]
- Linder, W. Digital Photogrammetry; Springer: Berlin/Heidelberg, Germany, 2009; ISBN 978-3-540-92724-2. [Google Scholar]
- Zhang, Z. A Flexible New Technique for Camera Calibration. IEEE Trans. Pattern Anal. Machine Intell. 2000, 22, 1330–1334. [Google Scholar] [CrossRef]
- Hartley, R.; Zisserman, A. Multiple View Geometry in Computer Vision; Cambridge University Press: Cambridge, UK, 2003. [Google Scholar]
- Klema, V.; Laub, A. The Singular Value Decomposition: Its Computation and Some Applications. IEEE Trans. Automat. Contr. 1980, 25, 164–176. [Google Scholar] [CrossRef]
- Golub, G.H.; Van Loan, C.F. Matrix Computations; JHU Press: Baltimore, MD, USA, 2013; ISBN 1-4214-0859-7. [Google Scholar]
- Liu, Z.; Gu, X.; Yang, H.; Wang, L.; Chen, Y.; Wang, D. Novel YOLOv3 Model with Structure and Hyperparameter Optimization for Detection of Pavement Concealed Cracks in GPR Images. IEEE Trans. Intell. Transp. Syst. 2022, 23, 22258–22268. [Google Scholar] [CrossRef]
- Khan, A.; Sohail, A.; Zahoora, U.; Qureshi, A.S. A Survey of the Recent Architectures of Deep Convolutional Neural Networks. Artif. Intell. Rev. 2020, 53, 5455–5516. [Google Scholar] [CrossRef]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-Based Learning Applied to Document Recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep Learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Zhou, W.; Wang, H.; Wan, Z. Ore Image Classification Based on Improved CNN. Comput. Electr. Eng. 2022, 99, 107819. [Google Scholar] [CrossRef]
- Schroff, F.; Kalenichenko, D.; Philbin, J. FaceNet: A Unified Embedding for Face Recognition and Clustering. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 815–823. [Google Scholar]
- Verma, K.K.; Kumar, P.; Tomar, A. Analysis of Moving Object Detection and Tracking in Video Surveillance System. In Proceedings of the 2015 2nd International Conference on Computing for Sustainable Global Development (INDIACom), New Delhi, India, 11–13 March 2015; pp. 1758–1762. [Google Scholar]
- Mohan, A.; Kaseb, A.S.; Gauen, K.W.; Lu, Y.-H.; Reibman, A.R.; Hacker, T.J. Determining the Necessary Frame Rate of Video Data for Object Tracking under Accuracy Constraints. In Proceedings of the 2018 IEEE Conference on Multimedia Information Processing and Retrieval (MIPR), Miami, FL, USA, 10–12 April 2018; pp. 368–371. [Google Scholar]
- Danelljan, M.; Robinson, A.; Khan, F.S.; Felsberg, M. Beyond Correlation Filters: Learning Continuous Convolution Operators for Visual Tracking. In Proceedings of the Computer Vision–ECCV 2016, Amsterdam, The Netherlands, 11–14 October 2016; Lecture Notes in Computer Science. Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer: Cham, Switzerland, 2016; Volume 9909, pp. 472–488. [Google Scholar]
- Dardagan, N.; Brđanin, A.; Džigal, D.; Akagic, A. Multiple Object Trackers in OpenCV: A Benchmark. In Proceedings of the 2021 IEEE 30th International Symposium on Industrial Electronics (ISIE), Kyoto, Japan, 20–23 June 2021. [Google Scholar]
- Ding, B.; Zhang, R.; Xu, L.; Liu, G.; Yang, S.; Liu, Y.; Zhang, Q. U2D2 Net: Unsupervised Unified Image Dehazing and Denoising Network for Single Hazy Image Enhancement. IEEE Trans. Multimed. 2023, 26, 202–217. [Google Scholar] [CrossRef]
- Gu, H.; Li, J.; Fu, G.; Wong, C.; Chen, X.; Zhu, J. Autoloss-Gms: Searching Generalized Margin-Based Softmax Loss Function for Person Re-Identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 4744–4753. [Google Scholar]
- Su, C.; Li, J.; Zhang, S.; Xing, J.; Gao, W.; Tian, Q. Pose-Driven Deep Convolutional Model for Person Re-Identification. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 3960–3969. [Google Scholar]
- Guo, Y.; Li, W.; Yang, G.; Jiao, Z.; Yan, J. Combining Dilution of Precision and Kalman Filtering for UWB Positioning in a Narrow Space. Remote Sens. 2022, 14, 5409. [Google Scholar] [CrossRef]
- Ho, Y.H.; Chan, H.C. Decentralized Adaptive Indoor Positioning Protocol Using Bluetooth Low Energy. Comput. Commun. 2020, 159, 231–244. [Google Scholar] [CrossRef]
- Bi, J.; Zhao, M.; Yao, G.; Cao, H.; Feng, Y.; Jiang, H.; Chai, D. PSOSVRPos: WiFi Indoor Positioning Using SVR Optimized by PSO. Expert Syst. Appl. 2023, 222, 119778. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Candidate Pedestrians | Coordinates | Pcnn | f(i) | p |
|---|---|---|---|---|
| 1 | (405, 345) | 0.4140 | 2.032 × 10−2 | 0.0084 |
| 2 | (1520, 284) | 0.1570 | 0 | 0 |
| 3 | (536, 308) | 0.4280 | 1.281 × 10−2 | 0.0055 |
| 4 | (986, 878) | 7.249 × 10−5 | 4.033 × 10−17 | 0 |
| 5 | (591, 1146) | 0.0005 | 6.725 × 10−22 | 3.36 × 10−27 |
| 6 | (386, 517) | 7.199 × 10−6 | 9.216 × 10−9 | 6.64 × 10−16 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, C.; Li, W.; Yang, G.; Yan, J.; Zhou, B.; Li, Y. Cross-Video Pedestrian Tracking Algorithm with a Coordinate Constraint. Sensors 2024, 24, 779. https://doi.org/10.3390/s24030779
Huang C, Li W, Yang G, Yan J, Zhou B, Li Y. Cross-Video Pedestrian Tracking Algorithm with a Coordinate Constraint. Sensors. 2024; 24(3):779. https://doi.org/10.3390/s24030779
Chicago/Turabian StyleHuang, Cheng, Weihong Li, Guang Yang, Jiachen Yan, Baoding Zhou, and Yujun Li. 2024. "Cross-Video Pedestrian Tracking Algorithm with a Coordinate Constraint" Sensors 24, no. 3: 779. https://doi.org/10.3390/s24030779