
Synthetic Document Images with Diverse Shadows for Deep Shadow Removal Networks

Abstract
:1. Introduction
- We propose the synthetic dataset called SynDocDS, a large-scale, diverse synthetic document dataset comprising shadow images, shadow-free images, and shadow mattes in various scenes. The dataset is diversified based on our observations regarding the illumination model. The source code and datasets will be released.
- We show that (pre-)training on the SynDocDS dataset results in more effective and robust networks than training on a limited real dataset.
- We propose a new network for shadow removal that fuses multiple features and shadow attentions efficiently. Experimental results show that our network yields better results than other networks.
2. Related Work
2.1. Shadow Removal
2.2. Shadow Synthesis
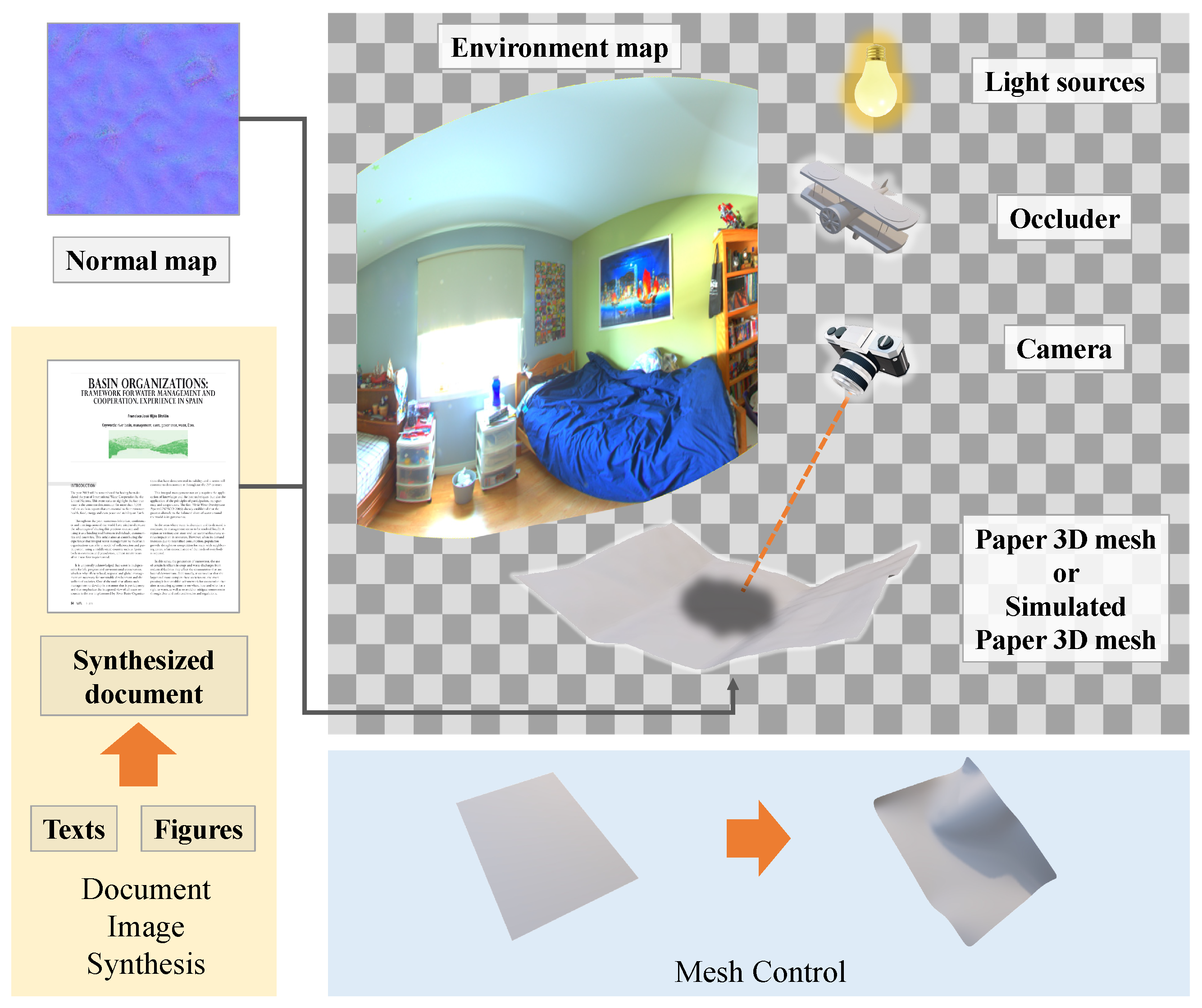
3. Synthetic Documents with Diverse Shadows
3.1. Image Rendering
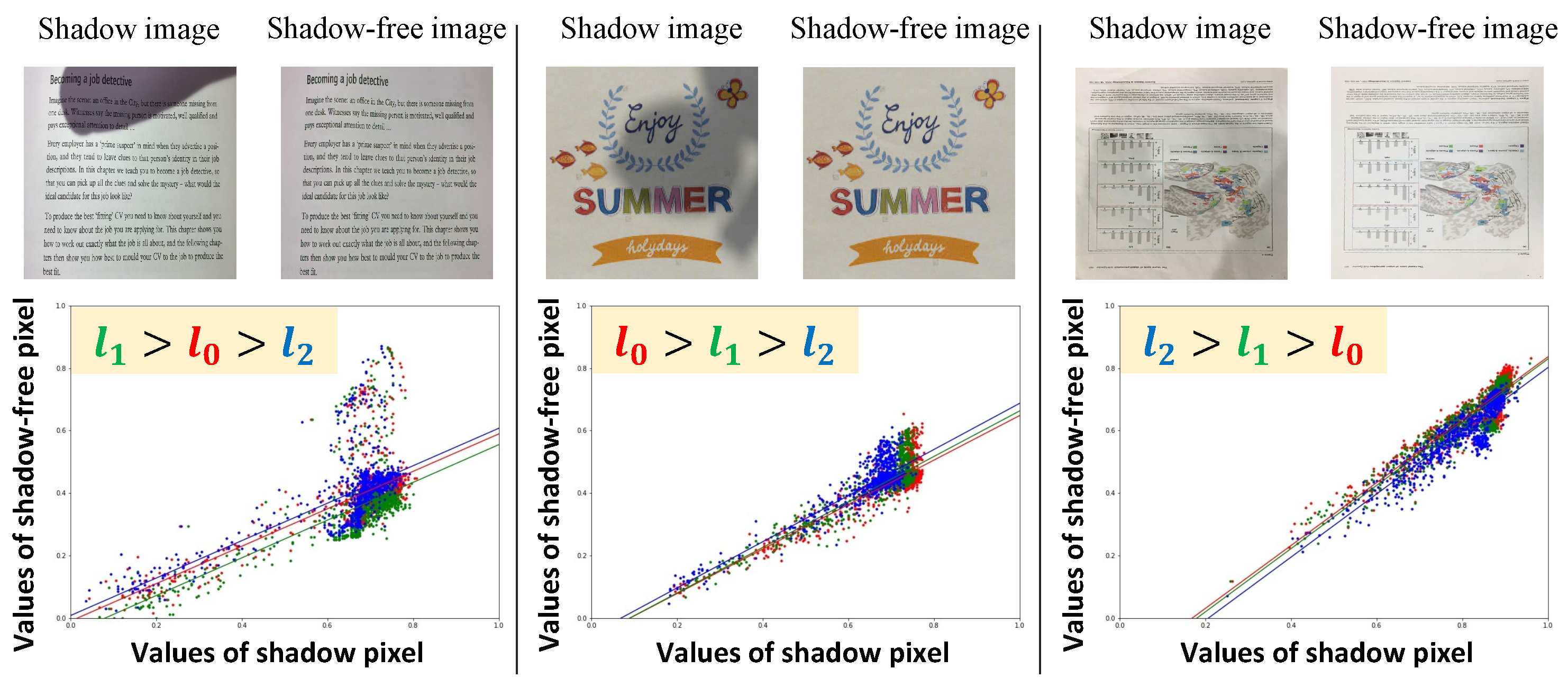
3.2. Enriching Shadow Images
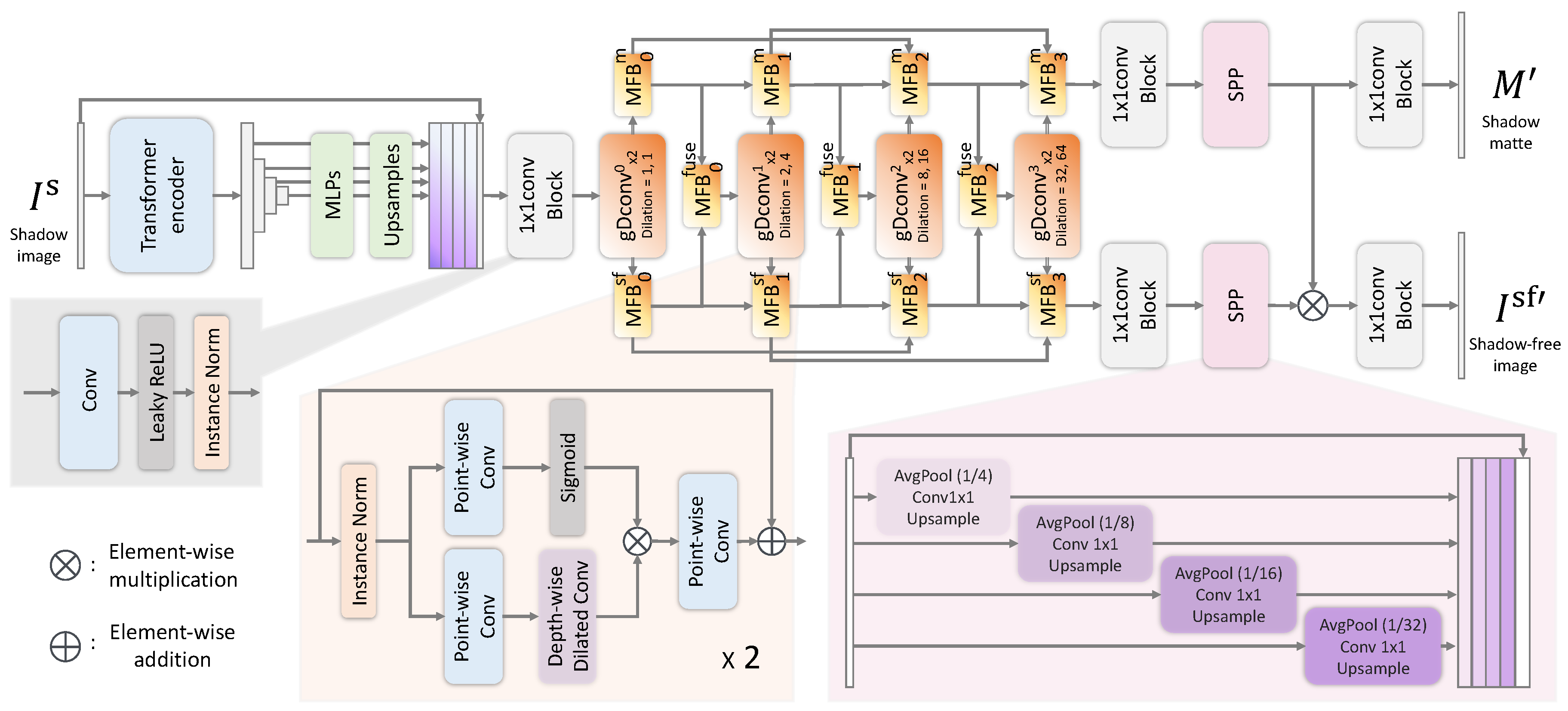
4. Method
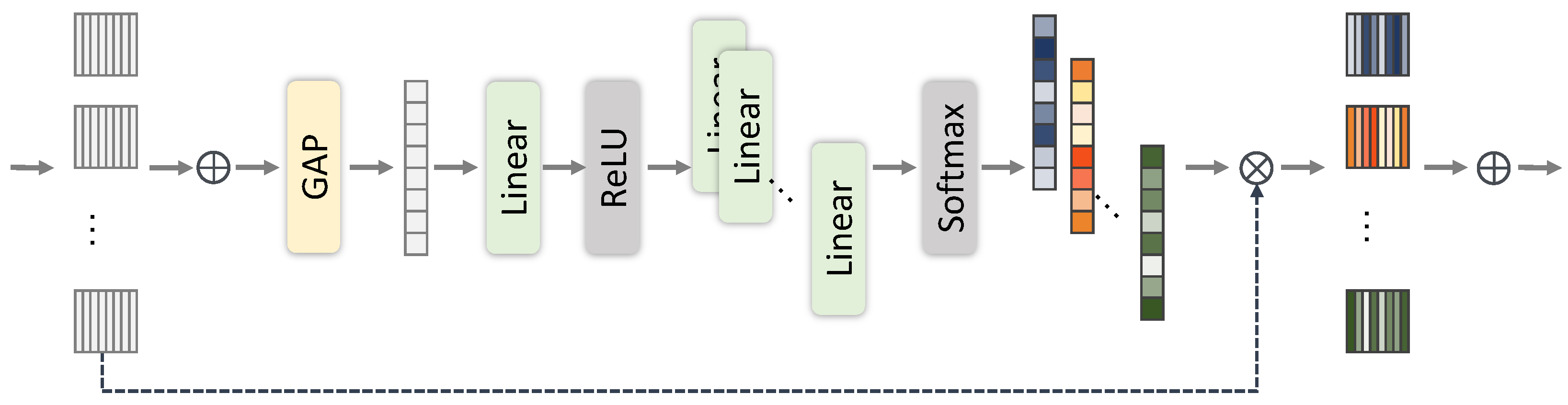
4.1. Dual Shadow Fusion Network
4.2. Loss Functions
5. Experiments
5.1. Dataset Details
5.2. Compared Methods and Evaluation Metrics
5.3. Visual Quality
5.4. Text Readability
6. Discussion
6.1. Quantitative Score
6.2. Dataset Diversity
6.3. Limitations
6.4. Future Works
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A



References
- Bako, S.; Darabi, S.; Shechtman, E.; Wang, J.; Sunkavalli, K.; Sen, P. Removing Shadows from Images of Documents. In Proceedings of the Asian Conference on Computer Vision (ACCV 2016), Taipei, Taiwan, 20–24 November 2016. [Google Scholar]
- Kligler, N.; Katz, S.; Tal, A. Document Enhancement Using Visibility Detection. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2374–2382. [Google Scholar] [CrossRef]
- Jung, S.; Hasan, M.A.; Kim, C. Water-filling: An efficient algorithm for digitized document shadow removal. In Proceedings of the Asian Conference on Computer Vision, Perth, Australia, 2–6 December 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 398–414. [Google Scholar]
- Wang, B.; Chen, C.L.P. An Effective Background Estimation Method for Shadows Removal of Document Images. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 3611–3615. [Google Scholar] [CrossRef]
- Wang, B.; Chen, C. Local Water-Filling Algorithm for Shadow Detection and Removal of Document Images. Sensors 2020, 20, 6929. [Google Scholar] [CrossRef] [PubMed]
- Lin, Y.H.; Chen, W.C.; Chuang, Y.Y. Bedsr-net: A deep shadow removal network from a single document image. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 12905–12914. [Google Scholar]
- Wang, J.; Li, X.; Yang, J. Stacked conditional generative adversarial networks for jointly learning shadow detection and shadow removal. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1788–1797. [Google Scholar]
- Hu, X.; Fu, C.W.; Zhu, L.; Qin, J.; Heng, P.A. Direction-Aware Spatial Context Features for Shadow Detection and Removal. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2795–2808. [Google Scholar] [CrossRef] [PubMed]
- Cun, X.; Pun, C.M.; Shi, C. Towards ghost-free shadow removal via dual hierarchical aggregation network and shadow matting GAN. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 May 2020; Volume 34, pp. 10680–10687. [Google Scholar]
- Zhang, L.; He, Y.; Zhang, Q.; Liu, Z.; Zhang, X.; Xiao, C. Document Image Shadow Removal Guided by Color-Aware Background. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 18–22 June 2023; pp. 1818–1827. [Google Scholar]
- Li, Z.; Chen, X.; Pun, C.M.; Cun, X. High-Resolution Document Shadow Removal via A Large-Scale Real-World Dataset and A Frequency-Aware Shadow Erasing Net. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 30 September–6 October 2023; pp. 12449–12458. [Google Scholar]
- Inoue, N.; Yamasaki, T. Learning from Synthetic Shadows for Shadow Detection and Removal. IEEE Trans. Circuits Syst. Video Technol. 2021, 31, 4187–4197. [Google Scholar] [CrossRef]
- Guo, R.; Dai, Q.; Hoiem, D. Paired Regions for Shadow Detection and Removal. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 2956–2967. [Google Scholar] [CrossRef] [PubMed]
- Shor, Y.; Lischinski, D. The Shadow Meets the Mask: Pyramid-Based Shadow Removal. Comput. Graph. Forum 2008, 27, 577–586. [Google Scholar] [CrossRef]
- Le, H.; Samaras, D. Physics-Based Shadow Image Decomposition for Shadow Removal. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 9088–9101. [Google Scholar] [CrossRef] [PubMed]
- Qu, L.; Tian, J.; He, S.; Tang, Y.; Lau, R.W. Deshadownet: A multi-context embedding deep network for shadow removal. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4067–4075. [Google Scholar]
- Fu, L.; Zhou, C.; Guo, Q.; Juefei-Xu, F.; Yu, H.; Feng, W.; Liu, Y.; Wang, S. Auto-exposure fusion for single-image shadow removal. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 10571–10580. [Google Scholar]
- Yu, F.; Wang, D.; Shelhamer, E.; Darrell, T. Deep layer aggregation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2403–2412. [Google Scholar]
- Hu, X.; Jiang, Y.; Fu, C.W.; Heng, P.A. Mask-shadowgan: Learning to remove shadows from unpaired data. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 2472–2481. [Google Scholar]
- Liu, Z.; Yin, H.; Mi, Y.; Pu, M.; Wang, S. Shadow removal by a lightness-guided network with training on unpaired data. IEEE Trans. Image Process. 2021, 30, 1853–1865. [Google Scholar] [CrossRef] [PubMed]
- Liu, Z.; Yin, H.; Wu, X.; Wu, Z.; Mi, Y.; Wang, S. From Shadow Generation to Shadow Removal. In Proceedings of the CVPR, Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization. Int. J. Comput. Vis. 2020, 128, 336–360. [Google Scholar] [CrossRef]
- Sidorov, O. Conditional gans for multi-illuminant color constancy: Revolution or yet another approach? In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–17 June 2019. [Google Scholar]
- Gryka, M.; Terry, M.; Brostow, G.J. Learning to Remove Soft Shadows. ACM Trans. Graph. 2015, 34, 1–15. [Google Scholar] [CrossRef]
- Autodesk, I. Maya. 2019. Available online: https://autodesk.com/maya (accessed on 19 October 2023).
- Das, S.; Sial, H.A.; Ma, K.; Baldrich, R.; Vanrell, M.; Samaras, D. Intrinsic Decomposition of Document Images In-the-Wild. In Proceedings of the 31st British Machine Vision Conference 2020, BMVC 2020, Manchester, UK, 7–10 September 2020; BMVA Press: Durham, UK, 2020. [Google Scholar]
- Das, S.; Ma, K.; Shu, Z.; Samaras, D.; Shilkrot, R. Dewarpnet: Single-image document unwarping with stacked 3d and 2d regression networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 131–140. [Google Scholar]
- Clausner, C.; Antonacopoulos, A.; Pletschacher, S. ICDAR2017 Competition on Recognition of Documents with Complex Layouts—RDCL2017. In Proceedings of the 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), Kyoto, Japan, 9–15 November 2017; Volume 1, pp. 1404–1410. [Google Scholar] [CrossRef]
- Blender Online Community. Blender—A 3D Modelling and Rendering Package; Blender Foundation; Stichting Blender Foundation: Amsterdam, The Netherlands, 2018. [Google Scholar]
- Veach, E.; Guibas, L.J. Metropolis Light Transport. In Seminal Graphics Papers: Pushing the Boundaries, 1st ed.; Association for Computing Machinery: New York, NY, USA, 2023; Volume 2. [Google Scholar]
- Zharikov, I.; Nikitin, P.; Vasiliev, I.; Dokholyan, V. DDI-100. In Proceedings of the 4th International Symposium on Computer Science and Intelligent Control, Newcastle upon Tyne, UK, 17–19 November 2020. [Google Scholar] [CrossRef]
- Deschaintre, V.; Aittala, M.; Durand, F.; Drettakis, G.; Bousseau, A. Single-image svbrdf capture with a rendering-aware deep network. ACM Trans. Graph. 2018, 37, 1–15. [Google Scholar] [CrossRef]
- Chang, A.X.; Funkhouser, T.; Guibas, L.; Hanrahan, P.; Huang, Q.; Li, Z.; Savarese, S.; Savva, M.; Song, S.; Su, H.; et al. ShapeNet: An Information-Rich 3D Model Repository. 2015. Available online: http://xxx.lanl.gov/abs/1512.03012 (accessed on 19 October 2023).
- Xiao, J.; Ehinger, K.A.; Oliva, A.; Torralba, A. Recognizing scene viewpoint using panoramic place representation. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 2695–2702. [Google Scholar]
- Gardner, M.A.; Sunkavalli, K.; Yumer, E.; Shen, X.; Gambaretto, E.; Gagné, C.; Lalonde, J.F. Learning to predict indoor illumination from a single image. ACM Trans. Graph. 2017, 36, 1–14. [Google Scholar] [CrossRef]
- Barrow, H.; Tenenbaum, J.; Hanson, A.; Riseman, E. Recovering intrinsic scene characteristics. Comput. Vis. Syst. 1978, 2, 2. [Google Scholar]
- Xie, E.; Wang, W.; Yu, Z.; Anandkumar, A.; Alvarez, J.M.; Luo, P. SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers. arXiv 2021, arXiv:2105.15203. [Google Scholar] [CrossRef]
- Matsuo, Y.; Akimoto, N.; Aoki, Y. Document Shadow Removal with Foreground Detection Learning From Fully Synthetic Images. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Bordeaux, France, 16–19 October 2022; pp. 1656–1660. [Google Scholar] [CrossRef]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Song, Y.; Zhou, Y.; Qian, H.; Du, X. Rethinking Performance Gains in Image Dehazing Networks. arXiv 2022, arXiv:2209.11448. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed]
- Yu, J.; Lin, Z.; Yang, J.; Shen, X.; Lu, X.; Huang, T.S. Free-form image inpainting with gated convolution. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 4471–4480. [Google Scholar]
- Zamir, S.W.; Arora, A.; Khan, S.; Hayat, M.; Khan, F.S.; Yang, M.H. Restormer: Efficient transformer for high-resolution image restoration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 5728–5739. [Google Scholar]
- Li, X.; Wang, W.; Hu, X.; Yang, J. Selective kernel networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2019; pp. 510–519. [Google Scholar]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-Excitation Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2011–2023. [Google Scholar] [CrossRef] [PubMed]
- Isola, P.; Zhu, J.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1125–1134. [Google Scholar]
- Johnson, J.; Alahi, A.; Li, F.-F. Perceptual losses for real-time style transfer and super-resolution. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part II 14. Springer: Berlin/Heidelberg, Germany, 2016; pp. 694–711. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Smith, R.W. Hybrid Page Layout Analysis via Tab-Stop Detection. In Proceedings of the 10th International Conference on Document Analysis and Recognition, Barcelona, Spain, 26–29 July 2009; pp. 241–245. [Google Scholar] [CrossRef]
- Gusfield, D. Algorithms on Strings, Trees, and Sequences: Computer Science and Computational Biology; EBL-Schweitzer; Cambridge University Press: Cambridge, UK, 1997. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | #pairs | #documents | Characteristics of Images | Shadow Mask |
|---|---|---|---|---|
| Bako [1] | 81 | 11 | Light shadows, text only | - |
| Kligler [2] | 300 | 25 | Dark shadow, complex content | - |
| Jung [3] | 87 | 87 | Multicast shadows | - |
| OSR [5] | 237 | 26 | Colored shadows, text only | ✓ |
| RDSRD [6] | 540 | 25 | Complex content/shadows | ✓ |
| RDD [10] | 4916 | <500 | Complex content/shadows | ✓ |
| SD7K [11] | 7620 | 350 | Complex content/shadows | ✓ |
| SDSRD [6] | 8309 | 970 | Synthetic shadows, diverse contents/shadows | ✓ |
| SynDocDS (ours) | 50,000 | 1420 | Synthetic documents and shadows, diverse textures/contents/shadows | ✓ |
| Property | Value | |
|---|---|---|
| Mass | 0.4 | |
| Friction | 15 | |
| Stiffness | Tension | 80 |
| Compression | 80 | |
| Shear | 80 | |
| Bending | 10 | |
| Damping | Tension | 25 |
| Compression | 25 | |
| Shear | 25 | |
| Bending | 1 | |
| Training Dataset | Method | Average | OSR Dataset [5] | Kliglers’s Dataset [2] | Jung’s Dataset [3] | ||||
|---|---|---|---|---|---|---|---|---|---|
| PSNR (↑) | SSIM (↑) | PSNR (↑) | SSIM (↑) | PSNR (↑) | SSIM (↑) | PSNR (↑) | SSIM (↑) | ||
| - | Original | 15.72 | 0.9100 | 17.25 | 0.9326 | 14.73 | 0.8874 | 14.93 | 0.9211 |
| - | Bako [1] | 22.31 | 0.9494 | 20.57 | 0.9599 | 24.78 | 0.9443 | 18.54 | 0.9383 |
| Kligler [2] | 19.88 | 0.9184 | 18.17 | 0.9251 | 21.31 | 0.9179 | 19.62 | 0.9018 | |
| Jung [3] | 15.74 | 0.9260 | 15.36 | 0.944 | 13.72 | 0.9053 | 23.76 | 0.9483 | |
| SDSRD [6] | STCGAN-BE [6,7] | 21.94 | 0.9355 | 19.22 | 0.9302 | 24.27 | 0.9438 | 21.20 | 0.9212 |
| BEDSRNet [6] | 22.76 | 0.9459 | 19.24 | 0.9434 | 25.72 | 0.9524 | 22.14 | 0.9303 | |
| DHAN [9] | 20.28 | 0.9512 | 17.48 | 0.9473 | 21.68 | 0.9552 | 23.10 | 0.9483 | |
| DSFN (Ours) | 23.00 | 0.9590 | 19.74 | 0.9581 | 25.53 | 0.9630 | 23.16 | 0.9480 | |
| SynDocDS (Ours) | STCGAN-BE [6,7] | 25.1 | 0.9637 | 23.41 | 0.9696 | 27.01 | 0.9617 | 23.13 | 0.9547 |
| BEDSRNet [6] | 25.69 | 0.9656 | 22.95 | 0.9696 | 28.50 | 0.9649 | 23.48 | 0.9571 | |
| DHAN [9] | 25.51 | 0.9703 | 22.33 | 0.9734 | 29.21 | 0.9717 | 21.45 | 0.9572 | |
| DSFN (ours) | 25.70 | 0.9708 | 22.50 | 0.9739 | 29.24 | 0.9723 | 22.20 | 0.9575 | |
| Method | Training Dataset | OSR Dataset [5] | Kliglers’s Dataset [2] | Jung’s Dataset [3] | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| RMSE (↓) | PSNR (↑) | SSIM (↑) | RMSE (↓) | PSNR (↑) | SSIM (↑) | RMSE (↓) | PSNR (↑) | SSIM (↑) | ||
| Original | - | 9.86 | 17.57 | 0.9249 | 11.61 | 14.76 | 0.9010 | 12.45 | 13.96 | 0.8813 |
| BEDSRNet [6] | Real dataset | 5.72 | 23.37 | 0.9251 | 3.64 | 27.77 | 0.9569 | 5.18 | 24.42 | 0.9144 |
| SDSRD [6] | 7.68 | 19.19 | 0.9055 | 4.72 | 24.58 | 0.9587 | 6.93 | 20.07 | 0.8880 | |
| SynDocDS | 5.51 | 23.97 | 0.9520 | 3.73 | 28.31 | 0.9689 | 4.69 | 22.97 | 0.9332 | |
| SDSRD [6] + FT | 5.04 | 23.76 | 0.9448 | 3.13 | 29.25 | 0.9687 | 4.16 | 24.06 | 0.9205 | |
| SynDocDS + FT | 4.67 | 25.68 | 0.9648 | 2.73 | 30.05 | 0.9745 | 3.68 | 25.01 | 0.9330 | |
| DSFN (ours) | Real dataset | 8.46 | 24.34 | 0.9676 | 3.69 | 25.85 | 0.9738 | 4.25 | 23.62 | 0.9303 |
| SDSRD [6] | 5.85 | 21.74 | 0.9546 | 3.65 | 26.75 | 0.9731 | 5.1 | 21.89 | 0.9213 | |
| SynDocDS | 5.42 | 24.20 | 0.9705 | 2.51 | 30.57 | 0.9809 | 5.59 | 21.20 | 0.9317 | |
| SDSRD [6] + FT | 5.66 | 25.38 | 0.9724 | 2.14 | 30.83 | 0.9799 | 3.71 | 24.82 | 0.9356 | |
| SynDocDS + FT | 5.39 | 25.77 | 0.9728 | 1.97 | 32.02 | 0.9802 | 3.56 | 25.02 | 0.9361 | |
| Method | Original | STCGAN-BE | BEDSR-Net | DHAN | DSFN (Ours) |
|---|---|---|---|---|---|
| Edit distance (↓) @OSR dataset [5] | 172.26 | 28.52 | 28.20 | 26.64 | 25.14 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Matsuo, Y.; Aoki, Y. Synthetic Document Images with Diverse Shadows for Deep Shadow Removal Networks. Sensors 2024, 24, 654. https://doi.org/10.3390/s24020654
Matsuo Y, Aoki Y. Synthetic Document Images with Diverse Shadows for Deep Shadow Removal Networks. Sensors. 2024; 24(2):654. https://doi.org/10.3390/s24020654
Chicago/Turabian StyleMatsuo, Yuhi, and Yoshimitsu Aoki. 2024. "Synthetic Document Images with Diverse Shadows for Deep Shadow Removal Networks" Sensors 24, no. 2: 654. https://doi.org/10.3390/s24020654