



Development of an Effective Corruption-Related Scenario-Based Testing Approach for Robustness Verification and Enhancement of Perception Systems in Autonomous Driving


Abstract
:1. Introduction
2. Related Works
3. Methodology of Simulation-Based Corruption-Related Testing Scenario Benchmark Generation for Robustness Verification and Enhancement
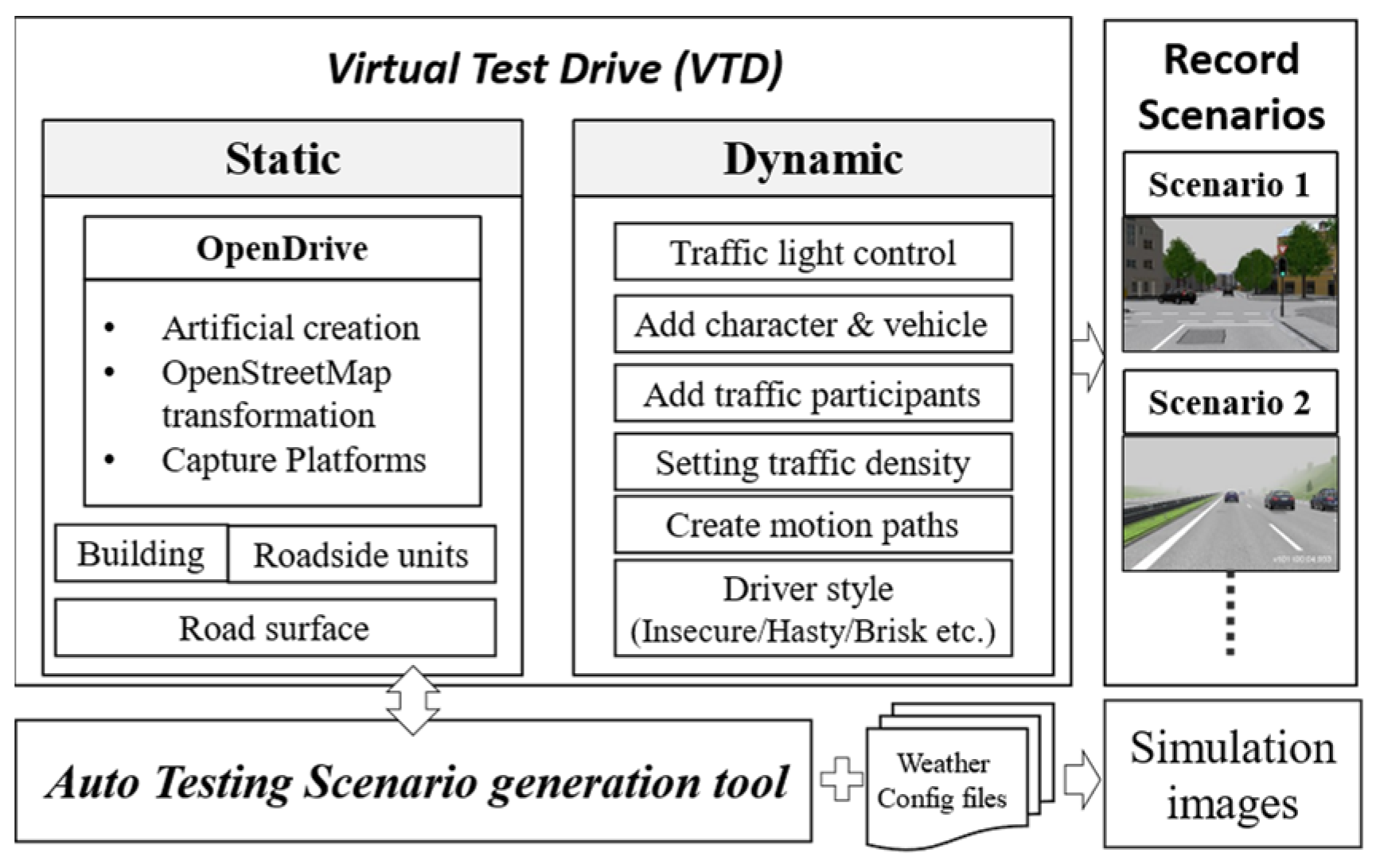
3.1. Automated Test Scenario Generation
3.2. Test Benchmark Dataset Generation
3.2.1. Weather-Related Corruptions
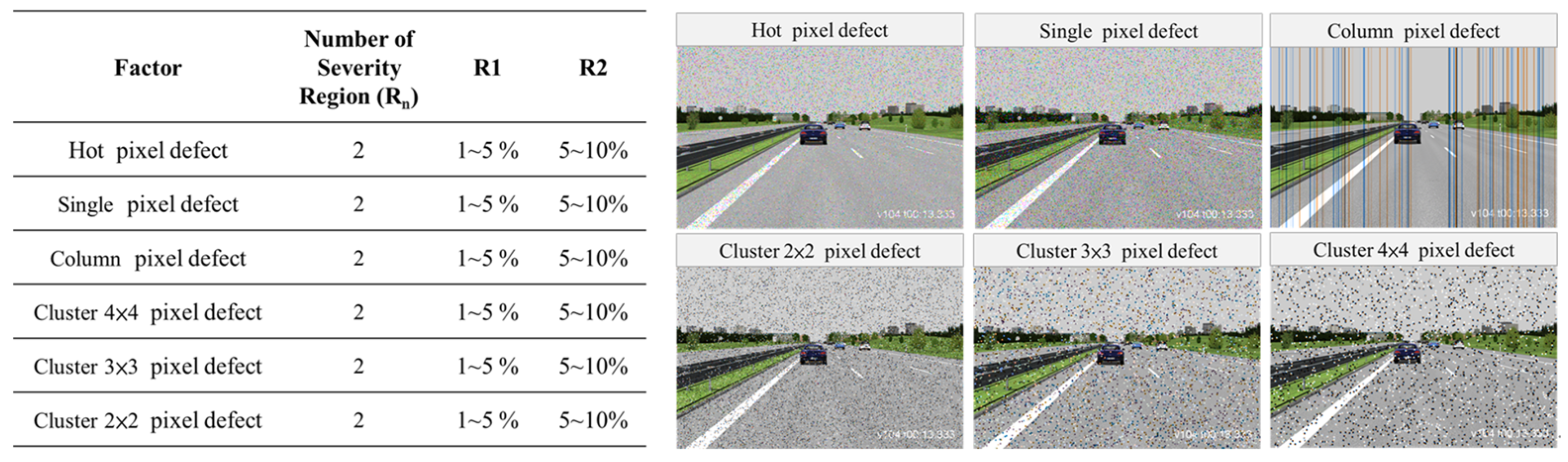
3.2.2. Noise-Related Corruptions
3.2.3. Raindrop Factor
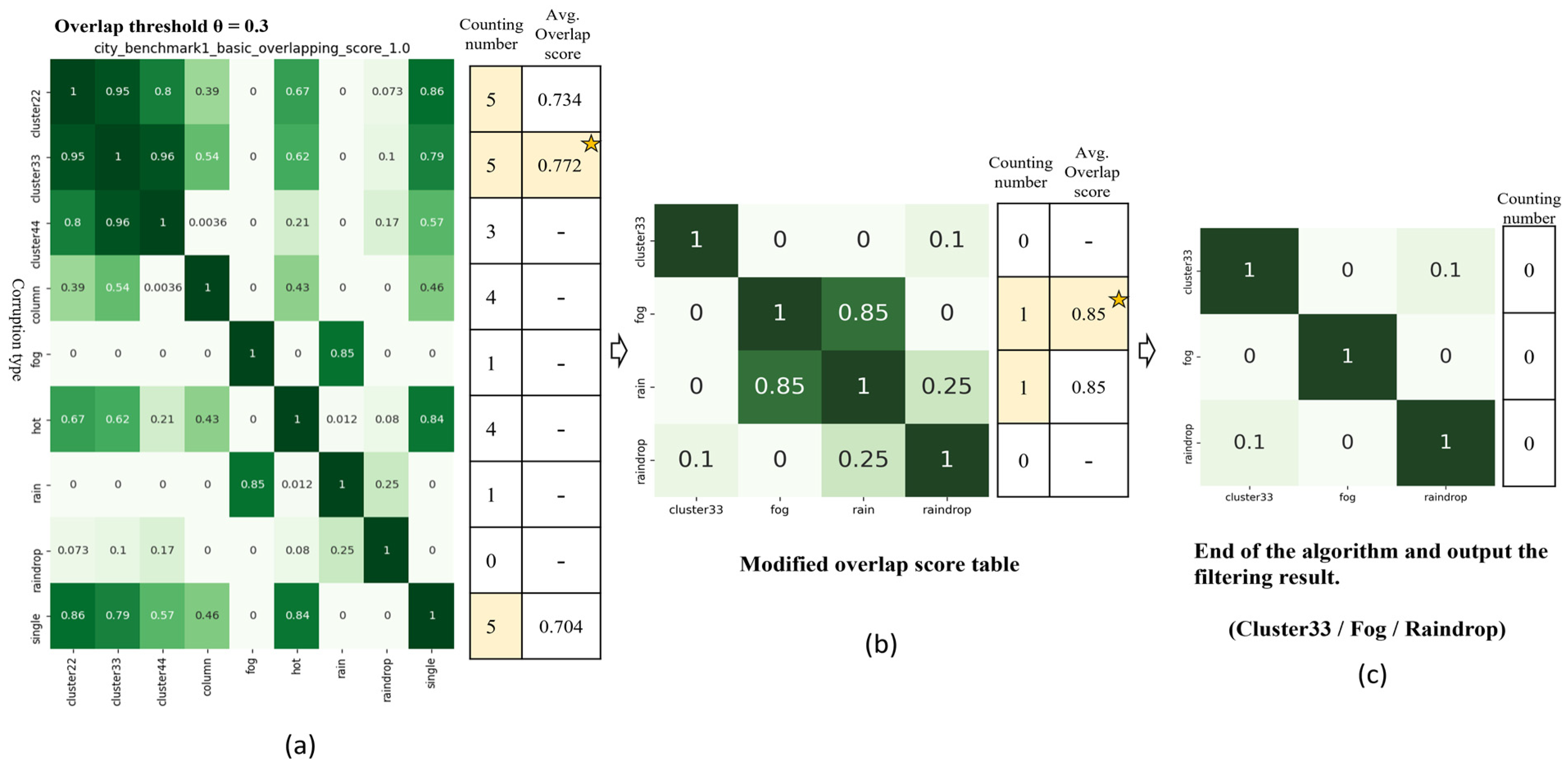
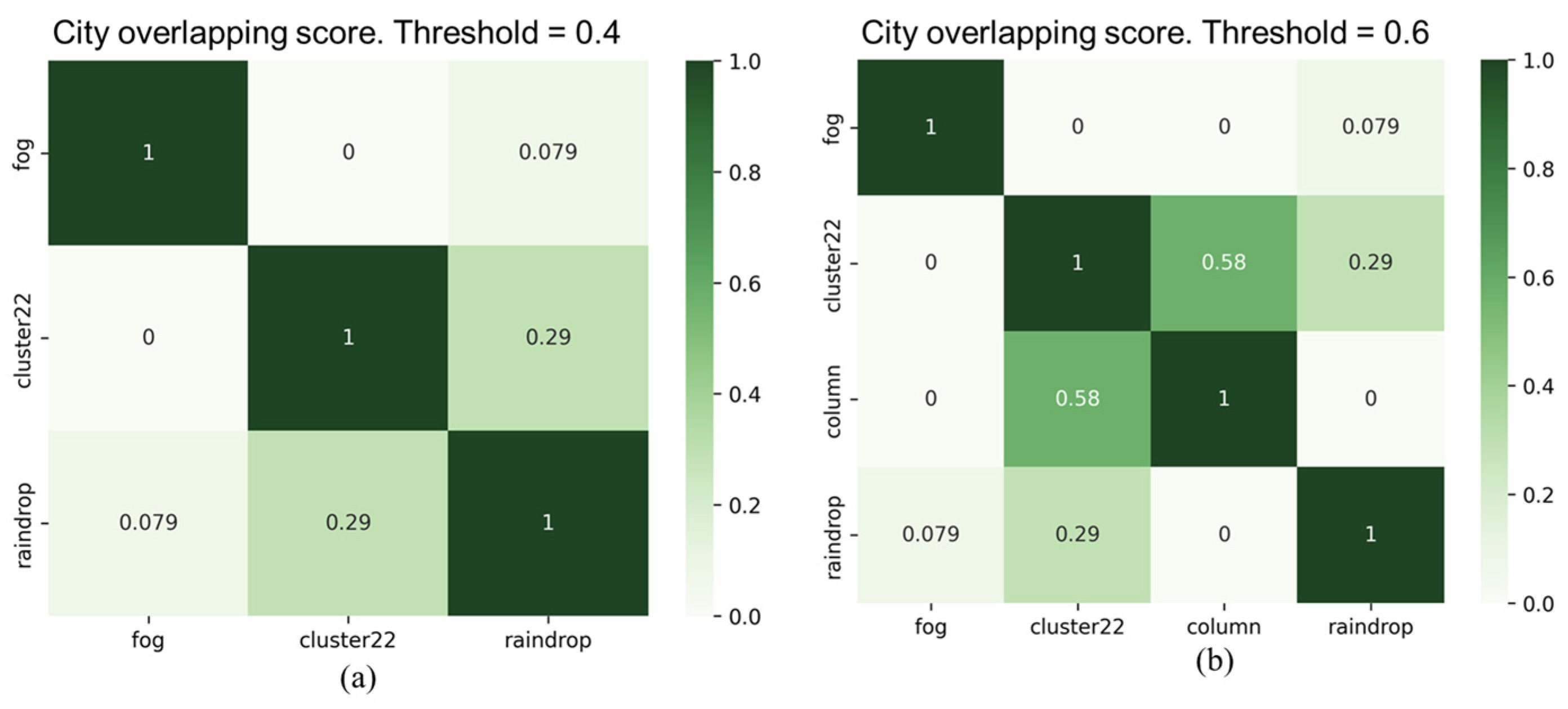
3.3. Safety-Related Corruption Similarity Filtering Algorithm
| Algorithm 1: Corruption Similarity Filtering Algorithm |
| Input: given a two-dimensional overlap score table OS(NC, NC) where NC is the number of corruptions and OS(i, j) represents the overlap score between corruption i and corruption j. Set up an overlap threshold θ to guide the filtering of corruptions from the overlap score table. Output: a subset of NC corruptions which will be used to form the benchmark dataset k ← NC
|
| Algorithm 2: Corruption Grouping Algorithm |
| Input: given a two-dimensional overlap score table OS(NC, NC) where NC is the number of corruptions and OS(i, j) represents the overlap score between corruption i and corruption j. Set up an overlap threshold θ. Output: corruption groups
|
3.4. Corruption Type Object Detection Model Enhancement Techniques
4. Experimental Results and Analysis
4.1. Corruption Types and Benchmark Dataset Generation
4.2. Corruption Type Selection
4.3. Model Corruption Type Vulnerability Analysis and Enhanced Training
- Dataset without any corruption.
- Dataset containing all corruption types with all severity regions.
- Dataset with three corruption types (F3) derived from the corruption filtering algorithm.
- Dataset with four corruption types (F4) derived from the corruption filtering algorithm.
- NEI: number of images contained in an enhancement dataset.
- NEC: number of enhancement corruption types.
- : the i-th enhancement corruption type, where i = 1 to NEC.
- : number of severity regions for enhancement corruption type i, where i is from 1 to NEC.
- : the j-th region of enhancement corruption type i, where j = 1 to NER(ECi).
- For each severity region , the number of reinforcement training images is denoted as NEI.
- IS: number of input images for each transfer learning step.
- ET: estimated time of required for transfer learning in second per step for object detection model.
- NE: the total number of epochs for model reinforcement transfer learning.
- MET: the training time required for object detection model reinforcement.
4.4. Robustness Analysis of Enhanced Training Models
4.5. Exploring Scenarios with Two Corruption Combinations
4.6. Real-World Scenario Testing and Verification
5. Conclusions and Future Works
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Min, K.; Han, S.; Lee, D.; Choi, D.; Sung, K.; Choi, J. SAE Level 3 Autonomous Driving Technology of the ETRI. In Proceedings of the 2019 International Conference on Information and Communication Technology Convergence (ICTC), Jeju Island, Republic of Korea, 16–18 October 2019; pp. 464–466. [Google Scholar]
- Klück, F.; Zimmermann, M.; Wotawa, F.; Nica, M. Genetic Algorithm-Based Test Parameter Optimization for ADAS System Testing. In Proceedings of the 2019 IEEE 19th International Conference on Software Quality, Reliability and Security (QRS), Sofia, Bulgaria, 22–26 July 2019; pp. 418–425. [Google Scholar]
- Koopman, P.; Wagner, M. Autonomous Vehicle Safety: An Interdisciplinary Challenge. IEEE Intell. Transp. Syst. Mag. 2017, 9, 90–96. [Google Scholar] [CrossRef]
- Pezzementi, Z.; Tabor, T.; Yim, S.; Chang, J.K.; Drozd, B.; Guttendorf, D.; Wagner, M.; Koopman, P. Putting Image Manipulations in Context: Robustness Testing for Safe Perception. In Proceedings of the 2018 IEEE International Symposium on Safety, Security, and Rescue Robotics (SSRR), Philadelphia, PA, USA, 6–8 August 2018; pp. 1–8. [Google Scholar]
- Bolte, J.; Bar, A.; Lipinski, D.; Fingscheidt, T. Towards Corner Case Detection for Autonomous Driving. In Proceedings of the 2019 IEEE Intelligent Vehicles Symposium (IV), Paris, France, 9–12 June 2019; pp. 438–445. [Google Scholar]
- VIRES Simulationstechnologie GmbH. VTD—VIRES Virtual Test Drive. 2022. Available online: https://www.embeddedindia.com/download/hexagon-vtd.PDF (accessed on 1 November 2023).
- CarMaker|IPG Automotive. Available online: https://ipg-automotive.com/en/products-solutions/software/carmaker/ (accessed on 11 October 2022).
- Dosovitskiy, A.; Ros, G.; Codevilla, F.; Lopez, A.; Koltun, V. CARLA: An Open Urban Driving Simulator. In Proceedings of the 1st Annual Conference on Robot Learning, Mountain View, CA, USA, 13–15 November 2017; pp. 1–16. [Google Scholar]
- International Organization for Standardization. ISO 26262; Road Vehicles–Functional Safety. International Organization for Standardization: Geneva, Switzerland, 2018. Available online: https://www.iso.org/obp/ui/#iso:std:iso:26262:-1:en (accessed on 1 November 2023).
- von Bernuth, A.; Volk, G.; Bringmann, O. Simulating Photo-Realistic Snow and Fog on Existing Images for Enhanced CNN Training and Evaluation. In Proceedings of the 2019 IEEE Intelligent Transportation Systems Conference (ITSC), Auckland, New Zealand, 27–30 October 2019; pp. 41–46. [Google Scholar]
- Caesar, H.; Bankiti, V.; Lang, A.H.; Vora, S.; Liong, V.E.; Xu, Q.; Krishnan, A.; Pan, Y.; Baldan, G.; Beijbom, O. nuScenes: A Multimodal Dataset for Autonomous Driving. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 11618–11628. [Google Scholar]
- Yu, F.; Chen, H.; Wang, X.; Xian, W.; Chen, Y.; Liu, F.; Madhavan, V.; Darrell, T. BDD100K: A Diverse Driving Dataset for Heterogeneous Multitask Learning. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 2633–2642. [Google Scholar]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The Cityscapes Dataset for Semantic Urban Scene Understanding. arXiv 2016, arXiv:1604.01685. [Google Scholar]
- Geiger, A.; Lenz, P.; Urtasun, R. Are We Ready for Autonomous Driving? The KITTI Vision Benchmark Suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar]
- Su, J.; Vargas, D.V.; Kouichi, S. One Pixel Attack for Fooling Deep Neural Networks. IEEE Trans. Evol. Comput. 2019, 23, 828–841. [Google Scholar] [CrossRef]
- Zofka, M.R.; Klemm, S.; Kuhnt, F.; Schamm, T.; Zöllner, J.M. Testing and Validating High Level Components for Automated Driving: Simulation Framework for Traffic Scenarios. In Proceedings of the 2016 IEEE Intelligent Vehicles Symposium (IV), Gotenburg, Sweden, 19–22 June 2016; pp. 144–150. [Google Scholar]
- Yu, H.; Li, X. Intelligent Corner Synthesis via Cycle-Consistent Generative Adversarial Networks for Efficient Validation of Autonomous Driving Systems. In Proceedings of the 2018 23rd Asia and South Pacific Design Automation Conference (ASP-DAC), Jeju Island, Republic of Korea, 22–25 January 2018; pp. 9–15. [Google Scholar]
- Muckenhuber, S.; Holzer, H.; Rübsam, J.; Stettinger, G. Object-Based Sensor Model for Virtual Testing of ADAS/AD Functions. In Proceedings of the 2019 IEEE International Conference on Connected Vehicles and Expo (ICCVE), Graz, Austria, 4–8 November 2019; pp. 1–6. [Google Scholar]
- Menzel, T.; Bagschik, G.; Isensee, L.; Schomburg, A.; Maurer, M. From Functional to Logical Scenarios: Detailing a Keyword-Based Scenario Description for Execution in a Simulation Environment. In Proceedings of the 2019 IEEE Intelligent Vehicles Symposium (IV), Paris, France, 9–12 June 2019; pp. 2383–2390. [Google Scholar]
- Zhu, H.; Ng, M.K. Structured Dictionary Learning for Image Denoising Under Mixed Gaussian and Impulse Noise. IEEE Trans. Image Process. 2020, 29, 6680–6693. [Google Scholar] [CrossRef] [PubMed]
- Wu, D.; Du, X.; Wang, K. An Effective Approach for Underwater Sonar Image Denoising Based on Sparse Representation. In Proceedings of the 2018 IEEE 3rd International Conference on Image, Vision and Computing (ICIVC), Chongqing, China, 27–29 June 2018; pp. 389–393. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image Quality Assessment: From Error Visibility to Structural Similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed]
- Horé, A.; Ziou, D. Image Quality Metrics: PSNR vs. SSIM. In Proceedings of the 2010 20th International Conference on Pattern Recognition, Istanbul, Turkey, 23–26 August 2010; pp. 2366–2369. [Google Scholar]
- Cord, A.; Gimonet, N. Detecting Unfocused Raindrops: In-Vehicle Multipurpose Cameras. IEEE Robot. Autom. Mag. 2014, 21, 49–56. [Google Scholar] [CrossRef]
- Qian, R.; Tan, R.T.; Yang, W.; Su, J.; Liu, J. Attentive Generative Adversarial Network for Raindrop Removal from a Single Image. arXiv 2018, arXiv:1711.10098. [Google Scholar]
- von Bernuth, A.; Volk, G.; Bringmann, O. Rendering Physically Correct Raindrops on Windshields for Robustness Verification of Camera-Based Object Recognition. In Proceedings of the 2018 IEEE Intelligent Vehicles Symposium (IV), Suzhou, China, 26–30 June 2018; pp. 922–927. [Google Scholar]
- Porav, H.; Musat, V.-N.; Bruls, T.; Newman, P. Rainy Screens: Collecting Rainy Datasets, Indoors. arXiv 2020, arXiv:2003.04742. [Google Scholar]
- Deter, D.; Wang, C.; Cook, A.; Perry, N.K. Simulating the Autonomous Future: A Look at Virtual Vehicle Environments and How to Validate Simulation Using Public Data Sets. IEEE Signal Process. Mag. 2021, 38, 111–121. [Google Scholar] [CrossRef]
- Johnson-Roberson, M.; Barto, C.; Mehta, R.; Sridhar, S.N.; Rosaen, K.; Vasudevan, R. Driving in the Matrix: Can Virtual Worlds Replace Human-Generated Annotations for Real World Tasks? In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 746–753. [Google Scholar]
- Gaidon, A.; Wang, Q.; Cabon, Y.; Vig, E. VirtualWorlds as Proxy for Multi-Object Tracking Analysis. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 4340–4349. [Google Scholar]
- Jin, J.; Fatemi, A.; Pinto Lira, W.M.; Yu, F.; Leng, B.; Ma, R.; Mahdavi-Amiri, A.; Zhang, H. RaidaR: A Rich Annotated Image Dataset of Rainy Street Scenes. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW), Montreal, BC, Canada, 11–17 October 2021; pp. 2951–2961. [Google Scholar]
- Hendrycks, D.; Dietterich, T. Benchmarking Neural Network Robustness to Common Corruptions and Perturbations. arXiv 2019, arXiv:1903.12261. [Google Scholar]
- Muhammad, K.; Ullah, A.; Lloret, J.; Ser, J.D.; de Albuquerque, V.H.C. Deep Learning for Safe Autonomous Driving: Current Challenges and Future Directions. IEEE Trans. Intell. Transp. Syst. 2021, 22, 4316–4336. [Google Scholar] [CrossRef]
- Nowruzi, F.E.; Kapoor, P.; Kolhatkar, D.; Hassanat, F.A.; Laganiere, R.; Rebut, J. How Much Real Data Do We Actually Need: Analyzing Object Detection Performance Using Synthetic and Real Data. arXiv 2019, arXiv:1907.07061. [Google Scholar]
- Marzuki, M.; Randeu, W.L.; Schönhuber, M.; Bringi, V.N.; Kozu, T.; Shimomai, T. Raindrop Size Distribution Parameters of Distrometer Data With Different Bin Sizes. IEEE Trans. Geosci. Remote Sens. 2010, 48, 3075–3080. [Google Scholar] [CrossRef]
- Serio, M.A.; Carollo, F.G.; Ferro, V. Raindrop Size Distribution and Terminal Velocity for Rainfall Erosivity Studies. A Review. J. Hydrol. 2019, 576, 210–228. [Google Scholar] [CrossRef]
- Roser, M.; Kurz, J.; Geiger, A. Realistic Modeling of Water Droplets for Monocular Adherent Raindrop Recognition Using Bézier Curves. In Proceedings of the Computer Vision—ACCV 2010 Workshops, Queenstown, New Zealand, 8–9 November 2019; Koch, R., Huang, F., Eds.; Springer: Berlin/Heidelberg, Germany, 2011; pp. 235–244. [Google Scholar]
- Huang, W.; Lv, Y.; Chen, L.; Zhu, F. Accelerate the Autonomous Vehicles Reliability Testing in Parallel Paradigm. In Proceedings of the 2017 IEEE 20th International Conference on Intelligent Transportation Systems (ITSC), Yokohama, Japan, 16–19 October 2017; pp. 922–927. [Google Scholar]
- Laugros, A.; Caplier, A.; Ospici, M. Using the Overlapping Score to Improve Corruption Benchmarks. In Proceedings of the 2021 IEEE International Conference on Image Processing (ICIP), Anchorage, AK, USA, 19–22 September 2021; pp. 959–963. [Google Scholar]
- Kenk, M.A.; Hassaballah, M. DAWN: Vehicle Detection in Adverse Weather Nature Dataset. arXiv 2020, arXiv:2008.05402. [Google Scholar]
- Sakaridis, C.; Dai, D.; Van Gool, L. Semantic Foggy Scene Understanding with Synthetic Data. Int. J. Comput. Vis. 2018, 126, 973–992. [Google Scholar] [CrossRef]
- Poucin, F.; Kraus, A.; Simon, M. Boosting Instance Segmentation with Synthetic Data: A Study to Overcome the Limits of Real World Data Sets. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 945–953. [Google Scholar]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | No. Severity Region (Rn) | R1 | R2 | R3 | R4 | R5 |
|---|---|---|---|---|---|---|
| Fog Visibility (m) | 5 | 200~164 | 164~128 | 128~92 | 92~56 | 56~20 |
| Rain mm/h | 2 | 43~48 | 48~55 | - | - | - |
| Type | Severity Region | No. Subsections (STn) | ST1 | ST2 | ST3 | ST4 | ST5 |
|---|---|---|---|---|---|---|---|
| Fog Visibility (m) | R1 | 5 | 200 | 191 | 182 | 173 | 164 |
| Rain mm/h | R1 | 5 | 43 | 44.25 | 45.5 | 46.75 | 48 |
| Precipitation Type | Precipitation Intensity | Visibility (m) | Time of Day in Second | Cloud State |
|---|---|---|---|---|
| None, Rain, Snow | 0.0~1.0 | 0~100,000 | 0~86,400 | Off: Sky off/0: Blue sky/4: Cloudy/6: Overcast/8:Rainy |
| Type | Number of Severity Region (Rn) | R1 | R2 |
|---|---|---|---|
| Rain mm/h | 2 | 43~48 mm/h | 48~55 mm/h |
| Visibility ≈ 300~200 m | Visibility ≈ 200~100 m |
| Raindrop | 2 µL | 5 µL | 10 µL | 15 µL | 20 µL |
|---|---|---|---|---|---|
| Volume | >0 & <5 | ≥5 & <10 | ≥10 & <15 | ≥15 & <20 | ≥20 & <91 |
| Original Corruption Type Test Dataset | Filtered Corruption Types Test Dataset | (Fog, Rain) Test Dataset | (Hot, Single, Cluster 22, 33, 44) Test Dataset | |
|---|---|---|---|---|
| Model trained by filtered corruption types | A | B | E | F |
| Model trained by original corruption types | C | D | G | H |
| City 2 Corruptions | Fog | Cluster 22 |
|---|---|---|
| Vulnerability region | Visibility 50~20 m | Percentage 13~15% |
| SR1 | (50 + 35)/2 = 42.5 m | (13 + 14)/2 = 13.5% |
| SR2 | (35 + 20)/2 = 27.5 m | (14 + 15)/2 = 14.5% |
| B1 (AP) | B2 (AP) | |
|---|---|---|
| Model-Clean | E-0-1 | E-0-2 |
| Model-B1 (Single corruption) | E-1-1 | E-1-2 |
| Model-B2 (Two corruptions) | E-2-1 | E-2-2 |
| Model-Original | E-A-1 | E-A-2 |
| Type | Corruption Type | NER | Factor | R1 | R2 | R3 | R4 | R5 |
|---|---|---|---|---|---|---|---|---|
| Clean | C0 | 1 | Clean | Non-corruption | ||||
| Weather Relative (WR) | C1 | 5 | Fog Visibility (m) | 200~164 | 164~128 | 128~92 | 92~56 | 56~20 |
| C2 | 2 | Rain | 43~48.7 mm/h Vis.: 300 m−200 m | 48.7~54.8 mm/h Vis.: 200 m−100 m | − | − | − | |
| Noise Relative (NR) | C3 | 3 | Hot | 1~5% | 5~10% | 10~15% | − | − |
| C4 | 3 | Single | 1~5% | 5~10% | 10~15% | − | − | |
| C5 | 3 | Cluster 44 | 1~5% | 5~10% | 10~15% | − | − | |
| C6 | 3 | Cluster 33 | 1~5% | 5~10% | 10~15% | − | − | |
| C7 | 3 | Cluster 22 | 1~5% | 5~10% | 10~15% | − | − | |
| C8 | 3 | Column | 1~5% | 5~10% | 10~15% | − | − | |
| C9 | 2 | Raindrop | 20~35 mm/h D 0.183~0.207 cm | 35~50 mm/h D 0.207~0.229 cm | − | − | − | |
| Type | Corruption Type | NSL | Factor | Severity Level |
|---|---|---|---|---|
| Clean | 1 | Clean | Non-corruption | |
| Weather Relative (WR) | C1 | 7 | Fog | 20 m, 50 m, 80 m, 110 m, 140 m, 170 m, 200 m |
| C2 | 3 | Rain | 43 mm/h, 48.7 mm/h, 54.8 mm/h | |
| Noise Relative (NR) | C3 | 8 | Hot | 1%, 3%, 5%, 7%, 9%, 11%, 13%, 15% |
| C4 | 8 | Single | 1%, 3%, 5%, 7%, 9%, 11%, 13%, 15% | |
| C5 | 8 | Cluster 44 | 1%, 3%, 5%, 7%, 9%, 11%, 13%, 15% | |
| C6 | 8 | Cluster 33 | 1%, 3%, 5%, 7%, 9%, 11%, 13%, 15% | |
| C7 | 8 | Cluster 22 | 1%, 3%, 5%, 7%, 9%, 11%, 13%, 15% | |
| C8 | 8 | Column | 1%, 3%, 5%, 7%, 9%, 11%, 13%, 15% | |
| C9 | 3 | Raindrop | 20 mm_d0183, 35 mm_d0207, 50 mm_d0229 |
| Fog | Column | Cluster 22 | Raindrop | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Visibility | AP50 | Slope | Percent | AP50 | Slope | Percent | AP50 | Slope | Precipitation | AP50 | Slope |
| City Scenario | |||||||||||
| 200 m | 75.53 | - | 1% | 77.99 | - | 1% | 77.79 | - | 20 mm/h | 66.85 | - |
| 170 m | 73.93 | −0.05 | 2% | 77.11 | −0.44 | 2% | 76.70 | −0.54 | 35 mm/h | 63.41 | −0.229 |
| 140 m | 70.49 | −0.11 | 5% | 75.22 | −0.95 | 5% | 75.47 | −0.62 | 50 mm/h | 61.11 | −0.153 |
| 110 m | 64.30 | −0.21 | 7% | 74.10 | −0.56 | 7% | 73.26 | −1.10 | |||
| 80 m | 56.98 | −0.24 | 9% | 73.92 | −0.09 | 9% | 70.28 | −1.49 | |||
| 50 m | 43.66 | −0.44 | 11% | 72.91 | −0.50 | 11% | 67.18 | −1.55 | |||
| 20 m | 6.86 | −1.23 | 13% | 72.34 | −0.28 | 13% | 62.57 | −2.31 | Clean | ||
| 15% | 69.80 | −1.27 | 15% | 56.07 | −3.25 | 78.27 | |||||
| Highway Scenario | |||||||||||
| 200 m | 88.48 | - | 1% | 92.74 | - | 1% | 93.28 | - | 20 mm/h | 83.43 | - |
| 170 m | 84.39 | −0.14 | 2% | 90.52 | −1.11 | 2% | 90.99 | −1.15 | 35 mm/h | 82.12 | −0.087 |
| 140 m | 82.28 | −0.07 | 5% | 90.54 | 0.01 | 5% | 88.64 | −1.17 | 50 mm/h | 81.06 | −0.071 |
| 110 m | 77.29 | −0.17 | 7% | 89.94 | −0.30 | 7% | 86.44 | −1.10 | |||
| 80 m | 69.73 | −0.25 | 9% | 88.00 | −0.97 | 9% | 84.09 | −1.18 | |||
| 50 m | 58.83 | −0.36 | 11% | 87.31 | −0.34 | 11% | 81.75 | −1.17 | |||
| 20 m | 39.42 | −0.65 | 13% | 87.11 | −0.10 | 13% | 79.41 | −1.17 | Clean | ||
| 15% | 86.19 | −0.46 | 15% | 74.40 | −2.50 | 93.11 | |||||
| City & Highway M1-Clean | Clean | Total Images | Training Time (hours) | ||||
| 3840 | 1.173 | ||||||
| City & Highway M1-All | Clean, Fog, Rain, Hot, Single, Cluster 44, Cluster 33, Cluster 22, Column, Raindrop (All Severity Range) | 238,080 | 72.75 | ||||
| City_M1-B1F3 & Highway_M1-B1F3 (Threshold 0.4/3 Corruptions) | Clean | Fog | Cluster 22 | Raindrop | 15,360 | 4.69 | |
| Visibility 50~20 m | Percentage 13~15% | Rainfall: 20~35 mm/h Raindrop diameter: 0.183~0.207 cm | |||||
| City_M1-B1F4 (Threshold 0.6/4 Corruptions) | Clean | Fog | Cluster 22 | Raindrop | Column | 19,200 | 5.87 |
| Visibility 50~20 m | Percentage 13~15% | Rainfall: 20~35 mm/h Raindrop diameter: 0.183~0.207 cm | Percentage 13~15% | ||||
| Highway_M1-B1F4 (Threshold 0.5/4 Corruptions) | Clean | Fog | Cluster 22 | Raindrop | Column | 19,200 | 5.87 |
| Visibility 50~20 m | Percentage 13~15% | Rainfall: 20~35 mm/h Raindrop diameter: 0.183~0.207 cm | Percentage 1~3% | ||||
| All Corruption Type Test Dataset | Test Dataset (Clean, Fog, Cluster 22, Raindrop) | Test Dataset (Clean, Fog, Rain) | Test Dataset (Hot, Single, Cluster 22/33/44) | ||
|---|---|---|---|---|---|
| (a) | City_M1-B1F3 | 75.80 | 75.24 | 72.51 | 77.41 |
| City_M1-All | 75.06 | 74.14 | 72.52 | 76.38 | |
| (b) | Highway_M1-B1F3 | 89.38 | 89.64 | 89.74 | 90.03 |
| Highway_M1-All | 88.55 | 88.48 | 89.19 | 89.22 |
| All Corruption Type Test Dataset | Test Dataset (Clean, Fog, Cluster 22, Raindrop, Column) | Test Dataset (Clean, Fog, Rain) | Test Dataset (Hot, Single, Cluster 22/33/44) | ||
|---|---|---|---|---|---|
| (a) | City_M1-B1F4 | 75.81 | 74.74 | 72.47 | 77.49 |
| City_M1-All | 75.06 | 74.11 | 72.52 | 76.38 | |
| (b) | Highway_M1-B1F4 | 89.54 | 89.89 | 89.42 | 90.41 |
| Highway_M1-All | 88.55 | 88.55 | 89.19 | 89.22 |
| City_M1-B2F3 & Highway_M1-B2F3 (Threshold 0.4/3 Factors) | Clean | Fog | Cluster 22 | Raindrop | ||
| Visibility 50~20 m | Percentage 13~15% | Rainfall: 20~35 mm/h | ||||
| SR1 | − | 42.5 m | 13.5% | 23.8 mm/h | ||
| SR2 | − | 27.5 m | 14.5% | 31.3 mm/h | ||
| Clean | Fog & Cluster 22 | Fog & Raindrop | Cluster 22 & Raindrop | |||
| (42.5 m, 13.5%) | (27.5 m, 14.5%) | (42.5 m, 23.8 mm/h) | (27.5 m, 31.3 mm/h) | (13.5%, 23.8 mm/h) | (14.5%, 31.3 mm/h) | |
| B1 Single Factor Test Dataset (Clean, Fog, Cluster 22, Raindrop) | B2 Two Factors Test Dataset (Clean, Fog & Cluster 22, Fog & Raindrop, Cluster 22 & Raindrop) | ||
|---|---|---|---|
| (a) | City_M1-Clean | 68.34 | 40.78 |
| City_M1-All | 74.14 | 57.00 | |
| City_M1-B1F3 (Single corruption) | 75.24 | 54.67 | |
| City_M1-B2F3 (Two corruptions) | 74.05 | 59.70 | |
| (b) | Highway_M1-Clean | 82.66 | 61.43 |
| Highway_M1-All | 88.48 | 69.20 | |
| Highway_M1-B1F3 (Single corruption) | 89.64 | 67.48 | |
| Highway_M1-B2F3 (Two corruptions) | 86.11 | 72.29 |
| (a) | (b) | |||||||
|---|---|---|---|---|---|---|---|---|
| City_ M1–Clean | City_ M1–B1F3 | City_M1- Clean_R800_ Daytime Clear | City_M1- B1F3_R800_ Daytime Clear | Highway_ M1-Clean | Highway_M1-B1F3 | Highway_ M1-Clean_R800_ Daytime Clear | Highway_ M1-B1F3_R800_ Daytime Clear | |
| DAWN Foggy/haze/mist/ rain–storm (total 491 images) | 44.22 | 45.77 | 52.76 | 56.64 | 43 | 46.75 | 50.3 | 54 |
| Foggy Cityscapes Beta_008 (total 2831 images) | 14.21 | 15.33 | 16.01 | 18.09 | 11.36 | 14.04 | 15.25 | 17.29 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hsiang, H.; Chen, Y.-Y. Development of an Effective Corruption-Related Scenario-Based Testing Approach for Robustness Verification and Enhancement of Perception Systems in Autonomous Driving. Sensors 2024, 24, 301. https://doi.org/10.3390/s24010301
Hsiang H, Chen Y-Y. Development of an Effective Corruption-Related Scenario-Based Testing Approach for Robustness Verification and Enhancement of Perception Systems in Autonomous Driving. Sensors. 2024; 24(1):301. https://doi.org/10.3390/s24010301
Chicago/Turabian StyleHsiang, Huang, and Yung-Yuan Chen. 2024. "Development of an Effective Corruption-Related Scenario-Based Testing Approach for Robustness Verification and Enhancement of Perception Systems in Autonomous Driving" Sensors 24, no. 1: 301. https://doi.org/10.3390/s24010301