
A Binocular Vision-Based Crack Detection and Measurement Method Incorporating Semantic Segmentation

Abstract
:1. Introduction
2. Methodology
2.1. Overview
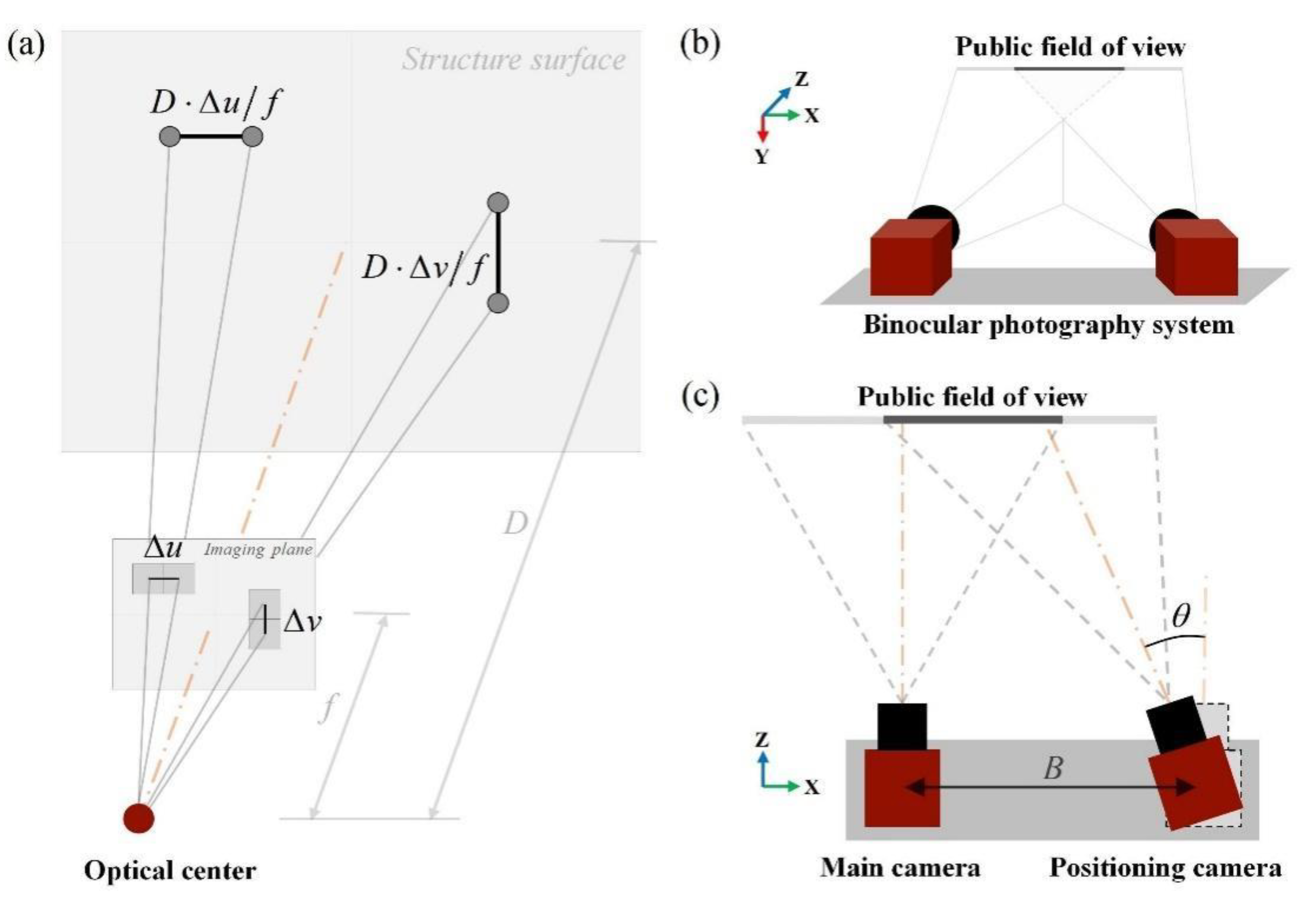
2.2. Crack Data Acquisition
2.3. Crack Pixel-Level Detection
2.3.1. FCN for Crack Segmentation
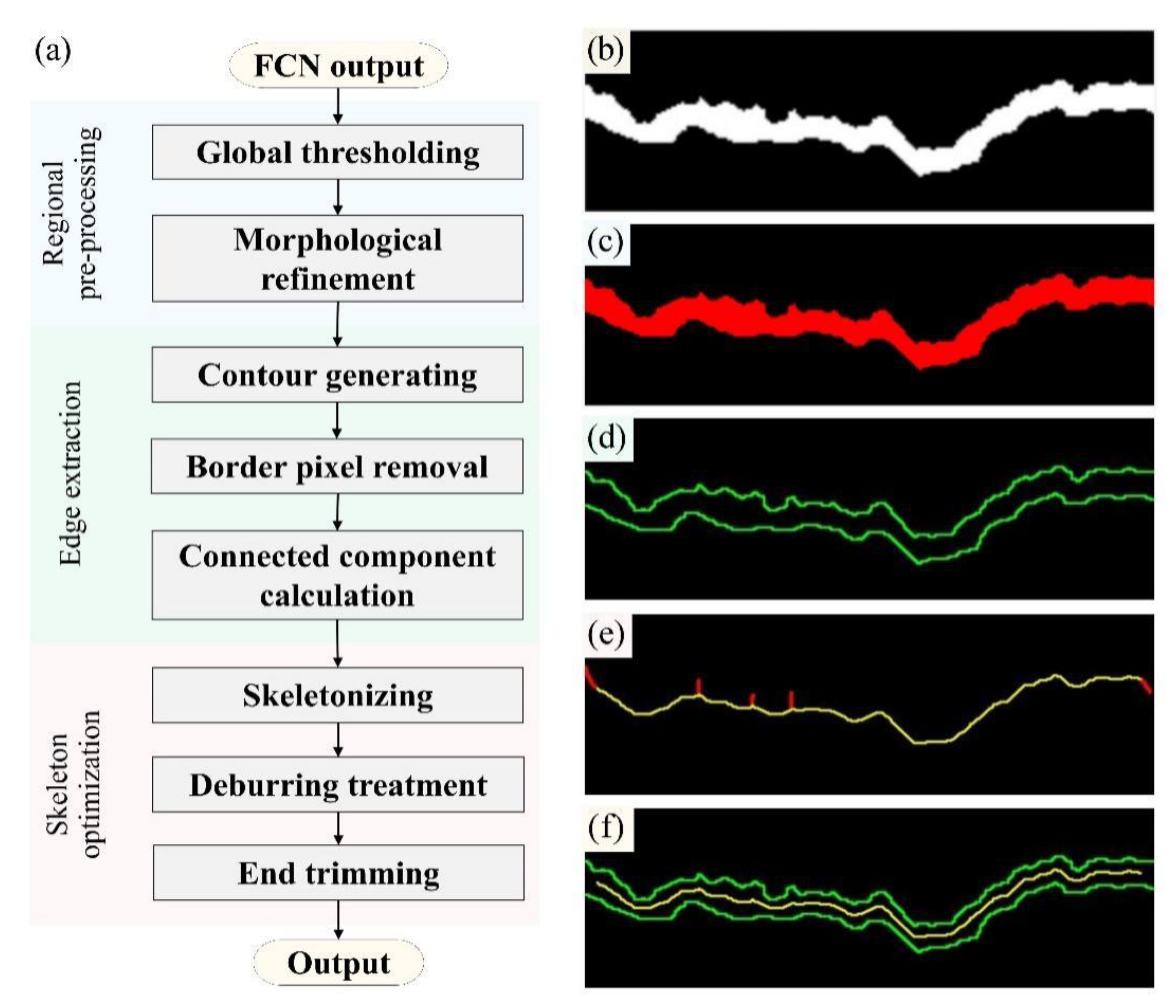
2.3.2. Extraction of Crack Edges and Skeletons
2.4. Crack Quantitative Assessment
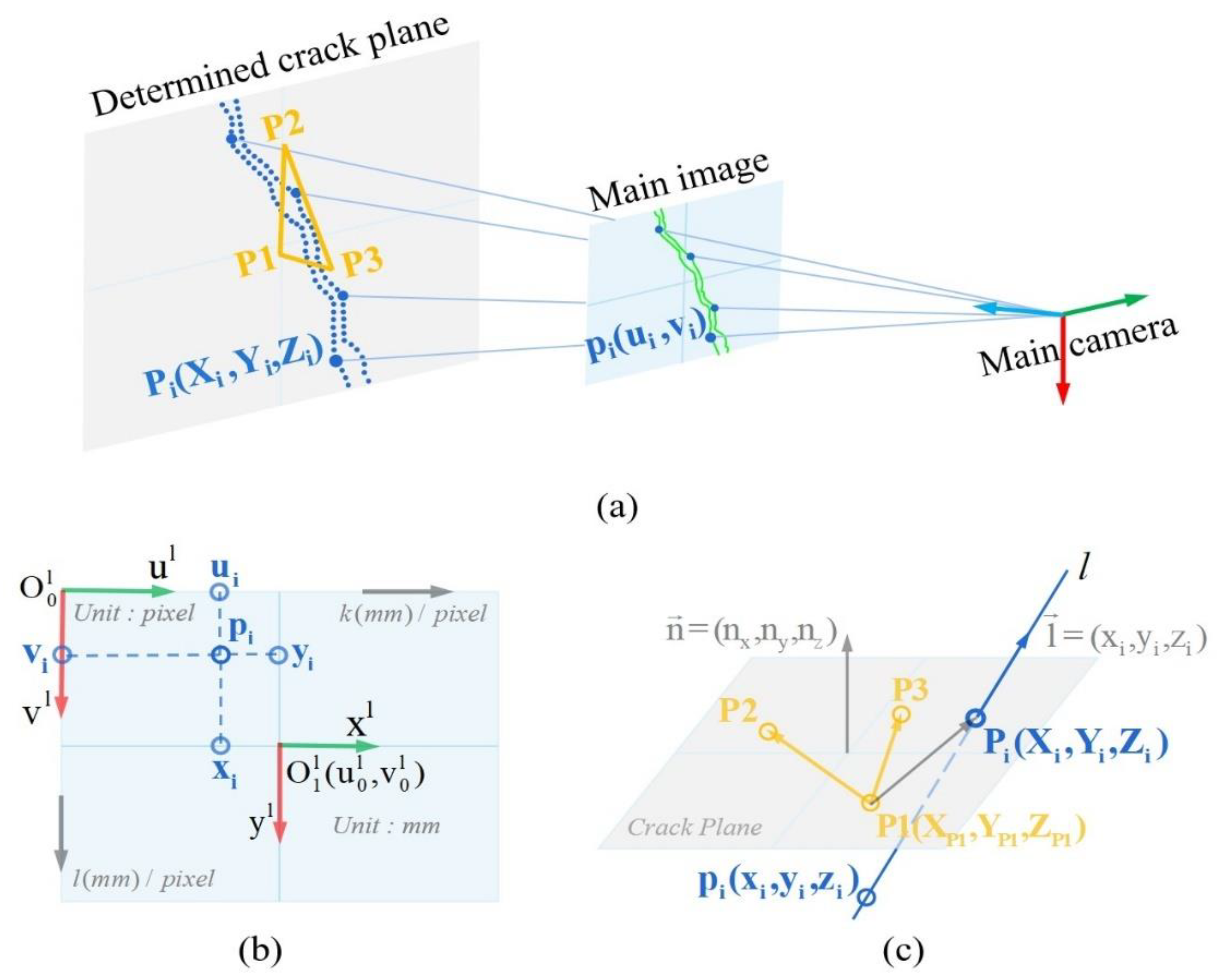
2.4.1. Binocular Vision for Crack Location
2.4.2. Central Projection for Crack Reconstruction
3. Training FCN
3.1. Crack Segmentation Database
3.2. Implementation Parameters
3.3. Model Initialization and Evaluation Metrics
- True Positive (crack pixels classified as crack pixels);
- False Negative (crack pixels classified as background pixels);
- False Positive (background pixels classified as crack pixels);
- True Negative (background pixels classified as background pixels).
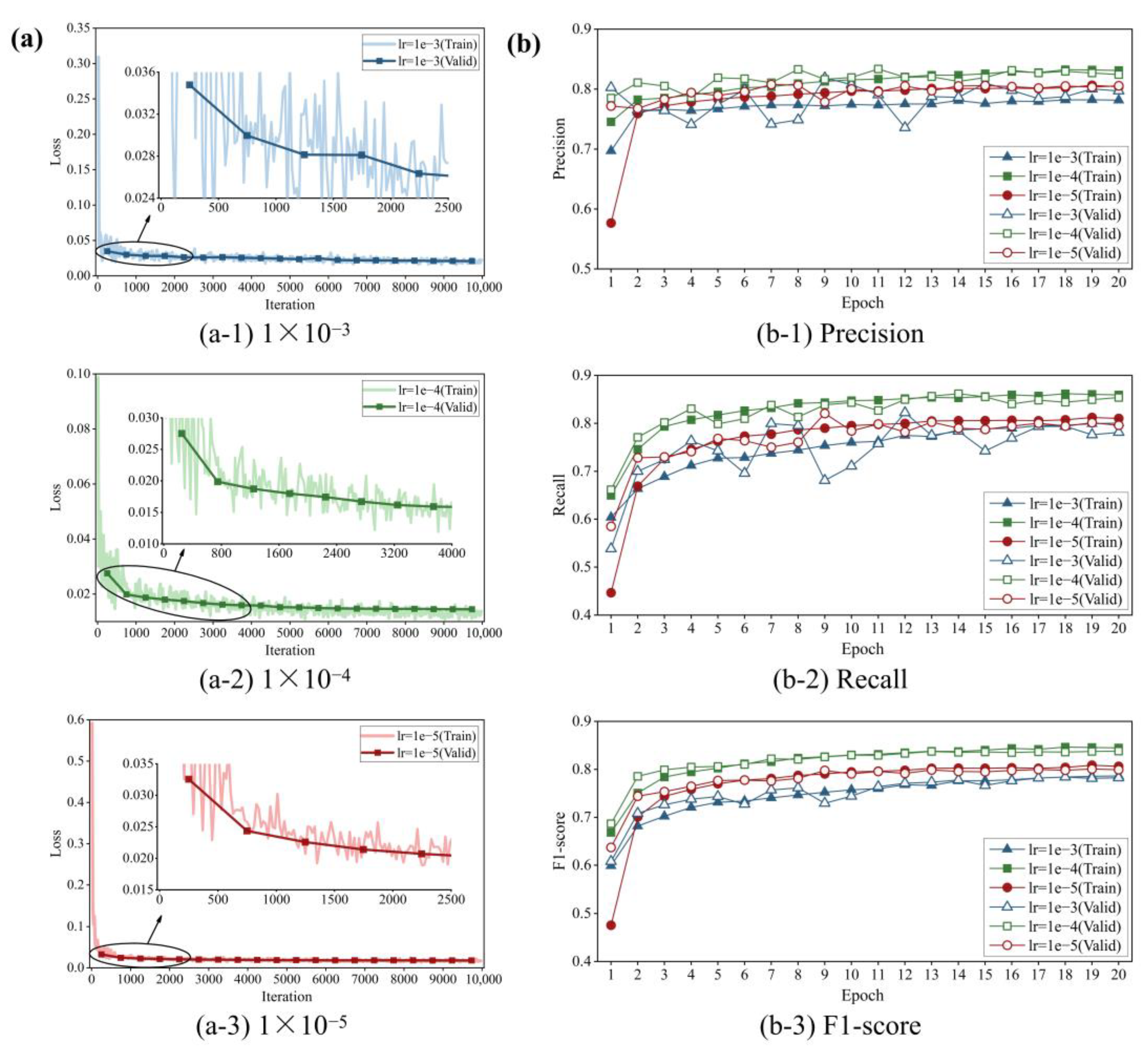
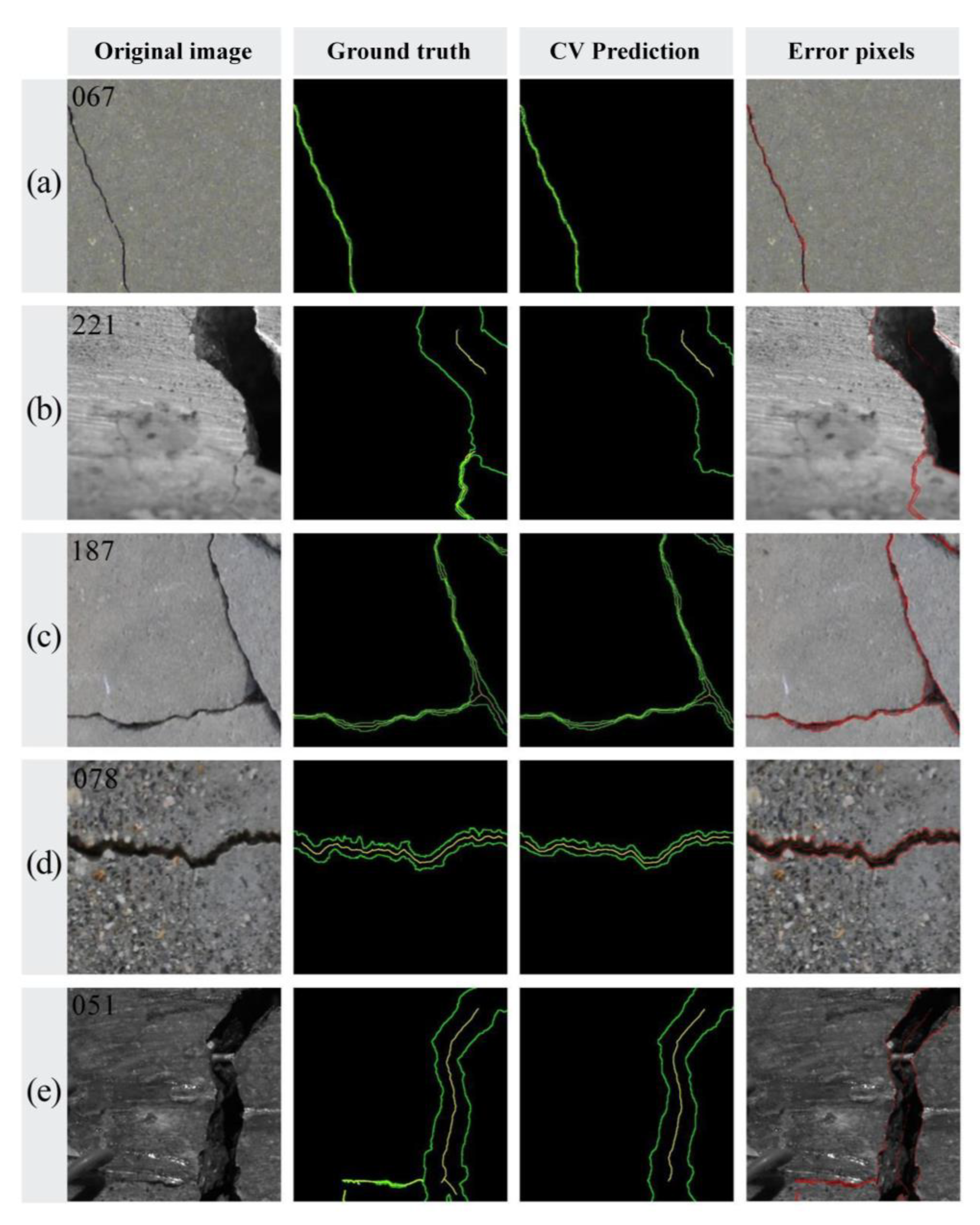
3.4. Training Results and Discussion
4. Experiment
5. Conclusions and Discussion
- To fit the ground truth to the fullest extent, the proposed FCN adopts the encoder–decoder structure and skip connections to enable enhanced focus on details during crack segmentation. The optimal FCN model is fine-tuned using a training dataset consisting of 1108 concrete surface images with a resolution of 448 × 448 pixels, resulting in satisfactory levels for all three evaluation metrics: precision at 83.85%, recall at 85.74% and F1 score at 84.14%. These results demonstrate that the proposed FCN can accurately detect cracks at the pixel level. Since a plate is a commonly used substructure in civil engineering, an experiment of a steel plate is carried out to validate the feasibility of the proposed methodology.
- An integrated CV procedure is specifically designed to extract the edges and skeletons of cracks from binary graphs predicted by FCN, with the aim of preparing data for crack measurements. The performance of the CV procedure is subsequently assessed on FCN predictions of various types of cracks in the test set, demonstrating that its output is both acceptable and effective. Moreover, skeletonization results exhibit a higher level of adherence to the actual crack topology in regions that are distant from the image boundary.
- The proposed method is applied to quantitatively evaluate the cracking of concrete specimens in real-life scenarios, with a comparison made against manual inspection results. The experimental results demonstrate that our FCN possesses remarkable generalization capability, and the binocular measurement method can also control errors at a low level, thereby ensuring both robustness in detection and accuracy in measurement. For crack width, the maximum error is 0.144 mm, while the mean relative error stands at 5.03%, thus confirming the feasibility of the proposed method.
- The experiment also involves an overhead shot of a target crack through the binocular photography system. The calculated error of −0.041 mm, along with its corresponding relative error of −0.8%, validates the high level of accuracy achieved by the binocular vision-based measurement method even under tilted shooting conditions, emphasizing its superiority over the monocular vision method and making it more suitable for implementation on remotely operated piggyback platforms, such as UAVs or robots.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Kayondo, M.; Combrinck, R.; Boshoff, W.P. State-of-the-art review on plastic cracking of concrete. Constr. Build. Mater. 2019, 225, 886–899. [Google Scholar] [CrossRef]
- Wang, H.L.; Dai, J.G.; Sun, X.Y.; Zhang, X.L. Characteristics of concrete cracks and their influence on chloride penetration. Constr. Build. Mater. 2016, 107, 216–225. [Google Scholar] [CrossRef]
- Zhang, H.; Zhou, Y.H.; Quan, L.W. Identification of a moving mass on a beam bridge using piezoelectric sensor arrays. J. Sound. Vib. 2021, 491, 115754. [Google Scholar] [CrossRef]
- Aboudi, J. Stiffness Reduction of Cracked Solids. Eng. Fract. Mech. 1987, 26, 637–650. [Google Scholar] [CrossRef]
- Chupanit, P.; Roesler, J.R. Fracture energy approach to characterize concrete crack surface roughness and shear stiffness. J. Mater. Civil. Eng. 2008, 20, 275–282. [Google Scholar] [CrossRef]
- Güllü, H.; Canakci, H.; Alhashemy, A. Use of ranking measure for performance assessment of correlations for the compression index. Eur. J. Environ. Civ. Eng. 2018, 22, 578–595. [Google Scholar] [CrossRef]
- Güllü, H.; Canakci, H.; Alhashemy, A. A Ranking Distance Analysis for Performance Assessment of UCS Versus SPT-N Correlations. Arab. J. Sci. Eng. 2019, 44, 4325–4337. [Google Scholar] [CrossRef]
- Jahanshahi, M.R.; Kelly, J.S.; Masri, S.F.; Sukhatme, G.S. A survey and evaluation of promising approaches for automatic image-based defect detection of bridge structures. Struct. Infrastruct. Eng. 2009, 5, 455–486. [Google Scholar] [CrossRef]
- Jiang, W.B.; Liu, M.; Peng, Y.N.; Wu, L.H.; Wang, Y.N. HDCB-Net: A Neural Network With the Hybrid Dilated Convolution for Pixel-Level Crack Detection on Concrete Bridges. IEEE Trans. Ind. Inform. 2021, 17, 5485–5494. [Google Scholar] [CrossRef]
- Zhang, H.; Zhou, Y.H.; Huang, Z.Y.; Shen, R.H.; Wu, Y.D. Multiparameter Identification of Bridge Cables Using XGBoost Algorithm. J. Bridge Eng. 2023, 28. [Google Scholar] [CrossRef]
- Huston, D.; Hu, J.Q.; Maser, K.; Weedon, W.; Adam, C. GIMA ground penetrating radar system for monitoring concrete bridge decks. J. Appl. Geophys. 2000, 43, 139–146. [Google Scholar] [CrossRef]
- Chen, S.-E.; Liu, W.; Bian, H.; Smith, B. 3D LiDAR Scans for Bridge Damage Evaluations. In Forensic Engineering 2012; ASCE Library: New York, NY, USA, 2013; pp. 487–495. [Google Scholar] [CrossRef]
- Valenca, J.; Puente, I.; Julio, E.; Gonzalez-Jorge, H.; Arias-Sanchez, P. Assessment of cracks on concrete bridges using image processing supported by laser scanning survey. Constr. Build. Mater. 2017, 146, 668–678. [Google Scholar] [CrossRef]
- Zhang, B.N.; Zhou, Z.X.; Zhang, K.H.; Yan, G.; Xu, Z.Z. Sensitive skin and the relative sensing system for real-time surface monitoring of crack in civil infrastructure. J. Intell. Mater. Syst. Struct. 2006, 17, 907–917. [Google Scholar] [CrossRef]
- Hurlebaus, S.; Gaul, L. Smart layer for damage diagnostics. J. Intell. Mater. Syst. Struct. 2004, 15, 729–736. [Google Scholar] [CrossRef]
- Roopa, A.K.; Hunashyal, A.M.; Mysore, R.R.M. Development and Implementation of Cement-Based Nanocomposite Sensors for Structural Health Monitoring Applications: Laboratory Investigations and Way Forward. Sustainability 2022, 14, 12452. [Google Scholar] [CrossRef]
- Dorafshan, S.; Thomas, R.J.; Maguire, M. Comparison of deep convolutional neural networks and edge detectors for image-based crack detection in concrete. Constr. Build. Mater. 2018, 186, 1031–1045. [Google Scholar] [CrossRef]
- Zhang, H.; Zhou, Y. AI-Based Modeling and Data-Driven Identification of Moving Load on Continuous Beams. Fundam. Res. 2022, 3, 796–803. [Google Scholar] [CrossRef]
- Yeum, C.M.; Dyke, S.J. Vision-Based Automated Crack Detection for Bridge Inspection. Comput.-Aided Civ. Infrastruct. Eng. 2015, 30, 759–770. [Google Scholar] [CrossRef]
- Oh, J.K.; Jang, G.; Oh, S.; Lee, J.H.; Yi, B.J.; Moon, Y.S.; Lee, J.S.; Choi, Y. Bridge inspection robot system with machine vision. Autom. Constr. 2009, 18, 929–941. [Google Scholar] [CrossRef]
- Iyer, S.; Sinha, S.K. A robust approach for automatic detection and segmentation of cracks in underground pipeline images. Image Vis. Comput. 2005, 23, 921–933. [Google Scholar] [CrossRef]
- Fujita, Y.; Hamamoto, Y. A robust automatic crack detection method from noisy concrete surfaces. Mach. Vis. Appl. 2011, 22, 245–254. [Google Scholar] [CrossRef]
- Lee, B.Y.; Kim, Y.Y.; Yi, S.T.; Kim, J.K. Automated image processing technique for detecting and analysing concrete surface cracks. Struct. Infrastruct. Eng. 2013, 9, 567–577. [Google Scholar] [CrossRef]
- Zhang, H.; Shen, M.Z.; Zhang, Y.Y.; Chen, Y.S.; Lu, C.F. Identification of Static Loading Conditions Using Piezoelectric Sensor Arrays. J. Appl. Mech. 2018, 85, 011008. [Google Scholar] [CrossRef]
- Nguyen, H.N.; Kam, T.Y.; Cheng, P.Y. An Automatic Approach for Accurate Edge Detection of Concrete Crack Utilizing 2D Geometric Features of Crack. J. Signal Process. Syst. 2014, 77, 221–240. [Google Scholar] [CrossRef]
- Sohn, H.G.; Lim, Y.M.; Yun, K.H.; Kim, G.H. Monitoring crack changes in concrete structures. Comput.-Aided Civ. Infrastruct. Eng. 2005, 20, 52–61. [Google Scholar] [CrossRef]
- Ni, T.Y.; Zhou, R.X.; Gu, C.P.; Yang, Y. Measurement of concrete crack feature with android smartphone APP based on digital image processing techniques. Measurement 2020, 150, 107093. [Google Scholar] [CrossRef]
- Abdel-Qader, L.; Abudayyeh, O.; Kelly, M.E. Analysis of edge-detection techniques for crack identification in bridges. J. Comput. Civ. Eng. 2003, 17, 255–263. [Google Scholar] [CrossRef]
- Wang, K.C.P.; Li, Q.; Gong, W.G. Wavelet-based pavement distress image edge detection with a trous algorithm. Transp. Res. Rec. 2007, 2024, 73–81. [Google Scholar] [CrossRef]
- Xiang, T.; Huang, K.X.; Zhang, H.; Zhang, Y.Y.; Zhang, Y.N.; Zhou, Y.H. Detection of Moving Load on Pavement Using Piezoelectric Sensors. Sensors 2020, 20, 2366. [Google Scholar] [CrossRef]
- Yamaguchi, T.; Hashimoto, S. Fast crack detection method for large-size concrete surface images using percolation-based image processing. Mach. Vis. Appl. 2010, 21, 797–809. [Google Scholar] [CrossRef]
- Adhikari, R.S.; Moselhi, O.; Bagchi, A. Image-based retrieval of concrete crack properties for bridge inspection. Autom. Constr. 2014, 39, 180–194. [Google Scholar] [CrossRef]
- Payab, M.; Abbasina, R.; Khanzadi, M. A Brief Review and a New Graph-Based Image Analysis for Concrete Crack Quantification. Arch. Comput. Methods Eng. 2019, 26, 347–365. [Google Scholar] [CrossRef]
- Andrushia, A.D.; Anand, N.; Arulraj, G.P. A novel approach for thermal crack detection and quantification in structural concrete using ripplet transform. Struct. Control Health Monit. 2020, 27, e2621. [Google Scholar] [CrossRef]
- Liu, Y.F.; Cho, S.; Spencer, B.F.; Fan, J.S. Concrete Crack Assessment Using Digital Image Processing and 3D Scene Reconstruction. J. Comput. Civ. Eng. 2016, 30, 04014124. [Google Scholar] [CrossRef]
- Li, S.Y.; Zhao, X.F.; Zhou, G.Y. Automatic pixel-level multiple damage detection of concrete structure using fully convolutional network. Comput.-Aided Civ. Infrastruct. Eng. 2019, 34, 616–634. [Google Scholar] [CrossRef]
- Prasanna, P.; Dana, K.J.; Gucunski, N.; Basily, B.B.; La, H.M.; Lim, R.S.; Parvardeh, H. Automated Crack Detection on Concrete Bridges. IEEE Trans. Autom. Sci. Eng. 2016, 13, 591–599. [Google Scholar] [CrossRef]
- Peng, X.; Zhong, X.G.; Zhao, C.; Chen, A.H.; Zhang, T.Y. A UAV-based machine vision method for bridge crack recognition and width quantification through hybrid feature learning. Constr. Build. Mater. 2021, 299, 123896. [Google Scholar] [CrossRef]
- Alipour, M.; Harris, D.K.; Miller, G.R. Robust Pixel-Level Crack Detection Using Deep Fully Convolutional Neural Networks. J. Comput. Civ. Eng. 2019, 33, 04019040. [Google Scholar] [CrossRef]
- Zhang, H.; Shen, Z.J.; Lin, Z.H.; Quan, L.W.; Sun, L.F. Deep learning-based automatic classification of three-level surface information in bridge inspection. Comput.-Aided Civ. Infrastruct. Eng. 2023. [Google Scholar] [CrossRef]
- Zhang, L.; Yang, F.; Zhang, Y.D.; Zhu, Y.J. Road Crack Detection Using Deep Convolutional Neural Network. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 3708–3712. [Google Scholar] [CrossRef]
- Cha, Y.J.; Choi, W.; Buyukozturk, O. Deep Learning-Based Crack Damage Detection Using Convolutional Neural Networks. Comput.-Aided Civ. Infrastruct. Eng. 2017, 32, 361–378. [Google Scholar] [CrossRef]
- Chen, F.C.; Jahanshahi, M.R. NB-CNN: Deep Learning-Based Crack Detection Using Convolutional Neural Network and Naive Bayes Data Fusion. IEEE Trans. Ind. Electron. 2018, 65, 4392–4400. [Google Scholar] [CrossRef]
- Kim, B.; Cho, S. Automated Vision-Based Detection of Cracks on Concrete Surfaces Using a Deep Learning Technique. Sensors 2018, 18, 3452. [Google Scholar] [CrossRef] [PubMed]
- Cha, Y.J.; Choi, W.; Suh, G.; Mahmoudkhani, S.; Buyukozturk, O. Autonomous Structural Visual Inspection Using Region-Based Deep Learning for Detecting Multiple Damage Types. Comput.-Aided Civ. Infrastruct. Eng. 2018, 33, 731–747. [Google Scholar] [CrossRef]
- Deng, J.H.; Lu, Y.; Lee, V.C.S. Concrete crack detection with handwriting script interferences using faster region-based convolutional neural network. Comput.-Aided Civ. Infrastruct. Eng. 2020, 35, 373–388. [Google Scholar] [CrossRef]
- Zhang, C.B.; Chang, C.C.; Jamshidi, M. Concrete bridge surface damage detection using a single-stage detector. Comput.-Aided Civ. Infrastruct. Eng. 2020, 35, 389–409. [Google Scholar] [CrossRef]
- Li, Y.D.; Li, H.G.; Wang, H.R. Pixel-Wise Crack Detection Using Deep Local Pattern Predictor for Robot Application. Sensors 2018, 18, 3042. [Google Scholar] [CrossRef] [PubMed]
- Kim, B.; Cho, S. Image-based concrete crack assessment using mask and region-based convolutional neural network. Struct. Control. Health Monit. 2019, 26, e2381. [Google Scholar] [CrossRef]
- Zhang, A.; Wang, K.C.P.; Fei, Y.; Liu, Y.; Chen, C.; Yang, G.W.; Li, J.Q.; Yang, E.H.; Qiu, S. Automated Pixel-Level Pavement Crack Detection on 3D Asphalt Surfaces with a Recurrent Neural Network. Comput.-Aided Civ. Infrastruct. Eng. 2019, 34, 213–229. [Google Scholar] [CrossRef]
- Yang, X.C.; Li, H.; Yu, Y.T.; Luo, X.C.; Huang, T.; Yang, X. Automatic Pixel-Level Crack Detection and Measurement Using Fully Convolutional Network. Comput.-Aided Civ. Infrastruct. Eng. 2018, 33, 1090–1109. [Google Scholar] [CrossRef]
- Dung, C.V.; Anh, L.D. Autonomous concrete crack detection using deep fully convolutional neural network. Autom. Constr. 2019, 99, 52–58. [Google Scholar] [CrossRef]
- Liu, Z.Q.; Cao, Y.W.; Wang, Y.Z.; Wang, W. Computer vision-based concrete crack detection using U-net fully convolutional networks. Autom. Constr. 2019, 104, 129–139. [Google Scholar] [CrossRef]
- Liu, J.W.; Yang, X.; Lau, S.; Wang, X.; Luo, S.; Lee, V.C.S.; Ding, L. Automated pavement crack detection and segmentation based on two-step convolutional neural network. Comput.-Aided Civ. Infrastruct. Eng. 2020, 35, 1291–1305. [Google Scholar] [CrossRef]
- Miao, Z.H.; Ji, X.D.; Okazaki, T.; Takahashi, N. Pixel-level multicategory detection of visible seismic damage of reinforced concrete components. Comput.-Aided Civ. Infrastruct. Eng. 2021, 36, 620–637. [Google Scholar] [CrossRef]
- Guan, J.C.; Yang, X.; Ding, L.; Cheng, X.Y.; Lee, V.C.S.; Jin, C. Automated pixel-level pavement distress detection based on stereo vision and deep learning. Autom. Constr. 2021, 129, 103788. [Google Scholar] [CrossRef]
- Zhang, X.X.; Rajan, D.; Story, B. Concrete crack detection using context-aware deep semantic segmentation network. Comput.-Aided Civ. Infrastruct. Eng. 2019, 34, 951–971. [Google Scholar] [CrossRef]
- Chen, T.Y.; Cai, Z.H.; Zhao, X.; Chen, C.; Lianga, X.F.; Zou, T.R.; Wang, P. Pavement crack detection and recognition using the architecture of segNet. J. Ind. Inf. Integr. 2020, 18, 100144. [Google Scholar] [CrossRef]
- Zheng, X.; Zhang, S.L.; Li, X.; Li, G.; Li, X.Y. Lightweight Bridge Crack Detection Method Based on SegNet and Bottleneck Depth-Separable Convolution With Residuals. IEEE Access 2021, 9, 161649–161668. [Google Scholar] [CrossRef]
- Ji, A.K.; Xue, X.L.; Wang, Y.N.; Luo, X.W.; Xue, W.R. An integrated approach to automatic pixel-level crack detection and quantification of asphalt pavement. Autom. Constr. 2020, 114, 103176. [Google Scholar] [CrossRef]
- Sun, Y.J.; Yang, Y.; Yao, G.; Wei, F.J.; Wong, M.P. Autonomous Crack and Bughole Detection for Concrete Surface Image Based on Deep Learning. IEEE Access 2021, 9, 85709–85720. [Google Scholar] [CrossRef]
- Bang, S.; Park, S.; Kim, H.; Kim, H. Encoder-decoder network for pixel-level road crack detection in black-box images. Comput.-Aided Civ. Infrastruct. Eng. 2019, 34, 713–727. [Google Scholar] [CrossRef]
- Li, G.; Li, X.Y.; Zhou, J.; Liu, D.Z.; Ren, W. Pixel-level bridge crack detection using a deep fusion about recurrent residual convolution and context encoder network. Measurement 2021, 176, 109171. [Google Scholar] [CrossRef]
- Zhang, L.; Jiang, F.L.; Yang, J.; Kong, B.; Hussain, A. A real-time lane detection network using two-directional separation attention. Comput.-Aided Civ. Infrastruct. Eng. 2023. [Google Scholar] [CrossRef]
- Chen, J.; He, Y. A novel U-shaped encoder–decoder network with attention mechanism for detection and evaluation of road cracks at pixel level. Comput.-Aided Civ. Infrastruct. Eng. 2022, 37, 1721–1736. [Google Scholar] [CrossRef]
- Chen, L.J.; Yao, H.D.; Fu, J.Y.; Ng, C.T. The classification and localization of crack using lightweight convolutional neural network with CBAM. Eng. Struct. 2023, 275, 115291. [Google Scholar] [CrossRef]
- Du, Y.C.; Zhong, S.; Fang, H.Y.; Wang, N.N.; Liu, C.L.; Wu, D.F.; Sun, Y.; Xiang, M. Modeling automatic pavement crack object detection and pixel-level segmentation. Autom. Constr. 2023, 150, 104840. [Google Scholar] [CrossRef]
- Yang, L.; Bai, S.L.; Liu, Y.H.; Yu, H.N. Multi-scale triple-attention network for pixelwise crack segmentation. Autom. Constr. 2023, 150, 104853. [Google Scholar] [CrossRef]
- Zhu, G.J.; Liu, J.C.; Fan, Z.; Yuan, D.; Ma, P.L.; Wang, M.H.; Sheng, W.H.; Wang, K.C.P. A lightweight encoder-decoder network for automatic pavement crack detection. Comput.-Aided Civ. Infrastruct. Eng. 2023. [Google Scholar] [CrossRef]
- Lei, M.F.; Zhang, Y.B.; Deng, E.; Ni, Y.Q.; Xiao, Y.Z.; Zhang, Y.; Zhang, J.J. Intelligent recognition of joints and fissures in tunnel faces using an improved mask region-based convolutional neural network algorithm. Comput.-Aided Civ. Infrastruct. Eng. 2023. [Google Scholar] [CrossRef]
- Que, Y.; Dai, Y.; Ji, X.; Leung, A.K.; Chen, Z.; Jiang, Z.L.; Tang, Y.C. Automatic classification of asphalt pavement cracks using a novel integrated generative adversarial networks and improved VGG model. Eng. Struct. 2023, 277, 115406. [Google Scholar] [CrossRef]
- Nguyen, Q.D.; Thai, H.T. Crack segmentation of imbalanced data: The role of loss functions. Eng. Struct. 2023, 297, 116988. [Google Scholar] [CrossRef]
- Weng, X.X.; Huang, Y.C.; Li, Y.A.; Yang, H.; Yu, S.H. Unsupervised domain adaptation for crack detection. Autom. Constr. 2023, 153, 104939. [Google Scholar] [CrossRef]
- Kang, D.; Benipal, S.S.; Gopal, D.L.; Cha, Y.J. Hybrid pixel-level concrete crack segmentation and quantification across complex backgrounds using deep learning. Autom. Constr. 2020, 118, 103291. [Google Scholar] [CrossRef]
- Yuan, C.; Xiong, B.; Li, X.; Sang, X.; Kong, Q. A novel intelligent inspection robot with deep stereo vision for three-dimensional concrete damage detection and quantification. Struct. Health Monit. 2022, 21, 788–802. [Google Scholar] [CrossRef]
- Kim, H.; Sim, S.-H.; Spencer, B.F. Automated concrete crack evaluation using stereo vision with two different focal lengths. Autom. Constr. 2022, 135, 104136. [Google Scholar] [CrossRef]
- Chen, C.X.; Shen, P. Research on Crack Width Measurement Based on Binocular Vision and Improved DeeplabV3+. Appl. Sci 2023, 13, 2752. [Google Scholar] [CrossRef]
- Pan, S.J.; Yang, Q.A. A Survey on Transfer Learning. IEEE Trans. Knowl. Data Eng. 2010, 22, 1345–1359. [Google Scholar] [CrossRef]
- Wang, M.; Deng, W.H. Deep visual domain adaptation: A survey. Neurocomputing 2018, 312, 135–153. [Google Scholar] [CrossRef]
- Zhang, T.Y.; Suen, C.Y. A Fast Parallel Algorithm for Thinning Digital Patterns. Commun. ACM 1984, 27, 236–239. [Google Scholar] [CrossRef]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Shan, B.; Zheng, S.; Ou, J. A stereovision-based crack width detection approach for concrete surface assessment. KSCE J. Civ. Eng. 2016, 20, 803–812. [Google Scholar] [CrossRef]
- Hinton, G.E.; Srivastava, N.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Improving neural networks by preventing co-adaptation of feature detectors. arXiv 2012, arXiv:1207.0580. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A Simple Way to Prevent Neural Networks from Overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Zhuang, F.Z.; Qi, Z.Y.; Duan, K.Y.; Xi, D.B.; Zhu, Y.C.; Zhu, H.S.; Xiong, H.; He, Q. A Comprehensive Survey on Transfer Learning. Proc. IEEE 2021, 109, 43–76. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Component | Model | Specification |
|---|---|---|
| CCD grayscale camera@2 | MV-EM120M | Sensor resolution: 1280 × 960 pixels Pixel size: 3.75 × 3.75 (μm) Size: 29 × 35 × 48.9 (mm) Weight: 50 g |
| Industrial fixed-focus lens@2 | BT-118C1620MP5 | Focal length: 16 mm Size: φ27.2 × 26.4 (mm) Weight: 75 g |
| Initial Learning Rate (×10−4) | Highest Precision (%) | Highest Recall (%) | Highest F1 Score (%) |
|---|---|---|---|
| 0.1 | 80.48 | 80.67 | 80.47 |
| 1 | 83.10 | 85.74 | 84.14 |
| 10 | 79.53 | 79.84 | 78.43 |
| Measurement Result | CrackⅠ_01 | CrackⅠ_02 | CrackⅠ_03 | CrackⅢ_06 | CrackⅣ_01 |
|---|---|---|---|---|---|
| Calculated value (mm) | 0.544 | 0.981 | 1.993 | 2.980 | 8.431 |
| Reference value (mm) | 0.400 | 1.045 | 2.106 | 2.887 | 8.5 * |
| Error (mm) | 0.144 | −0.064 | −0.113 | 0.093 | −0.069 |
| Relative error | 36.0% | −6.1% | −5.4% | 3.2% | −0.8% |
| Measurement Result | CrackⅡ_01 | CrackⅡ_02 | CrackⅡ_03 | CrackⅡ_04 | CrackⅡ_05 |
|---|---|---|---|---|---|
| Calculated value (mm) | 0.803 | 1.601 | 1.206 | 1.722 | 2.168 |
| Reference value (mm) | 0.836 | 1.613 | 1.200 | 1.743 | 2.153 |
| Error (mm) | −0.033 | −0.012 | 0.006 | −0.021 | 0.015 |
| Relative error | −3.9% | −0.7% | 0.5% | 1.2% | 0.7% |
| Measurement Result | CrackⅢ_01 | CrackⅢ_02 | CrackⅢ_03 | CrackⅢ_04 | CrackⅢ_05 |
|---|---|---|---|---|---|
| Calculated value (mm) | 1.663 | 1.124 | 2.081 | 2.067 | 2.165 |
| Reference value (mm) | 1.706 | 1.045 | 2.090 | 2.026 | 2.129 |
| Error (mm) | −0.043 | 0.079 | −0.009 | 0.041 | 0.036 |
| Relative error | −2.5% | 7.6% | 0.4% | 2.0% | 1.7% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Z.; Shen, Z.; Liu, J.; Shu, J.; Zhang, H. A Binocular Vision-Based Crack Detection and Measurement Method Incorporating Semantic Segmentation. Sensors 2024, 24, 3. https://doi.org/10.3390/s24010003
Zhang Z, Shen Z, Liu J, Shu J, Zhang H. A Binocular Vision-Based Crack Detection and Measurement Method Incorporating Semantic Segmentation. Sensors. 2024; 24(1):3. https://doi.org/10.3390/s24010003
Chicago/Turabian StyleZhang, Zhicheng, Zhijing Shen, Jintong Liu, Jiangpeng Shu, and He Zhang. 2024. "A Binocular Vision-Based Crack Detection and Measurement Method Incorporating Semantic Segmentation" Sensors 24, no. 1: 3. https://doi.org/10.3390/s24010003