
Exponential Fusion of Interpolated Frames Network (EFIF-Net): Advancing Multi-Frame Image Super-Resolution with Convolutional Neural Networks

Abstract
:1. Introduction
2. Materials and Methods
2.1. Observation Model
2.2. EFIF-Net Multiframe Super-Resolution
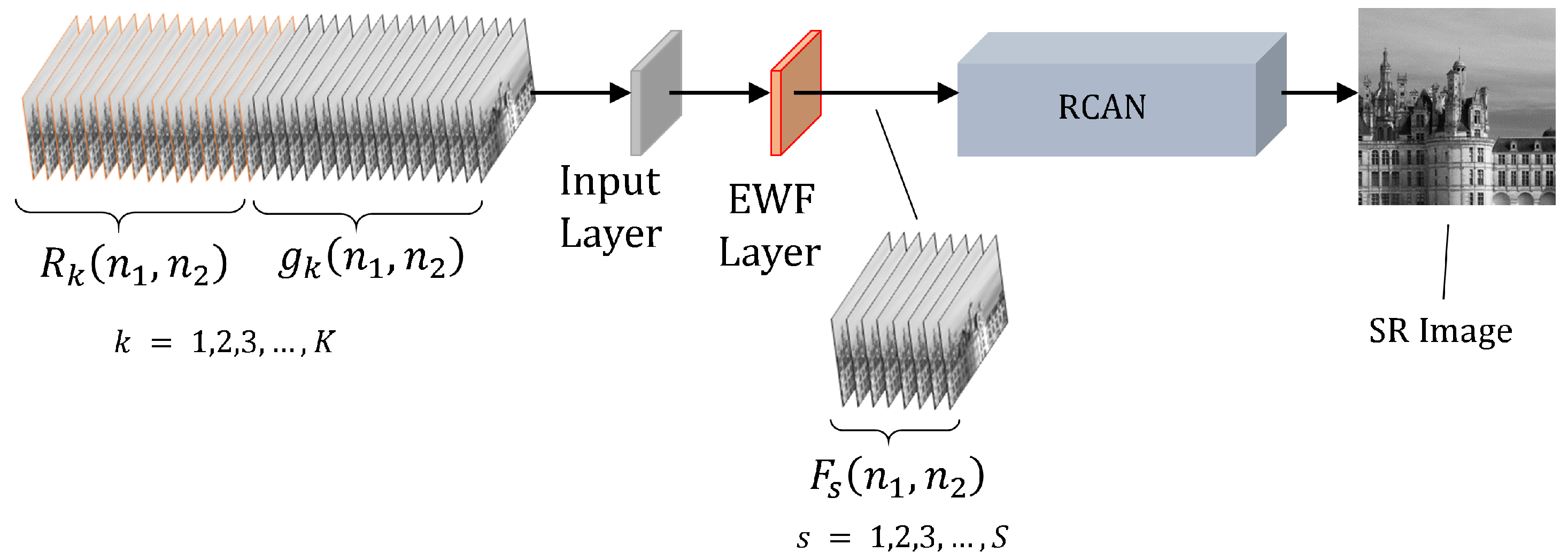
2.2.1. EFIF-Net Architecture
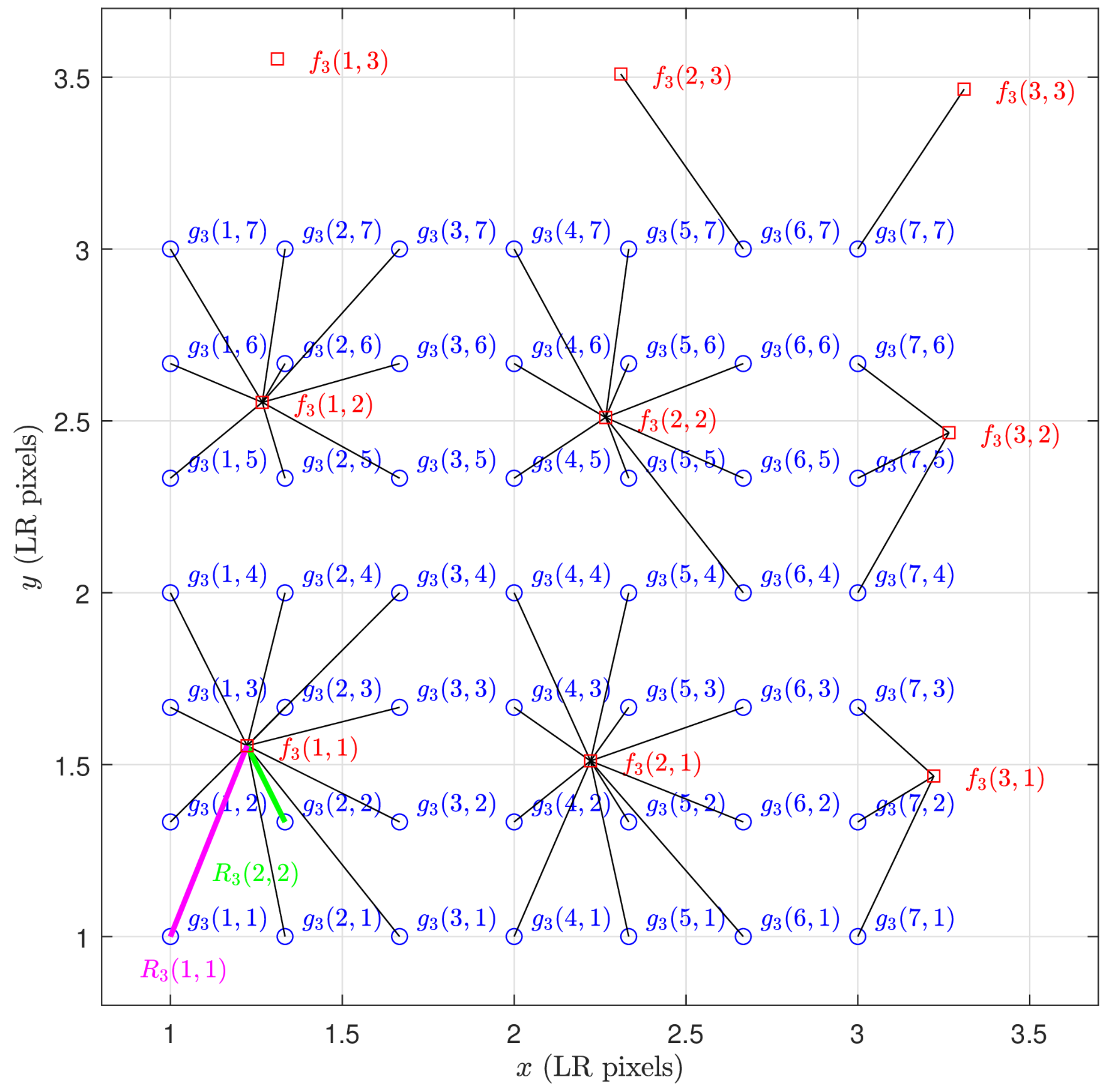
2.2.2. Preprocessing
2.2.3. Exponential Weighted Fusion Layer
2.2.4. Network Training
2.3. Performance Analysis
2.3.1. Simulated Data
2.3.2. Real Camera Data
3. Results
3.1. Quantitative Results with Simulated Data
3.2. Subjective Results with Real Camera Data
4. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Park, S.C.; Park, M.K.; Kang, M.G. Super-resolution image reconstruction: A technical overview. IEEE Signal Process. Mag. 2003, 20, 21–36. [Google Scholar] [CrossRef]
- Bashir, S.M.A.; Wang, Y.; Khan, M.; Niu, Y. A comprehensive review of deep learning-based single image super-resolution. PeerJ Comput. Sci. 2021, 7, e621. [Google Scholar] [CrossRef] [PubMed]
- Tan, R.; Yuan, Y.; Huang, R.; Luo, J. Video super-resolution with spatial-temporal transformer encoder. In Proceedings of the 2022 IEEE International Conference on Multimedia and Expo (ICME), Taipei, Taiwan, 18–22 July 2022; pp. 1–6. [Google Scholar]
- Li, H.; Zhang, P. Spatio-temporal fusion network for video super-resolution. In Proceedings of the 2021 International Joint Conference on Neural Networks (IJCNN), Shenzhen, China, 18–22 July 2021; pp. 1–9. [Google Scholar]
- Thawakar, O.; Patil, P.W.; Dudhane, A.; Murala, S.; Kulkarni, U. Image and video super resolution using recurrent generative adversarial network. In Proceedings of the 2019 16th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Taipei, Taiwan, 18–21 September 2019; pp. 1–8. [Google Scholar]
- Smith, E.; Fujimoto, S.; Meger, D. Multi-view silhouette and depth decomposition for high resolution 3d object representation. Conf. Neural Inf. Process. Syst. 2018, 32, 6479–6489. [Google Scholar]
- Li, B.; Li, X.; Lu, Y.; Liu, S.; Feng, R.; Chen, Z. Hst: Hierarchical swin transformer for compressed image super-resolution. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; pp. 651–668. [Google Scholar]
- Li, H.; Yang, Y.; Chang, M.; Chen, S.; Feng, H.; Xu, Z.; Li, Q.; Chen, Y. Srdiff: Single image super-resolution with diffusion probabilistic models. Neurocomputing 2022, 479, 47–59. [Google Scholar] [CrossRef]
- Ma, Z.; Liao, R.; Tao, X.; Xu, L.; Jia, J.; Wu, E. Handling motion blur in multi-frame super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 5224–5232. [Google Scholar]
- Johnson, J.; Alahi, A.; Fei-Fei, L. Perceptual losses for real-time style transfer and super-resolution. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 694–711. [Google Scholar]
- Ledig, C.; Theis, L.; Huszár, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 105–114. [Google Scholar] [CrossRef]
- Lai, W.S.; Huang, J.B.; Ahuja, N.; Yang, M.H. Deep Laplacian Pyramid Networks for Fast and Accurate Super-Resolution. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5835–5843. [Google Scholar] [CrossRef]
- Lim, B.; Son, S.; Kim, H.; Nah, S.; Lee, K.M. Enhanced Deep Residual Networks for Single Image Super-Resolution. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017; pp. 1132–1140. [Google Scholar] [CrossRef]
- Sajjadi, M.S.M.; Schölkopf, B.; Hirsch, M. EnhanceNet: Single Image Super-Resolution Through Automated Texture Synthesis. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 4501–4510. [Google Scholar] [CrossRef]
- Bulat, A.; Tzimiropoulos, G. Super-FAN: Integrated Facial Landmark Localization and Super-Resolution of Real-World Low Resolution Faces in Arbitrary Poses with GANs. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 109–117. [Google Scholar] [CrossRef]
- Chu, X.; Zhang, B.; Ma, H.; Xu, R.; Li, Q. Fast, Accurate and Lightweight Super-Resolution with Neural Architecture Search. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 59–64. [Google Scholar] [CrossRef]
- Ahn, N.; Kang, B.; Sohn, K.A. Image Super-Resolution via Progressive Cascading Residual Network. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018; pp. 904–9048. [Google Scholar] [CrossRef]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image super-resolution using deep convolutional networks. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 295–307. [Google Scholar] [CrossRef]
- Dong, C.; Loy, C.C.; Tang, X. Accelerating the super-resolution convolutional neural network. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 391–407. [Google Scholar]
- Kim, J.; Lee, J.K.; Lee, K.M. Accurate Image Super-Resolution Using Very Deep Convolutional Networks. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 1646–1654. [Google Scholar] [CrossRef]
- Kim, J.; Lee, J.K.; Lee, K.M. Deeply-recursive convolutional network for image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1637–1645. [Google Scholar]
- Tai, Y.; Yang, J.; Liu, X. Image super-resolution via deep recursive residual network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3147–3155. [Google Scholar]
- Tai, Y.; Yang, J.; Liu, X.; Xu, C. Memnet: A persistent memory network for image restoration. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4539–4547. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Yu, J.; Fan, Y.; Yang, J.; Xu, N.; Wang, Z.; Wang, X.; Huang, T. Wide activation for efficient and accurate image super-resolution. arXiv 2018, arXiv:1808.08718. [Google Scholar]
- Zhang, Y.; Li, K.; Li, K.; Wang, L.; Zhong, B.; Fu, Y. Image super-resolution using very deep residual channel attention networks. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 286–301. [Google Scholar]
- Hardie, R.C.; Droege, D.R.; Dapore, A.J.; Greiner, M.E. Impact of detector-element active-area shape and fill factor on super-resolution. Front. Phys. 2015, 3, 31. [Google Scholar] [CrossRef]
- Milanfar, P. Super-Resolution Imaging; CRC Press: Boca Raton, FL, USA, 2017. [Google Scholar]
- Deudon, M.; Kalaitzis, A.; Goytom, I.; Arefin, M.R.; Lin, Z.; Sankaran, K.; Michalski, V.; Kahou, S.E.; Cornebise, J.; Bengio, Y. Highres-net: Recursive fusion for multi-frame super-resolution of satellite imagery. arXiv 2020, arXiv:2002.06460. [Google Scholar]
- Arefin, M.R.; Michalski, V.; St-Charles, P.L.; Kalaitzis, A.; Kim, S.; Kahou, S.E.; Bengio, Y. Multi-image super-resolution for remote sensing using deep recurrent networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 206–207. [Google Scholar]
- Molini, A.B.; Valsesia, D.; Fracastoro, G.; Magli, E. Deepsum: Deep neural network for super-resolution of unregistered multitemporal images. IEEE Trans. Geosci. Remote Sens. 2019, 58, 3644–3656. [Google Scholar] [CrossRef]
- Bajo, M. Multi-Frame Super Resolution of Unregistered Temporal Images Using WDSR Nets; 2020; Available online: https://zenodo.org/records/3733116 (accessed on 1 November 2023).
- Dorr, F. Satellite image multi-frame super resolution using 3D wide-activation neural networks. Remote Sens. 2020, 12, 3812. [Google Scholar] [CrossRef]
- Salvetti, F.; Mazzia, V.; Khaliq, A.; Chiaberge, M. Multi-image super resolution of remotely sensed images using residual attention deep neural networks. Remote Sens. 2020, 12, 2207. [Google Scholar] [CrossRef]
- Bhat, G.; Danelljan, M.; Van Gool, L.; Timofte, R. Deep burst super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 9209–9218. [Google Scholar]
- Tian, Y.; Zhang, Y.; Fu, Y.; Xu, C. Tdan: Temporally-deformable alignment network for video super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 3360–3369. [Google Scholar]
- Ustinova, E.; Lempitsky, V. Deep multi-frame face super-resolution. arXiv 2017, arXiv:1709.03196. [Google Scholar]
- Wang, X.; Chan, K.C.; Yu, K.; Dong, C.; Loy, C.C. EDVR: Video Restoration With Enhanced Deformable Convolutional Networks. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Long Beach, CA, USA, 16–17 June 2019; pp. 1954–1963. [Google Scholar] [CrossRef]
- Zhu, X.; Hu, H.; Lin, S.; Dai, J. Deformable convnets v2: More deformable, better results. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9308–9316. [Google Scholar]
- Cao, F.; Su, M. Research on Face Recognition Algorithm Based on CNN and Image Super-resolution Reconstruction. In Proceedings of the 2022 IEEE 8th Intl Conference on Big Data Security on Cloud (BigDataSecurity), IEEE Intl Conference on High Performance and Smart Computing,(HPSC) and IEEE Intl Conference on Intelligent Data and Security (IDS), Jinan, China, 6–8 May 2022; pp. 157–161. [Google Scholar]
- An, T.; Zhang, X.; Huo, C.; Xue, B.; Wang, L.; Pan, C. TR-MISR: Multiimage super-resolution based on feature fusion with transformers. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 1373–1388. [Google Scholar] [CrossRef]
- Gonbadani, M.M.A.; Abbasfar, A. Combined Single and Multi-frame Image Super-resolution. In Proceedings of the 2020 28th Iranian Conference on Electrical Engineering (ICEE), Tabriz, Iran, 4–6 August 2020; pp. 1–6. [Google Scholar]
- Elwarfalli, H.; Hardie, R.C. Fifnet: A convolutional neural network for motion-based multiframe super-resolution using fusion of interpolated frames. Comput. Vis. Image Underst. 2021, 202, 103097. [Google Scholar] [CrossRef]
- Hardie, R. A fast image super-resolution algorithm using an adaptive Wiener filter. IEEE Trans. Image Process. 2007, 16, 2953–2964. [Google Scholar] [CrossRef] [PubMed]
- Hardie, R.C.; Barnard, K.J.; Ordonez, R. Fast super-resolution with affine motion using an adaptive Wiener filter and its application to airborne imaging. Opt. Express 2011, 19, 26208–26231. [Google Scholar] [CrossRef]
- Hardie, R.C.; Rucci, M.; Karch, B.K.; Dapore, A.J.; Droege, D.R.; French, J.C. Fusion of interpolated frames superresolution in the presence of atmospheric optical turbulence. Opt. Eng. 2019, 58, 083103. [Google Scholar] [CrossRef]
- Zhang, Y. RCAN: PyTorch Code for Our ECCV 2018 Paper “Image Super-Resolution Using Very Deep Residual Channel Attention Networks”. Available online: https://github.com/yulunzhang/RCAN/tree/master (accessed on 1 November 2023).
- Agustsson, E.; Timofte, R. NTIRE 2017 challenge on single image super-resolution: Dataset and study. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 1122–1131. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2017, arXiv:1412.6980. [Google Scholar]
- Arbelaez, P.; Maire, M.; Fowlkes, C.; Malik, J. Contour detection and hierarchical image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 898–916. [Google Scholar] [CrossRef]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef]
- Hardie, R.C.; Barnard, K.J. Fast super-resolution using an adaptive Wiener filter with robustness to local motion. Opt. Express 2012, 20, 21053–21073. [Google Scholar] [CrossRef] [PubMed]
- Karch, B.K.; Hardie, R.C. Robust super-resolution by fusion of interpolated frames for color and grayscale images. Front. Phys. 2015, 3, 28. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| Aperture | mm |
| Focal length | mm |
| F-number | F = 5.60 |
| Wavelength | μm |
| Optical cut-off frequency | cyc/mm |
| Detector Pitch | m |
| Sampling frequency | cyc/mm |
| Undersampling | |
| Upsampling factor | |
| Noise model | Additive Gaussian () |
| Dynamic range of dataset | 0–1 |
| Camera motion model | Affine |
| Dataset | K | PSNR(dB)/SSIM | |||
|---|---|---|---|---|---|
| Bicubic | RCAN | FIFNET | EFIF-Net | ||
| Set14 | 1 | 23.55/0.692 | 27.46/0.814 | 27.44/0.808 | 27.51/0.814 |
| 9 | - | - | 31.45/0.909 | 32.67/0.925 | |
| 30 | - | - | 31.16/0.909 | 33.71/0.939 | |
| 60 | - | - | 31.03/0.903 | 34.24/0.945 | |
| BSDS100 | 1 | 24.31/0.720 | 26.36/0.781 | 26.29/0.775 | 26.36/0.781 |
| 9 | - | - | 30.11/0.898 | 31.26/0.918 | |
| 30 | - | - | 29.98/0.897 | 32.56/0.937 | |
| 60 | - | - | 29.89/0.892 | 33.18/0.945 | |
| DIV2K | 1 | 26.61/0.790 | 30.00/0.866 | 29.69/0.859 | 29.81/0.864 |
| 9 | - | - | 33.10/0.919 | 34.48/0.940 | |
| 30 | - | - | 32.67/0.917 | 34.97/0.946 | |
| 60 | - | - | 32.41/0.9111 | 35.16/0.948 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Elwarfalli, H.; Flaute, D.; Hardie, R.C. Exponential Fusion of Interpolated Frames Network (EFIF-Net): Advancing Multi-Frame Image Super-Resolution with Convolutional Neural Networks. Sensors 2024, 24, 296. https://doi.org/10.3390/s24010296
Elwarfalli H, Flaute D, Hardie RC. Exponential Fusion of Interpolated Frames Network (EFIF-Net): Advancing Multi-Frame Image Super-Resolution with Convolutional Neural Networks. Sensors. 2024; 24(1):296. https://doi.org/10.3390/s24010296
Chicago/Turabian StyleElwarfalli, Hamed, Dylan Flaute, and Russell C. Hardie. 2024. "Exponential Fusion of Interpolated Frames Network (EFIF-Net): Advancing Multi-Frame Image Super-Resolution with Convolutional Neural Networks" Sensors 24, no. 1: 296. https://doi.org/10.3390/s24010296