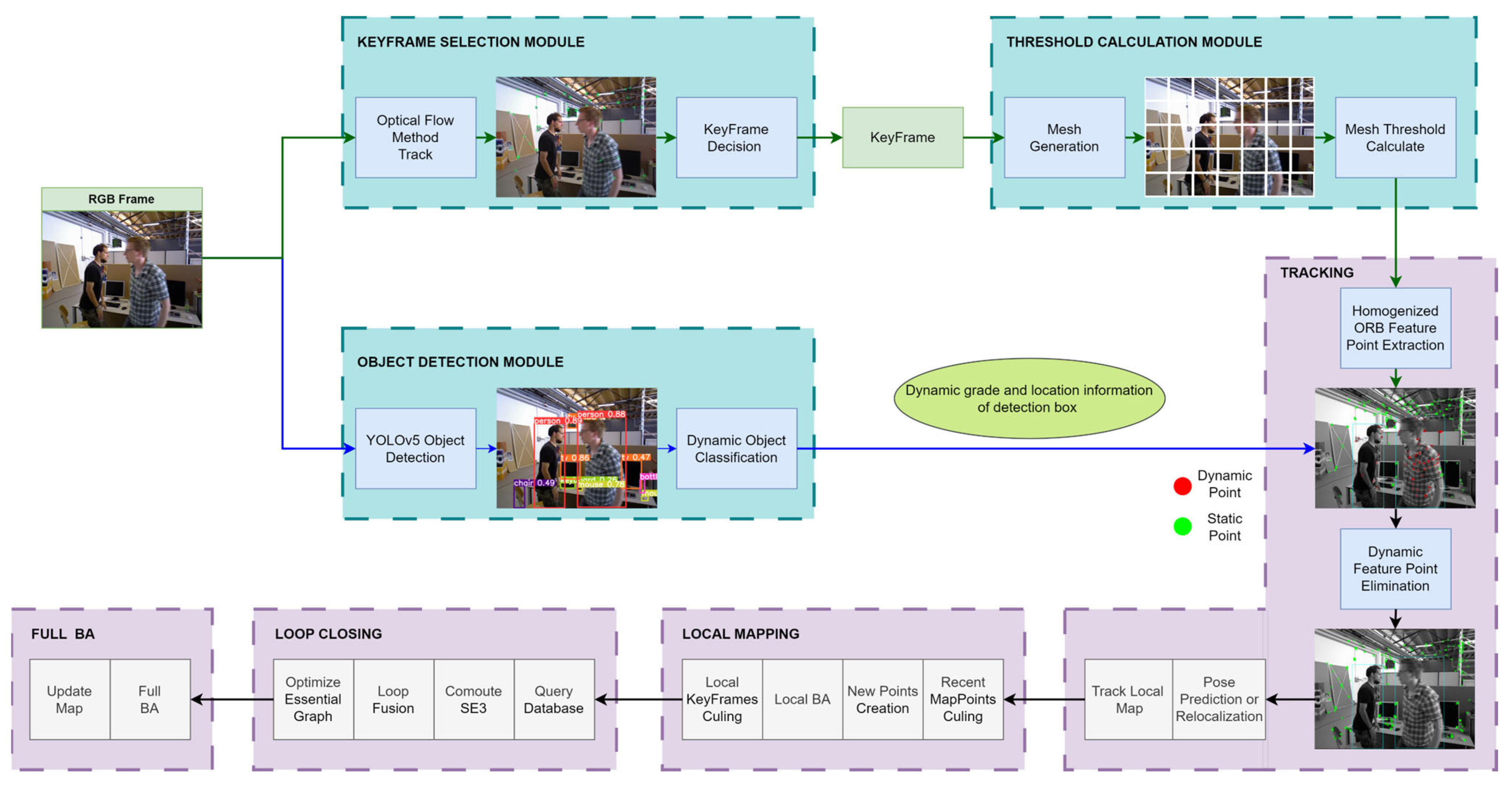
3.1. System Architecture
The system architecture of AHY-SLAM is shown in
Figure 1. The blue box is the innovative part of AHY-SLAM compared with ORB-SLAM2, which includes three new modules, namely, keyframe selection, threshold calculation, and object detection. Homogenized ORB feature point extraction and dynamic feature point elimination steps are added to the tracking thread.
Each ordinary frame entering the system is first processed in two modules: keyframe selection and object detection. After an ordinary frame enters the keyframe selection module, AHY-SLAM extracts the FAST corners of the image and tracks them using the LK optical flow method. According to the improved keyframe decision, whether the ordinary frame can be selected as a keyframe is judged. For non-keyframes that do not meet the requirements, AHY-SLAM uses PNP + RANSAC to calculate the camera pose and continue to judge the next frame. If the ordinary frame is judged to be a keyframe, it is output to the threshold calculation module, wherein the image is divided into several small regions, and the corner calculation threshold is calculated separately according to the grey value of a region. All thresholds are exported to the homogenized ORB feature point extraction step in a tracking thread.
On the other side, after the ordinary frame is input into the object detection module, AHY-SLAM uses YOLOv5 to detect an object and draw a detection box around the detected object. For objects with different levels of dynamics, AHY-SLAM classifies them. Finally, the detection box positions of the different objects are output to the tracking thread for dynamic feature point elimination.
3.2. Keyframe Selection Module Based on Optical Flow Method
The information redundancy between similar frames acquired with the camera is relatively high, which has a limited effect on the accuracy improvement of the system. Moreover, if all frames are put into the local map construction and closed-loop detection thread, a large number of redundant calculations will be caused. To solve this problem, ORB-SLAM2 adopts a way of selecting keyframes that involves dividing all ordinary frames into two categories: keyframes and non-keyframes. The camera receives one frame each time (a stereo or RGB-D receives two images) to form one frame. The keyframe is filtered from the ordinary frame, which can only be used to solve the camera pose and tracking state of the current frame, while the keyframe can be used to determine the loopback detection and complete the local map construction. In addition, normal frames only resolve the current frame situation, while keyframes can have an impact on the entire system.
Because the keyframe selection strategy adopted in the ORB-SLAM2 system needs to obtain the feature point data on an image in advance, it is necessary to extract an ORB feature point from every incoming frame image. The ORB feature point method needs to extract FAST corners from images and calculate BRIEF descriptors and then find feature matching in different images by calculating the distances of descriptors. Therefore, extracting ORB feature points from all incoming ordinary frames would be computationally intensive and time-consuming for the entire system. ORB-SLAM2 optimizes a keyframe, but a keyframe is only a small fraction of the total frames, so it cannot achieve a significant optimization effect in actual use.
To improve this situation, AHY-SLAM implements a keyframe selection module based on the optical flow method. This module mainly uses the LK optical flow method to judge keyframes in advance so as to avoid complicated descriptor calculation.
Optical flow, a concept first proposed by Stoffregen et al. [
35], carries information, such as about the direction and amplitude of moving objects. It is a method for describing the motion of pixels between images over time, essentially estimating the motion of pixels in images at different times. Different from the feature point method, the optical flow method does not use descriptors to find matching points, but directly uses gray information between images to track corners, so the calculation amount is much less than that for the feature point method. Optical flow is usually dense and sparse, and the dense optical flow method is represented in the HS optical flow method, and the sparse optical flow law is represented in the LK optical flow method [
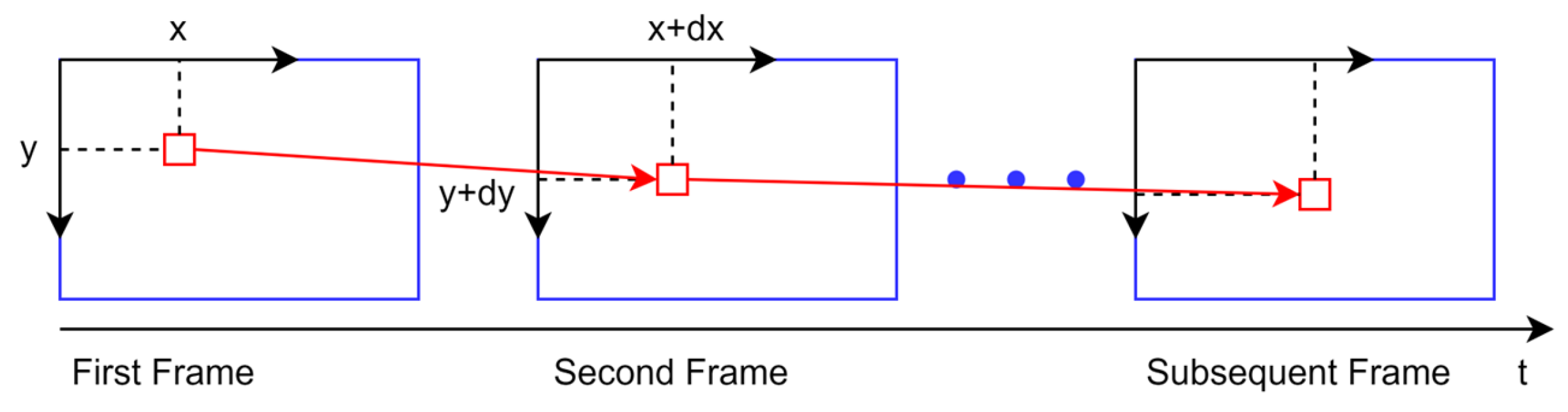
36]. Since only the optical flow method is needed to track feature points and corners in SLAM, the sparse optical flow method is generally used. AHY-SLAM avoids the overhead of constructing descriptors and matching by introducing LK optical flow into the keyframe selection module to directly track corners. The keyframe selection module extracts FAST corners from the first normal frame that is passed in and uses the LK optical flow method to track the corners in the first frame in subsequent frames. Its tracking mode is shown in
Figure 2. The red boxes in the figure represent the position of a FAST corner in different frames.
The optical flow method tracks corners according to the assumption of gray-scale value invariance and motion constraints. Letting the gray-scale value of a pixel at
at time
t be
, and moving it to
at time
, its gray-scale value is
The following can be obtained from the assumption of gray-scale value invariance:
The gray-scale value at time
is expanded via Taylor, and the first-order term is retained to obtain the following:
Via gray-scale value invariant reduction, both sides are obtained:
where
represents the gradient
of the image in the direction of
;
represents the gradient
of the image in the direction of
;
represents the gradient
of the image in the direction of
;
represents the gradient
of the image in the direction of
; and
represents the change
of image gray-scale value with respect to time
.
The above equation is a binary first-order equation, which cannot be solved by using one pixel point and needs to refer to additional constraints. That is, it is not only assumed that the gray-scale value of pixels is constant but also that the motion mode of pixels in the same window is the same.
Setting a window of size
, it then contains
pixels altogether, and multiple equations can be obtained:
By solving the above equation, we obtain
Since the optical flow method is a nonlinear optimization problem, it is assumed that the initial value of optimization is close to the optimal value to ensure the convergence of the algorithm to a certain extent. If the camera motion is fast and the difference between two images is obvious, then the single-layer image optical flow method can easily reach a local minimum. AHY-SLAM addresses this problem by introducing an image pyramid. The lowest layer of the pyramid, that is, of the number of layers in the original image, is the 0th layer. The original image is constantly reduced to reduce the image resolution. When the resolution of the top layer image is reduced to a certain extent, the movement of pixels becomes small enough to meet the prerequisite of a small movement in the LK optical flow method. The optical flow is estimated from the top layer of the pyramid, and then it is iteratively calculated layer by layer along the pyramid structure to constantly correct the displacement assumed at the beginning so as to obtain the optical flow motion estimation for the original image. The advantage of moving from coarse to fine layers of optical flow is that while the pixel motion of the original image is large, the motion remains within a small range from the top of the pyramid.
After using optical flow to track the corners, AHY-SLAM sets the following new keyframe selection criteria based on the original steps of ORB-SLAM2:
Whether the number of frames in the distance from the last keyframe is enough, that is, the keyframe cannot take into consideration a frame with a similar time;
Whether the movement distance of the last keyframe is far enough, that is, the keyframe cannot take into consideration a frame with less movement, and rotation and displacement can be considered at the same time;
Whether there is any difference in the number and proportion of co-view points compared with the last keyframe, that is, when the camera is facing the same scene, no repeated keyframes are recorded, and a new keyframe is created only when the camera leaves the scene.
In addition to the above three selection criteria, because the optical flow method itself has weaker adaptability to environmental changes than the feature point method, it needs to be considered that the optical flow method cannot track enough corners for camera pose calculation. As shown in
Figure 3a, the number of corners tracked using the optical flow method may be insufficient. To this end, AHY-SLAM adds a keyframe selection condition:
- 4.
When the total number of corners tracked using the optical flow method does not meet the requirements, a frame is selected as a keyframe, and the image after ORB feature extraction is re-entered into the keyframe selection module as the new first frame for follow-up tracking.
Figure 3b shows the result of extracting ORB feature points from the keyframe. It can be seen that more points are extracted, and these points will be tracked using the optical flow method.
The overall process of the keyframe selection module is shown in Algorithm 1. After the first frame is passed into the module, FAST corners are extracted, and then these corners are tracked using the LK optical flow method. Whether this frame can be selected as a keyframe is judged according to the above four keyframe judgment criteria. For non-keyframes, AHY-SLAM uses PNP + RANSC to predict the camera pose and then continues to repeat the above judgment process for the next frame. If the frame is selected as a keyframe, AHY-SLAM will extract ORB feature points from it, and the keyframe will become the new first frame and be tracked using LK optical flow method to repeat the judging process. By replacing the ORB feature point method with the optical flow method for keyframe judgment, unnecessary computing costs for non-keyframes can be saved.
| Algorithm 1: Keyframe selection process |
![Sensors 23 04241 i001]() |
3.3. Adaptive Threshold Calculation Module and Homogenized ORB Feature Point Extraction
ORB is one of the fastest and most stable feature point detection and extraction algorithms. ORB feature points are composed of FAST corners and BRIEF descriptors. A FAST corner is a fast detection corner, which is faster than other corner detection algorithms because it only needs to compare the gray-scale differences between the center point and 16 pixel points within a radius of 3.
As shown in
Figure 4, the main detection process for the central pixel
P is as follows:
Record the gray-scale value of the central pixel point as Ip;
Set an appropriate threshold t;
With this pixel as the center point, select the discretized Bresenham circle with a radius of 3 pixels, and select 16 pixel points on the boundary of the circle;
Compare the gray-scale values of the 16 pixel points with Ip. When the gray-scale values of n consecutive pixel points (usually 12 or 9) are greater than Ip + t or less than Ip − t, the point is a corner.
Because it takes a lot of time to go through the detection of 16 pixel points, the method of rapid detection is usually adopted for only a few points to improve efficiency. For example, FAST corner detection in ORB-SLAM2 is used to detect only the gray-scale differences between pixels 1, 9, 5, and 13 of the 16 pixel points and the center point. Whether 3 or more of them exceed the threshold is checked. If so, they are selected as alternative corner points for subsequent detection.
The problem with selecting FAST corners in this way is that the set threshold t is an arbitrary constant value. In this way, only the point with the most obvious gray-scale difference in the whole image is extracted as a corner. In the subsequent quadtree partition extraction, there will be a large number of partition areas without corners. The method of reserving the maximum Harris response value according to quadtree screening eventually leads to all corners being concentrated in the area with the biggest change in light and shade in the whole image, forming aggregation. For the whole SLAM system, the excessive aggregation of feature points produces a large number of redundant feature point information, which will have a certain impact on the matching progress of subsequent images and the positioning accuracy of the camera. For SLAM that uses dynamic points elimination, this is more serious. If dynamic objects account for a large proportion of an image, it is easy for feature points to gather in the dynamic region, resulting in a small number of static points remaining after dynamic points elimination. If you end up keeping too few static points, you can lose trace at worst, which can seriously affect the functioning of the entire SLAM system. The larger the set threshold t is, the more serious the situation becomes.
To solve the above problems, AHY-SLAM sets up the adaptive threshold calculation module to independently calculate the threshold for each small region of keyframes and adjust it according to the number of extracted feature points. The thresholds obtained with the adaptive threshold calculation module are used in the homogenized ORB feature point extraction step. The overall process of the adaptive threshold calculation and homogenized ORB feature point extraction is shown in Algorithm 2. This module receives keyframes from the output of the keyframe selection module. To ensure that the extracted feature points have scale invariance, the image pyramid needs to be built on the keyframe first, and the number of layers of the pyramid needs to be determined according to the size of the image. The strategy for extracting feature points at different levels involves spreading all feature points evenly on each layer of the image in proportion to the image area. Assume that the total number of extracted ORB feature points is N, the total number of scaled pyramid layers is m, the height of the original image is H, the width is W, the image area is W × H = C, and the image pyramid scaling factor is s .
The total image area of the image pyramid can be expressed as
The number of feature points assigned per unit area is
The number of feature points assigned via the original image layer is expressed as
The number of feature points assigned in layer
i is expressed as
After the image pyramid is constructed, meshes are divided for each layer according to their size. Independent detection thresholds are set for each divided mesh, and their initial values are set according to the gray-scale value in each mesh. A divided threshold
t is expressed as
In the above equation, λ is the scale factor, which is generally 0.01; m is the number of pixels in the mesh; and and are the gray-scale value for each pixel and the average gray-scale value of the mesh, respectively.
After mesh division, feature extraction is carried out in the first layer of the image pyramid by traversing the mesh according to the threshold value t obtained with each mesh. In the extraction process, the feature points extracted from all the meshes of each layer are counted. If the total number is greater than or equal to Ni, the loop is withdrawn to end the extraction of feature points from this layer. In some cases, the number of feature points extracted from a layer using this threshold value does not meet the requirements of Ni. In this case, the threshold value is adjusted, and all the original extracted points are retained, while the threshold value is reduced to t/2, and the extraction is stopped until the total number of points in this layer meets the requirements.
After all feature points are extracted, the total number of feature points may be large, and they are still densely distributed in some areas. Therefore, quadtree splitting should be further carried out to delete redundant points in the image after the feature points are extracted. The specific method is as follows: First, set the total number of feature points
M to be retained, divide the input image into 4 nodes, and gradually judge the number of feature points contained in each node. If the number of feature points in a node is greater than 1, further split it into 4 nodes; if it is equal to 0 or 1, do not split it anymore. Calculate the total number of nodes
m to be split. If the total number of nodes
m is greater than or equal to
M, stop all splitting operations. If there are still multiple feature points in a node, perform non-maximum suppression according to the Harris response value.
| Algorithm 2: Adaptive threshold calculation and homogenized ORB feature point extraction process |
![Sensors 23 04241 i002]() |
Considering that it is impossible to obtain all images with high quality from the environments faced in SLAM [
37,
38,
39], it is necessary to conduct experiments on images of different qualities in the image dataset to confirm whether the uniformity of the new method in feature extraction meets requirements [
40,
41,
42]. The ORB feature points extracted using the proposed method and the traditional ORB algorithm, separately, were compared in the Mikolajczyk open-source image dataset [
43], and the effects are shown in
Figure 5.
In order to test the effect of this algorithm on the uniformity of feature points, the uniformity calculation method proposed by Yao et al. [
44] in the literature is adopted. An image is divided into regions in the vertical, horizontal, and 45° and 135° directions as well as in the center and periphery. The number of feature points in each region is counted separately and is denoted as the regional statistical distribution vector. The variance
V of the vector and the uniformity
u are calculated as follows:
It can be seen in
Table 1 that the improved method greatly improves the uniformity of feature point extraction, and the average uniformity is increased by 23.8%, which solves the problem of redundancy caused by the excessive aggregation of ORB feature points. Based on the TUM dynamic scene dataset, we further verified the effect of uniformity enhancement on removing dynamic feature points and retaining static feature points in dynamic scenes.
Figure 6 shows a frame in the freiburg3_walking_halfsphere sequence. The red points in the image are dynamic feature points, while the green points are static feature points.
Figure 6a is the processing result without using homogenized extraction;
Figure 6b is the processing result after using the homogenized extraction method in this paper. It is obvious that a large number of feature points in
Figure 6a are concentrated on the dynamic objects, while the remaining static points are very few. If all dynamic points are eliminated, the accuracy of the system will be greatly affected. In contrast,
Figure 6b retains a large number of feature points outside the dynamic objects, so it is necessary to carry out homogenized extraction of the feature points in the dynamic scene.
3.4. Object Detection Module Based on YOLOv5 and Dynamic Feature Point Elimination
As ORB-SLAM2 itself has a weak ability to deal with dynamic objects, it can only remove partial dynamic points on small objects through RANSC and cannot deal with scenes with a large number of dynamic objects. In order to make the system suitable for dynamic scenes, AHY-SLAM sets an object detection module base on YOLOv5. The detection results were applied to the step of dynamic feature point elimination. Algorithm 3 shows the overall process of the object detection module base on YOLOv5 and dynamic feature point elimination. After the RGB images of each frame are input into the system, AHY-SLAM first uses YOLOv5 object detection to draw detection boxes for different objects.
Figure 7a is the incoming ordinary RGB image, and
Figure 7b is the image after YOLOv5 processing. As can be seen, YOLOv5 drew detection boxes for detecting objects of different categories and determined the types of objects to which they belonged.
Then, AHY-SLAM classifies different types of objects according to dynamic levels and divides all the objects into high-dynamic objects, low-dynamic objects, and static objects. For example, both people and vehicles belong to high-dynamic objects, which are the first part of the image in which to eliminate feature points. Mice and cups belong to low-dynamic objects, and in most cases, the feature points need to be retained for tracking. Computers, desks, and so on are static objects, and the feature points can be directly regarded as static feature points. All detection box information and object category information is output to non-keyframes with FAST feature points and keyframes with ORB feature points. According to this information, AHY-SLAM determines whether corners and feature points belong to static points. If they are dynamic points, they need to be eliminated. The specific methods are as follows: For highly dynamic objects, dynamic points in the images processed using either the optical flow method or the ORB feature point method are eliminated. For low-dynamic objects, only dynamic points in keyframes are eliminated, while non-keyframes retain this part. For static objects, all feature points are directly retained. Because the detection box in YOLO is rectangular, if all feature points in the dynamic object box are directly eliminated, a large number of static points will be mistakenly deleted. Therefore, according to the above classification rules, the overlapped part of the detection boxes is determined. If the dynamic object box overlaps the static object box, all feature points in the static object box are retained first. Then, the remaining feature points in the dynamic object box are eliminated.
| Algorithm 3: Object detection based on YOLOv5 and dynamic feature point elimination process |
![Sensors 23 04241 i003]() |
The result of eliminating the abnormal points on the dynamic object is shown in
Figure 8a, which is the image after extracting the feature points, and
Figure 8b is the image after removing the dynamic feature points. It can be seen that in
Figure 8b, the feature points in the overlapping part between the high-dynamic object “man” and the static object “computer” are retained according to the static feature points, while all the red dynamic points on the dynamic object are eliminated.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}