1. Introduction
The aim of vehicle re-identification (ReID) [
1,
2,
3] is to retrieve a specific vehicle image from a large-scale vehicle gallery captured by non-overlapping cameras, which receives a lot of attention from the artificial intelligence research field due to its significant role in intelligent transportation systems for building smart cities. Most existing vehicle ReID methods [
4,
5,
6,
7,
8,
9,
10,
11,
12,
13,
14,
15,
16] are only based on single-modal visible images, i.e., RGB images, which would suffer from weak performance because of the poor imaging quality under low light environments.
To overcome low illumination conditions, Li et al. [
17] firstly proposed using three-modal (i.e., visible, near-infrared, and thermal-infrared) images for vehicle ReID, and constructed a vehicle ReID benchmark that shows that three-modal vehicle ReID greatly improves accuracy in low illumination conditions. Although a non-visible spectrum could show good night imaging results to play good complements to visible images, different spectra have different imaging characteristics, which could be a challenge even to a strong global feature modeling model [
16]. As shown in
Figure 1, the contrast between the foreground (i.e., vehicles) and background in near-infrared images is lower than that in visible images. Visible images have a stronger ability to reflect texture detail information of vehicles than near-infrared images in the daytime. Thermal-infrared images contain more noise than visible and near-infrared images. As a result, although non-visible images have great potential to boost vehicle ReID performance in low illumination environments, there is an open question in multi-modal ReID in practice: how to effectively fuse the complementary information from multi-modal data?
Existing multi-modal vehicle Re-ID [
17,
18,
19,
20] most focus on learning modal robust features. For example, Wang et al. [
20] designed a cross-modal interacting module and a relation-based embedding module to exchange useful information from multi-modal features so as to enhance features’ richness. Both cross-modal interacting and relation-based embedding modules are convolutional neural network (CNN) branches. Zheng et al. [
19] proposed a cross-directional consistency network to mitigate cross-modal discrepancies and adjust individual feature distributions for learning modal robust features. Li et al. [
17] proposed a heterogeneity collaboration aware multi-stream convolutional neural network to constrain scores of different instances of the same identity to be coherent. Guo et al. [
21] proposed a generative and attentive fusion network to fuse and align features of the original data. Although they have acquired great progress for multi-modal vehicle ReID, there is still room for designing an effective multi-modal fusion manner to improve multi-modal vehicle ReID. Specifically, there are two reasons for emphasizing multi-modal fusion. First, current multi-modal vehicle ReID works [
17,
18,
19,
20,
21,
22] are based on CNNs that use local kernels having a limited receptive field, which is inadequate in fusing global features of multi-modal data. Hence, this paper designs a multi-modal hybrid transformer to use the transformer’s long-distance dependency learning ability to realize a global feature fusion of multi-modal data. Second, current multi-modal vehicle ReID methods only pay attention to the feature level fusion, and the image level fusion is underestimated. Therefore, this paper proposes a random hybrid augmentation to fuse multi-modal complementary information at the image level. Consequently, combing the multi-modal hybrid transformer and the random hybrid augmentation, a progressively hybrid transformer is constructed in this paper, which fuses multi-modal complementary information at both image and feature levels.
The contributions of this paper are summarized as follows:
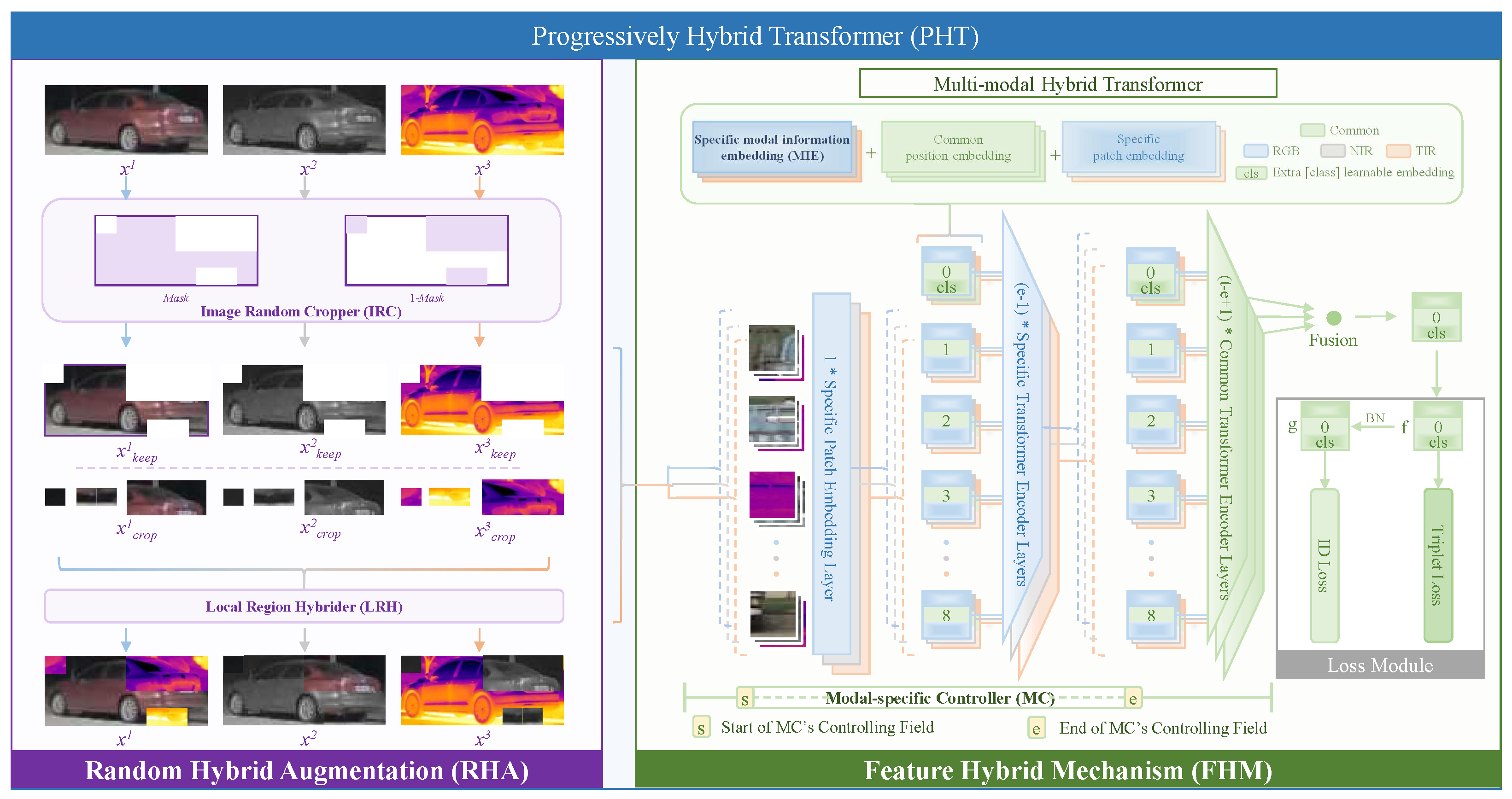
This paper proposes a multi-modal hybrid transformer, which applies the feature hybrid mechanism (FHM) to fuse multi-modal information at the feature level by the modal-specific controller and modal information embedding.
This paper designs a random hybrid augmentation (RHA) to fuse multi-modal information at the image level, which upgrades the multi-modal hybrid transformer into a progressively hybrid transformer (PHT) that fuses multi-modal information at both image and feature levels.
Experimental results on RGBNT100 and RGBN300 demonstrate that the proposed PHT outperforms state-of-the-art methods.
This paper is an extended version of the preliminary work [
23]. Compared with the preliminary work [
23], this paper is improved in two aspects. (1) This paper designs a new data augmentation method (i.e., random hybrid augmentation) to form a more comprehensive multi-modal information fusion which outperforms [
23] a larger 0.9% mAP on RGBNT100 and a larger 0.3% mAP on RGBN300. (2) This paper implements more experiments to analyze the proposed method. The rest of this paper is organized as follows.
Section 2 contains recent works related to the proposed method.
Section 3 describes the proposed method in detail.
Section 4 presents experimental results and analysis to show the proposed method’s advantage.
Section 5 concludes this paper.
4. Experiments and Analysis
To show the proposed method’s advantage, this paper compares the PHT method with state-of-the-art methods on two challenging multi-modal vehicle datasets, namely, RGBNT100 [
17] and RGBN300 [
17]. The RGBNT100 is a three-modal dataset, including visible, near-infrared, and thermal images of 100 subjects, and the RGBN300 is a two-modal dataset, containing visible and near-infrared images of 300 subjects. Following [
17], on both RGBNT100 and RGBN300 datasets, half of the dataset is used for training and the other half is for testing. The cumulative matching characteristic (CMC) curve [
63] and the mean average precision (mAP) [
64] are applied as the performance metric. R1, R5, and R10 denote rank-1, rank-5, and rank-10 identification rates on a CMC curve, respectively.
4.1. Implementation Details
The software tools are Pytorch 1.7 [
65], CUDA 11.1, and python 3.8. The hardware device is one GeForce RTX 3090 GPU. All images of each modality are resized to
sized images. The random horizontal flipping, padding, random cropping, and random erasing [
55] are applied for data augmentation, as performed in [
16]. Each mini-batch contains 16 subjects, and if on the RGBNT100 dataset, each subject has 4 visible images, 4 near-infrared images, and 4 thermal images, otherwise, on the RGBN300 dataset, each subject has 4 visible images and 4 near-infrared images. The ImageNet pre-trained vision transformer (ViT) is applied as the backbone as performed in [
16]. Following [
16], the momentum and weight decay of the stochastic gradient descent (SGD) optimizer [
33] are set to 0.9 and 0.0001, respectively, the learning rate is initialized as 0.008 with cosine learning rate decay, and the patch size and stride size are both set to
. As RGBNT100 and RGBN300 are three-modal and double-modal datasets, the PHT’s backbone is correspondingly made to have three ViT branches and two ViT branches on the RGBNT100 and RGBN300. As each ViT branch has 1 patch embedding layer and 12 transformer encoder layers, the controlled field of the modal-specific controller (MC) is limited to
.
4.2. Comparison with State-of-the-Art
The performance comparison between the proposed PHT and state-of-the-art methods is shown in
Table 1. Those state-of-the-art methods could be divided into two categories: (1) CNN-based methods, namely, HAMNet [
17], GAFNet [
21], CCNet [
19], and DANet [
22]; (2) the transformer-based method, namely, TransReID [
16]. Several interesting observations are as follows.
First, the transformer-based method TransReID [
16] is inferior to those CNN-based methods. For example, the mAP of TransReID [
16] is 5.3% smaller than the earliest CNN-based method called HAMNet [
17]. This observation illustrates that without an appropriate multi-modal information fusion, even using a strong transformer, there is no accuracy performance advantage.
Second, the proposed method (i.e., PHT) greatly improves TransReID [
16] and outperforms those CNN-based methods. On RGBNT100, the PHT’s mAP is 1.8% larger than that of the strongest CNN-based method, i.e., CCNet [
19], although R1, R5, and R10 of the PHT are inferior to those of CCNet [
19]. According to [
64], mAP is a more comprehensive performance indicator than R1, R5, and R10, who are isolated points on a CMC curve. Therefore, the PHT is better overall than CCNet [
19]. Similarly, on RGBN300, the PHT gains good performance, which defeats the strongest one (i.e., GAFNet [
21]) by a 6.6% larger mAP. These results suggest that the full fusion working at both image and feature levels is a great help for a transformer model to improve multi-modal vehicle ReID.
4.3. Analysis of Feature Hybrid Mechanism
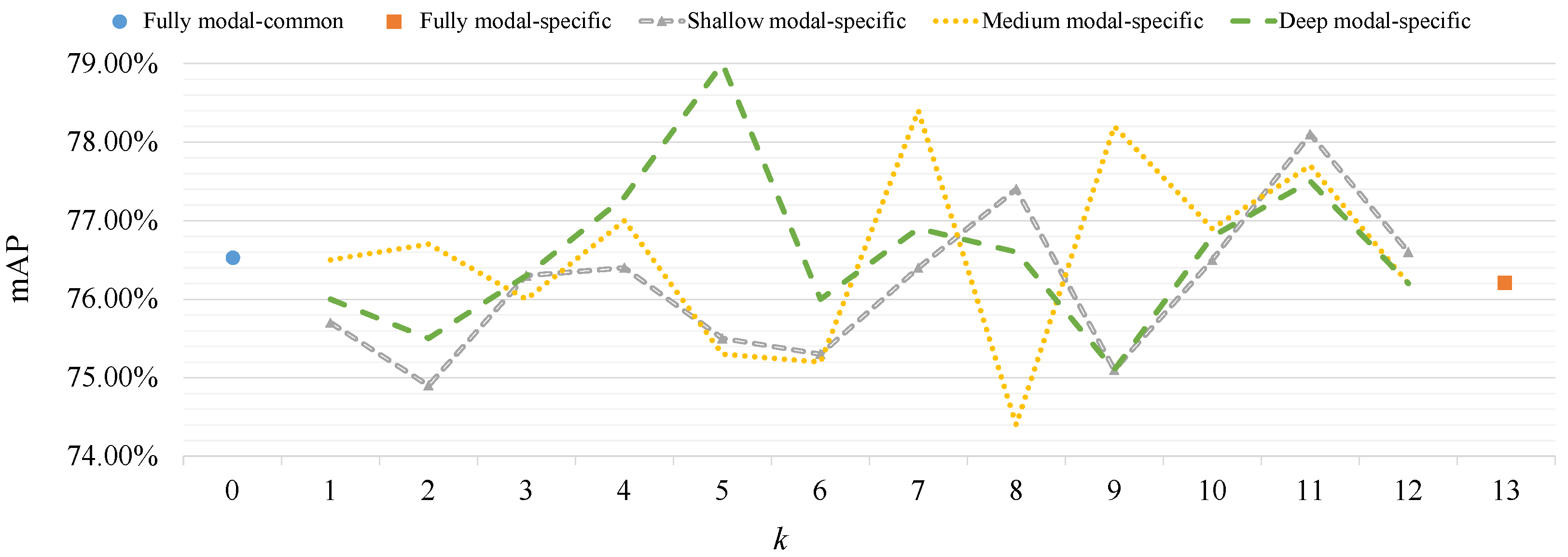
4.3.1. Influence of Modal-Specific Controller
To investigate the influence of using modal-specific layers at different positions, five types of modal-specific controller (MC) configurations are formed based on Equation (
4), as shown in
Table 2. These configurations of the MC are conducted on RGBNT100. Furthermore, position embedding is set to be modal-common and disabled RHA to avoid their influence. The experimental results are shown in
Figure 3.
From
Figure 3 one can see that three partial modal-specific (i.e., shallow modal-specific, medium modal-specific, and deep modal-specific) configurations outperform fully modal-specific and fully modal-common configurations. Especially, when the deep modal-specific configuration has the number of modal-specific layers
and controlled field
, the best performance (79.0% mAP) is achieved. Furthermore, among three partial modal-specific configurations, the deep modal-specific configuration outperforms shallow modal-specific and medium modal-specific configurations. The strength of the deep modal-specific configuration setting shallow layers of a transformer to be modal-common is that the fusion computation works on a deep location requiring complementary features of different modalities so that modal-common layers should be configured at shallow positions while modal-specific layers should be configured at deep positions near to the fusion computation for fusing multi-modal complementary information better.
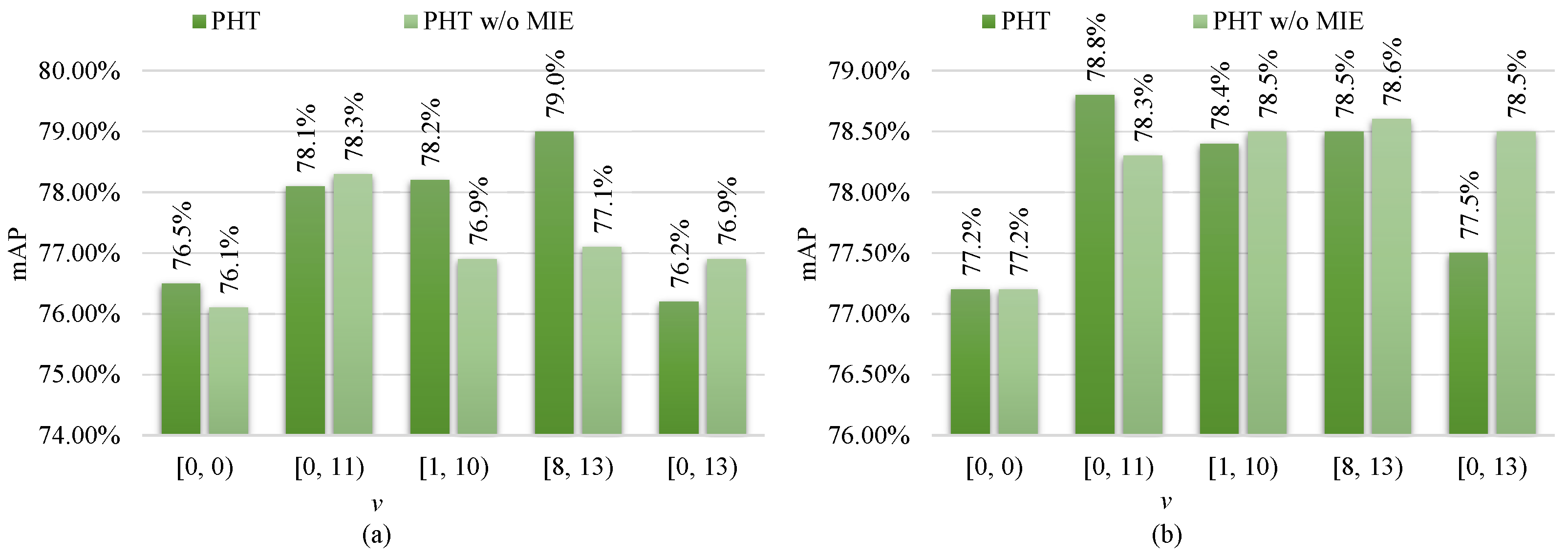
4.3.2. Role of Modal Information Embedding
Based on the observation on the analysis of the modal-specific controller (MC) in
Section 4.3.1, each type’s best MC configuration is chosen and RHA is discarded, and then the role of modal information embedding (MIE) is analyzed, as follows.
From
Figure 4, one can see that PHT with MIE outperforms the PHT without MIE by a 1.9% larger mAP on RGBNT100 and a larger 0.5% mAP on RGBN300, respectively, under the modal-specific configuration of
. Unfortunately, using MIE brings a negative impact on RGBNT100 and RGBN300 under the fully modal-specific configuration of
. This is because the fully modal-specific configuration has no modal-common layers, hindering MIE from learning modal invariant characteristics. Consequently, MIE is useful to alleviate feature deviations towards modal variations and is helpful to enhance multi-modal complementary information fusing but requires a proper MC configuration.
4.3.3. Impact of Position Embedding
Similar to the experiment settings in the previous model information embedding (MIE) analysis, each type’s best MC configuration is chosen and RHA is discarded, and then the performance resulting from modal-specific and modal-common position embedding on RGBNT100 and RGBN300 is compared.
From
Table 3, one can find that most modal-common position embedding cases are stronger than modal-specific position embedding. For example, on RGBNT100, regarding the
case, the mAP of modal-common position embedding is 1.5% larger than that of the modal-specific position embedding. Similarly, for the
case, the modal-common position embedding outperforms the modal-specific position embedding by a 1.4% mAP improvement. These results mean that the modal-common position embedding is more robust than the modal-specific position embedding. The reason for this situation is deduced to the modal-common position embedding requiring fewer parameters than the modal-specific position embedding so that it is easier to be well trained.
4.3.4. Effect of Feature Fusion
According to
Figure 3, the best configuration (i.e.,
and
in deep modal specific) are selected to compare the average, Hadamard product [
66], and concatenating fusion methods. Here, the modal-common position embedding is applied and RHA is still disabled.
From
Table 4, one can observe that the average fusion method gains the best result, that is, 79.0% mAP, 93.4% R1, 94.4% R5, and 95.3% R10 on RGBNT100, and 78.5% mAP, 92.3% R1, 93.1% R5, and 93.7% R10 on RGBN300. The preponderance of the average fusion method suggests that the low-pass effect of average fusion could filter out multi-modal heterogeneity of multi-modal data, so as to improve performance more significantly.
4.4. Analysis of Random Hybrid Augmentation
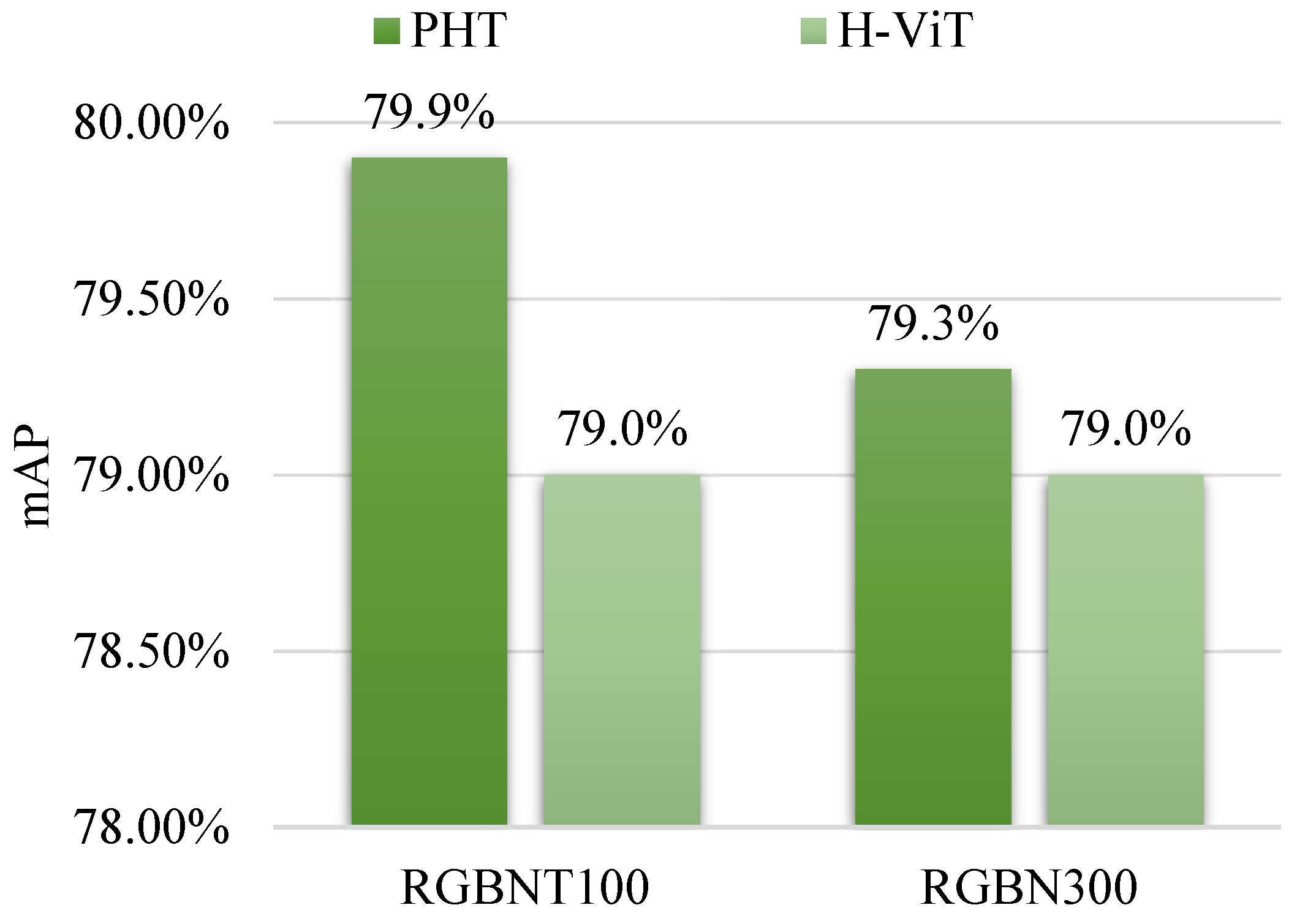
4.4.1. Comparison with the Preliminary Work
To straightforwardly show the role of random hybrid augmentation (RHA), this paper compares the proposed PHT to the preliminary work [
23], namely, H-ViT, which does not utilize RHA. As shown in
Figure 5, the PHT in this paper consistently outperforms H-ViT [
23] on both RGBNT100 and RGBN300. This comparison illustrates that the fusion at the image level of RHA supplements the fusion at the feature level, further boosting multi-modal vehicle ReID. More detailed analyses of RHA are constructed as follows.
4.4.2. Role of Image Random Cropper
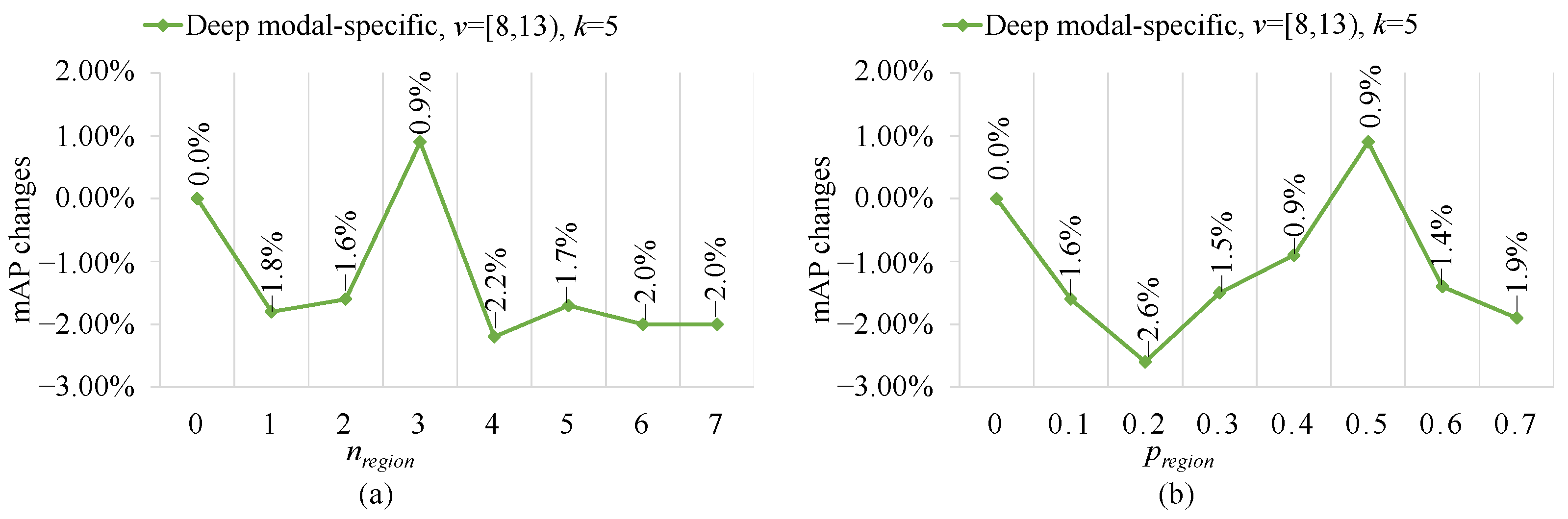
According to
Figure 3, the best MC configuration (i.e., the deep modal-specific configuration of
) is fixed and two key parameters of the image random cropper (IRC), i.e.,
and
, are changed to validate the role of IRC. The results are shown in
Figure 6a,b.
As shown in
Figure 6a, one can see that the best
value is 3 which brings 0.9% mAP performance improvements but most of the rest of the values cause performance degradation. This paper believes this small
could not bring data augmentation while a too dominant
could damage the original image information. Based on a similar reason, as shown in
Figure 6b, the
has a similar performance fluctuation trend, that is, performance improvements followed by performance degradation. Therefore, good RHA should have proper
and
settings for better multi-modal complementary information learning, as performed in existing data augmentation works [
55,
56].
4.4.3. Impact of Local Region Hybrider
Based on observations in the previous subsection (i.e.,
Section 4.4.2) of IRC analysis, the impact of the local region hybrider is further analyzed by using different hybrid methods, including (1) average, (2) self-excluding average, (3) Hadamard product, (4) self-excluding Hadamard product, and (5) randomly swapping. The results are shown in
Table 5.
From
Table 5, it can be found that average reaches the best performance, i.e., 79.9% mAP, which defeats self-excluding average, Hadamard product, self-excluding Hadamard product, and randomly swapping by a 1.2%, 1.1%, 3.1%, and 1.9% mAP, respectively. This result is in line with the average preponderance of the average fusion method in the feature hybrid mechanism (i.e.,
Section 4.3.4), which demonstrates that the low-pass effect of average fusion could filter out multi-modal heterogeneity of multi-modal data again to improve performance more significantly.
4.5. Discussion
Based on the comparison with state-of-the-art methods in
Section 4.2, the performance strength of the PHT is demonstrated. Specifically, the proposed PHT method is superior to the transformer-based method TransReID [
16] by 19.8% mAP on RGBNT100 [
17] and 12.2% mAP on RGBN300 [
17]. Compared to two strong CNN-based methods, namely, GAFNet [
21] and CCNet [
19], the proposed PHT method outperforms GAFNet [
21] by 2.7% mAP on RGBNT100 [
17] and CCNet [
19] by 6.6% mAP on RGBN300 [
17]. Furthermore, based on ablation experiments in
Section 4.3 and
Section 4.4, the performance advantage of the PHT is demonstrated. Especially, compared to the preliminary work H-ViT [
23], the proposed PHT mAP is 0.9% larger on RGBNT100 [
17]. The victory of the proposed PHT in this paper demonstrates that image level information fusion is beneficial to feature level information fusion. The victory is actually expected because the fusion at the image level could be seen as a data augmentation, which is naturally conducive to the subsequent feature learning.
5. Conclusions
To comprehensively fuse multi-modal complementary information for multi-modal vehicle ReID, this paper proposes a progressively hybrid transformer (PHT). The PHT is constructed with two aspects: random hybrid augmentation (RHA) and a feature hybrid mechanism (FHM). At the image level, the RHA emphasizes structural characteristics of all modalities by fusing random regions of multi-modal images. At the feature level, the FHM allows for a multi-modal feature interaction by encoding modal information and fusing different modal features in different positions. The experiments show that (1) the proposed PHT surpasses the state-of-the-art methods on both RGBNT100 and RGBN300 datasets; (2) the multi-modal hybrid transformer built on the FHM is more advantageous than the single-branch transformer; (3) the fusion at the image level of RHA supplements the fusion at the feature level to further boost multi-modal vehicle ReID. Although the PHT is effective for multi-modal vehicle ReID, there is still a limitation of the PHT because it requires a manual setting of fusion configurations (e.g., fusion locations and fusion manners). In the future, a network architecture search approach will be explored to automatically determine fusion locations and manners to realize an adaptive fusion for multi-modal vehicle ReID.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}