1. Introduction
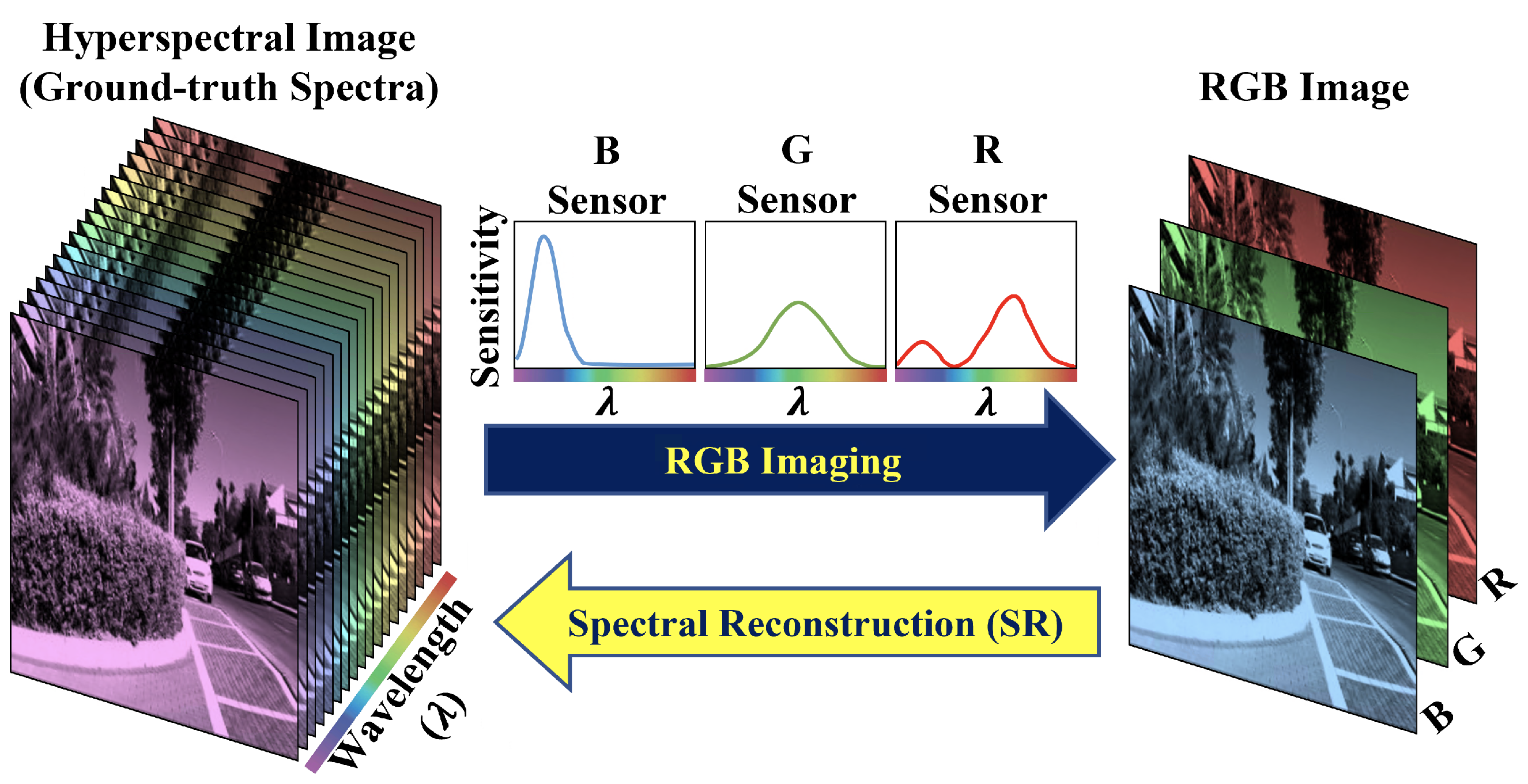
Almost all consumer RGB cameras record 3 intensity values per pixel. These cameras use three types of color sensors with different weighting functions (called spectral sensitivity functions or camera response functions) that weighted-sum the incoming spectral signals over roughly the red, green and blue spectral regions (
Figure 1 upper arrow). However, compared with RGBs, the spectrum (from which the RGB is formed [
1]) conveys significantly more information about an object’s material properties. Consequently, in many computer vision tasks, it is useful to deploy
hyperspectral cameras where finely-sampled light spectrum is captured at every pixel of the scene, including remote sensing [
2,
3,
4,
5], anomaly detection [
6,
7,
8,
9], medical imaging [
10,
11], food processing [
12,
13,
14] and artwork preservation [
15,
16].
Despite the wide usage, traditional hyperspectral techniques [
17,
18] (where spectra are physically and accurately measured) are often expensive, not mobile (difficult to deploy outside the lab), and subject to low light sensitivity, low spatial resolution and/or long integration time. Many recent hyperspectral camera models resort to compressive imaging solutions [
19,
20,
21,
22,
23,
24,
25], where the spectral information is encoded spatially as part of the captured 2D image, and some “decompressing” algorithms are used to restore the hyperspectral information. These designs realize lower-cost, higher-speed and more compact hyperspectral imaging, but nevertheless, they still require specialized physical optics, which limits their usefulness on the already widespread devices, for example, mobile phones and digital cameras. Instead of creating a new device, in spectral reconstruction (SR), we recover hyperspectral signals directly from the RGB camera responses (
Figure 1 lower arrow).
Historically, SR was limited to training a “pixel-based” mapping where the RGB at each pixel is mapped to its spectral estimate independent of other pixels [
26,
27,
28], whereas recently deep neural networks (DNN) adopt “patch-based” mappings, where image content information is (expected to be) extracted from large image patches and utilized as a part of the SR process [
29,
30].
On the surface, it seems the DNNs have rather a strong advantage over the legacy pixel-based methods since DNNs are built with much more powerful processing and mapping architectures, and their input information increases from pixel-RGB to an extended patch region of an RGB image. Moreover, it is sometimes argued that somewhere deep in the DNN mapping, the network can recognize materials and objects, and it is this recognition process that helps recover spectra. Tantalizingly, because of the link to the spatial context, it is sometimes claimed that DNNs can map the same RGB viewed in a different context to different spectra, solving the metamerism problem [
31].
Yet, research shows that a simple pixel-based “polynomial regression” provides an SR accuracy that is only roughly 10% worse than a top DNN method [
32]. This being said, it seems the idea that large image patches really bring in much useful information to SR should be challenged. Indeed, if incorporating local context into SR was found not to be helpful, then it should suffice if we revert to using the much simpler pixel-based methods (which have fewer model parameters, can be trained on the smaller data set, and run in less time compared with the current best DNN approaches). This is especially true if this 10% gap can be further lessened or indeed if the pixel-based approach can be shown to deliver better performance than DNNs.
Another way to challenge existing DNNs is to look at their robustness. As most DNNs learn from image patches, it is easier for them to overfit to well-captured image contents (compared to the pixel-based SRs where image contents are not involved). For example, the contemporary DNN-based SRs do not work as well when the exposure of the image changes [
33,
34]. See column (A) of
Figure 2, where in this paper we tested the best DNN [
35] (i.e., the winner of NTIRE 2020 Spectral Reconstruction Challenge [
30]) with rotated or blurred input images, and discovered that its performance considerably degraded.
Although generally, a DNN’s lack of robustness can be mitigated via data augmentation, the increase in data complexity might negatively affect the DNN’s overall performance (e.g., this is true for maintaining the exposure invariance of the DNNs [
36]). Given that it is already such a close race between pixel-based and DNN-based SRs, we must re-compare both approaches—after data-augmenting the best DNN, and under the desired realistic imaging conditions.
In this paper, we challenge ourselves to achieve state-of-the-art SR performance without the help of DNN and patch-based mapping. We extend from a sparse coding method, A+ [
37], where localized SR mappings are applied in different RGB neighborhoods. Our method, called A++, uses a polynomial regression SR [
32] to map all RGBs to the spectral space in which we define spectral neighborhoods and localize the SR mappings. In a second contribution, on discovering the best DNN degrades when images are rotated or blurred, we introduce those image manipulations in its training stage as part of a data augmentation process, which stabilizes its SR performance across those conditions (column (B) of
Figure 2). Combined, we present experimental results which indicate (i) the pixel-based A++ generally outperforms the leading DNN across the concerned testing conditions (column (C) of
Figure 2), (ii) A++ takes 1/20 the time to train, and (iii) A++ recovers spectra in 1/4 the time as the best DNN.
The rest of the paper is organized as follows.
Section 2 reviews related works in SR.
Section 3 presents our proposed new method. The experiment and results of the SR testing are reported in
Section 4. In addition, in
Section 5, we present a demonstration of using the concerned SR models for the scene relighting application.
Section 6 concludes this paper.
2. Related Works
The earliest SR approaches seek 3-dimensional linear models of spectra. It is then shown that, if such a “3-D” linear model holds, the spectra can be exactly recovered from RGBs using a linear transform [
28,
38]. While a 3-D model can only cover limited variance of real-world spectra [
39,
40,
41], simple statistical models such as regression [
27,
34,
42] and Bayesian inference [
26,
43] are proposed, which supports higher- or full-dimensional spectral recovery. As the amount of available data has increased, recent methods are based on richer inference algorithms, including sparse coding [
29,
44], shallow networks [
45,
46,
47] and deep neural networks (DNN) [
29,
30,
35,
48,
49,
50,
51]. However, not all recent and early methods have been benchmarked on the same database so a fair overall comparison of the methods is not fully available. Yet, it would be fair to say that DNNs are accepted as the leading SR method.
Among the early methods, regression [
27] is a popular approach due to its simple, fast, accurate and closed-form solution. The simplest “linear regression” [
27] relates RGBs and their spectral estimates by a single linear transformation matrix. To introduce non-linearity, polynomial and root-polynomial regression [
34,
42] expand the RGBs into polynomial/root-polynomial terms, which are then mapped to spectra via a linear transform. Generally, “least-squares” regressions are considered, where the mean squared error (MSE) in the training set is minimized. However, because SRs are—at least latterly—more commonly evaluated using relative (percentage) errors [
29,
30,
37,
44], Lin and Finlayson [
32] developed a “relative-error-least-squares” minimization approach for regressions, which further improves the performance of regression-based SR.
Unlike regression, where one single SR mapping is applied to all the input RGBs, sparse coding approaches [
37,
44,
52] seek to determine multiple SR mappings that are used in different RGB neighborhoods. Recently Lin and Finalyson [
53] proposed that instead of assigning local mappings in the RGB space, doing so in the spectral space can greatly improve the upper-bound performance of sparse coding—to the extent that it even far surpasses a top DNN [
53]. Though, their argument employed the concept of an “oracle” that could always correctly locate the (practically unknown) ground-truth spectra among the spectral neighborhoods. In this paper, we seek to propose an approximated model that can probably help us approach the performance of this oracle solution.
Most of the recently proposed approaches to SR are based on DNN architectures—either convolutional neural networks (CNN) or generative adversarial networks (GAN)—where large image patches are standard inputs to the networks. In the recent NTIRE 2018 and 2020 Spectral Reconstruction Challenges [
29,
30], all top finalists are based on DNNs. In this paper, we consider two DNN models for comparison to our proposed method. First, “HSCNN-D” [
50] is the 1st-place winner of the NTIRE 2018 challenge [
29], which adopts a densely-connected structure. In addition, “AWAN” [
35] is the winner of NTIRE 2020 challenge [
30], which is based on the attention network structure. Despite those advances, most DNN benchmarks are carried out on ideally captured images (e.g., still images with well-adjusted exposures). The main ranking protocols of NTIRE competitions also do not account for performance under more difficult imaging conditions (that are still often encountered in the real world). Indeed, more comprehensive benchmarks show that DNNs are generally vulnerable to exposure change [
33,
34], out-of-scope scenes [
30] and scenes without particular image contents [
30,
54]. In this paper, we will also show that the leading DNN is negatively and significantly affected by image rotation and blur.
4. Experiments
In this section, we will benchmark our method against two of the top-performing DNNs: HSCNN-D [
29,
50] and AWAN [
30,
35], as well as the pixel-based A+ sparse coding [
37] and PR-RELS regression methods [
32]. Our A++ method combines aspects of the latter two methods.
According to the recommendations in respective citations, we set the depth of HSCNN-D to 240 (i.e., equivalent to 58 dense blocks) [
50], and our AWAN implementation uses 8 dual residual attention blocks (DRAB) with 200 output channels set for their patch-level second-order non-local (PSNL) module [
35].
All models will be tested on the original, rotated and blurred testing images. We will also introduce how we tune the hyperparameters of our A++ sparse coding architecture and our data augmentation attempt for AWAN.
4.1. Dataset
We use the ICVL benchmarking hyperspectral dataset [
44], which was the basis for the NTIRE 2018 SR challenge [
29]. ICVL comprises 200 scenes captured both indoors and outdoors. The size of each image is 1300 × 1392, and at each pixel, the spectral signal is recorded in 31 channels, referring to the discrete spectral measurements from 400 to 700 nanometers (nm) with 10-nm intervals.
The corresponding RGB images are derived from the hyperspectral images using Equation (
2), with CIE 1964 color matching functions [
59] as the spectral sensitivities.
This dataset setting aligns with the “clean track” of NTIRE 2018 and 2020 SR challenges [
29,
30].
4.2. Training, Validation and Testing
From the dataset, we randomly separate the hyperspectral/RGB image pairs into 100 pairs for training, 50 pairs for testing, and 50 pairs for
model validation (i.e., for determining regularization parameter
in Equation (
8), or for determining the ending epochs of DNN trainings).
To speed up the training process of A+ and A++, we train both models with only a fraction of the training data (this is possible because sparse coding methods, compared to DNNs, need fewer data to train). We randomly select 3000 pixels per training scene for the clustering training (Equation (
5)), and 30,000 pixels per scene for determining the fixed-sized clusters (Equation (
6)).
As for the DNNs (AWAN and HSCNN-D), we use the complete images in training and validation. We stop iterating HSCNN-D until the training loss does not decay anymore, while for AWAN, we set the maximum epoch at 25.
The reference information of the number of model parameters (indicating the model complexity), consumed training time and testing (reconstruction) time is given in
Table 2. Our equipment includes Intel
Core
i7-9700 CPU and NVIDIA
GeForce
RTX 2080 SUPER
GPU. The GPU is only used to train the DNNs. All testing, as well as the training of pixel-based methods, only involve the CPU.
Evidently, similar to the pixel-based A+ and PR-RELS, our A++ method uses much fewer model parameters (about 8% as much as AWAN uses), which leads to much faster training and reconstruction.
4.3. Evaluation Setup
In the robustness testing, we create a rotated test set which consists of the 50 original testing images rotating by 90 degrees clockwise. As for the blurred test set, we apply 2-D Gaussian filters to the original testing images, with two different standard deviation (
) settings:
and
(unit: pixels). Moreover, when applying the Gaussian filters at border pixels, the outer margins of the images are reflected with respect to the edges (i.e., the “half-sample symmetric” approach [
60]).
The metric used for testing the SR efficacy is the often-used Mean Relative Absolute Error (MRAE) [
29,
30]:
where
and
denote the reconstructed and ground-truth spectrum at a pixel, the division is component-wise to the vectors, and
refers to the
(Taxicab) norm. The
factor signifies that MRAE measures the mean error over the 31 spectral channels. In this paper, we present MRAE in
percentages since in MRAE, the error is calculated with respect to the ground truth, which is a percentage error by nature.
We use MRAE because it is the standard protocol for evaluating and ranking the modern DNN-based SR approaches [
29,
30]. Many top DNNs also directly optimize for this metric, including the HSCNN-D and AWAN models [
35,
50]. For a more in-depth explanation on why MRAE is more suitable than the common Root-Mean-Squared Error (RMSE) for SR evaluation, we point the readers to [
32].
4.4. Tuning Our A++ Sparse Coding Architecture
As mentioned in
Section 3.4, there are 2 hyperparameters in A++ that could potentially influence the performance: the number of clusters (
K in Equation (
5)) and the size of each cluster (
N in Equation (
6)).
The original A+ model [
37] uses
, and yet this might not be the best setting for our new setup. So, we are to re-determine both factors.
We start with fixing
and search for the best
K setting. We experiment on original testing images (no rotation, no blur) and calculate the mean per-image-mean-MRAE over the test set. The result is shown in the upper
Table 3, which suggests that
is the best setting. Then, we, in turn, fix
K at this value and search for
N. It is shown in the lower
Table 3 that
returns the lowest error. Therefore, we use
for our A++ implementation.
4.5. DNN Data Augmentation
In this paper, we add a data augmentation step to the AWAN DNN model [
35], so the networks can account for rotation and blur. We do not also data-augment HSCNN-D [
50] because, as will be shown later in the result section, HSCNN-D is more stable against both conditions.
Although we only test the models with one condition at a time (either rotation or blur), we shall still ensure that the data-augmented AWAN can adapt to more extensive changes. For each training/validation image inputted to the network, we are to randomly decide both of the following:
one out of four image orientations including the original, 90 degrees, 180 degrees and 270 degrees clockwise, and
a factor for the Gaussian filter, drawn from the uniform distribution between .
Both conditions are applied consecutively to the input image (the order does not matter). Then, the processed image will be—in replacement for the original image—used to train the AWAN network.
Notice that for training the data-augmented model, we increase the polynomial decay power of their adaptive learning rate from the original 1.5 to 15, which ensures better training-loss convergence.
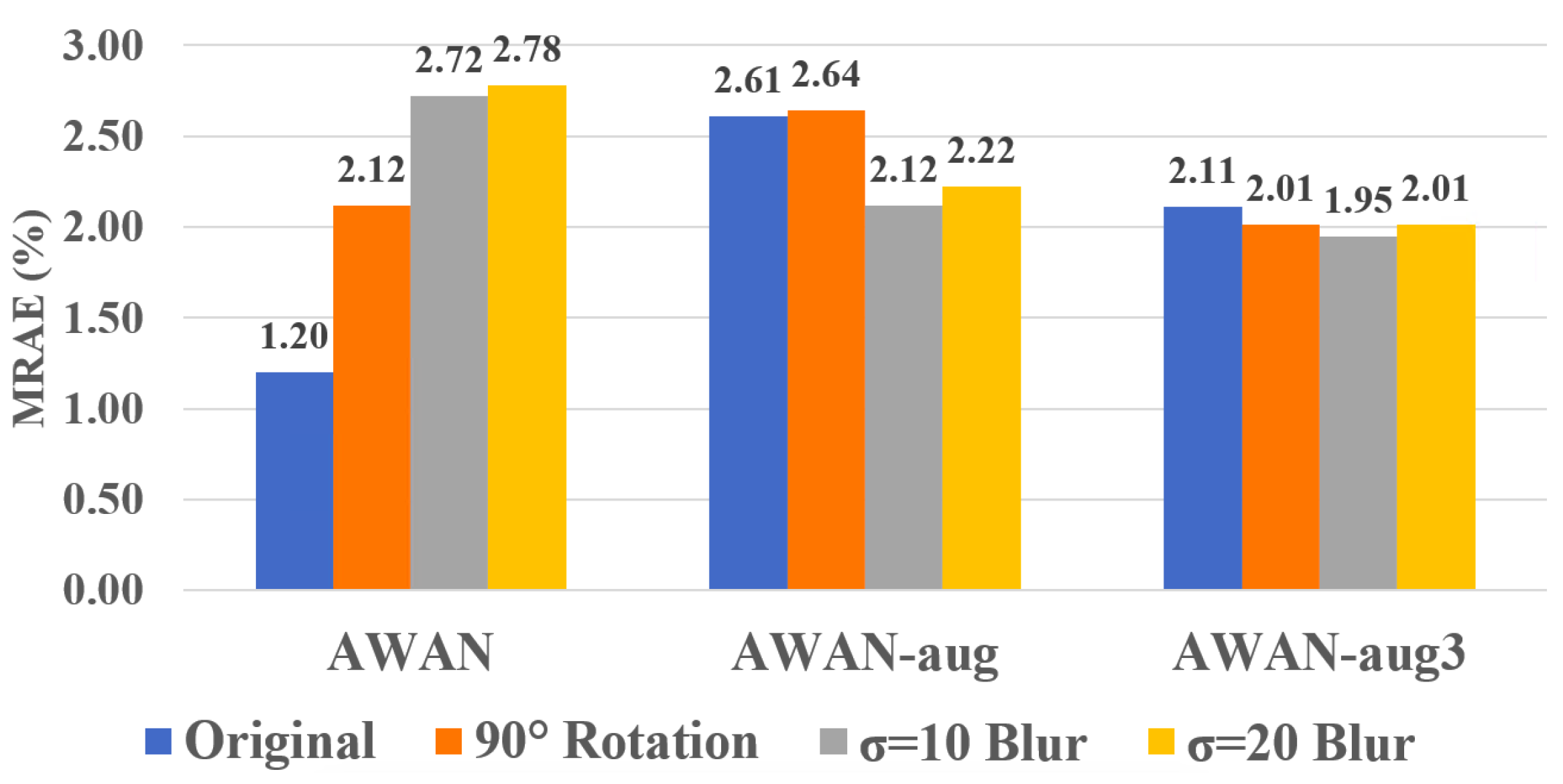
As shown in the left-most result in
Figure 3, on average, the non data-augmented AWAN works well on the original image, but has almost twice as much error for rotated images and performs even worse on blurred images. With data augmentation (the middle “AWAN-aug” result), we see that the model delivers a more stable performance across different conditions but at a worse overall performance level.
Considering that perhaps adopting only one random condition per image is not enough for the network to learn the variation, we try augmenting the network with 3 random conditions per image (the right-most result in
Figure 3). Evidently, this “AWAN-aug3” setting provides even better stability and overall performance across all testing conditions. In the following section, we will include AWAN-aug3 in the benchmark with other compared methods.
4.6. Results
We present the mean and 99-percentile (i.e., the “worst-case”) performance of all considered models and imaging conditions in
Table 4. For each image, we first calculate the mean and 99-percentile MRAE across its pixels, i.e., the “per-image-mean” and “per-image-99-percentile” MRAE. Next, we calculate the mean of these per-image statistics across the testing image set, provide the final presented mean and worst-case statistics.
In terms of the models’ mean performance, we see the best-performing model under the original testing condition (headlined “Orig”) is the DNN-based AWAN. In fact, it performs considerably better than all the rest of the models. However, it also suffers the most when the 90-rotation (“Rot90”) and blur conditions (“Blur10” and “Blur20”) are introduced. While the HSCNN-D and AWAN-aug3 provide much more stable performance across the testing conditions, they do not perform as well as our proposed method.
This result shows a key advantage of pixel-based approaches that, perforce, they are independent of where the pixel is positioned in an image, and so the image orientation does not change the SR outcomes. Equally, assuming the pixel-based methods are well regularized (not overly fit to the training data), small perturbations in the RGB value should result in small perturbations in the recovered spectrum [
32], which suggests that pixel-based SRs are resilient in the face of image blurring. In contrast, the blurring condition prevents the patch-based DNNs from inferring using the high-frequency content in the image.
Next, the worst-case results (right-hand-side
Table 4). We see that under the original testing condition, the DNNs generally have better worst-case performance compared to the pixel-based methods. However, their advantage does not hold when the rotation and blur conditions are introduced, where the pixel-based PR-RELS takes the lead.
Example hyperspectral image reconstruction results are visualized in
Figure 4. Clearly, A++ significantly improves from the pixel-based baselines i.e., using A+ and PR-RELS individually, while retaining their robustness against image rotation and blur. On the other hand, while the effectiveness of our data augmentation setup on AWAN-aug3 is evident, its overall performance is still inferior to our proposed pixel-based A++ method.
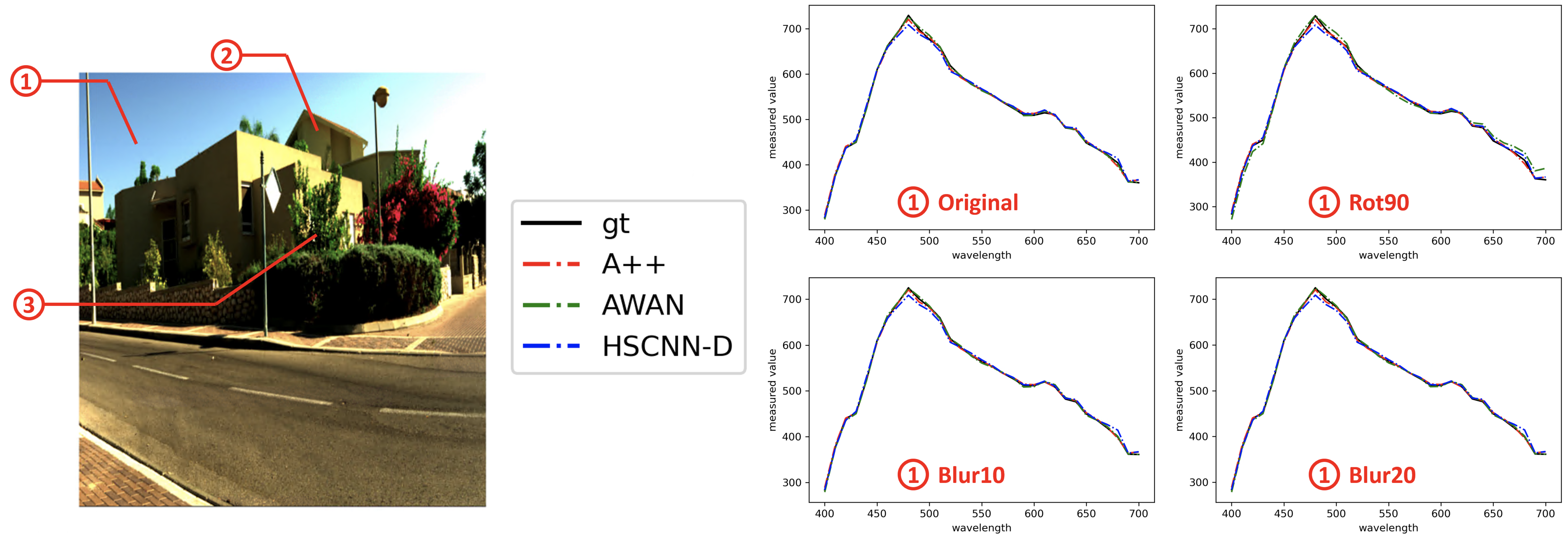
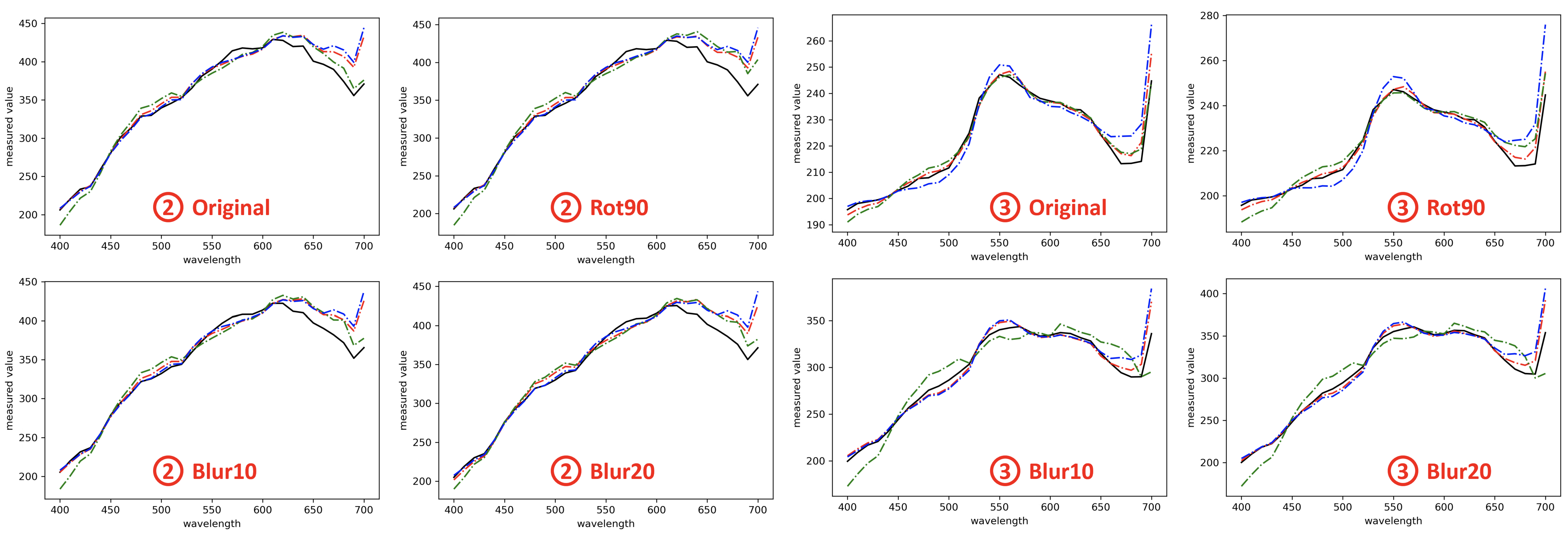
In
Figure 5 and
Figure 6, we visualize the spectral recovery results of A++, AWAN and HSCNN-R in comparison to the ground-truth at three selected pixels of an example scene—the
sky,
building, and
plants. The results under the original, rotation and blurring are also shown separately. It is clear that the rotation and blurring effects cause AWAN to deteriorate, and in the third example (➂ on the right of
Figure 6), we see the degradation of AWAN under blurring effect can be very significant. It is also shown that A++ performs on par with HSCNN-D in example ➀ and ➁, and better in example ➂.
Characteristic Vector Analysis Test
Another way of looking at the feasibility of a reconstructed dataset is by conducting Characteristic Vector Analysis (CVA) [
61] and comparing its outcome with the ground-truth’s (A well-known variant of CVA is the Principal Component Analysis (PCA). In PCA, we conduct CVA while the vector of the mean values of all feature dimensions is subtracted from all data points [
61]). In CVA, we find characteristic vectors in the feature space that—in descending order—maximally explain the variance in data and are orthogonal to all previous characteristic vectors. Practically, CVA is often used to reduce the dimensionality of a dataset by selecting only the top few characteristic vectors and representing all data points as linear combinations of these components. On the other hand, given two spectral datasets—one ground-truth and one reconstructed—by comparing their top characteristic vectors and the
eigenvalues of these vectors (aka the “explained variance” by each characteristic vector), we can conclude how alike these two datasets are.
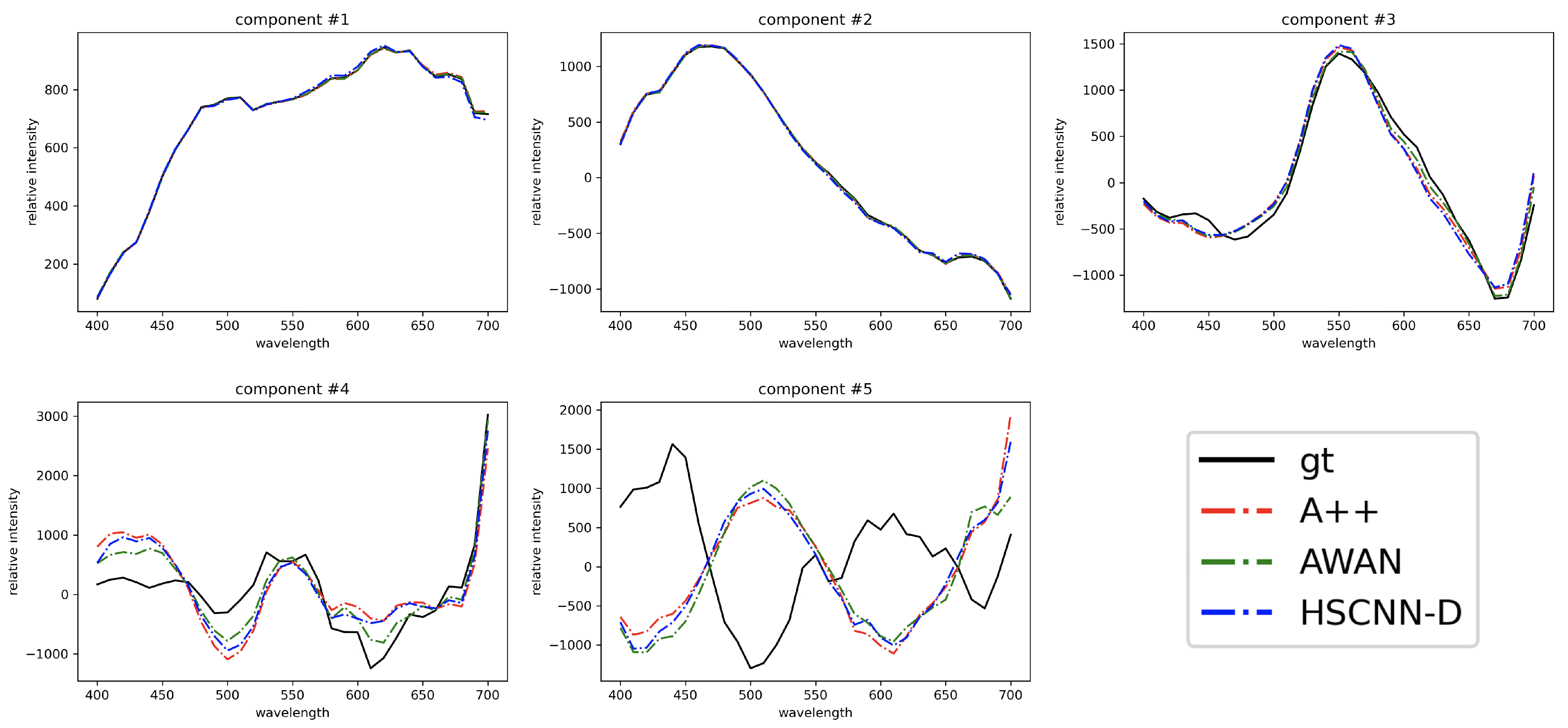
In
Figure 7, we compare the top 5 CVA characteristic vectors of the recovered spectra (by HSCNN-D, AWAN and A++) and ground-truth spectra in the testing image set. Evidently, the first 3 characteristic vectors of all three reconstructed spectral datasets are very similar to the ground-truth dataset. Clear discrepancies start to appear in the 4th component, and the 5th component of all algorithms are drastically different from the ground-truth’s. Nevertheless, the similarity of the 4th and 5th characteristic vectors among reconstruction algorithms remains high. This means that our proposed pixel-based A++ algorithm can recover a spectral dataset similar to the datasets recovered by the DNN-based AWAN and HSCNN-D. We can also see that as shown in
Table 5, the respectively explained variances of the top 5 characteristic vectors of all algorithms are broadly in the same order of magnitude as the ground-truth’s.
4.7. Discussion and Limitations
While AWAN does not work well under more general realistic conditions, we do notice that it provides leading performance on the original testing images. In other words, if for some domain-specific tasks, the image orientation can be fixed and the image blur is the same as in testing (e.g., viewing fixed objects), then AWAN is a good candidate.
One might also argue that we could calibrate the image orientation and deblur the images prior to SR, or augment more data with perhaps a more complex or deeper network structure, and as such, it is still possible for AWAN to surpass A++ for those realistic conditions. However, all of these additional processes effectively add more computational complexity to what appears to be already complex (making AWAN even less approachable in practice). In contrast, A++ is a much simpler and equally effective SR solution that has lower hardware requirements than the DNNs—which is an import factor to consider if we would like to implement the algorithm on, for example, drones, embedded systems, etc.
We want also to point out that, although as per our research interest (to see whether patch information is needed for top-performing SR), we design A++ to be a pixel-based method, a pixel-based mapping fundamentally cannot distinguish materials of the same RGB (since the same RGB will always map to the same spectral estimate). This limitation goes against the premise that hyperspectral imaging can distinguish materials that are not distinguishable by an RGB camera. Hence, for applications where this ability is crucial, A++ and all other pixel-based methods may not be competent. However, they still serve as a baseline to see if the patch-based DNNs indeed perform better in this regard.
Even though we are presenting a pixel-based algorithm, what we want to show here is that currently, the best DNNs do not perform better than the best pixel-based methods, and this calls into doubt the extent to which these algorithms can map the same RGB to different spectra depending on context. This does not mean we do not recognize the DNNs’ premise—that materials and/or objects are identified deep in the network—is good. Unfortunately, that premise is not delivered upon in the architectures that are currently used. We believe our development of A++ will encourage future research on simpler spectral reconstruction techniques as well as more mindful and efficient designs for DNN-based solutions.
5. Demonstration: Spectral Reconstruction for Scene Relighting
Scene relighting refers to changing the light source of the scene as a computational process (instead of physically changing the light source), which predicts how the RGB colors would appear under the target illumination (
Figure 8).
In most color imaging applications where the illumination of the scene is manipulated (e.g., most significantly the color constancy or white balancing application), an “RGB diagonal model” is assumed [
62], which suggests that the relighted RGBs,
, are related to the original RGBs,
, by:
where
and
are, respectively, the RGB colors of the target and original light sources (a.k.a. their “white points”). Here, the division is component-wise, and the
function turns a vector into a diagonal matrix (the vector makes up the diagonal entries of the matrix with zeros elsewhere).
In this demonstration, we evaluate how scene relighting via SR (which will be introduced later) works in comparison to the traditional RGB diagonal method (Equation (
10)).
5.1. “Ground-Truth” Scene Relighting
Theoretically, the RGB diagonal model is only exact when
(in which case
is the correct answer), and yet for all other RGBs this model is only an assumption-based approximation (and thus the ≈ symbol in Equation (
10)).
With the help of hyperspectral imaging, we can derive physically accurate scene relighting for all RGBs. Returning to Equation (
2), where we described that RGB
is formed by
where
is the measured radiance spectrum and
is the RGB camera’s spectral sensitivities. In fact, the measured
can be further separated into two independent components: the illumination spectrum
(intrinsic to the light source) and the object’s surface reflectance
(intrinsic to the object surface). Assuming the world is strictly composed of flat and matte surfaces, we write [
1,
63]:
Given this simple physical model, we can formulate ground-truth scene relighting as:
where
is the given target illumination spectrum we wish to relight the scene to,
is the relighted radiance spectrum, and
is the
exact relighted RGB (i.e., the “ground-truth”).
5.2. Experiment: SR Relighting vs. RGB Diagonal Model Relighting
Given the RGB data, instead of adopting the RGB diagonal model assumption in Equation (
10), SR algorithms estimate the radiance spectrum
from the RGBs, which enables us to use the physical model (Equation (
12)) for scene relighting. While the efficacy of the RGB diagonal model is subject to how well the assumption holds, the SR relighting approach is influenced by the SR accuracy.
We examine the efficacy of SR relighting delivered by all considered SR algorithms and under all concerned realistic imaging conditions (rotation and blur). The performance of the traditional RGB diagonal model is also presented as a baseline. The ground-truth relighted RGB images are derived from the ground-truth hyperspectral images using the physical model in Equation (
12).
Specifically, we relight all test scenes (defined in
Section 4.2) to the standard CIE Illuminant
A and Illuminant
E [
64], where the former represents a tungsten-filament light source with a color temperature around 2856 K, and the latter is the quintessential “white spectrum” (that is, a hypothetical spectrum with a constant intensity across all wavelengths). We study relighting to a white spectrum because it resembles the white balancing process, which normally adopts the RGB diagonal model.
We also need to know the original illumination spectrum
(or for the RGB diagonal model, the original illumination color
) to operate scene relighting. Therefore, we estimate
using the “white patch” approach [
65]. In particular, we set
as the hand-crafted brightest achromatic spectrum in each hyperspectral image, where
brightness is defined as the
norm of the spectrum (the illumination color
can then be derived from the hand-crafted
using RGB simulation:
).
5.2.1. Evaluation Metric
We wish to evaluate the scene relighting color error at each pixel using the CIE 2000 color difference (
) [
66]. To calculate
, we are to transform both the ground truth and the compared estimated relighted RGBs to CIELAB colors [
67]. Given that our RGBs are, in effect, the CIEXYZ tristimulus values (because we use the CIE color matching functions to simulate the RGBs; see
Section 4.1), there is a direct transformation from CIEXYZ to CIELAB given the target relighting illumination color
[
68].
We choose
as our color error metric because it provides homogeneous measurements of color differences. More specifically, a
indicates the “just noticeable difference” between two colors (below which a standard human observer cannot tell their differences). Implementing
is rather complicated. Interested readers are pointed to [
66] for more details.
5.2.2. Results
The CIE Illumination
A and
E relighting results are presented in
Table 6 and
Table 7, respectively. We present the mean and worst-case (99-percentile) performance of all considered SR models and imaging conditions. Both statistics are calculated per image and then averaged over the test set.
First, we observe that all SR methods provide better scene relighting performance compared to the traditional RGB diagonal model, for both the mean and worst-case results. Specifically, the mean relighting accuracy via SR is generally very good ( which is less than the human’s perceivable difference). Arguably, here, bounding the worst-case performance might be more important. Indeed, we see that for all methods the worst-case , which might inflict perceivable color-shift defects in the resulting relighted images.
Next, although in our experiment the most accurate and robust SR methods (A++ and PR-RELS) also suggest the best results in scene relighting, in general, better spectral accuracy does not always imply better relighting performance. For instance, the DNN-based HSCNN-D provides much more accurate SR than the pixel-based A+ sparse coding (
Table 4), but does not show many advantages over A+ in CIE Illuminant
A relighting (
Table 6). For another example, we see that even though AWAN-aug3 provides better spectral accuracy than AWAN on rotated and blurred images, its advantage does not reflect on the scene-relighting application, specifically if we look at its worst-case performance. However, we note that not performing well on scene relighting also does not necessarily mean an SR algorithm would fail in other applications (in which case the spectral accuracy may account for more of the performance).
Finally, we see that under the original testing condition, the DNN-based AWAN method provides the best relighting results overall, while for the robustness tests concerning image rotation and blur, the pixel-based PR-RELS and our proposed A++ methods come to the fore.
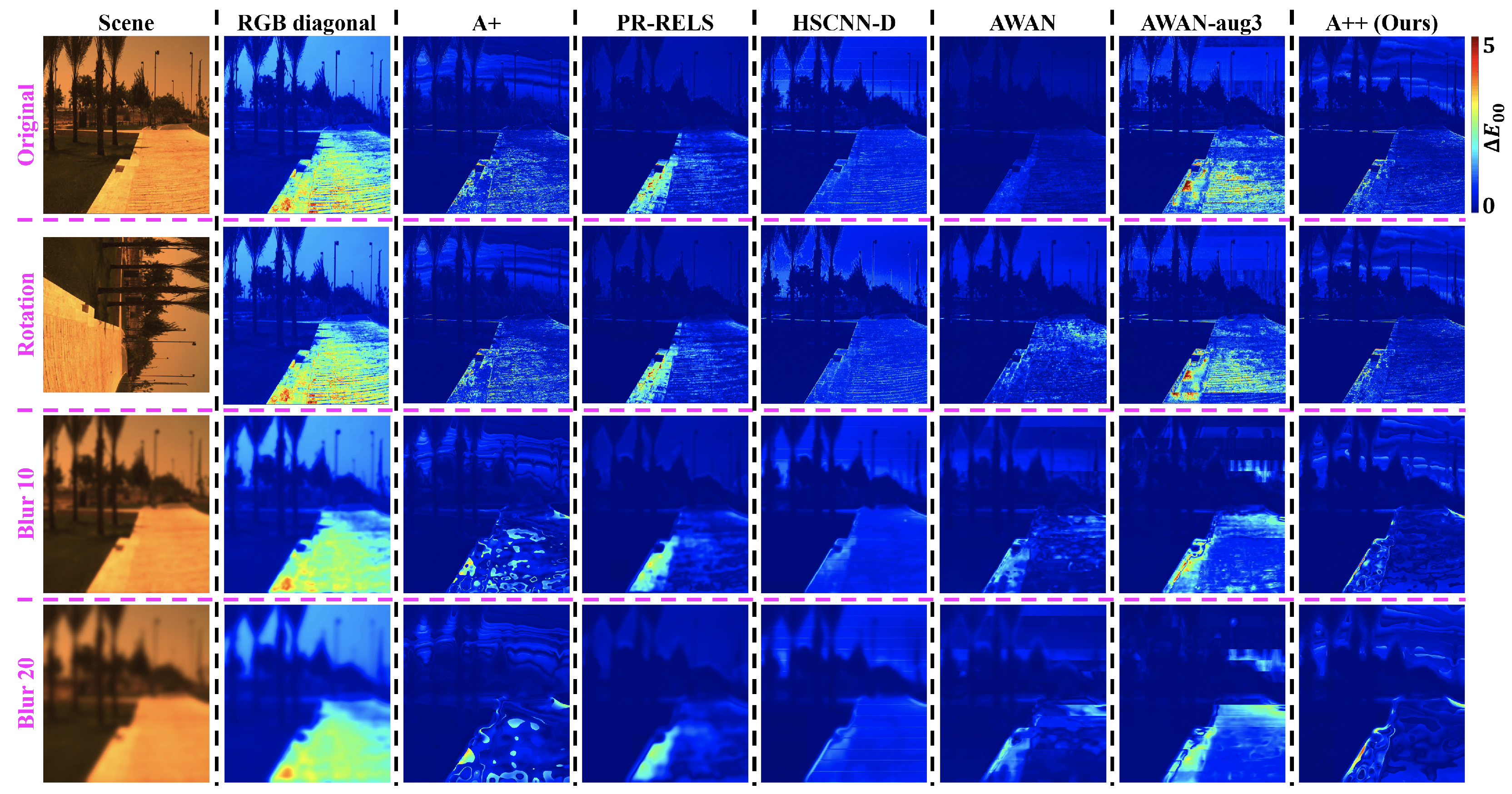
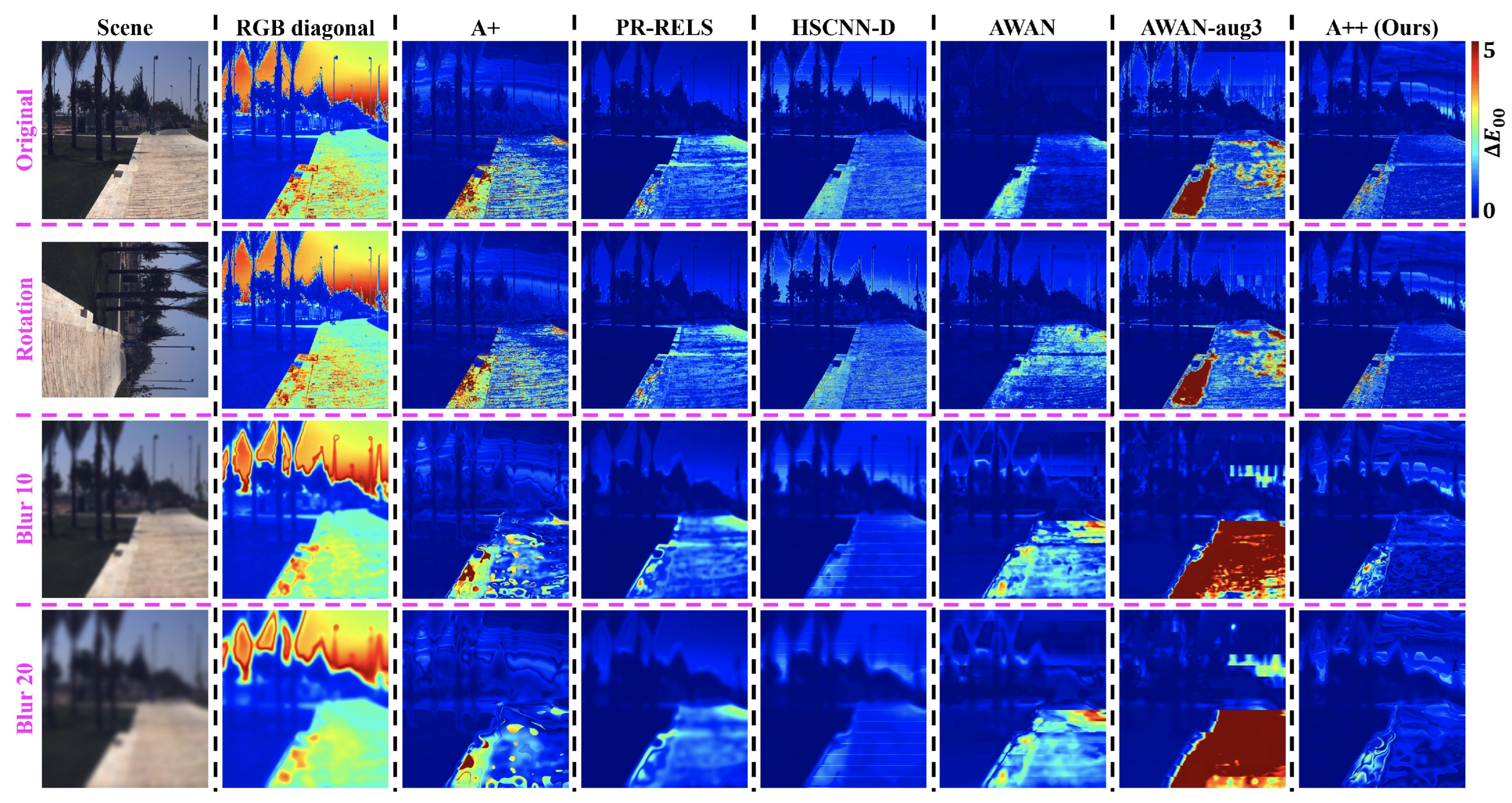
Visualized
error maps for CIE Illuminant
A and
E relighting are respectively presented in
Figure 9 and
Figure 10. Evidently, relighting via SR algorithms generally provide much better color accuracy than the traditional RGB diagonal process, and our proposed SR method A++ provides the best accuracy and robustness in scene relighting overall.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}