3.1. System Design
The apple sorting system consists of three primary sections: the conveying section, classification section, and holder section. A computer with an Intel® Core™ i5-11400 CPU, 32 GB of DDR4-3200 memory, a 2 TB system storage, and a 4 TB data storage controlled the entire system.
The overall process of the apple sorting system is depicted in
Figure 1a–f. Apples are loaded onto the conveyor (
Figure 1a) and placed into individual holders for scanning and classification (
Figure 1b). The apples detected by the object detection sensor roll towards the holder and settle into place (
Figure 1c). The process of apple insertion into the holder is controlled by the object detection sensor, and it is indicated in red circles in
Figure 1b,c. Once in the holder, the apple is immediately captured by the cameras, and the obtained images are processed through the CNN classifier deployed on each embedded board for inference. The apple is then rotated once, and the same inference is performed for the captured images on the other side of the apple (
Figure 1d). More information about the rotation and camera structure can be found in the description in the Holder section. Finally, the stepping motor moves the apple to the box according to its classification results in the direction of the red arrow (
Figure 1e), and the results can be monitored (
Figure 1f). To aid in understanding, the workflow of the system is depicted in
Figure 2.
Moving to the components of the system, the conveying section consisted of a conveying belt, measuring 2300 mm (W) × 1000 mm (H) × 700 mm (D), divided into an apple supply conveyor and an apple transfer conveyor belt. Apples were transferred to the holder through the fruit supply conveyor belt, and their movement flow was regulated by the central sensor. The central sensor could manage the general fault condition of the system by halting the motor drive immediately to prevent bottlenecking during apple input.
The classification section comprised an industrial camera, a light sensor, and an embedded board (NVIDIA Jetson Nano [
30]). The IMX264 CMOS sensing device used an industrial camera (acA2240-35uc, Basler AG, Schleswig-Holstein, Germany) with a 5 MP resolution (2448 × 2048 pixels) and a speed of 35 frames per second at 5.0 MP resolution. The camera was equipped with a lens (FL-CC1618-5MX, Ricoh Co., Ltd., Tokyo, Japan) with a focal length of 16 mm and a maximum aperture ratio of 1:1.8. To obtain uniform and accurate images of apple surfaces with an elliptical shape, we designed a camera structure with three cameras placed at a 120-degree interval (
Figure 3a). To minimize light interference, the cameras were placed under illumination.
In the holder section, an apple detected by the object detection sensor rolled into the holder, and three cameras simultaneously captured each of the three sides (
Figure 3a). The holder then rotated the apple 180 degrees in the direction of the red arrow using a rotation mechanism based on the principle of rotational friction force generated by rapidly running the motor of the internal roller (
Figure 3b). After rotation, there was a two-second waiting period for the apple to stabilize in the holder, which prevented significant motion blur from the camera during rotation and enhanced data quality for classification. Once the apple had stabilized, all three cameras captured its three sides again, resulting in six images of the apple’s surface: three before rotation and three after rotation. The three images before the rotation were immediately classified by the CNN classifier on the embedded boards. The classification results of the three images after the rotation were obtained by the same process. After obtaining a total of six classification results, if even one image detects a surface defect, the external stepping motor of the holder rotated 45 degrees to sort the apple into the box (
Figure 3c). Therefore, this is to rotate to the Surface-defects box as indicated by the red arrow on the left, and rotate to the normal box as indicated by the red arrow on the right.
However, it was necessary to verify the reliability of whether the designed camera structure captures the entire surface of the apple. Therefore, a random sample of apples with an average diameter of 150 mm or less was collected to verify whether the surface of the apple was uniformly captured. To quantify the surface exposure rate, the surface exposure calculation method proposed by [
31] was used. As shown in
Figure 4, the diameter of 8mm was marked at each pole (top vertex, bottom vertex, left, right, front, back) of the apple surface. The apple was rotated using a rotating mechanism to count the total number of poles
and the number of poles that can be captured by the cameras
, and the surface exposure rate was calculated using Equation (1).
A total of 50 randomly sampled normal and surface defective apples was calculated for surface exposure rate and repeated 5 times. Then, by calculating the average exposure rate, the surface exposure rate for each type could be calculated, as shown in
Table 2. Spherical objects of imperfect shape were difficult to rotate perfectly with a rotating mechanism, resulting in a slightly lower surface exposure rate than other cases.
3.2. Data Acquisition
Using the system developed in
Section 3.1, we captured a total of 12,000 images by taking six images per apple for 2000 apples (Fuji) harvested from an orchard in Jangseong-gun, South Korea. The acquired apple images were labeled into two classes, normal and surface defects apples, based on the criterion of whether or not there were surface defects, as shown in
Figure 5. Apples with surface defects exhibited substantial deformations in their skin, such as irregular patterns, pest infestations, as well as morphological and physiological aberrations, attributable to multifaceted factors including climatic and environmental conditions. As shown in
Figure 5b–e, the majority of these deformities were visually conspicuous and could be discerned with ease using unaided observation. Nonetheless, there were instances where apples may have sustained scratches on their surface during the harvesting process due to physical contact. Such scratches, as shown in
Figure 5f, tended to be relatively small in size compared to other surface defects, and their features may be obscured by the reflection of light or insufficient illumination, making them a challenge to classify accurately. For this reason, apples with fine scratches were more likely to be misclassified, which could result in ambiguous labeling at the boundary between the two classes. To ensure accurate classification, we adopted a rigorous manual labeling process with repeated verification. Any images that were difficult to classify based on visual inspection alone were excluded from the surface defects apple class and labeled as normal apples to avoid misclassification. As a result, we constructed a dataset named Surface Defect Apple (SDA) by obtaining a total of 12,000 images and excluding 2000 ambiguous images, resulting in a dataset of 10,000 images. This dataset comprised 6201 normal-class images and 3799 surface defects-class images.
Meanwhile, due to the use of a 5 MP camera in the system, the image resolution of the dataset was 2440 × 2048, which was somewhat large for training a CNN classifier. As a common practice, downsampling is a straightforward method of resizing images to adjust their size when training with extremely large images. However, downsampling apple images captured with the background may result in the loss of critical features, such as fine scratches or defects, as they may become indiscernible or blurred. Therefore, downsampling in this manner could cause the images to become similar to normal apples, increasing the probability of misclassification during training and resulting in the learning of incorrect class information. Thus, additional image preprocessing is necessary to ensure uniformity and feature preservation across various types of apples in high-quality images.
3.3. Data Preprocessing
In CNN-based object classification, the presence of background noise can significantly impact the model’s generalization performance and lead to inconsistent classification results [
32]. The acquired images of apples contained non-target background elements that could further deteriorate the model’s performance. Moreover, the original image size was 2440 × 2048 × 3, making it computationally expensive to use the embedded board for direct inference using a CNN classifier. However, forcing all images to be resized equally could lead to microscopic scratches being categorized into the same class as normal apples, which was a critical issue that must be handled with caution. Therefore, we propose an apple segmentation algorithm that extracts only the apple area.
Step 1. Pyramid-based apple position estimation: Given an input image
in RGB color of size
, the pyramid downsampling method is applied to reduce the image size while maintaining the apple shape. This method enables fast and efficient apple detection, and the calculation is based on Equation (2) when the maximum size of the reduced image is assumed to be
.
The ratio value is the number of times the pyramid downsampling method is applied to . We experimentally fit three times for pyramid downsampling. Thus, we have of reduced size , where . However, in the first-step approach, it is difficult to obtain an apple with a perfect boundary because apple body is greatly affected by the segment when there is a region such as background noise or an apple stem. Therefore, step 2 is performed.
Step 2. Histogram-based complete apple segment: We apply a Gaussian blur filter with
to the image
to remove noise for better apple region estimation. Additionally,
uses a color-based approach to estimate the apple position. Thus, we assume that R, G, and B are matrices of red, green, and blue channels in
. Therefore, it is possible to check the intensity of the R, G, and B pixels at the horizontal coordinates, aligned with the center coordinate values of the apple, as shown in the sample apple image in
Figure 6a, which is depicted as shown in
Figure 6b. And for each color, the red line stands for R, the green line for G, and the blue line for B.
In this distribution, as shown in Equation (3), in the area of the apple, the red value is much higher than the green value, the difference is higher than 40, and the red value is higher than the blue value. Therefore, the region satisfying this is estimated to be the apple region.
As shown in
Figure 6, to remove the small blob created outside the apple area and to connect the area that is not completely closed, the apple boundary is smoothly filled using morphology with an ellipse kernel of size 9 × 9, and the apple boundary is selected the largest area among the filled areas. Then, if only the outer apple boundary is connected by applying the convex hull algorithm, only a perfect apple region is finally extracted. The finally extracted apples are as shown in
Figure 7d.
Step 3. Crop the apple area: we estimate the smallest rectangle that encloses the apples, returning a 4-dimention of type
where
is the upper-left coordinate and
is the height and width of the rectangle. In general, the input image for training a CNN model is a square. We normalize this vector so that it has the smallest square that binds the complete segmented apples obtained in step 2. If
is higher than
, Equation (4) is followed. Otherwise,
is lower than
according to Equation (5). We cut the apple directly from the original
by adjusting this vector of apple area back to the new vector bbox. For the convenience of cropping the image, bbox is of type
, and, in Equation (6),
is the upper-left coordinate and
is the lower-right coordinate.
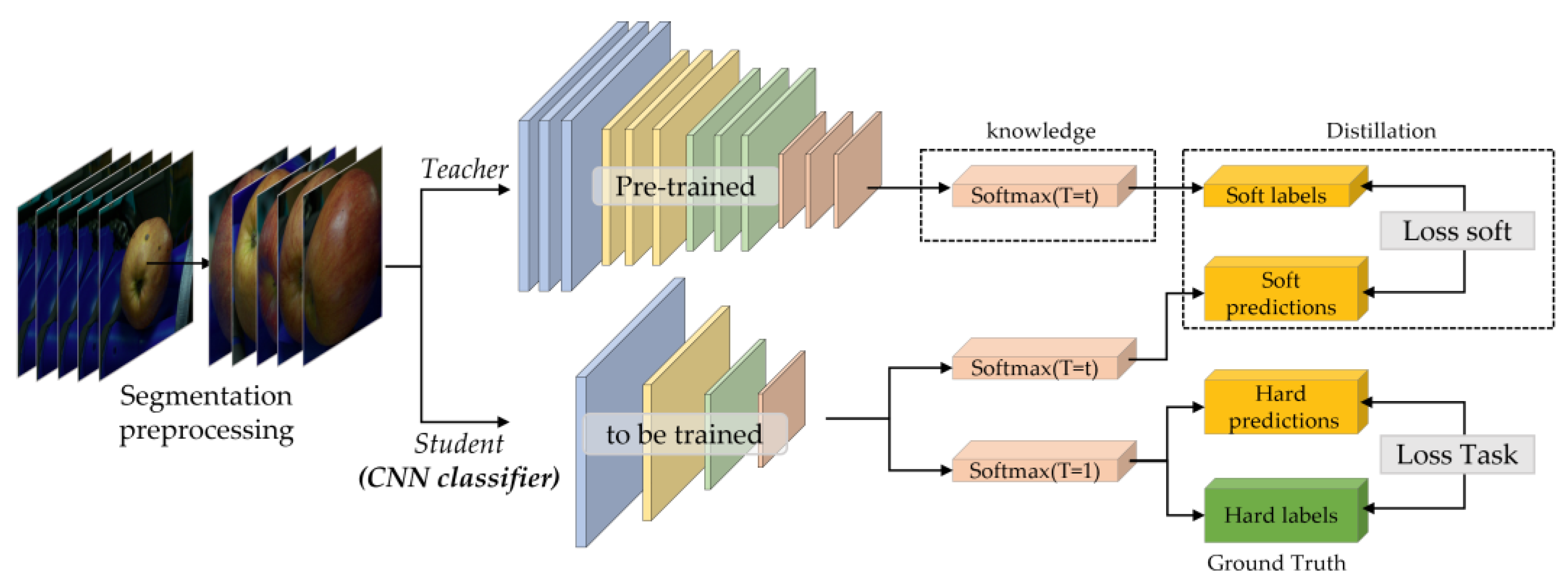
3.4. Knowledge-Distillation-Based Lightweight CNN Classifier
The relationship between the size of deep learning model parameters and their performance has been found to be directly proportional, indicating that an increase in the number of parameters generally leads to improved results. However, developing a lightweight model with an optimal balance between parameter size and performance, particularly in constrained hardware environments such as the system proposed in this paper, is a challenging task. Accordingly, various approaches have been proposed to address this issue. We utilize knowledge distillation (KD) [
33] as a method for developing a lightweight CNN classifier that can efficiently operate within the limited resources of the target hardware system while maintaining high accuracy.
The training process for KD is similar to that of general deep learning training, with one distinction. In traditional deep neural network training, a softmax function is applied to generate a probability value for each class before the final layer. The softmax function is expressed as follows, assuming the logit is
, and the probability of each class is
.
Softmax is commonly used as an activation function in deep learning, including in knowledge distillation. However, the use of softmax in knowledge distillation can pose a problem due to the fact that it maps the largest input value close to 1 and the remaining inputs close to 0, which can cause even minor variations in input values to result in significant output changes. This can reduce the impact of smaller input information and compromise the regularization effect.
To overcome this problem, a hyperparameter known as Temperature () is introduced in knowledge distillation as shown in Equation (8). This parameter scales the softmax function, producing a softer probability distribution as its value increases. When , the distribution corresponds to the standard softmax function. Increasing leads to a softer distribution, where lower probabilities are given more weight, and high probabilities are given less emphasis.
Kullback–Leibler divergence (KL divergence) is a measure of how one probability distribution differs from another probability distribution. In KD, KL divergence is used to calculate the difference between the soft-target probability distribution obtained from the teacher model and the ground truth distribution. Thus, during the training process, the teacher model provides a soft-target probability distribution as a guide for the student model to learn from. This soft-target distribution is typically obtained by applying a softmax activation to the output of the teacher model. The student model then learns to approximate the soft-target distribution using its own output.
KL divergence is used to measure the difference between the soft-target distribution and the ground truth distribution. The ground truth distribution represents the true probability distribution of the target labels. The KL divergence measures the amount of information lost when the soft-target distribution is used to approximate the ground truth distribution.
By minimizing the KL divergence between the soft-target distribution and the ground truth distribution, the student model is encouraged to learn from the teacher model’s knowledge as shown in Equations (9)–(11). Here, () is the logit value of the teacher model, and ) is the logit value of the student model in Equation (9). In this way, KD can help the student model achieve better performance than it would have otherwise by leveraging the knowledge contained in the teacher model.
Meanwhile, the teacher refers to the large deep learning model, while the student refers to a smaller model that aims to learn from the teacher’s knowledge. Specifically, the teacher model transfers its learned weights and biases to the student model to assist its training. This knowledge transfer is then utilized by the student model to learn from its own set of data. From this perspective, it can be argued that the performance of knowledge distillation in image recognition tasks is heavily dependent on the performance of the teacher model. Considering this, we have selected the well-trained deep neural networks EfficientNet [
34] and RegNet [
35], which have demonstrated impressive performance on datasets such as CIFAR-10, CIFAR-100, SVHN, and ImageNet, to serve as our teacher models. In this study, we fine-tune the pre-trained teacher model on the ImageNet dataset to train SDA dataset.
For the teacher model, we chose both large and medium-sized models (EfficientNet-B4 and B7 and RegNetY-8.0GF and 3.2GF) from EfficientNet and RegNet. Additionally, we then trained the student model ResNet18 [
36] on the same dataset using the KD framework, as depicted in
Figure 8. The student model, which was trained using the KD process, fulfills the role of a CNN classifier in our system.
According to TensorFlow Hub, ResNet50 is the most popular among large-capacity models that achieve high performance, as it has demonstrated stable performance in various research and development projects [
37]. Therefore, we considered using ResNet50 in our system, but it is already a large model to be used on our embedded board. As a result, we used the shallowest model in the ResNet family ResNet18 and designed a smaller-sized model than the original ResNet18 for use in the KD process. The design of this model is as follows:
The student model ResNet18 is a deep neural network consisting of 18 layers and 5 blocks (A, B, C, D, E), along with fully connected layers. Each block, except for blocks A and B, is composed of a Convolution Block and an Identity Block. We adopt the ResNet18 architecture but reduce all channel sizes to half for a lightweight model, as illustrated in
Figure 9. As a result, the output feature map from Block A is 56 × 56 × 32. The feature map sequentially passes through each layer, and adaptive average pooling is applied to obtain a 7 × 7 × 256 feature map, which is fully connected to two neurons. Finally, the softmax function is utilized to determine the probability of belonging to each of the two classes based on the output values of the two neurons.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}