
Multi-Object Multi-Camera Tracking Based on Deep Learning for Intelligent Transportation: A Review


Abstract
:1. Introduction
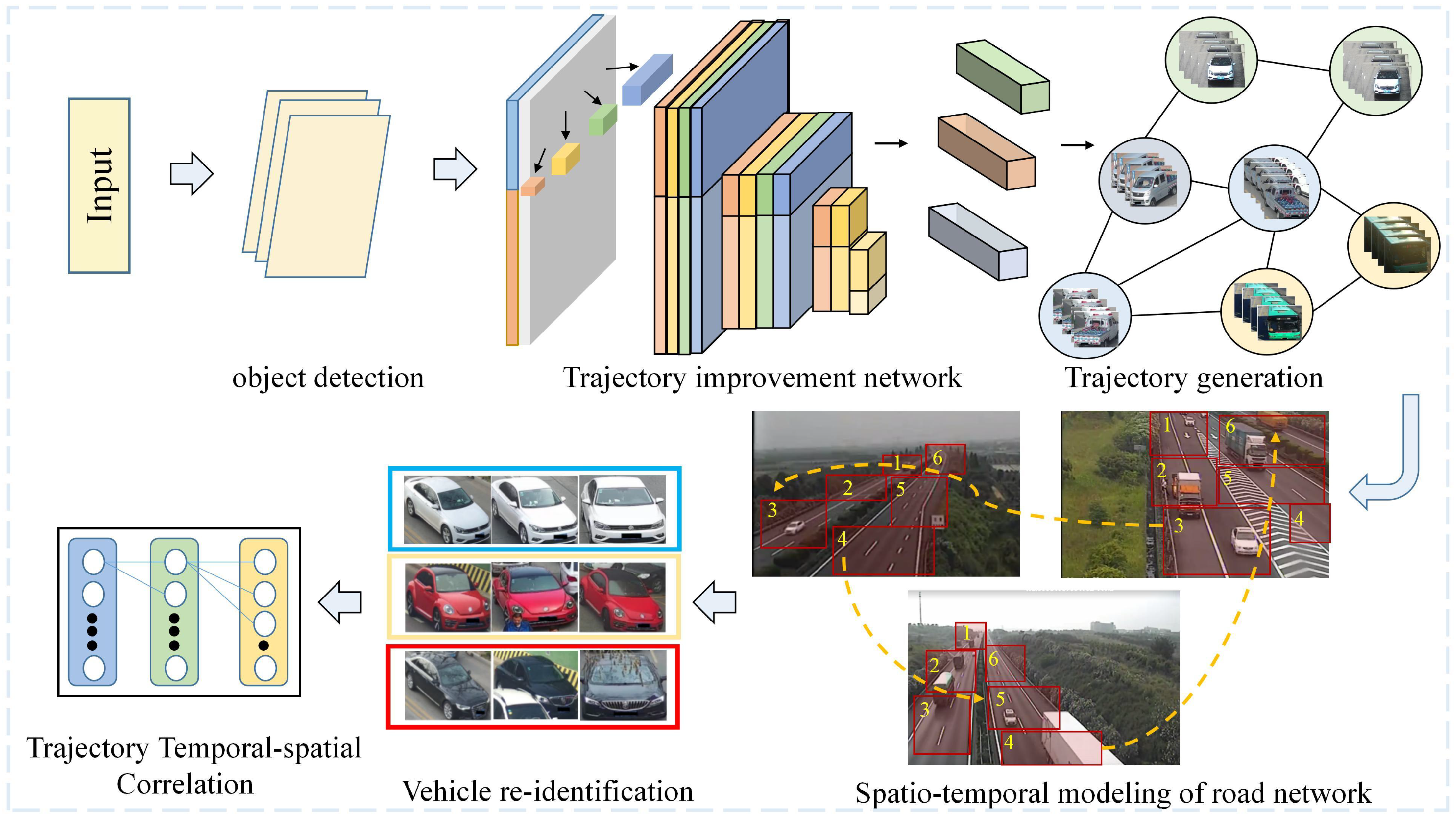
- We provide a comprehensive overview of the application based on deep learning technology in multi-object multi-camera tracking tasks. We have classified and summarised the different stages of deep learning-based MOMCT algorithms, including object detection, object tracking, vehicle re-identification and multi-object cross-camera tracking.
- We have aggregated the most commonly benchmark datasets and standard metrics for MOMCT. We have combined various data for experimental visualisation and comprehensive metrics evaluation of the main algorithms in MOMCT.
- We discuss the challenges MOMCT has faced in recent years from several perspectives, as well as the main application scenarios in practice, and explore potential future directions for MOMCT.

2. Overview of Object Detector
2.1. Two-Stage vs. Single-Stage Object Detectors
2.2. 2D vs. 3D Object Detectors

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Year | Type | Dataset | mAP | Inference Rate (FPS) |
|---|---|---|---|---|---|
| YOLOv1 [27] | 2016 | 2D | Pascal VOC | 63.4% | 45 |
| YOLOv2 [28] | 2016 | Pascal VOC | 78.6% | 67 | |
| YOLOv3 [29] | 2018 | COCO | 44.3% | 95.2 | |
| YOLOv4 [39] | 2020 | COCO | 65.7% | 62 | |
| YOLOv5 [40] | 2021 | COCO | 56.4% | 140 | |
| YOLOX [41] | 2021 | COCO | 51.2% | 57.8 | |
| YOLOR [42] | 2021 | COCO | 74.3% | 30 | |
| R-CNN [21] | 2014 | Pascal VOC | 66% | 0.02 | |
| Fast R-CNN [22] | 2015 | Pascal VOC | 68.8% | 0.5 | |
| Faster R-CNN [23] | 2016 | COCO | 78.9% | 7 | |
| SSD [30] | 2016 | Pascal VOC | 74.3% | 59 | |
| RetinaNet [31] | 2018 | COCO | 61.1% | 90 | |
| Complex-YOLO [37] | 2018 | 3D | KITTI | 64% | 50.4 |
| Complexer-YOLO [37] | 2019 | KITTI | 49.44% | 100 | |
| Wen et al. [38] | 2021 | KITTI | 73.76% | 17.8 |
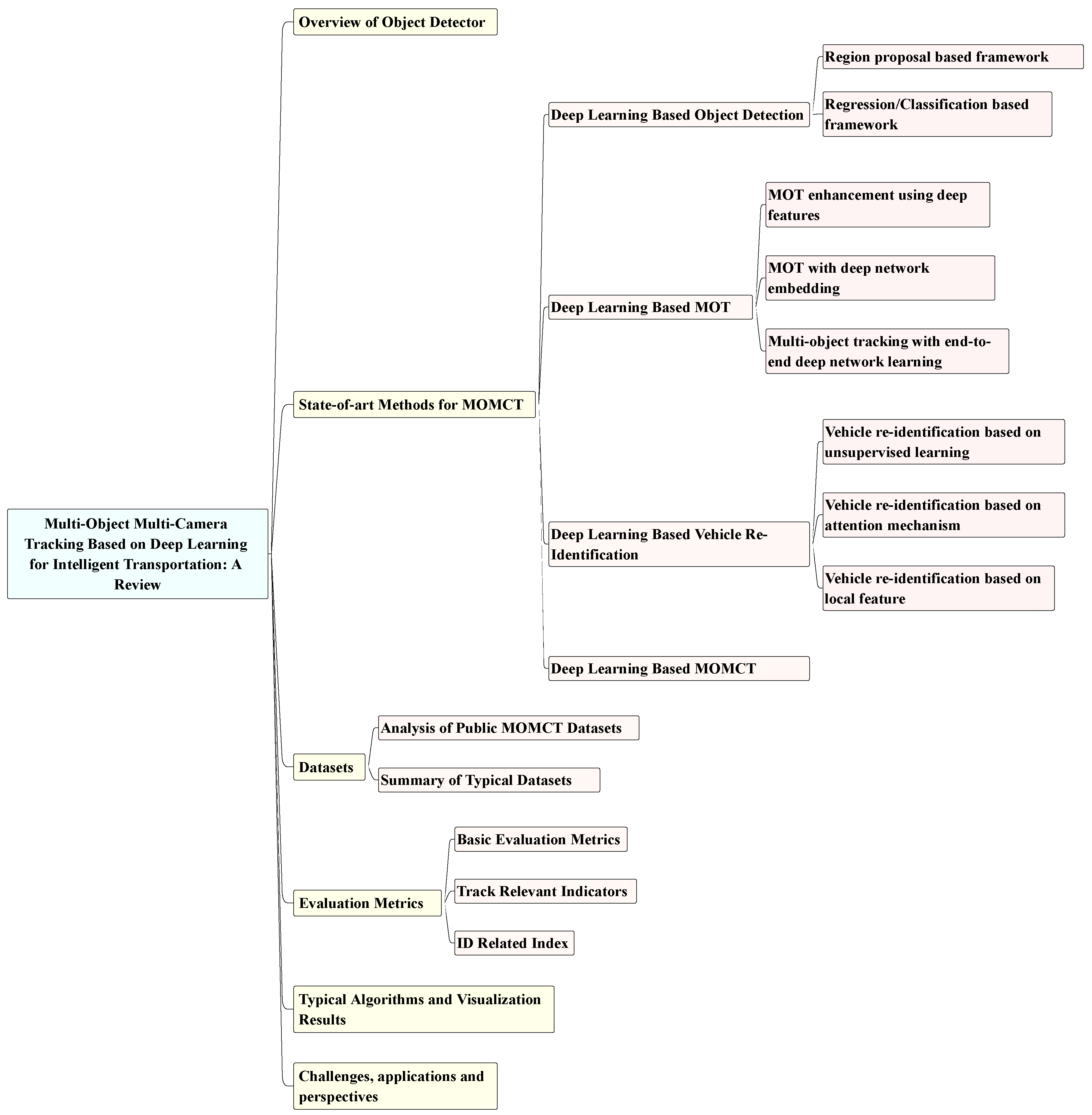
3. State-of-Art Methods for MOMCT
3.1. Deep Learning Based Object Detection
3.1.1. Region Proposal Based Framework
- (1)
- R-CNN
- (2)
- R-FCN
3.1.2. Regression/Classification Based Framework
- (1)
- YOLO
- (2)
- SSD
3.2. Deep Learning Based MOT
3.2.1. MOT Enhancement Using Deep Features
3.2.2. MOT with Deep Network Embedding
3.2.3. MOT with End-to-End Deep Network Learning
3.3. Deep -Learning-Based Vehicle Re-Identification
3.3.1. Vehicle Re-Identification Based on Unsupervised Learning
3.3.2. Vehicle Re-Identification Based on Attention Mechanism
3.3.3. Vehicle Re-Identification Based on Local Feature
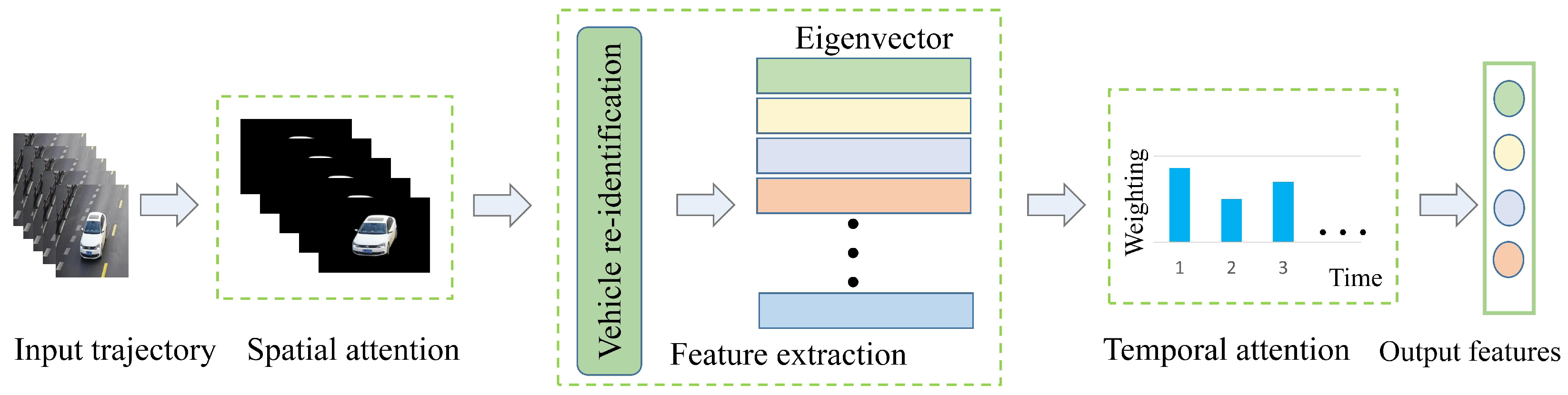
3.4. Deep Learning Based Multi-Object Multi-Camera Tracking
4. Datasets
4.1. Analysis of Public MOMCT Datasets
4.1.1. BDD100K Dataset
4.1.2. VehicleX Dataset
4.1.3. UA-DETRAC Dataset
4.1.4. KITTI Dataset
4.1.5. Nuscenes Dataset
4.2. Summary of Typical Datasets
5. Evaluation Metrics
5.1. Basic Evaluation Metrics
- (1)
- TP: True Positive is a positive sample that is predicted to be positive by the model, which can be referred to as the percentage of correct judgments that are positive.
- (2)
- TN: True Negative is a negative sample that is predicted to be negative by the model and can be referred to as the percentage of correct judgments that are negative.
- (3)
- FP: False Positive is a negative sample that is predicted to be positive by the model and can be referred to as the false positive rate.
- (4)
- FN: False Negative refers to positive samples that are predicted to be negative by the model and can be referred to as the under-reporting rate.
- (5)
- Accuracy: This refers to the weighting of the correct decision by the classifier, and is publicly expressed as.
- (6)
- Precision: Its the proportion of true positive samples among the positive examples determined by the classifier, expressed publicly as.
- (7)
- Recall: Its the proportion of positive cases correctly determined by the classifier to the total number of positive cases, expressed publicly as.
5.2. Track Relevant Indicators
- (1)
- MOTA [143]: MOT Accuracy is a measure of single-camera MOT accuracy and is publicly represented as.where is the sum of the false negatives of all frames, i.e., assuming that is the false negative of frame t, then . Similarly, . T is the sum of the number of real objects in all frames, i.e., assuming that there are objects in frame t, then . is the number of object jumps in all frames, is the number of object jumps in frame t, then . In other words, these three items represent the missing rate, the false positive rate, and the mismatch rate in that order. The closer MOTA is to 1 the better the tracker performance.
- (2)
- MOTP [143]: MOT accuracy is a measure of single-camera MOT position error, expressed by the formula.where denotes the number of matches at frame t. For each pair of matches, the matching error , represents the distance between the object , and its pairing hypothesis position at frame t.
- (3)
- MT: Mostly tracked is the number of tracks where the tracked portion is greater than 80%, the larger the value the better.
- (4)
- ML: Mostly lost is the number of tracks where the lost portion is greater than 80%, the smaller the value the better.
- (5)
- Frag: The number of jumps is the number of track changes from “tracking” to “not tracking” state.
5.3. ID Related Index
- (1)
- IDP: Identification Precision is the accuracy of vehicle ID identification in each bounding box. The formula is:where and are the number of true IDs and the number of false positive IDs, respectively.
- (2)
- IDR: Identification Recall is the recall rate of vehicle ID identification in each bounding box. The formula is:where is the negative ID number.
- (3)
- IDF1: Identification F-Score is the F-value of the vehicle ID identification in each bounding box. The formula is:In general, IDF1 is the first default metric used to evaluate the performance of the tracker. These three metrics can be inferred from any two of them, so it is also possible to show only two of them, although it is preferable that these two include IDF1.
- (4)
- IDS: The number of ID switches is the number of instantaneous vehicle ID transitions in the tracking track, usually reflecting the stability of the tracking, the smaller the value the better.
6. Typical Algorithms and Visualization Results
6.1. Comparison and Analysis of Algorithms
- (1)
- GCNM: After associating the object trajectory, the algorithm uses the graph convolution network to form the global trajectory. Then on the trajectory level, instant erasure and random horizontal flip are used to expand the data, which enhances the data robustness of the camera. Finally, the new loss function improves the generalization ability of the model, thus obtaining good performance in data accuracy.
- (2)
- UWIPL: This method generates a motion track by using its appearance and time information. The system takes ResNet50 as the backbone network and combines Xent loss and Htri loss for training. The tracking accuracy is improved based on road channelization and road condition information, and the applicability of this method in different scenarios is realized.
- (3)
- ANU: It provides fine-grained features by using road spatio-temporal information and camera topology information. Removing overlapping bounding boxes by non-maximum suppression. At the same time, it also uses the color dithering mechanism to improve the performance of the model.
- (4)
- BUPT: It utilizes ResNet network as the backbone network and uses random filling and erasing methods to fill data. Then, it trains the framework by combining trajectory consistency loss and clustering loss. Finally, a higher IDF1 is obtained by introducing temporal and spatial clues.
- (5)
- DyGLIP: It has better lost trajectory recovery and better feature representation during camera overload. By adding correlation regression and attention module in the experiment, the scalability of the model in large-scale data sets is improved.
- (6)
- Online-MTMC: It solves the MOMCT problem by using the detection-clustering method. The feature pyramid network is used as the backbone network, and the quality of features is improved by Gaussian blur and contrast disturbance mechanism. This method also employs the minimum loss function to optimize the network parameters.
- (7)
- ELECTRICITY: It applies a cluster loss strategy to remove isolated tracks and synchronise track ID based on the re-identification results. Meanwhile, depth ranking is considered as a tracking model and Adagrad is applied as a loss function to optimise the model, which makes the algorithm suitable for large-scale realistic intelligent traffic scenes.
- (8)
- NCCU: It adopts vehicle image features and geometric factors for collaborative optimization matching. Then, FBG analysis is used to generate the mask of road region of interest, which effectively solves the problem of finding broken down vehicles on the road.
6.2. Visualization Results and Analysis
- (1)
- ANU adjusts the thresholds of positive and negative sample pairs by increasing the perception of locality in small scenes. The non-maximum suppression mechanism also removes some of the overlapping bounding boxes and retains those close to the camera, improving the success rate of tracking to the vehicle.
- (2)
- UWIPL combines camera linking and deep feature re-identification of trajectories, uses the appearance and time information of trajectories for high confidence matching, and uses a greedy algorithm to select the smallest pairwise distance to match the vehicle being tracked, resulting in accurate tracking results in different scenarios.
- (3)
- ELECTRICITY combines MOMCT strategy and aggregation loss to eliminate the erroneous trajectories. It tracks objects mainly through re-identification, and further improves the robustness of the algorithm through image flipping and random erasure.
- (4)
- BUPT system combines the loss of trajectory consistency with the loss of clustering, and extracts more obvious features. The cluster loss used in the method improves the tracking accuracy.
7. Challenges, Applications and Perspectives
7.1. Challenges and Opportunities
- (1)
- Real-time processing
- (2)
- Semi-supervised object detection
- (3)
- Publicly available datasets
7.2. Applications
- (1)
- Intelligent transportation
- (2)
- Intelligent surveillance
- (3)
- Automated driving
7.3. Outlook
- (1)
- Learning-based active tracking
- (2)
- Multi-view information fusion
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Wang, Z.; Zheng, L.; Liu, Y.; Li, Y.; Wang, S. Towards real-time multi-object tracking. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XI 16; Springer: Cham, Switzerland, 2020; pp. 107–122. [Google Scholar]
- Tang, Z.; Naphade, M.; Liu, M.Y.; Yang, X.; Birchfield, S.; Wang, S.; Kumar, R.; Anastasiu, D.; Hwang, J.N. Cityflow: A city-scale benchmark for multi-target multi-camera vehicle tracking and re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–19 June 2019; pp. 8797–8806. [Google Scholar]
- Wang, W.; Wang, L.; Zhang, C.; Liu, C.; Sun, L. Social interactions for autonomous driving: A review and perspectives. Found. Trends Robot. 2022, 10, 198–376. [Google Scholar] [CrossRef]
- Bendali-Braham, M.; Weber, J.; Forestier, G.; Idoumghar, L.; Muller, P.A. Recent trends in crowd analysis: A review. Mach. Learn. Appl. 2021, 4, 100023. [Google Scholar] [CrossRef]
- Cao, J.; Weng, X.; Khirodkar, R.; Pang, J.; Kitani, K. Observation-centric sort: Rethinking sort for robust multi-object tracking. arXiv 2022, arXiv:2203.14360. [Google Scholar]
- Zhang, Y.; Wang, Q.; Zhao, A.; Ke, Y. A multi-object posture coordination method with tolerance constraints for aircraft components assembly. Assem. Autom. 2020, 40, 345–359. [Google Scholar] [CrossRef]
- Liu, Q.; Chen, D.; Chu, Q.; Yuan, L.; Liu, B.; Zhang, L.; Yu, N. Online multi-object tracking with unsupervised re-identification learning and occlusion estimation. Neurocomputing 2022, 483, 333–347. [Google Scholar] [CrossRef]
- Parashar, A.; Shekhawat, R.S.; Ding, W.; Rida, I. Intra-class variations with deep learning-based gait analysis: A comprehensive survey of covariates and methods. Neurocomputing 2022, 505, 315–338. [Google Scholar] [CrossRef]
- Zhang, Z.; Wang, S.; Liu, C.; Xie, R.; Hu, W.; Zhou, P. All-in-one two-dimensional retinomorphic hardware device for motion detection and recognition. Nat. Nanotechnol. 2022, 17, 27–32. [Google Scholar] [CrossRef]
- Jiang, D.; Li, G.; Tan, C.; Huang, L.; Sun, Y.; Kong, J. Semantic segmentation for multiscale target based on object recognition using the improved Faster-RCNN model. Future Gener. Comput. Syst. 2021, 123, 94–104. [Google Scholar] [CrossRef]
- Li, X.; Zhao, H.; Yu, L.; Chen, H.; Deng, W.; Deng, W. Feature extraction using parameterized multisynchrosqueezing transform. IEEE Sens. J. 2022, 22, 14263–14272. [Google Scholar] [CrossRef]
- Zaidi, S.S.A.; Ansari, M.S.; Aslam, A.; Kanwal, N.; Asghar, M.; Lee, B. A survey of modern deep learning based object detection models. Digit. Signal Process. 2022, 126, 103514. [Google Scholar] [CrossRef]
- Jiménez-Bravo, D.M.; Murciego, Á.L.; Mendes, A.S.; San Blás, H.S.; Bajo, J. Multi-object tracking in traffic environments: A systematic literature review. Neurocomputing 2022, 494, 43–55. [Google Scholar] [CrossRef]
- Khan, S.D.; Ullah, H. A survey of advances in vision-based vehicle re-identification. Comput. Vis. Image Underst. 2019, 182, 50–63. [Google Scholar] [CrossRef] [Green Version]
- Dong, C.; Zhou, J.; Wen, W.; Chen, S. Deep Learning Based Multi-Target Multi-Camera Tracking System. In Proceedings of the 8th International Conference on Computing and Artificial Intelligence, Tianjin, China, 18–21 May 2022; pp. 419–424. [Google Scholar]
- Luo, R.; Peng, Z.; Hu, J. On Model Identification Based Optimal Control and It’s Applications to Multi-Agent Learning and Control. Mathematics 2023, 11, 906. [Google Scholar] [CrossRef]
- Iguernaissi, R.; Merad, D.; Aziz, K.; Drap, P. People tracking in multi-camera systems: A review. Multimed. Tools Appl. 2019, 78, 10773–10793. [Google Scholar] [CrossRef]
- Sufi, F.B.; Gazzano, J.D.D.; Calle, F.R.; Lopez, J.C.L. Multi-camera tracking system applications based on reconfigurable devices: A review. In Proceedings of the 2019 International Conference on Computer, Communication, Chemical, Materials and Electronic Engineering (IC4ME2), Rajshahi, Bangladesh, 11–12 July 2019; pp. 1–5. [Google Scholar]
- Wang, X. Intelligent multi-camera video surveillance: A review. Pattern Recognit. Lett. 2013, 34, 3–19. [Google Scholar] [CrossRef]
- Olagoke, A.S.; Ibrahim, H.; Teoh, S.S. Literature survey on multi-camera system and its application. IEEE Access 2020, 8, 172892–172922. [Google Scholar] [CrossRef]
- Bharati, P.; Pramanik, A. Deep learning techniques—R-CNN to mask R-CNN: A survey. In Computational Intelligence in Pattern Recognition: Proceedings of CIPR 2019; Springer: Singapore, 2020; pp. 657–668. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Jiang, M.; Gu, L.; Li, X.; Gao, F.; Jiang, T. Ship Contour Extraction from SAR images Based on Faster R-CNN and Chan-Vese model. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5203414. [Google Scholar] [CrossRef]
- Felzenszwalb, P.F.; Girshick, R.B.; McAllester, D.; Ramanan, D. Object detection with discriminatively trained part-based models. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 32, 1627–1645. [Google Scholar] [CrossRef] [Green Version]
- Chen, M.; Yu, L.; Zhi, C.; Sun, R.; Zhu, S.; Gao, Z.; Ke, Z.; Zhu, M.; Zhang, Y. Improved faster R-CNN for fabric defect detection based on Gabor filter with Genetic Algorithm optimization. Comput. Ind. 2022, 134, 103551. [Google Scholar] [CrossRef]
- Maity, M.; Banerjee, S.; Chaudhuri, S.S. Faster r-cnn and yolo based vehicle detection: A survey. In Proceedings of the 2021 5th International Conference on Computing Methodologies and Communication (ICCMC), Erode, India, 8–10 April 2021; pp. 1442–1447. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11–14, 2016, Proceedings, Part I 14; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Tiwari, V.; Singhal, A.; Dhankhar, N. Detecting COVID-19 Opacity in X-ray Images Using YOLO and RetinaNet Ensemble. In Proceedings of the 2022 IEEE Delhi Section Conference (DELCON), New Delhi, India, 11–13 February 2022; pp. 1–5. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Peng, X.; Sun, B.; Ali, K.; Saenko, K. Learning deep object detectors from 3d models. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1278–1286. [Google Scholar]
- Wang, L.; Chen, T.; Anklam, C.; Goldluecke, B. High dimensional frustum pointnet for 3D object detection from camera, lidar, and radar. In Proceedings of the 2020 IEEE Intelligent Vehicles Symposium (IV), Las Vegas, NV, USA, 19 October–13 November 2020; pp. 1621–1628. [Google Scholar]
- Guo, Y.; Wang, H.; Hu, Q.; Liu, H.; Liu, L.; Bennamoun, M. Deep learning for 3d point clouds: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 4338–4364. [Google Scholar] [CrossRef] [PubMed]
- Pan, X.; Xia, Z.; Song, S.; Li, L.E.; Huang, G. 3D object detection with pointformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 7463–7472. [Google Scholar]
- Simon, M.; Milz, S.; Amende, K.; Gross, H.M. Complex-yolo: Real-time 3d object detection on point clouds. arXiv 2018, arXiv:1803.06199. [Google Scholar]
- Wen, L.H.; Jo, K.H. Fast and accurate 3D object detection for lidar-camera-based autonomous vehicles using one shared voxel-based backbone. IEEE Access 2021, 9, 22080–22089. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Wu, W.; Liu, H.; Li, L.; Long, Y.; Wang, X.; Wang, Z.; Li, J.; Chang, Y. Application of local fully Convolutional Neural Network combined with YOLO v5 algorithm in small target detection of remote sensing image. PLoS ONE 2021, 16, e0259283. [Google Scholar] [CrossRef]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. Yolox: Exceeding yolo series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Wang, C.Y.; Yeh, I.H.; Liao, H.Y.M. You only learn one representation: Unified network for multiple tasks. arXiv 2021, arXiv:2105.04206. [Google Scholar]
- Sermanet, P.; Eigen, D.; Zhang, X.; Mathieu, M.; Fergus, R.; LeCun, Y. Overfeat: Integrated recognition, localization and detection using convolutional networks. arXiv 2013, arXiv:1312.6229. [Google Scholar]
- Hinton, G.E.; Krizhevsky, A.; Wang, S.D. Transforming auto-encoders. In Artificial Neural Networks and Machine Learning–ICANN 2011: 21st International Conference on Artificial Neural Networks, Espoo, Finland, June 14–17, 2011, Proceedings, Part I 21; Springer: Berlin/Heidelberg, Germany, 2011; pp. 44–51. [Google Scholar]
- Taylor, G.W.; Spiro, I.; Bregler, C.; Fergus, R. Learning invariance through imitation. In Proceedings of the CVPR 2011, Colorado Springs, CO, USA, 20–25 June 2011; pp. 2729–2736. [Google Scholar]
- Aliasghar, O.; Kanani Moghadam, V. Selective search and new-to-market process innovation. J. Manuf. Technol. Manag. 2022, 33, 1301–1318. [Google Scholar] [CrossRef]
- Li, Y.; Shen, Y.; Zhang, W.; Zhang, C.; Cui, B. VolcanoML: Speeding up end-to-end AutoML via scalable search space decomposition. VLDB J. 2022, 32, 389–413. [Google Scholar] [CrossRef]
- Daulton, S.; Eriksson, D.; Balandat, M.; Bakshy, E. Multi-objective bayesian optimization over high-dimensional search spaces. In Proceedings of the Thirty-Eighth Conference on Uncertainty in Artificial Intelligence, Eindhoven, The Netherlands, 1–5 August 2022; pp. 507–517. [Google Scholar]
- Xie, X.; Cheng, G.; Wang, J.; Yao, X.; Han, J. Oriented R-CNN for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 3520–3529. [Google Scholar]
- Hong, Q.; Liu, F.; Li, D.; Liu, J.; Tian, L.; Shan, Y. Dynamic sparse r-cnn. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 4723–4732. [Google Scholar]
- Ali, R.; Chuah, J.H.; Talip, M.S.A.; Mokhtar, N.; Shoaib, M.A. Structural crack detection using deep convolutional neural networks. Autom. Constr. 2022, 133, 103989. [Google Scholar] [CrossRef]
- Wang, X.; Wang, L.; Zheng, P. SC-dynamic R-CNN: A self-calibrated dynamic R-CNN model for lung cancer lesion detection. Comput. Math. Methods Med. 2022, 2022, 9452157. [Google Scholar] [CrossRef] [PubMed]
- Alsharekh, M.F.; Habib, S.; Dewi, D.A.; Albattah, W.; Islam, M.; Albahli, S. Improving the Efficiency of Multistep Short-Term Electricity Load Forecasting via R-CNN with ML-LSTM. Sensors 2022, 22, 6913. [Google Scholar] [CrossRef] [PubMed]
- Ma, W.; Zhou, T.; Qin, J.; Zhou, Q.; Cai, Z. Joint-attention feature fusion network and dual-adaptive NMS for object detection. Knowl.-Based Syst. 2022, 241, 108213. [Google Scholar] [CrossRef]
- Zhang, S.; Yu, Z.; Liu, L.; Wang, X.; Zhou, A.; Chen, K. Group R-CNN for weakly semi-supervised object detection with points. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 9417–9426. [Google Scholar]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-fcn: Object detection via region-based fully convolutional networks. Adv. Neural Inf. Process. Syst. 2016, 29, 1–9. [Google Scholar]
- Vijaya Kumar, D.; Mahammad Shafi, R. A fast feature selection technique for real-time face detection using hybrid optimized region based convolutional neural network. Multimed. Tools Appl. 2022, 82, 13719–13732. [Google Scholar] [CrossRef]
- Zhang, R.; Song, Y. Non-intrusive load identification method based on color encoding and improve R-FCN. Sustain. Energy Technol. Assess. 2022, 53, 102714. [Google Scholar] [CrossRef]
- Roy, A.M.; Bhaduri, J.; Kumar, T.; Raj, K. WilDect-YOLO: An efficient and robust computer vision-based accurate object localization model for automated endangered wildlife detection. Ecol. Inform. 2023, 75, 101919. [Google Scholar] [CrossRef]
- Karaman, A.; Pacal, I.; Basturk, A.; Akay, B.; Nalbantoglu, U.; Coskun, S.; Sahin, O.; Karaboga, D. Robust real-time polyp detection system design based on YOLO algorithms by optimizing activation functions and hyper-parameters with artificial bee colony (ABC). Expert Syst. Appl. 2023, 221, 119741. [Google Scholar] [CrossRef]
- Xue, Z.; Xu, R.; Bai, D.; Lin, H. YOLO-Tea: A Tea Disease Detection Model Improved by YOLOv5. Forests 2023, 14, 415. [Google Scholar] [CrossRef]
- Mittal, U.; Chawla, P.; Tiwari, R. EnsembleNet: A hybrid approach for vehicle detection and estimation of traffic density based on faster R-CNN and YOLO models. Neural Comput. Appl. 2023, 35, 4755–4774. [Google Scholar] [CrossRef]
- Han, G.; Huang, S.; Ma, J.; He, Y.; Chang, S.F. Meta faster r-cnn: Towards accurate few-shot object detection with attentive feature alignment. Proc. AAAI Conf. Artif. Intell. 2022, 36, 780–789. [Google Scholar] [CrossRef]
- Cuomo, S.; Di Cola, V.S.; Giampaolo, F.; Rozza, G.; Raissi, M.; Piccialli, F. Scientific machine learning through physics–informed neural networks: Where we are and what is next. J. Sci. Comput. 2022, 92, 88. [Google Scholar] [CrossRef]
- Jia, D.; Zhou, J.; Zhang, C. Detection of cervical cells based on improved SSD network. Multimed. Tools Appl. 2022, 81, 13371–13387. [Google Scholar] [CrossRef]
- Chen, Z.; Guo, H.; Yang, J.; Jiao, H.; Feng, Z.; Chen, L.; Gao, T. Fast vehicle detection algorithm in traffic scene based on improved SSD. Measurement 2022, 201, 111655. [Google Scholar] [CrossRef]
- Gao, X.; Xu, J.; Luo, C.; Zhou, J.; Huang, P.; Deng, J. Detection of Lower Body for AGV Based on SSD Algorithm with ResNet. Sensors 2022, 22, 2008. [Google Scholar] [CrossRef]
- Ma, R.; Chen, C.; Yang, B.; Li, D.; Wang, H.; Cong, Y.; Hu, Z. CG-SSD: Corner guided single stage 3D object detection from LiDAR point cloud. ISPRS J. Photogramm. Remote Sens. 2022, 191, 33–48. [Google Scholar] [CrossRef]
- Cheng, L.; Ji, Y.; Li, C.; Liu, X.; Fang, G. Improved SSD network for fast concealed object detection and recognition in passive terahertz security images. Sci. Rep. 2022, 12, 12082. [Google Scholar] [CrossRef]
- Cao, H.; Wang, Y.; Chen, J.; Jiang, D.; Zhang, X.; Tian, Q.; Wang, M. Swin-unet: Unet-like pure transformer for medical image segmentation. In Computer Vision–ECCV 2022 Workshops: Tel Aviv, Israel, October 23–27, 2022, Proceedings, Part III; Springer: Cham, Switzerland, 2023; pp. 205–218. [Google Scholar]
- Kim, H.; Jung, W.K.; Park, Y.C.; Lee, J.W.; Ahn, S.H. Broken stitch detection method for sewing operation using CNN feature map and image-processing techniques. Expert Syst. Appl. 2022, 188, 116014. [Google Scholar] [CrossRef]
- Chen, H.C.; Widodo, A.M.; Wisnujati, A.; Rahaman, M.; Lin, J.C.W.; Chen, L.; Weng, C.E. AlexNet convolutional neural network for disease detection and classification of tomato leaf. Electronics 2022, 11, 951. [Google Scholar] [CrossRef]
- Kim, C.; Li, F.; Ciptadi, A.; Rehg, J.M. Multiple hypothesis tracking revisited. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 4696–4704. [Google Scholar]
- Wang, S.; Sheng, H.; Yang, D.; Zhang, Y.; Wu, Y.; Wang, S. Extendable multiple nodes recurrent tracking framework with RTU++. IEEE Trans. Image Process. 2022, 31, 5257–5271. [Google Scholar] [CrossRef] [PubMed]
- Wojke, N.; Bewley, A.; Paulus, D. Simple online and realtime tracking with a deep association metric. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 3645–3649. [Google Scholar]
- Leal-Taixé, L.; Canton-Ferrer, C.; Schindler, K. Learning by tracking: Siamese CNN for robust target association. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Las Vegas, NV, USA, 27–30 June 2016; pp. 33–40. [Google Scholar]
- Zhang, J.; Sun, J.; Wang, J.; Li, Z.; Chen, X. An object tracking framework with recapture based on correlation filters and Siamese networks. Comput. Electr. Eng. 2022, 98, 107730. [Google Scholar] [CrossRef]
- Su, Q.; Tang, J.; Zhai, M.; He, D. An intelligent method for dairy goat tracking based on Siamese network. Comput. Electron. Agric. 2022, 193, 106636. [Google Scholar] [CrossRef]
- Chen, L.; Ai, H.; Shang, C.; Zhuang, Z.; Bai, B. Online multi-object tracking with convolutional neural networks. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 645–649. [Google Scholar]
- Theckedath, D.; Sedamkar, R. Detecting affect states using VGG16, ResNet50 and SE-ResNet50 networks. SN Comput. Sci. 2020, 1, 79. [Google Scholar] [CrossRef] [Green Version]
- Chu, Q.; Ouyang, W.; Li, H.; Wang, X.; Liu, B.; Yu, N. Online multi-object tracking using CNN-based single object tracker with spatial-temporal attention mechanism. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4836–4845. [Google Scholar]
- Liu, M.; Gu, Q.; Yang, B.; Yin, Z.; Liu, S.; Yin, L.; Zheng, W. Kinematics Model Optimization Algorithm for Six Degrees of Freedom Parallel Platform. Appl. Sci. 2023, 13, 3082. [Google Scholar] [CrossRef]
- Katz, S.M.; Corso, A.L.; Strong, C.A.; Kochenderfer, M.J. Verification of image-based neural network controllers using generative models. J. Aerosp. Inf. Syst. 2022, 19, 574–584. [Google Scholar] [CrossRef]
- Lu, J.; Wan, H.; Li, P.; Zhao, X.; Ma, N.; Gao, Y. Exploring High-order Spatio-temporal Correlations from Skeleton for Person Re-identification. IEEE Trans. Image Process. 2023, 32, 949–963. [Google Scholar] [CrossRef]
- Hasan, M.R.; Guest, R.; Deravi, F. Presentation-Level Privacy Protection Techniques for Automated Face Recognition—A Survey. ACM Comput. Surv. 2023, Accepted. [Google Scholar] [CrossRef]
- Tang, W.; Chouzenoux, E.; Pesquet, J.C.; Krim, H. Deep transform and metric learning network: Wedding deep dictionary learning and neural network. Neurocomputing 2022, 509, 244–256. [Google Scholar] [CrossRef]
- Son, J.; Baek, M.; Cho, M.; Han, B. Multi-object tracking with quadruplet convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5620–5629. [Google Scholar]
- Xiang, J.; Zhang, G.; Hou, J.; Sang, N.; Huang, R. Multiple target tracking by learning feature representation and distance metric jointly. arXiv 2018, arXiv:1802.03252. [Google Scholar]
- Cheng, D.; Gong, Y.; Zhou, S.; Wang, J.; Zheng, N. Person re-identification by multi-channel parts-based cnn with improved triplet loss function. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1335–1344. [Google Scholar]
- Aggarwal, R.; Singh, N. An Approach to Learn Structural Similarity between Decision Trees Using Hungarian Algorithm. In Proceedings of 3rd International Conference on Recent Trends in Machine Learning, IoT, Smart Cities and Applications: ICMISC 2022; Springer: Singapore, 2023; pp. 185–199. [Google Scholar]
- Fang, K.; Xiang, Y.; Li, X.; Savarese, S. Recurrent autoregressive networks for online multi-object tracking. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; pp. 466–475. [Google Scholar]
- Fernando, T.; Denman, S.; Sridharan, S.; Fookes, C. Tracking by prediction: A deep generative model for mutli-person localisation and tracking. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; pp. 1122–1132. [Google Scholar]
- Ondruska, P.; Posner, I. Deep tracking: Seeing beyond seeing using recurrent neural networks. Proc. AAAI Conf. Artif. Intell. 2016, 30, 10413. [Google Scholar] [CrossRef]
- Milan, A.; Rezatofighi, S.H.; Dick, A.; Reid, I.; Schindler, K. Online multi-target tracking using recurrent neural networks. Proc. AAAI Conf. Artif. Intell. 2017, 31, 11194. [Google Scholar] [CrossRef]
- Sadeghian, A.; Alahi, A.; Savarese, S. Tracking the untrackable: Learning to track multiple cues with long-term dependencies. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 300–311. [Google Scholar]
- Li, D.; Ge, S.S.; Lee, T.H. Fixed-time-synchronized consensus control of multiagent systems. IEEE Trans. Control Netw. Syst. 2020, 8, 89–98. [Google Scholar] [CrossRef]
- Kim, C.; Li, F.; Rehg, J.M. Multi-object tracking with neural gating using bilinear lstm. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 200–215. [Google Scholar]
- Bashir, R.M.S.; Shahzad, M.; Fraz, M. Vr-proud: Vehicle re-identification using progressive unsupervised deep architecture. Pattern Recognit. 2019, 90, 52–65. [Google Scholar] [CrossRef]
- Deng, W.; Zheng, L.; Ye, Q.; Kang, G.; Yang, Y.; Jiao, J. Image-image domain adaptation with preserved self-similarity and domain-dissimilarity for person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 994–1003. [Google Scholar]
- Wang, J.; Zhu, X.; Gong, S.; Li, W. Transferable joint attribute-identity deep learning for unsupervised person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2275–2284. [Google Scholar]
- Shen, F.; Du, X.; Zhang, L.; Tang, J. Triplet Contrastive Learning for Unsupervised Vehicle Re-identification. arXiv 2023, arXiv:2301.09498. [Google Scholar]
- Zhu, W.; Peng, B. Manifold-based aggregation clustering for unsupervised vehicle re-identification. Knowl.-Based Syst. 2022, 235, 107624. [Google Scholar] [CrossRef]
- Wang, Y.; Wei, Y.; Ma, R.; Wang, L.; Wang, C. Unsupervised vehicle re-identification based on mixed sample contrastive learning. Signal Image Video Process. 2022, 16, 2083–2091. [Google Scholar] [CrossRef]
- Gao, Z.; Wu, T.; Lin, L.; Zhao, J.; Zhang, A.; Wu, J. Eliminating domain deviation via synthetic data for vehicle re-identification. In Proceedings of the International Conference on Computer, Artificial Intelligence, and Control Engineering (CAICE 2022), Zhuhai, China, 25–27 February 2022; Volume 12288, pp. 6–11. [Google Scholar]
- Chai, X.; Wang, Y.; Chen, X.; Gan, Z.; Zhang, Y. TPE-GAN: Thumbnail preserving encryption based on GAN with key. IEEE Signal Process. Lett. 2022, 29, 972–976. [Google Scholar] [CrossRef]
- Zhou, Z.; Li, Y.; Li, J.; Yu, K.; Kou, G.; Wang, M.; Gupta, B.B. Gan-siamese network for cross-domain vehicle re-identification in intelligent transport systems. IEEE Trans. Netw. Sci. Eng. 2022, 2022, 3199919. [Google Scholar] [CrossRef]
- Yan, T.; Li, H.; Sun, B.; Wang, Z.; Luo, Z. Discriminative feature mining and enhancement network for low-resolution fine-grained image recognition. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 5319–5330. [Google Scholar] [CrossRef]
- Fayou, S.; Ngo, H.; Sek, Y. Combining multi-feature regions for fine-grained image recognition. Int. J. Image Graph. Signal Process 2022, 14, 15–25. [Google Scholar] [CrossRef]
- Ning, X.; Tian, W.; He, F.; Bai, X.; Sun, L.; Li, W. Hyper-sausage coverage function neuron model and learning algorithm for image classification. Pattern Recognit. 2023, 136, 109216. [Google Scholar] [CrossRef]
- Cenggoro, T.W.; Pardamean, B. A systematic literature review of machine learning application in COVID-19 medical image classification. Procedia Comput. Sci. 2023, 216, 749–756. [Google Scholar]
- Salaberria, A.; Azkune, G.; de Lacalle, O.L.; Soroa, A.; Agirre, E. Image captioning for effective use of language models in knowledge-based visual question answering. Expert Syst. Appl. 2023, 212, 118669. [Google Scholar] [CrossRef]
- Li, Z.; Wei, J.; Huang, F.; Ma, H. Modeling graph-structured contexts for image captioning. Image Vis. Comput. 2023, 129, 104591. [Google Scholar] [CrossRef]
- Zhu, W.; Wang, Z.; Wang, X.; Hu, R.; Liu, H.; Liu, C.; Wang, C.; Li, D. A Dual Self-Attention mechanism for vehicle re-Identification. Pattern Recognit. 2023, 137, 109258. [Google Scholar] [CrossRef]
- Lian, J.; Wang, D.; Zhu, S.; Wu, Y.; Li, C. Transformer-based attention network for vehicle re-identification. Electronics 2022, 11, 1016. [Google Scholar] [CrossRef]
- Jiang, G.; Pang, X.; Tian, X.; Zheng, Y.; Meng, Q. Global reference attention network for vehicle re-identification. Appl. Intell. 2022, 1–16. [Google Scholar] [CrossRef]
- Tian, X.; Pang, X.; Jiang, G.; Meng, Q.; Zheng, Y. Vehicle Re-Identification Based on Global Relational Attention and Multi-Granularity Feature Learning. IEEE Access 2022, 10, 17674–17682. [Google Scholar] [CrossRef]
- Li, M.; Wei, M.; He, X.; Shen, F. Enhancing Part Features via Contrastive Attention Module for Vehicle Re-identification. In Proceedings of the 2022 IEEE International Conference on Image Processing (ICIP), Bordeaux, France, 16–19 October 2022; pp. 1816–1820. [Google Scholar]
- Song, L.; Zhou, X.; Chen, Y. Global attention-assisted representation learning for vehicle re-identification. Signal Image Video Process. 2022, 16, 807–815. [Google Scholar] [CrossRef]
- Li, H.; Wang, Y.; Wei, Y.; Wang, L.; Li, G. Discriminative-region attention and orthogonal-view generation model for vehicle re-identification. Appl. Intell. 2023, 53, 186–203. [Google Scholar] [CrossRef]
- Tang, L.; Wang, Y.; Chau, L.P. Weakly-supervised Part-Attention and Mentored Networks for Vehicle Re-Identification. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 8887–8898. [Google Scholar] [CrossRef]
- Liu, Y.; Hu, H.; Chen, D. Attentive Part-Based Alignment Network for Vehicle Re-Identification. Electronics 2022, 11, 1617. [Google Scholar] [CrossRef]
- Shen, F.; Xie, Y.; Zhu, J.; Zhu, X.; Zeng, H. Git: Graph interactive transformer for vehicle re-identification. arXiv 2021, arXiv:2107.05475. [Google Scholar] [CrossRef] [PubMed]
- Wang, H.; Peng, J.; Jiang, G.; Xu, F.; Fu, X. Discriminative feature and dictionary learning with part-aware model for vehicle re-identification. Neurocomputing 2021, 438, 55–62. [Google Scholar] [CrossRef]
- Rong, L.; Xu, Y.; Zhou, X.; Han, L.; Li, L.; Pan, X. A vehicle re-identification framework based on the improved multi-branch feature fusion network. Sci. Rep. 2021, 11, 20210. [Google Scholar] [CrossRef]
- Yang, J.; Xing, D.; Hu, Z.; Yao, T. A two-branch network with pyramid-based local and spatial attention global feature learning for vehicle re-identification. CAAI Trans. Intell. Technol. 2021, 6, 46–54. [Google Scholar] [CrossRef]
- Fu, X.; Peng, J.; Jiang, G.; Wang, H. Learning latent features with local channel drop network for vehicle re-identification. Eng. Appl. Artif. Intell. 2022, 107, 104540. [Google Scholar] [CrossRef]
- Liu, Y.; Zhang, X.; Zhang, B.; Zhang, X.; Wang, S.; Xu, J. Multi-camera vehicle tracking based on occlusion-aware and inter-vehicle information. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–20 June 2022; pp. 3257–3264. [Google Scholar]
- Hsu, H.M.; Wang, Y.; Cai, J.; Hwang, J.N. Multi-Target Multi-Camera Tracking of Vehicles by Graph Auto-Encoder and Self-Supervised Camera Link Model. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2022; pp. 489–499. [Google Scholar]
- Hsu, H.M.; Wang, Y.; Hwang, J.N. Traffic-aware multi-camera tracking of vehicles based on reid and camera link model. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 964–972. [Google Scholar]
- Li, Y.J.; Weng, X.; Xu, Y.; Kitani, K.M. Visio-temporal attention for multi-camera multi-target association. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 9834–9844. [Google Scholar]
- Liu, C.; Zhang, Y.; Chen, W.; Wang, F.; Li, H.; Shen, Y.D. Adaptive Matching Strategy for Multi-Target Multi-Camera Tracking. In Proceedings of the ICASSP 2022–2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 23–27 May 2022; pp. 2934–2938. [Google Scholar]
- Zhao, J.; Gao, F.; Jia, W.; Yuan, W.; Jin, W. Integrated Sensing and Communications for UAV Communications with Jittering Effect. IEEE Wirel. Commun. Lett. 2023, 2023, 3243590. [Google Scholar] [CrossRef]
- Yang, K.S.; Chen, Y.K.; Chen, T.S.; Liu, C.T.; Chien, S.Y. Tracklet-refined multi-camera tracking based on balanced cross-domain re-identification for vehicles. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 3983–3992. [Google Scholar]
- Li, Y.L.; Chin, Z.Y.; Chang, M.C.; Chiang, C.K. Multi-camera tracking by candidate intersection ratio tracklet matching. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 4103–4111. [Google Scholar]
- Liang, N.S.J.; Srigrarom, S. Multi-camera multi-target drone tracking systems with trajectory-based target matching and re-identification. In Proceedings of the 2021 International Conference on Unmanned Aircraft Systems (ICUAS), Athens, Greece, 15–18 June 2021; pp. 1337–1344. [Google Scholar]
- He, Y.; Han, J.; Yu, W.; Hong, X.; Wei, X.; Gong, Y. City-scale multi-camera vehicle tracking by semantic attribute parsing and cross-camera tracklet matching. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 576–577. [Google Scholar]
- Tran, D.N.N.; Pham, L.H.; Jeon, H.J.; Nguyen, H.H.; Jeon, H.M.; Tran, T.H.P.; Jeon, J.W. A robust traffic-aware city-scale multi-camera vehicle tracking of vehicles. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 3150–3159. [Google Scholar]
- Yu, F.; Chen, H.; Wang, X.; Xian, W.; Chen, Y.; Liu, F.; Madhavan, V.; Darrell, T. Bdd100k: A diverse driving dataset for heterogeneous multitask learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 2636–2645. [Google Scholar]
- Yao, Y.; Zheng, L.; Yang, X.; Naphade, M.; Gedeon, T. Simulating content consistent vehicle datasets with attribute descent. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part VI 16; Springer: Cham, Switzerland, 2020; pp. 775–791. [Google Scholar]
- Wen, L.; Du, D.; Cai, Z.; Lei, Z.; Chang, M.C.; Qi, H.; Lim, J.; Yang, M.H.; Lyu, S. UA-DETRAC: A new benchmark and protocol for multi-object detection and tracking. Comput. Vis. Image Underst. 2020, 193, 102907. [Google Scholar] [CrossRef] [Green Version]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? the kitti vision benchmark suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar]
- Caesar, H.; Bankiti, V.; Lang, A.H.; Vora, S.; Liong, V.E.; Xu, Q.; Krishnan, A.; Pan, Y.; Baldan, G.; Beijbom, O. nuscenes: A multimodal dataset for autonomous driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11621–11631. [Google Scholar]
- Bernardin, K.; Stiefelhagen, R. Evaluating multiple object tracking performance: The clear mot metrics. EURASIP J. Image Video Process. 2008, 2008, 246309. [Google Scholar] [CrossRef] [Green Version]
- Luna, E.; Miguel, J.C.S.; Martínez, J.M.; Escudero-Viñolo, M. Graph Convolutional Network for Multi-Target Multi-Camera Vehicle Tracking. arXiv 2022, arXiv:2211.15538. [Google Scholar]
- Hsu, H.M.; Huang, T.W.; Wang, G.; Cai, J.; Lei, Z.; Hwang, J.N. Multi-camera tracking of vehicles based on deep features re-id and trajectory-based camera link models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Long Beach, CA, USA, 15–20 June 2019; pp. 416–424. [Google Scholar]
- Hou, Y.; Du, H.; Zheng, L. A locality aware city-scale multi-camera vehicle tracking system. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Long Beach, CA, USA, 15–20 June 2019; pp. 167–174. [Google Scholar]
- He, Z.; Lei, Y.; Bai, S.; Wu, W. Multi-Camera Vehicle Tracking with Powerful Visual Features and Spatial-Temporal Cue. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Long Beach, CA, USA, 15–20 June 2019; pp. 203–212. [Google Scholar]
- Quach, K.G.; Nguyen, P.; Le, H.; Truong, T.D.; Duong, C.N.; Tran, M.T.; Luu, K. Dyglip: A dynamic graph model with link prediction for accurate multi-camera multiple object tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13784–13793. [Google Scholar]
- Luna, E.; SanMiguel, J.C.; Martínez, J.M.; Escudero-Vinolo, M. Online clustering-based multi-camera vehicle tracking in scenarios with overlapping FOVs. Multimed. Tools Appl. 2022, 81, 7063–7083. [Google Scholar] [CrossRef]
- Qian, Y.; Yu, L.; Liu, W.; Hauptmann, A.G. Electricity: An efficient multi-camera vehicle tracking system for intelligent city. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 588–589. [Google Scholar]
- Chang, M.C.; Wei, J.; Zhu, Z.A.; Chen, Y.M.; Hu, C.S.; Jiang, M.X.; Chiang, C.K. AI City Challenge 2019-City-Scale Video Analytics for Smart Transportation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Long Beach, CA, USA, 15–20 June 2019; pp. 99–108. [Google Scholar]


















| Dataset | Year | Total Images | Categories | Image Size | Objects of Image | Size | Highlights |
|---|---|---|---|---|---|---|---|
| OpenData | 2017 | 10,000 | 10 | 400 × 424 | Varied | 16 G | A great variety. |
| Stanford Cars | 2013 | 16,185 | 5 | 720 × 540 | 3 | 10 G | Automobile model verification. |
| CompCars | 2015 | 136,726 | 5 | 540 × 540 | 4 | 18 G | Fine-grained classification. |
| ImageNet | 2009 | 14,197,122 | 21,841 | 500 × 400 | 1.5 | 138 G | Image classification, detection and location. |
| PASCAL VOC | 2009 | 11,540 | 20 | 470 × 380 | 2.4 | 8 G | One of the mainstream data sets of computer vision. |
| MS COCO | 2015 | 328,000+ | 91 | 640 × 480 | 7.3 | 18 G | Very high industry status and huge data set. |
| Open image | 2020 | 9 million+ | 6000+ | Varied | 8.3 | 500 G | Very diverse. |
| KITTI | 2012 | 500+ | 5 | 1240 × 376 | 1.7 | 180 G | Evaluate vehicle performance. |
| BD100K | 2018 | 100,000 | 10 | 1280 × 720 | 2.4 | 7 G | One of the largest driving data sets. |
| UA-DETRAC | 2020 | 140,000 | 8 | 960 × 540 | 2.3 | 14.5 G | Challenging data set. |
| ILSVRC | 2012 | 170,000+ | 1000 | 1280 × 720 | Varied | 16 G | The most popular machine vision competition. |
| vehiclex | 2020 | 192,150 | 10 | 960 × 540 | Varied | 16 G | Accurate data. |
| CityFlow | 2019 | 229,680 | 6 | 1080 × 540 | Varied | 8 G | Large-scale. |
| VehicleID | 2019 | 221,763 | 11 | 840 × 840 | Varied | 7 G | Large-scale. |
| Method | Object Detector | SCT | IDP↑ | IDR↑ | IDF1↑ |
|---|---|---|---|---|---|
| GCNM [144] | SSD | TNT | 71.95 | 92.81 | 81.06 |
| UWIPL [145] | SSD | TNT | 70.21 | 92.61 | 79.87 |
| ANU [146] | SSD | custom | 67.53 | 81.99 | 74.06 |
| BUPT [147] | FPN | custom | 78.23 | 63.69 | 70.22 |
| DyGLIP [148] | Mask-RCCN | DeepSORT | - | - | 64.90 |
| Online-MTMC [149] | EfficientDet | Custom | 55.15 | 76.98 | 64.26 |
| ELECTRICITY [150] | Mask-RCCN | DeepSORT | - | - | 53.80 |
| NCCU [151] | FPN | DaSiamRPN | 48.91 | 43.35 | 45.97 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fei, L.; Han, B. Multi-Object Multi-Camera Tracking Based on Deep Learning for Intelligent Transportation: A Review. Sensors 2023, 23, 3852. https://doi.org/10.3390/s23083852
Fei L, Han B. Multi-Object Multi-Camera Tracking Based on Deep Learning for Intelligent Transportation: A Review. Sensors. 2023; 23(8):3852. https://doi.org/10.3390/s23083852
Chicago/Turabian StyleFei, Lunlin, and Bing Han. 2023. "Multi-Object Multi-Camera Tracking Based on Deep Learning for Intelligent Transportation: A Review" Sensors 23, no. 8: 3852. https://doi.org/10.3390/s23083852