
Reduced-Parameter YOLO-like Object Detector Oriented to Resource-Constrained Platform

Abstract
:1. Introduction
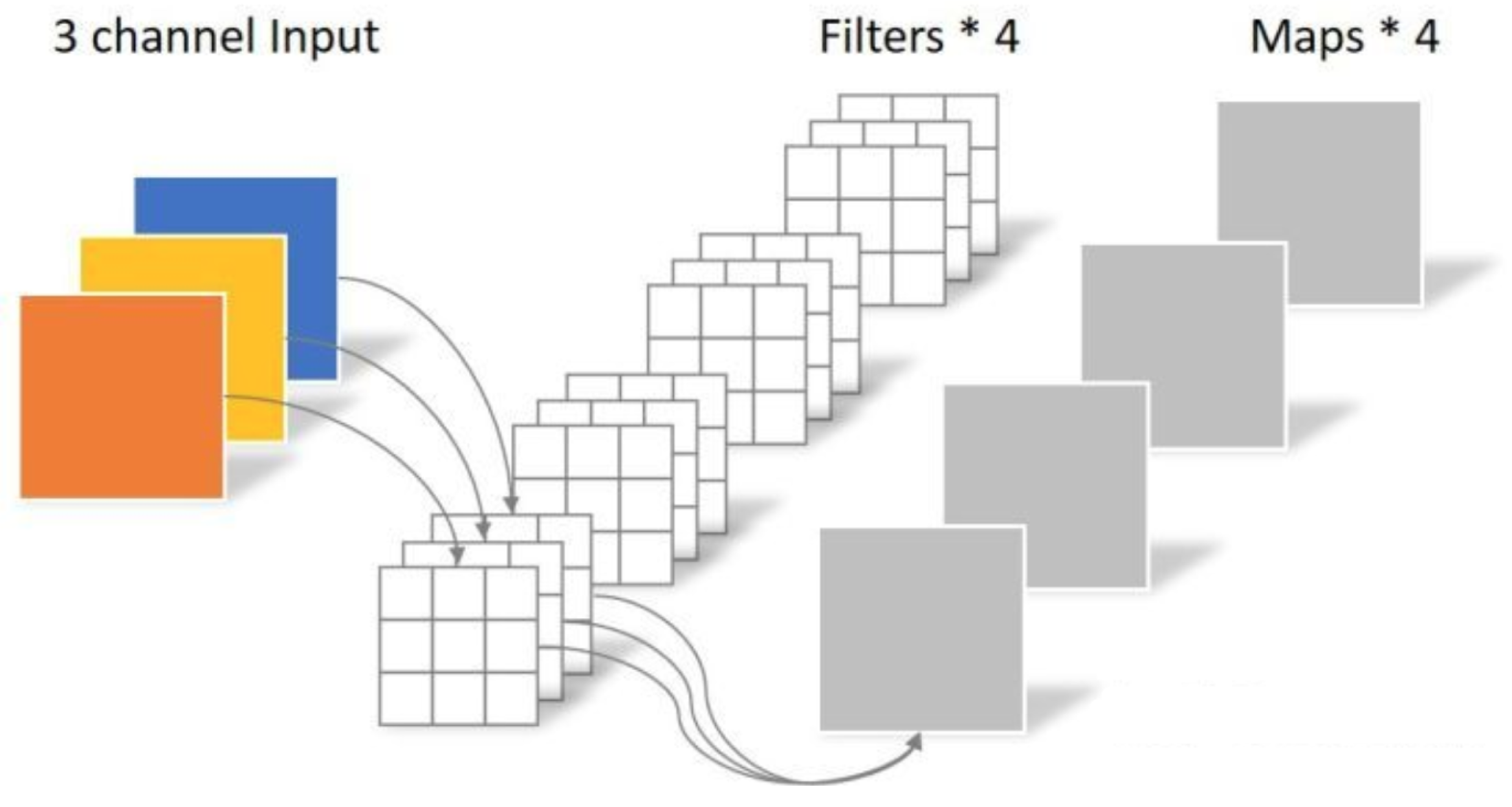
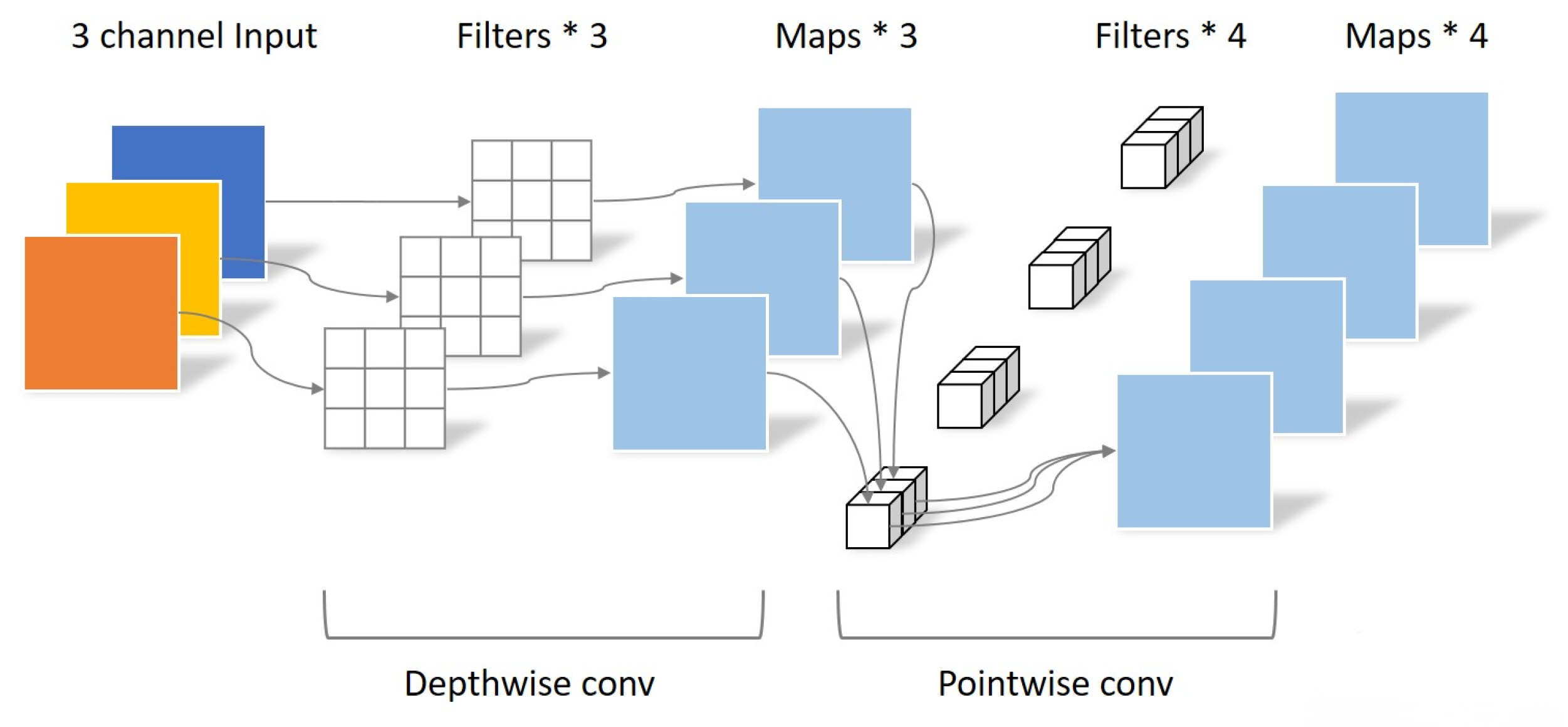
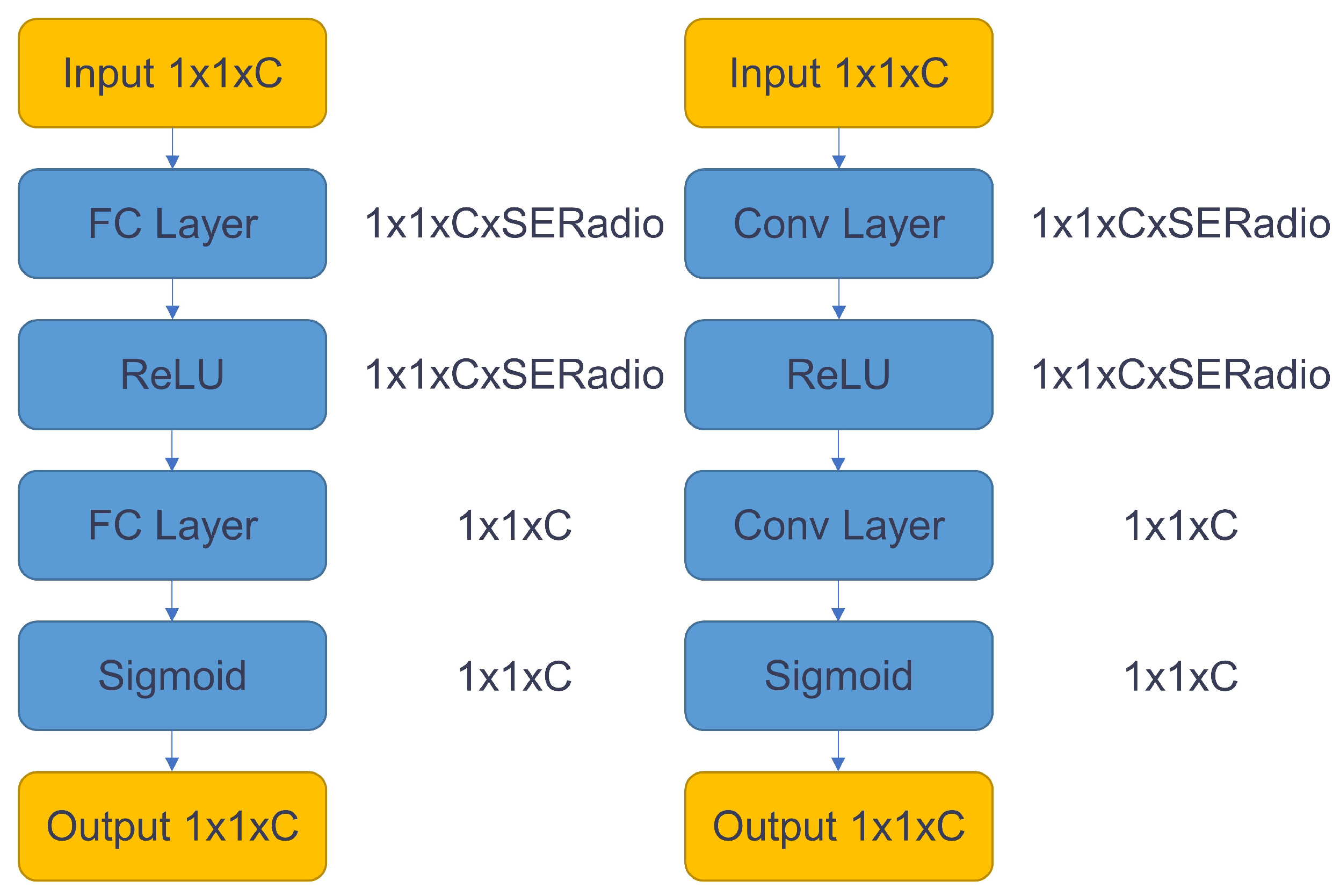
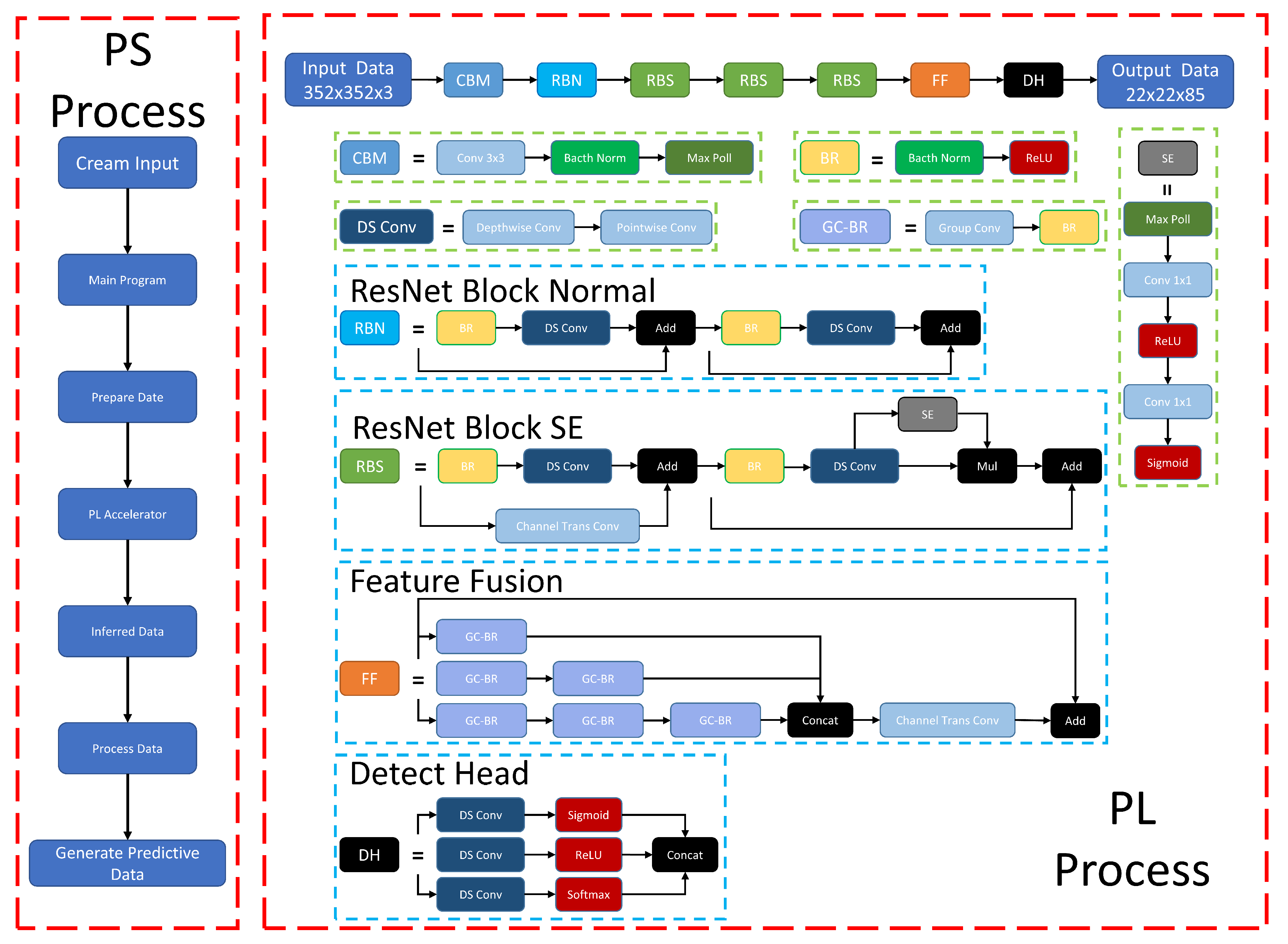
- Considering the limited resources on the FPGA chip when designing the model algorithm, the following methods are used in the algorithm model to reduce the model size and computational effort: (1) reduce the hardware computation and number of parameters using Depthwise Separable Convolution [19] and network quantization [20]. (2) Improve network accuracy by adding SE modules [21] within specific network layers. (3) A single lightweight detection head is designed to improve the running speed of the algorithm. (4) Improving network training quality with dynamic positive and negative sample assignment, data augmentation, and multiple candidate targets across grids [22,23].
- On the FPGA side, based on the Xilinx FINN framework [24,25], the neural network written by Pytorch [26] is converted to ONNX format, and the basic operators are written by HLS. The neural network nodes in ONNX format are transformed into hardware code with custom operators via HLS, resulting in a low latency, low power, and highly accurate neural network.
2. Algorithm Design
2.1. Overall Algorithm Model Design
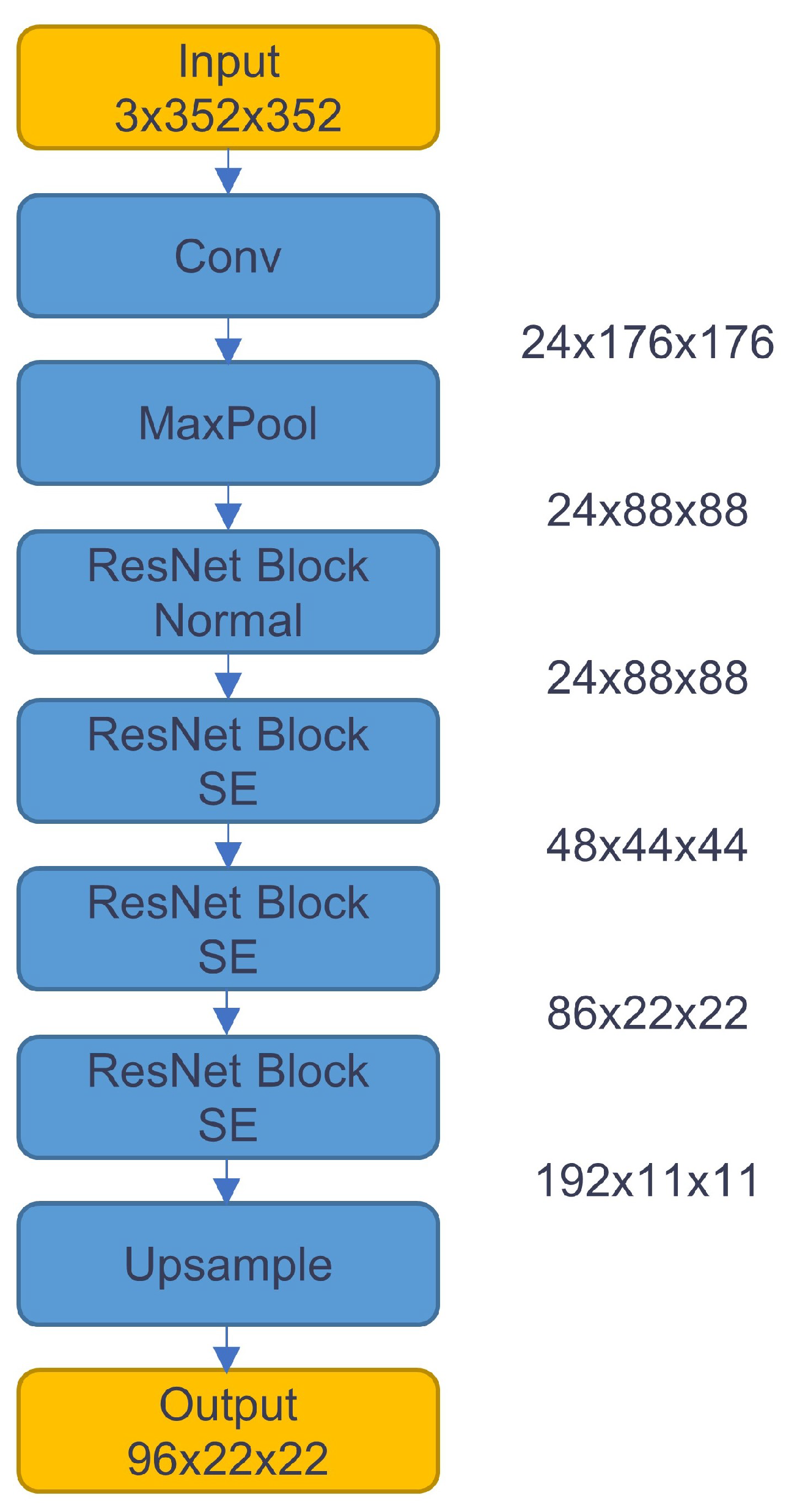
2.1.1. Backbone Design
2.1.2. Detection Head Design
2.2. Network Optimization Design
2.2.1. Neural Network Quantization
2.2.2. Data Format
3. Hardware Orient Algorithm Optimization
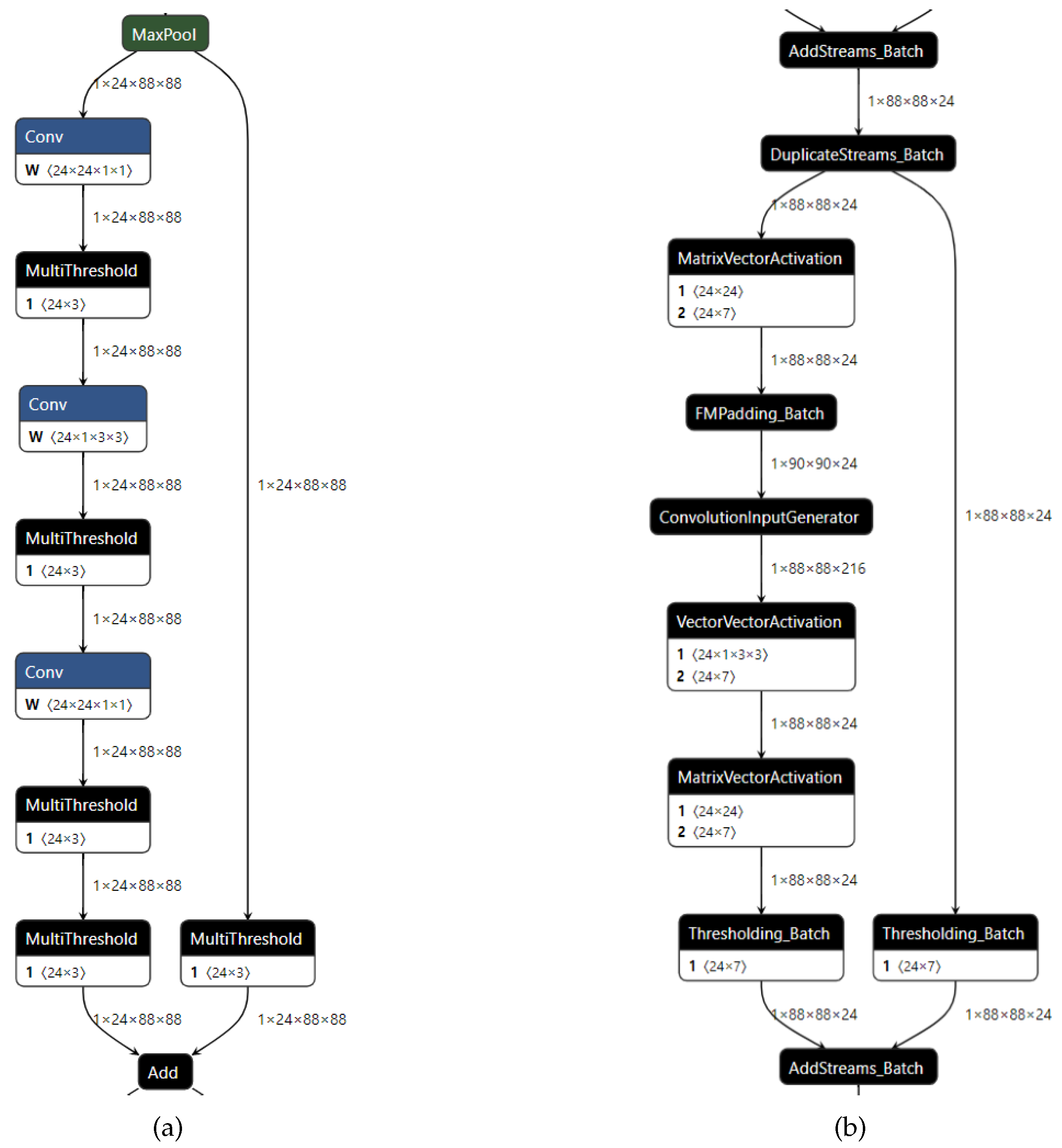
3.1. FPGA Operator Design
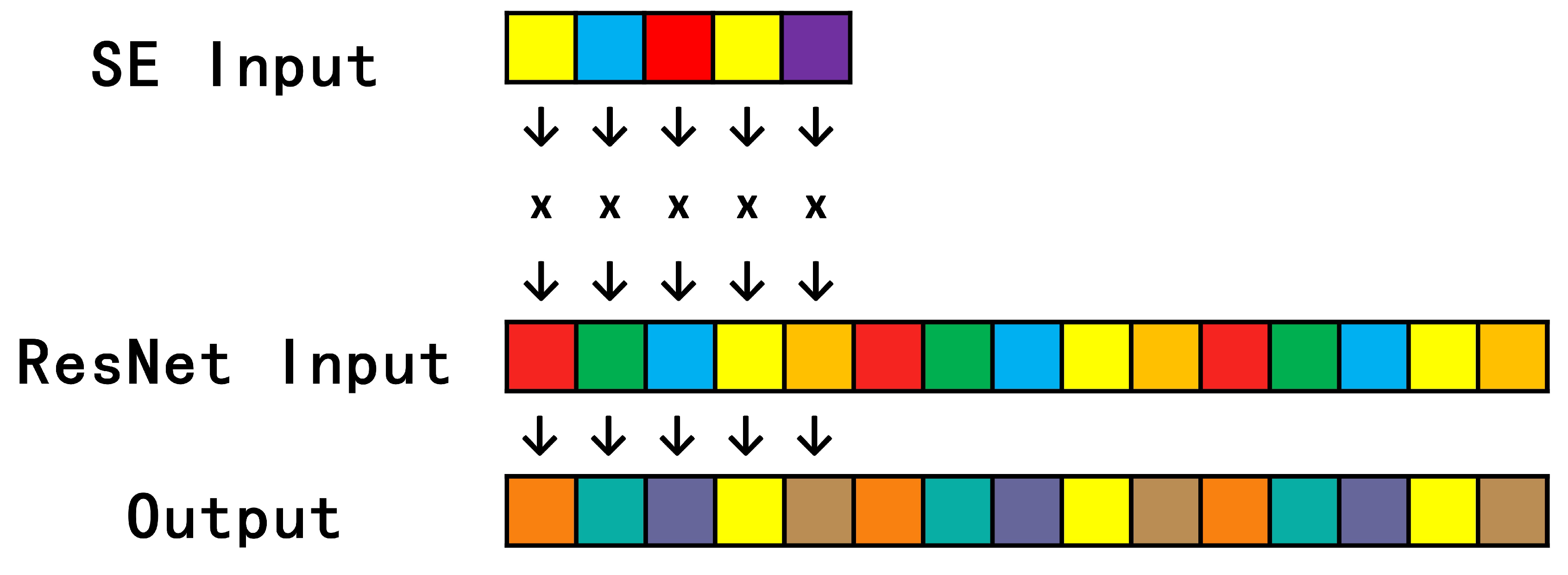
3.1.1. Streamling Mul Op
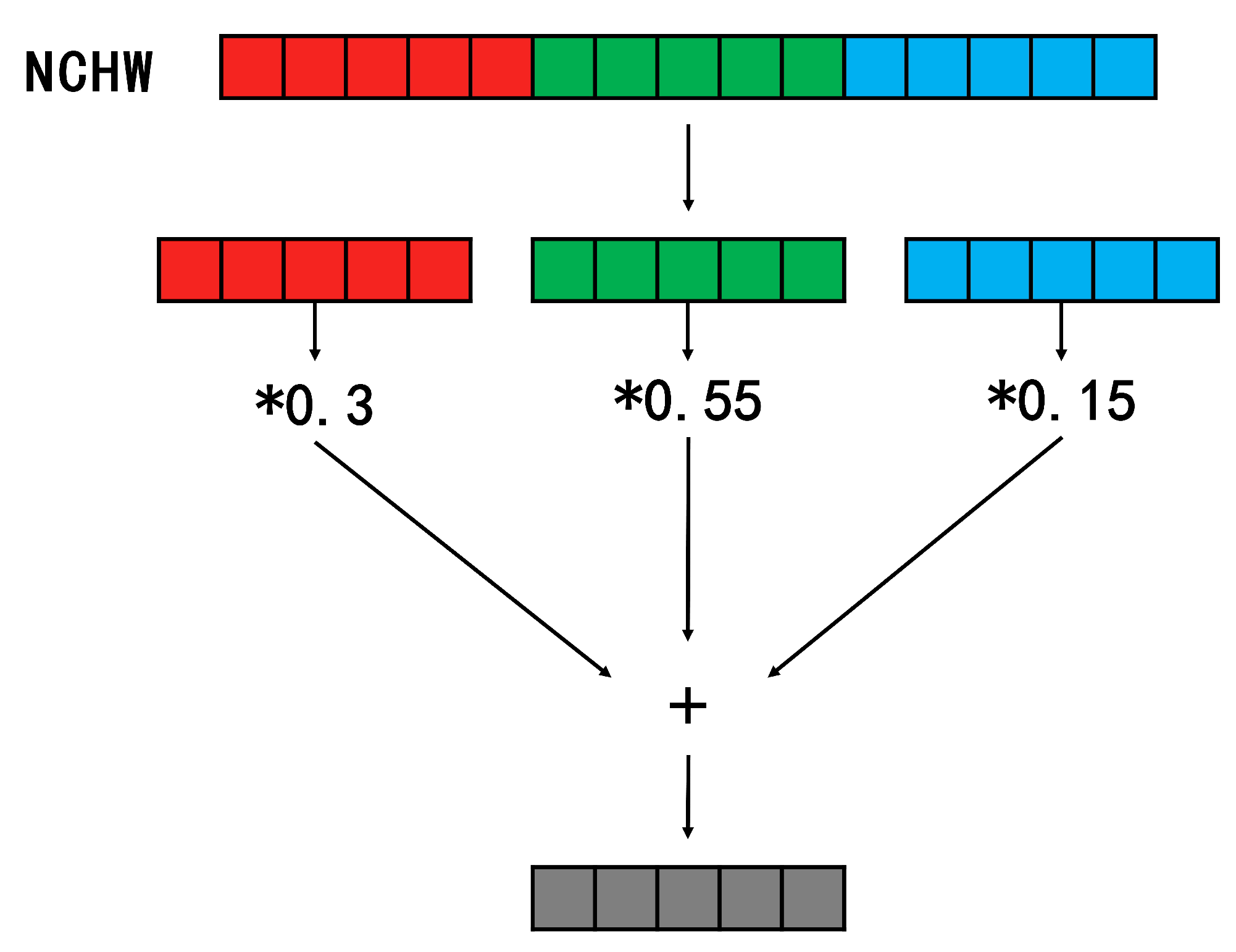
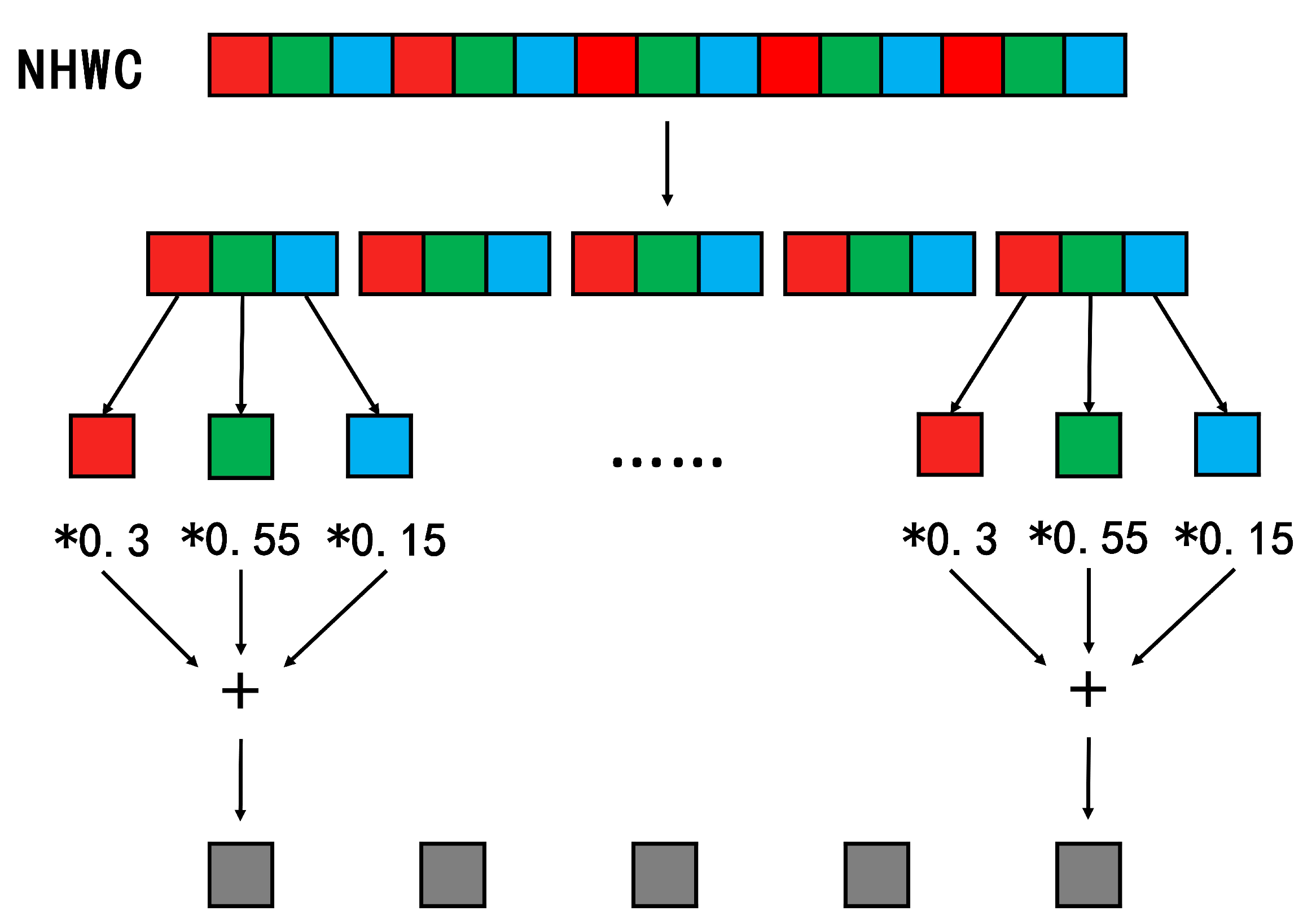
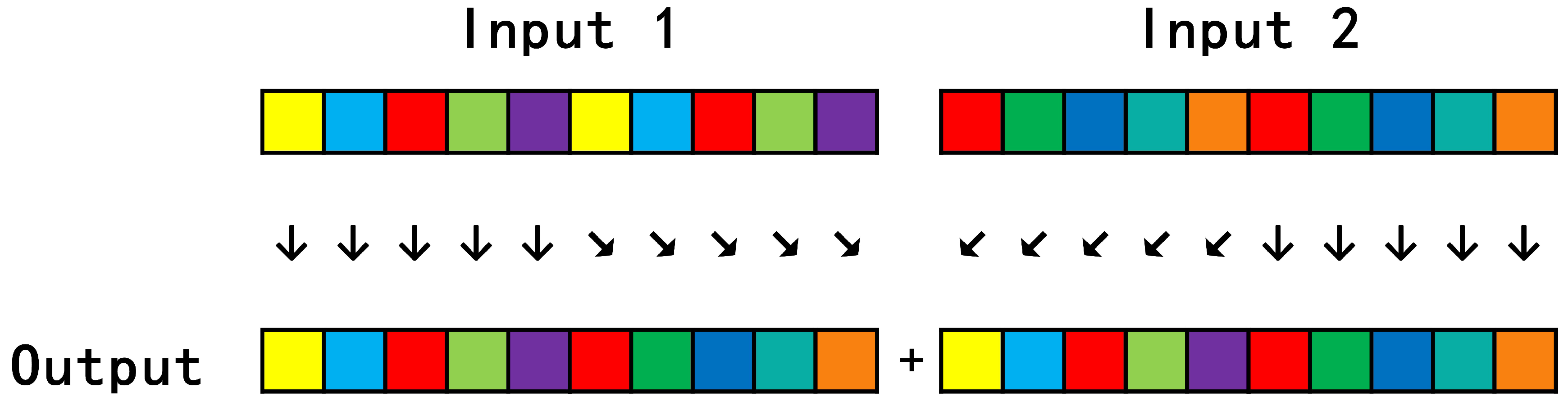
3.1.2. Streamling Concat Op
3.2. General Framework
3.3. Deployment
4. Experimental Results
4.1. Experimental Design
4.2. Host Side
4.3. FPGA Side
4.4. Results
4.5. Further Discussion and Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Sun, X.; Zhu, X.; Wang, P.; Chen, H. A review of robot control with visual servoing. In Proceedings of the 2018 IEEE 8th Annual International Conference on CYBER Technology in Automation, Control, and Intelligent Systems (CYBER), Tianjin, China, 19–23 July 2018; pp. 116–121. [Google Scholar]
- Bai, Q.; Li, S.; Yang, J.; Song, Q.; Li, Z.; Zhang, X. Object detection recognition and robot grasping based on machine learning: A survey. IEEE Access 2020, 8, 181855–181879. [Google Scholar] [CrossRef]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Beijing, China, 17–21 October 2005; pp. 1440–1448. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Beijing, China, 17–21 October 2005; pp. 2961–2969. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE conference on computer vision and pattern recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 779–788. [Google Scholar]
- Kazerouni, I.A.; Fitzgerald, L.; Dooly, G.; Toal, D. A Survey of State-of-the-Art on Visual SLAM. Expert Syst. Appl. 2022, 205, 117734. [Google Scholar] [CrossRef]
- Mazumder, A.N.; Meng, J.; Rashid, H.A.; Kallakuri, U.; Zhang, X.; Seo, J.S.; Mohsenin, T. A survey on the optimization of neural network accelerators for micro-ai on-device inference. IEEE J. Emerg. Sel. Top. Circuits Syst. 2021, 11, 532–547. [Google Scholar] [CrossRef]
- Hu, Y.; Liu, Y.; Liu, Z. A survey on convolutional neural network accelerators: GPU, FPGA and ASIC. In Proceedings of the 2022 14th International Conference on Computer Research and Development (ICCRD), Shenzhen, China, 7–9 January 2022; pp. 100–107. [Google Scholar]
- Mittal, S. A survey of FPGA-based accelerators for convolutional neural networks. Neural Comput. Appl. 2020, 32, 1109–1139. [Google Scholar] [CrossRef]
- Zhai, J.; Li, B.; Lv, S.; Zhou, Q. FPGA-Based Vehicle Detection and Tracking Accelerator. Sensors 2023, 23, 2208. [Google Scholar] [CrossRef] [PubMed]
- Wu, R.; Guo, X.; Du, J.; Li, J. Accelerating neural network inference on FPGA-based platforms—A survey. Electronics 2021, 10, 1025. [Google Scholar] [CrossRef]
- Sledevič, T.; Serackis, A.; Plonis, D. FPGA Implementation of a Convolutional Neural Network and Its Application for Pollen Detection upon Entrance to the Beehive. Agriculture 2022, 12, 1849. [Google Scholar] [CrossRef]
- Yan, T.; Zhang, N.; Li, J.; Liu, W.; Chen, H. Automatic Deployment of Convolutional Neural Networks on FPGA for Spaceborne Remote Sensing Application. Remote Sens. 2022, 14, 3130. [Google Scholar] [CrossRef]
- Majoros, T.; Oniga, S. Overview of the EEG-Based Classification of Motor Imagery Activities Using Machine Learning Methods and Inference Acceleration with FPGA-Based Cards. Electronics 2022, 11, 2293. [Google Scholar] [CrossRef]
- Hussein, A.S.; Anwar, A.; Fahmy, Y.; Mostafa, H.; Salama, K.N.; Kafafy, M. Implementation of a dpu-based intelligent thermal imaging hardware accelerator on fpga. Electronics 2022, 11, 105. [Google Scholar] [CrossRef]
- Guo, K.; Zeng, S.; Yu, J.; Wang, Y.; Yang, H. [DL] A survey of FPGA-based neural network inference accelerators. ACM Trans. Reconfig. Technol. Syst. (TRETS) 2019, 12, 1–26. [Google Scholar] [CrossRef]
- Cho, M.; Kim, Y. FPGA-Based Convolutional Neural Network Accelerator with Resource-Optimized Approximate Multiply-Accumulate Unit. Electronics 2021, 10, 2859. [Google Scholar] [CrossRef]
- Wang, C.; Luo, Z. A Review of the Optimal Design of Neural Networks Based on FPGA. Appl. Sci. 2022, 12, 10771. [Google Scholar] [CrossRef]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Han, S.; Mao, H.; Dally, W.J. Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding. arXiv 2015, arXiv:1510.00149. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- xuehao.ma. FastestDet: Ultra Lightweight Anchor-Free Real-Time Object Detection Algorithm. Available online: https://github.com/dog-qiuqiu/FastestDet (accessed on 21 December 2022).
- Zhu, B.; Wang, J.; Jiang, Z.; Zong, F.; Liu, S.; Li, Z.; Sun, J. Autoassign: Differentiable label assignment for dense object detection. arXiv 2020, arXiv:2007.03496. [Google Scholar]
- Umuroglu, Y.; Fraser, N.J.; Gambardella, G.; Blott, M.; Leong, P.; Jahre, M.; Vissers, K. FINN: A Framework for Fast, Scalable Binarized Neural Network Inference. In Proceedings of the 2017 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, Monterey, CA, USA, 22–24 February 2017; ACM: New York, NY, USA, 2017. FPGA’17. pp. 65–74. [Google Scholar]
- Blott, M.; Preußer, T.B.; Fraser, N.J.; Gambardella, G.; O’brien, K.; Umuroglu, Y.; Leeser, M.; Vissers, K. FINN-R: An end-to-end deep-learning framework for fast exploration of quantized neural networks. ACM Trans. Reconfig. Technol. Syst. (TRETS) 2018, 11, 1–23. [Google Scholar] [CrossRef]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An imperative style, high-performance deep learning library. Adv. Neural Inf. Process. Syst. 2019, 32. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Chen, Q.; Wang, Y.; Yang, T.; Zhang, X.; Cheng, J.; Sun, J. You only look one-level feature. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13039–13048. [Google Scholar]
- Li, Y.; Chen, Y.; Wang, N.; Zhang, Z. Scale-aware trident networks for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6054–6063. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the Computer Vision—ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Proceedings, Part V 13. Springer: Berlin/Heidelberg, Germany, 2014; pp. 740–755. [Google Scholar]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. YOLOv6: A single-stage object detection framework for industrial applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. arXiv 2022, arXiv:2207.02696. [Google Scholar]
- Zhao, K. Local exponential stability of several almost periodic positive solutions for a classical controlled GA-predation ecosystem possessed distributed delays. Appl. Math. Comput. 2023, 437, 127540. [Google Scholar] [CrossRef]
- Zhao, K. Global stability of a novel nonlinear diffusion online game addiction model with unsustainable control. AIMS Math. 2022, 7, 120752–120766. [Google Scholar] [CrossRef]
- Yu, L.; Zhu, J.; Zhao, Q.; Wang, Z. An Efficient YOLO Algorithm with an Attention Mechanism for Vision-Based Defect Inspection Deployed on FPGA. Micromachines 2022, 13, 1058. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model Name | Model Size | Data Type |
|---|---|---|
| YOLOv3-Tiny | 33.7 MB | FP32 |
| YOLOv4-Tiny | 23.0 MB | FP32 |
| YOLOv5s | 27.8 MB | FP32 |
| Our Net | 9.4 MB | INT4 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zheng, X.; He, T. Reduced-Parameter YOLO-like Object Detector Oriented to Resource-Constrained Platform. Sensors 2023, 23, 3510. https://doi.org/10.3390/s23073510
Zheng X, He T. Reduced-Parameter YOLO-like Object Detector Oriented to Resource-Constrained Platform. Sensors. 2023; 23(7):3510. https://doi.org/10.3390/s23073510
Chicago/Turabian StyleZheng, Xianbin, and Tian He. 2023. "Reduced-Parameter YOLO-like Object Detector Oriented to Resource-Constrained Platform" Sensors 23, no. 7: 3510. https://doi.org/10.3390/s23073510