1. Introduction
Commuting to work or school is often a daily activity that comprises a significant amount of time and effort. Full-time workers in England spend an average of one hour per day commuting, and one in seven workers spends at least two hours commuting. People’s commuting ways are influenced by their personal characteristics and life circumstances [
1]. The commuter’s daily commute may affect them in both objective and subjective ways while traveling, after traveling, and over time. Commuting can be time-consuming, costly, and unpleasant, and it can have an impact on mood both during and after the journey. The effect that commuting will have on your health will probably depend on how long you commute, what kind of transportation you use, and the weather you encounter [
1]. Recent research analyzed commute stress among commuters who used various modes of transportation and discovered that those who walked or cycled to work experienced the least stress and those who drove experienced the most stress [
2].
The human brain reacts to various moods and emotions. The brain is like a control center, and it usually uses electrical impulses to control how the body works. Numerous environmental factors, including exercise, anxiety, sleep, and stress, affect the heart rate. According to Peter et al., stress in any form in humans can cause a change in heart rate and BP [
3]. It has been shown that cutting down on free time and sleep makes people less productive because it throws off their daily schedules. Commuters reported higher levels of mental stress, more health issues, the majority of which were psychosomatic in nature, and more sick days taken from work [
4].
According to Milner, Kavanagh, Badland, and LaMontagne, there is a threshold relationship that governs how much time is spent commuting, for more than 6 h per week is linked to declining subjective mental health outcomes. Job control and job security are moderating factors in this relationship [
5]. The study discovered that when commuting time exceeded 6 h per week, people who were considered to demonstrate low levels of control in their professional function received negative ratings on a mental health questionnaire. Longer commutes resulted in higher stress levels for commuters, depending on how much their travel was affected, for example, by unreliable public transportation and traffic, according to O’Regan’s findings [
6]. More evidence has shown that the degree of control a commuter has over their travel affects how much of an impact longer commutes have on stress [
7]. It has been proposed that traffic congestion, rather than necessarily the amount of time spent traveling, is the mediator of stress during commutes due to their strong correlation, especially in urban regions [
8].
Research used body mass index, hip circumference, waist circumference, and waist–hip ratio to predict high blood pressure [
9]. This investigation was carried out using a machine learning technique called classification trees. Machine learning techniques are widely employed in many fields for a variety of purposes [
10]. Similarly, research was conducted to detect stress in working people using ECG and galvanic skin response (GSR). According to a study, stress is a mental health issue that can induce depression, loss of clarity at work, bad working relationships, socio-financial issues, and in some extreme situations, suicide. EEG signals were recorded using sensor equipment, they were pre-processed and used to investigate the stress level using the machine learning techniques SVM and KNN. Datasets included both sensor data and information on the stress of the workplace, such as email interruptions and deadline pressure [
11]. A new method for evaluating stressed and depressed people’s psychophysiology has emerged in recent years because of the measurement and objectification of stress [
12]. Researchers collected data from a diverse range of users in around 100 nations using a well-known meditation app, including heart rate variability (HRV) and heart rate (HR), besides the self-assessment of stress [
13]. Those data were recorded using a mobile camera as a standalone or as a voluntary pair before and after the assessments.
Our daily lives are significantly impacted by stress because it is linked to the various tasks we complete daily. Our body responds to outside events in several ways, both directly and indirectly. Monitoring bio signals such as pulse rate, blood pressure (BP), and others can teach us about what is happening to our body. Any abnormalities from the previously mentioned factors lead to illness. An individual experiences stress when engaging in any kind of physical or mental effort. Based on bio signals and questionnaire-based surveys, mental stress can be predicted. In a study, stress was detected with machine learning and deep learning using multimodal physiological data [
14].
In the present context, there are several technologies to monitor stress levels. These technologies are based on different bio signals: heart rate, heart rate variability, electroencephalograms, blood pressure, skin conductance, cortisol, and pupil diameter. Out of these bio signals, most of the research is based on EEG signals to monitor stress [
15]. The emotional and physical health of long-distance commuters is negatively impacted. Additionally, it may cause depression and increased anxiety [
16]. Stress can also occur when people have high expectations for someone, but that person is unable to meet those expectations.
Currently, the only people who can tell if someone is stressed or not are medical and physiological professionals. Using a questionnaire is one of the conventional methods for determining stress [
17]. This approach solely relies on the participants’ reactions; whether they tremble indicates whether they are under stress. Stress can be found automatically, which can improve social well-being and reduce the risk of health problems. It is important to make a smart model that can predict stress levels using the bio signals. This study uses machine learning to predict how a commute will impact a person’s health, so they can use active or alternative commuting methods to avoid health risks such as high blood pressure or worry.
We aimed to investigate the subjective and objective experiences of the commute. This study examines the social and neurophysiological impacts of real-time commuting. It accomplishes this by utilizing machine learning to analyze brain waves and bio signals. Today’s society has made commuting a necessity and unavoidable part of every day. In this research, we will create an innovative model that investigates the health impacts of commuting using bio signals and an intelligent approach.
2. Related Literature Review
Stress is what happens to our bodies when changes in the environment upset the balance of our bodies, minds, or emotions. Positive and negative stress are referred to as eustress and distress, respectively [
18]. Stress over a prolonged period can be the cause of several mental health issues. Stress can cause a variety of health problems, including cardiovascular disease [
15]. The recognition of mental stress in its earliest stages is very necessary for effective clinical treatment [
18]. Most people commonly feel stress in their everyday lives as a typical physiological reaction to their environment [
16]. People typically experience it when they feel intimidated or challenged. People get the impression that it is challenging to balance and adjust to both internal and external situations. Several wearable technologies, such as Olive, Spire, and Breath Acoustics, can detect the degree of tension in the user [
19].
Standard surveys or questionnaires are the foundation of most stress detection studies. Such a technique requires a significant amount of time and resources, as a specialized individual must evaluate the stress in each one [
16]. Recently, bio-signal-based stress analysis has been developed, which can help by saving time and effort [
18]. Bio signals such as HRV, galvanic skin reaction, electrocardiogram, electromyography, blood pressure, and finger and skin temperatures are used for real-time stress identification [
20].
Similarly, a study was conducted to identify stress while driving using medical data, including heart rate, ECG, breathing, and EMG under different circumstances. Biodata such as respiration, GSR from the hand and foot, heart rate, and EMG were analyzed in this study utilizing a machine-learning-based technique. The information was then divided into time periods of 100, 200, and 300 s for varying degrees of stress. The segmented data was then used to create statistical characteristics, which were then given to the chosen classifier. Stress levels were labelled based on their intensity as high, medium, and low. SVM exceeded KNN with an accuracy of 98.41% for time intervals of 100 s and 200 s and 99.1% for intervals of 300 s [
21]. Cho et al. also investigated how deep neural networks and ECG data might identify stress levels [
22]. They used a cross-validation method to evaluate their model.
A questionnaire was used to classify the stress of university students using various machine learning techniques: linear regression, SVM, naïve Bayes, and random forest [
23]. In this research, the support vector machine performed well compared to other techniques. Rizwan et al. used ECG signals to detect stress levels [
18]. Various SVM methods were applied to alter the feature number and types of kernels. With an accuracy of 98.6%, the gaussian cubic SVM produced a very promising result.
Pascual et al. made a portable device that can measure how stressed a person is [
24]. This device uses different bio signals as input parameters, such as body temperature, heart rate, and galvanic skin responses. Those bio signals were classified using an artificial neural network algorithm, which performed very well, with an accuracy of 91.67% [
25].
The EEG data were analyzed offline with a LabView-based algorithm to monitor the degree of stress that was being experienced [
26]. In that model, EEG was recorded using a one-channel EEG headset, and the recorded EEG signals were obtained from the headset using the EEGID mobile application. According to their findings, when people are under stress, the EEG beta band will be greater than the alpha band. In a similar study, Jaun and Ioannis assessed emotion, mood, personality, and social situation using EEG data and the PANAS form (individual vs. group setting) [
27]. This was completed with an SVM technique in which the characteristics of each EEG band’s differential entropy and fractal dimension were found. According to their study, these characteristics were connected to participants’ emotional reactions. They addressed the two situations that served as the labels for their dataset. According to their findings, employing SVM with a radial basis function for their arousal scenario resulted in an accuracy of 68%, while using SVM with a linear kernel function for their emotional valence scenario delivered an accuracy of 61%.
Using an end-to-end learning approach for the time and spatial dimensions related to EEG data, a novel EEG classification network was developed in the research to enhance classification performance [
22]. The techniques described an architecture with 77.9%, 89.91%, and 88.31% accuracy in motor imagery and emotion classification, respectively. Similarly, a group of researchers developed a non-invasive brain–computer interface to identify and categorize human mental states using EEG data [
28]. In that study, the continuous decoding of EEG data was used to classify the flying-related mental states of pilots. Various simulated flying scenarios were used to collect the EEG data from seven pilots.
In past studies that tried to build models to predict stress levels, blood pressure and HRV were the two most important factors. Compared to bio signals, physiological characteristics are given less thought. Aside from artificial neural networks, the most popular machine learning applications are support vector machines and K’s closest neighbor. In this research, we are predicting that systolic BP will be higher when the EEG beta low power exceeds alpha low power after the commute.
3. Data Collection and Research Hypothesis
The employed data in this study were collected from 45 individuals who were in generally good health and who travelled to London each day for their jobs for five days in a row. Each participant completed an informed consent form after being cleared medically to take part in this study. According to the demographics in
Table 1, participants in this data-gathering procedure came from various parts of London, worked at various places, and travelled to work using a variety of modes, where frequency refers to the number per category. In this study, multimodal data were used, including responses from a questionnaire as well as numerous human bio signals including blood pressure, heart rate, and EEG signals (PANAS). Bio signals were collected using non-invasive wearable biosensor technology. As shown in
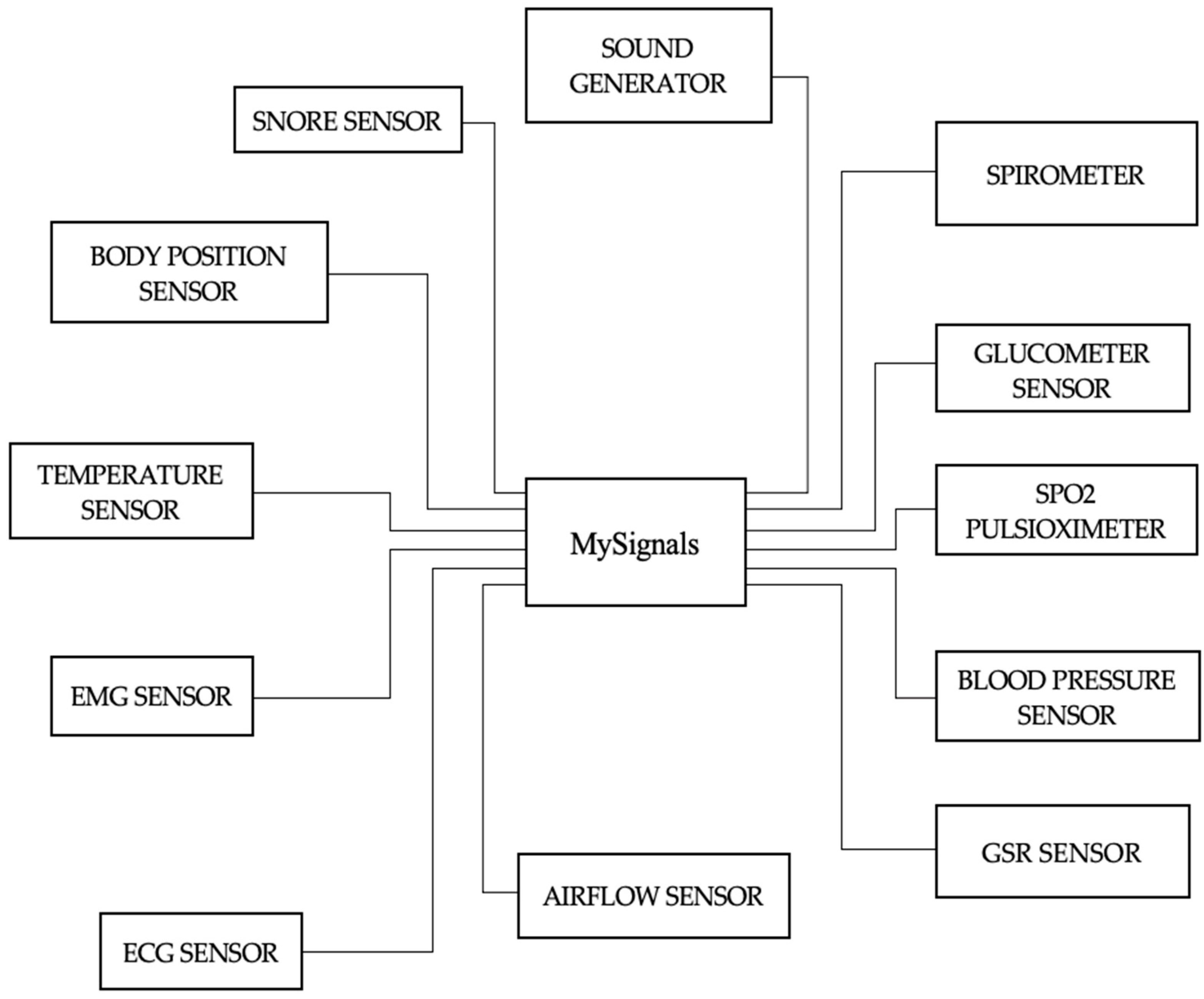
Figure 1, the MySignals device was utilized to capture the user’s blood pressure as well as their heart rate both before and after the journey. Blood pressure was collected from the upper arms before and after the commute. We can monitor more than 20 bio signals with this device, including heart rate, BP, ECG, oxygen levels in the blood, pulse, and breath rate. Similarly, EEG signals were captured from many points on the head while the subject was travelling from their house to their workplace. Additionally, the individuals’ heart rates and blood pressures were measured and recorded. Through the collection and analysis of bio signal datasets that were gathered throughout the journey from home to work, we were able to examine the effects that commuting within Greater London had on the participants’ mood and stress levels. These datasets were collected during the commute from home to work. The recording of bio signals was an extremely risk-free process that posed no danger to the participants in the study.
The major steps in the data collection were as follows:
While travelling to work, participants had to wear an EEG headset, and a sensor arm and ear clip.
For five working days, bio signals were recorded when they commuted to work.
They were instructed to initialize the devices and fill out an online health questionnaire as a part of the pre-experiment process.
The wearable devices captured the bio signals when the participant was travelling to and from work.
When the participant arrived at their place of work, they took three to four minutes to complete an online survey that documented their experience during their commute.
Please keep in mind that all the information or data that was recorded was made anonymous and kept secret.
Similarly, the participants in this study consisted of people who lived in London, were employed, and often commuted there for five consecutive working days. To calculate the necessary sample size for this study, we utilized a simple random sampling approach. This method gave each person an equal chance of being selected for this research. Daniel WW utilized the technique to determine the sample size for this research presented in [
29]. Using the simple random sampling method, the sample size for our research was found to be 42. Additionally, similar research was conducted with a much smaller number of participants compared to our research. The research was conducted to detect levels using machine learning and deep learning using multimodal physiological data from only 15 subjects [
3]. Similarly, another study, in which machine-learning-based signal processing using physiological signals was used for stress detection, was conducted successfully using data from only 17 drivers [
21].
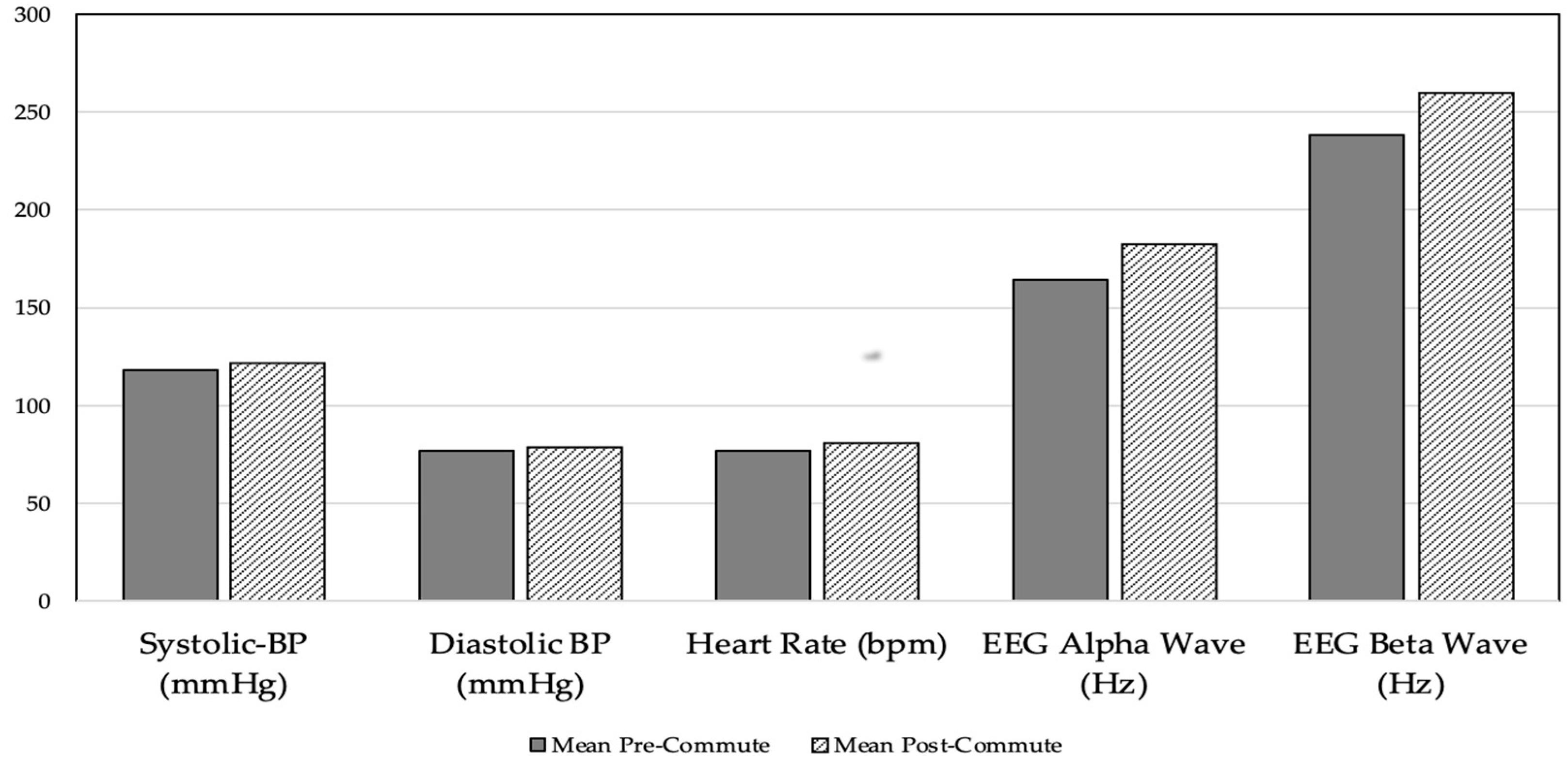
Every participant’s blood pressure and heart rate were taken for five days in a row using the MySignals device. Blood pressure is made up of two numbers: the first is systolic BP and the second is diastolic BP. The pressure that is present while the heart contracts is known as systolic pressure, while the pressure that is present when the heart relaxes in between beats is known as diastolic pressure. Blood pressure is measured in millimeters of mercury (mmHg). The ideal blood pressure ranges from 90/60 mmHg to 120/80 mmHg. The top number is systolic, and the bottom number is diastolic blood pressure. Similarly, heart rate and EEG power spectrum are expressed as beats per minute (BPM) and hertz (Hz), respectively. The value of the EEG band in
Figure 2 is plotted with a sampling rate of every 10 s. These data were collected from the participants pre commute and post commute. The observed patterns of bio signals show that heart rate and blood pressure are generally higher post commute than pre commute, as shown in
Figure 2.
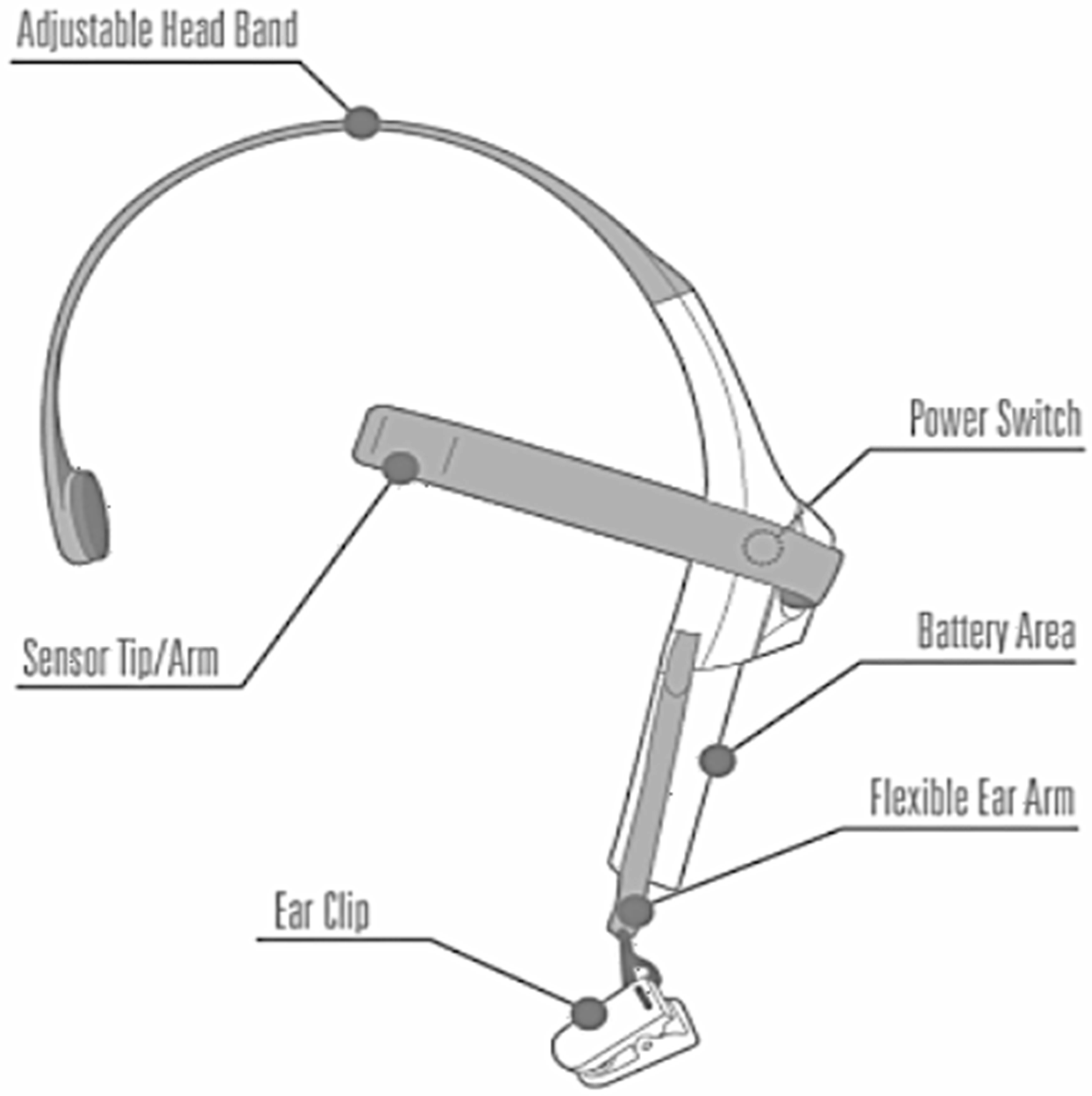
Similarly, EEG data were acquired using a mobile EEG headset throughout the journey to work, as illustrated in
Figure 3. This headset measures and securely produces EEG power spectrums. A headset, an ear chip, and a sensor arm were all included in this set of equipment. The reference and ground electrodes of the headset were attached to the ear clip, as shown in
Figure 3, and the EEG electrode was attached to the sensor arm, which was placed on the forehead above the eye (FP1 position). One AAA battery was all that was needed for its eight hours of operation [
22].
The data collection stages also involved the collection of other subjective factors and parameters from every participant including age, height, gender, weight, medication intake, smoking and alcohol status, location, weather temperature (degree Celsius), and medical health. Blood pressure can vary or rise for a variety of causes, such as when people consume excessive alcohol or medication with a high sodium/protein content, or when they have low levels of calcium, potassium, or magnesium [
30]. A PANAS questionnaire form was used to collect the responses from the participants before and after the commute [
31]. The PANAS questionnaire was created in 1988 based on research work from the University of Minnesota and Southern Methodist University. This questionnaire comprises a scale of words that, according to a person’s surroundings, indicate their feelings and emotions [
32]. The PANAS scale ranges from 1 to 5, as shown in
Table 2 and
Table 3.
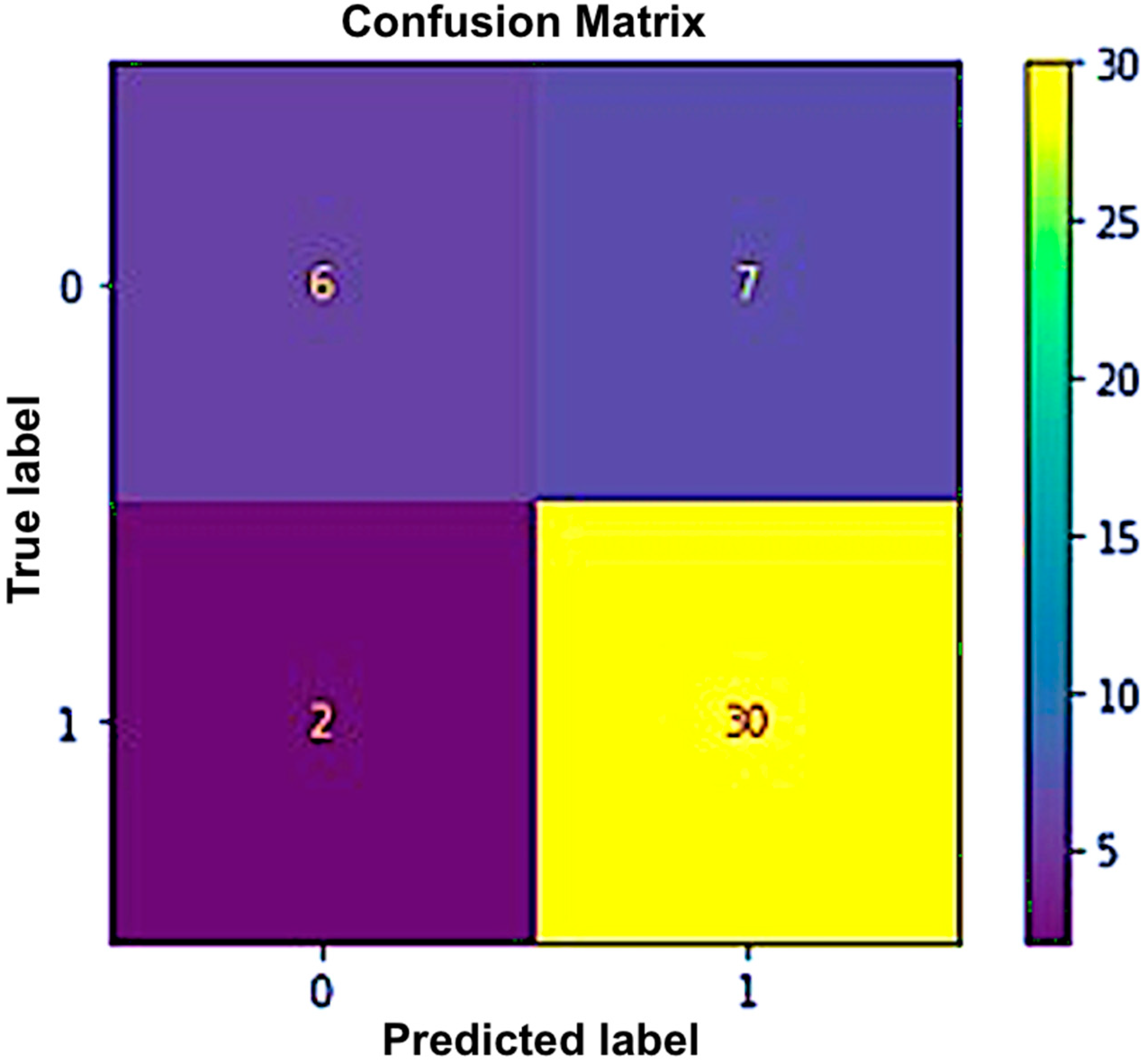
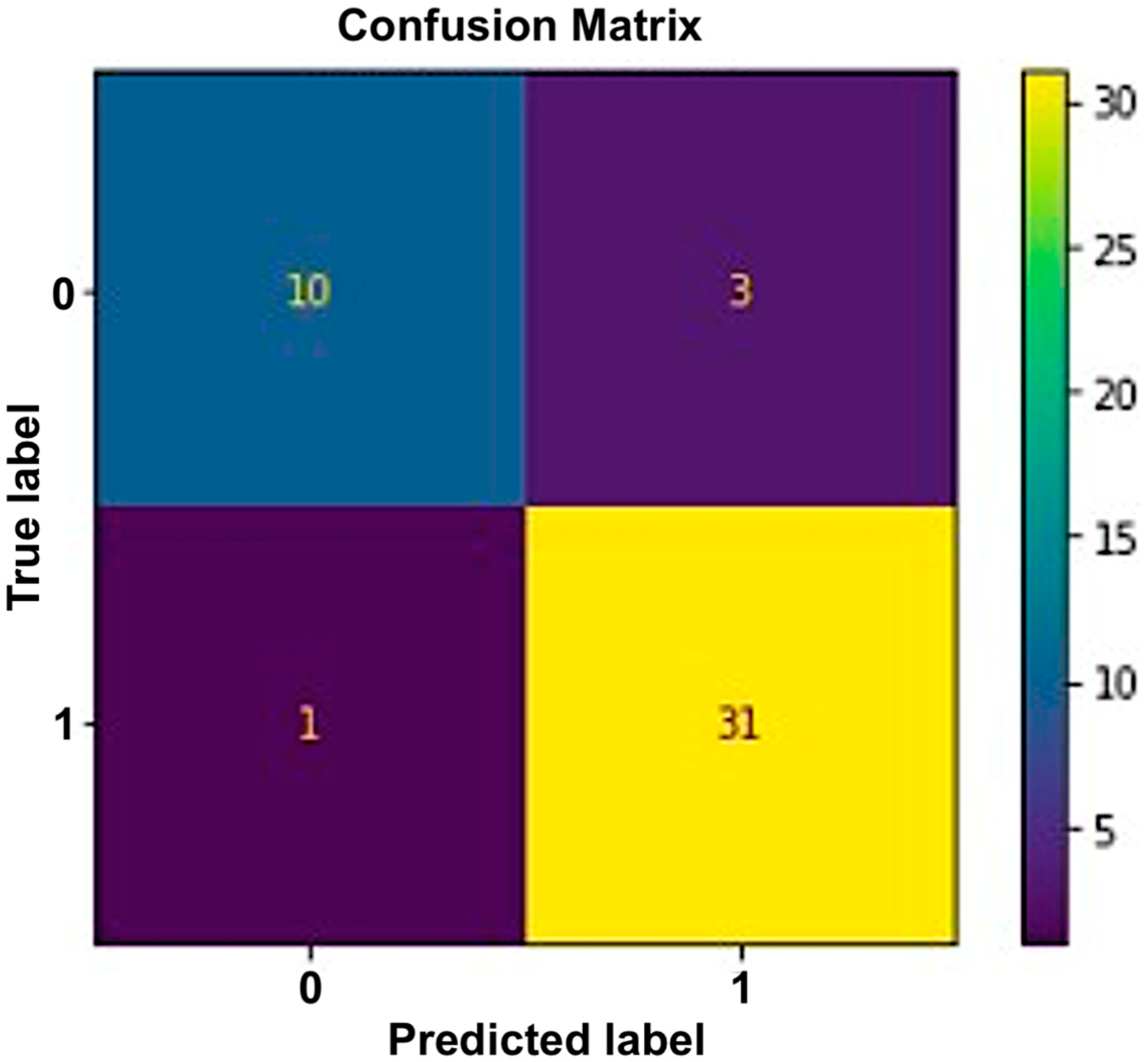
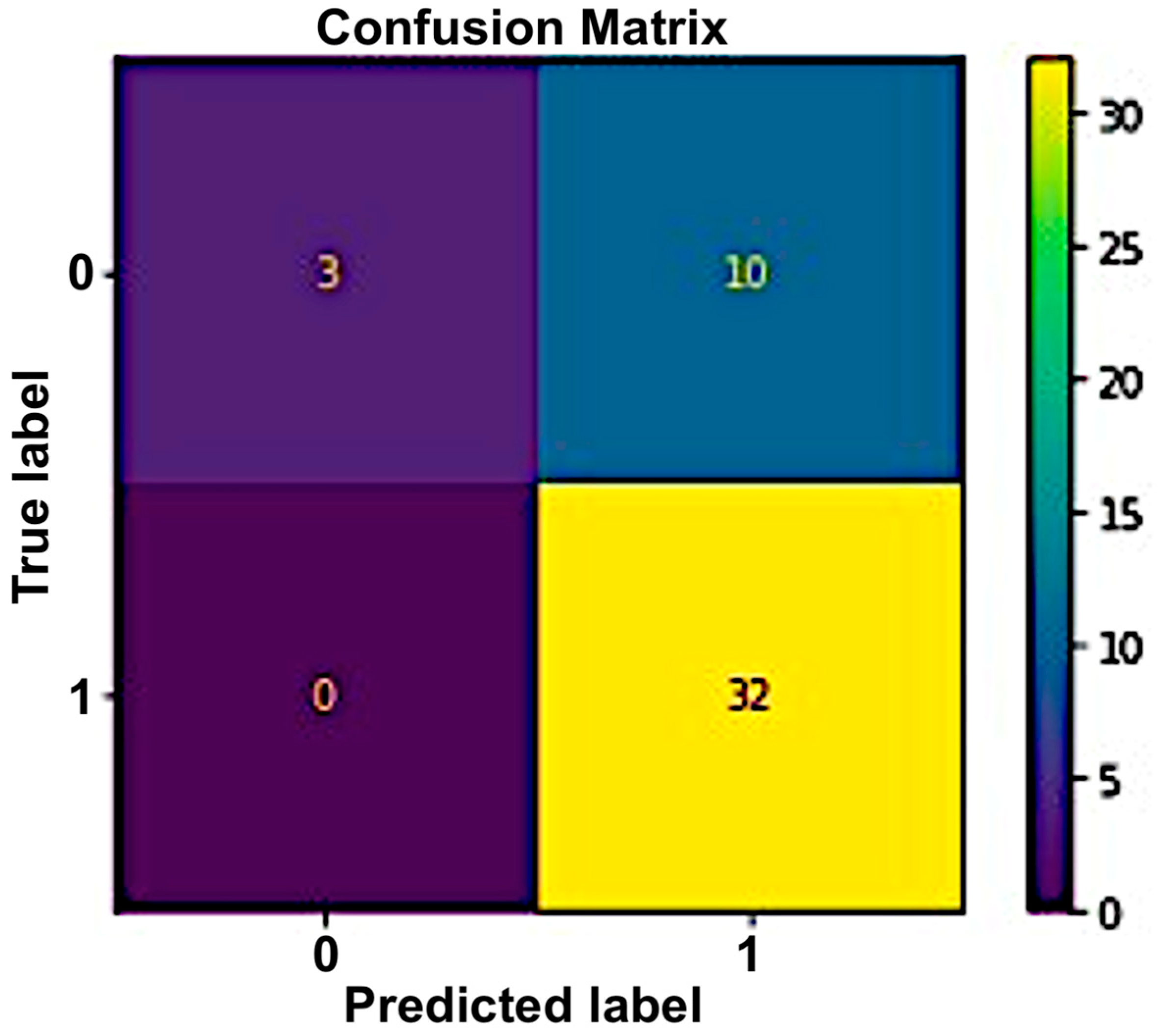
In this research, two datasets were formed using the main data. The first dataset comprised objective parameters (BP and EEG), while the second dataset comprised both objective parameters (BP and EEG) and additional parameters including age, gender, height, medication intake, weight, and smoking and alcohol status. We had to pre-process the data before applying the chosen machine learning algorithms. Pre-processing of data was conducted based on the hypothesis. The data analysis was conducted to visualize and identify any null values or missing data. There were 225 rows, which comprised the data collected from 45 participants over 5 days (45 × 5). Similarly, there were 11 columns, which represented the different objective parameters. To employ the chosen algorithms, the data for each algorithm was pre-processed to evaluate the study hypothesis. Based on the characteristics, each dataset was classified as “X” or “Y” (training data or target data). Datasets were split into training and test sets at a ratio of 80:20. Samples were labelled as zero (class 0) and one as positive (class 1). The samples were labelled as positive (class 1) if the EEG beta low power was higher than the EEG alpha power and the systolic BP had increased after the commute; otherwise, they were labelled as zero (class 0).
To employ the different machine learning algorithms, the pre-processed data for each method was used to evaluate the following research hypotheses: After the commute, if the EEG beta low power is greater than the alpha low power, systolic blood pressure will be higher. In this research, the hypothesis was tested to detect stress levels after commuting. EEG and blood pressure were acquired from the participants during the commute. The EEG signal may be utilized to detect and track stress levels in humans [
26]. EEG data consists of five distinct bands: delta, theta, alpha, and beta. In this research, we only used alpha and beta bands, as the alpha band is associated with when we are relaxed, while the beta band is active when we are actively thinking, alert, or stressed. Similarly, systolic pressure was selected from the collected BP, as it occurs when the heart contracts to pump blood out. Additionally, it is regarded as a stronger predictor of stress compared to diastolic pressure [
33,
34].
7. Conclusions
This study developed several machine-learning-based approaches deploying multimodal data to create an intelligent model capable of predicting the commute impact on human health. This research acquired responses to a questionnaire (PANAS) to illustrate the effect of commuting on self-reported evaluations. The employment of a machine-learning-based approach has led to the conclusion that systolic blood pressure was greater post commute. It was independent of the length of the journey and whether it was a short or long period of time. After the commute, beta low power in the EEG was found to be greater than alpha low power. Alpha power is associated with a relaxed but awakened state, which is observed when we are awake but relaxed and not processing a great deal of information, whereas beta power is associated with a state of mental and intellectual activity and outwardly focused concentration, reflecting a state of alertness.
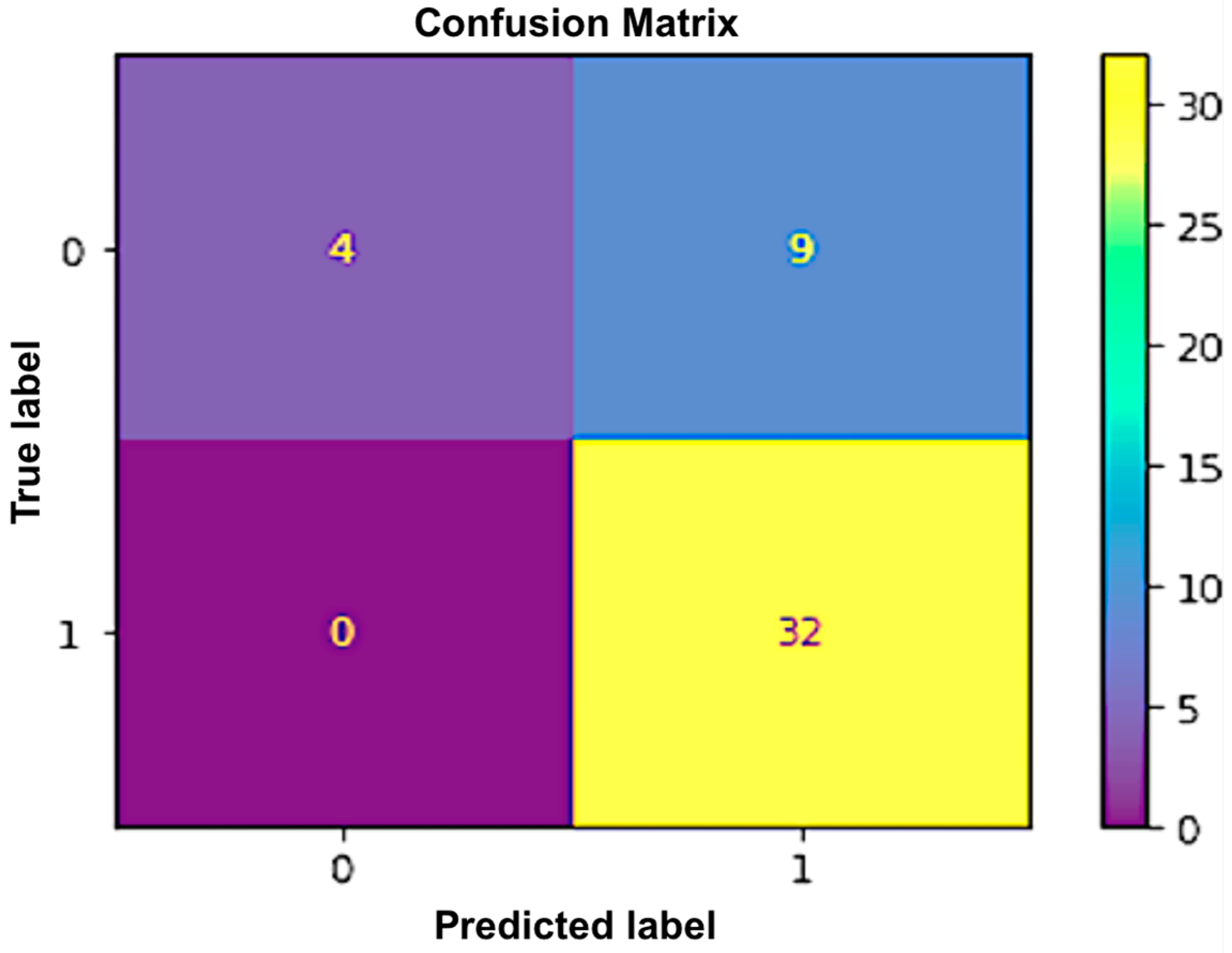
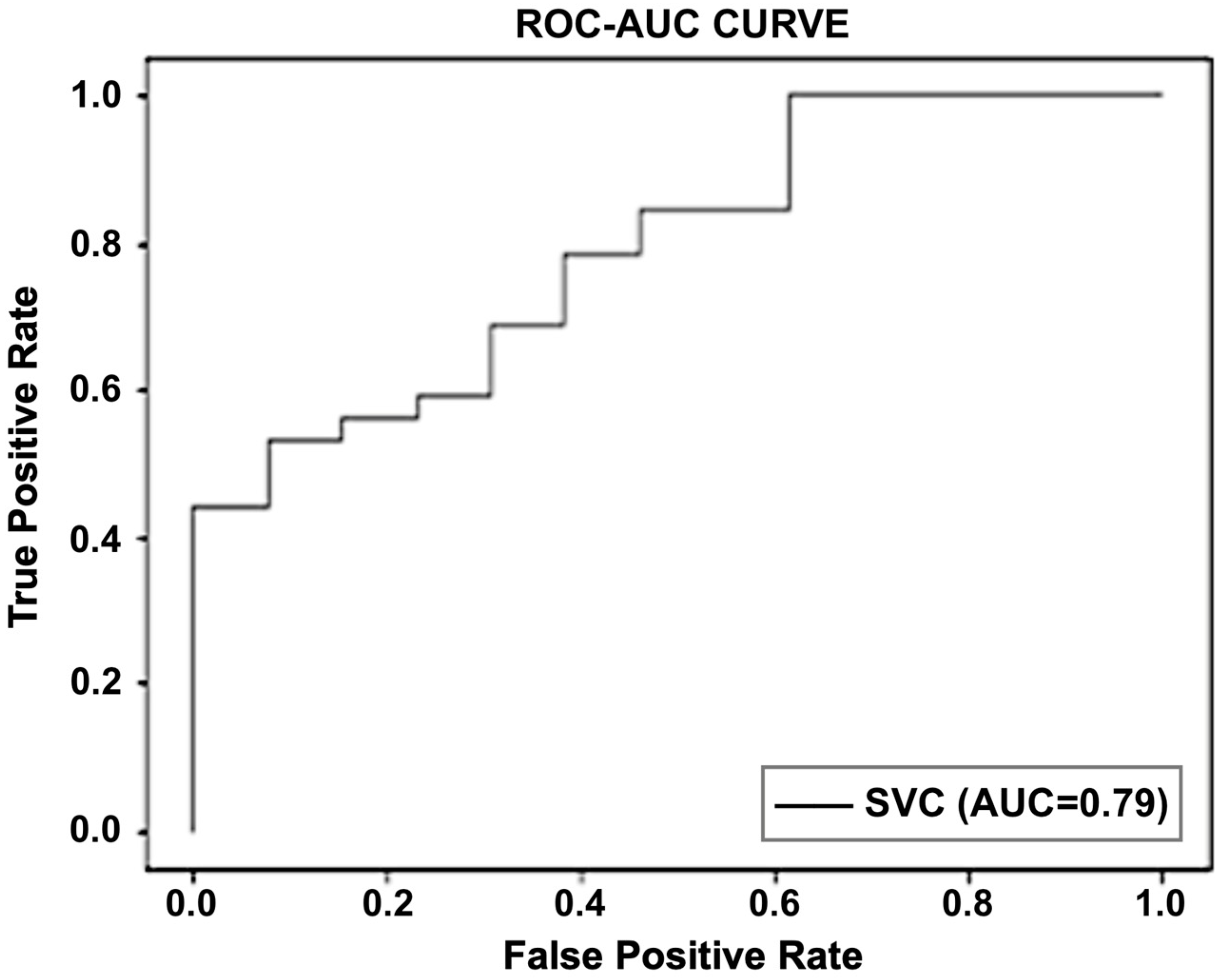
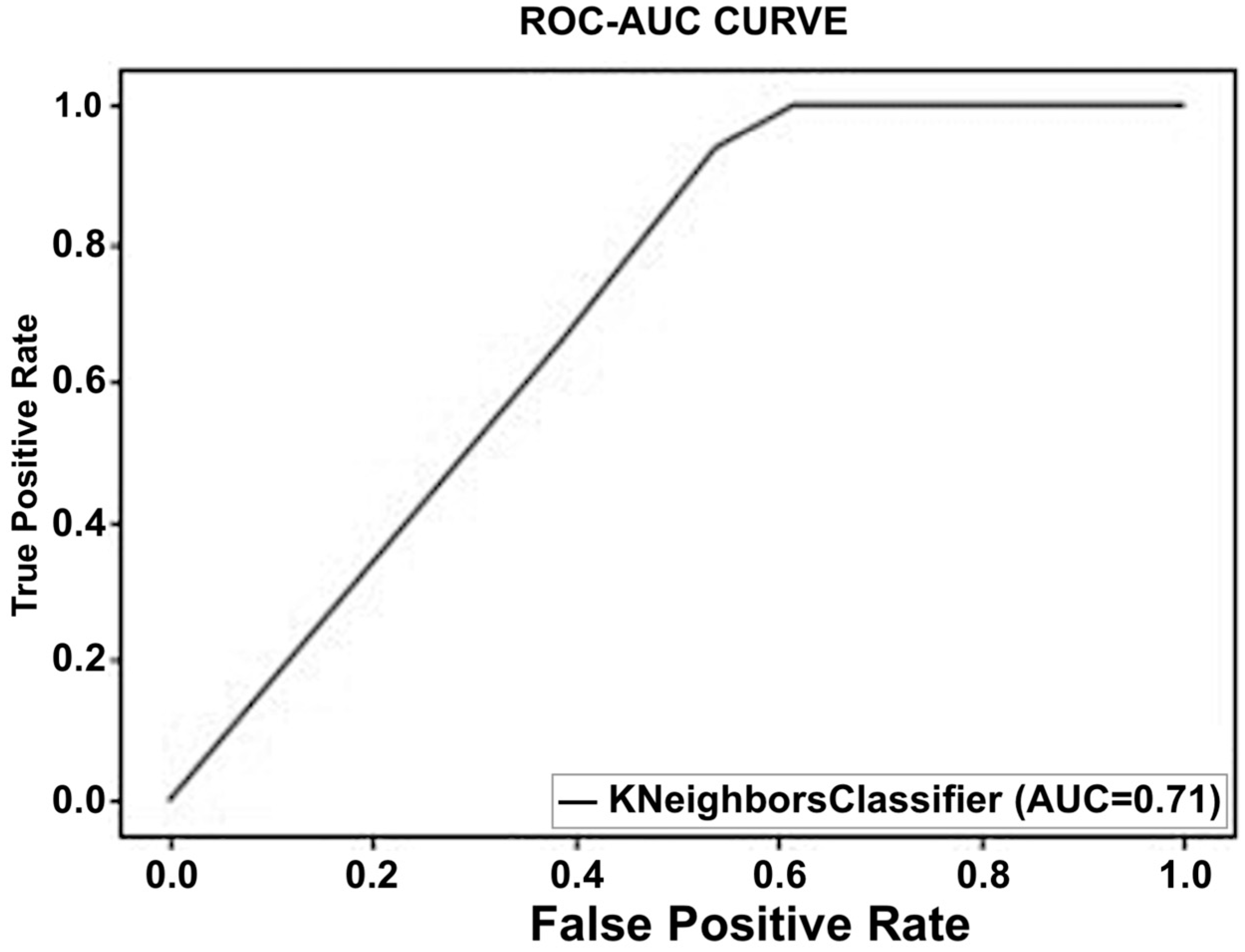
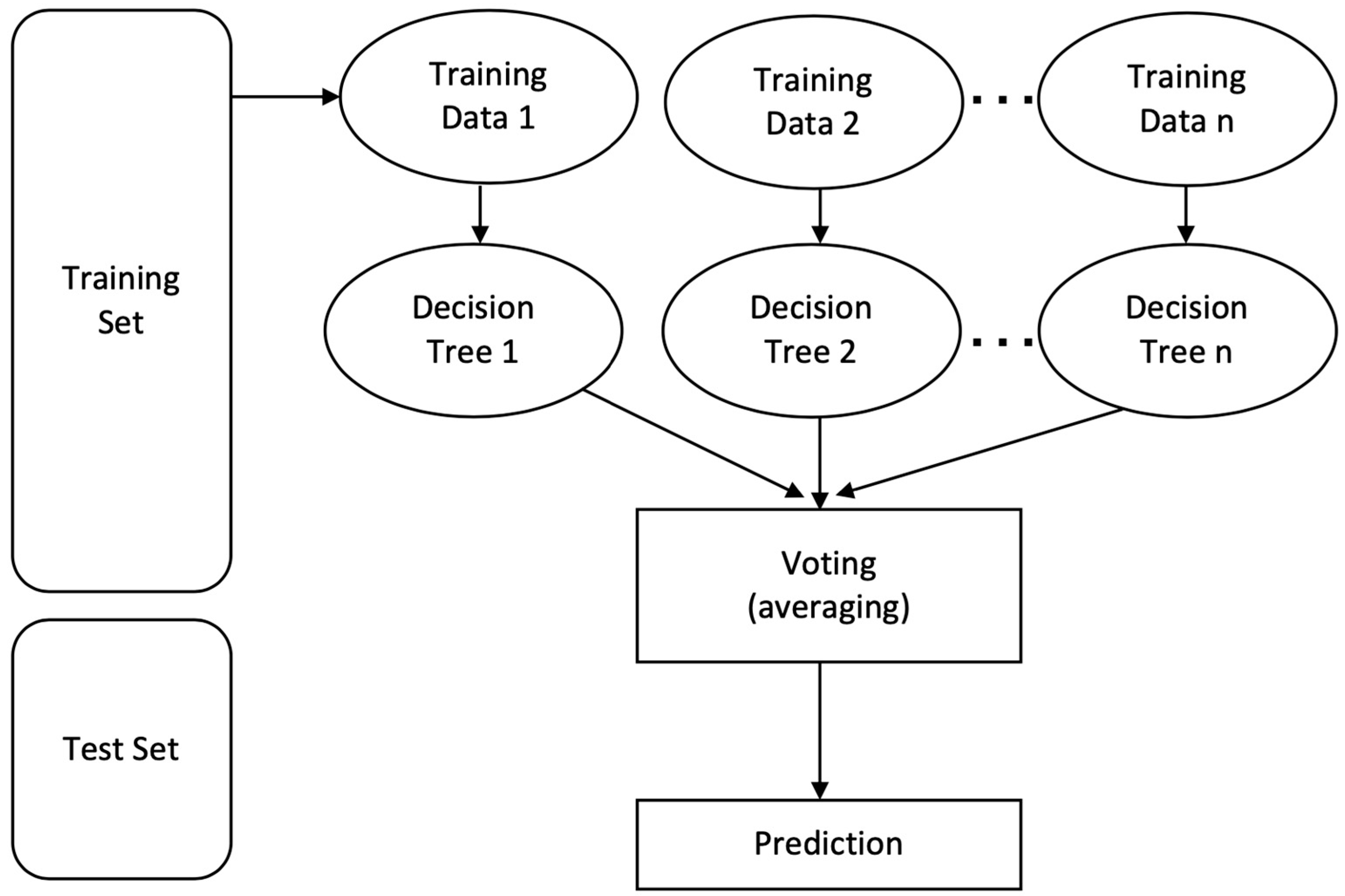
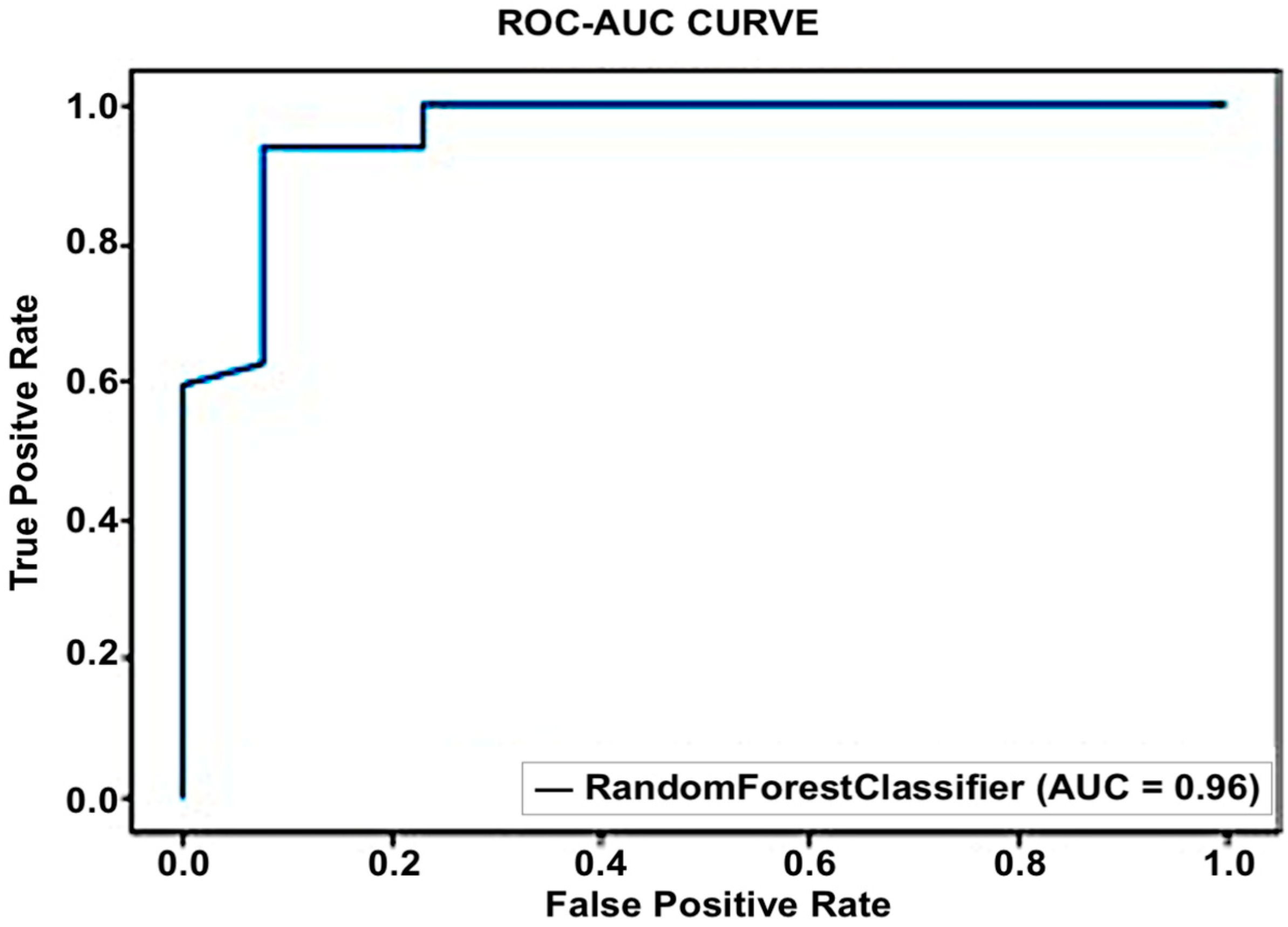
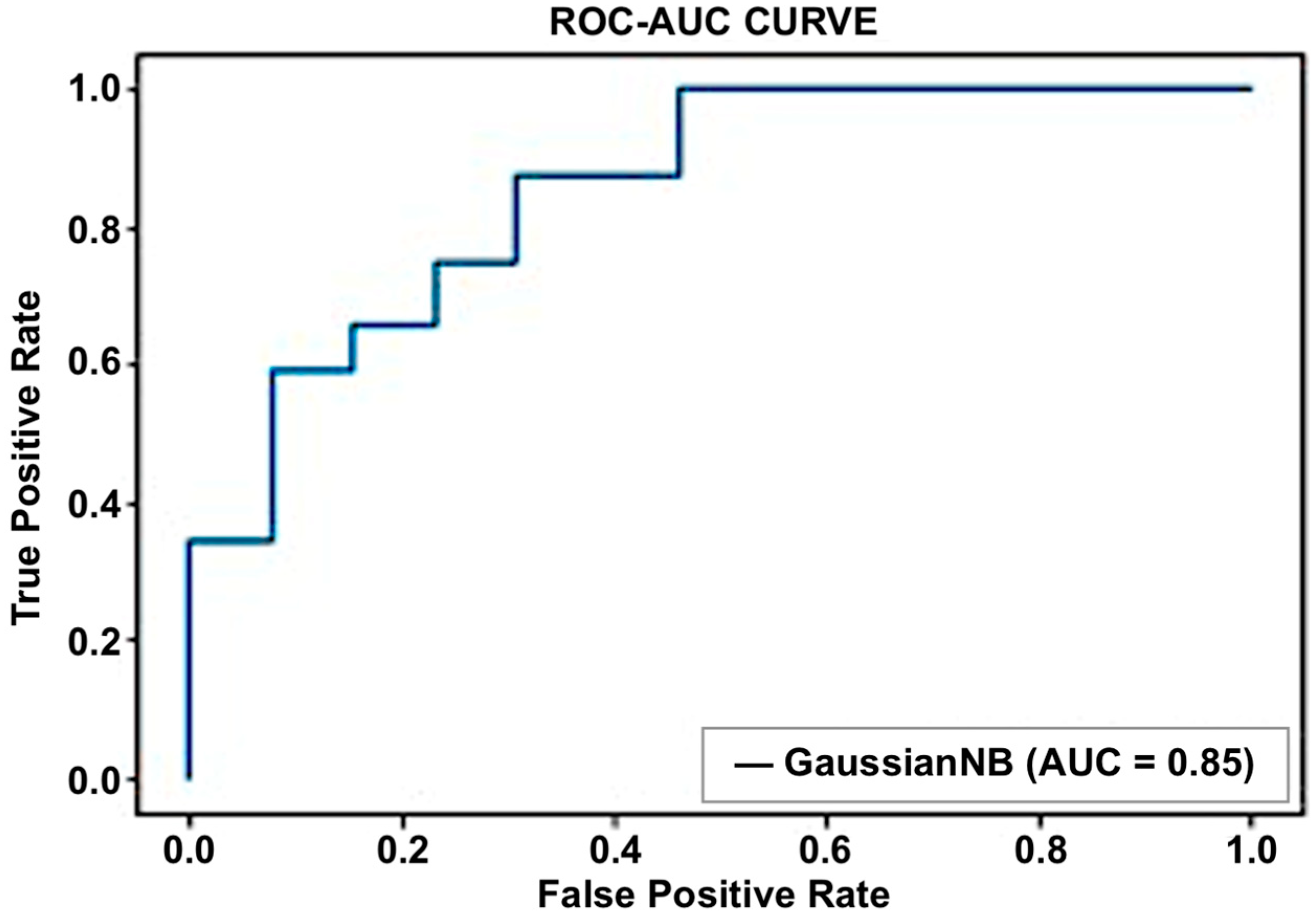
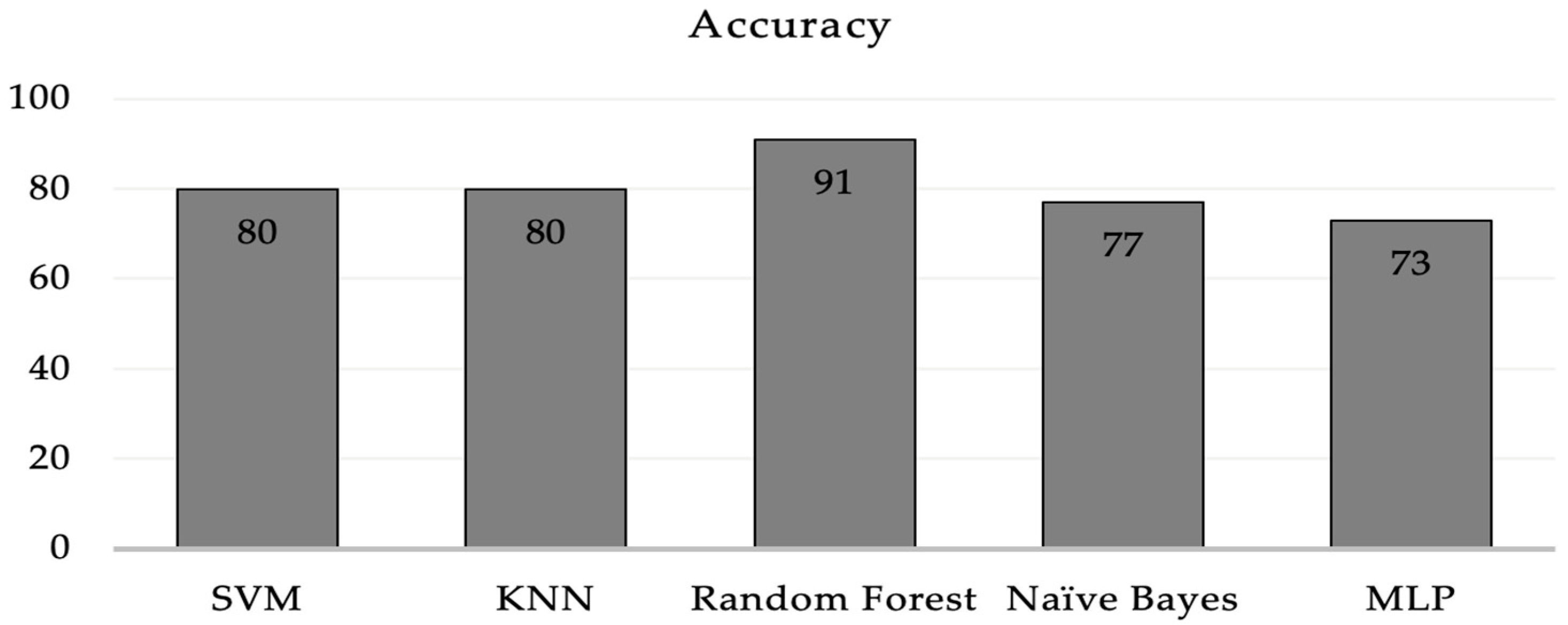
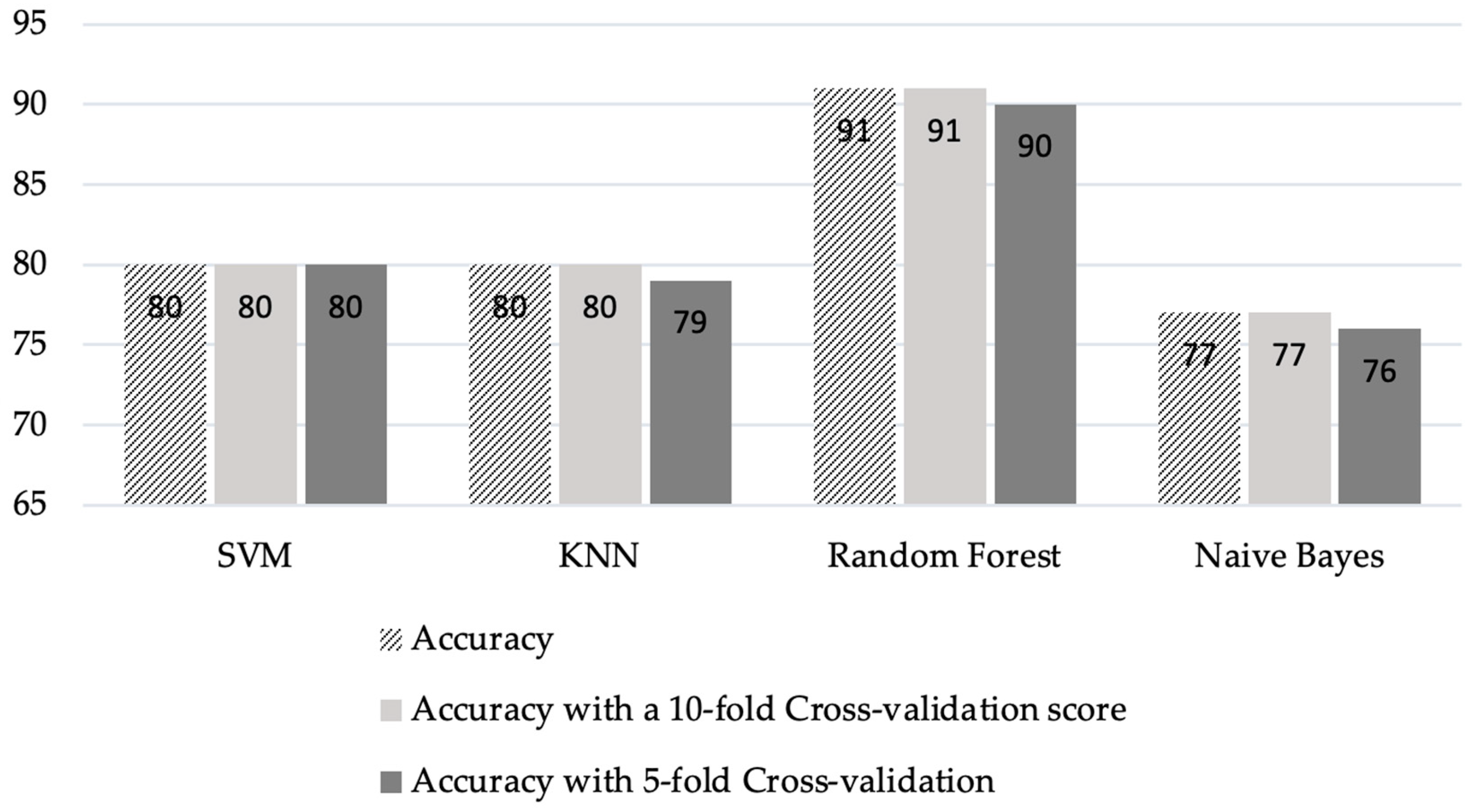
An accuracy of 91% was achieved for the first dataset, which contained the objective parameters (EEG and BP). While a 91.1% accuracy rate was attained for the second set of data, which included objective parameters and personalized parameters. The random forest algorithm showed the best performance in both datasets. The results obtained from the selected classifiers supported the research hypothesis. Similarly, using PANAS, we also found that positive affect was higher before the commute. This means that the participants were more positive and interested in going to work before the commute. Negative affect was higher after the commute, which means that participants were less interested or more stressed. The objective results from the machine-learning-based method supported the subjective results obtained using PANAS.
The goal of this study was to find out how commuting in a busy city affects a person’s body and try to predict what those effects are based on machine learning approaches. It also helps recording the experience of commuters with a special focus on the use of emerging computing technologies. This research will help make a living lab for multimodal research experiments in areas such as body sensors, ubiquitous computing, and wireless telehealth. Currently, the only people who can tell if someone is stressed or not are medical and physiological professionals. Using a questionnaire is one of the conventional methods for determining stress. This approach solely relies on the participants’ reactions: whether they tremble indicates they are under stress or not. Stress can be found automatically, which can improve social well-being and reduce the risk of health problems. It is important to make an intelligent model that uses people’s body data to automatically figure out how stressed they are and prevent hazards to their health such as high blood pressure. The objective bio signals (heart rate and BP) were found to be higher post commute than pre commute, regardless of the commute duration. Mood and stress are favorably linked with bio signals. Based on the machine learning technique, we were able to determine the participants’ stress levels after commuting.
Our future work will focus on designing a smart model to find out how commuting affects productivity at work.


 ,
, 














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}