


Anomaly Detection Module for Network Traffic Monitoring in Public Institutions
 ,
,  , , , , ,
, , , , ,
Abstract
:1. Introduction
- the procedural and organizational model of operation of the regional centres in cooperation with the national cybersecurity structure (people, processes);
- the cybersecurity monitoring platform (technology).
2. Motivation
3. Related Works
3.1. The Definition of an Anomaly
3.2. Anomaly Detection Approaches
- graph-based methods (e.g., [34]);
3.2.1. Statistical-Based Methods
3.2.2. Distance-Based Methods
3.2.3. Density-Based Methods
3.2.4. Clustering-Based Methods
3.2.5. Graph-Based Method
3.2.6. Ensemble-Based Methods
3.2.7. Learning-Based Methods
4. Anomaly Detection Module Environment
- online: based on the Scapy AsyncSniffer [70], collecting and processing packets from a network, used for pseudo-real-time monitoring;
- offline: reading CSV files, previously created by the online mode. Typically used for tuning the algorithms or reviewing historical traffic with other anomaly detection methods.
- source/destination IP address;
- pairs of IP addresses;
- IP address and port pairs.
4.1. Implemented Anomaly Detection Methods
4.1.1. Robust Kernel-Based Local Outlier Detection (RKOF)
4.1.2. VAE
4.2. Model Construction
4.3. Training and Prediction
4.4. Data Learning Selection
4.5. Processing Time Window
5. Experiments
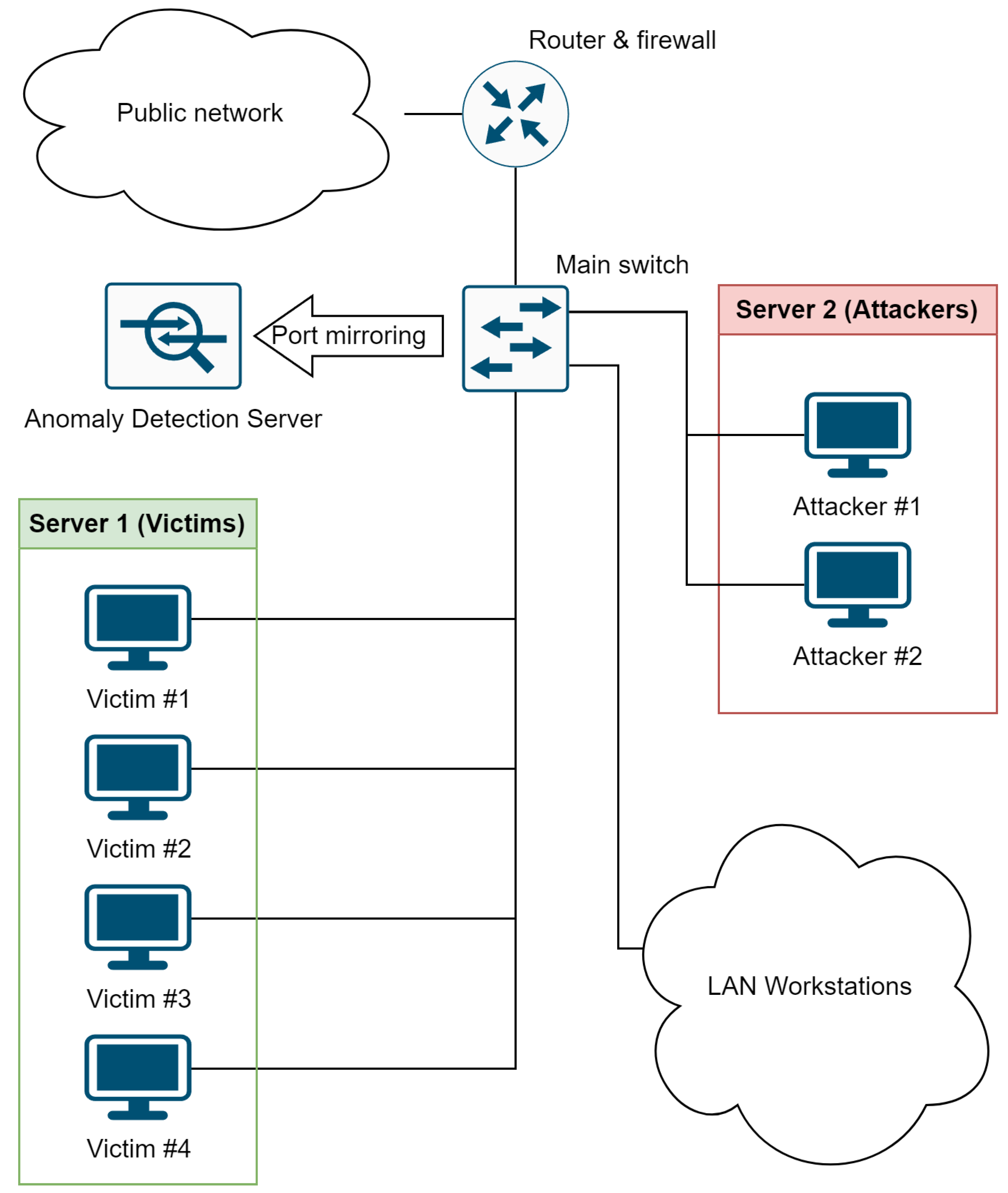
5.1. Hardware and Network Background
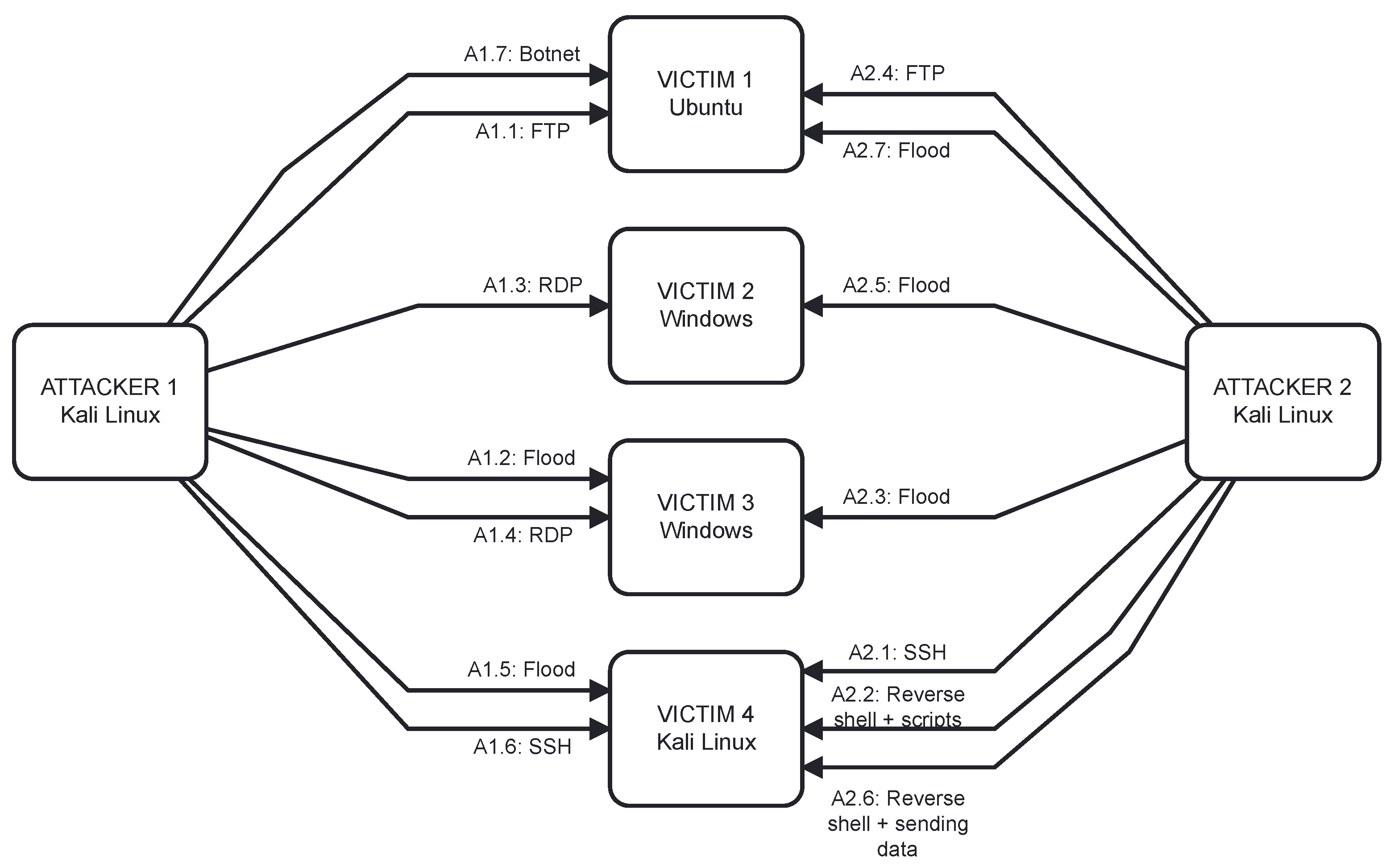
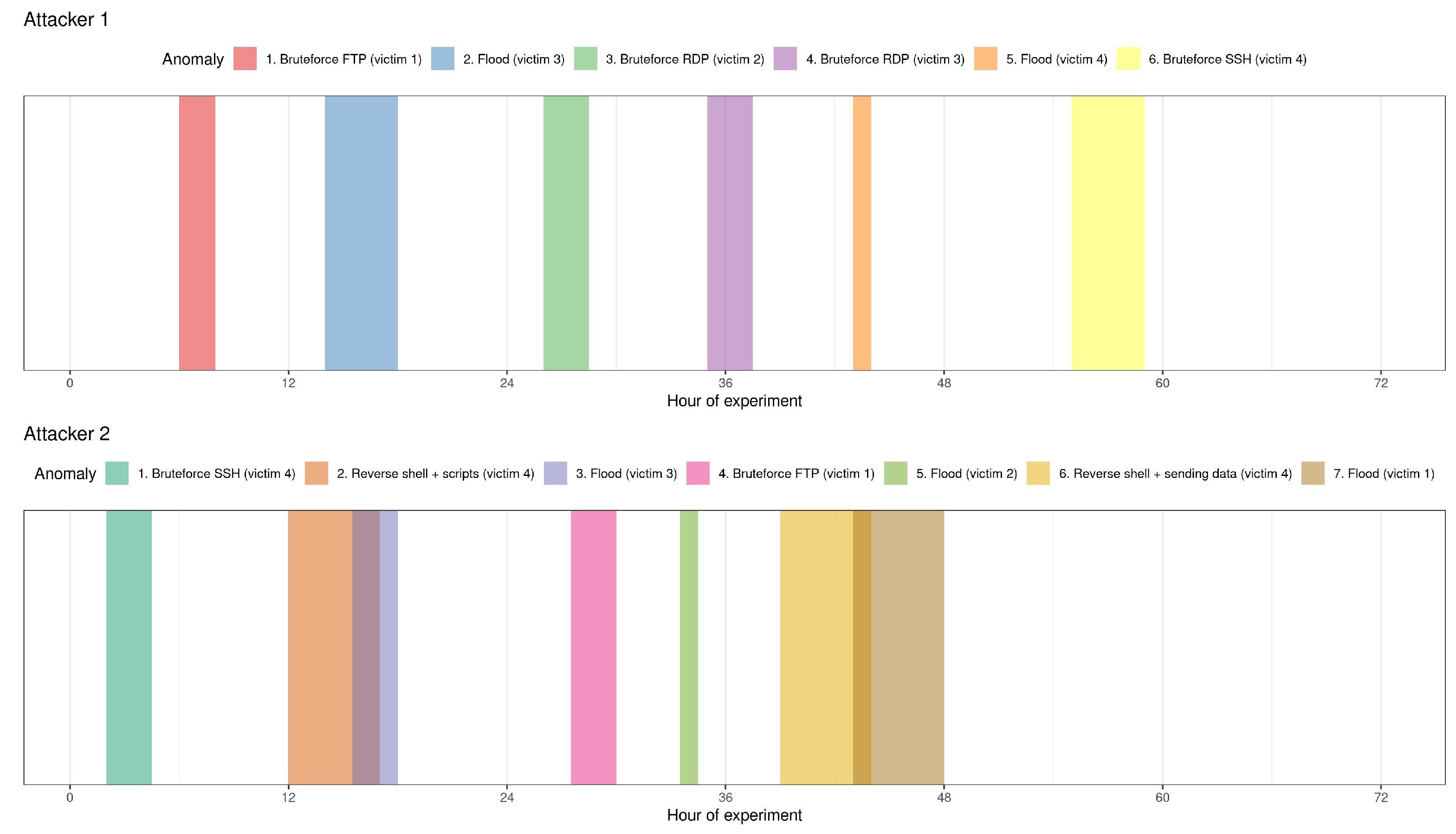
5.2. Data Preparation—Attack Script
5.3. Collected Data Pre-Processing
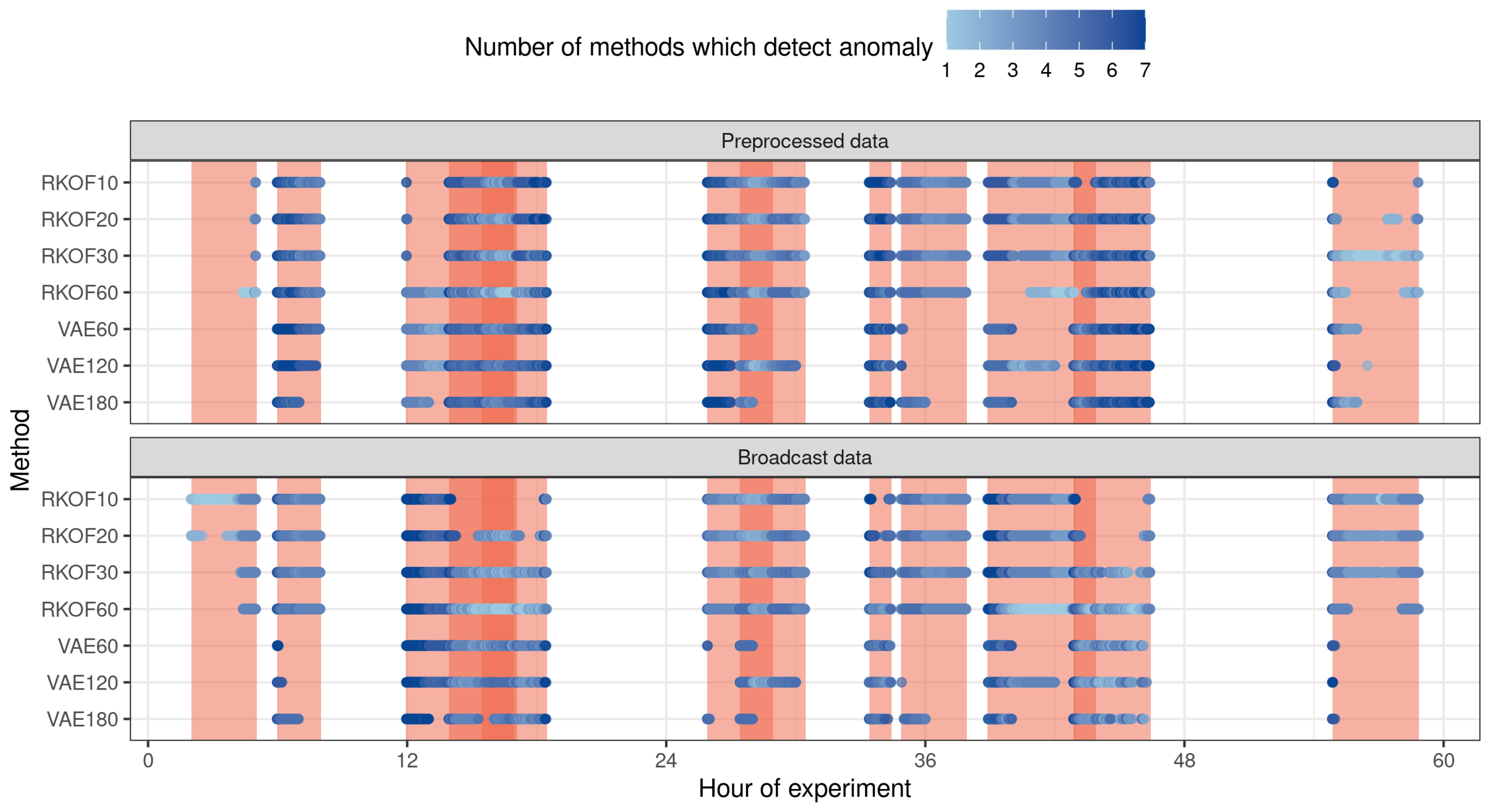
5.4. Results
6. Conclusions and Further Works
- online: such a mode is dedicated to the application phase when the anomaly detection models are trained sufficiently to detect anomalies in a network traffic description and it is possible to generate reports summing up the detected anomalies (to be further proceeded by a regional security operator);
- offline: a mode for tuning an anomaly detection method with data of known anomaly positions; such a mode helps to tune anomaly detection methods much faster than in the online (almost real-time) mode.
- the ADM is an autonomic and complete solution, based on well-known methods of anomaly detection, also equipped with strategies to train and tune;
- the ADM was developed as an additional tool to complement other network monitoring systems, e.g., ElasticSearch [74];
- it is expected that the ADM may detect zero-day attacks whose signatures remain unknown for signature-based systems because the ADM is a stream-based system;
- thanks to this, it is possible for the ADM to detect occurrences that are not detected by other tools, i.e., signature-based;
- the methodology of the tuned model is also provided with the module.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zimmerman, Z. Ten Strategies of a World–Class Cybersecurity Operations Center; The MITRE Corp.: Fairfax, VA, USA, 2014. [Google Scholar]
- Muniz, J.; McIntyre, G.; AlFardan, N. Security Operations Center: Building, Operating, and Maintaining Your SOC; Cisco Press: Indianapolis, IN, USA, 2016. [Google Scholar]
- Snort IDS. 2020. Available online: www.snort.org (accessed on 15 January 2023).
- Khan, N.F.; Ikram, N.; Murtaza, H.; Javed, M. Evaluating protection motivation based cybersecurity awareness training on Kirkpatrick’s Model. Comput. Secur. 2023, 125, 103049. [Google Scholar] [CrossRef]
- Guo, Y. A review of Machine Learning-based zero-day attack detection: Challenges and future directions. Comput. Commun. 2023, 198, 175–185. [Google Scholar] [CrossRef]
- Bialas, A.; Michalak, M.; Flisiuk, B. Anomaly detection in network traffic security assurance. In Proceedings of the International Conference on Dependability and Complex Systems, Brunow, Poland, 1–5 July 2019; Springer: Cham, Switzerland, 2019; pp. 46–56. [Google Scholar]
- Michalak, M.; Wawrowski, Ł.; Sikora, M.; Kurianowicz, R.; Kozłowski, A.; Białas, A. Open–source–based Environment for Network Traffic Anomaly Detection. In Proceedings of the Engineering in Dependability of Computer Systems and Networks, Wroclaw, Poland, 27 June–1 July 2022; pp. 284–295. [Google Scholar]
- Michalak, M.; Wawrowski, L.; Sikora, M.; Kurianowicz, R.; Kozlowski, A.; Bialas, A. Outlier Detection in Network Traffic Monitoring. In Proceedings of the 10th International Conference on Pattern Recognition Applications and Methods, Shanghai, China, 15–17 October 2021; Volume 1, pp. 523–530. [Google Scholar]
- Jiménez-Carvelo, A.M.; Li, P.; Erasmus, S.W.; Wang, H.; van Ruth, S.M. Spatial-Temporal Event Analysis as a Prospective Approach for Signalling Emerging Food Fraud-Related Anomalies in Supply Chains. Foods 2023, 12, 61. [Google Scholar] [CrossRef] [PubMed]
- Bakumenko, A.; Elragal, A. Detecting Anomalies in Financial Data Using Machine Learning Algorithms. Systems 2022, 10, 130. [Google Scholar] [CrossRef]
- Bin Sarhan, B.; Altwaijry, N. Insider Threat Detection Using Machine Learning Approach. Appl. Sci. 2023, 13, 259. [Google Scholar] [CrossRef]
- Hajtmanek, R.; Kontšek, M.; Smieško, J.; Uramová, J. One-Parameter Statistical Methods to Recognize DDoS Attacks. Symmetry 2022, 14, 2388. [Google Scholar] [CrossRef]
- Mozaffari, M.; Doshi, K.; Yilmaz, Y. Online Multivariate Anomaly Detection and Localization for High-Dimensional Settings. Sensors 2022, 22, 8264. [Google Scholar] [CrossRef]
- Breunig, M.M.; Kriegel, H.P.; Ng, R.T.; Sander, J. LOF: Identifying Density-Based Local Outliers. In Proceedings of the 2000 ACM SIGMOD International Conference on Management of Data, Dallas, TX, USA, 15–18 May 2000; pp. 93–104. [Google Scholar]
- Gao, J.; Hu, W.; Zhang, Z.M.; Zhang, X.; Wu, O. RKOF: Robust Kernel–Based Local Outlier Detection. In Proceedings of the Advances in Knowledge Discovery and Data Mining, Shenzhen, China, 24–27 May 2011; pp. 270–283. [Google Scholar]
- Knorr, E.M.; Ng, R.T. Algorithms for Mining Distance-Based Outliers in Large Datasets. In Proceedings of the 24rd International Conference on Very Large Data Bases, New York City, NY, USA, 24–27 August 1998; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 1998; pp. 392–403. [Google Scholar]
- Grubbs, F.E. Procedures for Detecting Outlying Observations in Samples. Technometrics 1969, 11, 1–21. [Google Scholar] [CrossRef]
- Hawkins, D.M. Identification of Outliers; Monographs on Applied Probability and Statistics; Springer: Dordrecht, The Netherlands, 1980. [Google Scholar]
- Barnett, V.; Lewis, T. Outliers in Statistical Data, 3rd ed.; Wiley: Chichester, UK, 1994. [Google Scholar]
- Weisberg, S. Applied Linear Regression, 3rd ed.; Wiley Series in Probability and Statistics; Wiley & Sons: Hoboken, NJ, USA, 2005. [Google Scholar]
- John, G.H. Robust Decision Trees: Removing Outliers from Databases. In Proceedings of the In Knowledge Discovery and Data Mining, Montreal, QC, Canada, 20–21 August 1995; AAAI Press: New Orleans, LA, USA, 1995; pp. 174–179. [Google Scholar]
- Aggarwal, C.C.; Yu, P.S. Outlier Detection for High Dimensional Data. SIGMOD Rec. 2001, 30, 37–46. [Google Scholar] [CrossRef]
- Ayadi, A.; Ghorbel, O.; Obeid, A.M.; Abid, M. Outlier detection approaches for wireless sensor networks: A survey. Comput. Netw. 2017, 129, 319–333. [Google Scholar] [CrossRef]
- Wang, H.; Bah, M.J.; Hammad, M. Progress in Outlier Detection Techniques: A Survey. IEEE Access 2019, 7, 107964–108000. [Google Scholar] [CrossRef]
- Yang, X.; Latecki, L.J.; Pokrajac, D. Outlier Detection with Globally Optimal Exemplar-Based GMM. In Proceedings of the 2009 SIAM International Conference on Data Mining (SDM), Sparks, NV, USA, 30 April–2 May 2009; Society for Industrial and Applied Mathematics: Philadelphia, PA, USA, 2009; pp. 145–154. [Google Scholar] [CrossRef] [Green Version]
- Tang, X.M.; Yuan, R.X.; Chen, J. Outlier Detection in Energy Disaggregation Using Subspace Learning and Gaussian Mixture Model. Int. J. Control. Autom. 2015, 8, 161–170. [Google Scholar] [CrossRef]
- Knorr, E.M.; Ng, R.T.; Tucakov, V. Distance-based outliers: Algorithms and applications. VLDB J. 2000, 8, 237–253. [Google Scholar] [CrossRef]
- Park, C.M.; Jeon, J. Regression-Based Outlier Detection of Sensor Measurements Using Independent Variable Synthesis. In Data Science: Second International Conference, ICDS 2015, Sydney, Australia, 8–9 August 2015; Zhang, C., Huang, W., Shi, Y., Yu, P.S., Zhu, Y., Tian, Y., Zhang, P., He, J., Eds.; Springer International Publishing: Cham, Switzerland, 2015; pp. 78–86. [Google Scholar]
- Ramaswamy, S.; Rastogi, R.; Shim, K. Efficient Algorithms for Mining Outliers from Large Data Sets. SIGMOD Rec. 2000, 29, 427–438. [Google Scholar] [CrossRef]
- Angiulli, F.; Basta, S.; Pizzuti, C. Distance-based detection and prediction of outliers. IEEE Trans. Knowl. Data Eng. 2006, 18, 145–160. [Google Scholar] [CrossRef]
- Schubert, E.; Zimek, A.; Kriegel, H.P. Local outlier detection reconsidered: A generalized view on locality with applications to spatial, video, and network outlier detection. Data Min. Knowl. Discov. 2014, 28, 190–237. [Google Scholar] [CrossRef]
- Ester, M.; Kriegel, H.P.; Sander, J.; Xu, X. A Density-Based Algorithm for Discovering Clusters in Large Spatial Databases with Noise. In Proceedings of the Second International Conference on Knowledge Discovery and Data Mining (KDD’96), Portland, OR, USA, 2–4 August 1996; AAAI Press: New Orleans, LA, USA, 1996; pp. 226–231. [Google Scholar]
- Hinneburg, A.; Keim, D.A. An Efficient Approach to Clustering in Large Multimedia Databases with Noise. In Proceedings of the Fourth International Conference on Knowledge Discovery and Data Mining (KDD’98), New York, NY, USA, 27–31 August 1998; AAAI Press: New Orleans, LA, USA, 1998; pp. 58–65. [Google Scholar]
- Kim, H.; Lee, B.S.; Shin, W.Y.; Lim, S. Graph Anomaly Detection with Graph Neural Networks: Current Status and Challenges. IEEE Access 2022, 10, 111820–111829. [Google Scholar] [CrossRef]
- Zhao, Y.; Hryniewicki, M.K. XGBOD: Improving Supervised Outlier Detection with Unsupervised Representation Learning. In Proceedings of the 2018 International Joint Conference on Neural Networks (IJCNN), Rio de Janeiro, Brazil, 8–13 July 2018; pp. 1–8. [Google Scholar] [CrossRef] [Green Version]
- Rayana, S.; Akoglu, L. Less is More: Building Selective Anomaly Ensembles. ACM Trans. Knowl. Discov. Data 2016, 10, 42. [Google Scholar] [CrossRef]
- Aggarwal, C.; Yu, S. An Effective and Efficient Algorithm for High-Dimensional Outlier Detection. VLDB J. 2005, 14, 211–221. [Google Scholar] [CrossRef]
- Dutta, J.K.; Banerjee, B.; Reddy, C.K. RODS: Rarity based Outlier Detection in a Sparse Coding Framework. IEEE Trans. Knowl. Data Eng. 2016, 28, 483–495. [Google Scholar] [CrossRef]
- Müller, E.; Schiffer, M.; Seidl, T. Statistical selection of relevant subspace projections for outlier ranking. In Proceedings of the 2011 IEEE 27th International Conference on Data Engineering, Hannover, Germany, 11–16 April 2011; pp. 434–445. [Google Scholar] [CrossRef]
- Grubbs, F.E. Sample criteria for testing outlying observations. Ann. Math. Stat. 1950, 21, 27–58. [Google Scholar] [CrossRef]
- Bishop, C.M. Pattern Recognition and Machine Learning (Information Science and Statistics); Springer: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Amutha, A.L.; Annie Uthra, R.; Preetha Roselyn, J.; Golda Brunet, R. Anomaly detection in multivariate streaming PMU data using density estimation technique in wide area monitoring system. Expert Syst. Appl. 2021, 175, 114865. [Google Scholar] [CrossRef]
- Satman, M. A new algorithm for detecting outliers in linear regression. Int. J. Stat. Probab. 2013, 2, 101–109. [Google Scholar] [CrossRef] [Green Version]
- Latecki, L.J.; Lazarevic, A.; Pokrajac, D. Outlier Detection with Kernel Density Functions. In Machine Learning and Data Mining in Pattern Recognition; Perner, P., Ed.; Springer: Berlin/Heidelberg, Germany, 2007; pp. 61–75. [Google Scholar]
- Zhang, L.; Lin, J.; Karim, R. Adaptive kernel density-based anomaly detection for nonlinear systems. Knowl.-Based Syst. 2018, 139, 50–63. [Google Scholar] [CrossRef] [Green Version]
- Dang, T.T.; Ngan, H.Y.; Liu, W. Distance-based k-nearest neighbors outlier detection method in large-scale traffic data. In Proceedings of the 2015 IEEE International Conference on Digital Signal Processing (DSP), Singapore, 21–24 July 2015; pp. 507–510. [Google Scholar] [CrossRef]
- Wang, B.; Xiao, G.; Yu, H.; Yang, X. Distance-Based Outlier Detection on Uncertain Data. In Proceedings of the 2009 Ninth IEEE International Conference on Computer and Information Technology, Washington, DC, USA, 11–14 October 2009; Volume 1, pp. 293–298. [Google Scholar] [CrossRef]
- Shaikh, S.A.; Kitagawa, H. Distance-Based Outlier Detection on Uncertain Data of Gaussian Distribution. In Web Technologies and Applications; Sheng, Q.Z., Wang, G., Jensen, C.S., Xu, G., Eds.; Springer: Berlin/Heidelberg, Germany, 2012; pp. 109–121. [Google Scholar]
- Yang, Y.; Fan, C.; Chen, L.; Xiong, H. IPMOD: An efficient outlier detection model for high-dimensional medical data streams. Expert Syst. Appl. 2022, 191, 116212. [Google Scholar] [CrossRef]
- Chen, L.; Wang, W.; Yang, Y. CELOF: Effective and fast memory efficient local outlier detection in high-dimensional data streams. Appl. Soft Comput. 2021, 102, 107079. [Google Scholar] [CrossRef]
- Tang, J.; Chen, Z.; Fu, A.W.c.; Cheung, D.W. Enhancing Effectiveness of Outlier Detections for Low Density Patterns. In Advances in Knowledge Discovery and Data Mining; Chen, M.S., Yu, P.S., Liu, B., Eds.; Springer: Berlin/Heidelberg, Germany, 2002; pp. 535–548. [Google Scholar]
- Kriegel, H.P.; Kröger, P.; Schubert, E.; Zimek, A. LoOP: Local outlier probabilities. In Proceedings of the CIKM, Hong Kong, China, 2–6 November 2009; Cheung, D.W.L., Song, I.Y., Chu, W.W., Hu, X., Lin, J., Eds.; ACM: New Orleans, LA, USA, 2009; pp. 1649–1652. [Google Scholar]
- Xu, X.; Lei, Y.; Li, Z. An Incorrect Data Detection Method for Big Data Cleaning of Machinery Condition Monitoring. IEEE Trans. Ind. Electron. 2020, 67, 2326–2336. [Google Scholar] [CrossRef]
- Jiang, M.; Tseng, S.; Su, C. Two-phase clustering process for outliers detection. Pattern Recognit. Lett. 2001, 22, 691–700. [Google Scholar] [CrossRef]
- Zhang, Y.; Meratnia, N.; Havinga, P. Outlier Detection Techniques for Wireless Sensor Networks: A Survey. IEEE Commun. Surv. Tutor. 2010, 12, 159–170. [Google Scholar] [CrossRef] [Green Version]
- Akoglu, L.; Tong, H.; Koutra, D. Graph based anomaly detection and description: A survey. Data Min. Knowl. Discov. 2015, 29, 626–688. [Google Scholar] [CrossRef] [Green Version]
- Perozzi, B.; Akoglu, L.; Iglesias Sánchez, P.; Müller, E. Focused Clustering and Outlier Detection in Large Attributed Graphs. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD’14), New York, NY, USA, 24–27 August 2014; Association for Computing Machinery: New York, NY, USA, 2014; pp. 1346–1355. [Google Scholar] [CrossRef]
- Kang, U.; Lee, J.Y.; Koutra, D.; Faloutsos, C. Net-Ray: Visualizing and Mining Billion-Scale Graphs. In Proceedings of the Advances in Knowledge Discovery and Data Mining, Tainan, Taiwan, 13–16 May 2014; Tseng, V.S., Ho, T.B., Zhou, Z.H., Chen, A.L.P., Kao, H.Y., Eds.; Springer International Publishing: Cham, Switzerland, 2014; pp. 348–361. [Google Scholar]
- Rossi, R.A.; Gallagher, B.; Neville, J.; Henderson, K. Modeling Dynamic Behavior in Large Evolving Graphs. In Proceedings of the Sixth ACM International Conference on Web Search and Data Mining (WSDM’13), Rome, Italy, 4–8 February 2013; Association for Computing Machinery: New York, NY, USA, 2013; pp. 667–676. [Google Scholar] [CrossRef] [Green Version]
- Rokah, L. Ensemble-based classifiers. Artif. Intell. Rev. 2010, 33, 1–39. [Google Scholar] [CrossRef]
- Freund, Y.; Schapire, R.E. Experiments with a New Boosting Algorithm. In Proceedings of the Thirteenth International Conference on International Conference on Machine Learning (ICML’96), Bari, Italy, 3–6 July 1996; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 1996; pp. 148–156. [Google Scholar]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Gaikwad, D.; Thool, R.C. Intrusion Detection System Using Bagging with Partial Decision TreeBase Classifier. Procedia Comput. Sci. 2015, 49, 92–98. [Google Scholar] [CrossRef] [Green Version]
- Li, C.; Guo, L.; Gao, H.; Li, Y. Similarity-Measured Isolation Forest: Anomaly Detection Method for Machine Monitoring Data. IEEE Trans. Instrum. Meas. 2021, 70, 3512512. [Google Scholar] [CrossRef]
- Rubens, N.; Elahi, M.; Sugiyama, M.; Kaplan, D. Active Learning in Recommender Systems. In Recommender Systems Handbook; Ricci, F., Rokach, L., Shapira, B., Eds.; Springer: Boston, MA, USA, 2015; pp. 809–846. [Google Scholar] [CrossRef]
- Deng, L.; Yu, D. Deep Learning: Methods and Applications. Found. Trends® Signal Process. 2014, 7, 197–387. [Google Scholar] [CrossRef] [Green Version]
- Russo, S.; Lürig, M.; Hao, W.; Matthews, B.; Villez, K. Active learning for anomaly detection in environmental data. Environ. Model. Softw. 2020, 134, 104869. [Google Scholar] [CrossRef]
- Zipfel, J.; Verworner, F.; Fischer, M.; Wiel, U.; Kraus, M.; Zschech, P. Anomaly detection for industrial quality assurance: A comparative evaluation of unsupervised deep learning models. Comput. Ind. Eng. 2023, 177, 109045. [Google Scholar] [CrossRef]
- Gómez, A.L.P.; Maimó, L.F.; Celdrán, A.H.; Clemente, F.J.G. SUSAN: A Deep Learning based anomaly detection framework for sustainable industry. Sustain. Comput. Inform. Syst. 2023, 37, 100842. [Google Scholar] [CrossRef]
- Philippe Biondi. 2019. Available online: https://www.scapy.net/ (accessed on 15 January 2023).
- Kingma, D.P.; Welling, M. Auto-Encoding Variational Bayes. arXiv 2013, arXiv:1312.6114. [Google Scholar] [CrossRef]
- Kathareios, G.; Anghel, A.; Mate, A.; Clauberg, R.; Gusat, M. Catch It If You Can: Real-Time Network Anomaly Detection with Low False Alarm Rates. In Proceedings of the 2017 16th IEEE International Conference on Machine Learning and Applications (ICMLA), Cancun, Mexico, 18–21 December 2017; pp. 924–929. [Google Scholar] [CrossRef]
- Wawrowski, Ł.; Michalak, M.; Białas, A.; Kurianowicz, R.; Sikora, M.; Uchroński, M.; Kajzer, A. Detecting anomalies and attacks in network traffic monitoring with classification methods and XAI-based explainability. Procedia Comput. Sci. 2021, 192, 2259–2268. [Google Scholar] [CrossRef]
- Negoita, O.; Carabas, M. Enhanced security using elasticsearch and machine learning. In Proceedings of the 2020 Computing Conference, London, UK, 16–17 July 2020; Springer: Cham, Switzerland, 2020; Volume 3, pp. 244–254. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Number of Anomalies | Percentage of Anomalies |
|---|---|---|
| Pre-processed data | ||
| RKOF10 | 8262 | 3.58 |
| RKOF20 | 5840 | 2.53 |
| RKOF30 | 6252 | 2.71 |
| RKOF60 | 4113 | 1.78 |
| VAE60 | 8060 | 3.49 |
| VAE120 | 22,703 | 9.84 |
| VAE180 | 20,156 | 8.74 |
| Broadcast data | ||
| RKOF10 | 7466 | 9.21 |
| RKOF20 | 10,715 | 13.22 |
| RKOF30 | 9208 | 11.36 |
| RKOF60 | 4929 | 6.08 |
| VAE60 | 6614 | 8.16 |
| VAE120 | 10,629 | 13.12 |
| VAE180 | 9514 | 11.74 |
| Method | Balanced Accuracy | Sensitivity (TPR) | Specificity (TNR) |
|---|---|---|---|
| Pre-processed data | |||
| RKOF10 | 0.7337 | 0.4944 | 0.9730 |
| RKOF20 | 0.7598 | 0.5351 | 0.9845 |
| RKOF30 | 0.8251 | 0.6651 | 0.9852 |
| RKOF60 | 0.7438 | 0.4962 | 0.9914 |
| VAE60 | 0.6781 | 0.3844 | 0.9718 |
| VAE120 | 0.6700 | 0.4319 | 0.9080 |
| VAE180 | 0.7049 | 0.4894 | 0.9204 |
| Broadcast data | |||
| RKOF10 | 0.7575 | 0.5793 | 0.9356 |
| RKOF20 | 0.7390 | 0.5845 | 0.8936 |
| RKOF30 | 0.7976 | 0.6767 | 0.9185 |
| RKOF60 | 0.7777 | 0.5864 | 0.9691 |
| VAE60 | 0.5751 | 0.2237 | 0.9265 |
| VAE120 | 0.5441 | 0.2146 | 0.8736 |
| VAE180 | 0.6244 | 0.3528 | 0.8960 |
| Attack | RKOF10 | RKOF20 | RKOF30 | RKOF60 | VAE60 | VAE120 | VAE180 |
|---|---|---|---|---|---|---|---|
| Pre-processed data | |||||||
| A1.1: Brute-force FTP | 100.00 | 80.83 | 100.00 | 87.08 | 51.67 | 51.25 | 40.83 |
| A1.2: Flood | 53.72 | 58.78 | 65.96 | 37.77 | 60.64 | 63.83 | 56.12 |
| A1.3: Brute-force RDP | 99.45 | 99.72 | 80.66 | 34.81 | 20.44 | 70.17 | 22.93 |
| A1.4: Brute-force RDP | 100.00 | 100.00 | 100.00 | 72.65 | 33.43 | 1.66 | 0.55 |
| A1.5: Flood | 14.75 | 36.07 | 87.70 | 41.80 | 75.41 | 86.07 | 87.70 |
| A1.6: Brute-force SSH | 2.08 | 17.50 | 94.58 | 30.83 | 9.79 | 7.71 | 2.29 |
| A2.1: Brute-force SSH | 1.10 | 2.76 | 0.55 | 19.61 | 0.00 | 0.00 | 0.00 |
| A2.2: Reverse shell + scripts | 0.32 | 0.96 | 0.64 | 66.99 | 40.71 | 76.60 | 76.28 |
| A2.3: Flood | 47.24 | 50.28 | 68.23 | 50.83 | 63.26 | 65.19 | 60.77 |
| A2.4: Brute-force FTP | 50.55 | 49.45 | 66.57 | 82.87 | 19.89 | 19.89 | 86.19 |
| A2.5: Flood | 53.28 | 71.31 | 75.41 | 100.00 | 81.15 | 83.61 | 90.98 |
| A2.6: Reverse shell + sending data | 49.69 | 50.93 | 48.45 | 24.33 | 27.22 | 27.22 | 76.70 |
| A2.7: Flood | 71.70 | 86.08 | 90.80 | 53.30 | 79.01 | 80.66 | 88.21 |
| Mean | 49.53 | 54.21 | 67.66 | 54.07 | 43.28 | 48.76 | 53.04 |
| Median | 50.55 | 50.93 | 75.41 | 50.83 | 40.71 | 63.83 | 60.77 |
| Broadcast data | |||||||
| A1.1: Brute-force FTP | 100.00 | 100.00 | 100.00 | 90.42 | 28.33 | 2.50 | 8.33 |
| A1.2: Flood | 2.13 | 23.67 | 50.53 | 58.78 | 30.59 | 39.63 | 40.43 |
| A1.3: Brute-force RDP | 100.00 | 100.00 | 78.45 | 32.60 | 3.87 | 0.55 | 0.00 |
| A1.4: Brute-force RDP | 100.00 | 100.00 | 100.00 | 71.27 | 33.15 | 0.00 | 0.28 |
| A1.5: Flood | 9.84 | 24.59 | 42.62 | 40.16 | 59.02 | 80.33 | 81.15 |
| A1.6: Brute-force SSH | 99.17 | 94.58 | 94.58 | 37.29 | 1.67 | 1.67 | 0.83 |
| A2.1: Brute-force SSH | 99.45 | 34.81 | 23.48 | 19.89 | 0.00 | 0.00 | 0.00 |
| A2.2: Reverse shell + scripts | 76.28 | 75.64 | 75.64 | 78.21 | 35.90 | 54.17 | 76.28 |
| A2.3: Flood | 2.21 | 35.08 | 52.49 | 75.69 | 20.99 | 20.44 | 25.97 |
| A2.4: Brute-force FTP | 51.38 | 51.38 | 96.13 | 85.08 | 19.89 | 19.89 | 85.36 |
| A2.5: Flood | 12.30 | 31.97 | 52.46 | 99.18 | 57.38 | 68.85 | 87.70 |
| A2.6: Reverse shell + sending data | 50.10 | 50.31 | 51.75 | 55.67 | 24.12 | 23.09 | 54.85 |
| A2.7: Flood | 5.19 | 14.15 | 47.64 | 54.72 | 31.60 | 38.68 | 59.43 |
| Mean | 54.46 | 56.63 | 66.60 | 61.46 | 26.65 | 26.91 | 40.05 |
| Median | 51.38 | 50.31 | 52.49 | 58.78 | 28.33 | 20.44 | 40.43 |
| Methods | BACC | Sens. | Spec. |
|---|---|---|---|
| Pre-processed | |||
| RKOF20, RKOF30, RKOF60, VAE60 | 0.9162 | 0.8829 | 0.9495 |
| RKOF10, RKOF30, RKOF60, VAE60 | 0.9152 | 0.8895 | 0.9409 |
| RKOF10, RKOF20, RKOF30, RKOF60, VAE60 | 0.9140 | 0.8895 | 0.9384 |
| RKOF10, RKOF30, RKOF60 | 0.9138 | 0.8650 | 0.9626 |
| RKOF10, RKOF20, RKOF30, RKOF60 | 0.9124 | 0.8652 | 0.9595 |
| RKOF30, RKOF60, VAE60 | 0.9075 | 0.8595 | 0.9554 |
| RKOF20, RKOF30, RKOF60 | 0.9071 | 0.8403 | 0.9740 |
| RKOF10, RKOF30, RKOF60, VAE180 | 0.9026 | 0.9165 | 0.8887 |
| RKOF20, RKOF30, RKOF60, VAE180 | 0.9016 | 0.9053 | 0.8978 |
| RKOF10, RKOF20, RKOF30, RKOF60, VAE180 | 0.9013 | 0.9165 | 0.8861 |
| Broadcast | |||
| RKOF10, RKOF30, RKOF60 | 0.8893 | 0.9410 | 0.8376 |
| RKOF10, RKOF60 | 0.8876 | 0.8673 | 0.9078 |
| RKOF10, RKOF60, VAE60 | 0.8792 | 0.9170 | 0.8414 |
| RKOF10, RKOF60, VAE180 | 0.8787 | 0.9405 | 0.8168 |
| RKOF30, RKOF60 | 0.8749 | 0.8545 | 0.8954 |
| RKOF10, RKOF30, RKOF60, VAE60 | 0.8665 | 0.9570 | 0.7761 |
| RKOF10, RKOF20, RKOF30, RKOF60 | 0.8655 | 0.9410 | 0.7901 |
| RKOF10, RKOF30, RKOF60, VAE180 | 0.8646 | 0.9737 | 0.7555 |
| RKOF10, RKOF60, VAE60, VAE180 | 0.8643 | 0.9430 | 0.7856 |
| RKOF10, RKOF60, VAE120 | 0.8626 | 0.9286 | 0.7966 |
| Pre-Processed Data | |||||
|---|---|---|---|---|---|
| Attack\Methods | RKOF10, RKOF30, RKOF60, VAE180 | RKOF20, RKOF30, RKOF60, VAE60, VAE120, VAE180 | RKOF20, RKOF30, RKOF60, VAE120, VAE180 | RKOF20, RKOF30, RKOF60, VAE60, VAE180 | RKOF20, RKOF30, RKOF60, VAE180 |
| A1.1: Brute-force FTP | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 |
| A1.2: Flood | 99.73 | 96.01 | 96.01 | 95.21 | 90.69 |
| A1.3: Brute-force RDP | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 |
| A1.4: Brute-force RDP | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 |
| A1.5: Flood | 98.36 | 98.36 | 98.36 | 98.36 | 98.36 |
| A1.6: Brute-force SSH | 94.58 | 94.58 | 94.58 | 94.58 | 94.58 |
| A2.1: Brute-force SSH | 19.61 | 19.61 | 19.61 | 19.61 | 19.61 |
| A2.2: Reverse shell + scripts | 87.50 | 87.50 | 87.50 | 87.50 | 87.50 |
| A2.3: Flood | 100.00 | 97.24 | 96.96 | 96.96 | 95.86 |
| A2.4: Brute-force FTP | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 |
| A2.5: Flood | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 |
| A2.6: Reverse shell + sending data | 98.97 | 98.97 | 98.97 | 98.97 | 98.97 |
| A2.7: Flood | 99.76 | 99.76 | 99.76 | 99.76 | 99.76 |
| Mean | 92.19 | 91.70 | 91.67 | 91.61 | 91.18 |
| Median | 99.76 | 98.97 | 98.97 | 98.97 | 98.97 |
| Broadcast data | |||||
| Attack\Methods | RKOF10, RKOF30, RKOF60, VAE60, VAE180 | RKOF10, RKOF30, RKOF60, VAE180 | RKOF10, RKOF30, RKOF60, VAE60, VAE120 | RKOF10, RKOF20, RKOF60, VAE60, VAE120, VAE180 | RKOF10, RKOF20, RKOF60, VAE120, VAE180 |
| A1.1: Brute-force FTP | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 |
| A1.2: Flood | 99.73 | 99.73 | 99.73 | 91.22 | 91.22 |
| A1.3: Brute-force RDP | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 |
| A1.4: Brute-force RDP | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 |
| A1.5: Flood | 86.89 | 86.89 | 86.89 | 86.07 | 86.07 |
| A1.6: Brute-force SSH | 99.17 | 99.17 | 99.17 | 99.17 | 99.17 |
| A2.1: Brute-force SSH | 99.45 | 99.45 | 99.45 | 99.45 | 99.45 |
| A2.2: Reverse shell + scripts | 87.18 | 87.18 | 87.18 | 87.18 | 87.18 |
| A2.3: Flood | 100.00 | 100.00 | 100.00 | 98.62 | 98.62 |
| A2.4: Brute-force FTP | 100.00 | 100.00 | 98.62 | 100.00 | 100.00 |
| A2.5: Flood | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 |
| A2.6: Reverse shell + sending data | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 |
| A2.7: Flood | 87.97 | 87.74 | 77.83 | 87.03 | 86.79 |
| Mean | 96.95 | 96.93 | 96.07 | 96.06 | 96.04 |
| Median | 100.00 | 100.00 | 99.73 | 99.45 | 99.45 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wawrowski, Ł.; Białas, A.; Kajzer, A.; Kozłowski, A.; Kurianowicz, R.; Sikora, M.; Szymańska-Kwiecień, A.; Uchroński, M.; Białczak, M.; Olejnik, M.; et al. Anomaly Detection Module for Network Traffic Monitoring in Public Institutions. Sensors 2023, 23, 2974. https://doi.org/10.3390/s23062974
Wawrowski Ł, Białas A, Kajzer A, Kozłowski A, Kurianowicz R, Sikora M, Szymańska-Kwiecień A, Uchroński M, Białczak M, Olejnik M, et al. Anomaly Detection Module for Network Traffic Monitoring in Public Institutions. Sensors. 2023; 23(6):2974. https://doi.org/10.3390/s23062974
Chicago/Turabian StyleWawrowski, Łukasz, Andrzej Białas, Adrian Kajzer, Artur Kozłowski, Rafał Kurianowicz, Marek Sikora, Agnieszka Szymańska-Kwiecień, Mariusz Uchroński, Miłosz Białczak, Maciej Olejnik, and et al. 2023. "Anomaly Detection Module for Network Traffic Monitoring in Public Institutions" Sensors 23, no. 6: 2974. https://doi.org/10.3390/s23062974