
Sign2Pose: A Pose-Based Approach for Gloss Prediction Using a Transformer Model



Abstract
:1. Introduction
- We introduce a novel approach for our pose-based WLSR using a keyframe extraction technique to discard the irrelevant frames from the critical frames. To perform this keyframe extraction, we use a modified histogram difference algorithm and Euclidean distance algorithm through which our model achieves 5% improvement compared to other existing pose-based state-of-the-art results on all the subsets of the WLASL dataset (WLASL 100, WLASL 300, WLASL1000, WLASL 2000).
- We employ augmentation techniques that let our model fit and be adapted for any additional real-time dataset in generalizing so that it can handle the real-time scenario. For this, we adopt in-plane rotation with perspective transformation and joint rotation, which has the added benefit of enabling our model to recognize poses executed at various angles, with various hand sizes, and even at various locations.
- We introduce a novel pose normalization approach in WLSR using YOLO v3, through which our approach has seen significant improvement of up to 20% for the exact detection of the pose vectors in the signing space.
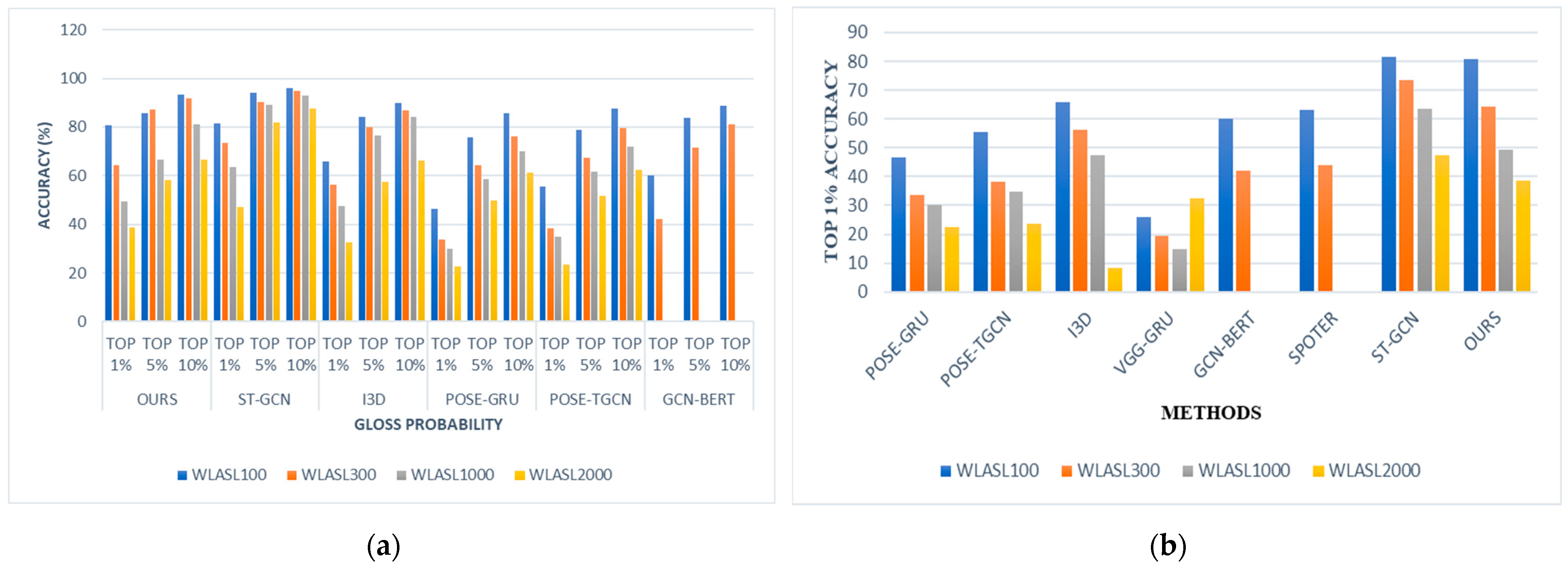
- To predict the glosses from the normalized pose sequence, we propose a novel method through a Sign2Pose Gloss prediction transformer, which attains the highest top 1% recognition accuracy of 80.9 in WLASL 100, 64.21 in WLASL 300, 49.46 WLASL 1000, and 38.65 WLASL 2000, surpassing all state-of-the-art outcomes from the existing pose-based models.
2. Related Works
2.1. Significance of Glosses in Vision-Based CSLT
2.2. End-to-End and Two-Stage Translation in SLT
2.3. Video Analysis and Summarization
2.4. Pose-Based Methods for SLT
3. Materials and Methods
3.1. Dataset Description
3.2. Key Frame Extraction Technique
| Algorithm 1. Key-frame extraction | |
| Input: | Let I be the input sign video I Ii….IN Let n be the number of frames in Ii |
| Output: | Set of key-frames fkey: fkey {1 to m} where m < n |
| 1 | for fRGB in n (frames): |
| 2 | Convert RGB frames into grayscale frames fRGB → fGRAY |
| 3 | Compute histogram difference Hdiff between successive frames using Equation (1) |
| 4 | Calculate mean μ and standard deviation σ of the Hdiff |
| 5 | Compute threshold value “Th”: |
| 6 | Calculate the Euclidean distance Ed using Equation (2) |
| 7 | fGRAY ={elements of K and elements of R} “R” denotes the set of redundant frames Such that, K = {k1, k2, k3,…kN} R = {r1, r2, r4,...rM} |
| 8 | for I in n: |
| 9 | if Ed > Th: |
| 10 | R\K = {rM−1} Element obtained belongs to set of redundant frames but not to set of key-frames Add the frames to the set fkey |
| 11 | else |
| 12 | Discard the frame |
| 13 | Repeat steps 1 to 12 for the entire dataset, and once completed, discarding redundant frames stops the process. |
3.3. Pose Estimation from Key-Frame
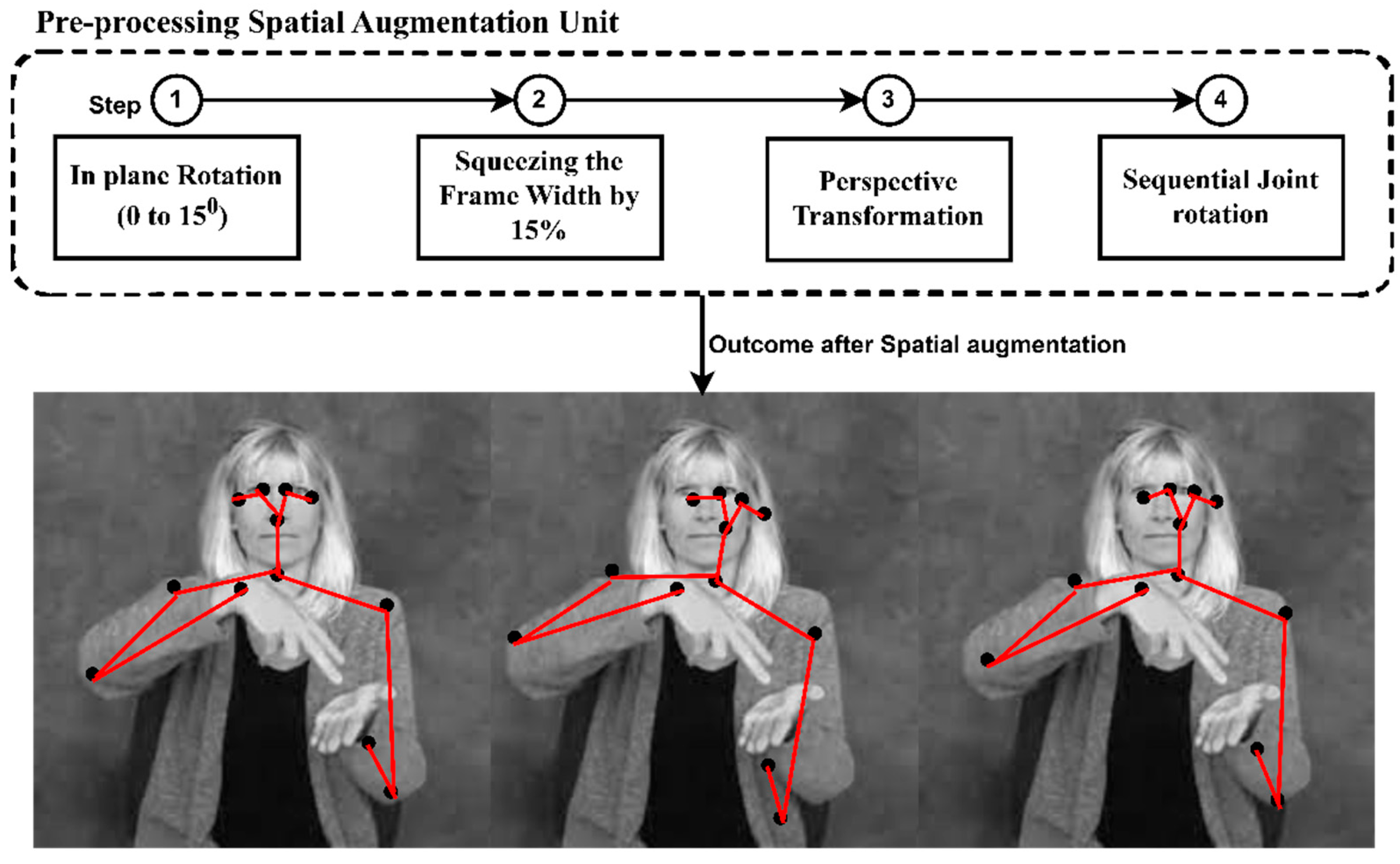
3.4. Pre-Processing
| Algorithm 2. Sequential Joint Rotation | |
| 1 | Input image Iin, x, and y standard coordinates |
| 2 | Initialize center point of the frame as Cmid |
| 3 | Fix Cmid = 0.5 |
| 4 | Rotate frame frot according to Cmid, and [x,y] Standard Rotation Matrix is given as R |
| 5 | frot with then the moved state is denoted by x’ and y’ x’ = (x − – (y − 0.5) + 0.5 y’ + (x − 0.5) + 0.5 frot(x’y’) = (x − 0.5) – (y − 0.5) + 0.5, (y − + (x − 0.5) + 0.5 |
| 6 | Angle of rotation θ ≤ 15° |
| 7 | Generate random moving state Sm based on θ and uniform distribution |
| 8 | Within the range of Cmid, move x based on Sm, then y based on Sm to calculate Sm’ to obtain a new range of x and x’, y and y’ IAugmentation = Augment (Iin, x, y) IAugmentation’ = Augment (Iin, x’, y’) |
| 9 | Calculate recognized image Iobs and measure the Euclidean distance Ed |
| 10 | if Ed(Iobs, Cmid) ≤ Ed(Iobs’, Cmid)then Improve the recognition accuracy else stop |
3.5. Pose Normalization
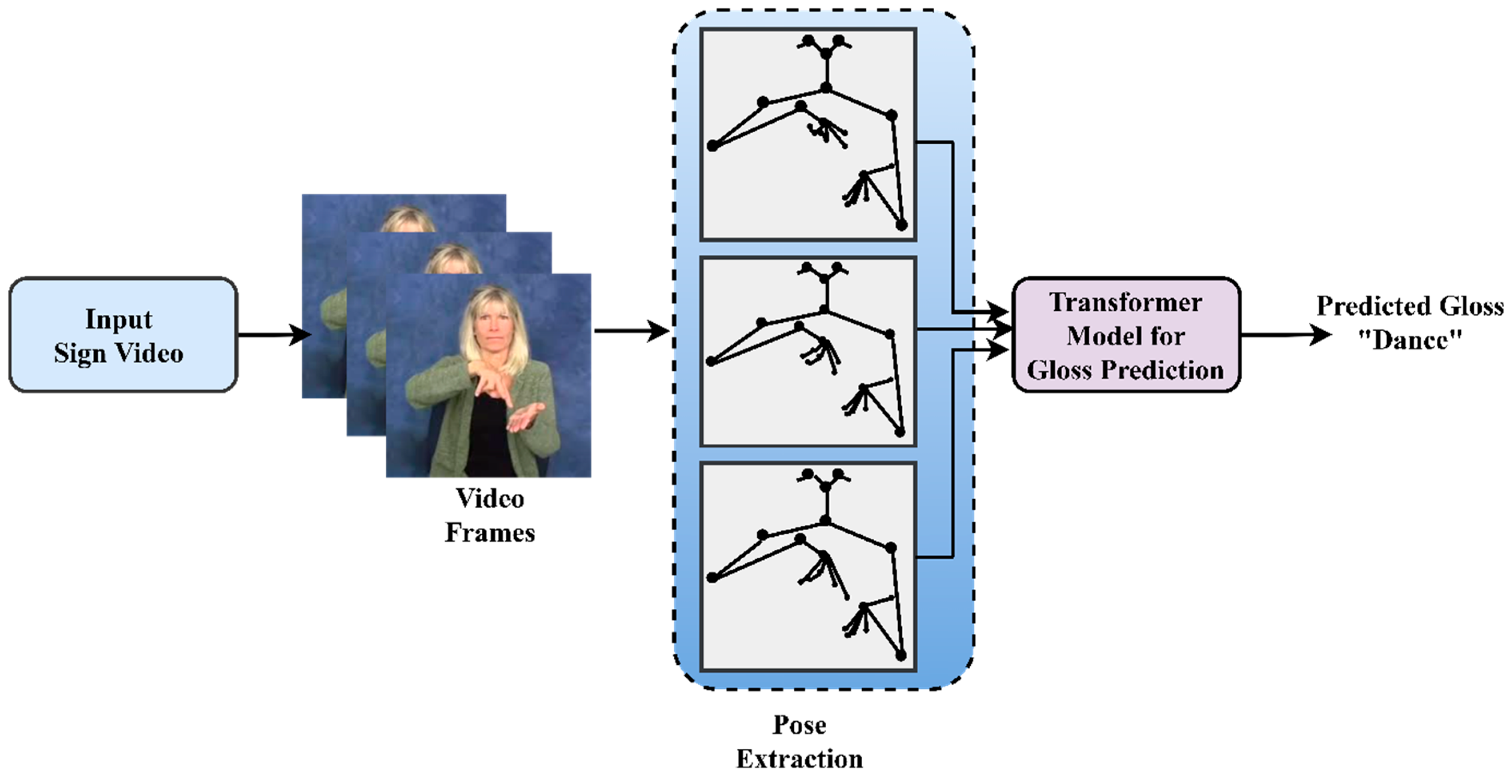
4. Proposed Architecture
5. Experiments
6. Results and Discussions
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Asst professor, B.M.; Dept, C. Automatic Sign Language Finger Spelling Using Convolution Neural Network: Analysis. Int. J. Pure Appl. Math. 2017, 117, 9–15. [Google Scholar]
- Jennifer Eunice R, H.D.J. Deep CNN for Static Indian Sign Language Digits Recognition. In Frontiers in Artificial Intelligence and Applications; IOS Press: Amsterdam, The Netherlands, 2022; Volume 347, pp. 437–446. [Google Scholar]
- Chajri, Y.; Bouikhalene, B. Handwritten mathematical symbols dataset. Data Br. 2016, 7, 432–436. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Huang, J.; Zhou, W.; Zhang, Q.; Li, H.; Li, W. Video-based sign language recognition without temporal segmentation. In Proceedings of the 32nd Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; pp. 2257–2264. [Google Scholar]
- Tolentino, L.K.S.; Serfa Juan, R.O.; Thio-ac, A.C.; Pamahoy, M.A.B.; Forteza, J.R.R.; Garcia, X.J.O. Static sign language recognition using deep learning. Int. J. Mach. Learn. Comput. 2019, 9, 821–827. [Google Scholar] [CrossRef] [Green Version]
- Liao, Y.; Xiong, P.; Min, W.; Min, W.; Lu, J. Dynamic Sign Language Recognition Based on Video Sequence with BLSTM-3D Residual Networks. IEEE Access 2019, 7, 38044–38054. [Google Scholar] [CrossRef]
- Kumar, P.; Gauba, H.; Roy, P.P.; Dogra, D.P. Coupled HMM-based Multi-Sensor Data Fusion for Sign Language Recognition. Pattern Recognit. Lett. 2016, 86, 1–8. [Google Scholar] [CrossRef]
- Chabchoub, A.; Hamouda, A.; Al-Ahmadi, S.; Barkouti, W.; Cherif, A. Hand Sign Language Feature Extraction Using Image Processing. Adv. Intell. Syst. Comput. 2020, 1070, 122–131. [Google Scholar] [CrossRef]
- Ong, E.J.; Bowden, R. A boosted classifier tree for hand shape detection. In Proceedings of the Sixth IEEE International Conference on Automatic Face and Gesture Recognition, Seoul, Republic of Korea, 19 May 2004; pp. 889–894. [Google Scholar] [CrossRef] [Green Version]
- Charles, J.; Pfister, T.; Everingham, M.; Zisserman, A. Automatic and efficient human pose estimation for sign language videos. Int. J. Comput. Vis. 2014, 110, 70–90. [Google Scholar] [CrossRef]
- Liu, J.; Liu, B.; Zhang, S.; Yang, F.; Yang, P.; Metaxas, D.N.; Neidle, C. Non-manual grammatical marker recognition based on multi-scale, spatio-temporal analysis of head pose and facial expressions. Image Vis. Comput. 2014, 32, 671–681. [Google Scholar] [CrossRef]
- Cheng, K.L.; Yang, Z.; Chen, Q.; Tai, Y.W. Fully Convolutional Networks for Continuous Sign Language Recognition. In Lecture Notes in Computer Science; Including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics; Springer: Berlin/Heidelberg, Germany, 2020; Volume 12369 LNCS, pp. 697–714. [Google Scholar] [CrossRef]
- Koller, O.; Ney, H.; Bowden, R. Deep Hand: How to Train a CNN on 1 Million Hand Images When Your Data Is Continuous and Weakly Labelled. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Koller, O.; Zargaran, S.; Ney, H. Resign: Re-aligned end-to-end sequence modelling with deep recurrent CNN-HMMs. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21 July 2017–26 July 2017; pp. 3416–3424. [Google Scholar] [CrossRef]
- Zhang, F.; Sheng, J. Gesture Recognition Based on CNN and DCGAN for Calculation and Text Output. IEEE Access 2019, 7, 28230–28237. [Google Scholar] [CrossRef]
- Rastgoo, R.; Kiani, K.; Escalera, S. Word separation in continuous sign language using isolated signs and post-processing. arXiv 2022, arXiv:2204.00923. [Google Scholar]
- Guo, D.; Zhou, W.; Li, H.; Wang, M. Hierarchical LSTM for sign language translation. In Proceedings of the 32nd AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; pp. 6845–6852. [Google Scholar]
- Agha, R.A.A.R.; Sefer, M.N.; Fattah, P. A comprehensive study on sign languages recognition systems using (SVM, KNN, CNN and ANN). In Proceedings of the Proceedings of the First International Conference on Data Science, E-learning and Information Systems-DATA’18, New York, NY, USA, 1–2 October 2018; ACM Press: New York, NY, USA, 2018; pp. 1–6. [Google Scholar]
- Rahim, M.A.; Islam, M.R.; Shin, J. Non-touch sign word recognition based on dynamic hand gesture using hybrid segmentation and CNN feature fusion. Appl. Sci. 2019, 9, 3790. [Google Scholar] [CrossRef] [Green Version]
- Wu, Y.; Zhou, Y.; Zeng, W.; Qian, Q.; Song, M. An Attention-based 3D CNN with Multi-scale Integration Block for Alzheimer’ s Disease Classification. IEEE J. Biomed. Health Inform. 2022, 26, 5665–5673. [Google Scholar] [CrossRef] [PubMed]
- Neto, G.M.R.; Junior, G.B.; de Almeida, J.D.S.; de Paiva, A.C. Sign Language Recognition Based on 3D Convolutional Neural Networks. In Lecture Notes in Computer Science; Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics; Springer: Berlin/Heidelberg, Germany, 2018; Volume 10882 LNCS, pp. 399–407. [Google Scholar]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to sequence learning with neural networks. Adv. Neural Inf. Process. Syst. 2014, 4, 3104–3112. [Google Scholar]
- Chen, Y.; Wei, F.; Sun, X.; Wu, Z.; Lin, S. A Simple Multi-Modality Transfer Learning Baseline for Sign Language Translation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–20 June 2022; pp. 5110–5120. [Google Scholar] [CrossRef]
- Camgoz, N.C.; Hadfield, S.; Koller, O.; Ney, H.; Bowden, R. Neural Sign Language Translation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7784–7793. [Google Scholar] [CrossRef]
- Jin, T.; Zhao, Z.; Zhang, M.; Zeng, X. Findings of the Association for Computational Linguistics Prior Knowledge and Memory Enriched Transformer for Sign Language Translation. Assoc. Comput. Linguist. 2022, 2022, 3766–3775. [Google Scholar]
- Camgoz, N.C.; Koller, O.; Hadfield, S.; Bowden, R. Sign language transformers: Joint end-to-end sign language recognition and translation. In Proceedings of the Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10023–10033. [Google Scholar]
- Xu, Y.; Seneff, S. Two-Stage Translation: A Combined Linguistic and Statistical Machine Translation Framework. In Proceedings of the Conference of the Association for Machine Translation in the Americas, Waikiki, HI, USA, 21–25 October 2008. [Google Scholar]
- Jang, J.Y.; Park, H.; Shin, S.; Shin, S.; Yoon, B.; Gweon, G. Automatic Gloss-level Data Augmentation for Sign Language Translation. In Proceedings of the 2022 Language Resources and Evaluation Conference, LREC 2022, Marseille, France, 20–25 June 2022; pp. 6808–6813. [Google Scholar]
- Sehyr, Z.S.; Caselli, N.; Cohen-Goldberg, A.M.; Emmorey, K. The ASL-LEX 2.0 Project: A Database of Lexical and Phonological Properties for 2,723 Signs in American Sign Language. J. Deaf Stud. Deaf Educ. 2021, 26, 263–277. [Google Scholar] [CrossRef]
- Caselli, N.K.; Sehyr, Z.S.; Cohen-Goldberg, A.M.; Emmorey, K. ASL-LEX: A lexical database of American Sign Language. Behav. Res. Methods 2017, 49, 784–801. [Google Scholar] [CrossRef] [Green Version]
- Vaswani, A.; Shazeer, N.M.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All you Need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Koller, O.; Zargaran, S.; Ney, H.; Bowden, R. Deep sign: Hybrid CNN-HMM for continuous sign language recognition. In Proceedings of the British Machine Vision Conference 2016, York, UK, 19–22 September 2016; pp. 136.1–136.12. [Google Scholar] [CrossRef] [Green Version]
- Wu, D.; Pigou, L.; Kindermans, P.J.; Le, N.D.H.; Shao, L.; Dambre, J.; Odobez, J.M. Deep Dynamic Neural Networks for Multimodal Gesture Segmentation and Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 1583–1597. [Google Scholar] [CrossRef] [Green Version]
- Koller, O.; Forster, J.; Ney, H. Continuous sign language recognition: Towards large vocabulary statistical recognition systems handling multiple signers. Comput. Vis. Image Underst. 2015, 141, 108–125. [Google Scholar] [CrossRef]
- Cui, R.; Liu, H.; Zhang, C. A Deep Neural Framework for Continuous Sign Language Recognition by Iterative Training. IEEE Trans. Multimed. 2019, 21, 1880–1891. [Google Scholar] [CrossRef]
- Sharma, S.; Gupta, R.; Kumar, A. Continuous sign language recognition using isolated signs data and deep transfer learning. J. Ambient Intell. Humaniz. Comput. 2021, 1, 1531–1542. [Google Scholar] [CrossRef]
- Niu, Z.; Mak, B. Stochastic Fine-Grained Labeling of Multi-state Sign Glosses for Continuous Sign Language Recognition. In Proceedings of the Computer Vision—ECCV 2020, Glasgow, UK, 23–28 August 2020; Vedaldi, A., Bischof, H., Brox, T., Frahm, J.-M., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 172–186. [Google Scholar]
- Tunga, A.; Nuthalapati, S.V.; Wachs, J. Pose-based Sign Language Recognition using GCN and BERT. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2021; pp. 31–40. [Google Scholar] [CrossRef]
- Cui, R.; Liu, H.; Zhang, C. Recurrent convolutional neural networks for continuous sign language recognition by staged optimization. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2016; pp. 1610–1618. [Google Scholar] [CrossRef]
- Zhao, J.; Qi, W.; Zhou, W.; Duan, N.; Zhou, M.; Li, H. Conditional Sentence Generation and Cross-Modal Reranking for Sign Language Translation. IEEE Trans. Multimed. 2022, 24, 2662–2672. [Google Scholar] [CrossRef]
- Kim, Y.; Kwak, M.; Lee, D.; Kim, Y.; Baek, H. Keypoint based Sign Language Translation without Glosses. arXiv 2022, arXiv:2204.10511. [Google Scholar]
- Du, Y.; Xie, P.; Wang, M.; Hu, X.; Zhao, Z.; Liu, J. Full transformer network with masking future for word-level sign language recognition. Neurocomputing 2022, 500, 115–123. [Google Scholar] [CrossRef]
- Camgöz, N.C.; Koller, O.; Hadfield, S.; Bowden, R. Sign Language Transformers: Joint End-to-end Sign Language Recognition and Translation. arXiv 2020, arXiv:2003.13830v1. [Google Scholar]
- Ko, S.K.; Kim, C.J.; Jung, H.; Cho, C. Neural sign language translation based on human keypoint estimation. Appl. Sci. 2019, 9, 2683. [Google Scholar] [CrossRef] [Green Version]
- Read, J.; Polytechnique, E. Better Sign Language Translation with STMC-Transformer. arXiv 2017, arXiv:2004.00588. [Google Scholar]
- Walczynska, J. HandTalk: American Sign Language Recognition by 3D-CNNs. Ph.D. Thesis, University of Groningen, Groningen, The Netherlands, 2022. [Google Scholar]
- Papastratis, I.; Dimitropoulos, K.; Daras, P. Continuous Sign Language Recognition through a Context-Aware Generative Adversarial Network. Sensors 2021, 21, 2437. [Google Scholar] [CrossRef]
- Bohacek, M.; Hruz, M. Sign Pose-based Transformer for Word-level Sign Language Recognition. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) Workshops, Waikoloa, HI, USA, 4–8 January 2022; pp. 182–191. [Google Scholar] [CrossRef]
- Inan, M.; Zhong, Y.; Hassan, S.; Quandt, L.; Alikhani, M. Modeling Intensification for Sign Language Generation: A Computational Approach. arXiv 2022, arXiv:2203.09679. [Google Scholar]
- Jiang, S.; Sun, B.; Wang, L.; Bai, Y.; Li, K.; Fu, Y. Sign Language Recognition via Skeleton-Aware Multi-Model Ensemble. arXiv 2021, arXiv:2110.06161v1. [Google Scholar]
- Yao, P. Key Frame Extraction Method of Music and Dance Video Based on Multicore Learning Feature Fusion. Sci. Program. 2022, 2022, 9735392. [Google Scholar] [CrossRef]
- Wang, J.; Zeng, C.; Wang, Z.; Jiang, K. An improved smart key frame extraction algorithm for vehicle target recognition. Comput. Electr. Eng. 2022, 97, 107540. [Google Scholar] [CrossRef]
- Li, Z.; Li, Y.; Tan, B.; Ding, S.; Xie, S. Structured Sparse Coding With the Group Log-regularizer for Key Frame Extraction. IEEE/CAA J. Autom. Sin. 2022, 9, 1818–1830. [Google Scholar] [CrossRef]
- Nie, B.X.; Xiong, C.; Zhu, S.C. Joint action recognition and pose estimation from video. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1293–1301. [Google Scholar] [CrossRef] [Green Version]
- Gan, S.; Yin, Y.; Jiang, Z.; Xie, L.; Lu, S. Skeleton-Aware Neural Sign Language Translation. In Proceedings of the 29th ACM International Conference on Multimedia, Virtual, 20–24 October 2021; pp. 4353–4361. [Google Scholar] [CrossRef]
- Novopoltsev, M.; Verkhovtsev, L.; Murtazin, R.; Milevich, D.; Zemtsova, I. Fine-tuning of sign language recognition models: A technical report. arXiv 2023, arXiv:2302.07693. [Google Scholar] [CrossRef]
- Shalev-Arkushin, R.; Moryossef, A.; Fried, O. Ham2Pose: Animating Sign Language Notation into Pose Sequences. arXiv 2022, arXiv:2211.13613. [Google Scholar] [CrossRef]
- Liu, F.; Dai, Q.; Wang, S.; Zhao, L.; Shi, X.; Qiao, J. Multi-relational graph convolutional networks for skeleton-based action recognition. In Proceedings of the 2020 IEEE Intl Conf on Parallel & Distributed Processing with Applications, Big Data & Cloud Computing, Sustainable Computing & Communications, Social Computing & Networking (ISPA/BDCloud/SocialCom/SustainCom), Exeter, UK, 17–19 December 2020; pp. 474–480. [Google Scholar] [CrossRef]
- De Coster, M.; Van Herreweghe, M.; Dambre, J. Isolated sign recognition from RGB video using pose flow and self-attention. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 3436–3445. [Google Scholar] [CrossRef]
- Li, D.; Opazo, C.R.; Yu, X.; Li, H. Word-level deep sign language recognition from video: A new large-scale dataset and methods comparison. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Snowmass Village, CO, USA, 1–5 March 2020; pp. 1448–1458. [Google Scholar] [CrossRef]
- Madadi, M.; Escalera, S.; Carruesco, A.; Andujar, C.; Baró, X.; Gonzàlez, J. Occlusion Aware Hand Pose Recovery from Sequences of Depth Images. In Proceedings of the 2017 12th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2017), Washington, DC, USA, 30 May 2017–3 June 2017; pp. 230–237. [Google Scholar]
- Joze, H.R.V.; Koller, O. MS-ASL: A large-scale data set and benchmark for understanding American sign language. In Proceedings of the 30th British Machine Vision Conference 2019, BMVC 2019, Cardiff, UK, 9–12 September 2019. [Google Scholar]
- Kagirov, I.; Ivanko, D.; Ryumin, D.; Axyonov, A.; Karpov, A. TheRuSLan: Database of Russian sign language. In Proceedings of the 12th Language Resources and Evaluation Conference, Marseille, France, 11–16 May 2020; pp. 6079–6085. [Google Scholar]
- Sincan, O.M.; Keles, H.Y. AUTSL: A large scale multi-modal Turkish sign language dataset and baseline methods. IEEE Access 2020, 8, 181340–181355. [Google Scholar] [CrossRef]
- Pishchulin, L.; Insafutdinov, E.; Tang, S.; Andres, B.; Andriluka, M.; Gehler, P.; Schiele, B. DeepCut: Joint subset partition and labeling for multi person pose estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4929–4937. [Google Scholar] [CrossRef] [Green Version]
- Feng, J.; Wang, X.; Liu, W. Deep graph cut network for weakly-supervised semantic segmentation. Sci. China Inf. Sci. 2021, 64, 130105. [Google Scholar] [CrossRef]
- Li, M.; Qin, J.; Li, D.; Chen, R.; Liao, X.; Guo, B. VNLSTM-PoseNet: A novel deep ConvNet for real-time 6-DOF camera relocalization in urban streets. Geo-Spatial Inf. Sci. 2021, 24, 422–437. [Google Scholar] [CrossRef]
- Kitamura, T.; Teshima, H.; Thomas, D.; Kawasaki, H. Refining OpenPose with a new sports dataset for robust 2D pose estimation. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2022; pp. 672–681. [Google Scholar] [CrossRef]
- Bauer, A. The Use of Signing Space in a Shared Sign Language of Australia; De Gruyter Mouton: Berlin, Germany, 2013; ISBN 9781614515470. [Google Scholar]
- Senanayaka, S.A.M.A.S.; Perera, R.A.D.B.S.; Rankothge, W.; Usgalhewa, S.S.; Hettihewa, H.D.; Abeygunawardhana, P.K.W. Continuous American Sign Language Recognition Using Computer Vision And Deep Learning Technologies. In Proceedings of the 2022 IEEE Region 10 Symposium (TENSYMP), Mumbai, India, 1-03 July 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 1–6. [Google Scholar]
- Maruyama, M.; Singh, S.; Inoue, K.; Roy, P.P.; Iwamura, M.; Yoshioka, M. Word-Level Sign Language Recognition with Multi-Stream Neural Networks Focusing on Local Regions and Skeletal Information. arXiv 2021, arXiv:2106.15989. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref. | Translation Type | Technique for Gloss Prediction | Dataset | Performance Metric | Remarks |
|---|---|---|---|---|---|
| [38] | Sign2Gloss2Text | Graph convolution network (GCN) and bi-directional encoder representations from transformer (BERT) | WLASL | 88.67 at top 10% accuracy on 100 gloss recognition | Image-based feature extraction enhances the performance of the model. |
| [44] | Sign2Gloss2Text | Human key-point estimation | KETI sign language | BLEU4—65.83 (Key points: Hand, body) | Performance would improve on improving key-point detection |
| [45] | Sign2Gloss2Text Gloss2Text | Spatial-temporal transformer and spatial-temporal RNN | Phoenix 2014T | BLEU4-24.00 | Dataset is restricted to the weather forecast |
| [46] | Sign2Gloss2Text | Temporal graph convolution network (TGCN) | WLASL | 62.63% at top 10 accuracy on 2000 gloss recognition | Labelling a large number of samples requires advanced deep algorithms to pave the way from word-level to sentence-level annotations |
| [47] | Sign2Gloss2Text | Context-aware GAN, temporal convolution layers (TCL), and BLSTM | Phoenix 2014T, CSL, and GSL signer independent | 23.4%, 2.1%, and 2.26% WER, respectively | Complexity and data imbalance in GAN network |
| [48] | Sign2Gloss2Text | Transformer | WLASL100, WLASL300, and LSA 64 | 63.18%, 43.78%, and 100% recognition accuracy | Shows better outcomes on even smaller datasets |
| [49] | Sign2Gloss2Text | Intensity modifier | Phoenix 2014T | BLEU1-26.51 | Lacks spatial and temporal information for black translation and lack of proper evaluation metrics. |
| Categories | Content | Type | Glosses | Samples | Mean (Avg. Instances/Class) | Signers |
|---|---|---|---|---|---|---|
| WLASL 100 | Video with Aligned Sign/Sentence with text and Gloss | RGB | 100 | 2038 | 20.38 | 97 |
| WLASL 300 | 300 | 5117 | 17.1 | 109 | ||
| WLASL 1000 | 1000 | 13,168 | 13.16 | 116 | ||
| WLASL 2000 | 2000 | 21,083 | 10.54 | 119 |
| Hyperparameter | Tuning Details |
|---|---|
| Pose vectors | 108 |
| Encoder layers | 6 |
| Decoder layers | 6 |
| Input and hidden dimension | 108 |
| Feed Forward dimension | 2048 |
| Learning rate | 0.001 |
| Weighted decay | 0.0001 |
| Optimizer | Stochastic Gradient Descent |
| Epochs | 300 |
| Model and Dataset | I3D [70] | Pose-GRU [70] | Pose-TGCN [70] | GCN-BERT [38] | ST-GCN [71] | SPOTTER [48] | OURS |
|---|---|---|---|---|---|---|---|
| Appearance-based | ✓ | ✕ | ✕ | ✕ | ✓ | ✕ | ✕ |
| Pose-based | ✕ | ✓ | ✓ | ✓ | ✕ | ✓ | ✓ |
| Augmentation | ✓ | ✓ | ✓ | ✕ | ✓ | ✓ | ✓ |
| WLASL 100 | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| WLASL300 | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| WLASL1000 | ✓ | ✓ | ✓ | ✕ | ✓ | ✕ | ✓ |
| WLASL 2000 | ✓ | ✓ | ✓ | ✕ | ✓ | ✕ | ✓ |
| Other datasets | ✕ | ✕ | ✕ | ✕ | ✓ | ✓ | ✕ |
| Pose-Based Models | WLASL100 Top-1% Accuracy | WLASL300 Top-1% Accuracy | WLASL1000 Top-1% Accuracy | WLASL2000 Top-1% Accuracy |
|---|---|---|---|---|
| POSE-GRU [46] | 46.51 | 33.68 | 30.1 | 22.54 |
| POSE-TGCN [46] | 55.43 | 38.32 | 34.86 | 23.65 |
| GCN-BERT [38] | 60.15 | 42.18 | - | - |
| SPOTER [48] | 63.18 | 43.78 | - | - |
| Our’s | 80.9 | 64.21 | 49.46 | 38.65 |
| Extracted Key-Frames | Top 5 Predicted Gloss | Top 1% Accuracy | Ground Truth | |||||
|---|---|---|---|---|---|---|---|---|
 |  |  |  |  |  | Connect Cut Chair Seat Sit | 93.6% | Chair |
 |  |  |  |  |  | Swing Baby Tummy Swaddle Platter | 84.8% | Baby |
 |  |  |  |  |  | Neck Collar Necklace Lip Smash | 88.5% | Neck |
 |  |  |  |  |  | Collide Hit Match Unite Relate | 90.35% | Match |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Eunice, J.; J, A.; Sei, Y.; Hemanth, D.J. Sign2Pose: A Pose-Based Approach for Gloss Prediction Using a Transformer Model. Sensors 2023, 23, 2853. https://doi.org/10.3390/s23052853
Eunice J, J A, Sei Y, Hemanth DJ. Sign2Pose: A Pose-Based Approach for Gloss Prediction Using a Transformer Model. Sensors. 2023; 23(5):2853. https://doi.org/10.3390/s23052853
Chicago/Turabian StyleEunice, Jennifer, Andrew J, Yuichi Sei, and D. Jude Hemanth. 2023. "Sign2Pose: A Pose-Based Approach for Gloss Prediction Using a Transformer Model" Sensors 23, no. 5: 2853. https://doi.org/10.3390/s23052853