
Towards a Broad-Persistent Advising Approach for Deep Interactive Reinforcement Learning in Robotic Environments


Abstract
:1. Introduction
2. Preliminary
2.1. Deep Reinforcement Learning
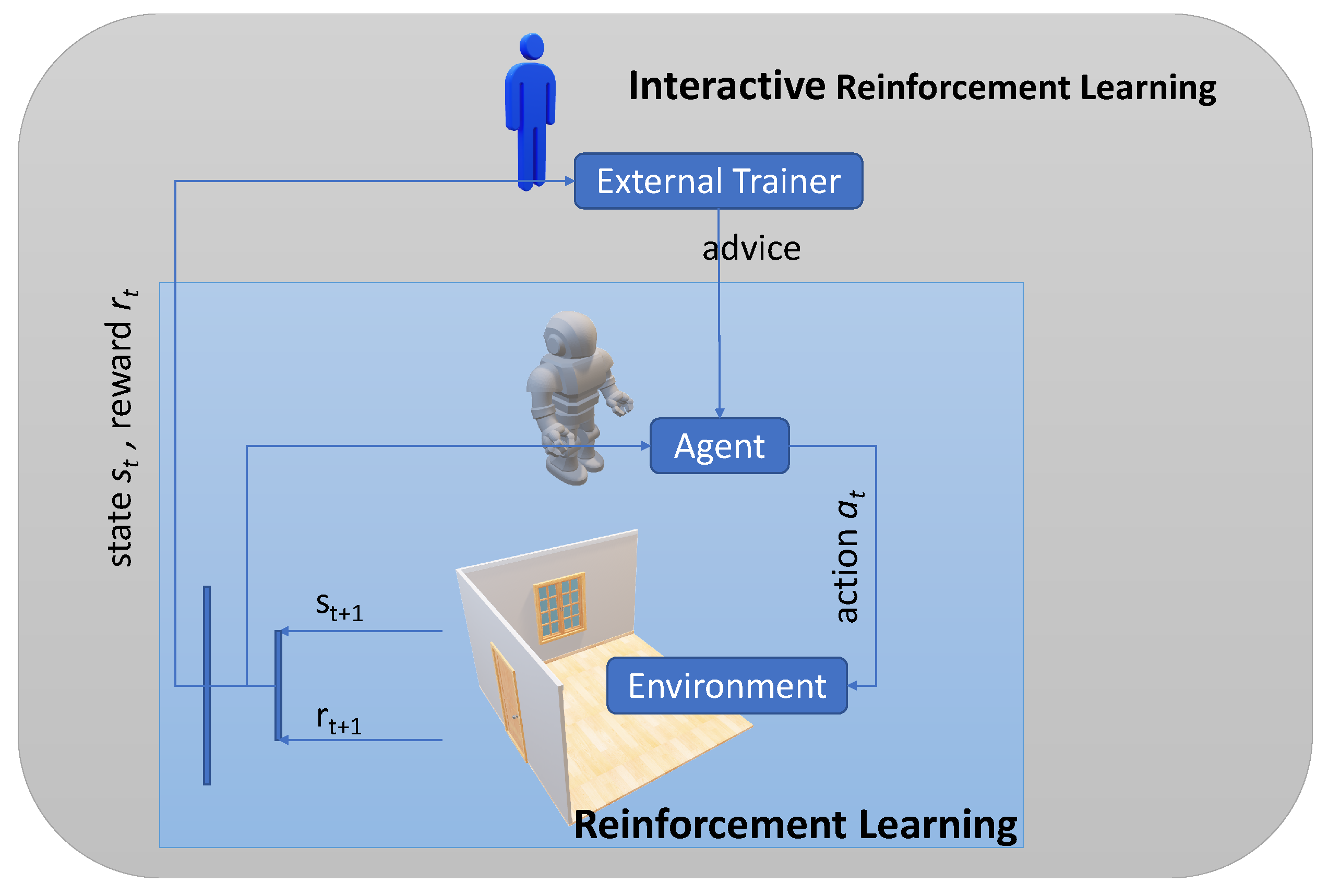
2.2. Reinforcement Learning with Interactive Feedback
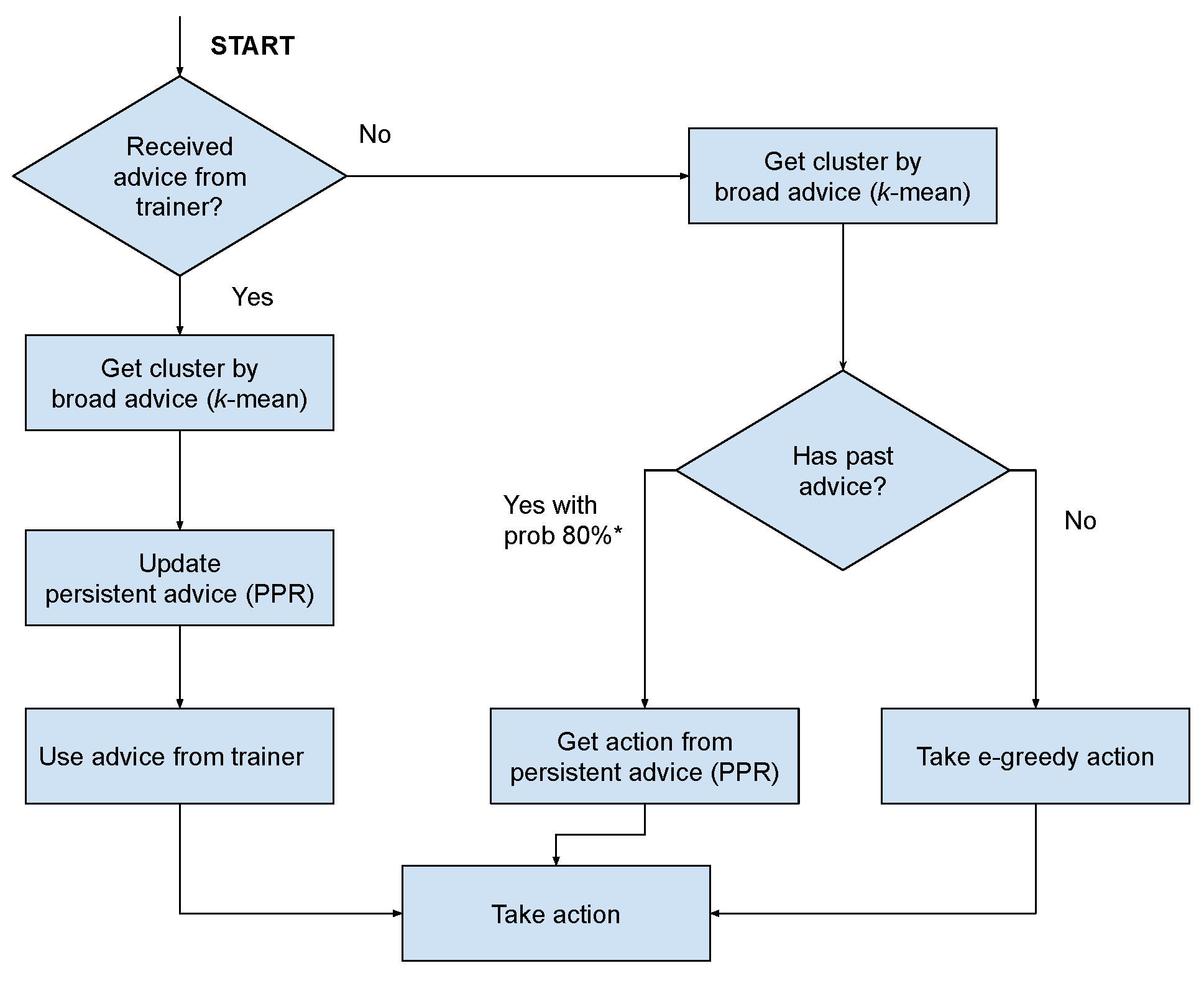
3. A Broad-Persistent Advising Approach
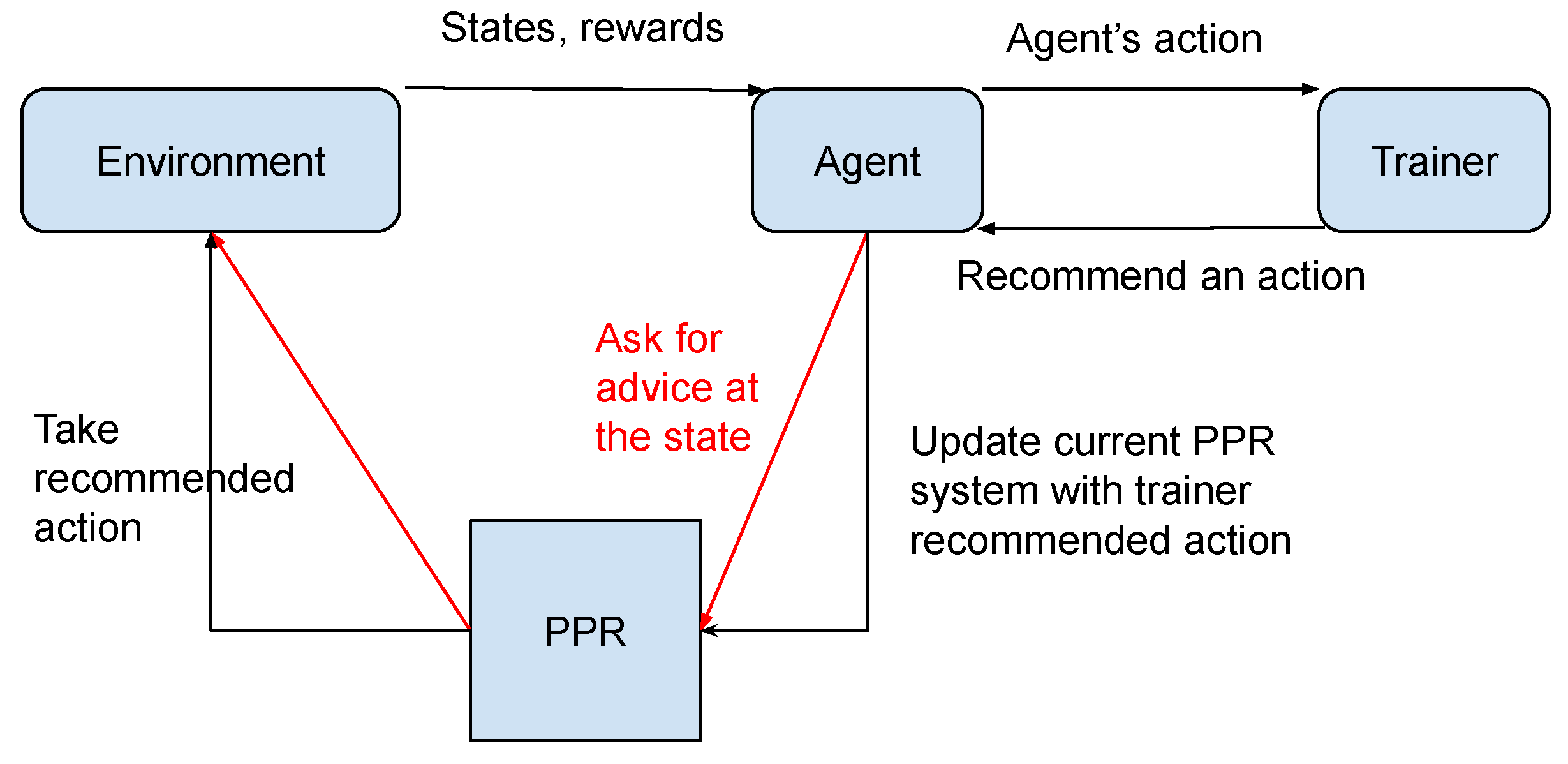
3.1. Persistent Advice
3.2. Broad Advice
4. Experimental Environments
4.1. Cart Pole Gym Environment
- State: The state vector has a continuous representation with four attributes, which represent the cart position, cart velocity, pole angle, and pole velocity.
- Action: The cart can perform two actions on the track: go to the left or the right.
- Reward function: As long as the agent holds the pole in a vertical position, a reward equal to 1 is awarded, and if it drops or goes beyond the boundaries of the track, the reward is equal to 0.
4.2. Domestic Robot Environment
- State: RGB image size 64 × 64 taken from the top of the environment.
- Action: Three actions: go straight at 3 mm/s, turn left, or turn right.
- Reward function: Turn left, right: −0.1; go straight: 0; collision: −100; reach final position: 1000.
4.3. Interactive Feedback
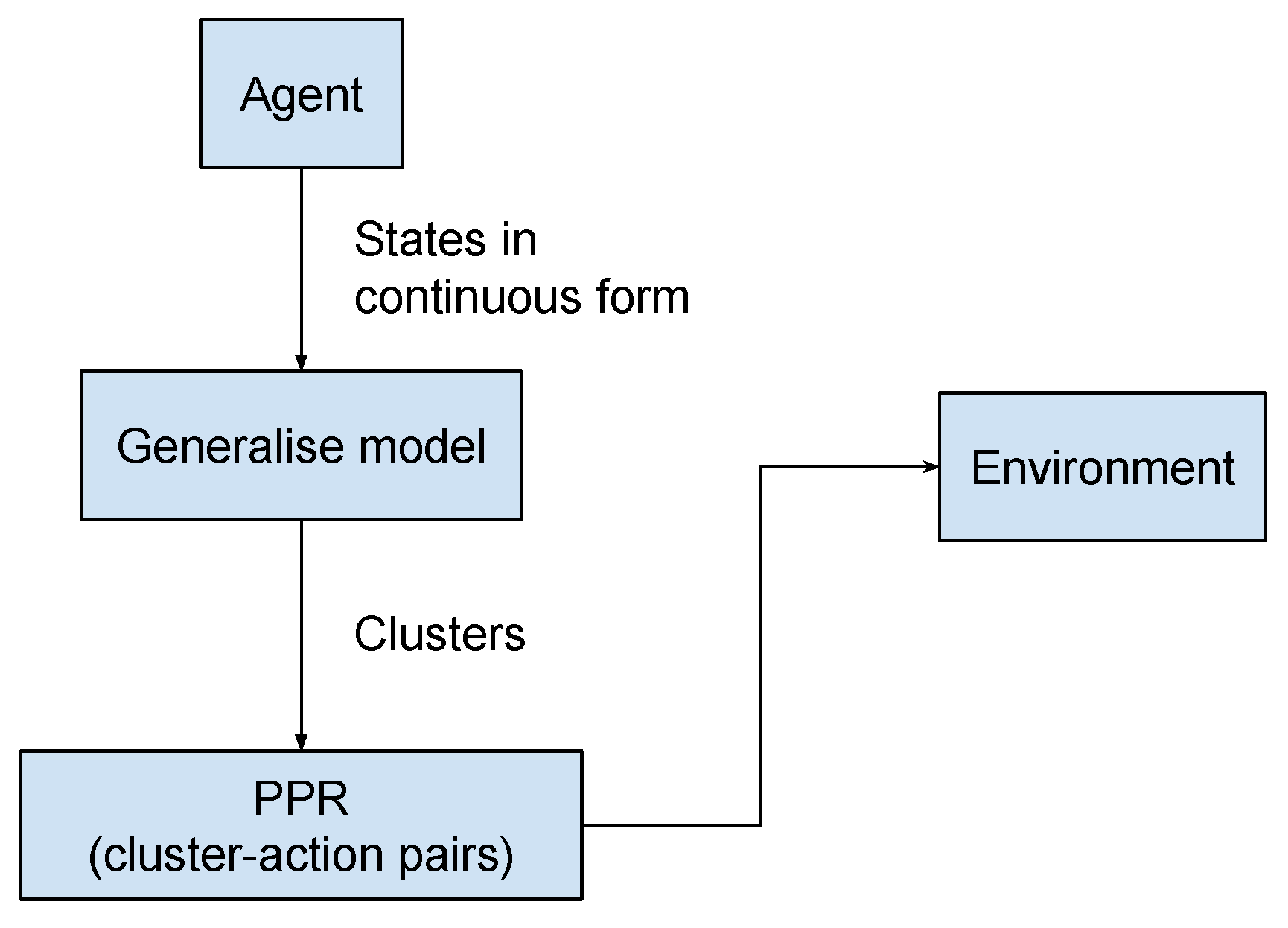
4.4. Generalised Model and Probabilistic Policy Reuse
| Algorithm 1 Interactive reinforcement learning with BPA. |
| 1: Build k-means model with states from trainer 2: Initialise environment selecting 3: for all (episodes) do 4: repeat 5: if (have feedback) then 6: Get recommended action 7: Get cluster by using k-means 8: Add pair (, ) to PPR 9: else 10: if () then 11: Get by using k-means 12: if ( is available in PPR) then 13: Get is reuse action from PPR 14: else 15: Random action from environment 16: end if 17: else 18: Choose action using 19: end if 20: end if 21: Perform action 22: Observe next state 23: until (s is terminal) 24: Update policy 25: end for |
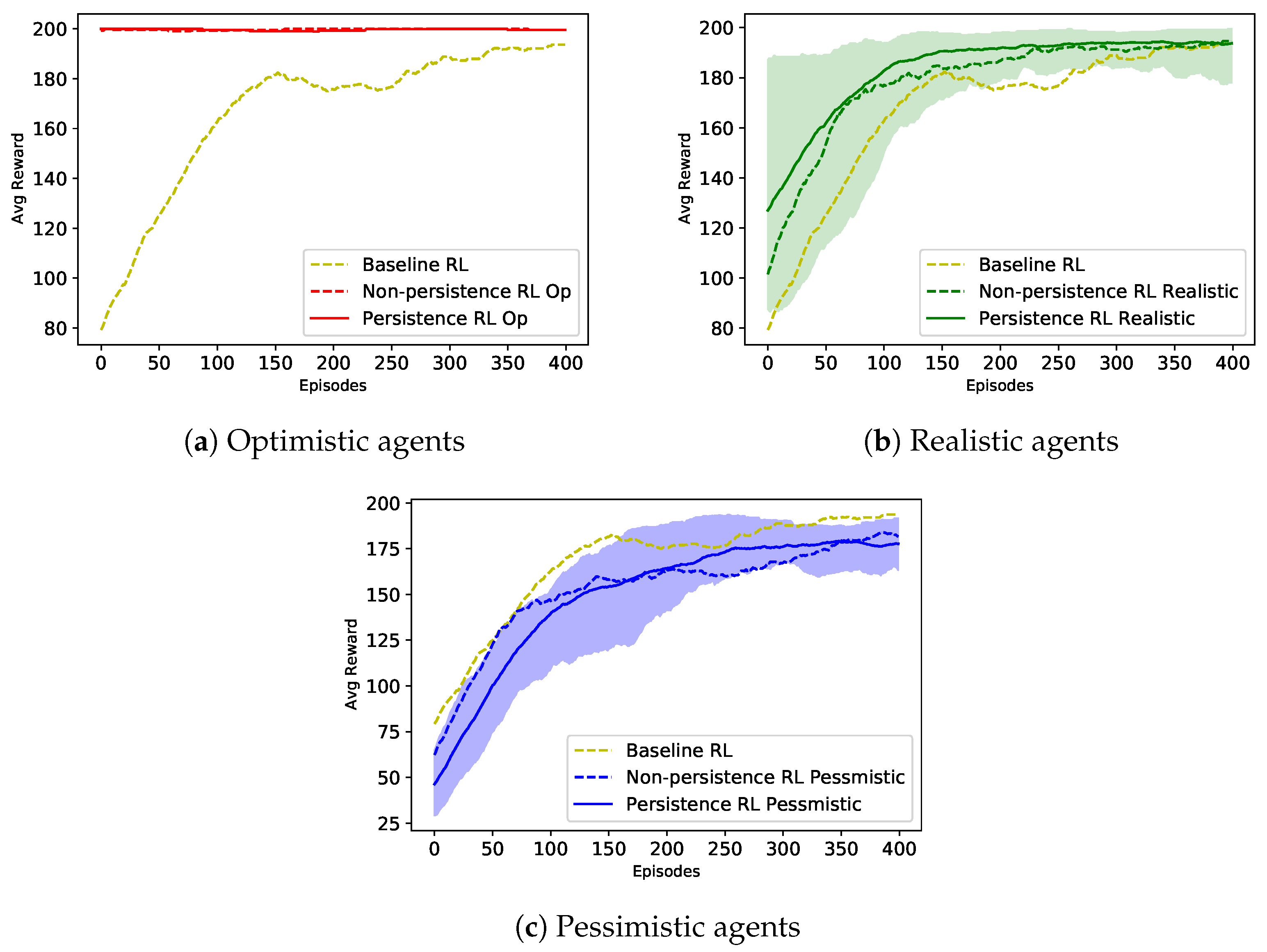
- Baseline reinforcement learning: The model is trained in a basic manner and collects information from the environment without using any interactive feedback or evaluation from the trainer. It was used as a benchmark.
- Non-persistent reinforcement learning: The agent is assisted by multiple types of users as mentioned before in Table 1. After taking the recommendation from the trainer and executing the action, the agent will discard the advice. When the agent comes to a similar state again in the future, it cannot recall the previous recommendation and performs an -greedy action instead.
- Persistent reinforcement learning: This agent is supported by a trainer and a PPR system. The trainer can suggest an action in each time step for the agent to take. If recommended, the learning agent will perform on that time step and retain the recommendation for reusing when it visits a similar state in the future. When an agent accesses a similar state it has previously suggested, it will perform that action with the probability determined by the PPR action selection rate.
5. Results
5.1. Cart Pole Domain
5.2. Webots Domain
6. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Dahlin, E. Are Robots Stealing Our Jobs? Socius Sociol. Res. Dyn. World 2019, 5, 237802311984624. [Google Scholar] [CrossRef] [Green Version]
- Cruz, F.; Wuppen, P.; Fazrie, A.; Weber, C.; Wermter, S. Action Selection Methods in a Robotic Reinforcement Learning Scenario. In Proceedings of the 2018 IEEE Latin American Conference on Computational Intelligence, LA-CCI 2018, Gudalajara, Mexico, 7–9 November 2018. [Google Scholar] [CrossRef]
- Tadele, T.S.; De Vries, T.; Stramigioli, S. The safety of domestic robotics: A survey of various safety-related publications. IEEE Robot. Autom. Mag. 2014, 21, 134–142. [Google Scholar] [CrossRef] [Green Version]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2018; p. 548. [Google Scholar]
- Kolat, M.; Kővári, B.; Bécsi, T.; Aradi, S. Multi-Agent Reinforcement Learning for Traffic Signal Control: A Cooperative Approach. Sustainability 2023, 15, 3479. [Google Scholar] [CrossRef]
- Lu, X.; Jie, J.; Lin, Z.; Xiao, L.; Li, J.; Zhang, Y. Reinforcement learning based energy efficient robot relay for unmanned aerial vehicles against smart jamming. Sci. China Inf. Sci. 2022, 65, 112304. [Google Scholar] [CrossRef]
- Wang, C.; Zhang, Q.; Tian, Q.; Li, S.; Wang, X.; Lane, D.; Petillot, Y.; Wang, S. Learning mobile manipulation through deep reinforcement learning. Sensors 2020, 20, 939. [Google Scholar] [CrossRef] [Green Version]
- Nguyen, H.; La, H. Review of deep reinforcement learning for robot manipulation. In Proceedings of the 2019 Third IEEE International Conference on Robotic Computing (IRC), Naples, Italy, 25–27 February 2019; pp. 590–595. [Google Scholar]
- Ibarz, J.; Tan, J.; Finn, C.; Kalakrishnan, M.; Pastor, P.; Levine, S. How to train your robot with deep reinforcement learning: Lessons we have learned. Int. J. Robot. Res. 2021, 40, 698–721. [Google Scholar] [CrossRef]
- Cruz, F.; Parisi, G.I.; Wermter, S. Multi-modal Feedback for Affordance-driven Interactive Reinforcement Learning. In Proceedings of the International Joint Conference on Neural Networks, Rio de Janeiro, Brazil, 8–13 July 2018. [Google Scholar] [CrossRef] [Green Version]
- Ayala, A.; Henríquez, C.; Cruz, F. Reinforcement learning using continuous states and interactive feedback. In Proceedings of the 2nd International Conference on Applications of Intelligent Systems, Las Palmas de Gran Canaria, Spain, 7–12 January 2019. [Google Scholar] [CrossRef]
- Bignold, A.; Cruz, F.; Taylor, M.E.; Brys, T.; Dazeley, R.; Vamplew, P.; Foale, C. A conceptual framework for externally-influenced agents: An assisted reinforcement learning review. J. Ambient. Intell. Humaniz. Comput. 2021, 1–24. [Google Scholar] [CrossRef]
- Cruz, F.; Magg, S.; Weber, C.; Wermter, S. Training Agents with Interactive Reinforcement Learning and Contextual Affordances. IEEE Trans. Cogn. Dev. Syst. 2016, 8, 271–284. [Google Scholar] [CrossRef]
- Moreira, I.; Rivas, J.; Cruz, F.; Dazeley, R.; Ayala, A.; Fernandes, B. Deep reinforcement learning with interactive feedback in a human-robot environment. Appl. Sci. 2020, 10, 5574. [Google Scholar] [CrossRef]
- Puterman, M.L. Markov Decision Processes: Discrete Stochastic Dynamic Programming; John Wiley & Sons: New York, NY, USA, 2014. [Google Scholar]
- Bellman, R. A Markovian decision process. J. Math. Mech. 1957, 6, 679–684. [Google Scholar] [CrossRef]
- Dulac-Arnold, G.; Mankowitz, D.; Hester, T. Challenges of real-world reinforcement learning. arXiv 2019, arXiv:1904.12901. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Graves, A.; Antonoglou, I.; Wierstra, D.; Riedmiller, M. Playing atari with deep reinforcement learning. arXiv 2013, arXiv:1312.5602. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef] [PubMed]
- Zhang, X.; Chen, P.; Yu, G.; Wang, S. Deep Reinforcement Learning Heterogeneous Channels for Poisson Multiple Access. Mathematics 2023, 11, 992. [Google Scholar] [CrossRef]
- Akkaya, I.; Andrychowicz, M.; Chociej, M.; Litwin, M.; McGrew, B.; Petron, A.; Paino, A.; Plappert, M.; Powell, G.; Ribas, R.; et al. Solving rubik’s cube with a robot hand. arXiv 2019, arXiv:1910.07113. [Google Scholar]
- Cruz, F.; Parisi, G.I.; Wermter, S. Learning contextual affordances with an associative neural architecture. In Proceedings of the European Symposium on Artificial Neural Networks (ESANN), Bruges, Belgium, 27–29 April 2016. [Google Scholar]
- Levine, S.; Pastor, P.; Krizhevsky, A.; Ibarz, J.; Quillen, D. Learning hand-eye coordination for robotic grasping with deep learning and large-scale data collection. Int. J. Robot. Res. 2018, 37, 421–436. [Google Scholar] [CrossRef]
- Griffith, S.; Subramanian, K.; Scholz, J.; Isbell, C.L.; Thomaz, A. Policy shaping: Integrating human feedback with Reinforcement Learning. In Proceedings of the Advances in Neural Information Processing Systems 26 (NIPS 2013), Lake Tahoe, NV, USA, 5–10 December 2013; pp. 1–9. [Google Scholar]
- Niv, Y. Reinforcement learning in the brain. J. Math. Psychol. 2009, 53, 139–154. [Google Scholar] [CrossRef] [Green Version]
- Knox, W.B.; Stone, P. Interactively shaping agents via human reinforcement: The TAMER framework. In Proceedings of the Fifth International Conference on Knowledge Capture, Redondo Beach, CA, USA, 1–4 September 2009; pp. 9–16. [Google Scholar]
- Cruz, F.; Twiefel, J.; Magg, S.; Weber, C.; Wermter, S. Interactive reinforcement learning through speech guidance in a domestic scenario. In Proceedings of the 2015 IEEE International Joint Conference on Neural Networks (IJCNN), Killarney, Ireland, 12–17 July 2015; pp. 1–8. [Google Scholar]
- Thomaz, A.L.; Hoffman, G.; Breazeal, C. Real-time interactive reinforcement learning for robots. In Proceedings of the AAAI 2005 Workshop on Human Comprehensible Machine Learning, Pittsburgh, PA, USA, 9–10 July 2005. [Google Scholar]
- Ng, A.Y.; Harada, D.; Russell, S. Policy invariance under reward transformations: Theory and application to reward shaping. In Proceedings of the Sixteenth International Conference on Machine Learning, Bled, Slovenia, 27–30 June 1999; Volume 3, pp. 278–287. [Google Scholar]
- Cederborg, T.; Grover, I.; Isbell, C.L.; Thomaz, A.L. Policy shaping with human teachers. In Proceedings of the Twenty-Fourth International Joint Conference on Artificial Intelligence, Buenos Aires, Argentina, 25–31 July 2015. [Google Scholar]
- Herbert, D.; Kang, B.H. Intelligent conversation system using multiple classification ripple down rules and conversational context. Expert Syst. Appl. 2018, 112, 342–352. [Google Scholar] [CrossRef]
- Bignold, A.; Cruz, F.; Dazeley, R.; Vamplew, P.; Foale, C. Human engagement providing evaluative and informative advice for interactive reinforcement learning. Neural Comput. Appl. 2022, 1–16. [Google Scholar] [CrossRef]
- Taylor, M.E.; Carboni, N.; Fachantidis, A.; Vlahavas, I.; Torrey, L. Reinforcement learning agents providing advice in complex video games. Connect. Sci. 2014, 26, 45–63. [Google Scholar] [CrossRef]
- Bignold, A.; Cruz, F.; Dazeley, R.; Vamplew, P.; Foale, C. Persistent rule-based interactive reinforcement learning. Neural Comput. Appl. 2021, 1–18. [Google Scholar] [CrossRef]
- Fernández, F.; Veloso, M. Probabilistic policy reuse in a reinforcement learning agent. In Proceedings of the Fifth International Conference on Autonomous Agents and Multiagent Systems, Hakodate, Japan, 8–12 May 2006; pp. 720–727. [Google Scholar]
- Park, G.Y.; Kim, H.; Jeong, H.W.; Youn, H.Y. A novel cluster head selection method based on K-means algorithm for energy efficient wireless sensor network. In Proceedings of the 2013 IEEE 27th International Conference on Advanced Information Networking and Applications Workshops, Barcelona, Spain, 25–28 March 2013; pp. 910–915. [Google Scholar]
- Madhulatha, T.S. An overview on clustering methods. arXiv 2012, arXiv:1205.1117. [Google Scholar] [CrossRef]
- Humaira, H.; Rasyidah, R. Determining The APPRopiate Cluster Number Using Elbow Method for K-Means Algorithm. In Proceedings of the 2nd Workshop on Multidisciplinary and Applications (WMA) 2018, Padang, Indonesia, 24–25 January 2018; EAI: Gent, Belgium, 2020. [Google Scholar]
- Brockman, G.; Cheung, V.; Pettersson, L.; Schneider, J.; Schulman, J.; Tang, J.; Zaremba, W. OpenAI Gym. arXiv 2016, arXiv:1606.01540. [Google Scholar]
- François-lavet, V.; Henderson, P.; Islam, R.; Bellemare, M.G.; François-lavet, V.; Pineau, J.; Bellemare, M.G. An Introduction to Deep Reinforcement Learning. Found. Trends Mach. Learn. 2018, 11, 219–354. [Google Scholar] [CrossRef] [Green Version]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef] [Green Version]
- Bishop, C.M. Pattern Recognition and Machine Learning Springer Mathematical Notation Ni; Springer: New York, NY, USA, 2006; p. 9. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Bignold, A.; Cruz, F.; Dazeley, R.; Vamplew, P.; Foale, C. An Evaluation Methodology for Interactive Reinforcement Learning with Simulated Users. Biomimetics 2021, 6, 13. [Google Scholar] [CrossRef]
- Cruz, F.; Magg, S.; Nagai, Y.; Wermter, S. Improving interactive reinforcement learning: What makes a good teacher? Connect. Sci. 2018, 30, 306–325. [Google Scholar] [CrossRef]
- Skinner, B.F. The Behavior of Organisms: An Experimental Analysis; BF Skinner Foundation: Cambridge, MA, USA, 2019. [Google Scholar]
- Kumar, S. Balancing a CartPole System with Reinforcement Learning—A Tutorial. arXiv 2020, arXiv:2006.04938. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Agent | Frequency | Accuracy |
|---|---|---|
| Pessimistic Advisor | 23.658% | 47.435% |
| Realistic Advisor | 47.316% | 94.87% |
| Optimistic Advisor | 100% | 100% |
| Agent | Interaction | |
|---|---|---|
| Non-Persistent | Persistent | |
| Optimistic Advisor | 99,796 (100%) | 99,846 (100%) |
| Realistic Advisor | 40,976 (47.15%) | 41,832 (47.1%) |
| Pessimistic Advisor | 18,034 (23.62%) | 16,685 (23.76%) |
| Agent | Interaction | |
|---|---|---|
| Non-Persistent | Persistent | |
| Realistic Advisor | 9077 (47.64%) | 8241 (47.18%) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nguyen, H.S.; Cruz, F.; Dazeley, R. Towards a Broad-Persistent Advising Approach for Deep Interactive Reinforcement Learning in Robotic Environments. Sensors 2023, 23, 2681. https://doi.org/10.3390/s23052681
Nguyen HS, Cruz F, Dazeley R. Towards a Broad-Persistent Advising Approach for Deep Interactive Reinforcement Learning in Robotic Environments. Sensors. 2023; 23(5):2681. https://doi.org/10.3390/s23052681
Chicago/Turabian StyleNguyen, Hung Son, Francisco Cruz, and Richard Dazeley. 2023. "Towards a Broad-Persistent Advising Approach for Deep Interactive Reinforcement Learning in Robotic Environments" Sensors 23, no. 5: 2681. https://doi.org/10.3390/s23052681