


Neural Networks for Hyperspectral Imaging of Historical Paintings: A Practical Review

 , ,
, ,  ,
,  , ,
, ,
Abstract
:1. Introduction
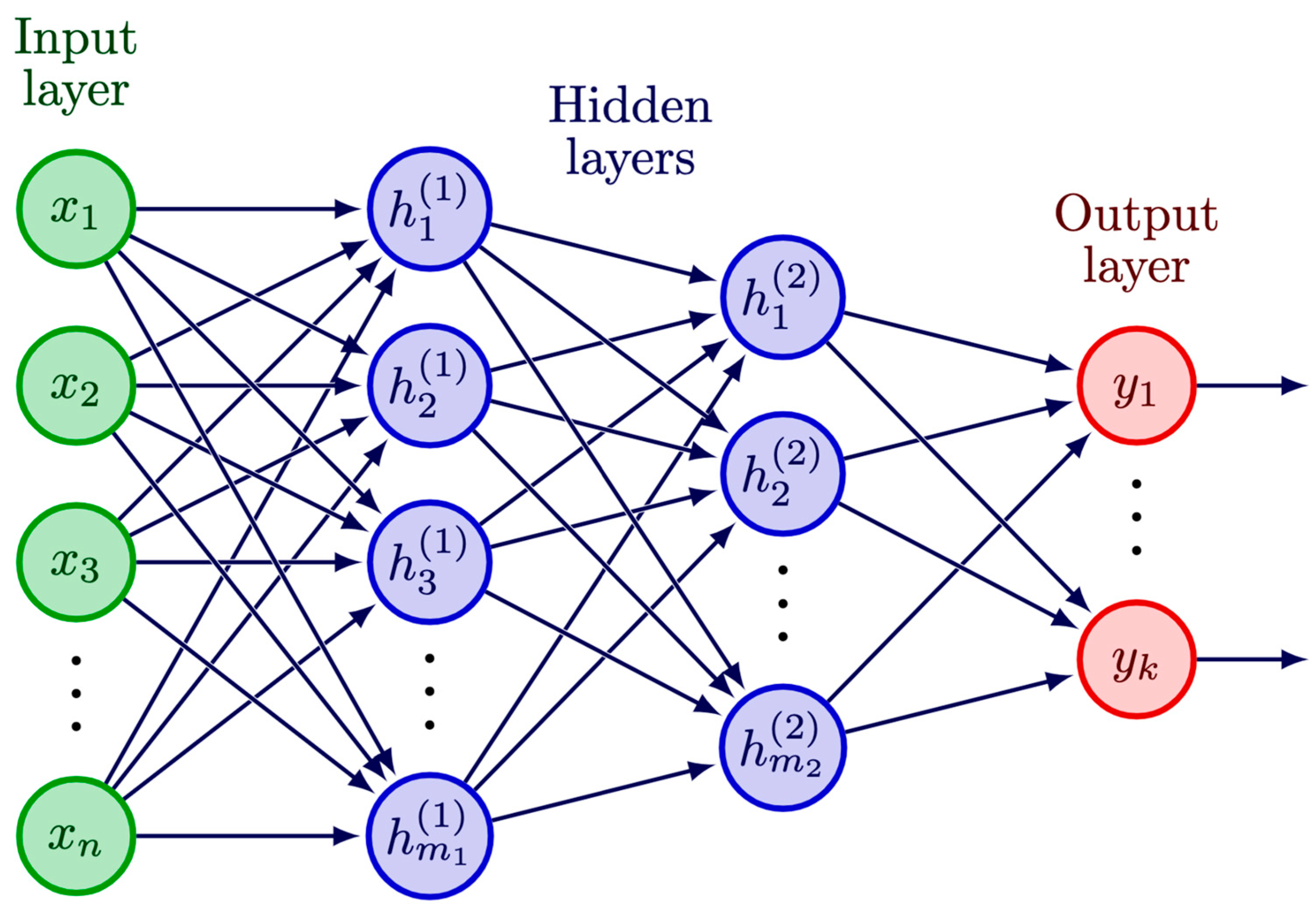
2. Neural Network Overall Workflow
- Number of hidden layers and neurons in each layer. The number of layers defines the depth of the network and is at the heart of the architecture affecting the performance of a NN [69].
- Activation functions define how the inputs to a neuron are transformed into an output to be fed into the next layer, where sigmoid, rectified linear unit (ReLU), and softmax functions are frequently used [70].
- Loss functions, such as mean squared error (MSE) and cross-entropy loss, are used to estimate the error between the ground truth and predicted output values [71].
- Learning rate defines how quickly a network updates its parameters towards convergence [72].
- Number of epochs and batch size. Epochs are the number of times the training data appears to the network and batch size determines after how many input sub-sets the network should update its parameters [72].
3. NN Application to the Study of Artistic Painting
- Paint component identification determines the presence or absence of a pigment based on a given spectrum—classification task;
- Paint component unmixing refers to quantitatively decomposing a given spectrum to its base constituents—regression task.
3.1. Paint Component Identification
3.2. Paint Component Unmixing
4. Dataset Preparation
4.1. Spectral Inputs
4.2. Data Types and Labelling Methods
4.2.1. Artificial Data
4.2.2. Modern Data
4.2.3. Historical Data
4.3. Pre-Processing
5. Model Architectures and Their Evaluation
5.1. Self-Organizing MAP (SOM)
5.2. Multilayer Perceptron (MLP)
5.2.1. Shallow MLP
5.2.2. Deep MLP
5.3. Convolutional Neural Networks (CNNs)
5.3.1. One-Dimensional-CNN
5.3.2. CNN with Transfer Learning
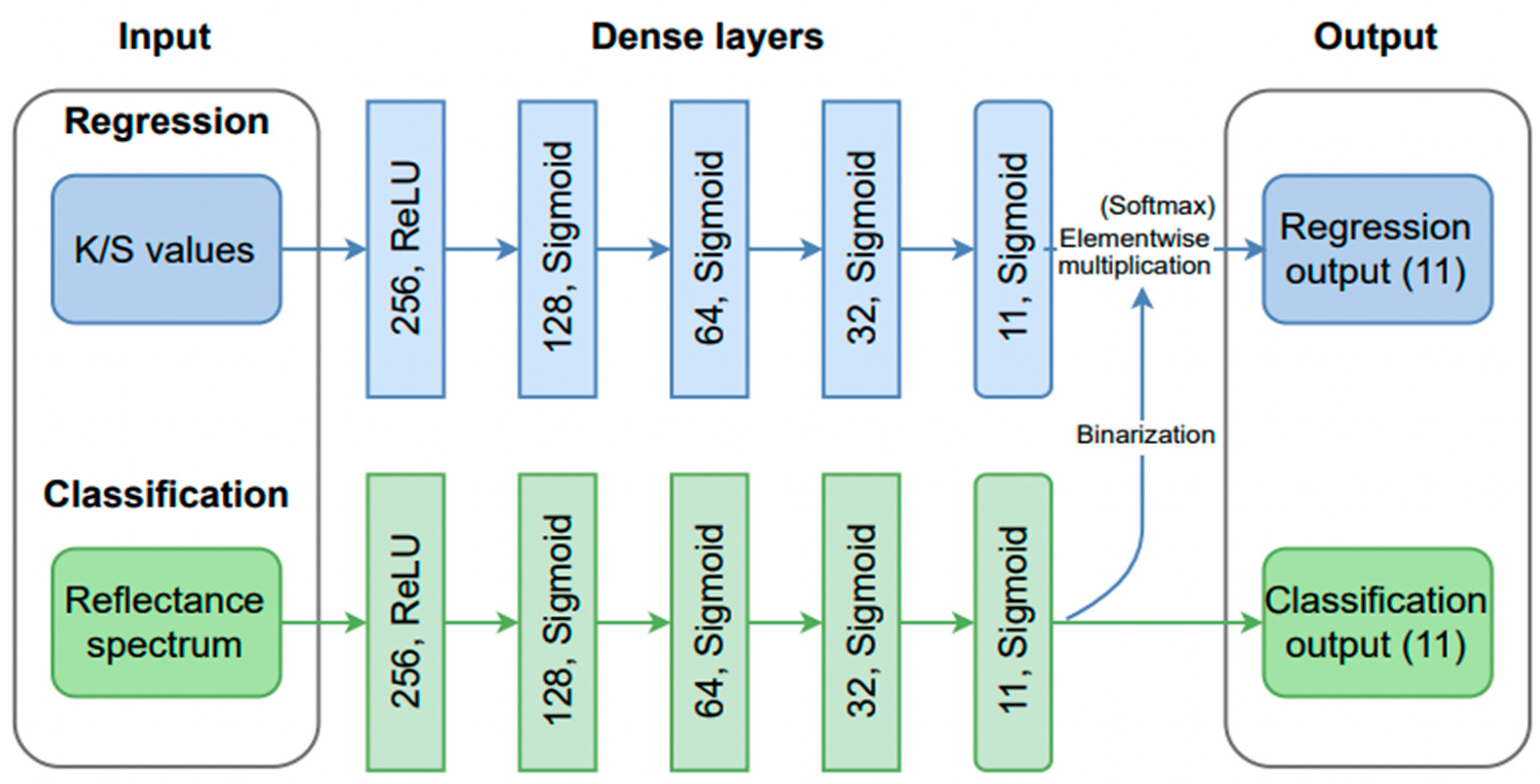
5.3.3. Multi-Branches CNN
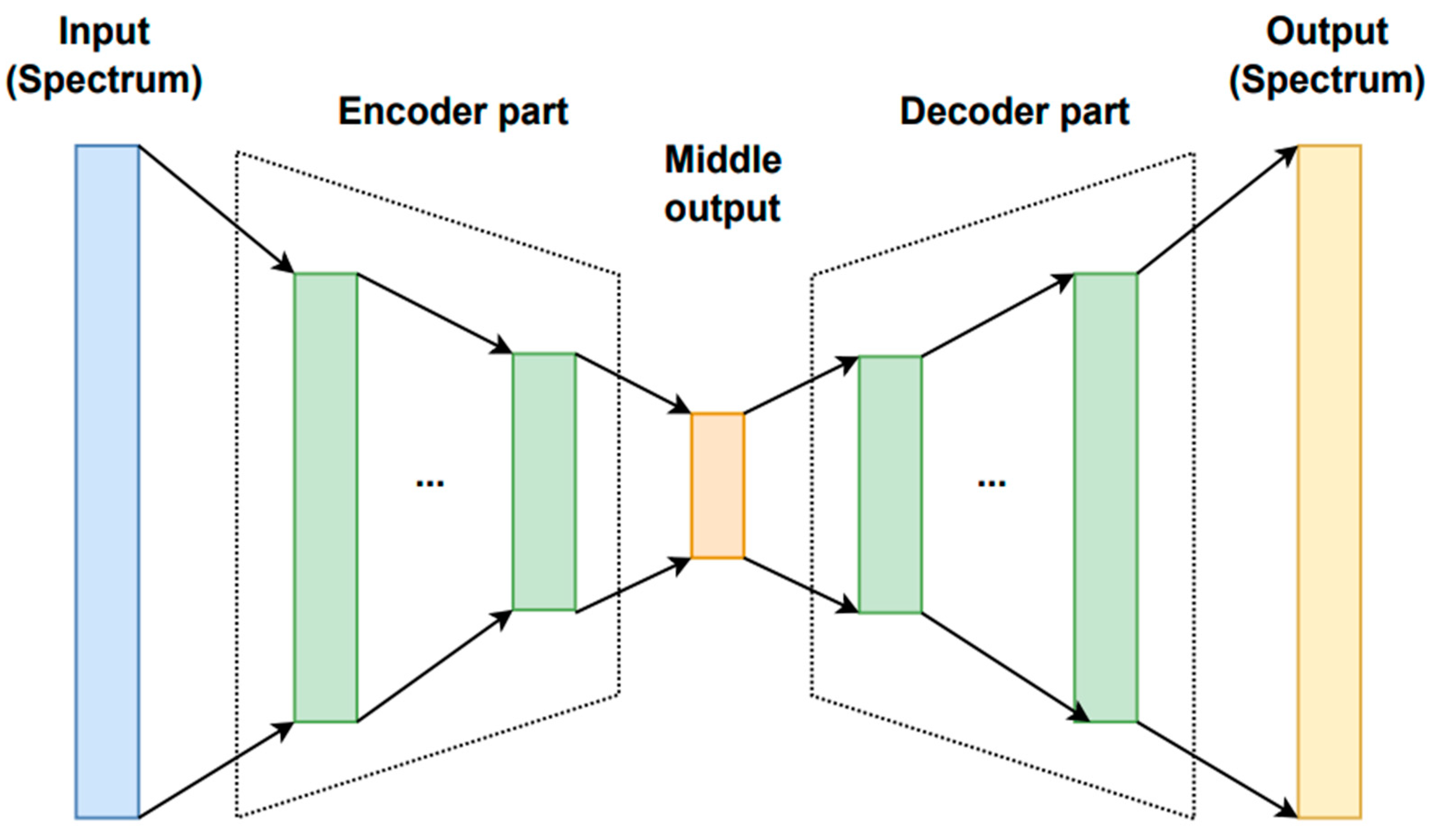
5.4. Encoder–Decoder (ENDEC)
5.5. Deep Belief Network (DBN)
5.6. Model Performance Evaluation
6. Discussion and Conclusions
7. Perspectives
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Liang, H. Advances in Multispectral and Hyperspectral Imaging for Archaeology and Art Conservation. Appl. Phys. A 2012, 106, 309–323. [Google Scholar] [CrossRef] [Green Version]
- Alfeld, M.; de Viguerie, L. Recent Developments in Spectroscopic Imaging Techniques for Historical Paintings—A Review. Spectrochim. Acta Part B At. Spectrosc. 2017, 136, 81–105. [Google Scholar] [CrossRef]
- Fischer, C.; Kakoulli, I. Multispectral and Hyperspectral Imaging Technologies in Conservation: Current Research and Potential Applications. Stud. Conserv. 2006, 51, 3–16. [Google Scholar] [CrossRef]
- Picollo, M.; Cucci, C.; Casini, A.; Stefani, L. Hyper-Spectral Imaging Technique in the Cultural Heritage Field: New Possible Scenarios. Sensors 2020, 20, 2843. [Google Scholar] [CrossRef]
- Legrand, S.; Vanmeert, F.; Van der Snickt, G.; Alfeld, M.; De Nolf, W.; Dik, J.; Janssens, K. Examination of Historical Paintings by State-of-the-Art Hyperspectral Imaging Methods: From Scanning Infra-Red Spectroscopy to Computed X-Ray Laminography. Herit. Sci. 2014, 2, 13. [Google Scholar] [CrossRef] [Green Version]
- Raimondi, V.; Conti, C.; Lognoli, D.; Palombi, L. Latest Advancements in Fluorescence Hyperspectral Lidar Imaging of the Cultural Heritage. In Proceedings of the Fundamentals of Laser-Assisted Micro- and Nanotechnologies 2013, St. Petersburg, Russia, 24–28 June 2013; SPIE: Bellingham, WA, USA; Volume 9065, pp. 274–284. [Google Scholar]
- Shi, W.; Koo, D.E.S.; Kitano, M.; Chiang, H.J.; Trinh, L.A.; Turcatel, G.; Steventon, B.; Arnesano, C.; Warburton, D.; Fraser, S.E.; et al. Pre-Processing Visualization of Hyperspectral Fluorescent Data with Spectrally Encoded Enhanced Representations. Nat. Commun. 2020, 11, 726. [Google Scholar] [CrossRef] [Green Version]
- Cucci, C.; Casini, A. Chapter 3.8—Hyperspectral Imaging for Artworks Investigation. In Data Handling in Science and Technology; Amigo, J.M., Ed.; Hyperspectral Imaging; Elsevier: Amsterdam, The Netherlands, 2019; Volume 32, pp. 583–604. [Google Scholar]
- Cucci, C.; Delaney, J.K.; Picollo, M. Reflectance Hyperspectral Imaging for Investigation of Works of Art: Old Master Paintings and Illuminated Manuscripts. Acc. Chem. Res. 2016, 49, 2070–2079. [Google Scholar] [CrossRef]
- Delaney, J.K.; Zeibel, J.G.; Thoury, M.; Littleton, R.O.Y.; Palmer, M.; Morales, K.M.; de La Rie, E.R.; Hoenigswald, A.N.N. Visible and Infrared Imaging Spectroscopy of Picasso’s Harlequin Musician: Mapping and Identification of Artist Materials in Situ. Appl. Spectrosc. 2010, 64, 584–594. [Google Scholar] [CrossRef]
- Bai, D.; Messinger, D.W.; Howell, D. A Pigment Analysis Tool for Hyperspectral Images of Cultural Heritage Artifacts. In Proceedings of the Algorithms and Technologies for Multispectral, Hyperspectral, and Ultraspectral Imagery XXIII, Anaheim, CA, USA, 9–13 April 2017; SPIE: Bellingham, WA, USA; Volume 10198, pp. 429–443. [Google Scholar]
- Costanzo, A.; Ebolese, D.; Ruffolo, S.A.; Falcone, S.; la Piana, C.; La Russa, M.F.; Musacchio, M.; Buongiorno, M.F. Detection of the TiO2 Concentration in the Protective Coatings for the Cultural Heritage by Means of Hyperspectral Data. Sustainability 2021, 13, 92. [Google Scholar] [CrossRef]
- Fan, C.; Zhang, P.; Wang, S.; Hu, B. A Study on Classification of Mineral Pigments Based on Spectral Angle Mapper and Decision Tree. In Proceedings of the Tenth International Conference on Digital Image Processing (ICDIP 2018), Shanghai, China, 11–14 May 2018; SPIE: Bellingham, WA, USA; Volume 10806, pp. 1639–1643. [Google Scholar]
- Rohani, N. Machine Learning for Multi-Sensory Data. Ph.D. Thesis, Northwestern University, Evanston, IL, USA, 2021. [Google Scholar]
- Gao, Z.; Du, M.; Cao, N.; Hou, M.; Wang, W.; Lyu, S. Application of Hyperspectral Imaging Technology to Digitally Protect Murals in the Qutan Temple. Herit. Sci. 2023, 11, 8. [Google Scholar] [CrossRef]
- Guan, Q.; Xu, T.; Feng, S.; Yu, F.; Song, K. Optimal Segmentation and Improved Abundance Estimation for Superpixel-Based Hyperspectral Unmixing. Eur. J. Remote Sens. 2022, 55, 485–506. [Google Scholar] [CrossRef]
- Sato, T.; Nakano, Y.; Iga, T.; Nakauchi, S.; Usui, S. Color Reproduction Based on Low Dimensional Spectral Reflectance Using the Principal Component Analysis. In Proceedings of the Color and Imaging Conference; Society for Imaging Science and Technology, Scottsdale, AZ, USA, 19–22 November 1996; Volume 1996, pp. 185–188. [Google Scholar]
- Peng, J.; Yu, K.; Wang, J.; Zhang, Q.; Wang, L.; Fan, P. Mining Painted Cultural Relic Patterns Based on Principal Component Images Selection and Image Fusion of Hyperspectral Images. J. Cult. Herit. 2019, 36, 32–39. [Google Scholar] [CrossRef]
- Farrell, M.D.; Mersereau, R.M. On the Impact of PCA Dimension Reduction for Hyperspectral Detection of Difficult Targets. IEEE Geosci. Remote Sens. Lett. 2005, 2, 192–195. [Google Scholar] [CrossRef]
- Rodarmel, C.; Shan, J. Principal Component Analysis for Hyperspectral Image Classification. Surv. Land. Inf. Syst. 2002, 62, 115–122. [Google Scholar]
- Chen, Y.; Liu, X.; Lyu, S.; Wu, W.; Wang, R. Method of Hidden Strip Information Extraction from Hyperspectral Images of Ancient Paintings. Sens. Mater. 2022, 34, 4463. [Google Scholar] [CrossRef]
- Catelli, E.; Randeberg, L.L.; Alsberg, B.K.; Gebremariam, K.F.; Bracci, S. An Explorative Chemometric Approach Applied to Hyperspectral Images for the Study of Illuminated Manuscripts. Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2017, 177, 69–78. [Google Scholar] [CrossRef]
- Rohani, N.; Salvant, J.; Bahaadini, S.; Cossairt, O.; Walton, M.; Katsaggelos, A. Automatic Pigment Identification on Roman Egyptian Paintings by Using Sparse Modeling of Hyperspectral Images. In Proceedings of the 2016 24th European Signal Processing Conference (EUSIPCO), Budapest, Hungary, 29 August–2 September 2016; pp. 2111–2115. [Google Scholar]
- Bai, D.; Messinger, D.W.; Howell, D. A Hyperspectral Imaging Spectral Unmixing and Classification Approach to Pigment Mapping in the Gough & Selden Maps. J. Am. Inst. Conserv. 2019, 58, 69–89. [Google Scholar] [CrossRef]
- Taufique, A.M.N.; Messinger, D.W. Hyperspectral Pigment Analysis of Cultural Heritage Artifacts Using the Opaque Form of Kubelka-Munk Theory. In Proceedings of the Algorithms, Technologies, and Applications for Multispectral and Hyperspectral Imagery XXV, Baltimore, MA, USA, 14–18 April 2019; SPIE: Bellingham, WA, USA; Volume 10986, pp. 297–307. [Google Scholar]
- Polak, A.; Kelman, T.; Murray, P.; Marshall, S.; Stothard, D.J.M.; Eastaugh, N.; Eastaugh, F. Hyperspectral Imaging Combined with Data Classification Techniques as an Aid for Artwork Authentication. J. Cult. Herit. 2017, 26, 1–11. [Google Scholar] [CrossRef]
- Grabowski, B.; Masarczyk, W.; Głomb, P.; Mendys, A. Automatic Pigment Identification from Hyperspectral Data. J. Cult. Herit. 2018, 31, 1–12. [Google Scholar] [CrossRef]
- Liu, L.; Delnevo, G.; Mirri, S. Hierarchical Clustering as an Unsurpervised Machine Learning Algorithm for Hyperspectral Image Segmentation of Films. In Proceedings of the 2022 ACM Conference on Information Technology for Social Good, Limassol, Cyprus, 7–9 September 2022; Association for Computing Machinery: New York, NY, USA; pp. 397–402. [Google Scholar]
- Pouyet, E.; Rohani, N.; Katsaggelos, A.K.; Cossairt, O.; Walton, M. Innovative Data Reduction and Visualization Strategy for Hyperspectral Imaging Datasets Using T-SNE Approach. Pure Appl. Chem. 2018, 90, 493–506. [Google Scholar] [CrossRef]
- Alfeld, M.; Pedetti, S.; Martinez, P.; Walter, P. Joint Data Treatment for Vis–NIR Reflectance Imaging Spectroscopy and XRF Imaging Acquired in the Theban Necropolis in Egypt by Data Fusion and t-SNE. Comptes Rendus Phys. 2018, 19, 625–635. [Google Scholar] [CrossRef]
- Van Loon, A.; Noble, P.; de Man, D.; Alfeld, M.; Callewaert, T.; Van der Snickt, G.; Janssens, K.; Dik, J. The Role of Smalt in Complex Pigment Mixtures in Rembrandt’s Homer 1663: Combining MA-XRF Imaging, Microanalysis, Paint Reconstructions and OCT. Herit. Sci. 2020, 8, 90. [Google Scholar] [CrossRef]
- Vermeulen, M.; Smith, K.; Eremin, K.; Rayner, G.; Walton, M. Application of Uniform Manifold Approximation and Projection (UMAP) in Spectral Imaging of Artworks. Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2021, 252, 119547. [Google Scholar] [CrossRef]
- Kleynhans, T.; Messinger, D.W.; Delaney, J.K. Towards Automatic Classification of Diffuse Reflectance Image Cubes from Paintings Collected with Hyperspectral Cameras. Microchem. J. 2020, 157, 104934. [Google Scholar] [CrossRef]
- Vermeulen, M.; McGeachy, A.; Xu, B.; Chopp, H.; Katsaggelos, A.; Meyers, R.; Alfeld, M.; Walton, M. XRFast a New Software Package for Processing of MA-XRF Datasets Using Machine Learning. J. Anal. At. Spectrom. 2022, 37, 2130–2143. [Google Scholar] [CrossRef]
- Liu, L.; Catelli, E.; Katsaggelos, A.; Sciutto, G.; Mazzeo, R.; Milanic, M.; Stergar, J.; Prati, S.; Walton, M. Digital Restoration of Colour Cinematic Films Using Imaging Spectroscopy and Machine Learning. Sci. Rep. 2022, 12, 21982. [Google Scholar] [CrossRef]
- Fiorucci, M.; Khoroshiltseva, M.; Pontil, M.; Traviglia, A.; Del Bue, A.; James, S. Machine Learning for Cultural Heritage: A Survey. Pattern Recognit. Lett. 2020, 133, 102–108. [Google Scholar] [CrossRef]
- Paoletti, M.E.; Haut, J.M.; Plaza, J.; Plaza, A. Deep Learning Classifiers for Hyperspectral Imaging: A Review. ISPRS J. Photogramm. Remote Sens. 2019, 158, 279–317. [Google Scholar] [CrossRef]
- Saleh, B.; Elgammal, A. Large-Scale Classification of Fine-Art Paintings: Learning The Right Metric on The Right Feature 2015. arXiv 2015, arXiv:1505.00855. [Google Scholar]
- Der Vaart, W.B.V.; Lambers, K. Learning to Look at LiDAR: The Use of R-CNN in the Automated Detection of Archaeological Objects in LiDAR Data from the Netherlands. J. Comput. Appl. Archaeol. 2019, 2, 31–40. [Google Scholar] [CrossRef] [Green Version]
- Sabetsarvestani, Z.; Sober, B.; Higgitt, C.; Daubechies, I.; Rodrigues, M.R.D. Artificial Intelligence for Art Investigation: Meeting the Challenge of Separating x-Ray Images of the Ghent Altarpiece. Sci. Adv. 2019, 5, eaaw7416. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Web of Science. Available online: https://www.webofscience.com/wos/ (accessed on 28 October 2022).
- Abiodun, O.I.; Jantan, A.; Omolara, A.E.; Dada, K.V.; Mohamed, N.A.; Arshad, H. State-of-the-Art in Artificial Neural Network Applications: A Survey. Heliyon 2018, 4, e00938. [Google Scholar] [CrossRef] [Green Version]
- Shi, L.; Babaei, V.; Kim, C.; Foshey, M.; Hu, Y.; Sitthi-Amorn, P.; Rusinkiewicz, S.; Matusik, W. Deep Multispectral Painting Reproduction via Multi-Layer, Custom-Ink Printing. ACM Trans. Graph. 2018, 37, 271:1–271:15. [Google Scholar] [CrossRef]
- Osorio-Gomez, C.A.; Mejia-Ospino, E.; Guerrero-Bermudez, J.E. Spectral Reflectance Curves for Multispectral Imaging, Combining Different Techniques and a Neural Network. Rev. Mex. Fis. 2009, 55, 120–124. [Google Scholar]
- Chane, C.S.; Thoury, M.; Tournié, A.; Echard, J.-P. Implementation of a Neural Network for Multispectral Luminescence Imaging of Lake Pigment Paints. Appl. Spectrosc. 2015, 69, 430–441. [Google Scholar] [CrossRef]
- Ribes, A.; Schmit, F. Reconstructing Spectral Reflectances with Mixture Density Networks. In Proceedings of the CGIV’2002: First European Conference on Colour in Graphics, Imaging, and Vision, Poitiers, France, 2–5 April 2002; pp. 486–491. [Google Scholar]
- Ribés, A.; Schmitt, F. A Fully Automatic Method for the Reconstruction of Spectral Reflectance Curves by Using Mixture Density Networks. Pattern Recognit. Lett. 2003, 24, 1691–1701. [Google Scholar] [CrossRef]
- Cortes, A.R. Multispectral Analysis and Spectral Reflectance Reconstruction of Art Paintings. Ph.D. Thesis, Télécom ParisTech, Palaiseau, France, 2003. [Google Scholar]
- Chen, A.; Jesus, R.; Vilarigues, M. Convolutional Neural Network-Based Pure Paint Pigment Identification Using Hyperspectral Images. In Proceedings of the ACM Multimedia Asia, Gold Coast, Australia, 1–3 December 2021; pp. 1–7. [Google Scholar]
- Jones, C.; Daly, N.S.; Higgitt, C.; Rodrigues, M.R.D. Neural Network-Based Classification of X-Ray Fluorescence Spectra of Artists’ Pigments: An Approach Leveraging a Synthetic Dataset Created Using the Fundamental Parameters Method. Herit. Sci. 2022, 10, 88. [Google Scholar] [CrossRef]
- Kogou, S.; Lee, L.; Shahtahmassebi, G.; Liang, H. A New Approach to the Interpretation OfXRFspectral Imaging Data Using Neural Networks. X-ray Spectrom. 2021, 50, 310–319. [Google Scholar] [CrossRef]
- Liggins, F.; Vichi, A.; Liu, W.; Hogg, A.; Kogou, S.; Chen, J.; Liang, H. Hyperspectral Imaging Solutions for the Non-Invasive Detection and Automated Mapping of Copper Trihydroxychlorides in Ancient Bronze. Herit. Sci. 2022, 10, 142. [Google Scholar] [CrossRef]
- Kleynhans, T.; Schmidt Patterson, C.M.; Dooley, K.A.; Messinger, D.W.; Delaney, J.K. An Alternative Approach to Mapping Pigments in Paintings with Hyperspectral Reflectance Image Cubes Using Artificial Intelligence. Herit. Sci. 2020, 8, 84. [Google Scholar] [CrossRef]
- Sun, M.; Zhang, D.; Wang, Z.; Ren, J.; Chai, B.; Sun, J. What’s Wrong with the Murals at the Mogao Grottoes: A Near-Infrared Hyperspectral Imaging Method. Sci. Rep. 2015, 5, 14371. [Google Scholar] [CrossRef] [Green Version]
- Lin, Y.; Xu, C.; Lyu, S. Disease Regions Recognition on Mural Hyperspectral Images Combined by MNF and BP Neural Network. J. Phys. Conf. Ser. 2019, 1325, 012095. [Google Scholar] [CrossRef]
- Rohani, N.; Pouyet, E.; Walton, M.; Cossairt, O.; Katsaggelos, A.K. Nonlinear Unmixing of Hyperspectral Datasets for the Study of Painted Works of Art. Angew. Chem. 2018, 130, 11076–11080. [Google Scholar] [CrossRef]
- Rohani, N.; Pouyet, E.; Walton, M.; Cossairt, O.; Katsaggelos, A.K. Pigment Unmixing of Hyperspectral Images of Paintings Using Deep Neural Networks. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 3217–3221. [Google Scholar]
- Pouyet, E.; Miteva, T.; Rohani, N.; de Viguerie, L. Artificial Intelligence for Pigment Classification Task in the Short-Wave Infrared Range. Sensors 2021, 21, 6150. [Google Scholar] [CrossRef]
- Xu, B.J.; Wu, Y.; Hao, P.; Vermeulen, M.; McGeachy, A.; Smith, K.; Eremin, K.; Rayner, G.; Verri, G.; Willomitzer, F.; et al. Can deep learning assist automatic identification of layered pigments from XRF data? J. Anal. At. Spectrom. 2022, 37, 2672–2682. [Google Scholar] [CrossRef]
- Striova, J.; Ruberto, C.; Barucci, M.; Blazek, J.; Kunzelman, D.; Dal Fovo, A.; Pampaloni, E.; Fontana, R. Spectral Imaging and Archival Data in Analysing Madonna of the Rabbit Paintings by Manet and Titian. Angew. Chem. Int. Edit. 2018, 57, 7408–7412. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Q.; Cui, S.; Liu, L.; Wang, J.; Wang, J.; Zhang, E.; Peng, J.; Kogou, S.; Liggins, F.; Liang, H. Deep Learning for the Extraction of Sketches from Spectral Images of Historical Paintings. In Proceedings of the Optics for Arts, Architecture, and Archaeology VIII, Online, 21–25 June 2021; SPIE: Bellingham, WA, USA; Volume 11784, pp. 11–20. [Google Scholar]
- Fukumoto, K.; Tsumura, N.; Berns, R. Estimating Pigment Concentrations from Spectral Images Using an Encoder—Decoder Neural Network. J. Imaging Sci. Technol. 2020, 64, art00004. [Google Scholar] [CrossRef]
- Sun, P.; Hou, M.; Lyu, S.; Wang, W.; Li, S.; Mao, J.; Li, S. Enhancement and Restoration of Scratched Murals Based on Hyperspectral Imaging—A Case Study of Murals in the Baoguang Hall of Qutan Temple, Qinghai, China. Sensors 2022, 22, 9780. [Google Scholar] [CrossRef]
- Shitomi, R.; Tsuji, M.; Fujimura, Y.; Funatomi, T.; Mukaigawa, Y.; Morimoto, T.; Oishi, T.; Takamatsu, J.; Ikeuchi, K. Unsupervised Learning with a Physics-Based Autoencoder for Estimating the Thickness and Mixing Ratio of Pigments. J. Opt. Soc. Am. A 2023, 40, 116. [Google Scholar] [CrossRef]
- Svozil, D.; Kvasnicka, V.; Pospichal, J. Introduction to Multi-Layer Feed-Forward Neural Networks. Chemom. Intell. Lab. Syst. 1997, 39, 43–62. [Google Scholar] [CrossRef]
- Sibi, P.; Jones, S.A.; Siddarth, P. Analysis of Different Activation Functions Using Back Propagation Neural Networks. J. Theor. Appl. Inf. Technol. 2013, 47, 1264–1268. [Google Scholar]
- Sharma, S.; Sharma, S.; Athaiya, A. Activation Functions in Neural Networks. Data Sci. 2017, 6, 310–316. [Google Scholar] [CrossRef]
- Diaz, G.I.; Fokoue-Nkoutche, A.; Nannicini, G.; Samulowitz, H. An Effective Algorithm for Hyperparameter Optimization of Neural Networks. IBM J. Res. Dev. 2017, 61, 9:1–9:11. [Google Scholar] [CrossRef] [Green Version]
- Adil, M.; Ullah, R.; Noor, S.; Gohar, N. Effect of Number of Neurons and Layers in an Artificial Neural Network for Generalized Concrete Mix Design. Neural Comput. Appl. 2022, 34, 8355–8363. [Google Scholar] [CrossRef]
- Karlik, B.; Olgac, A.V. Performance Analysis of Various Activation Functions in Generalized MLP Architectures of Neural Networks. Int. J. Artif. Intell. Expert Syst. 2011, 1, 111–122. [Google Scholar]
- Zhao, H.; Gallo, O.; Frosio, I.; Kautz, J. Loss Functions for Image Restoration With Neural Networks. IEEE Trans. Comput. Imaging 2017, 3, 47–57. [Google Scholar] [CrossRef]
- He, F.; Liu, T.; Tao, D. Control Batch Size and Learning Rate to Generalize Well: Theoretical and Empirical Evidence. In Proceedings of the Advances in Neural Information Processing Systems 32 (NeurIPS 2019), Vancouver, BC, Canada, 8–14 December 2019; Curran Associates, Inc.: Dutchess County, NY, USA; Volume 32. [Google Scholar]
- Karpathy, A.; Johnson, J.; Fei-Fei, L. Visualizing and Understanding Recurrent Networks. arXiv 2015, arXiv:1506.02078. [Google Scholar]
- Lipton, Z.C.; Berkowitz, J.; Elkan, C. A Critical Review of Recurrent Neural Networks for Sequence Learning. arXiv 2015, arXiv:1506.00019. [Google Scholar]
- Creswell, A.; White, T.; Dumoulin, V.; Arulkumaran, K.; Sengupta, B.; Bharath, A.A. Generative Adversarial Networks: An Overview. IEEE Signal Process. Mag. 2018, 35, 53–65. [Google Scholar] [CrossRef] [Green Version]
- Wang, K.; Gou, C.; Duan, Y.; Lin, Y.; Zheng, X.; Wang, F.-Y. Generative Adversarial Networks: Introduction and Outlook. IEEE/CAA J. Autom. Sin. 2017, 4, 588–598. [Google Scholar] [CrossRef]
- Albawi, S.; Mohammed, T.A.; Al-Zawi, S. Understanding of a Convolutional Neural Network. In Proceedings of the 2017 International Conference on Engineering and Technology (ICET), Antalya, Turkey, 21–23 August 2017; pp. 1–6. [Google Scholar]
- O’Shea, K.; Nash, R. An Introduction to Convolutional Neural Networks. arXiv 2015, arXiv:1511.08458. [Google Scholar]
- Zhuang, F.; Qi, Z.; Duan, K.; Xi, D.; Zhu, Y.; Zhu, H.; Xiong, H.; He, Q. A Comprehensive Survey on Transfer Learning. Proc. IEEE 2021, 109, 43–76. [Google Scholar] [CrossRef]
- Gurney, K. An Introduction to Neural Networks; CRC Press: Boca Raton, FL, USA, 2018. [Google Scholar]
- Arai, Y.; Nakauchi, S.; Usui, S. Color Correction Method Based on the Spectral Reflectance Estimation Using a Neural Network. In Proceedings of the Color and Imaging Conference, Scottsdale, AZ, USA, 19–22 November 1996; Society for Imaging Science and Technology: Springfield, VA, USA; Volume 1996, pp. 5–9. [Google Scholar]
- Sherman, J. The Theoretical Derivation of Fluorescent X-Ray Intensities from Mixtures. Spectrochim. Acta 1955, 7, 283–306. [Google Scholar] [CrossRef]
- Berns, R.S.; Mohammadi, M. Evaluating Single- and Two-Constant Kubelka-Munk Turbid Media Theory for Instrumental-Based Inpainting. Stud. Conserv. 2007, 52, 299–314. [Google Scholar] [CrossRef]
- Moghareh Abed, F. Pigment Identification of Paintings Based on Kubelka-Munk Theory and Spectral Images. Ph.D. Thesis, Rochester Institute of Technology, Rochester, NY, USA, 2014. [Google Scholar]
- Kohonen, T. Self-Organizing Maps, 3rd ed.; Springer Series in Information Services; Springer: Berlin/Heidelberg, Germany, 2001. [Google Scholar]
- Sazli, M.H. A Brief Review of Feed-Forward Neural Networks. Commun. Fac. Sci. Univ. Ank. Ser. A2–A3 Phys. Sci. Eng. 2006, 50, 11–17. [Google Scholar] [CrossRef]
- Mardquardt, D.W. An Algorithm for Least Square Estimation of Parameters. J. Soc. Ind. Appl. Math 1963, 11, 431–441. [Google Scholar] [CrossRef]
- Levenberg, K. A Method for the Solution of Certain Non-Linear Problems in Least Squares. Quart. Appl. Math. 1944, 2, 164–168. [Google Scholar] [CrossRef] [Green Version]
- Sklearn.Neural_network.MLPClassifier. Available online: https://scikit-learn/stable/modules/generated/sklearn.neural_network.MLPClassifier.html (accessed on 10 February 2023).
- Blažek, J.; Striová, J.; Fontana, R.; Zitová, B. Improvement of the Visibility of Concealed Features in Artwork NIR Reflectograms by Information Separation. Digit. Signal Process. 2017, 60, 140–151. [Google Scholar] [CrossRef]
- Sun, Y.; Xue, B.; Zhang, M.; Yen, G.G. Completely Automated CNN Architecture Design Based on Blocks. IEEE Trans. Neural Netw. Learn. Syst. 2020, 31, 1242–1254. [Google Scholar] [CrossRef]
- Alzubaidi, L.; Zhang, J.; Humaidi, A.J.; Al-Dujaili, A.; Duan, Y.; Al-Shamma, O.; Santamaría, J.; Fadhel, M.A.; Al-Amidie, M.; Farhan, L. Review of Deep Learning: Concepts, CNN Architectures, Challenges, Applications, Future Directions. J. Big Data 2021, 8, 53. [Google Scholar] [CrossRef]
- He, J.; Zhang, S.; Yang, M.; Shan, Y.; Huang, T. Bi-Directional Cascade Network for Perceptual Edge Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015, Munich, Germany, 5–9 October 2015; Springer International Publishing: Cham, Switzerland; pp. 234–241. [Google Scholar]
- Kriegeskorte, N.; Douglas, P.K. Interpreting Encoding and Decoding Models. Curr. Opin. Neurobiol. 2019, 55, 167–179. [Google Scholar] [CrossRef] [PubMed]
- Minaee, S.; Boykov, Y.; Porikli, F.; Plaza, A.; Kehtarnavaz, N.; Terzopoulos, D. Image Segmentation Using Deep Learning: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 3523–3542. [Google Scholar] [CrossRef]
- Ji, Y.; Zhang, H.; Zhang, Z.; Liu, M. CNN-Based Encoder-Decoder Networks for Salient Object Detection: A Comprehensive Review and Recent Advances. Inf. Sci. 2021, 546, 835–857. [Google Scholar] [CrossRef]
- Wan, Z.; Zhang, B.; Chen, D.; Zhang, P.; Chen, D.; Liao, J.; Wen, F. Bringing Old Photos Back to Life. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 2744–2754. [Google Scholar]
- Fischer, A.; Igel, C. An Introduction to Restricted Boltzmann Machines. In Proceedings of the Progress in Pattern Recognition, Image Analysis, Computer Vision, and Applications, Buenos Aires, Argentina, 3–6 September 2012; Springer: Berlin/Heidelberg, Germany, 2012; pp. 14–36. [Google Scholar]
- Zhang, N.; Ding, S.; Zhang, J.; Xue, Y. An Overview on Restricted Boltzmann Machines. Neurocomputing 2018, 275, 1186–1199. [Google Scholar] [CrossRef]
- Liu, H. Chapter 5—Single-Point Wind Forecasting Methods Based on Reinforcement Learning. In Wind Forecasting in Railway Engineering; Liu, H., Ed.; Elsevier: Amsterdam, The Netherlands, 2021; pp. 177–214. ISBN 978-0-12-823706-9. [Google Scholar]
- Li, S.; Song, W.; Fang, L.; Chen, Y.; Ghamisi, P.; Benediktsson, J.A. Deep Learning for Hyperspectral Image Classification: An Overview. IEEE Trans. Geosci. Remote Sens. 2019, 57, 6690–6709. [Google Scholar] [CrossRef] [Green Version]
- Shen, Y.; Xiao, L.; Chen, J.; Pan, D. A Spectral-Spatial Domain-Specific Convolutional Deep Extreme Learning Machine for Supervised Hyperspectral Image Classification. IEEE Access 2019, 7, 132240–132252. [Google Scholar] [CrossRef]
- Brigato, L.; Iocchi, L. A Close Look at Deep Learning with Small Data. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 2490–2497. [Google Scholar]
- Makantasis, K.; Karantzalos, K.; Doulamis, A.; Doulamis, N. Deep Supervised Learning for Hyperspectral Data Classification through Convolutional Neural Networks. In Proceedings of the 2015 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Milan, Italy, 26–31 July 2015; pp. 4959–4962. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-Level Control through Deep Reinforcement Learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef]
- Caggiani, M.C.; Cosentino, A.; Mangone, A. Pigments Checker Version 3.0, a Handy Set for Conservation Scientists: A Free Online Raman Spectra Database. Microchem. J. 2016, 129, 123–132. [Google Scholar] [CrossRef]
- Cosentino, A. FORS Spectral Database of Historical Pigments in Different Binders. E-Conserv. J. 2014, 2, 54–65. [Google Scholar] [CrossRef]
- Blažek, J.; Soukup, J.; Zitová, B.; Flusser, J.; Hradilová, J.; Hradil, D.; Tichý, T. M3art: A Database of Models of Canvas Paintings. In Proceedings of the 7th International Conference, EuroMed 2018, Nicosia, Cyprus, October 29–November 3 2018; Springer: Cham, Switzerland, 2014; pp. 176–185. [Google Scholar]
- Barrios, D.; Vergaz, R.; Sánchez-Pena, J.M.; García-Cámara, B.; Granqvist, C.G.; Niklasson, G.A. Simulation of the Thickness Dependence of the Optical Properties of Suspended Particle Devices. Sol. Energy Mater. Sol. Cells 2015, 143, 613–622. [Google Scholar] [CrossRef]
- Vargas, W.E.; Niklasson, G.A. Reflectance of Pigmented Polymer Coatings: Comparisons between Measurements and Radiative Transfer Calculations. Appl. Opt. 2001, 40, 85–94. [Google Scholar] [CrossRef] [PubMed]
- Väisänen, T.; Markkanen, J.; Penttilä, A.; Muinonen, K. Radiative Transfer with Reciprocal Transactions: Numerical Method and Its Implementation. PLoS ONE 2019, 14, e0210155. [Google Scholar] [CrossRef] [PubMed]
- Wambugu, N.; Chen, Y.; Xiao, Z.; Tan, K.; Wei, M.; Liu, X.; Li, J. Hyperspectral Image Classification on Insufficient-Sample and Feature Learning Using Deep Neural Networks: A Review. Int. J. Appl. Earth Obs. Geoinf. 2021, 105, 102603. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Metrics Type | Formula | Ref. |
|---|---|---|
| Sensitivity | [59] | |
| Overall accuracy (OA) | ||
| Average accuracy (AA) | , M—number of classes, OAi—overall per class accuracy | [27,53,55,59] |
| Standard deviation (STD) | , N—total # of examples, 𝛍 | [27] |
| Coefficient of determination () | —sum of squared residuals —total sum of squares, – mean value | [54] |
| Root mean square error (RMSE) | [54,56,61,62] |
| Architecture | Spectral Input | Input Type * | Dataset Size (Spectra) | Task | Application | Ref. |
|---|---|---|---|---|---|---|
| SOM | XRF | III | 41,327 | Clustering | Peruvian watercolour painting (c.1860) | [51] |
| RIS (SWIR) | II, III | NA | Clustering | Excavated bronze fragments (B.C.) | [52] | |
| MLP | RIS (VNIR) | III | NA | Classification | Mural paintings (17th–20th century) | [55] |
| RIS (VNIR) | I | 143,000 | Classification | II, illuminated folio (15th century) | [56] | |
| RIS (VNIR) | I | 110,000 | Unmixing | II | [57] | |
| RIS (SWIR) | II, III | 12,000 | Unmixing | Tibetan thangka (19th century) | [58] | |
| RIS (SWIR) | II | NA | Classification | II | [27] | |
| CNN | XRF | I | 16,224 | Unmixing | II, impressionistic paintings (c.1900) | [59] |
| II | 1320 | |||||
| XRF | I | 3000 | Classification | Early Renaissance painting (1468) | [50] | |
| II | 75 | |||||
| RIS (VIS) | I | 21,240 | Classification | Late Portuguese paintings (c.1910) | [49] | |
| RIS (VNIR) | III | 16,683 | Classification | Illuminated manuscript (c.1340) | [53] | |
| ENDEC | RIS (VIS) | I | 1,445,136 | Unmixing | II | [62] |
| RIS (VIS) ** | I | 35,700 | Unmixing | II | [64] | |
| II | 213,000 | Decorated tomb murals | ||||
| II | 171,600 | Watercolours | ||||
| RIS (VNIR) | III | NA *** | Restoration | Mural paintings (c.1392) | [63] | |
| CNN, ENDEC | RIS (VNIR) | III **** | 500 public images and 41 relics images | Edge detection | Painted cultural relics | [61] |
| DBN | RIS (NIR) | III | 12,000 | Classification | Mural paintings (7th–9th century) | [54] |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, L.; Miteva, T.; Delnevo, G.; Mirri, S.; Walter, P.; de Viguerie, L.; Pouyet, E. Neural Networks for Hyperspectral Imaging of Historical Paintings: A Practical Review. Sensors 2023, 23, 2419. https://doi.org/10.3390/s23052419
Liu L, Miteva T, Delnevo G, Mirri S, Walter P, de Viguerie L, Pouyet E. Neural Networks for Hyperspectral Imaging of Historical Paintings: A Practical Review. Sensors. 2023; 23(5):2419. https://doi.org/10.3390/s23052419
Chicago/Turabian StyleLiu, Lingxi, Tsveta Miteva, Giovanni Delnevo, Silvia Mirri, Philippe Walter, Laurence de Viguerie, and Emeline Pouyet. 2023. "Neural Networks for Hyperspectral Imaging of Historical Paintings: A Practical Review" Sensors 23, no. 5: 2419. https://doi.org/10.3390/s23052419