



Diagnosis of the Pneumatic Wheel Condition Based on Vibration Analysis of the Sprung Mass in the Vehicle Self-Diagnostics System
 ,
,  ,
,
Abstract
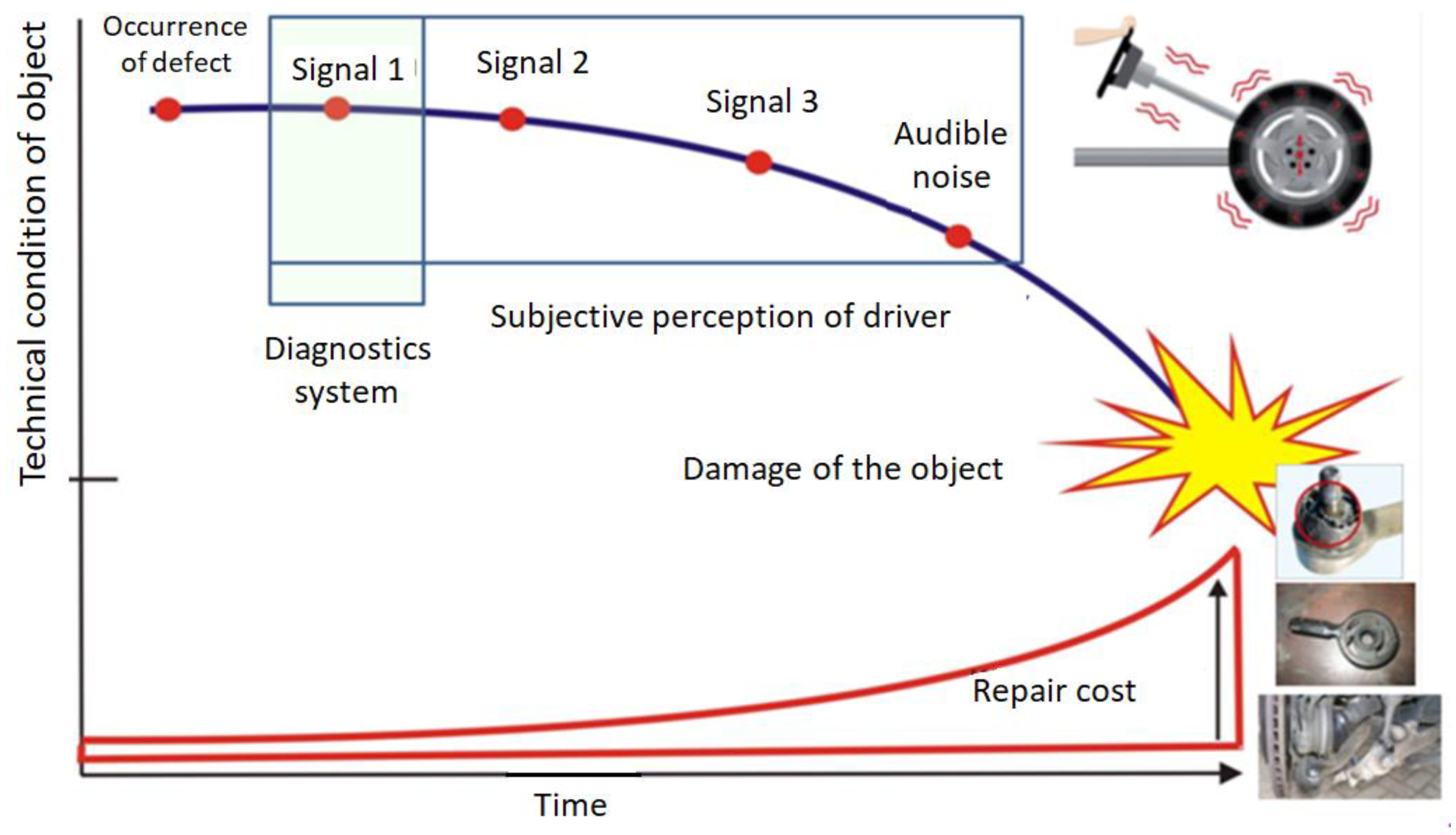
:1. Introduction
2. Related Works and Other Methods
3. Identification of the Pneumatic Wheel Condition
3.1. Research Methodology
3.2. Measurement System
3.3. The Main Concept of Experimental Measurements
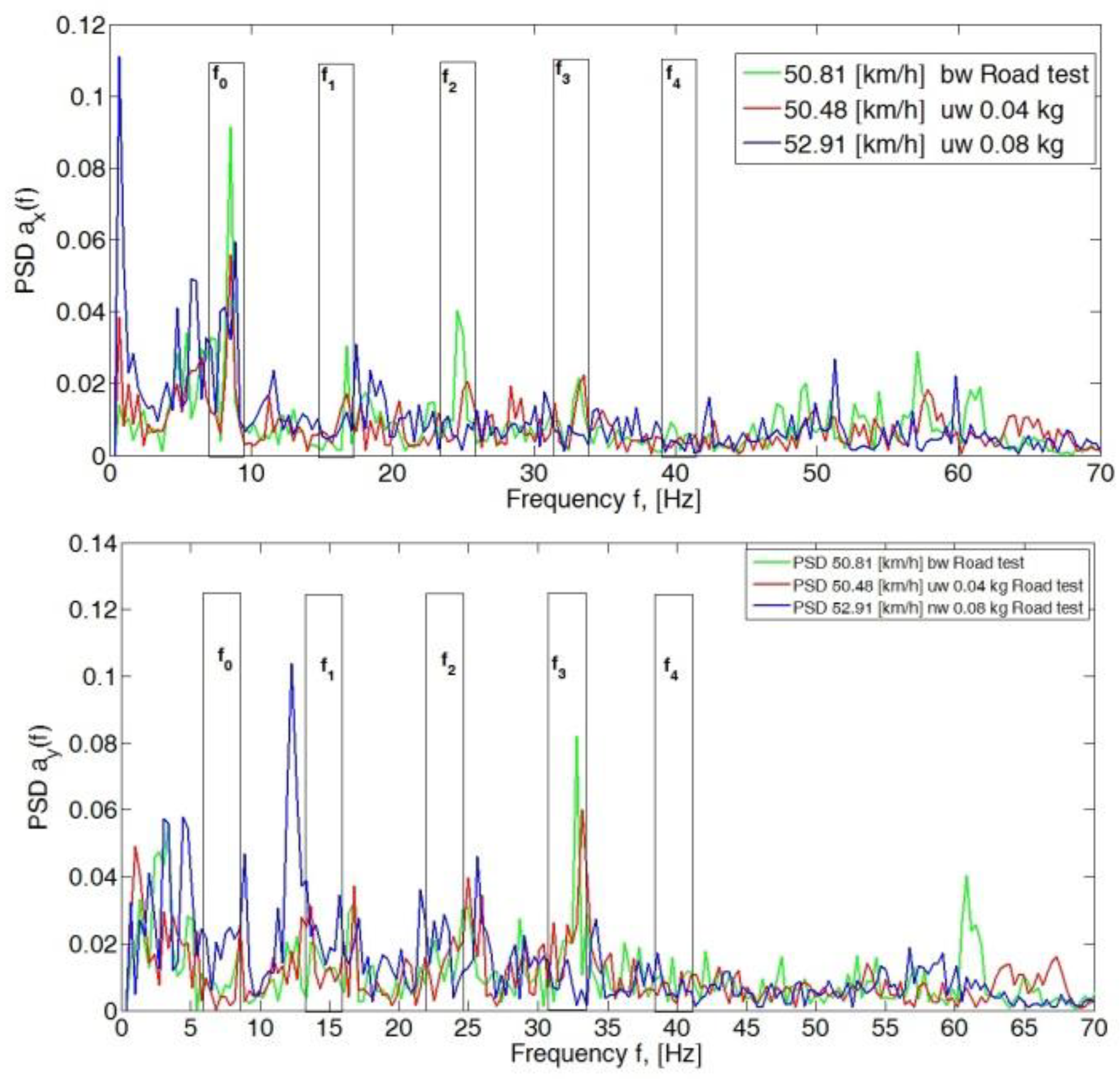
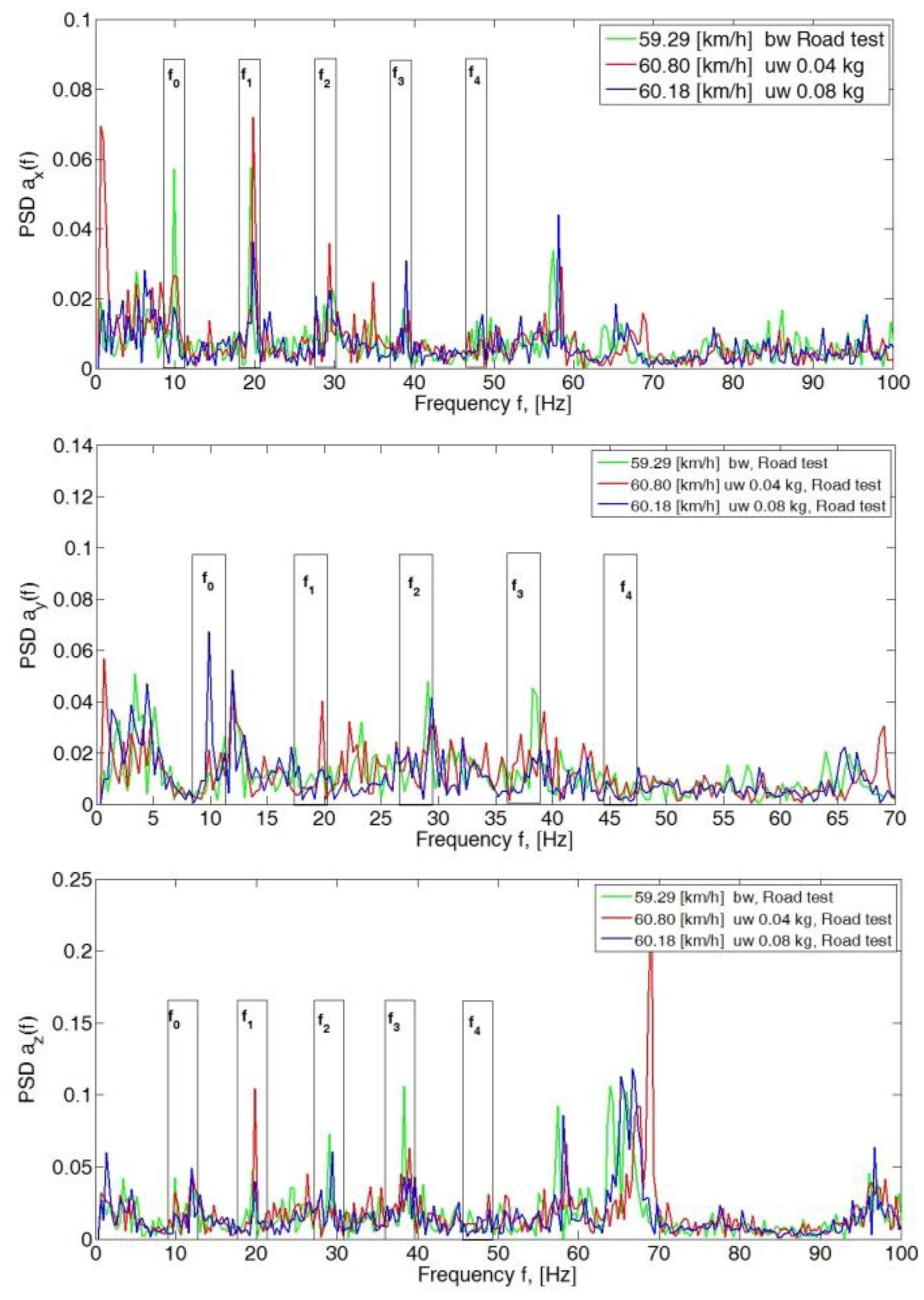
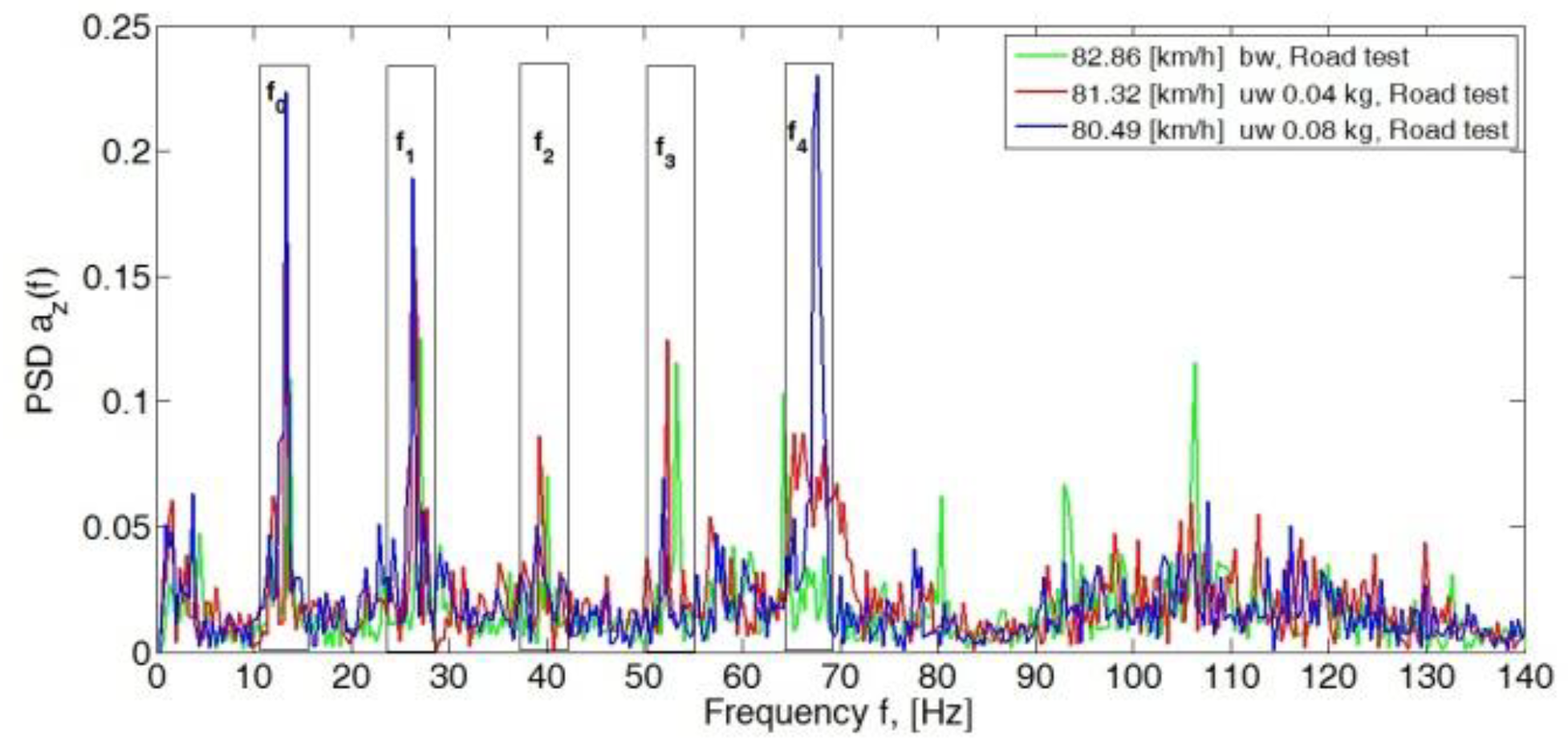
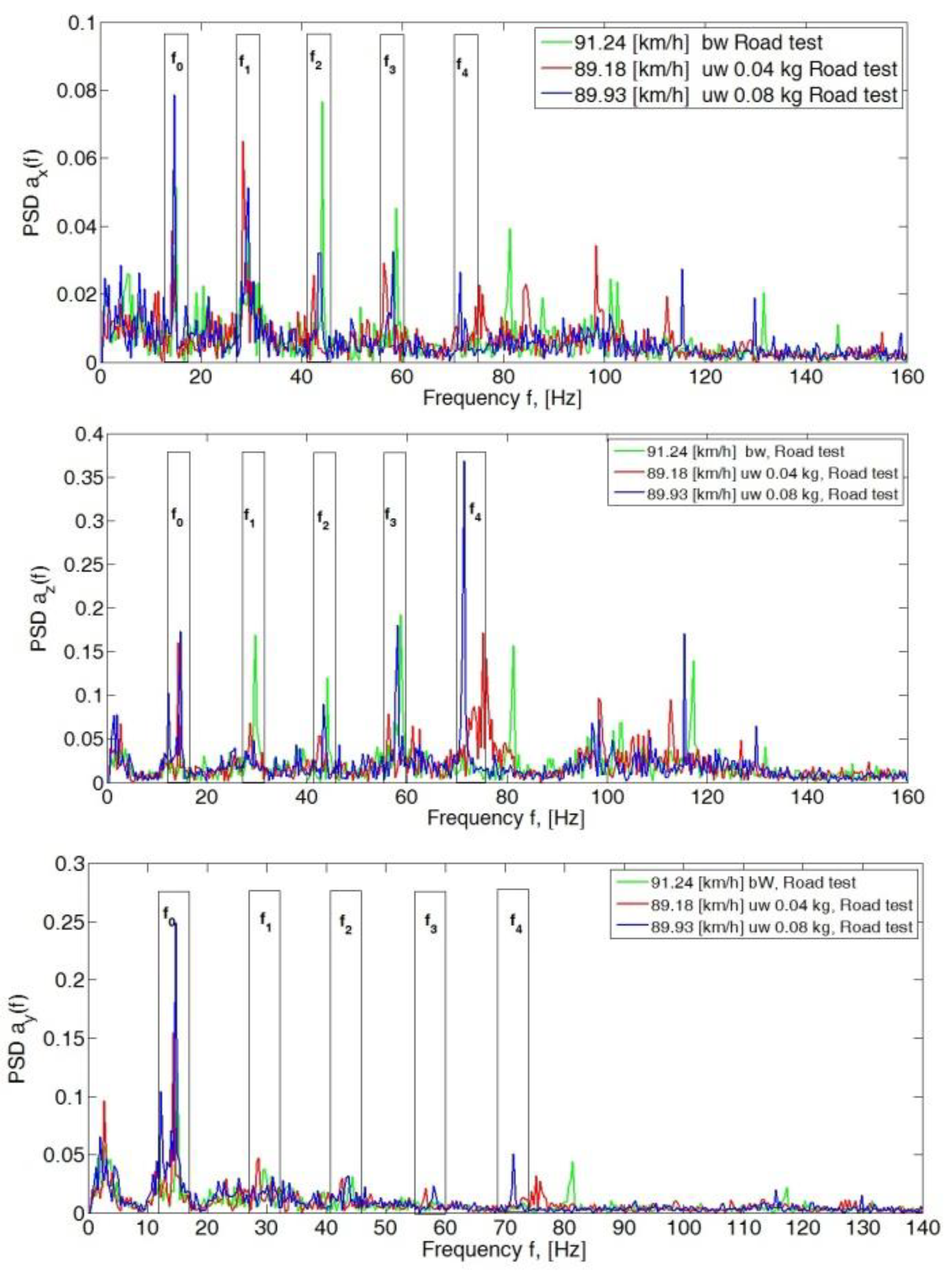
4. Analysis of the Body Vibration Signal
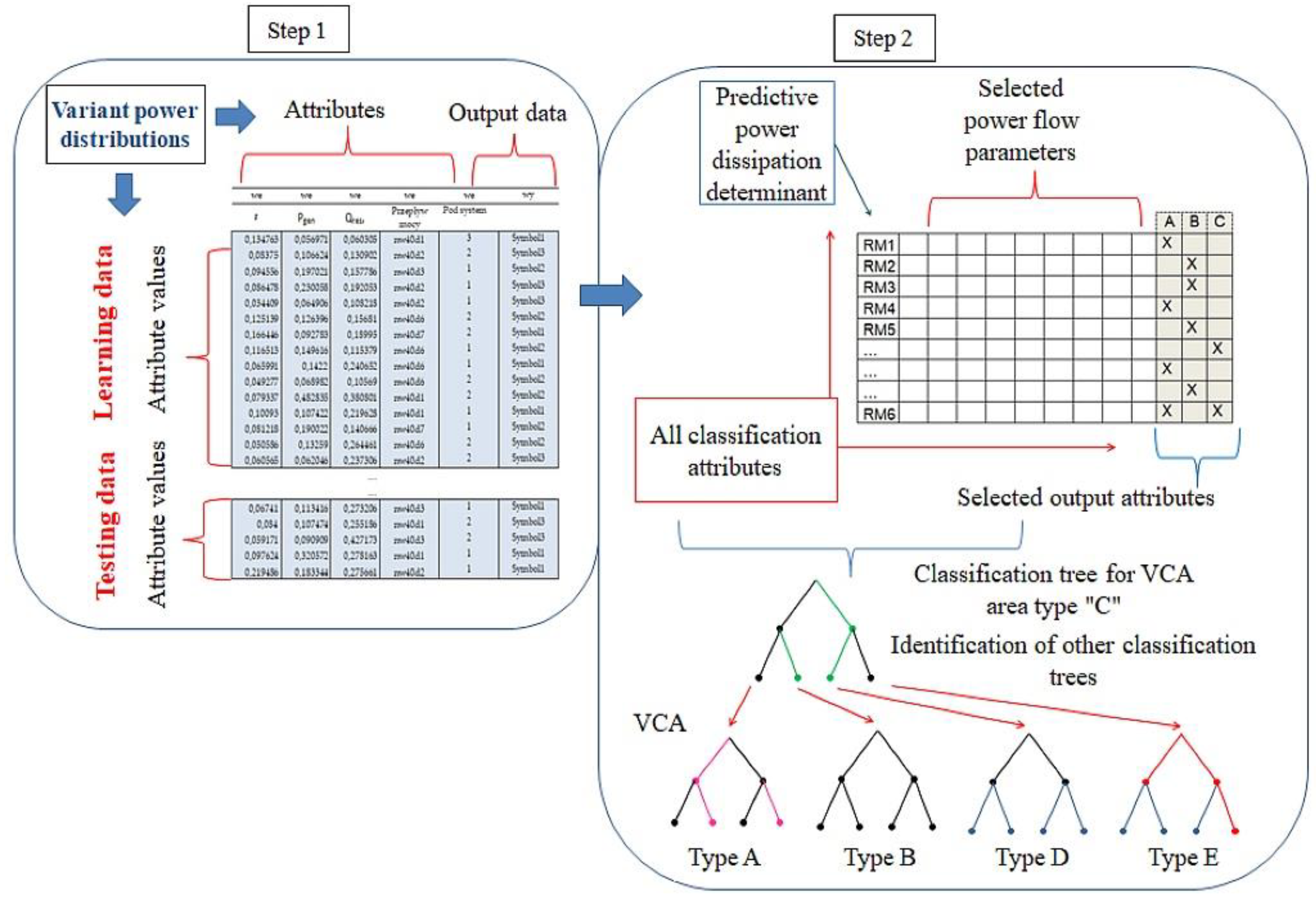
5. Application of Decision Rules to Classify Data
- -
- Functions measuring the difference between the set E (of examples) and the sets into which this set is divided according to the value of the attribute being evaluated due to the frequency distributions of the class decisions;
- -
- Functions measuring the difference between different subjects of the set E (formed by the value of the evaluated attribute) due to the frequency distributions of class decisions;
- -
- Functions measuring the statistical independence between the distribution of class decisions and the division of E into subsets.
- -
- Other reasons for choosing entropy include the following aspects:
- -
- It favors splits with fewer observations but many unique values;
- -
- In its calculation, the probability of a class is weighted by logarithm of the base two of the probability of that class.
- -
- Max_depth (i.e., blocking the maximum depth of the tree)—set to one so that the main factor is the expansion of the tree height;
- -
- Min_samples_split—using the decision tree generation option, the minimum number of examples forming the leaf of the tree was assumed to be five, and the option to trim the tree by 25% was selected (this is a hyperparameter of DecisionTreeClassifier);
- -
- Min_samples_leaf—parameter responsible for the minimum leaf size after splitting. It is very similar to the min_samples_split hyperparameter; however, it is concerned with the minimum number of observations after splitting (this is a hyperparameter of DecisionTreeClassifier).
- -
- With DecisionTreeClassifier, the following were analyzed:
- -
- Max_depth—from 1 to 12 (10 values);
- -
- Min_samples_split—from 4 to 22 (18 values);
- -
- Min_samples_leaf—from 1 to 30 (30 values);
- -
- Criterion—entropy, Gini (2 values).
6. Application of the Concept of Multi-Category Object Classification to the Diagnostics of the Pneumatic Wheel
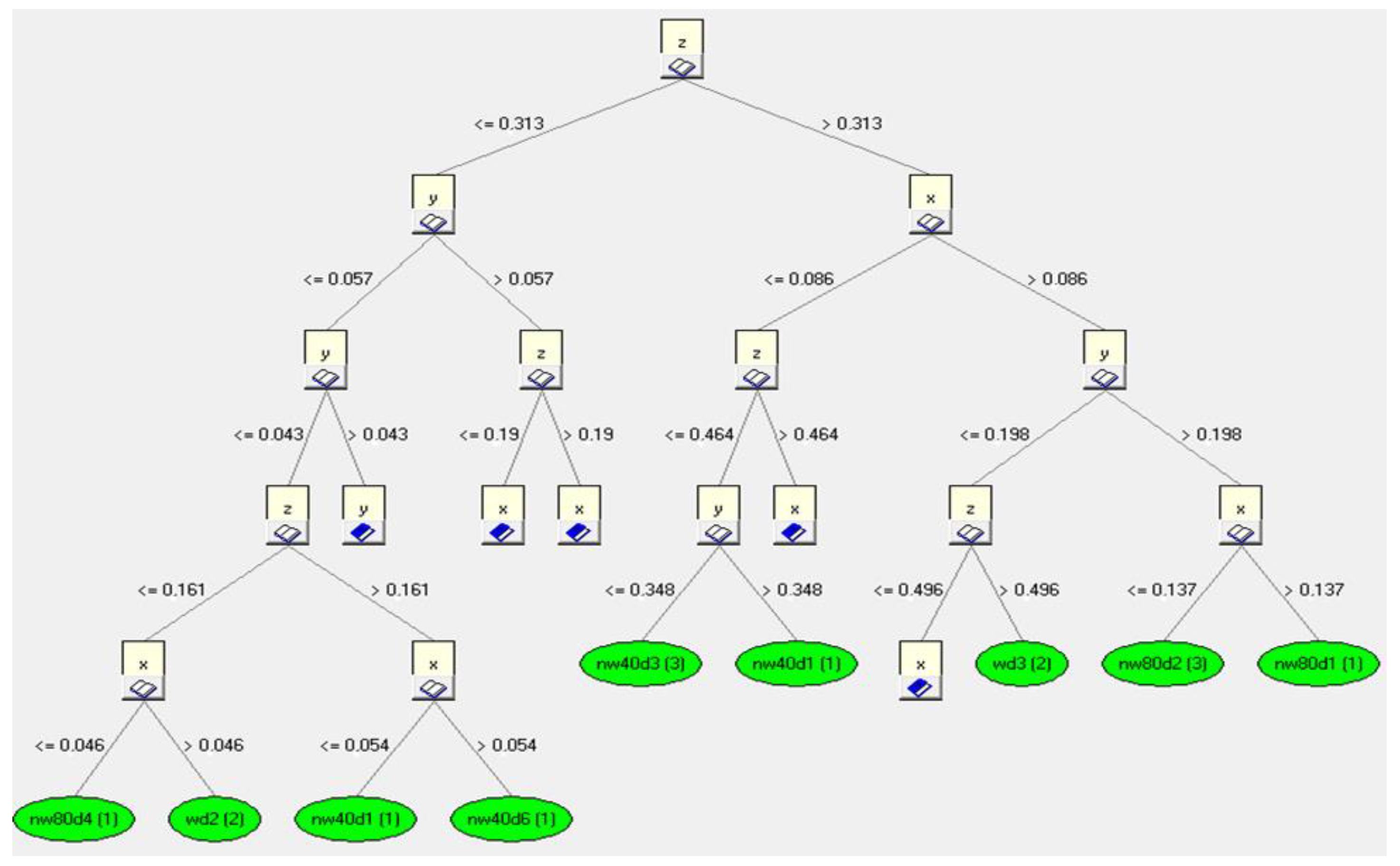
6.1. Generation of Induction Trees and Rules
6.2. Creating an Expert File
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kohavi, R.; Provost, F. Glossary of Terms. Mach. Learn. 1998, 30, 271–274. [Google Scholar] [CrossRef]
- Sankavaram, C.; Kodali, A.; Pattipati, K.R.; Singh, S. Incremental classifiers for data-driven fault diagnosis applied to automotive systems. IEEE Access 2015, 3, 407–419. [Google Scholar] [CrossRef]
- Mamala, J.; Prażnowski, K. Problems in Assessing Pneumatic Wheel Unbalance of a Passenger Car Determined with Test Road in Normal Conditions. In Proceedings of the Noise and Vibration Conference and Exhibition, Grand Rapids, MI, USA, 12–16 June 2017; SAE International: Warrendale, PA, USA, 2017. [Google Scholar]
- Smith, C.; Akujuobi, C.M.; Hamory, P.; Kloesel, K. An approach to vibration analysis using wavelets in an application of aircraft health monitoring. Mech. Syst. Signal Process. 2007, 21, 1255–1272. [Google Scholar] [CrossRef]
- Amarnath, M.; Sugumaran, V.; Kumar, H. Exploiting sound signals for fault diagnosis of bearings using decision tree. Meas. J. Int. Meas. Confed. 2013, 46, 1250–1256. [Google Scholar] [CrossRef]
- Bajaj, N.S.; Patange, A.D.; Jegadeeshwaran, R.; Kulkarni, K.A.; Ghatpande, R.S.; Kapadnis, A.M. A Bayesian Optimized Discriminant Analysis Model for Condition Monitoring of Face Milling Cutter Using Vibration Datasets. J. Nondestruct. Eval. Diagnostics Progn. Eng. Syst. 2021, 5, 021002. [Google Scholar] [CrossRef]
- Rymaniak, Ł.; Merkisz, J.; Szymlet, N.; Kamińska, M.; Weymann, S. Use of emission indicators related to co2 emissions in the ecological assessment of an agricultural tractor. Eksploat. i Niezawodn. 2021, 23, 605–611. [Google Scholar] [CrossRef]
- Dukalski, P.; Parczewski, K.; Augustynek, K. Piotr Dukalski Krzysztof Parczewski Henryk Wnęk Andrzej Urbaś Krzysztof Augustynek Dynamics of the vehicle rear suspension system with electric motors mounted in wheels Dynamika układu tylnego zawieszenia pojazdu z silnikami elektrycznymi wbudowanymi w kołach. Eksploat. i Niezawodn. 2019, 21, 125–136. [Google Scholar]
- Sun, Y.; Li, M.; Liao, C. Analysis of wheel hub motor drive application in electric vehicles. MATEC Web Conf. 2017, 100, 01004. [Google Scholar] [CrossRef] [Green Version]
- Zhu, B.; Han, J.; Zhao, J. Tire-pressure identification using intelligent tire with three-axis accelerometer. Sensors 2019, 19, 2560. [Google Scholar] [CrossRef] [Green Version]
- Burdzik, R. Implementation of multidimensional identification of signal characteristics in the analysis of vibration properties of an automotive vehicle’s floor panel|Implementacja wielowymiarowej identyfikacji charakterystycznych cech sygna?u w analizie w?asno?ci. Eksploat. i Niezawodn. 2014, 16, 458–464. [Google Scholar]
- Li, W.; Li, H.; Xu, K.; Huang, Z.; Li, K.; Du, H. Estimation of vehicle dynamic parameters based on the two-stage estimation method. Sensors 2021, 21, 3711. [Google Scholar] [CrossRef] [PubMed]
- Siegel, J.E.; Bhattacharyya, R.; Sarma, S.; Deshpande, A. Smartphone-Based Wheel Imbalance Detection. In Proceedings of the AMSE 2015 Dynamic Systems and Control Conference, Columbus, OH, USA, 28–30 October 2015; Volume 2. [Google Scholar]
- Szymański, G.M.; Josko, M.; Tomaszewski, F.; Filipiak, R. Application of time–frequency analysis to the evaluation of the condition of car suspension. Mech. Syst. Signal Process. 2015, 58–59, 298–307. [Google Scholar] [CrossRef]
- Nowakowski, T.; Komorski, P.; Szymański, G.M.; Tomaszewski, F. Wheel-flat detection on trams using envelope analysis with Hilbert transform. Lat. Am. J. Solids Struct. 2019, 16, 1–16. [Google Scholar] [CrossRef] [Green Version]
- Bi, X.; Cao, S.; Zhang, D. Diesel Engine Valve Clearance Fault Diagnosis Based on Improved Variational Mode Decomposition and Bispectrum. Energies 2019, 12, 661. [Google Scholar] [CrossRef] [Green Version]
- Donelson III, J.; Dicus, R.L. Bearing Defect Detection Using On-Board Accelerometer Measurements. In Proceedings of the ASME/IEEE Joint Rail Conference, Washington, DC, USA, 23–25 April 2002; pp. 95–102. [Google Scholar]
- Abid, F.B.; Sallem, M.; Braham, A. Optimized SWPT and Decision Tree for Incipient Bearing Fault Diagnosis. In Proceedings of the 2019 19th International Conference on Sciences and Techniques of Automatic Control and Computer Engineering (STA), Sousse, Tunisia, 24–26 March 2019; pp. 231–236. [Google Scholar]
- Nowakowski, T.; Komorski, P. Diagnostics of the drive shaft bearing based on vibrations in the high-frequency range as a part of the vehicle’s self-diagnostic system. Eksploat. i Niezawodn. 2022, 24, 70–79. [Google Scholar] [CrossRef]
- Dumitriu, M. Condition Monitoring of the Dampers in the Railway Vehicle Suspension Based on the Vibrations Response Analysis of the Bogie. Sensors 2022, 22, 3290. [Google Scholar] [CrossRef]
- Waluś, K.J.; Warszczyński, J. Analysis of the Damage Propagation Process during Actual Operation of a Truck Tire - A Case Study. SAE Int. J. Transp. Saf. 2022, 11, 9–11. [Google Scholar] [CrossRef]
- Pabarskaite, Z.; Raudys, A. A process of knowledge discovery from web log data: Systematization and critical review. J. Intell. Inf. Syst. 2007, 28, 79–104. [Google Scholar] [CrossRef]
- Gerdes, M.; Galar, D.; Scholz, D. Decision trees and the effects of feature extraction parameters for robust sensor network design. Eksploat. i Niezawodn. 2017, 19, 31–42. [Google Scholar] [CrossRef]
- Olson, D.L.; Wu, D. Predictive Data Mining Models; Springer: Singapore, 2016; ISBN 9789811025426. [Google Scholar]
- Kovalev, S.; Kolodenkova, A.; Muntyan, E. Educational Data Mining: Current Problems and Solutions. In Proceedings of the 2020 V International Conference on Information Technologies in Engineering Education, Moscow, Russia, 14–17 April 2020; pp. 1–5. [Google Scholar]
- Rudnik, K.; Deptuła, A.M. System with probabilistic fuzzy knowledge base and parametric inference operators in risk assessment of innovative projects. Expert Syst. Appl. 2015, 42, 6365–6379. [Google Scholar] [CrossRef]
- Deptuła, A.M.; Nosal, C.S. Innovator behavior questionnare as an expert selecting for technical innovation risk assaesment. Eur. Res. Stud. J. 2021, 24, 107–119. [Google Scholar] [CrossRef]
- Puri, A.; Kumar Gupta, M. Knowledge discovery from noisy imbalanced and incomplete binary class data. Expert Syst. Appl. 2021, 181, 115179. [Google Scholar] [CrossRef]
- Silver, D.; Huang, A.; Maddison, C.J.; Guez, A.; Sifre, L.; Van Den Driessche, G.; Schrittwieser, J.; Antonoglou, I.; Panneershelvam, V.; Lanctot, M.; et al. Mastering the game of Go with deep neural networks and tree search. Nature 2016, 529, 484–489. [Google Scholar] [CrossRef] [PubMed]
- Schmidhuber, J. Deep Learning in neural networks: An overview. Neural Networks 2015, 61, 85–117. [Google Scholar] [CrossRef] [Green Version]
- Prażnowski, K.; Mamala, J.; Śmieja, M.; Kupina, M. Assessment of the road surface condition with longitudinal acceleration signal of the car body. Sensors 2020, 20, 5987. [Google Scholar] [CrossRef]
- Deptuła, A. Application of Graphical Decision Structures in Design and Management Methodology. T. 3 Parameteric Graphs and Decision Multivalued Logical Trees in Planetary Gear Analysis; T. 539.; Studies and Monographs/Opole University of Technology: Opole, Poland, 2020. [Google Scholar]
- Tsipouras, M.G.; Tsouros, D.C.; Smyrlis, P.N.; Giannakeas, N.; Tzallas, A.T. Random Forests with Stochastic Induction of Decision Trees. In Proceedings of the 2018 IEEE 30th International Conference on Tools with Artificial Intelligence (ICTAI), Volos, Greece, 5–7 November 2018; pp. 527–531. [Google Scholar]
- Jin, C.; De-lin, L.; Fen-xiang, M. An improved ID3 decision tree algorithm. In Proceedings of the 2009 4th International Conference on Computer Science & Education, Nanning, China, 25–28 July 2009; pp. 127–130. [Google Scholar]
- Haruna, A.A.; Muhammad, L.J.; Yahaya, B.Z.; Garba, E.J.; Oye, N.D.; Jung, L.T. An Improved C4.5 Data Mining Driven Algorithm for the Diagnosis of Coronary Artery Disease. In Proceedings of the 2019 International Conference on Digitization (ICD), Sharjah, United Arab Emirates, 18–19 November 2019; pp. 48–52. [Google Scholar]
- Quinlan, J.R. C4.5 Programs for Machine Learning; Morgan, K., Ed.; Elsevier Science: San Mateo, CA, USA, 1992. [Google Scholar]
- Ripley, B.D. Pattern Recognition and Neural Networks; Cambridge University Press: Cambridge, UK, 1996. [Google Scholar]
- Deitz, S.J.; Chamberlain, B.L.; Snyder, L. Abstractions for dynamic data distribution. In Proceedings of the Ninth International Workshop on High-Level Parallel Programming Models and Supportive Environments, Santa Fe, NM, USA, 26 April 2004; pp. 42–51. [Google Scholar]
- Patil, S.S.; Pardeshi, S.S.; Patange, A.D. Health Monitoring of Milling Tool Inserts Using CNN Architectures Trained by Vibration Spectrograms. Comput. Model. Eng. Sci. 2023, 136, 177–199. [Google Scholar] [CrossRef]
- Patange, A.D.; Pardeshi, S.S.; Jegadeeshwaran, R.; Zarkar, A.; Verma, K. Augmentation of Decision Tree Model Through Hyper-Parameters Tuning for Monitoring of Cutting Tool Faults Based on Vibration Signatures. J. Vib. Eng. Technol. 2022. [Google Scholar] [CrossRef]
- Patange, A.D.; Jegadeeshwaran, R. A machine learning approach for vibration-based multipoint tool insert health prediction on vertical machining centre (VMC). Measurement 2021, 173, 108649. [Google Scholar] [CrossRef]
- Seekings, P.J.; Tan, J.; Potter, J.; Hoffman-Kuhnt, M.; Pack, A.A.; Herman, L.M. Denoising Dolphin Click Series in the Presence of Tonals, using Singular Spectrum Analysis and Higher Order Statistics. In Proceedings of the OCEANS 2006—Asia Pacific, Singapore, 16–19 May 2006; pp. 1–6. [Google Scholar]
- Ravizza, G.; Ferrari, R.; Rizzi, E.; Dertimanis, V. On the denoising of structural vibration response records from low-cost sensors: A critical comparison and assessment. J. Civ. Struct. Heal. Monit. 2021, 11, 1201–1224. [Google Scholar] [CrossRef]



























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Measurement range | ±5 g |
| Non-linearity | ±0.1% fs |
| In-run bias stability | ±0.04 mg |
| Initial bias error | ±0.002 g |
| Scale factor stability | ±0.05% |
| Noise density | 80 μg/√Hz |
| Data output rate | 1000 Hz |
| Speed range | 0.3–250 km/h |
| Distance resolution | 1.5 mm |
| Distance measurement deviation | <±0.1% |
| Speed linearity | <±0.2% |
| Working range linearity | <±0.2% |
| In | In | In | Out |
|---|---|---|---|
| x | y | z | Wheel Condition |
| 0.117304 | 0.103775 | 0.039480 | nw40d1 |
| 0.062202 | 0.052450 | 0.059505 | nw40d2 |
| 0.022630 | 0.024011 | 0.051509 | nw40d3 |
| 0.062550 | 0.044582 | 0.055876 | nw40d2 |
| 0.049989 | 0.014870 | 0.035145 | nw40d2 |
| 0.126599 | 0.085579 | 0.056270 | nw40d6 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Prażnowski, K.; Mamala, J.; Deptuła, A.; Deptuła, A.M.; Bieniek, A. Diagnosis of the Pneumatic Wheel Condition Based on Vibration Analysis of the Sprung Mass in the Vehicle Self-Diagnostics System. Sensors 2023, 23, 2326. https://doi.org/10.3390/s23042326
Prażnowski K, Mamala J, Deptuła A, Deptuła AM, Bieniek A. Diagnosis of the Pneumatic Wheel Condition Based on Vibration Analysis of the Sprung Mass in the Vehicle Self-Diagnostics System. Sensors. 2023; 23(4):2326. https://doi.org/10.3390/s23042326
Chicago/Turabian StylePrażnowski, Krzysztof, Jarosław Mamala, Adam Deptuła, Anna M. Deptuła, and Andrzej Bieniek. 2023. "Diagnosis of the Pneumatic Wheel Condition Based on Vibration Analysis of the Sprung Mass in the Vehicle Self-Diagnostics System" Sensors 23, no. 4: 2326. https://doi.org/10.3390/s23042326