
Precision Agriculture Using Soil Sensor Driven Machine Learning for Smart Strawberry Production


Abstract
:1. Introduction
2. Materials and Methods
2.1. Machine Learning Methods
2.1.1. Empirical Methods
2.1.2. Statistical Method
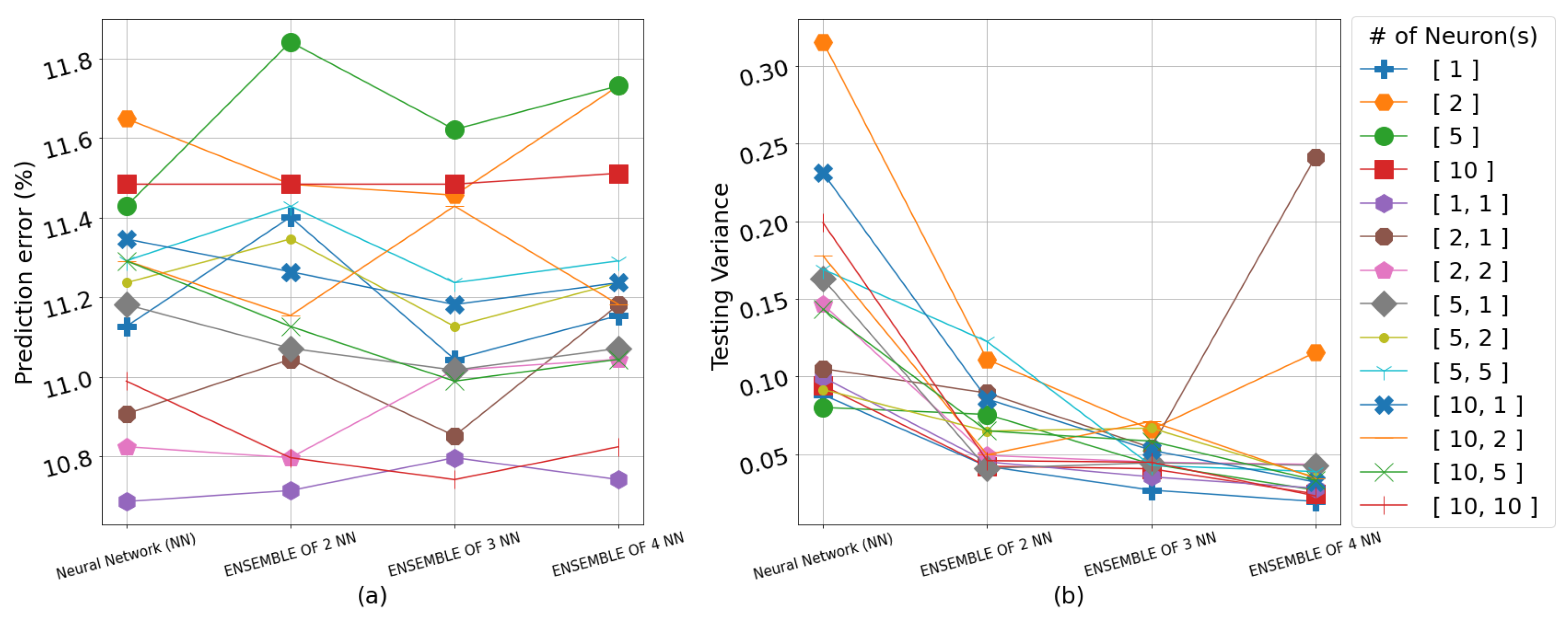
3. Results
3.1. Color
3.2. SSC and Color
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| AI | Artificial Intelligence |
| DL | Deep Learning |
| EC | Electrical Conductivity |
| ENN | Ensemble of Neural Networks |
| GPR | Gaussian Process Regression |
| KNN | K-Nearest Neighbor |
| ML | Machine Learning |
| NN | Neural Networks |
| PEP | Prediction Error Percentage |
| QA | Quality Average |
| RMSE | Root Mean Square Error |
| SSC | Soluble Solids Content |
| SVM | Support Vector Machine |
| WC | Water Content |
References
- Vuppalapati, C. Machine Learning and Artificial Intelligence for Agricultural Economics: Prognostic Data Analytics to Serve Small Scale Farmers Worldwide; International Series in Operations Research & Management Science; Springer International Publishing: Berlin/Heidelberg, Germany, 2021. [Google Scholar] [CrossRef]
- USDA. USDA Economic Research Service-Ag and Food Sectors and the Economy. 2020. Available online: https://www.ers.usda.gov (accessed on 10 February 2020).
- FAO. Food and Agriculture Organization of the United Nations. 2020. Available online: www.fao.org (accessed on 28 August 2020).
- Martínez-Ferri, E.; Soria, C.; Ariza, M.; Medina, J.; Miranda, L.; Domíguez, P.; Muriel, J. Water relations, growth and physiological response of seven strawberry cultivars (Fragaria× ananassa Duch.) to different water availability. Agric. Water Manag. 2016, 164, 73–82. [Google Scholar] [CrossRef]
- Bordonaba, J.G.; Terry, L.A. Manipulating the taste-related composition of strawberry fruits (Fragaria× ananassa) from different cultivars using deficit irrigation. Food Chem. 2010, 122, 1020–1026. [Google Scholar] [CrossRef] [Green Version]
- Klamkowski, K.; Treder, W. Morphological and physiological responses of strawberry plants to water stress. Agric. Conspec. Sci. 2006, 71, 159–165. [Google Scholar]
- Grant, O.M.; Johnson, A.W.; Davies, M.J.; James, C.M.; Simpson, D.W. Physiological and morphological diversity of cultivated strawberry (Fragaria× ananassa) in response to water deficit. Environ. Exp. Bot. 2010, 68, 264–272. [Google Scholar] [CrossRef]
- Hochmuth, G.J.; Albregts, E. Fertilization of Strawberries in Florida; University of Florida Cooperative Extension Service, Institute of Food and Agricultural Sciences: Gainesville, FL, USA, 1994. [Google Scholar]
- Hochmuth, G.J.; Cordasco, K. A Summary of N and K Research with Strawberry in Florida; University of Florida Cooperative Extension Service, Institute of Food and Agricultural Sciences: Gainesville, FL, USA, 1999. [Google Scholar]
- Wu, Y.; Li, L.; Li, M.; Zhang, M.; Sun, H.; Sigrimis, N. Optimal fertigation for high yield and fruit quality of greenhouse strawberry. PLoS ONE 2020, 15, e0224588. [Google Scholar] [CrossRef] [Green Version]
- Morillo, J.G.; Martín, M.; Camacho, E.; Díaz, J.R.; Montesinos, P. Toward precision irrigation for intensive strawberry cultivation. Agric. Water Manag. 2015, 151, 43–51. [Google Scholar] [CrossRef]
- Myers, J.M.; Locascio, S. Efficiency of irrigation methods for strawberries. In Proceedings of the Florida State Horticultural Society, Fort Lauderdale, FL, USA; 1972; Volume 85, pp. 114–117. Available online: https://journals.flvc.org/fshs/article/download/98978/94964 (accessed on 10 February 2020).
- Albregts, E.; Howard, C.; Chandler, C. Strawberry responses to K rate on a fine sand soil. HortScience 1991, 26, 135–138. [Google Scholar] [CrossRef]
- Cvelbar Weber, N.; Koron, D.; Jakopič, J.; Veberič, R.; Hudina, M.; Baša Česnik, H. Influence of nitrogen, calcium and nano-fertilizer on strawberry (Fragaria× ananassa Duch.) fruit inner and outer quality. Agronomy 2021, 11, 997. [Google Scholar] [CrossRef]
- Montero, T.M.; Mollá, E.M.; Esteban, R.M.; López-Andréu, F.J. Quality attributes of strawberry during ripening. Sci. Hortic. 1996, 65, 239–250. [Google Scholar] [CrossRef]
- Liakos, K.G.; Busato, P.; Moshou, D.; Pearson, S.; Bochtis, D. Machine learning in agriculture: A review. Sensors 2018, 18, 2674. [Google Scholar] [CrossRef] [Green Version]
- Elashmawy, R.; Yagiz, Y.; Uysal, I. A novel dataset for wireless soil monitoring of a strawberry harvest and respective evaluation of physicochemical qualities. Smart Agric. Technol. 2022, 2, 100055. [Google Scholar] [CrossRef]
- Gunness, P.; Kravchuk, O.; Nottingham, S.M.; D’Arcy, B.R.; Gidley, M.J. Sensory analysis of individual strawberry fruit and comparison with instrumental analysis. Postharvest Biol. Technol. 2009, 52, 164–172. [Google Scholar] [CrossRef]
- Han, J.; Zhang, Z.; Cao, J.; Luo, Y.; Zhang, L.; Li, Z.; Zhang, J. Prediction of Winter Wheat Yield Based on Multi-Source Data and Machine Learning in China. Remote Sens. 2020, 12, 236. [Google Scholar] [CrossRef] [Green Version]
- Kung, H.Y.; Kuo, T.H.; Chen, C.H.; Tsai, P.Y. Accuracy analysis mechanism for agriculture data using the ensemble neural network method. Sustainability 2016, 8, 735. [Google Scholar] [CrossRef] [Green Version]
- Zhang, L.; Zhang, J.; Kyei-Boahen, S.; Zhang, M. Simulation and prediction of soybean growth and development under field conditions. Am-Euras. J. Agr. Environ. Sci. 2010, 7, 374–385. [Google Scholar]
- Elashmawy, R.; Yagiz, Y.; Uysal, I. Data for: A Novel Dataset for Wireless Soil Monitoring of a Strawberry Harvest and Respective Evaluation of Physicochemical Qualities. Mendeley Repos. 2022, 2, 100055. [Google Scholar] [CrossRef]
- NWS. National Weather Service. 2019. Available online: w2.weather.gov (accessed on 8 August 2019).
- Friedman, S.P. Soil properties influencing apparent electrical conductivity: A review. Comput. Electron. Agric. 2005, 46, 45–70. [Google Scholar] [CrossRef]
- Kafkas, E.; Koşar, M.; Paydaş, S.; Kafkas, S.; Başer, K. Quality characteristics of strawberry genotypes at different maturation stages. Food Chem. 2007, 100, 1229–1236. [Google Scholar] [CrossRef]
- Risser, G.; Navatel, J. The strawberry. Part I: Planting stock and cultivars. Strawb. Part I Plant. Stock. Cultiv. 1997, 2, 103. [Google Scholar]
- Abbott, J.A. Quality measurement of fruits and vegetables. Postharvest Biol. Technol. 1999, 15, 207–225. [Google Scholar] [CrossRef]
- Yagiz, Y.; Balaban, M.O.; Kristinsson, H.G.; Welt, B.A.; Marshall, M.R. Comparison of Minolta colorimeter and machine vision system in measuring colour of irradiated Atlantic salmon. J. Sci. Food Agric. 2009, 89, 728–730. [Google Scholar] [CrossRef]
- Alavoine, F.; Crochon, M. Taste quality of strawberry. In Proceedings of the International Strawberry Symposium 265, Cesena, Italy, 22–27 May 1988; pp. 449–452. [Google Scholar] [CrossRef]
- Kallio, H.; Hakala, M.; Pelkkikangas, A.M.; Lapveteläinen, A. Sugars and acids of strawberry varieties. Eur. Food Res. Technol. 2000, 212, 81–85. [Google Scholar] [CrossRef]
- Avigdori-Avidov, H. Strawberry. In Fruit Set and Development; Monselise, S.P., Ed.; CRC Press: Boca Raton, FL, USA, 1986; pp. 419–448. [Google Scholar] [CrossRef]
- Salunkhe, D.; Desai, B. Strawberries. Postharvest Biotechnol. Fruits 1984, 1. Available online: https://agris.fao.org/agris-search/search.do?recordID=XF2015028099 (accessed on 10 February 2020).
- Ramos, P.; Prieto, F.A.; Montoya, E.; Oliveros, C.E. Automatic fruit count on coffee branches using computer vision. Comput. Electron. Agric. 2017, 137, 9–22. [Google Scholar] [CrossRef]
- Su, Y.x.; Xu, H.; Yan, L.j. Support vector machine-based open crop model (SBOCM): Case of rice production in China. Saudi J. Biol. Sci. 2017, 24, 537–547. [Google Scholar] [CrossRef]
- Pantazi, X.E.; Moshou, D.; Alexandridis, T.; Whetton, R.L.; Mouazen, A.M. Wheat yield prediction using machine learning and advanced sensing techniques. Comput. Electron. Agric. 2016, 121, 57–65. [Google Scholar] [CrossRef]
- Hansen, L.K.; Salamon, P. Neural network ensembles. IEEE Trans. Pattern Anal. Mach. Intell. 1990, 12, 993–1001. [Google Scholar] [CrossRef] [Green Version]
- Rasmussen, C.E. Gaussian processes in machine learning. In Summer School on Machine Learning; Springer: Berlin/Heidelberg, Germany, 2003; pp. 63–71. [Google Scholar] [CrossRef] [Green Version]
- Forte, D.; Ude, A.; Kos, A. Robot learning by Gaussian process regression. In Proceedings of the IEEE 19th International Workshop on Robotics in Alpe-Adria-Danube Region (RAAD 2010), Budapest, Hungary, 24–26 June 2010; pp. 303–308. [Google Scholar] [CrossRef] [Green Version]
- Moore, C.J.; Chua, A.J.; Berry, C.P.; Gair, J.R. Fast methods for training Gaussian processes on large datasets. R. Soc. Open Sci. 2016, 3, 160125. [Google Scholar] [CrossRef] [Green Version]
- Sollich, P.; Williams, C.K. Understanding gaussian process regression using the equivalent kernel. In International Workshop on Deterministic and Statistical Methods in Machine Learning; DSMML 2004; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germay, 2004; Volume 3635, pp. 211–228. [Google Scholar] [CrossRef]
- Williams, C.K.; Rasmussen, C.E. Gaussian Processes for Machine Learning; MIT Press: Cambridge, MA, USA, 2006; Volume 2. [Google Scholar]
- Li, Z.Z.; Li, L.; Shao, Z. Robust Gaussian process regression based on iterative trimming. Astron. Comput. 2021, 36, 100483. [Google Scholar] [CrossRef]
- ElMasry, G.; Wang, N.; ElSayed, A.; Ngadi, M. Hyperspectral imaging for nondestructive determination of some quality attributes for strawberry. J. Food Eng. 2007, 81, 98–107. [Google Scholar] [CrossRef]
- Sim, H.S.; Kim, D.S.; Ahn, M.G.; Ahn, S.R.; Kim, S.K. Prediction of strawberry growth and fruit yield based on environmental and growth data in a greenhouse for soil cultivation with applied autonomous facilities. Hortic. Sci. Technol. 2020, 38, 840–849. [Google Scholar] [CrossRef]
- Madhavi, B.G.K.; Basak, J.K.; Paudel, B.; Kim, N.E.; Choi, G.M.; Kim, H.T. Prediction of Strawberry Leaf Color Using RGB Mean Values Based on Soil Physicochemical Parameters Using Machine Learning Models. Agronomy 2022, 12, 981. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Raw Dataset | Pre-Processed Dataset for Analytics | |
|---|---|---|
| Number of soil sensor data points | 22,000 per sensor | 24 × 4 (WC) 24 × 8 (WC & EC) |
| Number of harvests for quality analysis | 4 | 4 |
| Number of sensors | 6 | 6 |
| Number of fruit samples analyzed per harvest | 5–15 per sensor | Averaged across the population for each sensor |
| Color Prediction Results from WC | Color Prediction Results from WC and EC | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| #Neurons | Statistical Value | Neural Network (NN) | Ensemble of 2 NN | Ensemble of 3 NN | Ensemble of 4 NN | Neural Network (NN) | Ensemble of 2 NN | Ensemble of 3 NN | Ensemble of 4 NN |
| [1] Neuron | Mean | 3.24 | 3.24 | 3.29 | 3.26 | 4.05 | 4.15 | 4.02 | 4.06 |
| Error% | 8.90%1 | 8.90%1 | 9.04% | 8.96% | 11.13% | 11.40% | 11.04% | 11.15% | |
| Variance | 0.04 | 0.011 | 0.011 | 0.011 | 0.09 | 0.04 | 0.03 | 0.02 | |
| [2] Neurons | Mean | 3.29 | 3.30 | 3.37 | 3.35 | 4.24 | 4.18 | 4.17 | 4.27 |
| Error% | 9.04% | 9.07% | 9.26% | 9.20% | 11.65% | 11.48% | 11.46% | 11.73% | |
| Variance | 0.05 | 0.02 | 0.04 | 0.24 | 0.322 | 0.11 | 0.07 | 0.12 | |
| [5] Neurons | Mean | 3.43 | 3.38 | 3.51 | 3.43 | 4.16 | 4.31 | 4.23 | 4.27 |
| Error% | 9.42% | 9.29% | 9.64% | 9.42% | 11.43% | 11.84%2 | 11.62% | 11.73% | |
| Variance | 0.08 | 0.05 | 0.02 | 0.29 | 0.08 | 0.08 | 0.04 | 0.03 | |
| [10] Neurons | Mean | 3.49 | 3.51 | 3.52 | 3.56 | 4.18 | 4.18 | 4.18 | 4.19 |
| Error% | 9.59% | 9.64% | 9.67% | 9.78% | 11.48% | 11.48% | 11.48% | 11.51% | |
| Variance | 0.08 | 0.06 | 0.05 | 0.25 | 0.09 | 0.04 | 0.04 | 0.02 | |
| [1, 1] Neurons | Mean | 3.28 | 3.29 | 3.28 | 3.29 | 3.89 | 3.9 | 3.93 | 3.91 |
| Error% | 9.01% | 9.04% | 9.01% | 9.04% | 10.69% | 10.71% | 10.80% | 10.74% | |
| Variance | 0.03 | 0.02 | 0.011 | 0.011 | 0.10 | 0.04 | 0.04 | 0.03 | |
| [2, 1] Neurons | Mean | 3.28 | 3.27 | 3.30 | 3.25 | 3.97 | 4.02 | 3.95 | 4.07 |
| Error% | 9.01% | 8.98% | 9.07% | 8.93% | 10.91% | 11.04% | 10.85% | 11.18% | |
| Variance | 0.06 | 0.04 | 0.03 | 0.02 | 0.10 | 0.09 | 0.05 | 0.24 | |
| [2, 2] Neurons | Mean | 3.32 | 3.38 | 3.36 | 3.34 | 3.94 | 3.93 | 4.01 | 4.02 |
| Error% | 9.12% | 9.29% | 9.23% | 9.18% | 10.82% | 10.80% | 11.02% | 11.04% | |
| Variance | 0.08 | 0.06 | 0.02 | 0.02 | 0.15 | 0.05 | 0.04 | 0.04 | |
| [5, 1] Neurons | Mean | 3.46 | 3.33 | 3.35 | 3.36 | 4.07 | 4.03 | 4.01 | 4.03 |
| Error% | 9.51% | 9.15% | 9.20% | 9.23% | 11.18% | 11.07% | 11.02% | 11.07% | |
| Variance | 0.09 | 0.04 | 0.24 | 0.03 | 0.16 | 0.04 | 0.04 | 0.04 | |
| [5, 2] Neurons | Mean | 3.39 | 3.52 | 3.45 | 3.43 | 4.09 | 4.13 | 4.05 | 4.09 |
| Error% | 9.31% | 9.67% | 9.48% | 9.42% | 11.24% | 11.35% | 11.13% | 11.24% | |
| Variance | 0.12 | 0.08 | 0.27 | 0.03 | 0.09 | 0.06 | 0.07 | 0.04 | |
| [5, 5] Neurons | Mean | 3.49 | 3.49 | 3.52 | 3.54 | 4.11 | 4.16 | 4.09 | 4.11 |
| Error% | 9.59% | 9.59% | 9.67% | 9.73% | 11.29% | 11.43% | 11.24% | 11.29% | |
| Variance | 0.08 | 0.04 | 0.28 | 0.02 | 0.17 | 0.12 | 0.04 | 0.04 | |
| [10, 1] Neurons | Mean | 3.40 | 3.46 | 3.42 | 3.47 | 4.13 | 4.1 | 4.07 | 4.09 |
| Error% | 9.34% | 9.51% | 9.40% | 9.53% | 11.35% | 11.26% | 11.18% | 11.24% | |
| Variance | 0.07 | 0.06 | 0.27 | 0.02 | 0.23 | 0.09 | 0.05 | 0.03 | |
| [10, 2] Neurons | Mean | 3.51 | 3.48 | 3.52 | 3.51 | 4.11 | 4.06 | 4.16 | 4.07 |
| Error% | 9.64% | 9.56% | 9.67% | 9.64% | 11.29% | 11.15% | 11.43% | 11.18% | |
| Variance | 0.11 | 0.04 | 0.28 | 0.02 | 0.18 | 0.05 | 0.07 | 0.03 | |
| [10, 5] Neurons | Mean | 3.55 | 3.57 | 3.54 | 3.60 | 4.11 | 4.05 | 4 | 4.02 |
| Error% | 9.75% | 9.81% | 9.73% | 9.89% | 11.29% | 11.13% | 10.99% | 11.04% | |
| Variance | 0.06 | 0.04 | 0.04 | 0.05 | 0.14 | 0.06 | 0.06 | 0.03 | |
| [10, 10] Neurons | Mean | 3.54 | 3.52 | 3.44 | 3.45 | 4 | 3.93 | 3.91 | 3.94 |
| Error% | 9.73% | 9.67% | 9.45% | 9.48% | 10.99% | 10.80% | 10.74% | 10.82% | |
| Variance | 0.08 | 0.05 | 0.03 | 0.03 | 0.20 | 0.05 | 0.04 | 0.02 | |
| Color and SSC Prediction Results from WC | Color and SSC Prediction Results from WC and EC | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| #Neurons | Statistical Value | Neural Network (NN) | Ensemble of 2 NN | Ensemble of 3 NN | Ensemble of 4 NN | Neural Network (NN) | Ensemble of 2 NN | Ensemble of 3 NN | Ensemble of 4 NN |
| [1] Neuron | Mean | 2.61 | 2.63 | 2.61 | 2.57 | 3.09 | 3.09 | 3.08 | 3.09 |
| Error% | 16.33% | 16.36% | 16.40% | 16.39% | 18.51% | 18.51% | 18.44% | 18.52% | |
| Variance | 0.02 | 0.011 | 0.14 | 0.011 | 0.03 | 0.02 | 0.011 | 0.011 | |
| [2] Neurons | Mean | 2.65 | 2.59 | 2.64 | 2.62 | 3.24 | 3.18 | 3.19 | 3.28 |
| Error% | 15.16% | 15.35% | 15.37% | 15.31% | 19.04%2 | 18.77% | 18.73% | 19.02% | |
| Variance | 0.03 | 0.011 | 0.15 | 0.011 | 0.12 | 0.04 | 0.07 | 0.192 | |
| [5] Neurons | Mean | 2.64 | 2.62 | 2.63 | 2.65 | 3.04 | 3.05 | 3.08 | 3.06 |
| Error% | 14.40% | 14.33% | 14.42% | 14.31% | 17.94% | 17.76% | 18.04% | 17.87% | |
| Variance | 0.03 | 0.011 | 0.16 | 0.011 | 0.05 | 0.02 | 0.02 | 0.011 | |
| [10] Neurons | Mean | 2.611 | 2.6 | 2.61 | 2.62 | 2.98 | 3.01 | 3 | 3.01 |
| Error% | 14.04%1 | 14.11% | 14.13% | 14.16% | 17.54% | 17.54% | 17.67% | 17.53% | |
| Variance | 0.03 | 0.03 | 0.15 | 0.011 | 0.05 | 0.011 | 0.011 | 0.011 | |
| [1, 1] Neurons | Mean | 2.61 | 2.62 | 2.59 | 2.59 | 3.02 | 3 | 3.02 | 3.04 |
| Error% | 16.35% | 16.49% | 16.45% | 16.49% | 17.97% | 17.92% | 17.90% | 18.00% | |
| Variance | 0.02 | 0.011 | 0.011 | 0.011 | 0.04 | 0.02 | 0.02 | 0.011 | |
| [2, 1] Neurons | Mean | 2.64 | 2.62 | 2.61 | 2.62 | 3.03 | 2.99 | 2.99 | 3 |
| Error% | 16.37% | 16.39% | 16.35% | 16.53% | 17.94% | 17.93% | 17.89% | 18.00% | |
| Variance | 0.02 | 0.011 | 0.011 | 0.011 | 0.06 | 0.02 | 0.02 | 0.011 | |
| [2, 2] Neurons | Mean | 2.62 | 2.68 | 2.64 | 2.64 | 2.99 | 3 | 3.01 | 3.02 |
| Error% | 16.15% | 16.07% | 15.98% | 15.87% | 17.97% | 17.93% | 17.98% | 17.99% | |
| Variance | 0.03 | 0.02 | 0.15 | 0.011 | 0.07 | 0.05 | 0.03 | 0.02 | |
| [5, 1] Neurons | Mean | 2.7 | 2.71 | 2.73 | 2.69 | 3.01 | 3.04 | 3.01 | 3.01 |
| Error% | 16.63% | 16.33% | 16.57% | 15.84% | 18.06% | 18.15% | 18.04% | 18.13% | |
| Variance | 0.04 | 0.02 | 0.02 | 0.02 | 0.05 | 0.04 | 0.011 | 0.02 | |
| [5, 2] Neurons | Mean | 2.77 | 2.77 | 2.78 | 2.75 | 3.08 | 3.07 | 3.04 | 3.05 |
| Error% | 15.81% | 15.93% | 15.72% | 15.41% | 18.24% | 18.26% | 18.01% | 18.11% | |
| Variance | 0.08 | 0.04 | 0.03 | 0.03 | 0.08 | 0.03 | 0.04 | 0.02 | |
| [5, 5] Neurons | Mean | 2.77 | 2.78 | 2.78 | 2.77 | 3.06 | 3.11 | 3.1 | 3.07 |
| Error% | 15.32% | 15.52% | 15.56% | 15.41% | 18.30% | 18.20% | 18.34% | 18.18% | |
| Variance | 0.05 | 0.03 | 0.04 | 0.011 | 0.08 | 0.05 | 0.03 | 0.02 | |
| [10, 1] Neurons | Mean | 2.71 | 2.72 | 2.7 | 2.7 | 3.05 | 3 | 3.02 | 2.98 |
| Error% | 16.63% | 16.52% | 16.47% | 16.40% | 18.23% | 17.98% | 18.07% | 17.96% | |
| Variance | 0.07 | 0.02 | 0.02 | 0.011 | 0.06 | 0.02 | 0.011 | 0.011 | |
| [10, 2] Neurons | Mean | 2.85 | 2.79 | 2.79 | 2.81 | 3.13 | 3.02 | 3.12 | 3.1 |
| Error% | 15.90% | 15.80% | 15.95% | 15.84% | 18.33% | 17.90% | 18.33% | 18.21% | |
| Variance | 0.04 | 0.05 | 0.03 | 0.02 | 0.09 | 0.03 | 0.08 | 0.02 | |
| [10, 5] Neurons | Mean | 2.74 | 2.76 | 2.77 | 2.76 | 3.08 | 3.06 | 3.1 | 3.14 |
| Error% | 14.97% | 15.18% | 15.33% | 15.04% | 18.05% | 18.26% | 18.17% | 18.28% | |
| Variance | 0.05 | 0.04 | 0.03 | 0.011 | 0.05 | 0.04 | 0.03 | 0.03 | |
| [10, 10] Neurons | Mean | 2.69 | 2.71 | 2.69 | 2.67 | 3.1 | 3.12 | 3.06 | 3.04 |
| Error% | 14.44% | 14.51% | 14.59% | 14.49% | 18.12% | 18.26% | 17.94% | 17.89% | |
| Variance | 0.04 | 0.03 | 0.02 | 0.02 | 0.08 | 0.05 | 0.02 | 0.011 | |
| Color Prediction from WC | Color Prediction from EC and WC | Color and SSC Prediction from WC | Color and SSC Prediction from WC and EC | |
|---|---|---|---|---|
| Mean | 3.55 | 4.09 | 2.59 | 3.05 |
| Error% | 9.75% | 11.25% | 21.15% | 25.79% |
| Variance | 4.43 | 5.1 | 1.95 | 2.49 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Elashmawy, R.; Uysal, I. Precision Agriculture Using Soil Sensor Driven Machine Learning for Smart Strawberry Production. Sensors 2023, 23, 2247. https://doi.org/10.3390/s23042247
Elashmawy R, Uysal I. Precision Agriculture Using Soil Sensor Driven Machine Learning for Smart Strawberry Production. Sensors. 2023; 23(4):2247. https://doi.org/10.3390/s23042247
Chicago/Turabian StyleElashmawy, Rania, and Ismail Uysal. 2023. "Precision Agriculture Using Soil Sensor Driven Machine Learning for Smart Strawberry Production" Sensors 23, no. 4: 2247. https://doi.org/10.3390/s23042247