This section first provides a basic overview of GAN, and then briefly introduces various previous studies on sound classification.
2.1. Overview of GAN
GAN is a data generation model based on the ideas of game theory [
6], which can generate realistic virtual data as output by learning the distribution of real data. GAN consists of generator and discriminator. The goal of the generator is to generate virtual data that resemble real data to deceive the discriminator into determining the generated data as real data. The discriminator incorporates both the virtual data of the generator and the real data as inputs and determines whether the input data are real or not. Because of these conflicting goals, both networks are competitively trained simultaneously; this process can be expressed by Equation (1).
Here, x and z refer to the data taken from the real data distribution pr and the latent variable obtained from the latent distribution pz, respectively; G(z) is the virtual data obtained from the generator, which utilizes z as an input; and D is the function of the discriminator that outputs 1 or 0, when the given data are real or fake, respectively. The generator aims to maximize the function V(D, G) such that D(G(z)) becomes 1, while the discriminator aims to minimize V(D, G) so that D(G(z)) becomes 0. Because of such conflicting objectives, it is difficult for the generator and discriminator to achieve their own goals. However, at the end of the training of the GAN, the generator can generate realistic virtual data that cannot be distinguished by the discriminator.
2.2. Data Augmentation for Sound Classification
In recent years, deep learning technology has shown remarkable progress in various fields. For instance, CNN-based models performed well in the ASC task due to their capabilities such as feature extraction for sound classification, complex pattern recognition, and robustness to noise. Specifically, Nanni et al. [
11] proposed an ensemble model of CNNs such as AlexNet, GoogleNet, and ResNet for automated animal audio classification. They first converted the animal sound waveform into various visual features such as spectrograms and harmonic images, and then constructed CNN-based ensemble models using these different visual features. Through extensive experiments on several animal audio datasets, they demonstrated that an ensemble model composed of CNNs can perform robust and generalizable audio classification. In order to utilize more diverse features, multi-stream-based techniques have been proposed, where different types of data such as visual features and acoustic features are used together as inputs. For instance, Wu et al. [
12] proposed a dual attention matching method to classify and localize the category of video segments composed of visual and audio data. This method combines related features of images and waveforms using an attention mechanism. They showed that their method outperforms other multi-stream methods in classification and localization problems, such as the audio-visual event localization task. In a similar context, Xie et al. [
13] presented a CNN-based ASC scheme that utilizes both waveforms and mel-spectrograms together. Based on the sensitivity of one-dimensional (1D)-CNN depending on a waveform to background noise and class imbalance, they investigated various combinations of three CNN architectures and four loss functions. Then, they showed that a combination of 1D-2D-CNN and focal loss, which fuses waveform and spectrogram features, is most effective for classifying both Australian and Brazilian frog calls.
To achieve good classification performance, CNN-based deep learning models require a large amount of high-quality animal sound data for training. However, constructing a large-scale sound dataset for rare animals is quite challenging as collecting sound data from these animals in real life is time-consuming and costly. This limitation can be mitigated via various sound data augmentation methods [
14], which can be largely divided into two types: waveform augmentation and spectrogram augmentation. For waveform augmentation, methods such as pitch shifting, time stretching, and noise addition are commonly used to increase the frequency or temporal diversity of sound data [
5]. For example, pitch shifting raises or lowers the pitch of a sound waveform by a preset range. Similarly, time stretching increases or decreases the speed of a waveform by a preset value. Noise addition mixes the target waveform with various types of noise, such as white noise or background noise [
15]. Mushtaq and Su [
16] used these waveform augmentation methods to train a CNN model for classifying environmental sounds such as dog barking and drilling. They showed that augmented sound data can significantly improve classification accuracy by preventing the CNN model from overfitting small amounts of training data. Meanwhile, spectrogram augmentation was suggested more recently for sound data augmentation. For instance, Park et al. [
17] introduced frequency and time masking methods, motivated by the idea that deep networks should be robust against a partial loss of frequency or time information. These two methods remove the spectrum information by randomly masking the frequency rows or time columns, respectively, from the spectrogram. They demonstrated that their augmentation methods could significantly improve the accuracy of human speech recognition. Nanni et al. [
5] performed extensive experiments on bird and cat sound datasets and found that most waveform and spectrogram data augmentation methods are beneficial for training CNN models, although some augmentation methods are useless or even degrade ASC performance. This indicates that the characteristics of the domain data should be considered when selecting an augmentation method and determining its transformation parameters.
Due to the limited availability of traditional augmentation methods, GAN-based models have attracted considerable attention as data augmentation tools in the signal data domain. For instance, Esmaeilpour et al. [
18] suggested a weighted cycle-consistent GAN (WCCGAN) for spectrogram augmentation. Their method transfers the structural features of source spectrogram to target spectrogram, generating deformed data. They showed that the accuracy of two classifiers trained with augmented data by WCCGAN improved significantly on four environmental sound datasets. Madhu and Suresh [
19] developed an unconditional GAN-based augmentation model by adding two layers and one stable loss function to WaveGAN [
20] to generate longer virtual waveforms suitable for representing environmental sounds. However, this approach requires a class-specific generative model to generate class-specific data properly in a multi-class environment. Consequently, as the number of sound classes increases, the time and effort required for model construction also increase.
This problem can be addressed by using conditional GANs that generate multiple class data within one unified model. For instance, Jayalakshmy et al. [
21] used a conditional GAN for respiratory waveform augmentation. They combined a 1D GAN with a standard conditional GAN (cGAN) [
22], whose generator and discriminator receive conditions via embedding layers and concatenation operations. Similarly, Seibold et al. [
23] proposed a data augmentation scheme based on the conditional Wasserstein GAN with gradient penalty (WGAN-GP) [
24] for clinical audio classification. This scheme generated log-mel spectrograms as input to a ResNet-based classifier and achieved better classification performance compared to other classic signal augmentation methods. Shao et al. [
25] suggested an auxiliary classifier GAN (ACGAN) [
26] for data augmentation to diagnose machine faults. To generate class-wise sensor data, they used the work type as a class condition for training the ACGAN. Through experiments, they showed that the ACGAN-based augmentation strategy can effectively compensate for imbalanced datasets and generate convincing sensor signal data.
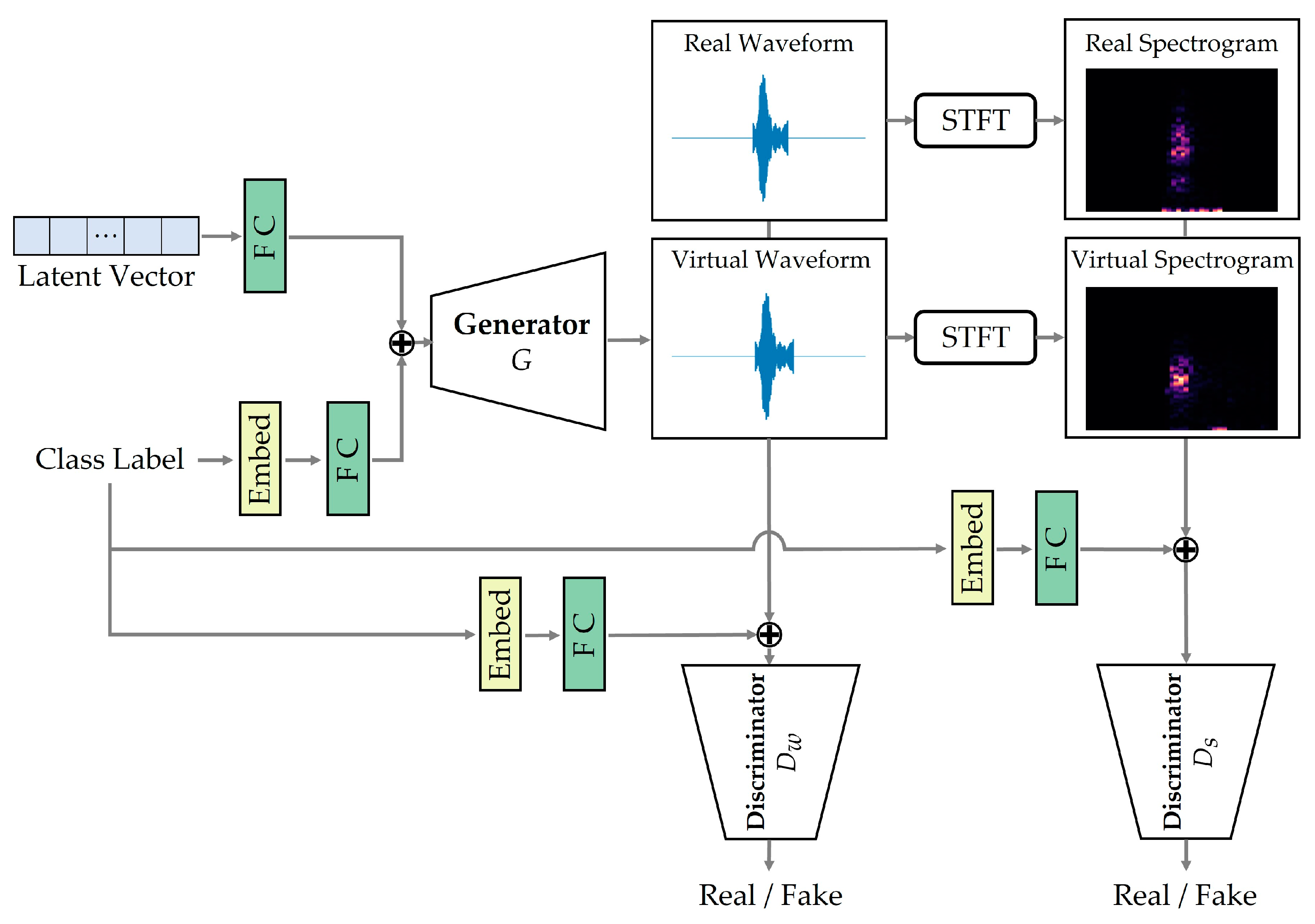
However, these cGAN-based approaches use a single discriminator that verifies the realness of virtual data in only one of the waveform and spectrogram [
9,
10]. This restricts the learning of discriminative features of different classes of sounds, making it difficult to reproduce some animal sounds with subtle differences. Furthermore, they cannot handle the case where virtual data with ambiguous characteristics is generated due to the influence of environmental noise included in real data. To overcome these limitations, we propose two discriminators to simultaneously process the waveforms and spectrograms of real animal sounds and a data selection technique to filter out ambiguous virtual animal sounds.







{kind=link}
{kind=link}
{kind=link}