Author Contributions
Conceptualization, A.Z.S., A.B. and A.T.-A.; dataset collecting, C.A.C. and L.D.; data annotation, A.Z.S. and C.A.C. software, A.Z.S., A.B. and A.T.-A.; validation, A.B., A.T.-A. and C.A.C.; formal analysis, A.B. and A.S.; investigation, A.T.-A. and A.B.; writing—review and editing, A.T.-A., C.A.C. and Y.E.H.; visualization, A.Z.S., A.B. and A.T.-A.; supervision, A.T.-A.; project administration, A.B. All authors have read and agreed to the published version of the manuscript.
Figure 1.
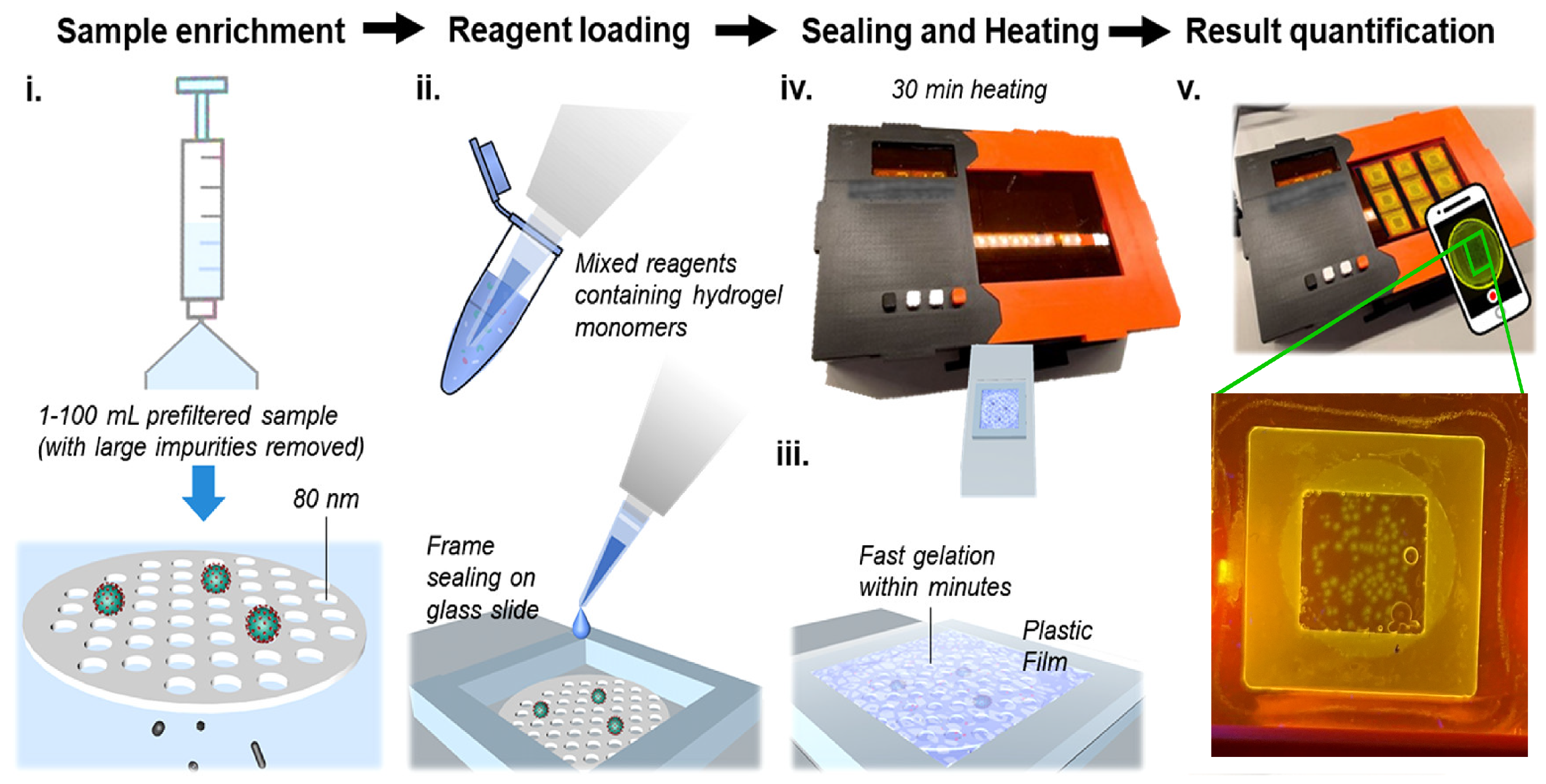
Data retriving process from the mgLAMP (i) Filtration. (ii) Reagent loading. (iii) Sealing. (iv) Incubation. (v) Imaging.
Figure 1.
Data retriving process from the mgLAMP (i) Filtration. (ii) Reagent loading. (iii) Sealing. (iv) Incubation. (v) Imaging.
Figure 2.
General structure of the proposed approach.
Figure 2.
General structure of the proposed approach.
Figure 3.
YOLOv5 version 6.1 (A): the overall architecture that consists of three main parts: the backbone, the neck, and the head modules. (B,C) two distinct types of CSP blocks (C3). In (D), a key block called CBS is defined, which consists of a Conv layer, a BN layer, and a SILU This CBS block is used in many other blocks (E) and two different botllneck blocks (F).
Figure 3.
YOLOv5 version 6.1 (A): the overall architecture that consists of three main parts: the backbone, the neck, and the head modules. (B,C) two distinct types of CSP blocks (C3). In (D), a key block called CBS is defined, which consists of a Conv layer, a BN layer, and a SILU This CBS block is used in many other blocks (E) and two different botllneck blocks (F).
Figure 4.
Hough transform converts the Cartesian representation of points in image (A) to polar coordinates, as shown in (B). By identifying clusters of points with similar polar coordinates, this transformation allows for the detection of lines in the image according to specified parameters.
Figure 4.
Hough transform converts the Cartesian representation of points in image (A) to polar coordinates, as shown in (B). By identifying clusters of points with similar polar coordinates, this transformation allows for the detection of lines in the image according to specified parameters.
Figure 5.
Steps of reprocessing: (A) rotated image, (B) zoomed image, (C) image after applying Canny edge detection, (D,E) intersection points identified using the Hough transform, (F,G) point selected for cropping the image, (H) cropped image.
Figure 5.
Steps of reprocessing: (A) rotated image, (B) zoomed image, (C) image after applying Canny edge detection, (D,E) intersection points identified using the Hough transform, (F,G) point selected for cropping the image, (H) cropped image.
Figure 6.
(a) YOLOv5 version 5.0 architecture, which consists of three main parts: the backbone, the neck, and the head. (b) YOLOv5 version 6.1 (A): the overall architecture that consists of three main parts: the backbone, the neck, and the head modules. (B,C) Two distinct types of CSP blocks (C3). In (D), a key block called CBS is defined, which consists of a Conv layer, a BN layer, and a SILU. This CBS block is used in many other blocks (E) and two different bottleneck blocks (F).
Figure 6.
(a) YOLOv5 version 5.0 architecture, which consists of three main parts: the backbone, the neck, and the head. (b) YOLOv5 version 6.1 (A): the overall architecture that consists of three main parts: the backbone, the neck, and the head modules. (B,C) Two distinct types of CSP blocks (C3). In (D), a key block called CBS is defined, which consists of a Conv layer, a BN layer, and a SILU. This CBS block is used in many other blocks (E) and two different bottleneck blocks (F).
Figure 7.
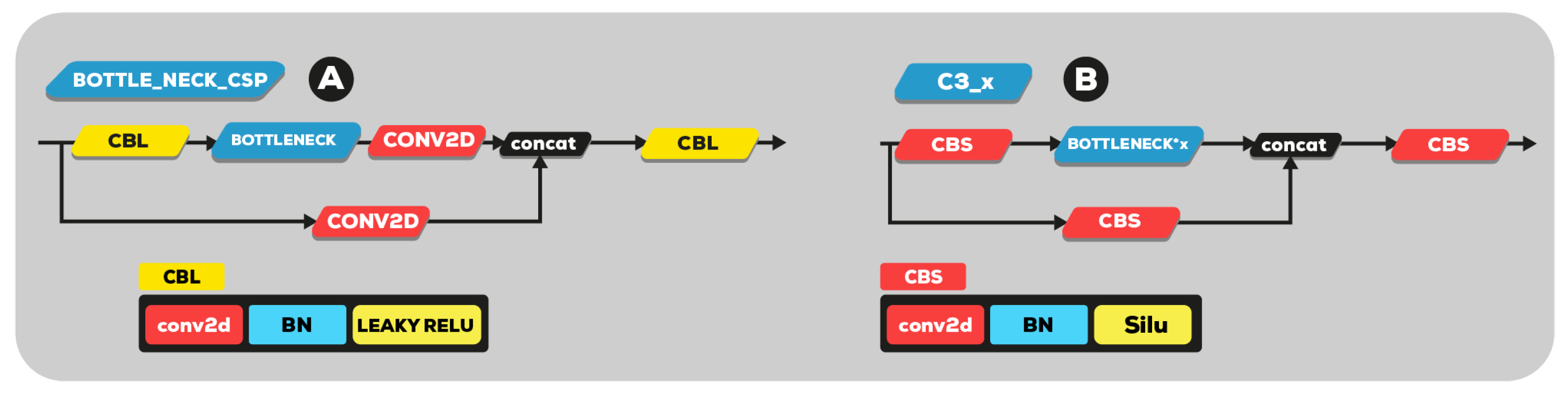
(A) YOLOv5 version 5.0 bottleneck CSP and (B) new C3 module.
Figure 7.
(A) YOLOv5 version 5.0 bottleneck CSP and (B) new C3 module.
Figure 8.
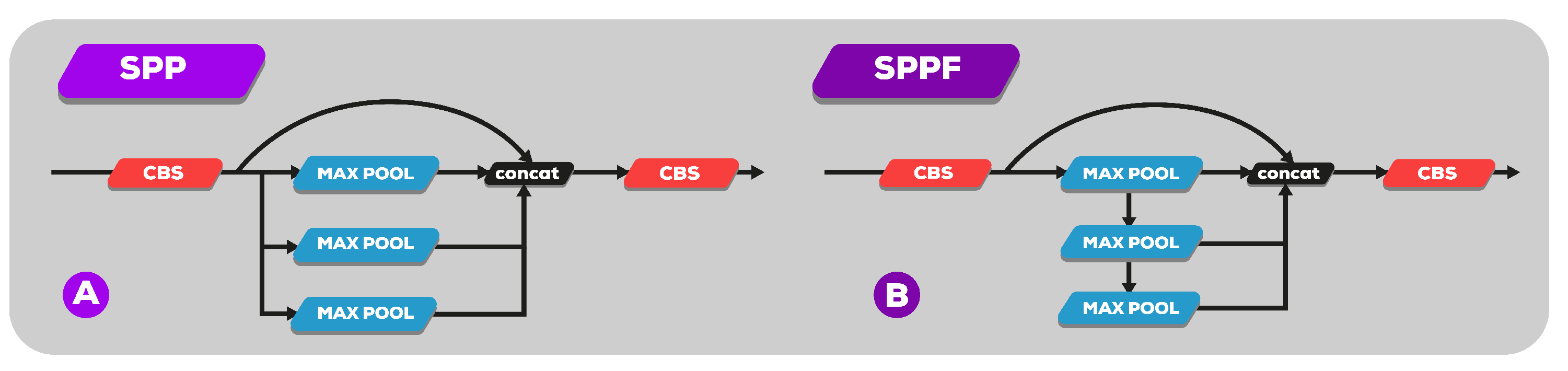
(A) SPP module for YOLO series. (B) SPPF module.
Figure 8.
(A) SPP module for YOLO series. (B) SPPF module.
Figure 9.
Example of a YOLOv5 workflow when applying a 80 × 80 grid to the input image. The input image is split into 3600 grid cells. Each grid cell predicts 3 bounding boxes and their objectness score along with their class predictions.
Figure 9.
Example of a YOLOv5 workflow when applying a 80 × 80 grid to the input image. The input image is split into 3600 grid cells. Each grid cell predicts 3 bounding boxes and their objectness score along with their class predictions.
Figure 10.
Workflow of TTA ensemble algorithm. Three methods have been applied to detect the objects in the original image.
Figure 10.
Workflow of TTA ensemble algorithm. Three methods have been applied to detect the objects in the original image.
Figure 11.
(a) Examples of green fluorescent cell images that have been captured from the Leica DMi8 fluorescence microscope and meticulously annotated. (b) Examples of green fluorescent cell images that have been captured from mgLAMP using a smart phone camera and meticulously annotated by scientists.
Figure 11.
(a) Examples of green fluorescent cell images that have been captured from the Leica DMi8 fluorescence microscope and meticulously annotated. (b) Examples of green fluorescent cell images that have been captured from mgLAMP using a smart phone camera and meticulously annotated by scientists.
Figure 12.
Example of intersection area (IoU). ’C’ represents the Intersection, which is the area of overlap between the ground truth and prediction.
Figure 12.
Example of intersection area (IoU). ’C’ represents the Intersection, which is the area of overlap between the ground truth and prediction.
Figure 13.
Various GIoU situations with values in each and an indicator of gradient presence in each case based on ’C’, which represents the Box Displacement between GT and Prediction.
Figure 13.
Various GIoU situations with values in each and an indicator of gradient presence in each case based on ’C’, which represents the Box Displacement between GT and Prediction.
Figure 14.
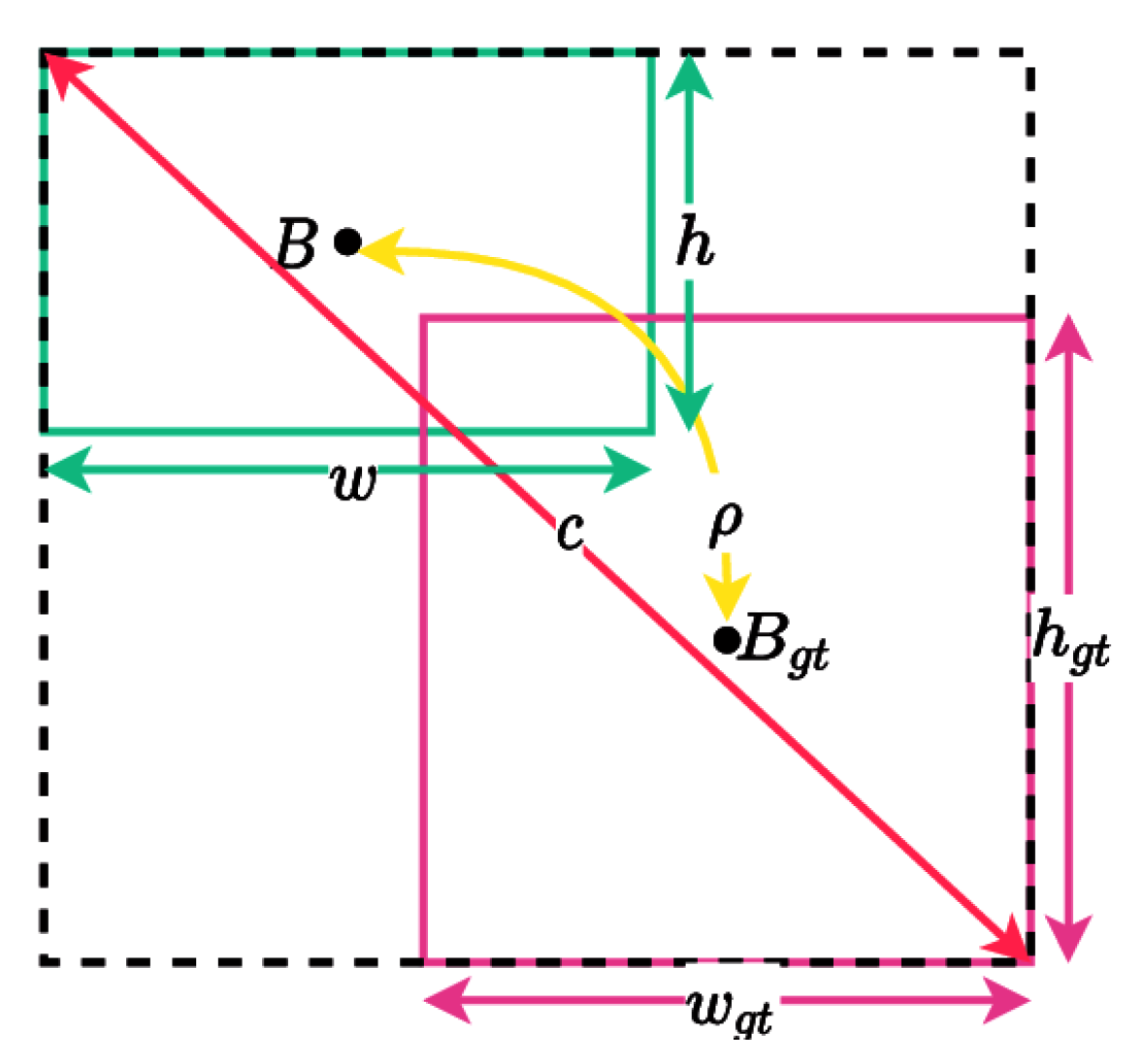
CIoU situations. (): Euclidean distance between two centre points. (B): represents the centre points of the prediction box. (): represents the centre points of the ground truth box. (): The weight function. c: represents the diagonal distance of the minimum closure region that can contain both prediction frame and real frame. (): measures the similarity of aspect ratio.
Figure 14.
CIoU situations. (): Euclidean distance between two centre points. (B): represents the centre points of the prediction box. (): represents the centre points of the ground truth box. (): The weight function. c: represents the diagonal distance of the minimum closure region that can contain both prediction frame and real frame. (): measures the similarity of aspect ratio.
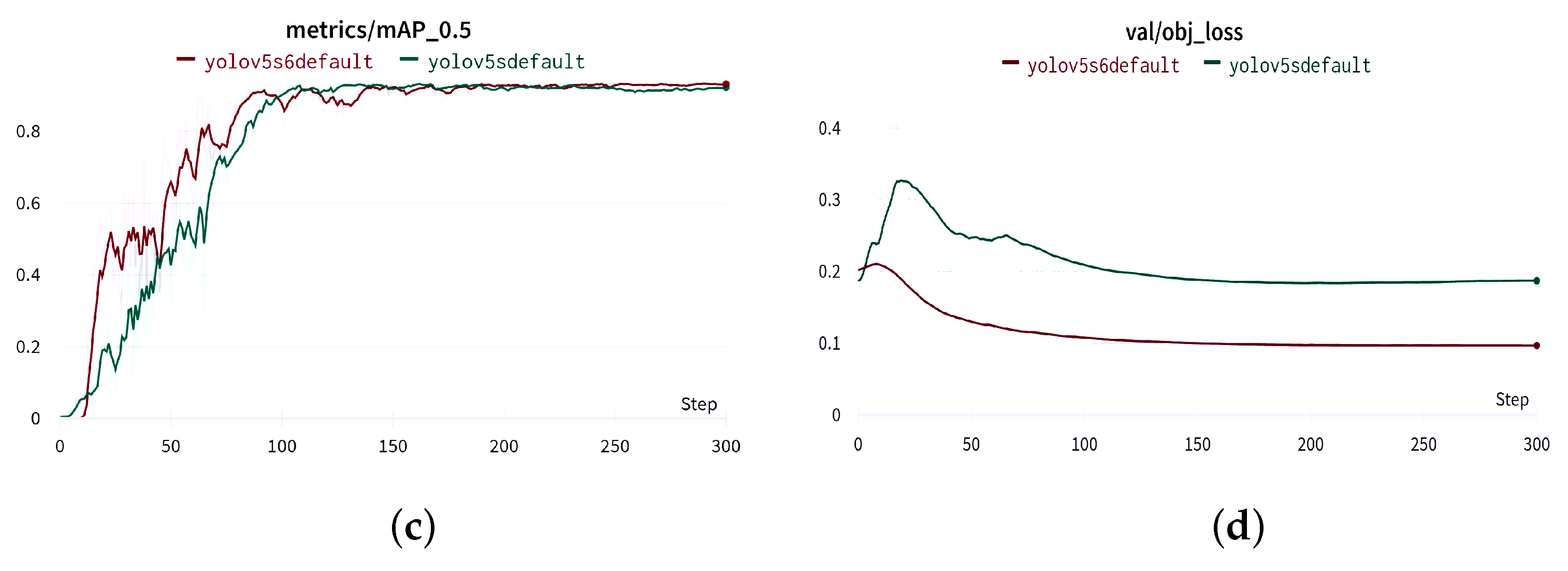
Figure 15.
Results of validation phase using YOLOv5-s and YOLOv5-s6. (a) precision, (b) recall, (c) mAP@0.5 and (d) objectness loss.
Figure 15.
Results of validation phase using YOLOv5-s and YOLOv5-s6. (a) precision, (b) recall, (c) mAP@0.5 and (d) objectness loss.
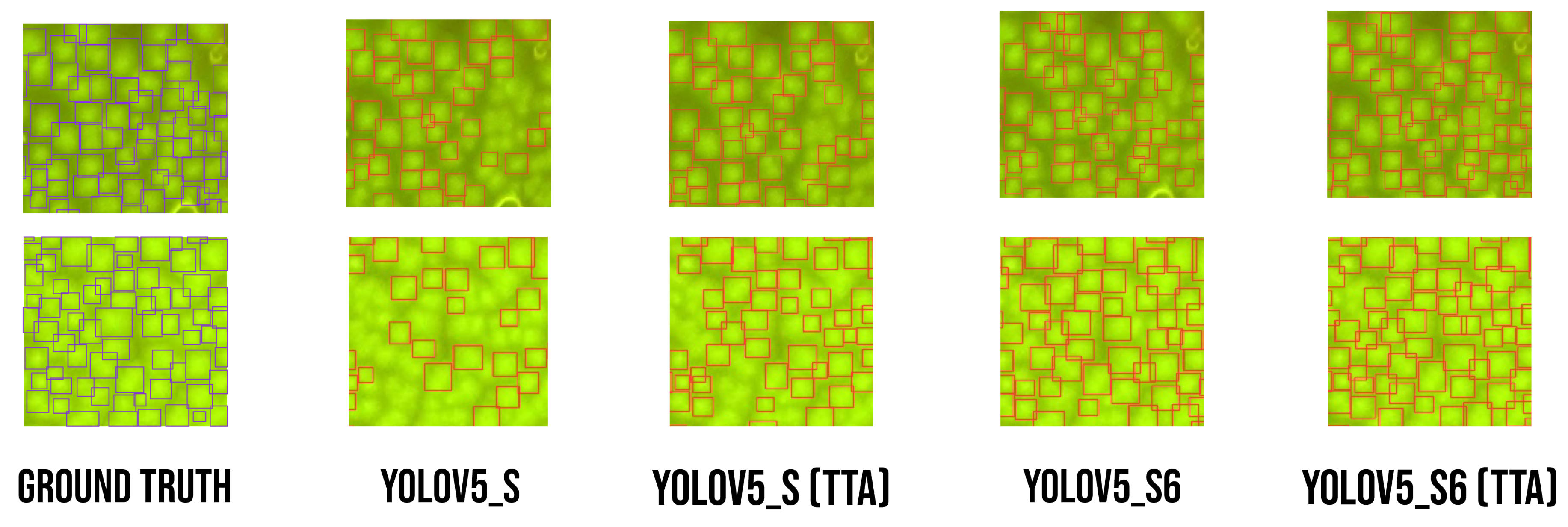
Figure 16.
Comparing results of images from test phase with ground truth annotation.
Figure 16.
Comparing results of images from test phase with ground truth annotation.
Table 1.
Hyperparameters values.
Table 1.
Hyperparameters values.
| Hyperparametres | Values |
|---|
| Input size | |
| Batch size | 32 |
| Warmup_Epochs | 3 |
| Epochs | 300 |
| Scale | 0.5 |
| Mosiac | 1 |
| Mixup | 0 |
| Translate | 0.1 |
| 4 |
| 0.7 |
| 0.4 |
| Momentum | 0.937 |
| Decay | 0.0005 |
Table 2.
YOLOv5 Performance on validation dataset.
Table 2.
YOLOv5 Performance on validation dataset.
| Module | Input | mAP@0.5 | Recall | Precision | Size |
|---|
| YOLOv5-s | 640 × 640 | 94.1 | 91.2 | 91.5 | 12 Mb |
| YOLOv5-s6 | 640 × 640 | 95.6 | 91.8 | 93.8 | 25 Mb |
Table 3.
Performances results using YOLOv5-s and YOLOv5-s6 on test images.
Table 3.
Performances results using YOLOv5-s and YOLOv5-s6 on test images.
| Module | Input | mAP@0.5 | Recall | Precision | Size | Inferance |
|---|
| YOLOv5-s | 640 × 640 | 87 | 82.3 | 89 | 12 Mb | 5.1 ms |
| YOLOv5-s (TTA) | 640 × 640 | 88 | 83.5 | 90.2 | 12 Mb | 7.9 ms |
| YOLOv5-s6 | 640 × 640 | 88.3 | 84.8 | 85.3 | 25 Mb | 5.6 ms |
| YOLOv5-s6 (TTA) | 640 × 640 | 90.3 | 85.2 | 90 | 25 Mb | 7.0 ms |
Table 4.
Comparison of different models on the SARS-CoV-2 fluorescent RNA dataset.
Table 4.
Comparison of different models on the SARS-CoV-2 fluorescent RNA dataset.
| Module | Backbones | mAP@0.5 | Size |
|---|
| Dynamic R-CNN | Resnet50 [42] | 50.3 | 330 mb |
| Faster R-CNN | Resnet50 | 58.7 | 320 mb |
| Cascade R-CNN | Resnet50 | 61.7 | 571 mb |
| PAA | Resnet50 | 70.4 | 256 mb |
| YOLOv5-s6 | CSPnet | 90.3 | 25 mb |
Table 5.
A comparison between different backbones.
Table 5.
A comparison between different backbones.
| Module | Backbone | Input | mAP@0.5 | Size |
|---|
| YOLOv3-tiny | Darknet | 640 × 640 | 79.1 | 33.2 Mb |
| YOLOv5-mobile | MobilenetV3 [43] | 640 × 640 | 82.9 | 6 Mb |
| YOLOv5-s6 | CSPnet | 640 × 640 | 90.3 | 25 Mb |
| YOLOv5-VGG | VGG [33] | 640 × 640 | 80.1 | 13.7 Mb |
| YOLOv5-Shuffle | Shuffelnet [44] | 640 × 640 | 76.2 | 8 Mb |
Table 6.
Performance of YOLOv5-P6 variations.
Table 6.
Performance of YOLOv5-P6 variations.
| Module | mAP@0.5 | Size |
|---|
| YOLOv5-n6 | 83.3 | 6.29 mb |
| YOLOv5-s6 | 90.3 | 24 mb |
| YOLOv5-m6 | 91.2 | 71 mb |
| YOLOv5-l6 | 91.6 | 145 mb |
| YOLOv5-x6 | 88.9 | 267 mb |


 ,
, 


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}