
Multi-Input Speech Emotion Recognition Model Using Mel Spectrogram and GeMAPS
Abstract
:1. Introduction
2. Related Works
2.1. Emotional Speech Database
2.2. Audio Features Used in SER
2.3. Models Used in SER
3. Materials and Methods
3.1. Dataset
3.2. Extraction of MelSpec and GeMAPS from Speech Data
3.3. Model Construction and Emotion Recognition
3.3.1. Training Procedure of the Model
3.3.2. Loss Functions Used in the Model
3.3.3. Emotion Recognition by the Model
4. Experiments
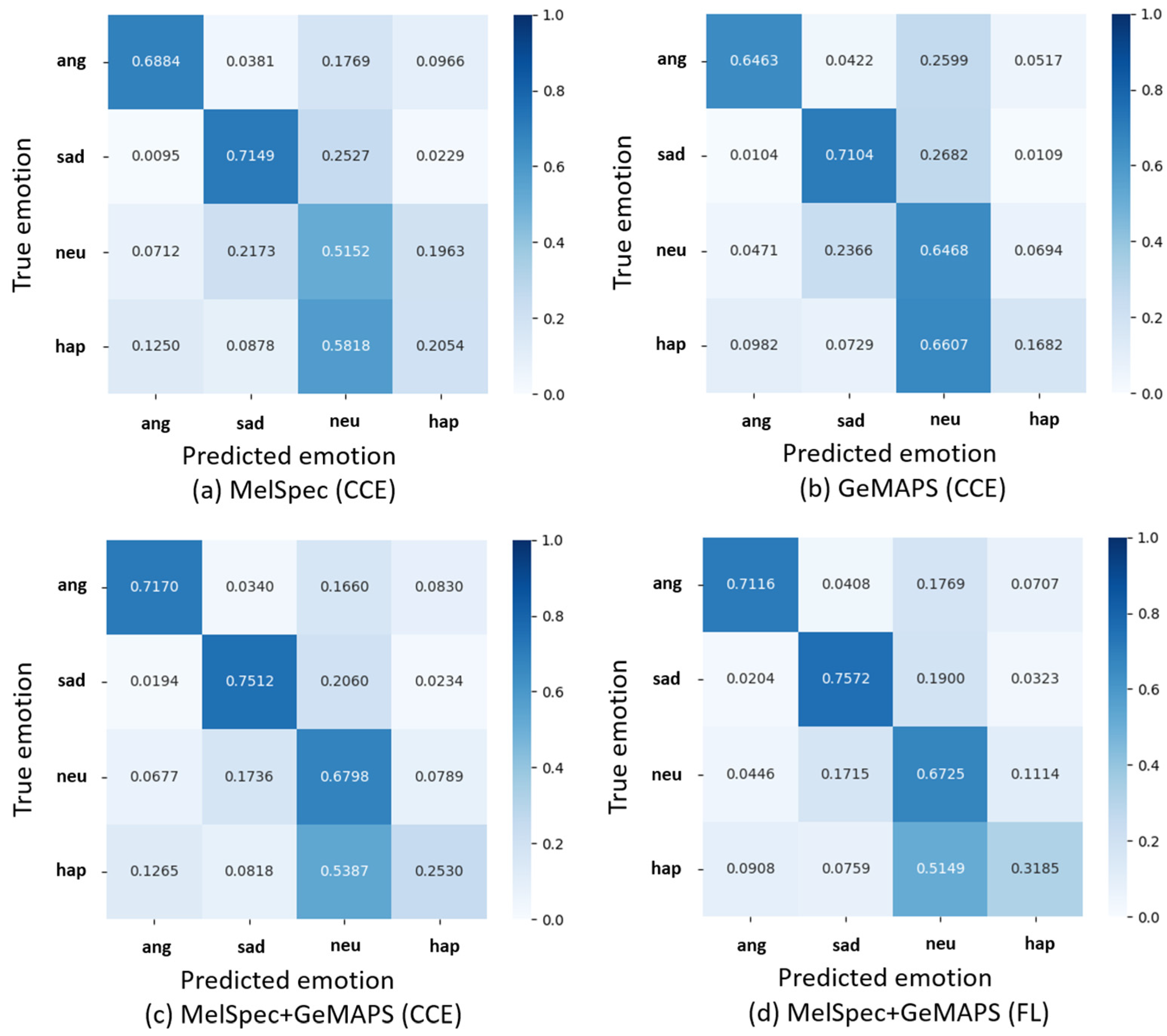
5. Results
5.1. Recognition Results of the Model
5.2. Comparison of Recognition Accuracy with Existing Methods
6. Discussion
7. Conclusions
- The proposed model delivered higher recognition accuracy than using MelSpec and GeMAPS separately.
- The recognition accuracy of the proposed model was higher than or comparable to those of the state-of-the-art existing methods.
- The introduction of the FL function improved the recognition accuracy of the “happiness” emotion.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kolakowska, A.; Szwoch, W.; Szwoch, M. A Review of Emotion Recognition Methods Based on Data Acquired via Smartphone Sensors. Sensors 2020, 20, 6367. [Google Scholar] [CrossRef] [PubMed]
- Fahad, S.; Ranjan, A.; Yadav, J.; Deepak, A. A survey of speech emotion recognition in natural environment. Digit. Signal Process. 2021, 110, 102951. [Google Scholar] [CrossRef]
- Zhuang, J.; Guan, Y.; Nagayoshi, H.; Muramatu, K.; Nagayoshi, H.; Watanuki, K.; Tanaka, E. Real-time emotion recognition system with multiple physiological signals. J. Adv. Mech. Des. Syst. Manuf. 2019, 13, JAMDSM0075. [Google Scholar] [CrossRef]
- Wei, L.; Wei-Long, Z.; Bao-Liang, L. Emotion recognition using multimodal deep learning. In Neural Information Processing: ICONIP 2016; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2016; Volume 9948, pp. 521–529. [Google Scholar]
- Alsharekh, M.F. Facial Emotion Recognition in Verbal Communication Based on Deep Learning. Sensors 2022, 22, 6105. [Google Scholar] [CrossRef] [PubMed]
- ArulDass, S.D.; Jayagopal, P. Identifying Complex Emotions in Alexithymia Affected Adolescents Using Machine Learning Techniques. Diagnostics 2022, 12, 3188. [Google Scholar] [CrossRef] [PubMed]
- Zhou, S.; Wu, X.; Jiang, F.; Huang, Q.; Huang, C. Emotion Recognition from Large-Scale Video Clips with Cross-Attention and Hybrid Feature Weighting Neural Networks. Int. J. Environ. Res. Public Health 2023, 20, 1400. [Google Scholar] [CrossRef]
- Lim, M.J.; Yi, M.H.; Shin, J.H. Intrinsic Emotion Recognition Considering the Emotional Association in Dialogues. Electronics 2023, 12, 326. [Google Scholar] [CrossRef]
- Dissanayake, T.; Rajapaksha, Y.; Ragel, R.; Nawinne, I. An Ensemble Learning Approach for Electrocardiogram Sensor Based Human Emotion Recognition. Sensors 2019, 19, 4495. [Google Scholar] [CrossRef] [PubMed]
- Ahmad, Z.; Khan, N. A Survey on Physiological Signal-Based Emotion Recognition. Bioengineering 2022, 9, 688. [Google Scholar] [CrossRef]
- Pell, M.D.; Monetta, L.; Paulmann, S.; Kotz, S.A. Recognizing emotions in a foreign language. J. Nonverbal Behav. 2009, 33, 107–120. [Google Scholar] [CrossRef] [Green Version]
- Fayek, H.F.; Lech, M.; Cavedon, L. Evaluating deep learning architectures for speech emotion recognition. Neural Netw. 2017, 92, 60–68. [Google Scholar] [CrossRef] [PubMed]
- Wani, T.M.; Gunawan, T.S.; Qadri, S.A.A.; Kartiwi, M.; Ambikairajah, E. A Comprehensive Review of Speech Emotion Recognition. Systems. IEEE Access 2021, 9, 47795–47814. [Google Scholar] [CrossRef]
- Eyben, F.; Scherer, K.R.; Schuller, B.W.; Sundberg, J.; André, E.; Busso, C.; Devillers, L.Y.; Epps, J.; Laukka, P.; Narayanan, S.; et al. The Geneva minimalistic acoustic parameter set (GeMAPS) for voice research and affective computing. IEEE Trans. Affect. Comput. 2016, 7, 190–202. [Google Scholar] [CrossRef]
- Busso, C.; Bulut, M.; Lee, C.; Kazemzadeh, A.; Mower, E.; Samuel, K.; Chang, J.N.; Lee, S.; Narayan, S.S. IEMOCAP: Interactive emotional dyadic motion capture database. Lang. Resour. Eval. 2008, 42, 335–359. [Google Scholar] [CrossRef]
- Li, D.; Li, J.; Zhuo, Y.; Linyu, S.; Zhe, W. Speech emotion recognition using recurrent neural networks with directional self-attention. Expert Syst. Appl. 2021, 173, 114683. [Google Scholar] [CrossRef]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 318–327. [Google Scholar] [CrossRef]
- Yeung, M.; Sala, E.; Schonlieb, C.B.; Rundo, L. Unified Focal loss: Generalising dice and cross entropy-based losses to handle class imbalanced medical image segmentation. Comput. Med. Imaging Graph. 2022, 95, 102026. [Google Scholar] [CrossRef] [PubMed]
- Dhall, A.; Goecke, R.; Lucey, S.; Gedeon, T. Collecting large, richly annotated facial-expression databases from movies. IEEE Multimed. 2021, 19, 34–41. [Google Scholar] [CrossRef]
- Ringeval, F.; Sonderegger, A.; Sauer, J.; Lalanne, D. Introducing the RECOLA multimodal corpus of remote collaborative and affective interactions. In Proceedings of the 2013 10th IEEE International Conference and Workshops on Automatic Face and Gesture Recognition (FG), Shanghai, China, 22–26 April 2013; pp. 1–8. [Google Scholar]
- Li, Y.; Tao, J.; Chao, L.; Bao, W.; Liu, Y. CHEAVD: A Chinese natural emotional audio—Visual database. J. Ambient. Intell. Humaniz. Comput. 2017, 8, 913–924. [Google Scholar] [CrossRef]
- Steidl, S. Automatic Classification of Emotion Related User States in Spontaneous Children’s Speech; Logos-Verlag: Berlin, Germany, 2009; p. 250. [Google Scholar]
- Hansen, J.H.L.; Bou, G.; Sahar, E.; Sarikaya, R.; Pellom, B. Getting started with SUSAS: A speech under simulated and actual stress database. Eurospeech 1997, 97, 1743–1746. [Google Scholar]
- Chavhan, Y.; Dhore, M.L.; Pallavi, Y. Speech Emotion Recognition Using Support Vector Machine. Int. J. Comput. Appl. 2010, 1, 6–9. [Google Scholar] [CrossRef]
- Iliou, T.; Christos, N.A. Comparison of different classifiers for emotion recognition. In Proceedings of the PCI 2009, 13th Panhellenic Conference on Informatics, Corfu, Greece, 10–12 September 2009. [Google Scholar]
- Shahin, I. Studying and enhancing talking condition recognition in stressful and emotional talking environments based on HMMs, CHMM2s and SPHMMs. J. Multimodal User Interfaces 2012, 6, 59–71. [Google Scholar] [CrossRef]
- Shahin, I.; Ali, B.N.; Shibani, H. Emotion recognition using hybrid Gaussian mixture model and deep neural network. IEEE Access 2019, 7, 26777–26787. [Google Scholar] [CrossRef]
- Sato, N.; Obuchi, Y. Emotion recognition using mel-frequency cepstral coefficients. Inf. Media Technol. 2007, 2, 835–848. [Google Scholar] [CrossRef] [PubMed]
- Bombatkar, A.; Gayatri, B.; Khushbu, M.; Gautam, S.; Vishnupriya, G. Emotion recognition using Speech Processing Using k-nearest neighbor algorithm. Int. J. Eng. Res. Appl. 2014, 4, 68–71. [Google Scholar]
- Lee, C.; Mower, E.; Busso, C.; Lee, S.; Narayan, S. Emotion recognition using a hierarchical binary decision tree approach. Speech Commun. 2011, 53, 1162–1171. [Google Scholar] [CrossRef]
- Youddha, B.S.; Shivani, G. A systematic literature review of speech emotion recognition approaches. Neurocomputing 2022, 492, 245–263. [Google Scholar]
- Jahamgir, R.; Ying, W.T.; Nweke, H.F.; Mujtaba, G.; Al-Garadi, M.; Ali, I. Speaker identification through artificial intelligence techniques: A comprehensive review and research challenges. Expert Syst. Appl. 2021, 171, 114591. [Google Scholar] [CrossRef]
- Motamed, S.; Saeed, S.; Azam, R. Speech emotion recognition based on a modified brain emotional learning model. Biol. Inspired Cogn. Archit. 2017, 19, 32–38. [Google Scholar] [CrossRef]
- LeCun, Y.; Yoshua, B.; Geoffrey, H. Deep learning. Nature 2015, 34, 436–444. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. In Proceedings of the 25th International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012. [Google Scholar]
- Kerkeni, L.; Serrestou, Y.; Raoof, K.; Mbarki, M.; Mahjoub, M.A.; Cleder, C. Automatic speech emotion recognition using an optimal combination of features based on EMD-TKEO. Speech Commun. 2019, 114, 22–35. [Google Scholar] [CrossRef]
- López, D.; Edwin, R.; Oscar, G. Primary user characterization for cognitive radio wireless networks using a neural system based on deep learning. Artif. Intell. Rev. 2019, 52, 169–195. [Google Scholar] [CrossRef]
- Badshah, A.M.; Ahmad, J.; Rahim, N.; Baik, S.W. Speech Emotion Recognition from Spectrograms with Deep Convolutional Neural Network. In Proceedings of the 2017 International Conference on Platform Technology and Service (PlatCon), Busan, Republic of Korea, 12–15 February 2017. [Google Scholar]
- Zhang, X.; Wang, M.J.; Guo, X.D. Multi-modal emotion recognition based on deep learning in speech, video and text. In Proceedings of the 2020 IEEE 5th International Conference on Signal and Image Processing (ICSIP), Nanjing, China, 23–25 October 2020; pp. 328–333. [Google Scholar]
- Satt, A.; Rozenberg, S.; Hoory, R. Efficient Emotion Recognition from Speech Using Deep Learning on Spectrograms. In Proceedings of the 18th Annual Conference of the International Speech Communication Association (Interspeech 2017), Stockholm, Sweden, 20–24 August 2017; pp. 1089–1093. [Google Scholar]
- Neumann, M.; Vu, N.T. Attentive convolutional neural network based speech emotion recognition: A study on the impact of input features, signal length, and acted speech. In Proceedings of the 18th Annual Conference of the International Speech Communication Association (Interspeech 2017), Stockholm, Sweden, 20–24 August 2017. [Google Scholar]
- Yenigalla, P.; Kumar, A.; Tripathi, S.; Singh, C.; Kar, S.; Vepa, J. Speech Emotion Recognition Using Spectrogram & Phoneme Embedding. In Proceedings of the 19th Annual Conference of the International Speech Communication Association (Interspeech 2018), Hyderabad, India, 2–6 September 2018. [Google Scholar]
- Yao, Z.; Wang, Z.; Liu, W.; Liu, Y.; Pan, I. Speech emotion recognition using fusion of three multi-task learning-based classifiers: HSF-DNN, MS-CNN and LLD-RNN. Speech Commun. 2020, 120, 11–19. [Google Scholar] [CrossRef]
- The Interactive Emotional Dyadic Motion Capture (IEMOCAP). Available online: https://sail.usc.edu/iemocap/index.html (accessed on 14 April 2021).
- Pandey, S.K.; Shekhawat, H.S.; Prasanna, S.R.M. Deep learning techniques for speech emotion recognition: A review. In Proceedings of the 2019 29th International Conference Radioelektronika (RADIOELEKTRONIKA), Pardubice, Czech Republic, 16–18 April 2019. [Google Scholar]
- McFee, B.; Raffel, C.; Liang, D.; Ellis, P.D.W.; Mcvicar, M.; Battenberg, E.; Nieto, O. Librosa: Audio and Music Signal Analysis in Python. In Proceedings of the 14th Python in Science Conference (SciPy 2015), Austin, TX, USA, 6–12 July 2015. [Google Scholar]
- Eyben, F.; Wollmer, M.; Schuller, B. Opensmile: The Munich versatile and fast open-source audio feature extractor. In Proceedings of the MM’10: ACM Multimedia Conference, Firenze, Italy, 25–19 October 2010. [Google Scholar]
- Bridle, J.S. Training Stochastic Model Recognition Algorithms as Networks Can Lead to Maximum Mutual Information Estimation of Parameters. In Advances in Neural Information Processing Systems, Proceedings of the Name of the 2nd International Conference on Neural Information Processing Systems (NIPS’89), Denver, CO, USA, 27–30 November 1989; MIT Press: Cambridge, MA, USA, 1990; pp. 211–217. [Google Scholar]
- Glorot, X.; Benglo, Y. Understanding the difficulty of training deep feedforward neural networks. In Proceedings of the 13th International Conference on Artificial Intelligence and Statistics (AISTATS) 2010, Sardinia, Italy, 13–15 May 2010. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Peng, P.; Mingyu, Y.; Weisheng, X.; Jiaxin, L. Fully integer-based quantization for mobile convolutional neural network inference. Neurocomputing 2021, 432, 194–205. [Google Scholar] [CrossRef]
- Choudhary, T.; Mishra, V.; Gowami, A.; Sarangapani, J. Inference-aware convolutional neural network pruning. Future Gener. Comput. Syst. 2022, 135, 44–56. [Google Scholar] [CrossRef]
- Yan, S.; Ye, S.; Han, T.; Li, Y.; Alasaarela, E. Speech Interactive Emotion Recognition System Based on Random Forest. In Proceedings of the 2020 International Wireless Communications and Mobile Computing (IWCMC) 2020, Limassol, Cyprus, 15–19 June 2020. [Google Scholar]
- Sravanthi, K.; Charles, A.T.; Ranga, B. Speech enhancement with noise estimation and filtration using deep learning models. Theor. Comput. Sci. 2023, 941, 14–28. [Google Scholar]



{kind=link}
{kind=link}
| Features | WA | UA |
|---|---|---|
| MelSpec (CCE) | 0.5710 | 0.5310 |
| GeMAPS (CCE) | 0.6130 | 0.5429 |
| MelSpec+GeMAPS (CCE) | 0.6597 | 0.6003 |
| MelSpec+GeMAPS (FL) | 0.6657 | 0.6149 |
| Author | Year | Features | Method | WA | UA |
|---|---|---|---|---|---|
| Lee et al. [30] | 2011 | Acoustic parameters | Hierarchical binary decision tree | 0.5638 | 0.5846 |
| Neumann et al. [41] | 2017 | MelSpec | Attention-CNN | 0.6195 | 0.6211 |
| Satt et al. [40] | 2017 | MelSpec | Convolution-LSTM | 0.6880 | 0.5940 |
| Zhang et al. [39] | 2020 | Acoustic parameters | DNN | 0.6272 | N/A |
| Yao et al. [43] | 2020 | Acoustic parameters, MelSpec | DNN+CNN+RNN multi-input model | 0.5710 | 0.5830 |
| Li et al. [16] | 2021 | Acoustic parameters | BLSTM-DSA | 0.6216 | 0.5521 |
| Proposed model | 2023 | MelSpec+GeMAPS | CNN+DNN | 0.6657 | 0.6149 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Toyoshima, I.; Okada, Y.; Ishimaru, M.; Uchiyama, R.; Tada, M. Multi-Input Speech Emotion Recognition Model Using Mel Spectrogram and GeMAPS. Sensors 2023, 23, 1743. https://doi.org/10.3390/s23031743
Toyoshima I, Okada Y, Ishimaru M, Uchiyama R, Tada M. Multi-Input Speech Emotion Recognition Model Using Mel Spectrogram and GeMAPS. Sensors. 2023; 23(3):1743. https://doi.org/10.3390/s23031743
Chicago/Turabian StyleToyoshima, Itsuki, Yoshifumi Okada, Momoko Ishimaru, Ryunosuke Uchiyama, and Mayu Tada. 2023. "Multi-Input Speech Emotion Recognition Model Using Mel Spectrogram and GeMAPS" Sensors 23, no. 3: 1743. https://doi.org/10.3390/s23031743